计算机起初是设计用来做数学计算的,Computer 一词英文原意是“计算员”——在计算机发明之前,计算员是一个独立的职业,专门做各种数学用表的计算,如测量和天文领域的三角函数表、对数表,航海领域的航海天文历等。
计算机发明后不久,人们发现,这玩意除了能当计算员,还能当文员,用来处理人类社会的非数字信息。然而,计算机在设计上是只认识数字的(具体说是只认识二进制数字),要想让它能够识别并处理人类符号,就必须采取某种翻译手段,在计算机的二进制数字和人类的符号之间做双向转换。
这种字符-数字的映射(转换)关系本质上就是一张查找表,在理论上是很简单的。我们先给人类的每个字符分配一个独一无二的编号(character code,字符编码),如图:
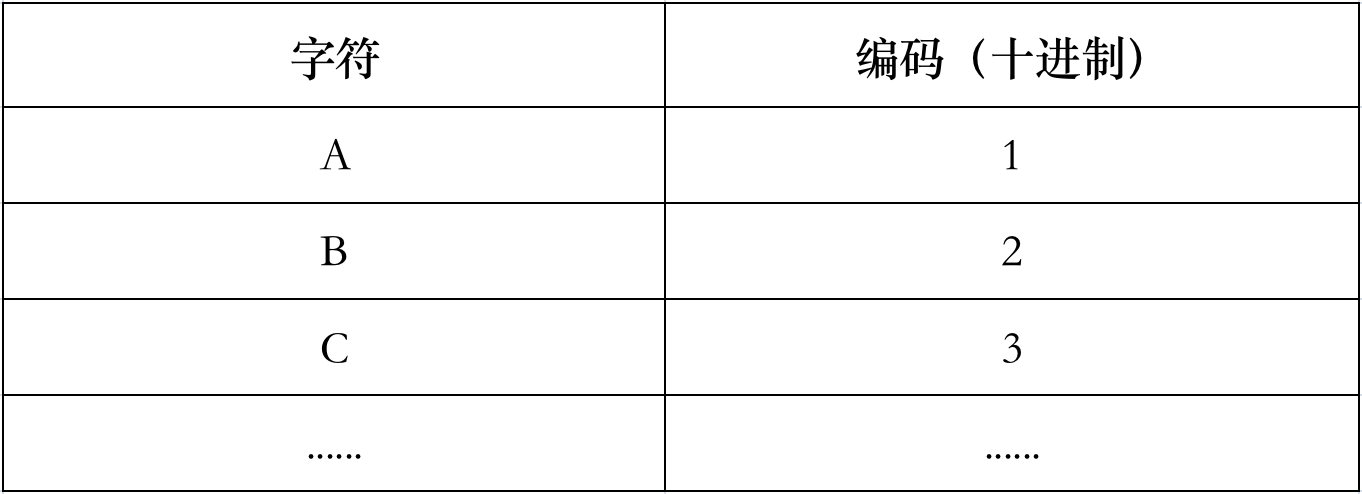
然后通过外设(键盘)将字符输入到计算机中,比如我们键盘上针对A、B、C分别都有按键。当我们按下“A”后,计算机通过查找表得知该字符的编码是十进制 1,便使用二进制 00000001 在内部表示和存储起来。
光存储还不行,我们还要将计算机中的字符(编号)显示或打印出来,所以还涉及到字库。在显示器上显示某个字符,本质上是在一个n*n 的像素点阵中,让某些位置的像素设置为黑色(用 1 表示),其它位置为白色(用 0 表示),比如中文“你”的点阵图(注意不同字库的点阵图不同):

这样一个 16*16 的像素矩阵,需要 16 * 16 / 8 = 32 字节的空间来表示,右边的“字模信息”称为字形编码。不同的字库(如宋体、黑体)对同一个字符的字形编码是不同的。
这里每个像素只需要黑、白两种颜色,只需要一个位就行了,如果是彩色,则理论上需要 3 字节(RGB)来表示(当然这里没考虑压缩算法)。
所以这里涉及到另一张查找表:字符编码-字形编码的映射关系:
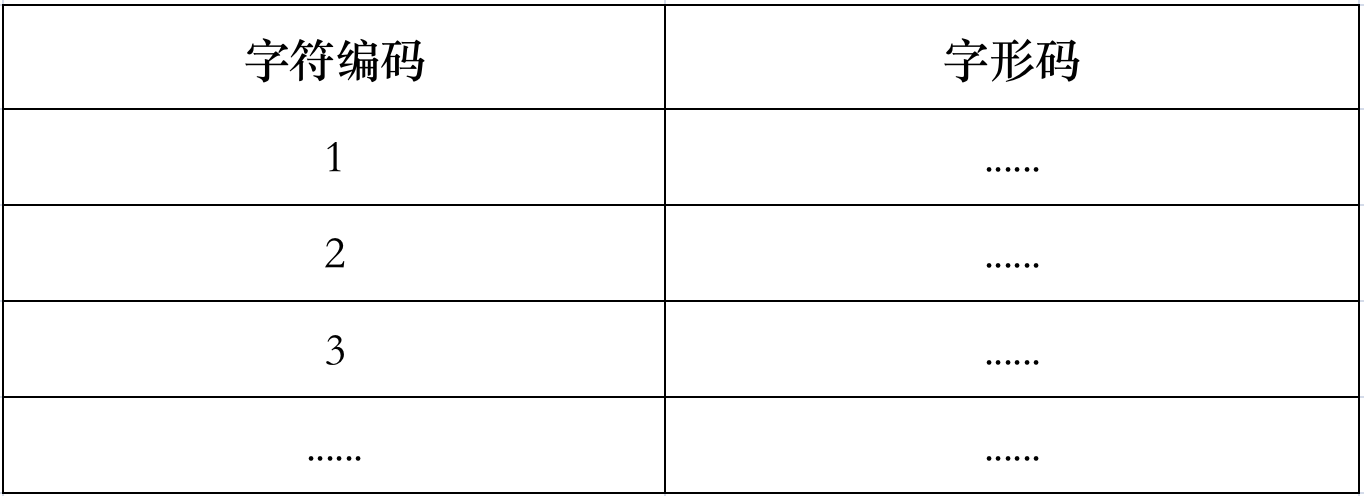
计算机根据用户指定的字库从中查出字符编码对应的字形编码值,输送给相应的图形处理程序进而显示出来相应的字符。
整个输入-转码存储-输出(显示/打印)的流程简单表示如下:

对于英文字符,直接在键盘上敲就行了,对于其他字符比如中文,则不是那么直观,因为键盘无论如何也放不下那么多汉字,所以又要用到另一层转换。我们称计算机内部那个字符编码称为内码,而外部用户输入用到的叫做外码,比如中文输入法用到的外码有拼音、五笔码、仓颉码等,对于这种情况,还需要做一次外码到内码的映射。
文字处理系统需要考虑的事情非常多,绝非简单进行编码映射就行。比如英文单词的换行、英文单词的大小写、中文的横排竖排、阿拉伯语的连字处理等,文字处理系统需要能够正确处理特定语言上下文。
我们接下来重点讲上图中“字符编码”这块。
源于美国
用今天的眼光看,这世界存在各种各样的字符编码标准,什么ASCII、 ISO-8859-1、GBK、Big5、Unicode 等——你有没有想过,单单一个字符编码,为啥会有这么多标准?这不是成心让程序员头大吗?
现实中的标准从来都不是由某权威机构事先制定的,而是一些公司因自身需求(市场拓展需要)而发明出来一套游戏规则。每家公司都根据自身情况发明自己的游戏规则,各家之间规则彼此不同,自己玩没事,跑到一起玩(互操作)就哑巴了。于是要么标准制定机构(如国家标准委员会、ISO 等)站出来,要么几家龙头企业凑到一起成立个某某联盟,总之大家都有一个目标:统一游戏规则。
套用鲁迅先生一句话就是:这世间本没有标准,玩得人多了,便成了标准。
只有从这个角度看问题,才能理解为啥会存在那么多字符集编码标准,为啥要有 Unicode,而 Unicode 的一些实现为啥怪怪的。
1964 年,IBM 推出其划时代的大型机 System/360(怎么个划时代请自行百度),为该大型机设计的字符集编码标准叫 EBCDIC(Extended Binary Coded Decimal Interchange Code,扩展二进制编码的十进制交换码),这是一个单字节编码方案,囊括了一些控制字符、数字、常用标点、大小写英文字母:
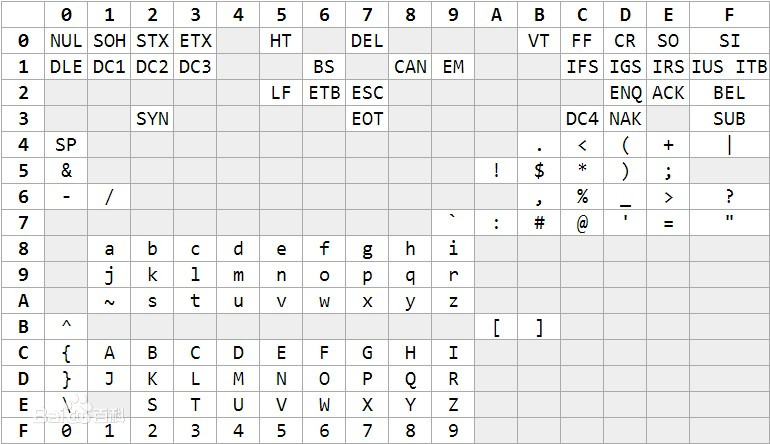
EBCDIC 编码。图片来自百度百科
图中行号表示字节高 4 位,列号表示字节低 4 位,行、列分别是十六进制 0~F,如 0x81 表示 a,0xC1 表示 A。注意表中英文单词不是连续的,这给程序处理带来些许麻烦。
4 年后,美国国家标准学会 ANSI(American National Standard Institute) 于 1968 年发布了著名的 ASCII(American Standard Code for Information Interchange美国信息交换标准码) 编码标准。ASCII 和 EBCDIC 一样是单字节编码,不过它吸取了 EBCDIC 的经验教训,给英文单词分配了连续的编码,方便程序处理。
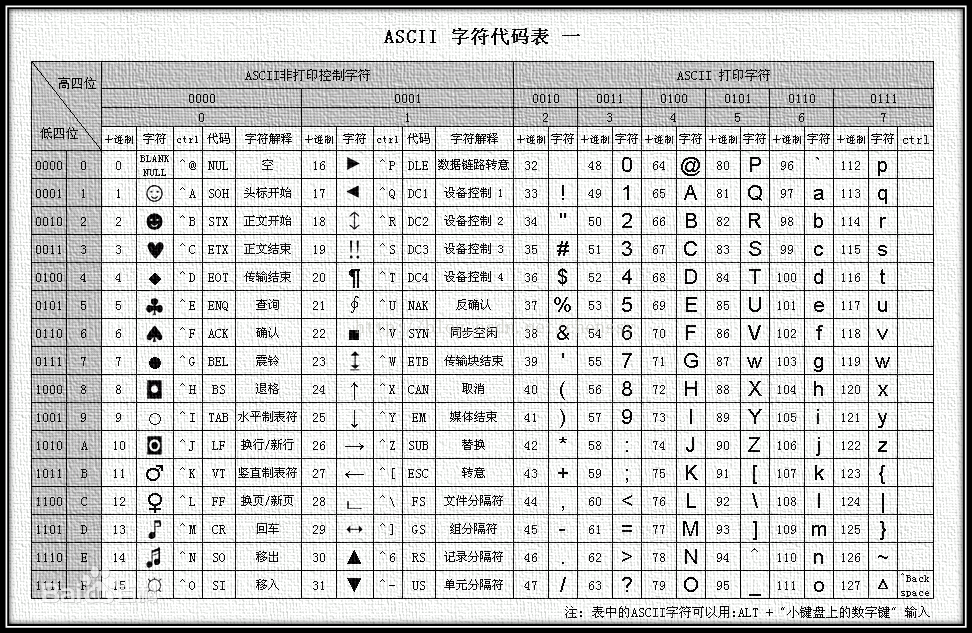
ASCII 编码(注意该表是列表示字节高 4 位)。图片来自百度百科
其中前 32 个(031)是不可见的控制字符,32126 是可见字符,127 是 DELETE 命令(键盘上的 DEL 键)。
ASCII 和 EBCDIC 编码相比,除了拉丁字母是连续排列的以外,ASCII 只用了一个字节的低 7 位,最高位永远是 0。所以 ASCII 最多能表示 2^7 = 128 个字符,这对于当时美国来说已经足够了。
别小看这个最高位的 0,这可以说是 ASCII 设计得最成功的一个地方,后面我们讨论其它编码规范的时候你会发现,正是有了这个最高位的 0 作为 ASCII 的标识,其它编码规范才能对 ASCII 码无缝兼容,这进而使得 ASCII 被广泛接受,并于 1972 年被 ISO/IEC 采用作为国际标准(ISO/IEC 646),直至今日仍然是世界上最基础、最重要、使用最广泛的字符编码标准之一。
EBCDIC 虽然用完了全部 8 个比特,理论上可以对 2^8 = 256 个字符进行编码,但实际上其中有很多编号并没有对应的字符,如图中所示,其中有几块不连续的“空洞地带”,其编码远没有 ASCII 紧凑。由于 EBCDIC 的一些弊端,在 ANSI 推出 ASCII 编码标准后,IBM 在其后来的个人计算机(PC)和工作站操作系统中不再使用自家的 EBCDIC,而是使用 ASCII。
个人计算机
1971 年,英特尔发布了世界上第一款微处理器 4004。这是一块 4 位微处理器(现在都是 64 位了),10 微米的工艺(现在是 10 纳米以下工艺),尺寸为 3*4mm,工作频率为 108KHz,每秒运算 6 万次。

第一枚微处理器 Intel 4004
用今天的标准看,这玩意算力不高,但它的突破性在于尺寸,只有几毫米见方,用当时的眼光看,可以用“微”来形容。
CPU 尺寸的大大缩小使得计算机体积大大降低,让计算机能够放在个人办公桌上,而不是只能呆在专门的机房里(想想第一台电子计算机 ENIAC 占地 170 平米,你我的房子都装不下)。另一个(但同样重要的)结果是使得计算机的生产成本大大降低——这两点让普通公司和个人拥有计算机成为可能。
因而在微处理器出世后的七八十年代,是个人计算机的井喷年代。
1975 年爱德华·罗伯茨的 MITS 公司制造了世界上第一台微型计算机 Altiar 8800,售价仅为 397 美元(IBM 大型机 System/360 售价在 300 万美元左右)。

第一台微型计算机 Altiar 8800
注意:关于谁是第一台个人计算机、第一台微型计算机的说法是有争议的(甚至包括微处理器也是如此),很多公司都说自己是第一,所以如果在其他地方看到不同的答案不要大惊小怪。
另外,虽然今天我们觉得个人拥有计算机是再正常不过的事情(没有才不正常),但 20 世纪 70 年代早期人们可不这样想,很多公司的第一反应是:个人要计算机干嘛?很多公司由于认知上的局限而错失 PC 浪潮(比如施乐)。
1975年,比尔·盖茨和保罗·艾伦创办微软。
1976年,史蒂夫·乔布斯和史蒂夫·沃兹尼亚克创办苹果。
1981 年,IBM PC 问世。IBM PC 对整个行业产生了深远影响。各大公司纷纷批量购入,从此个人电脑在办公中发挥了越来越重要的作用。IBM PC 使用了微软开发的 MS-DOS 操作系统,微软随之崛起。

1981 年发布的 IBM PC
——等等,我们不是要聊字符编码吗,怎么聊起个人计算机了?
如果没有个人计算机的普及,世界上压根不会出现那么多字符集编码,甚至不需要 Unicode。
像 System/360 那样的大型机,一台几百万美元(折合现在要2000多万美元),只有像航天局、银行、航空公司等才需要用到,小公司和个人消费者怎么也不会买——这种情况下,即便需要多语言编码标准,也不会涌现那么多的字符集,甚至很可能不会出现像 Unicode 这样的统一编码标准。
正是个人计算机的普及使得计算机在全世界范围内变成了日常办公用品,而软硬件制造商在国际化过程中便必然面临一个问题:原先的 ASCII 编码标准无法表示其他国家的语言符号。
欧洲
制造商们在进入欧洲市场的时候就遇到了麻烦。
欧洲的主流语言虽然也是用拉丁字母,但却存在很多扩展体,比如法语的 é,挪威语中的 Å,都无法用 ASCII 表示。
于是这些公司的技术人员就发挥自己的聪明才干。大家发现,ASCII 编码字节中,最高位是没有用到的(总是 0),既然这样,为何不把这一位用起来呢,这样能表达的字符数又多了 128 个,对于欧洲主流语言足够了。
于是,各公司开始在 ASCII 的基础上扩展出自己的字符集:当最高位是 0 的时候仍然表示原先的 ASCII 字符不变,当最高位是 1 时表示扩展字符——这样既完美兼容了原先的 ASCII,又能表达欧洲国家特定字符。比如 IBM 的 codepage 437 用来编码欧洲主要语言字符(主要是西欧字符),codepage 852 编码东欧国家的拉丁字母,codepage 855 编码西里尔字符(如俄语)。微软为 Windows 制定了 codepage 1252 用于编码西欧字符。苹果、施乐等也都在制定自己的 codepage 标准。
这里存在两个问题,一是各个公司各自制定自己的扩展编码,相互之间互不兼容;二是即便加上 128 个字符仍然无法表达所有的欧洲字符。
为了解决这两个问题,国际标准化组织 ISO 和 IEC 联合制定了一组标准叫 ISO/IEC 8859(简称 ISO 8859)。注意 ISO 8859 并不是一套具体的字符集编码标准,而是一组字符集的合称,称为 ISO/IEC 8859-n,n=1,2,3,...,15,16(其中12未定义,所以共15个)。
这些字符集编码标准都是单字节编码,前128 个字符编码(最高位为 0)和 ASCII 一样,后 128 个字符各自分配给不同的语系。ISO 8859 的各编码都兼容 ASCII,但彼此互不兼容(即 0~127 范围的大家都表示相同的字符,128~255 的各自表示各自体系里面的字符)。
其中使用最广泛的是 ISO/IEC 8859-1,又称 latin 1,收录了西欧常用字符,包括德语、意大利语、葡萄牙语、西班牙语等(由于 latin 1 中没有法语的 œ、Œ、Ÿ,所以法语用的 ISO 8859-15 字符集)。
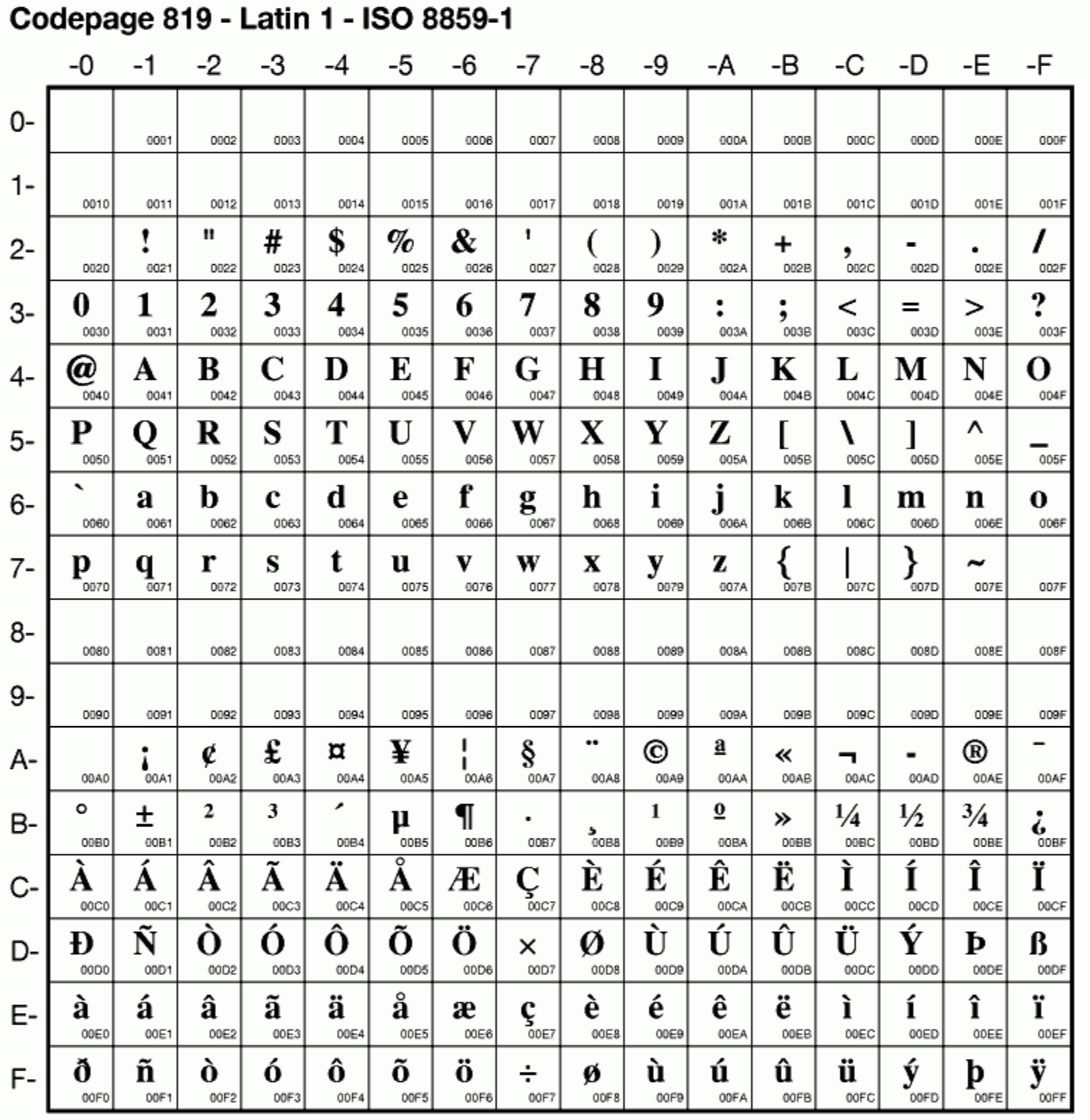
ISO/IEC 8859-1 字符集,注意 007F 之前和 ASCII 是一致的
上文说的字符 Å 在此处用 00C5 表示。
其余从 ISO 8859-2 到 ISO 8859-16 收录字符如下(部分):
ISO/IEC 8859-1 (Latin-1) - 西欧语言
ISO/IEC 8859-2 (Latin-2) - 中欧语言
ISO/IEC 8859-3 (Latin-3) - 南欧语言。
ISO/IEC 8859-4 (Latin-4) - 北欧语言
ISO/IEC 8859-5 (Cyrillic) - 斯拉夫语言
ISO/IEC 8859-6 (Arabic) - 阿拉伯语
ISO/IEC 8859-7 (Greek) - 希腊语
......
东亚
当这些厂商进入东亚市场时,更头大。
在欧洲,好歹能用 ASCII 高位保留的那个字节搞出个 ISO 8859 系列标准来,然而当他们面对几万个汉字时,一脸懵逼。
对于中日韩这种表意文字,单字节编码根本行不通,要用两个字节。日语方面制定了 Shift JIS 标准;繁体中文则由台湾相关行业协会于 1984 年制定了 Big5 标准;简体中文由中国国家标准总局于 1980 年制定了 GB 2312。
GB 码
作为中国大陆公民,这里稍微深入聊下 GB 系列编码标准。
GB 2312:
最初的标准是《信息交换用汉字编码字符集》,由中国国家标准总局于 1980年发布、1981 年 5 月 1 日开始实施的一套国家标准,标准号为 GB 2312-1980,共收录 6763 个汉字,另外还收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的 682 个字符。
GB 2312 是双字节编码。为了兼容 ASCII 码,GB 2312 规定,汉字必须由两个值大于 127(最高位是 1)的字节来表示;反过来说,如果一个字节的值小于等于 127(最高位是 0),则其和 ASCII 码表示的字符相同(也就是此时就是 ASCII 码)。
也就是说,在 GB 2312 里面,英文字母(以及 ASCII 中的标点)占 1 个字节,汉字占 2 个字节。
我们用 python 程序验证下:
>>> bytes("A", "GB 2312")
b'A'
>>> bytes("啊", "GB 2312")
b'\xb0\xa1'
上面字母“A”占 1 个字节,字符“啊”占了两个字节(字节值为 B0 A1,两个字节的最高位都是 1,其中 B0 叫高位字节,A1 叫低位字节)。
也就是说,GB 2312 属于变长编码,用 1~2 个字节表示字符,而字节最高位的值决定了字符占用的字节数。
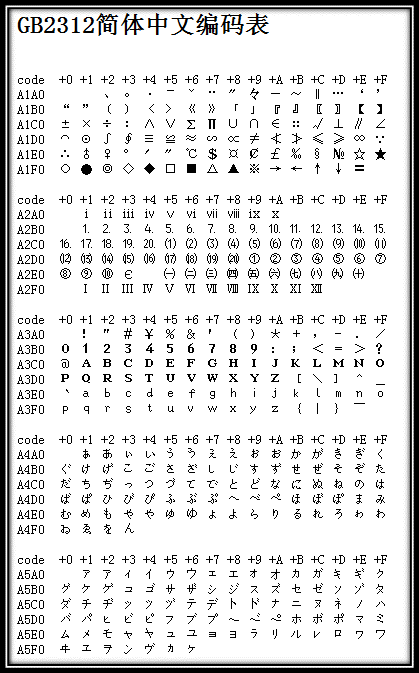
GB 2312 编码表(部分)
注意看在 GB 2312 中,“(1)”、“(一)” 这种组合字符都分配了单独的编码(即将它们视为一个字符而不是多字符组合), 这影响了后面 Unicode 的字符集设计。
区位码:
GB 2312 采用区位码的方式编码。这种编码方式将一个矩形区域划分成 94 行 × 94 列,形成 94 × 94 共 8836 个格子,然后将字符填入这些格子中。
行和列分别从 1 开始往后编号,行叫做区,列叫做位,这样形成 1~94 个区,每个区有 94 个位,其中的字符用区号+位号来表示。
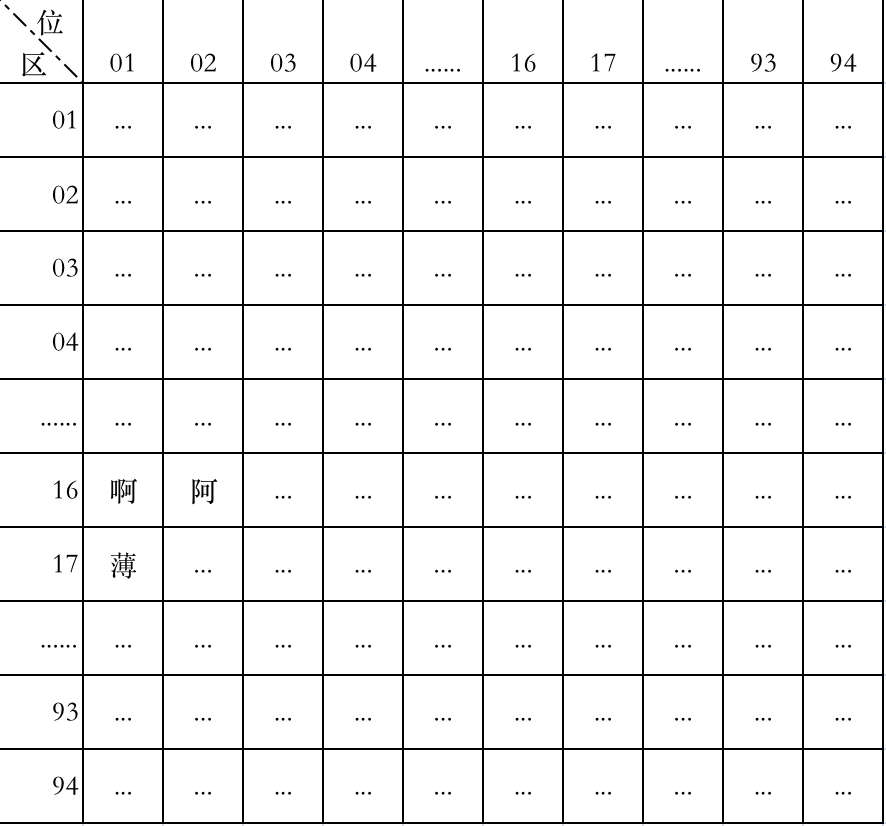
区位矩阵示意图。注意图中区位编号是用十进制表示的
其中:
-
01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的682个全角字符;
-
10~15区:空区,留待扩展;
-
16~55区(3755个):常用汉字(也称一级汉字),按拼音排序;
-
56~87区(3008个):非常用汉字(也称二级汉字),按部首/笔画排序;
-
88~94区:空区,留待扩展。
例如“啊”字的区号是 16,位号是 01,区位号用十六进制表示就是 10 01。前面不是说汉字用两个字节吗,那么我们就将 10 放入第一个字节中(高位字节),01 放入第二个字节中(低位字节)——不对啊!这两个值都小于 128 啊,按照前面的说法,表示汉字的两个字节的最高位必须是 1,转成数值也即是必须大于 127 才对。另外我们前面用 python 代码打出来“啊”字的字节值明明是 B0 A1 啊。
所以说这个区位码仅仅是给人类看的,逻辑上的编号,它不等于计算机里面的实际存储表示。
区位码在用计算机字节表示的时候,肯定要做某种转换——至少要让它大于 127。区位码本身都是小于 128 的(最大才 94),所以它们的字节原码的最高位都是 0,我们简单地将最高位都变成 1 就行了——也就是在原来的值上加上 2^7 = 128 即可。
不过这样得出来的值还不是最终的字节编码值,计算机中最终的字节编码值还要在此基础上加上 32(至于为啥要加 32,大体原因是 GB 2312 想对 ASCII 中的可见字符重新进行了双字节的全角编码,但这其中要排除掉那些不可打印的控制字符以及空格,所以要将原始区位码后移 32 位。对详细信息感兴趣的请自行百度)。也就是说,区位码要加上 128 + 32 = 160(十六进制 A0)才是机器字节码——为了和原始区位码做区分,这个字节码有个新名字叫内码。
我们算下汉字“啊”的内码。高位字节:16 + 160 = 176,转成十六进制是 B0;低位字节:01 + 160 = 161,转成十六进制是 A1,即“啊”字的内码是 B0 A1,和前面 python 程序输出的相吻合。
我们平时说某汉字的 GB 2312 编码值一般就是指内码。

三种码值对照表。原始区位码加 32 后的值也有个新名字叫“国标码”
GBK:
1980 年的 GB 2312 只收录了 6763 个汉字,虽然能满足 99% 以上的使用场景,但对于一些生僻字(如一些人名、古文字)就没办法处理了。另外一个问题是,GB 2312 不支持繁体字。
所以 1995 年又制定了《汉字内码扩展规范》(GBK,Guo Biao Kuozhan 的首字母,是对 GB 2312-1980 的扩展)。GBK 完全兼容 GB 2312,同时收录了 Big5 中的全部繁体字,以及 GB 2312 中没有的其他汉字,共计 21003 个汉字。
GBK 也是双字节编码。问题来了,GB 2312 中要求两个字节的最高位必须是 1,那最多也只能表示 2^14 = 16384 个字符——不够用啊。所以 GBK 只要求汉字的第一个字节(高位字节)的最高位必须是 1,第二位(低位字节)最高位可以是 0。
GB 18030:
随着字符集编码国际标准 ISO/IEC 10646 和 Unicode 的不断发展,越来越多的字符被纳入其中,而 GBK 一共才 2万多个字符(主要是汉字),有点赶不上时代了。
中国在 GBK 制定后的第五年(2000 年)又制定了新标准 GB 18030-2000,用来替代 GBK 标准。GB 18030-2000 是强制性标准(GBK 只是指导性的),也就是说在中国大陆销售的软件必须支持 GB 18030-2000 标准。
GB 18030 的目标是向 Unicode/UCS 对齐(而 GBK 只是 GB 2312 到 Unicode 对齐进程的一个过渡性标准),2000 版的 GB 18030 在GBK 基础上增加了 CJK 统一汉字扩充 A 的汉字(CJK 是中日韩的缩写),GB 18030-2005 在 GB 18030-2000 基础上增加了 CJK 统一汉字扩充 B 的汉字,收入汉字 70000 余个。另外 GB 18030-2005 还包含多种我国少数民族文字(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)。
诚然,2 个字节已经不够用了。GB 18030包含三种长度的编码:单字节的 ASCII、双字节的 GBK(略带扩展)、以及用于填补所有Unicode 码位的四字节 UTF 区块。GB 18030 是完全兼容 GBK 的,同时其码点足以囊括所有的 Unicode 编码空间。
注意 GB 18030-2005 是部分强制性的——其中囊括的 GB 18030-2000 部分是强制性的,在中国大陆销售的相关软件必须要支持该部分。
代码页
我们知道,早期那些软硬件制造商(IBM、微软、苹果等)在进入不同区域市场时,会单独制定一套针对特定区域语言文字的字符集编码标准,因而这些厂商内部都会持有很多套标准,这些字符集编码标准在他们内部通过不同的编号来标识,并且起了个名字叫代码页(Codepage,又称内码表)。
每个厂商有自己的一套代码页,这些代码页仅供他们自己内部使用,虽然基本都兼容 ASCII,但不同的代码页之间(包括同一厂商内部以及厂商之间的)互不兼容。比如 IBM 针对欧洲市场的 codepage 437(西欧拉丁字母)、852(东欧拉丁字母)、855(西里尔字母) 等;微软的 codepage 1251(西里尔字母)、 1252(西欧拉丁字母)、1253(希腊字母)等。
后来,一些标准化组织(如 ISO、ANSI、中国国家标准局)和联盟(如 Unicode 联盟)参与制定了若干标准后,厂商们也将这些标准纳入到自己的代码页体系中。比如 GB 2312 在微软代码页编号是 936,Big5 是 950,UTF-8 是 65001,UTF-32 LE 是 12000,UTF-32 BE 是 12001。
我们发现,UTF-8、UTF-32 都是对 Unicode 字符集编码标准的不同实现方式,在代码页体系中分配了不同的编号(即UTF-8、UTF-32 LE、UTF-32 BE 属于不同的代码页)。也就是说,代码页里面的编码是计算机的实际字节码,也就是字符在计算机中是怎么用字节表示的,这种编码我们称作“内码”——这就是代码页又称为“内码表”的原因。
字符编码有不同层次的表示,大体分为逻辑上(给人看的)和存储上(给计算机看的)。比如我们前面提到的 GB 2312 的区位码就属于逻辑层面的编码,而内码则是存储层面,如“啊”的区位码是(十六进制)10 01, 内码是 B0 A1。“啊”字在微软 codepage 936 的编码就是 B0 A1。“啊”字的 Unicode 编码是 U+554A,该(逻辑层面的)编码用 UTF-8 和 UTF-32 表示出来是不一样的,其 UTF-8 编码是 E5 95 8A,UTF-32 BE 编码是 00 00 55 4A,UTF-32 LE 编码是 4A 55 00 00(BE 表示大端表示法,LE 是小端表示法)。
另外代码页和一些标准之间不一定是完全等同的,往往是因某些标准满足不了厂商的特定需求,厂商会在标准的基础上做一些扩展,将标准纳为代码页的子集。比如微软的 codepage 1252 对应 ISO/IEC 8859-1(latin 1),同时对其做了扩展。
另一方面,由于某些厂商的产品被广泛使用,其制定的代码页也就被其他厂商的产品支持。比如由于 IBM PC 在商业上的巨大成功,微软的 MS-DOS 操作系统依赖其捆绑销售,所以我们打开微软的代码页列表可见里面有大量的 IBM 代码页,比如微软的 codepage 437 就是对应的 IBM codepage 437,以及里面很多有“OEM”描述的基本都是 IBM 的代码页。具体参见:https://docs.microsoft.com/en-us/windows/win32/intl/code-page-identifiers。
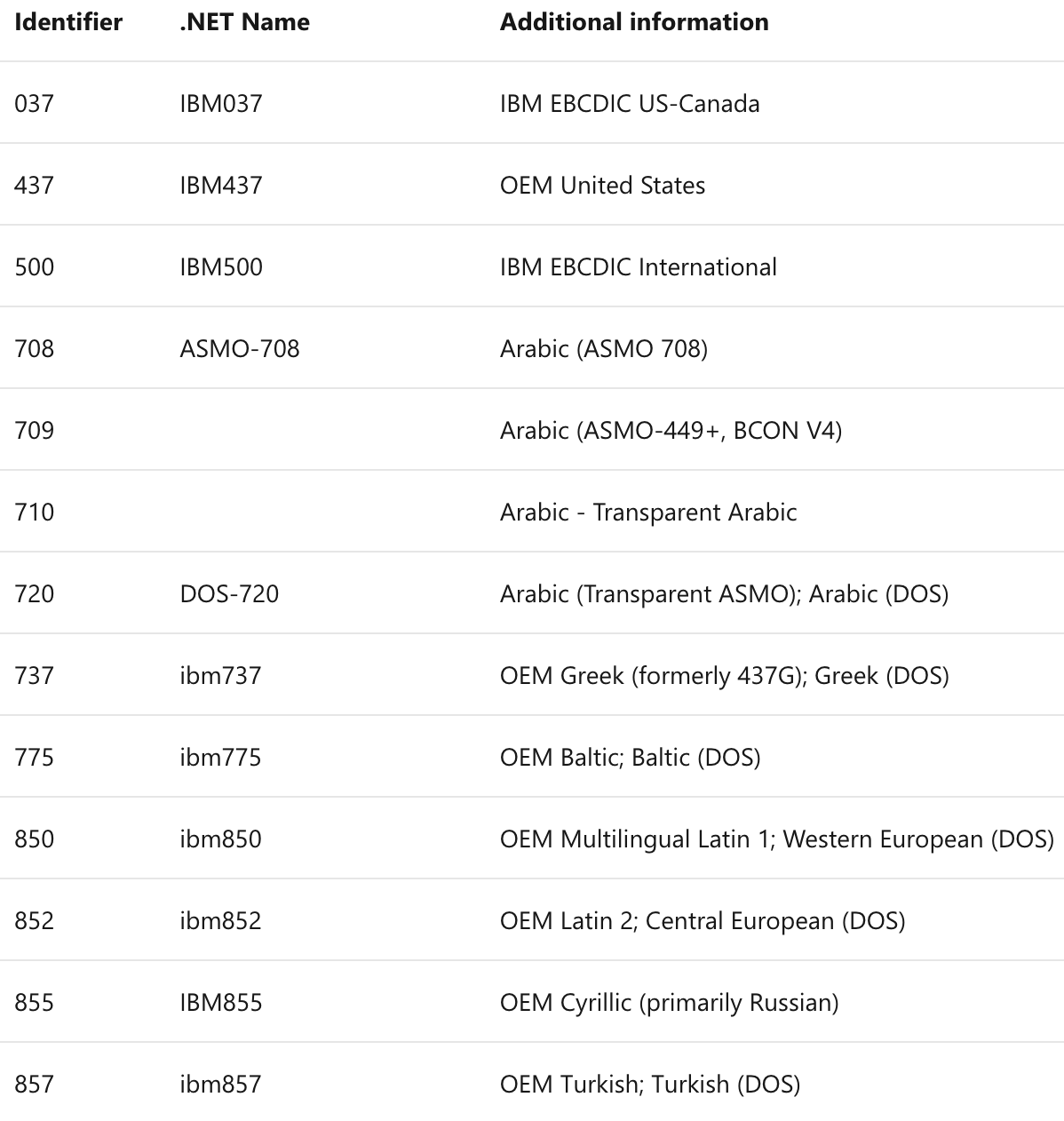
微软对 IBM 代码页的支持(部分)
Windows 的 ANSI 编码
你在 Windows 上保存记事本文件时,在编码栏会发现有个叫 ANSI 的编码方式:
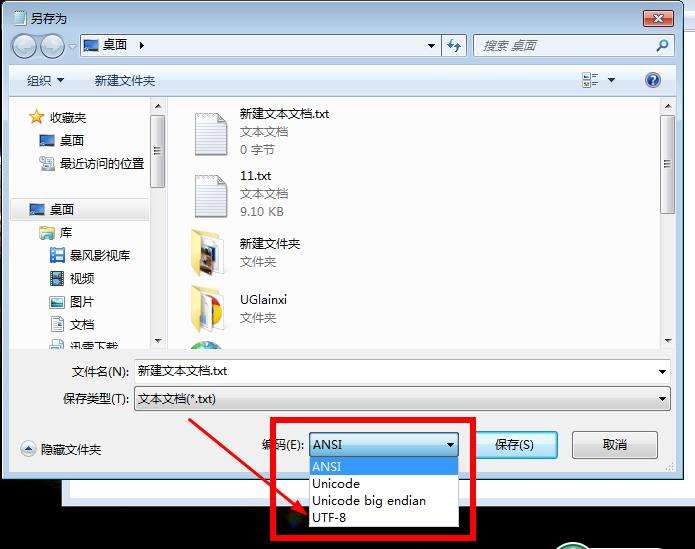
ANSI 是美国国家标准学会(American National Standards Institute),它是一个组织机构,被微软放在这里作为编码方式着实让人摸不着头脑。这要了解一下它的历史。
在微软开发 Windows 视窗操作系统时,美国国家标准学会 ANSI 正在制定针对西欧语言文字的 ASCII 扩展草案(该草案后来被 ISO/IEC 接受作为 ISO/IEC 8859-1 标准)。微软当时基于该草案制定了一个代码页 codepage 1252 用来编码西欧字符(注意微软是基于草案制定的代码页,那时候 ISO/IEC 8859-1 还没有对外发布。codepage 1252 是 ISO/IEC 8859-1 的超集)。微软管这个代码页叫“ANSI codepage”(微软官网对 codepage 1252 的描述是“ANSI Latin 1; Western European (Windows)”)。
也就是说,微软说的 ANSI 编码最早就是特指其基于 ANSI Latin 1 草案制定的 codepage 1252 这个代码页。
后来 Unicode 出现了,微软的新版本 Windows 很快就支持了 Unicode(最开始是以 UTF-16 的形式,所以你在微软的编码选项里面会看到一项“Unicode”编码项,就是指 UTF-16 编码)。为了和 Unicode 编码相区分,在 Windows 95 以及后续版本中,“ANSI 编码”的含义已经不再单指 codepage 1252 了,而是指所有的非 Unicode 编码方案——也就是说它不再表示一个代码页,而是表示一组代码页,具体表示哪个取决于系统设置,比如简体中文环境就表示 codepage 936(GB2312)。
传统编码的问题
我们上面讨论的这些编码标准(ASCII、ISO/IEC 8859 系列、GB 系列、Big5 以及各软硬件厂商自己制定的标准)都存在两个问题:
- 没有哪个编码标准能囊括全世界所有的字符,因而必须针对不同的文字符号制定不同的标准(如针对欧洲各语系的 ISO 8859 系列,针对简体中文的 GB2312,针对繁体中文的 Big5,针对日语的 Shift JIS 等)。
- 这些数目繁杂的标准之间互不兼容(比如同一个数字编号 1000 在 GB2312 和 Big5 里面表示的字符是不同的),因而软件对一段文本一旦用错了编码标准就会出现乱码。
以上问题导致的结果是,一个软件要想用在不同语言的市场,就得同时支持多种编码方式,特别在早期,这些工作都是各自厂商自己在做,耗费了大量的人力财力,而且还要不停地更新各种编码标准。另外,由于各厂商对同一个语系的字符采用了不同的编码标准,同样一个法语文件,在软件 A 中打开正常,在软件 B 中可能就是乱码,虽然 A 和 B 都支持法语字符。
总之,在很长一段时间,技术人员一边要不厌其烦地开发、更新、兼容各种字符集编码,另一方面又要受着各种乱码问题的折磨。
直到 1987 年的某一天,这帮人中的几个终于忍无可忍,凑到一起,决定开发一套能容纳全世界所有字符的标准,一统天下。
在下一篇文章中,我们将聊聊这个能“一统天下”的新编码标准:Unicode。