-
大文件处理(上传,下载)思考
文件处理一直都是前端人的心头病,如何控制好文件大小,文件太大上传不了,文件下载时间太长,tcp直接给断开了😱😱😱等效果
为了方便大家有意义的学习,这里就先放效果图,如果不满足直接返回就行,不浪费大家的时间。
文件上传

文件上传实现,分片上传,暂停上传,恢复上传,文件合并等
文件下载
为了方便测试,我上传了1个1g的大文件拿来下载,前端用的是
流的方式来保存文件的,具体的可以看这个api TransformStream正文
本项目的地址是: https://github.com/cll123456/deal-big-file 需要的自提
上传
请带着以下问题来阅读下面的文章
- 如何计算文件的hash,怎么做计算hash是最快的
- 文件分片的方式有哪些
- 如何控制分片上传的http请求(控制并发),大文件的碎片太多,直接把网络打垮
- 如何暂停上传
- 如何恢复上传等
计算文件hash
在计算文件hash的方式,主要有以下几种:
分片全量计算hash、抽样计算hash。
在这两种方式上,分别又可以使用web-work和浏览器空闲(requestIdleCallback)来实现.web-work有不明白的可以看这里: https://juejin.cn/post/7091068088975622175requestIdleCallback有不明白的可以看这里: https://juejin.cn/post/7069597252473815053
接下来咋们来计算文件的hash,计算文件的hash需要使用
spark-md5这个库,全量计算文件hash
export async function calcHashSync(file: File) { // 对文件进行分片,每一块文件都是分为2MB,这里可以自己来控制 const size = 2 * 1024 * 1024; let chunks: any[] = []; let cur = 0; while (cur < file.size) { chunks.push({ file: file.slice(cur, cur + size) }); cur += size; } // 可以拿到当前计算到第几块文件的进度 let hashProgress = 0 return new Promise(resolve => { const spark = new SparkMD5.ArrayBuffer(); let count = 0; const loadNext = (index: number) => { const reader = new FileReader(); reader.readAsArrayBuffer(chunks[index].file); reader.onload = e => { // 累加器 不能依赖index, count++; // 增量计算md5 spark.append(e.target?.result as ArrayBuffer); if (count === chunks.length) { // 通知主线程,计算结束 hashProgress = 100; resolve({ hashValue: spark.end(), progress: hashProgress }); } else { // 每个区块计算结束,通知进度即可 hashProgress += 100 / chunks.length // 计算下一个 loadNext(count); } }; }; // 启动 loadNext(0); }); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
全量计算文件hash,在文件小的时候计算是很快的,但是在文件大的情况下,计算文件的hash就会非常慢,并且影响主进程哦🙄🙄🙄
抽样计算文件hash
抽样就是取文件的一部分来继续,原理如下:
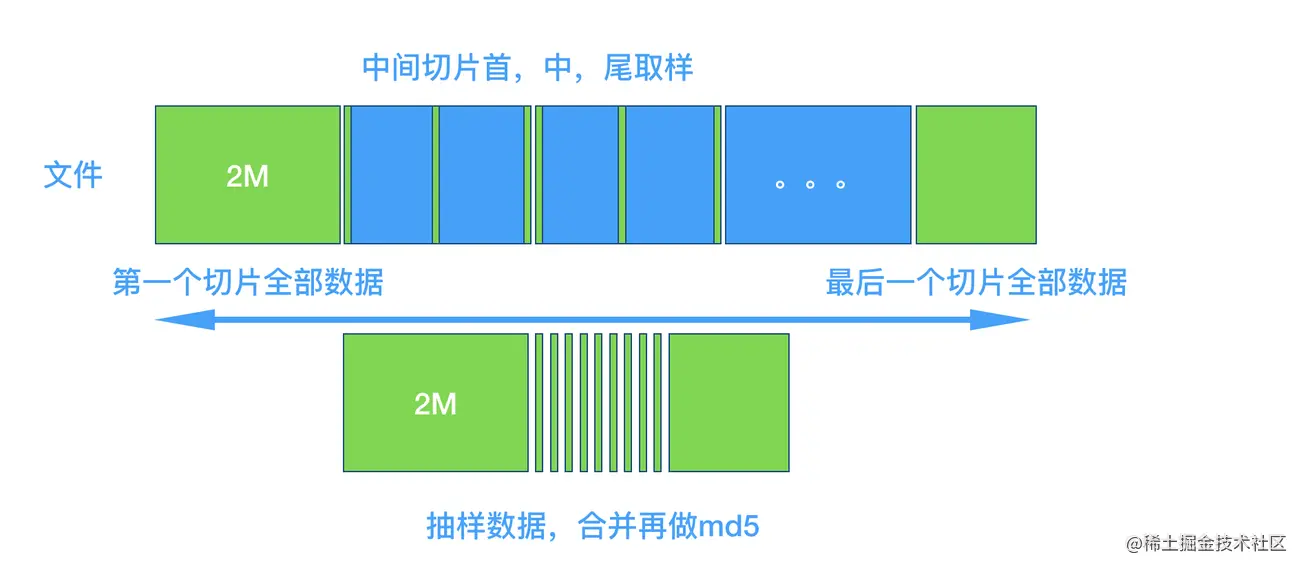
/** * 抽样计算hash值 大概是1G文件花费1S的时间 * * 采用抽样hash的方式来计算hash * 我们在计算hash的时候,将超大文件以2M进行分割获得到另一个chunks数组, * 第一个元素(chunks[0])和最后一个元素(chunks[-1])我们全要了 * 其他的元素(chunks[1,2,3,4....])我们再次进行一个分割,这个时候的分割是一个超小的大小比如2kb,我们取* 每一个元素的头部,尾部,中间的2kb。 * 最终将它们组成一个新的文件,我们全量计算这个新的文件的hash值。 * @param file {File} * @returns */ export async function calcHashSample(file: File) { return new Promise(resolve => { const spark = new SparkMD5.ArrayBuffer(); const reader = new FileReader(); // 文件大小 const size = file.size; let offset = 2 * 1024 * 1024; let chunks = [file.slice(0, offset)]; // 前面2mb的数据 let cur = offset; while (cur < size) { // 最后一块全部加进来 if (cur + offset >= size) { chunks.push(file.slice(cur, cur + offset)); } else { // 中间的 前中后去两个字节 const mid = cur + offset / 2; const end = cur + offset; chunks.push(file.slice(cur, cur + 2)); chunks.push(file.slice(mid, mid + 2)); chunks.push(file.slice(end - 2, end)); } // 前取两个字节 cur += offset; } // 拼接 reader.readAsArrayBuffer(new Blob(chunks)); // 最后100K reader.onload = e => { spark.append(e.target?.result as ArrayBuffer); resolve({ hashValue: spark.end(), progress: 100 }); }; }); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
这个设计是不是发现挺灵活的,真是个人才哇
在这两个的基础上,咋们还可以分别使用web-worker和requestIdleCallback来实现,源代码在hereヾ(≧▽≦*)o
这里把我电脑配置说一下,公司给我分的电脑配置比较lower, 8g内存的老机器。计算(
3.3g文件的)hash的结果如下: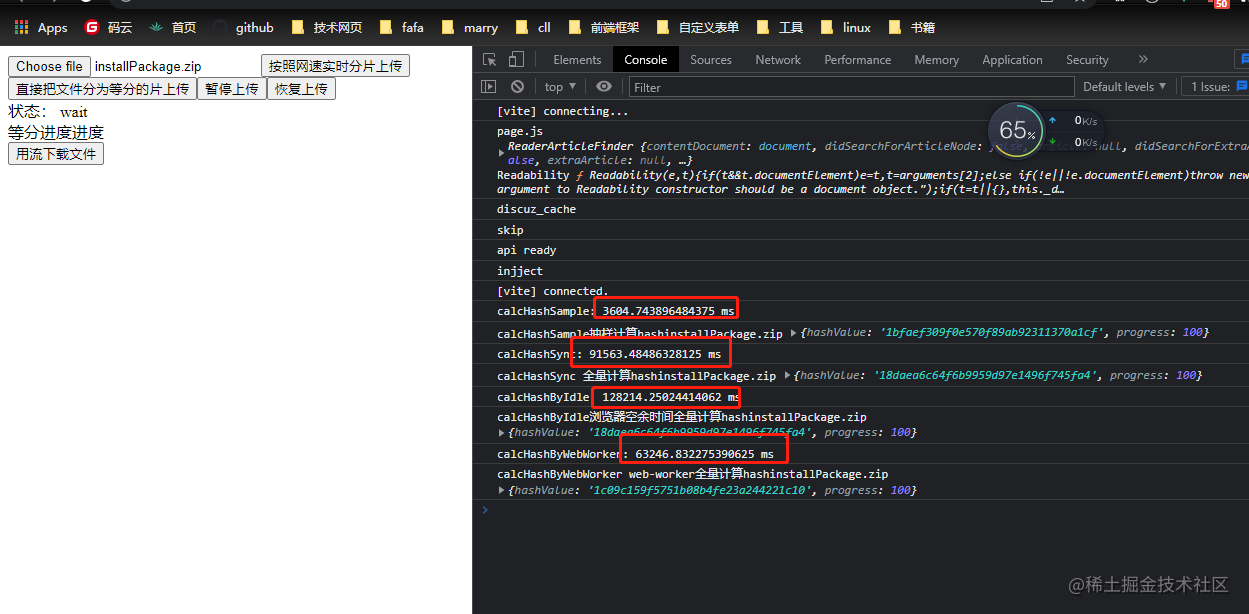
结果很显然,全量无论怎么弄,都是比抽样的更慢。
文件分片的方式
这里可能大家会说,文件分片方式不就是等分吗,其实还可以根据网速上传的速度来实时调整分片的大小哦!
const handleUpload1 = async (file:File) => { if (!file) return; const fileSize = file.size let offset = 2 * 1024 * 1024 let cur = 0 let count = 0 // 每一刻的大小需要保存起来,方便后台合并 const chunksSize = [0, 2 * 1024 * 1024] const obj = await calcHashSample(file) as { hashValue: string }; fileHash.value = obj.hashValue; //todo 判断文件是否存在存在则不需要上传,也就是秒传 while (cur < fileSize) { const chunk = file.slice(cur, cur + offset) cur += offset const chunkName = fileHash.value + "-" + count; const form = new FormData(); form.append("chunk", chunk); form.append("hash", chunkName); form.append("filename", file.name); form.append("fileHash", fileHash.value); form.append("size", chunk.size.toString()); let start = new Date().getTime() // todo 上传单个碎片 const now = new Date().getTime() const time = ((now - start) / 1000).toFixed(4) let rate = Number(time) / 10 // 速率有最大和最小 可以考虑更平滑的过滤 比如1/tan if (rate < 0.5) rate = 0.5 if (rate > 2) rate = 2 offset = parseInt((offset / rate).toString()) chunksSize.push(offset) count++ } //todo 可以发送合并操作了 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
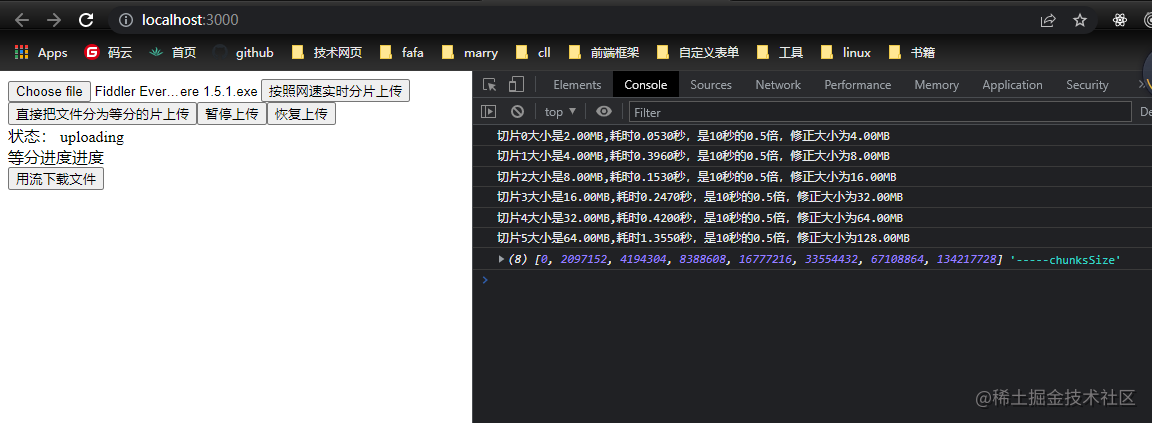
🥉🥉🥉ATTENTION!!! 如果是这样上传的文件碎片,如果中途断开是无法续传的(每一刻的网速都是不一样的),除非每一次上传都把 chunksSize(分片的数组)保存起来哦
控制http请求(控制并发)
控制http的请求咋们可以换一种想法,是不是就是控制异步任务呢?
/** * 异步控制池 - 异步控制器 * @param concurrency 最大并发次数 * @param iterable 异步控制的函数的参数 * @param iteratorFn 异步控制的函数 */ export async function* asyncPool<IN, OUT>(concurrency: number, iterable: ReadonlyArray<IN>, iteratorFn: (item: IN, iterable?: ReadonlyArray<IN>) => Promise<OUT>): AsyncIterableIterator<OUT> { // 传教set来保存promise const executing = new Set<Promise<IN>>(); // 消费函数 async function consume() { const [promise, value] = await Promise.race(executing) as unknown as [Promise<IN>, OUT]; executing.delete(promise); return value; } // 遍历参数变量 for (const item of iterable) { const promise = (async () => await iteratorFn(item, iterable))().then( value => [promise, value] ) as Promise<IN>; executing.add(promise); // 超出最大限制,需要等待 if (executing.size >= concurrency) { yield await consume(); } } // 存在的时候继续消费promise while (executing.size) { yield await consume(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
暂停请求
暂停请求,其实也很简单,在原生的
XMLHttpRequest里面有一个方法是xhr?.abort(),在发送请求的同时,在发送请求的时候,咋们用一个数组给他装起来,然后就可以自己直接调用abort方法了。在封装request的时候,咋们要求传入一个
requestList就好:export function request({ url, method = "post", data, onProgress = e => e, headers = {}, requestList }: IRequest) { return new Promise((resolve, reject) => { const xhr = new XMLHttpRequest(); xhr.upload.onprogress = onProgress // 发送请求 xhr.open(method, baseUrl + url); // 放入其他的参数 Object.keys(headers).forEach(key => xhr.setRequestHeader(key, headers[key]) ); xhr.send(data); xhr.onreadystatechange = e => { // 请求是成功的 if (xhr.readyState === 4) { if (xhr.status === 200) { if (requestList) { // 成功后删除列表 const i = requestList.findIndex(req => req === xhr) requestList.splice(i, 1) } // 获取服务响应的结构 const resp = JSON.parse(xhr.response); // 这个code是后台规定的,200是正确的响应,500是异常 if (resp.code === 200) { // 成功操作 resolve({ data: (e.target as any)?.response }); } else { reject('报错了 大哥') } } else if (xhr.status === 500) { reject('报错了 大哥') } } }; // 存入请求 requestList?.push(xhr) }); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
有了请求数组后,那么咋们想暂时直接遍历请求数组,调用
abort方法恢复上传
恢复上传是判断有哪些碎片上已经存在的,存在的就不需要上传了,不存在的继续上传。所以咋们要一个接口,
verify传入文件的hash,文件名称,判断文件是否存在或者说是上传了多少。/** * 验证文件是否存在 * @param req * @param res */ async handleVerify(req: http.IncomingMessage, res: http.ServerResponse) { // 解析post请求数据 const data = await resolvePost(req) as { filename: string, hash: string } const { filename, hash } = data // 获取文件后缀名称 const ext = extractExt(filename) const filePath = path.resolve(this.UPLOAD_DIR, `${hash}${ext}`) // 文件是否存在 let uploaded = false let uploadedList: string[] = [] if (fse.existsSync(filePath)) { uploaded = true } else { // 文件没有完全上传完毕,但是可能存在部分切片上传完毕了 uploadedList = await getUploadedList(path.resolve(this.UPLOAD_DIR, hash)) } res.end( JSON.stringify({ code: 200, uploaded, uploadedList // 过滤诡异的隐藏文件 }) ) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
注意,这里还需要在每一次验证的时候需要去删除片段的最后
几块文件,防止最后几块文件是不完全上传的残杂.合并文件
合并文件很好理解,就是把所有的碎片进行合并,但是有一个地方需要注意的是,咋们不能把所有的文件都读到内存中进行合并,而是使用流的方式来进行合并,边读边写入文件。写入文件的时候需要保证顺序,不然文件可能就会损坏了。
这一部分代码会比较多,感兴趣的同学可以看源码文件下载
对于文件下载的话,后端其实很简单,就是返回一个流就行,如下:
/** * 文件下载 * @param req * @param res */ async handleDownload(req: http.IncomingMessage, res: http.ServerResponse) { // 解析get请求参数 const resp: UrlWithParsedQuery = await resolveGet(req) // 获取文件名称 const filePath = path.resolve(this.UPLOAD_DIR, resp.query.filename as string) // 判断文件是否存在 if (fse.existsSync(filePath)) { // 创建流来读取文件并下载 const stream = fse.createReadStream(filePath) // 写入文件 stream.pipe(res) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
对于前端的话,咋们需要使用一个库,就是
streamsaver,这个库调用了TransformStreamapi来实现浏览器中把文件用流的方式保存在本地的。有了这个后,那就非常简单的使用啦😄😄😃const downloadFile = async () => { // StreamSaver // 下载的路径 const url = 'http://localhost:4001/download?filename=b0d9a1481fc2b815eb7dbf78f2146855.zip' // 创建一个文件写入流 const fileStream = streamSaver.createWriteStream('b0d9a1481fc2b815eb7dbf78f2146855.zip') // 发送请求下载 fetch(url).then(res => { const readableStream = res.body // more optimized if (window.WritableStream && readableStream?.pipeTo) { return readableStream.pipeTo(fileStream) .then(() => console.log('done writing')) } const writer = fileStream.getWriter() const reader = res.body?.getReader() const pump: any = () => reader?.read() .then(res => res.done ? writer.close() : writer.write(res.value).then(pump)) pump() }) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
-
相关阅读:
【三维重建】DreamGaussian:高斯splatting的单视图3D内容生成(原理+代码)
轮播图禁用手势滑动
2022 年 9 月青少年软编等考 C 语言一级真题解析
6. 无线体内纳米网:我们真的可以有一个运行在5G上的无线电网
文生图一致性角色生成!谷歌最新文本到图片扩散模型工作
修改vscode底部栏背景和字体颜色
Linux多进程(二)进程通信方式三 共享内存
【10】使用Test类测试&ImGUI
【C语言】2.数组与指针
k8s发布eureka集群,创建微服务项目
- 原文地址:https://blog.csdn.net/qq_41499782/article/details/124898811