前言
本篇博客将会介绍 CSAPP 之 CacheLab 的解题过程,分为 Part A 和 Part B 两个部分,其中 Part A 要求使用代码模拟一个高速缓存存储器,Part B 要求优化矩阵的转置运算。
解题过程
Part A
题目要求
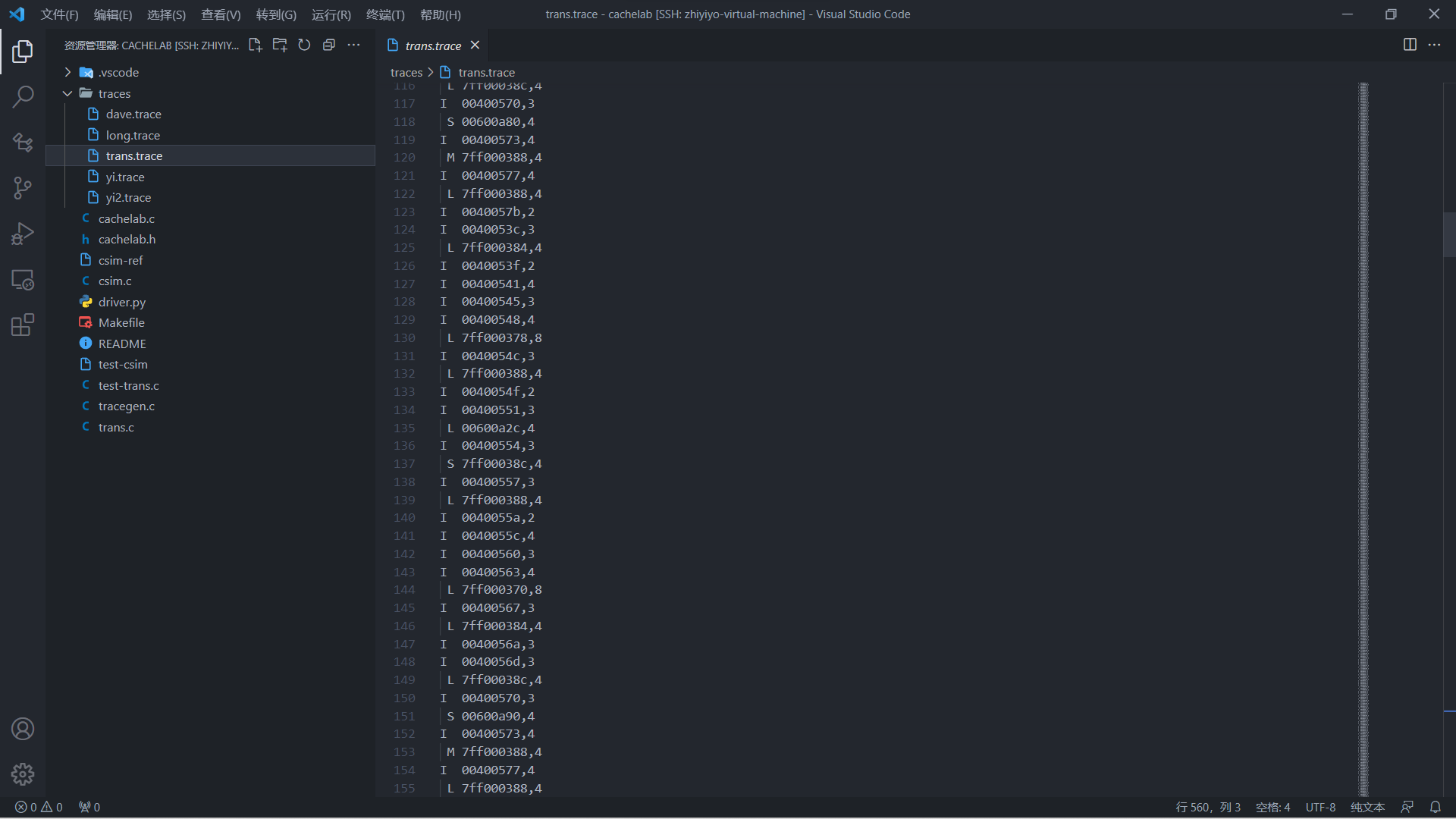
Part A 给出了一些后缀名为 trace 的文件,文件中的内容如下图所示,其中每一行代表一次对缓存的操作,格式为 [空格] 操作 地址,数据大小,其中操作的类型有以下几种:
- I:取指令操作
- L:读数据操作
- S:写数据操作
- M:修改数据操作,比如先读一次数据再写一次数据
只有 I 操作没有带前置空格,其他操作都有一个前置空格。地址为 64 位,数据大小以字节为单位。
Part A 要求实现的缓存存储器的行为和 csim-ref 一致,使用 LRU 算法进行替换操作。CSAPP 中指出高速缓存存储器可以用四元组 (S,E,B,m)
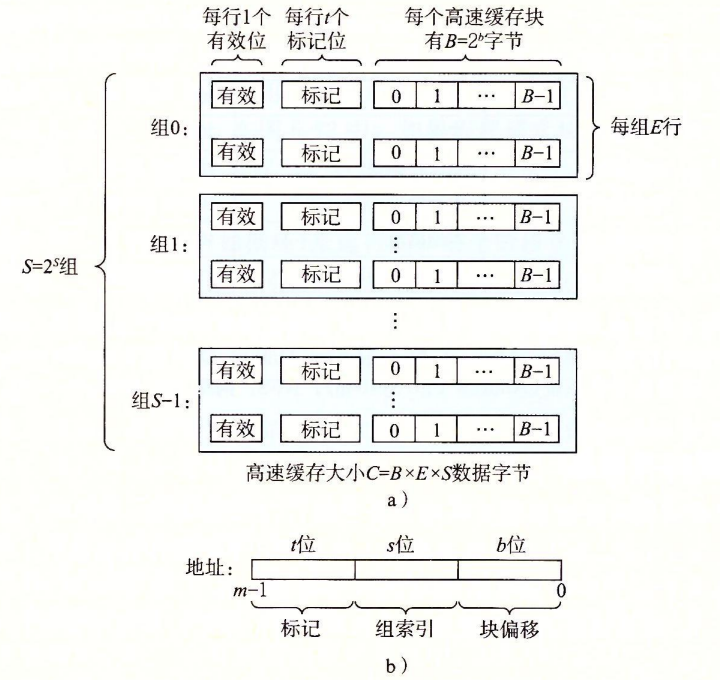
对于模拟的高速缓存,至少需要接受 4 个参数:
-s:组索引的位数-E:行数-b:块大小 B=2bB=2b 中的 bb -t:trace文件的路径
根据给定的 trace 文件,模拟的高速缓存 csim 需要给出命中次数、未命中次数和替换次数,只有和 csim-ref 的次数一样才能拿到分数。
代码
我们首先定义一个结构,用来代表高速缓存中的行,由于题目没要求存储数据,所以结构中并没有包含代表缓存块的数组,同时题目要求使用 LRU 替换算法,所以包含一个 time 代表与上次访问相隔多久:
复制typedef struct {
int valid;
int tag;
int time;
} CacheLine, *CacheSet, **Cache;
接着完成入口函数,进行命令行参数解析和模拟工作:
复制#include <assert.h>
#include <getopt.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "cachelab.h"
int hit, miss, evict;
int s, S, E, b;
char filePath[100];
Cache cache;
int main(int argc, char* argv[]) {
int opt;
while ((opt = getopt(argc, argv, "s:E:b:t:")) != -1) {
switch (opt) {
case 's':
s = atoi(optarg);
S = 1 << s;
break;
case 'E':
E = atoi(optarg);
break;
case 'b':
b = atoi(optarg);
break;
case 't':
strcpy(filePath, optarg);
break;
}
}
mallocCache();
simulate();
freeCache();
printSummary(hit, miss, evict);
return 0;
}
由于 smalloc 函数来在堆上分配空间,使用结束之后还得将这部分空间释放掉:
复制/* 动态分配缓存空间 */
void mallocCache() {
cache = (Cache)malloc(S * sizeof(CacheSet));
assert(cache);
for (int i = 0; i < S; ++i) {
cache[i] = (CacheSet)malloc(E * sizeof(CacheLine));
assert(cache[i]);
memset(cache[i], 0, sizeof(CacheLine) * E);
}
}
/* 释放缓存空间 */
void freeCache() {
for (int i = 0; i < S; ++i) {
free(cache[i]);
}
free(cache);
}
根据 trace 文件进行模拟的函数如下所示,其中 I 和 S 只需访问缓存一次,而 M 需要两次,且每进行一次操作,就得更新一次时间戳:
复制/* 模拟缓存读写操作*/
void simulate() {
FILE* file = fopen(filePath, "r");
assert(file);
char op;
uint64_t address;
int size;
while (fscanf(file, " %c %lx,%d", &op, &address, &size) > 0) {
switch (op) {
case 'M':
accessCache(address);
case 'L':
case 'S':
accessCache(address);
break;
}
lruUpdate();
}
fclose(file);
}
/* 更新访问时间 */
void lruUpdate() {
for (int i = 0; i < S; ++i) {
for (int j = 0; j < E; ++j) {
if (cache[i][j].valid) {
cache[i][j].time++;
}
}
}
}
访问缓存的代码如下所示,首先根据组索引选出组,接着行匹配,只有有效位为 1 且 tag 与地址中的 t
复制/* 访问缓存 */
void accessCache(uint64_t address) {
int tag = address >> (b + s);
uint64_t mask = ((1ULL << 63) - 1) >> (63 - s);
CacheSet cacheSet = cache[(address >> b) & mask];
// 缓存击中
for (int i = 0; i < E; ++i) {
if (cacheSet[i].valid && cacheSet[i].tag == tag) {
hit++;
cacheSet[i].time = 0;
return;
}
}
miss++;
// 有空位,直接写入
for (int i = 0; i < E; ++i) {
if (!cacheSet[i].valid) {
cacheSet[i].valid = 1;
cacheSet[i].tag = tag;
cacheSet[i].time = 0;
return;
}
}
// 没有空位,只能使用 LRU 算法进行替换
evict++;
int evictIndex = 0;
int maxTime = 0;
for (int i = 0; i < E; ++i) {
if (cacheSet[i].time > maxTime) {
maxTime = cacheSet[i].time;
evictIndex = i;
}
}
cacheSet[evictIndex].tag = tag;
cacheSet[evictIndex].time = 0;
}
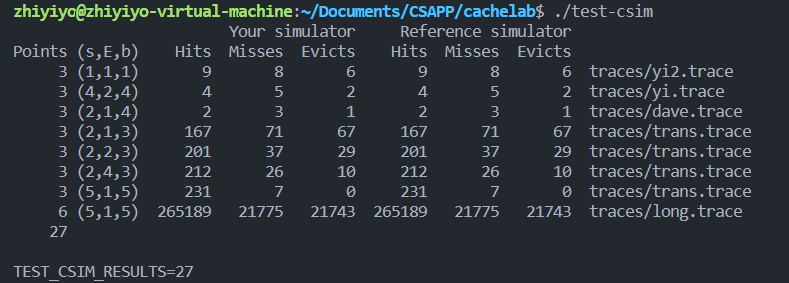
最终运行结果如下,发现模拟结果和参考答案一致:
Part B
Part B 给出了最原始的转置操作代码:
复制void trans(int M, int N, int A[N][M], int B[M][N]) {
int i, j, tmp;
for (i = 0; i < N; i++) {
for (j = 0; j < M; j++) {
tmp = A[i][j];
B[j][i] = tmp;
}
}
}
题目要求针对 32×32
- 使用分块技术进行优化
- 对角线上的元素会引发冲突未击中
由于高速缓存的 S=2s=32
复制for (int i = 0; i < N; i += 8)
for (int j = 0; j < M; j += 8)
for (int ii = i; ii < i + 8; ++ii)
for (int jj=j; jj < j + 8; ++jj)
B[jj][ii] = A[ii][jj];
测试效果如下图所示,发现未命中次数为 343 次,而满分要求未命中小于 300 次:

根据友情提示,我们应该避免对角线上元素原地转置引发的冲突未命中问题,所以使用循环展开直接访问行中的 8 个元素并赋值给 B
复制int a, b, c, d, e, f, g, h;
for (int i = 0; i < N; i += 8) {
for (int j = 0; j < M; j += 8) {
for (int ii = i; ii < i + 8; ++ii) {
a = A[ii][j];
b = A[ii][j + 1];
c = A[ii][j + 2];
d = A[ii][j + 3];
e = A[ii][j + 4];
f = A[ii][j + 5];
g = A[ii][j + 6];
h = A[ii][j + 7];
B[j][ii] = a;
B[j + 1][ii] = b;
B[j + 2][ii] = c;
B[j + 3][ii] = d;
B[j + 4][ii] = e;
B[j + 5][ii] = f;
B[j + 6][ii] = g;
B[j + 7][ii] = h;
}
}
}
再次测试,未命中次数为 287 次:

对于 64×64
复制int a, b, c, d;
for (int i = 0; i < N; i += 4) {
for (int j = 0; j < M; j += 4) {
for (int ii = i; ii < i + 4; ++ii) {
a = A[ii][j];
b = A[ii][j + 1];
c = A[ii][j + 2];
d = A[ii][j + 3];
B[j][ii] = a;
B[j + 1][ii] = b;
B[j + 2][ii] = c;
B[j + 3][ii] = d;
}
}
}
测试结果如下图所示,未命中次数为 1699 次,虽然没有达到低于 1300 次的满分要求(但是至少拿了一点分数):

最后是 61×67
复制int a, b, c, d, e, f, g, h;
int n = 8 * (N / 8);
int m = 8 * (M / 8);
for (int i = 0; i < n; i += 8) {
for (int j = 0; j < m; j += 8) {
for (int ii = i; ii < i + 8; ++ii) {
a = A[ii][j];
b = A[ii][j + 1];
c = A[ii][j + 2];
d = A[ii][j + 3];
e = A[ii][j + 4];
f = A[ii][j + 5];
g = A[ii][j + 6];
h = A[ii][j + 7];
B[j][ii] = a;
B[j + 1][ii] = b;
B[j + 2][ii] = c;
B[j + 3][ii] = d;
B[j + 4][ii] = e;
B[j + 5][ii] = f;
B[j + 6][ii] = g;
B[j + 7][ii] = h;
}
}
}
// 处理剩余部分
for (int i = 0; i < n; i++) {
for (int j = m; j < M; j++) {
B[j][i] = A[i][j];
}
}
for (int i = n; i < N; i++) {
for (int j = 0; j < M; j++) {
B[j][i] = A[i][j];
}
}
测试结果如下图所示,未命中次数为 2093,接近满分 2000:

总结
通过这次实验,可以加深对存储器层次结构和高速缓存工作原理的理解,为后续学习打下铺垫(经典实验报告总结)。以上~~