概述:
通常情况下我们需要操作数据量较大的数据库表时候,需要关注sql的开发规范、数据索引以及慢查询
开发规范:
1 查询sql都应该建立索引
覆盖索引:(这里我们先引用百度百科的解释)覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了(或覆盖了)满足查询结果的数据就叫做覆盖索引。优点:减少了回表时间
注:主键索引:叶子节点保存数据 ;辅助索引:叶子节点保存主键值 (基于innoDB引擎)
我们这里通过EXPLAIN语句查询(留意EXPLAIN输出的rows列,如果rows列太高,比如几千,上万,那么就需要考虑是否索引不佳或连接表的顺序不当)
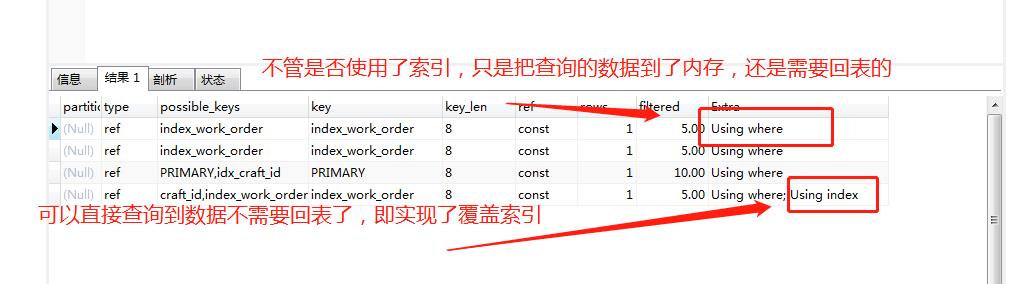
联合索引 + 最左匹配原则 :(这里引用知乎普及一下知识)
联合索引:索引的底层是一颗B+树,联合索引同样是一颗B+树,只不过联合索引的健值数量不是一个,而是多个,数据库依据联合索引最左的字段来构建B+树。
最左匹配原则:
联合索引(A,B,C),最左优先,以最左边的为起点任何连续的索引都能匹配上。
1)遇到范围查询(>、<、between、like)就会停止匹配。
2)因为Mysql中有查询优化器,会自动优化查询顺序,因此A,B,C顺序调换不影响查询结果。
3)没有从最左边开始,最后查询没有用到索引,用的是全表扫描
这时候一定有小伙伴会问:没看懂,这是啥啊?你以为我看懂了?我肯定也没啊?但是没关系,你只要记住为什么要使用联合索引,或者记住他的优点是什么?
优点:a.建立一个联合索引,相当于建立了多个索引(比如你建立一个(a,b)联合索引,等于建立了a,(a,b)),这样可以减少操作和磁盘空间的开销;
b.多索引会提高搜索效率实现之前所说的覆盖索引,减少回表
注:我们在使用GROUP BY、DISTINCT、ORDER BY,如果连接了多张表,ORDER BY的列应该属于连接顺序的第一张表,需要保证索引列和ORDER BY的列相同,且各列均按相同的方向进行排序
避免索引失效
索引会提高我们执行速度,但是有些操作会让我们索引失效,所以我们要注意不能让索引失效:
1.触发了值类型转换
2.对索引进行函数操作或者表达式操作
3.使用like进行了左模糊匹配或者左右模糊匹配 like "%##" ;like"%##%" (注:右模糊不会影响索引)
利用子查询优化超多分页场景
(这里引用一下阿里巴巴JAVA开发手册):MySQL 分页并不是跳过 offset 行,而是取 offset +N 行,然后返回放弃前 offset 行,返回
N 行,所以当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行 SQL 改写
简单说我们应该用子查询先把要查的范围取出来,作为一个临时表b
例如:select a.* from a , b where a.id = b.id
注:子查询在性能上会比连接查询差,所以能改成连接查询尽量改成连接查询。
事务隔离
这一部分我自己也不是很了解,最近出了一次生产事故所以特意去做了大致了解。大致介绍一下背景,我是个测试小罗罗,我们公司属于物联网公司,在边缘端本地工控机会存放比较大量的本地数据,但是受限于工控机的配置较低所以需要定期做数据清理,就是用定时任务去删除一些无用数据。接到这个测试任务的时候,我对数据库事务这块基本没有了解,所以用例的覆盖并没有并发操作。上线后第二天早上就接到告警电话了,一个大型工厂使用受限,cpu已经达到90%降不下来了,主要占比就是mysql。
复盘:本次优化的sql语句因为使用了多表连删,(这里需要特别提一句,MySQL连接(JOIN)严重降低了并发性,对于高并发,高性能的服务,应该尽量避免连接太多表,如果可能,对于一些严重影响性能的SQL,建议程序在应用层就实现部分连接的功能)虽然有部分回表但基本索引是走的没问题的,但是因为我们使用的是mysql的默认事务Repeatable read(可重复读),在删除语句事务执行时候上了行锁+间隙锁,并发的插入语句修改语句被锁,因为数据量很大导致瞬间cpu飙升,最终导致影响工厂生产。
总结:如果有了解到你们数据库隔离级别走的是 可重复读 (REPEATABLE READ)一定要注意了!只有在可重复读的隔离级别下,才会有间隙锁。间隙锁可能会造成死锁!
慢查询
当索引解决不了慢查询时,一般由于业务表的数据量太大导致,可以考虑走redis或者增加视图查询
当读写性能均遇到瓶颈时,升级数据库架构或者考虑分库分表