[源码解析] NVIDIA HugeCTR,GPU版本参数服务器---(3)
0x00 摘要
在本系列中,我们介绍了 HugeCTR,这是一个面向行业的推荐系统训练框架,针对具有模型并行嵌入和数据并行密集网络的大规模 CTR 模型进行了优化。
本文主要介绍HugeCTR所依赖的输入数据和一些基础数据结构。其中借鉴了HugeCTR源码阅读 这篇大作,特此感谢。因为 HugeCTR 实际上是一个具体而微的深度学习系统,所以它也实现了众多基础功能,值得想研究深度学习框架的朋友仔细研读。
本系列其他文章如下:
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(1)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (2)
0x01 回顾
我们首先回归一下前文内容,流水线逻辑关系如下:

训练流程如下:

基于前文知识,我们接下来看看如何处理数据。
0x02 数据集
HugeCTR 目前支持三种数据集格式,即Norm、Raw和Parquet,具体格式参见如下:
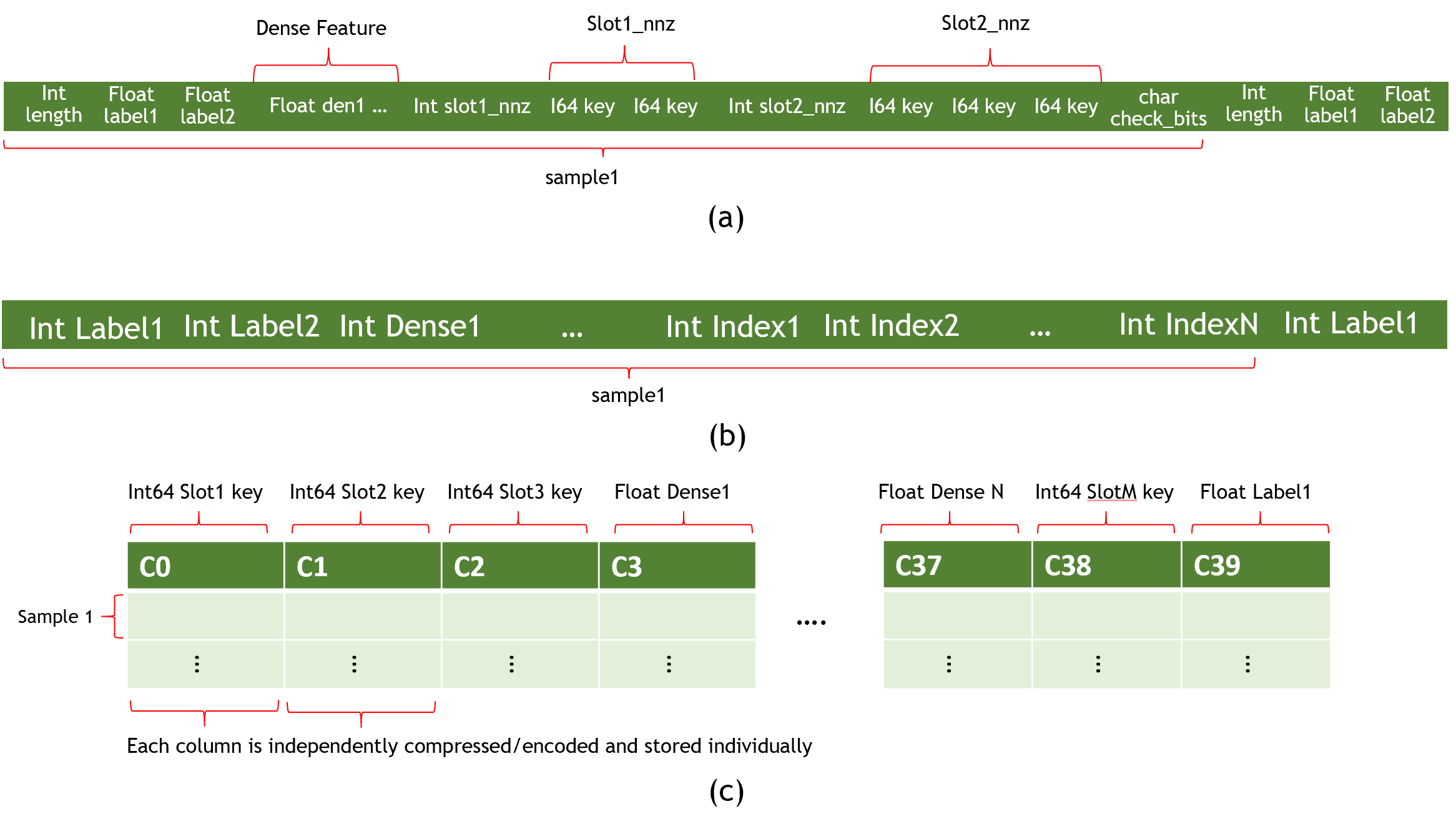
Fig. 1: (a) Norm (b) Raw (c) Parquet Dataset Formats
2.1 Norm
为了最大化数据加载性能并最小化存储,Norm 数据集格式由一组二进制数据文件和一个 ASCII 格式的文件列表组成。模型文件应指定训练和测试(评估)集的文件名,样本中的元素(键)最大数目和标签维度,具体如图 1(a)所示。
2.1.1 数据文件
一个数据文件是一个读取线程的最小读取粒度,因此每个文件列表中至少需要10个文件才能达到最佳性能。数据文件由header和实际表格(tabular )数据组成。
Header定义:
typedef struct DataSetHeader_ {
long long error_check; //0: 没有错误检查;1:check_num
long long number_of_records; //此数据文件中的样本数
long long label_dim; //标签的维度
long long density_dim; //密集特征的维度
long long slot_num; //每个嵌入的 slot_num
long long reserved[ 3 ]; //保留以备将来使用
数据集头;
数据定义(每个样本):
typedef struct Data_ {
int length; //此示例中的字节数(可选:仅在 check_sum 模式下)
float label[label_dim];
float dense[dense_dim];
Slot slots[slot_num];
char checkbits; //此样本的校验位(可选:仅在checksum模式下)
} Data;
typedef struct Slot_ {
int nnz;
unsigned int* keys; //可在配置文件的 `solver` 对象中使用 `"input_key_type"` 更改为 `long long`
} Slot;
数据字段(field)通常有很多样本。每个样本以格式化为整数的标签开始,然后是nnz(非零数)和使用 long long(或无符号整数)格式的输入key,如图 1(a)所示。
categorical 的输入key分布到插槽(slot)中,不允许重叠。例如:slot[0] = {0,10,32,45}, slot[1] = {1,2,5,67}。如果有任何重叠,它将导致未定义的行为。例如,给定slot[0] = {0,10,32,45}, slot[1] = {1,10,5,67},查找10键的表将产生不同的结果,结果根据插槽分配给 GPU 的方式。
2.1.2 文件列表
文件列表的第一行应该是数据集中数据文件的数量,然后是这些文件的路径,具体如下所示:
$ cat simple_sparse_embedding_file_list.txt
10
./simple_sparse_embedding/simple_sparse_embedding0.data
./simple_sparse_embedding/simple_sparse_embedding1.data
./simple_sparse_embedding/simple_sparse_embedding2.data
./simple_sparse_embedding/simple_sparse_embedding3.data
./simple_sparse_embedding/simple_sparse_embedding4.data
./simple_sparse_embedding/simple_sparse_embedding5.data
./simple_sparse_embedding/simple_sparse_embedding6.data
./simple_sparse_embedding/simple_sparse_embedding7.data
./simple_sparse_embedding/simple_sparse_embedding8.data
./simple_sparse_embedding/simple_sparse_embedding9.data
使用例子如下:
reader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.Norm,
source = ["./wdl_norm/file_list.txt"],
eval_source = "./wdl_norm/file_list_test.txt",
check_type = hugectr.Check_t.Sum)
2.2 Raw
Raw 数据集格式与 Norm 数据集格式的不同之处在于训练数据出现在一个二进制文件中,并且使用 int32。图 1 (b) 显示了原始数据集样本的结构。
注意:此格式仅接受独热数据。
Raw数据集格式只能与嵌入类型 LocalizedSlotSparseEmbeddingOneHot 一起使用。
例子:
reader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.Raw,
source = ["./wdl_raw/train_data.bin"],
eval_source = "./wdl_raw/validation_data.bin",
check_type = hugectr.Check_t.Sum)
2.3 Parquet
Parquet 是一种面向列的、开源的数据格式。它可用于 Apache Hadoop 生态系统中的任何项目。为了减小文件大小,它支持压缩和编码。图 1 (c) 显示了一个示例 Parquet 数据集。有关其他信息,请参阅parquet 文档。
请注意以下事项:
- Parquet 数据加载器当前不支持嵌套列类型。
- 不允许列中有任何缺失值。
- 与 Norm 数据集格式一样,标签和密集特征列应使用浮点格式。
- Slot 特征列应使用 Int64 格式。
- Parquet 文件中的数据列可以按任何顺序排列。
- 要从每个 parquet 文件中的所有行和每个标签、密集(数字)和槽(分类)特征的列索引映射中获取所需信息,需要一个单独的
_metadata.json文件。
例子 _metadata.json:
{
"file_stats": [{"file_name": "file1.parquet", "num_rows": 6528076}, {"file_name": "file2.parquet", "num_rows": 6528076}],
"cats": [{"col_name": "C11", "index": 24}, {"col_name": "C24", "index": 37}, {"col_name": "C17", "index": 30}, {"col_name": "C7", "index": 20}, {"col_name": "C6", "index": 19}],
"conts": [{"col_name": "I5", "index": 5}, {"col_name": "I13", "index": 13}, {"col_name": "I2", "index": 2}, {"col_name": "I10", "index": 10}],
"labels": [{"col_name": "label", "index": 0}]
}
使用如下:
reader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.Parquet,
source = ["./criteo_data/train/_file_list.txt"],
eval_source = "./criteo_data/val/_file_list.txt",
check_type = hugectr.Check_t.Non,
slot_size_array = [278899, 355877, 203750, 18573, 14082, 7020, 18966, 4, 6382, 1246, 49, 185920, 71354, 67346, 11, 2166, 7340, 60, 4, 934, 15, 204208, 141572, 199066, 60940, 9115, 72, 34])
我们提供了通过一个选项slot_size_array,可以为每个插槽添加偏移量。slot_size_array是一个长度等于槽数的数组。为了避免添加offset后出现key重复,我们需要保证第i个slot的key范围在0到slot_size_array[i]之间。我们将以这种方式进行偏移:对于第 i 个槽键,我们将其添加偏移量 slot_size_array[0] + slot_size_array[1] + ... + slot_size_array[i - 1]。在上面提到的配置片段中,对于第 0 个插槽,将添加偏移量 0。对于第一个插槽,将添加偏移量 278899。对于第三个插槽,将添加偏移量 634776。
0x03 CSR 格式
嵌入层是基于CSR格式基础之上搭建的,所以我们首先看看CSR格式。
3.1 什么是CSR
稀疏矩阵指的是矩阵中的元素大部分是0的矩阵,实际上现实问题中大多数的大规模矩阵都是稀疏矩阵,因此就出现了很多专门针对稀疏矩阵的高效存储格式,Compressed Sparse Row(CSR)就是其中之一。
这是最简单的一种格式,每一个元素需要用一个三元组来表示,分别是(行号,列号,数值),对应上图右边的一列。这种方式简单,但是记录单信息多(行列),每个三元组自己可以定位,因此空间不是最优。
CSR需要三类数据来表达:数值,列号,行偏移。它不是用三元组来表示一个元素,而是一个整体编码方式。
- 数值:一个元素。
- 列号 :元素的列号,
- 行偏移:某一行的第一个元素在values里面的起始偏移位置。
上图中,第一行元素1是0偏移,第二行元素2是2偏移,第三行元素5是4偏移,第4行元素6是7偏移。最后会在行偏移之后加上矩阵总的元素个数,本例子中是9。

3.2 HugeCTR 之中的CSR
我们从中找出一个例子看看。因为只是用来存储slot里的sparse key,所以没有列号,因为一个slot里的sparse key可以直接顺序存储。
* For example data:
* 4,5,1,2
* 3,5,1
* 3,2
* Will be convert to the form of:
* row offset: 0,4,7,9
* value: 4,5,1,2,3,5,1,3,2
我们再从源码之中找一些信息 samples/ncf/preprocess-20m.py。
def write_hugeCTR_data(huge_ctr_data, filename='huge_ctr_data.dat'):
print("Writing %d samples"%huge_ctr_data.shape[0])
with open(filename, 'wb') as f:
#write header
f.write(ll(0)) # 0: no error check; 1: check_num
f.write(ll(huge_ctr_data.shape[0])) # the number of samples in this data file
f.write(ll(1)) # dimension of label
f.write(ll(1)) # dimension of dense feature
f.write(ll(2)) # long long slot_num
for _ in range(3): f.write(ll(0)) # reserved for future use
for i in tqdm.tqdm(range(huge_ctr_data.shape[0])):
f.write(c_float(huge_ctr_data[i,2])) # float label[label_dim];
f.write(c_float(0)) # dummy dense feature
f.write(c_int(1)) # slot 1 nnz: user ID
f.write(c_uint(huge_ctr_data[i,0]))
f.write(c_int(1)) # slot 2 nnz: item ID
f.write(c_uint(huge_ctr_data[i,1]))
3.3 操作类
3.3.1 定义
这里只给出成员变量,具体可以和上面csr格式进行印证。
class CSR {
private:
const size_t num_rows_; /**< num rows. */
const size_t max_value_size_; /**< number of element of value the CSR matrix will have for
num_rows rows. */
Tensor2<T> row_offset_tensor_;
Tensor2<T> value_tensor_; /**< a unified buffer for row offset and value. */
T* row_offset_ptr_; /**< just offset on the buffer, note that the length of it is
* slot*batchsize+1.
*/
T* value_ptr_; /**< pointer of value buffer. */
size_t size_of_row_offset_; /**< num of rows in this CSR buffer */
size_t size_of_value_; /**< num of values in this CSR buffer */
size_t check_point_row_; /**< check point of size_of_row_offset_. */
size_t check_point_value_; /**< check point of size_of_value__. */
}
3.3.2 构造函数
构造函数之中,会在GPU之上进行分配内存。
/**
* Ctor
* @param num_rows num of rows is expected
* @param max_value_size max size of value buffer.
*/
CSR(size_t num_rows, size_t max_value_size)
: num_rows_(num_rows),
max_value_size_(max_value_size),
size_of_row_offset_(0),
size_of_value_(0) {
std::shared_ptr<GeneralBuffer2<CudaHostAllocator>> buff =
GeneralBuffer2<CudaHostAllocator>::create();
buff->reserve({num_rows + 1}, &row_offset_tensor_);
buff->reserve({max_value_size}, &value_tensor_);
buff->allocate();
row_offset_ptr_ = row_offset_tensor_.get_ptr();
value_ptr_ = value_tensor_.get_ptr();
}
3.3.3 生成新行
new_row 之中会生成新行,并且把目前value总数设置到row_offset之中。
/**
* Insert a new row to CSR
* Whenever you want to add a new row, you need to call this.
* When you have pushed back all the values, you need to call this method
* again.
*/
inline void new_row() { // call before push_back values in this line
if (size_of_row_offset_ > num_rows_) CK_THROW_(Error_t::OutOfBound, "CSR out of bound");
row_offset_ptr_[size_of_row_offset_] = static_cast<T>(size_of_value_);
size_of_row_offset_++;
}
3.3.4 插入数据
这里会插入数据,并且增加value总数。
/**
* Push back a value to this object.
* @param value the value to be pushed back.
*/
inline void push_back(const T& value) {
if (size_of_value_ >= max_value_size_)
CK_THROW_(Error_t::OutOfBound, "CSR out of bound " + std::to_string(max_value_size_) +
"offset" + std::to_string(size_of_value_));
value_ptr_[size_of_value_] = value;
size_of_value_++;
}
0x04 基础数据结构
因为 HugeCTR 实际上是一个具体而微的深度学习系统,所以它也实现了众多基础功能,为了更好的进行分析,我们需要首先介绍一些基础数据结构。以下只给出各个类的成员变量和必要函数。
4.1 张量
首先就是最基础的张量概念。
4.1.1 TensorBuffer2
TensorBuffer2 是张量底层的数据,也许联系到 PyTorch 的 data 或者 storage 可以更好的理解。
class TensorBuffer2 {
public:
virtual ~TensorBuffer2() {}
virtual bool allocated() const = 0;
virtual void *get_ptr() = 0;
};
4.1.2 Tensor2
这就对应了TF或者PyTorch的张量。
template <typename T>
class Tensor2 {
std::vector<size_t> dimensions_;
size_t num_elements_;
std::shared_ptr<TensorBuffer2> buffer_;
}
成员函数我们选介绍两个如下:
static Tensor2 stretch_from(const TensorBag2 &bag) {
return Tensor2(bag.dimensions_, bag.buffer_);
}
TensorBag2 shrink() const {
return TensorBag2(dimensions_, buffer_, TensorScalarTypeFunc<T>::get_type());
}
具体如下:

4.1.3 Tensors2
Tensors2 就是 Tensor2 的一个vector。
template <typename T> using Tensors2 = std::vector<Tensor2<T>>;
4.1.4 TensorBag2
PyTorch 之中也有一些Bag后缀名字的类,比如 nn.Embedding和nn.EmbeddingBag。当构建袋子模型时,做一个Embedding跟随Sum或是Mean常见的。对于可变长度序列,nn.EmbeddingBag 来提供了更加高效和更快速的处理方式,特别是对于可变长度序列。
在 HugeCTR,TensorBag2 可以认为是把 Tensor 放在袋子里统一处理的类。
class TensorBag2 {
template <typename T>
friend class Tensor2;
std::vector<size_t> dimensions_;
std::shared_ptr<TensorBuffer2> buffer_;
TensorScalarType scalar_type_;
};
using TensorBags2 = std::vector<TensorBag2>;
关于 Tensor 和 Bag 的联系,可以参见下面的函数。
template <typename T>
Tensors2<T> bags_to_tensors(const std::vector<TensorBag2> &bags) {
Tensors2<T> tensors;
for (const auto &bag : bags) {
tensors.push_back(Tensor2<T>::stretch_from(bag));
}
return tensors;
}
template <typename T>
std::vector<TensorBag2> tensors_to_bags(const Tensors2<T> &tensors) {
std::vector<TensorBag2> bags;
for (const auto &tensor : tensors) {
bags.push_back(tensor.shrink());
}
return bags;
}
4.1.5 SparseTensor
SparseTensor 是 Sparse 类型的张量,这是3.2 版本加入的,目的是为了统一处理CSR格式,或者说是统一处理稀疏矩阵,可以有效存储和处理大多数元素为零的张量。后续在读取数据到GPU时候会有分析。我们对比一下 CSR 格式,就可以看出来其内部机制就对应了CSR 的 rowoffset 和 value。其具体定义如下:
template <typename T>
class SparseTensor {
std::vector<size_t> dimensions_;
std::shared_ptr<TensorBuffer2> value_buffer_;
std::shared_ptr<TensorBuffer2> rowoffset_buffer_;
std::shared_ptr<size_t> nnz_; // maybe size_t for FixedLengthSparseTensor
size_t rowoffset_count_;
};
示意图如下:

我们从中找出一个例子看看。因为只是用来存储slot里的sparse key,所以没有列号,因为一个slot里的sparse key可以直接顺序存储。
* For example data:
* 4,5,1,2
* 3,5,1
* 3,2
* Will be convert to the form of:
* row offset: 0,4,7,9
* value: 4,5,1,2,3,5,1,3,2
对应下图:

成员函数介绍如下:
static SparseTensor stretch_from(const SparseTensorBag &bag) {
return SparseTensor(bag.dimensions_, bag.value_buffer_, bag.rowoffset_buffer_, bag.nnz_,
bag.rowoffset_count_);
}
SparseTensorBag shrink() const {
return SparseTensorBag(dimensions_, value_buffer_, rowoffset_buffer_, nnz_, rowoffset_count_,
TensorScalarTypeFunc<T>::get_type());
}
PyTorch
PyTorch 有 sparse_coo_tensor 可以实现类似的功能。PyTorch 支持不同layout的张量,大家可以从 torch/csrc/utils/tensor_layouts.cpp 找到,比如 at::Layout::Strided,at::Layout::Sparse,at::Layout::SparseCsr,at::Layout::Mkldnn 等等,这些对应了不同的内存布局模式。
使用稀疏张量时候,提供一对 dense tensors:一个value张量,一个二维indice张量,也有其他辅助参数。
>>> i = [[1, 1]]
>>> v = [3, 4]
>>> s=torch.sparse_coo_tensor(i, v, (3,))
>>> s
tensor(indices=tensor([[1, 1]]),
values=tensor( [3, 4]),
size=(3,), nnz=2, layout=torch.sparse_coo)
TensorFlow
TensorFlow 也有 SparseTensor 类型来表示多维稀疏数据。一个 SparseTensor 使用三个稠密张量来表示:
- indices 表示稀疏张量的非零元素坐标。
- values 则对应每个非零元素的值。
- shape 表示本稀疏张量转换为稠密形式后的形状。
比如下面代码:
indices = tf.constant([[0, 0], [1, 1], [2,2]], dtype=tf.int64)
values = tf.constant([1, 2, 3], dtype=tf.float32)
shape = tf.constant([3, 3], dtype=tf.int64)
sparse = tf.SparseTensor(indices=indices,
values=values,
dense_shape=shape)
dense = tf.sparse_tensor_to_dense(sparse, default_value=0)
with tf.Session() as session:
sparse, dense = session.run([sparse, dense])
print('Sparse is :\n', sparse)
print('Dense is :\n', dense)
打印出来如下:
Sparse is :
SparseTensorValue(indices=array([[0, 0],
[1, 1],
[2, 2]]), values=array([1., 2., 3.], dtype=float32), dense_shape=array([3, 3]))
Dense is :
[[1. 0. 0.]
[0. 2. 0.]
[0. 0. 3.]]
4.1.6 SparseTensorBag
这个类似 TensorBag 的功能,具体如下:
class SparseTensorBag {
template <typename T>
friend class SparseTensor;
std::vector<size_t> dimensions_;
std::shared_ptr<TensorBuffer2> value_buffer_;
std::shared_ptr<TensorBuffer2> rowoffset_buffer_;
std::shared_ptr<size_t> nnz_;
size_t rowoffset_count_;
TensorScalarType scalar_type_;
SparseTensorBag(const std::vector<size_t> &dimensions,
const std::shared_ptr<TensorBuffer2> &value_buffer,
const std::shared_ptr<TensorBuffer2> &rowoffset_buffer,
const std::shared_ptr<size_t> &nnz, const size_t rowoffset_count,
TensorScalarType scalar_type)
: dimensions_(dimensions),
value_buffer_(value_buffer),
rowoffset_buffer_(rowoffset_buffer),
nnz_(nnz),
rowoffset_count_(rowoffset_count),
scalar_type_(scalar_type) {}
public:
SparseTensorBag() : scalar_type_(TensorScalarType::None) {}
const std::vector<size_t> &get_dimensions() const { return dimensions_; }
};
4.1.7 向量类
以下是两个向量类,用来方便用户使用。
using TensorBags2 = std::vector<TensorBag2>;
template <typename T>
using SparseTensors = std::vector<SparseTensor<T>>;
4.2 内存
我们接下来看看一些内存相关类。
4.2.1 Allocator
首先看看如何为tensor等变量分配内存。
4.2.1.1 HostAllocator
HostAllocator 作用是在host之上管理内存。
class HostAllocator {
public:
void *allocate(size_t size) const { return malloc(size); }
void deallocate(void *ptr) const { free(ptr); }
};
后面几个实现都是调用了CUDA函数来进行内存分配,比如 cudaHostAlloc,有兴趣读者可以深入学习。
4.2.1.2 CudaHostAllocator
调用CUDA方法在主机上分配内存
class CudaHostAllocator {
public:
void *allocate(size_t size) const {
void *ptr;
CK_CUDA_THROW_(cudaHostAlloc(&ptr, size, cudaHostAllocDefault));
return ptr;
}
void deallocate(void *ptr) const { CK_CUDA_THROW_(cudaFreeHost(ptr)); }
};
4.2.1.3 CudaManagedAllocator
cudaMallocManaged 分配旨在供主机或设备代码使用的内存,算是一种统一分配内存的方法。
class CudaManagedAllocator {
public:
void *allocate(size_t size) const {
void *ptr;
CK_CUDA_THROW_(cudaMallocManaged(&ptr, size));
return ptr;
}
void deallocate(void *ptr) const { CK_CUDA_THROW_(cudaFree(ptr)); }
};
4.2.1.4 CudaAllocator
该类是在设备上分配内存。
class CudaAllocator {
public:
void *allocate(size_t size) const {
void *ptr;
CK_CUDA_THROW_(cudaMalloc(&ptr, size));
return ptr;
}
void deallocate(void *ptr) const { CK_CUDA_THROW_(cudaFree(ptr)); }
};
4.2.2 GeneralBuffer2
分析完如何分配内存,我们接下来看看如何封装内存,具体通过 GeneralBuffer2 完成的。GeneralBuffer2 可以认为是一个对大段内存的统一封装,具体在其上可以有若干Tensor。
4.2.2.1 定义
这里都忽略了成员函数,内部类也忽略了成员函数。
- allocator :具体内存分配器,也区分在GPU分配还是CPU分配。
- ptr_ :指向分配的内存;
- total_size_in_bytes_ :内存大小;
- reserved_buffers_ :前期预留buffer,后续会统一分配;
具体内部类为:
- BufferInternal 是接口。
- TensorBufferImpl 是 Tensor2 对应的buffer实现。
- BufferBlockImpl 则是在构建网络时候会用到。
具体代码如下:
template <typename Allocator>
class GeneralBuffer2 : public std::enable_shared_from_this<GeneralBuffer2<Allocator>> {
class BufferInternal {
public:
virtual ~BufferInternal() {}
virtual size_t get_size_in_bytes() const = 0;
virtual void initialize(const std::shared_ptr<GeneralBuffer2> &buffer, size_t offset) = 0;
};
class TensorBufferImpl : public TensorBuffer2, public BufferInternal {
size_t size_in_bytes_;
std::shared_ptr<GeneralBuffer2> buffer_;
size_t offset_;
};
template <typename T>
class BufferBlockImpl : public BufferBlock2<T>, public BufferInternal {
size_t total_num_elements_;
std::shared_ptr<TensorBufferImpl> buffer_impl_;
Tensor2<T> tensor_;
bool finalized_;
std::vector<std::shared_ptr<BufferInternal>> reserved_buffers_;
};
Allocator allocator_;
void *ptr_;
size_t total_size_in_bytes_;
std::vector<std::shared_ptr<BufferInternal>> reserved_buffers_;
}
4.2.2.2 TensorBufferImpl
就是指向了一个 GeneralBuffer2,然后设定了自己的offset和大小。
void initialize(const std::shared_ptr<GeneralBuffer2> &buffer, size_t offset) {
buffer_ = buffer;
offset_ = offset;
}
4.2.2.2 BufferBlockImpl 关键函数
BufferBlockImpl 和 TensorBufferImpl 可以来比较一下。
其中,BufferBlock2 是 BufferBlockImpl 的接口类。
template <typename T>
class BufferBlock2 {
public:
virtual ~BufferBlock2() {}
virtual void reserve(const std::vector<size_t> &dimensions, Tensor2<T> *tensor) = 0;
virtual Tensor2<T> &as_tensor() = 0;
};
BufferBlockImpl 是一组连续的 Tensor,某些特定的实现需要连续的内存,比如权重。
std::shared_ptr<BufferBlock2<float>> train_weight_buff = blobs_buff->create_block<float>();
// 省略其他代码......
network->train_weight_tensor_ = train_weight_buff->as_tensor();
BufferBlockImpl 多了一个reserve方法,用来预留内存空间,在此空间之上生成内部tensor。
void reserve(const std::vector<size_t> &dimensions, Tensor2<T> *tensor) override {
if (finalized_) {
throw std::runtime_error(ErrorBase + "Buffer block is finalized.");
}
size_t num_elements = get_num_elements_from_dimensions(dimensions);
size_t size_in_bytes = num_elements * TensorScalarSizeFunc<T>::get_element_size();
std::shared_ptr<TensorBufferImpl> buffer_impl =
std::make_shared<TensorBufferImpl>(size_in_bytes);
reserved_buffers_.push_back(buffer_impl);
*tensor = Tensor2<T>(dimensions, buffer_impl);
total_num_elements_ += num_elements;
}
initialize 会对内部进行配置
void initialize(const std::shared_ptr<GeneralBuffer2> &buffer, size_t offset) {
size_t local_offset = 0;
for (const std::shared_ptr<BufferInternal> &buffer_impl : reserved_buffers_) {
buffer_impl->initialize(buffer, offset + local_offset);
local_offset += buffer_impl->get_size_in_bytes();
}
reserved_buffers_.clear();
if (!finalized_) {
buffer_impl_ = std::make_shared<TensorBufferImpl>(
total_num_elements_ * TensorScalarSizeFunc<T>::get_element_size());
tensor_ = Tensor2<T>({total_num_elements_}, buffer_impl_);
finalized_ = true;
}
buffer_impl_->initialize(buffer, offset);
}
4.2.2.3 GeneralBuffer2 关键函数
reserve 方法会把某一个张量对应的内存需求用 TensorBufferImpl 的形式记录在reserved_buffers_之中,然后生成这个张量,而且就是用TensorBufferImpl 生成。
template <typename T>
void reserve(const std::vector<size_t> &dimensions, Tensor2<T> *tensor) {
if (allocated()) {
throw std::runtime_error(ErrorBase + "General buffer is finalized.");
}
size_t size_in_bytes =
get_num_elements_from_dimensions(dimensions) * TensorScalarSizeFunc<T>::get_element_size();
std::shared_ptr<TensorBufferImpl> buffer_impl =
std::make_shared<TensorBufferImpl>(size_in_bytes);
reserved_buffers_.push_back(buffer_impl);
*tensor = Tensor2<T>(dimensions, buffer_impl);
}
create_block 会针对BufferBlock2进行创建。
template <typename T>
std::shared_ptr<BufferBlock2<T>> create_block() {
if (allocated()) {
throw std::runtime_error(ErrorBase + "General buffer is finalized.");
}
std::shared_ptr<BufferBlockImpl<T>> block_impl = std::make_shared<BufferBlockImpl<T>>();
reserved_buffers_.push_back(block_impl);
return block_impl;
}
allocate 会遍历注册的 BufferInternal,累积其总大小,最后调用 allocator_ 进行分配内存。
void allocate() {
if (ptr_ != nullptr) {
throw std::runtime_error(ErrorBase + "Memory has already been allocated.");
}
size_t offset = 0;
for (const std::shared_ptr<BufferInternal> &buffer : reserved_buffers_) {
// 对 BufferInternal(比如TensorBufferImpl)内部进行配置
buffer->initialize(this->shared_from_this(), offset);
size_t size_in_bytes = buffer->get_size_in_bytes();
if (size_in_bytes % 32 != 0) {
size_in_bytes += (32 - size_in_bytes % 32);
}
offset += size_in_bytes;
}
reserved_buffers_.clear();
total_size_in_bytes_ = offset;
if (total_size_in_bytes_ != 0) {
ptr_ = allocator_.allocate(total_size_in_bytes_);
}
}
4.2.4 小结
至此,Tensor的逻辑拓展一下:
- TensorBufferImpl 的 buffer 是GeneralBuffer2;
- GeneralBuffer2 的 ptr 是由CudaAllocator在GPU之中分配的;GeneralBuffer2 可以认为是一个对大段内存的统一封装,在其上可以有若干Tensor。这些Tensor先reserve内存,然后统一分配。
- TensorBufferImpl 的 offset_ 就指向了 GeneralBuffer2 的 ptr 之中具体的某一个内存偏移;
- BufferBlockImpl 用来实现一个连续的Tensor内存。

如果还有另外一个 Tensor2,则其 TensorBufferImpl.offset 会指向 GPU内存的另外一个offset,比如下面有两个张量,Tensor 1 和 Tensor 2。

0xFF 参考
https://web.eecs.umich.edu/~justincj/teaching/eecs442/notes/linear-backprop.html