[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (6) --- Distributed hash表
0x00 摘要
在这系列文章中,我们介绍了 HugeCTR,这是一个面向行业的推荐系统训练框架,针对具有模型并行嵌入和数据并行密集网络的大规模 CTR 模型进行了优化。
其中借鉴了HugeCTR源码阅读 这篇大作,特此感谢。
本系列其他文章如下:
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(1)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (2)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器---(3)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (4)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (5) 嵌入式hash表
0x01 简述
1.1 基类
DistributedSlotSparseEmbeddingHash类继承自 IEmbedding,Embedding 是所有嵌入层的接口。
class IEmbedding {
public:
virtual ~IEmbedding() {}
virtual TrainState train(bool is_train, int i, TrainState state) { return TrainState(); }
// TODO: can we remove the default argument?
virtual void forward(bool is_train, int eval_batch = -1) = 0;
virtual void backward() = 0;
virtual void update_params() = 0;
virtual void init_params() = 0;
virtual void load_parameters(std::string sparse_model) = 0;
virtual void dump_parameters(std::string sparse_model) const = 0;
virtual void set_learning_rate(float lr) = 0;
// TODO: a workaround to enable GPU LR for HE only; need a better way
virtual GpuLearningRateSchedulers get_learning_rate_schedulers() const {
return GpuLearningRateSchedulers();
}
virtual size_t get_params_num() const = 0;
virtual size_t get_vocabulary_size() const = 0;
virtual size_t get_max_vocabulary_size() const = 0;
virtual Embedding_t get_embedding_type() const = 0;
virtual void load_parameters(BufferBag& buf_bag, size_t num) = 0;
virtual void dump_parameters(BufferBag& buf_bag, size_t* num) const = 0;
virtual void reset() = 0;
virtual void reset_optimizer() = 0;
virtual void dump_opt_states(std::ofstream& stream) = 0;
virtual void load_opt_states(std::ifstream& stream) = 0;
virtual const SparseEmbeddingHashParams& get_embedding_params() const = 0;
virtual std::vector<TensorBag2> get_train_output_tensors() const = 0;
virtual std::vector<TensorBag2> get_evaluate_output_tensors() const = 0;
virtual void check_overflow() const = 0;
virtual void get_forward_results_tf(const bool is_train, const bool on_gpu,
void* const forward_result) = 0;
virtual cudaError_t update_top_gradients(const bool on_gpu, const void* const top_gradients) = 0;
};
1.2 功能
在 DistributedSlotSparseEmbeddingHash 之中,嵌入表中的一些插槽被分配给多个GPU,称为分布式插槽。例如,slot-0 被分配到GPU-0/GPU-1上,slot-1 被分配到GPU-0/GPU-1上。嵌入表被封装在哈希表中,或者说哈希表是嵌入表的前置条件。哈希表一些相关成员变量如下:
- 哈希表中的键称为 hash_table_key。
- 哈希表中的值称为 hash_table_value_index,表示嵌入特征在嵌入表中的行号(row number)。
- 嵌入特征称为 hash_table_value,就是利用 hash_table_value_index(行号)在嵌入表之中找到的那一行。
DistributedSlotSparseEmbeddingHash 类实现了嵌入层的训练过程所需的所有操作,包括前向传播和后向传播。前向传播对应于API forward()。反向传播分为两个阶段的API:backward()和update_params()。该类还提供将哈希表(包括哈希表键hash_table_key、hash_table_value_index和hash_table_value)从主机文件上载到GPU(load_parameters 方法)的操作,以及将哈希表从GPU下载到主机文件(dump_parameters方法)的操作。
0x02 定义
2.1 思路
我们先自行想想看如何实现这个嵌入层,这样会让我们更好的理清楚思路。
- 高维矩阵 :假设不考虑field的情况下,embedding矩阵大小是 A * B,A 是 one-hot 的长度,B是embedding size,假如 one-hot 长10000000,embedding size是64。Hash_key 是一个one-hot [0,0,..0,1,0,..,0],其可以定位到 embedding矩阵的一行。假设 hash_key 的第367位置上是1,则就会找到embedding矩阵的367行,从 367 行得到一个64长度的dense vector。
- 数据特点 :前面提到过,CTR的特点是高维,稀疏,这说明嵌入表10000000 行之中可能只有500行是有意义的数值,其余为空,
- **低维矩阵 ** : HugeCTR 内部实际上不可能内部存放一个巨大矩阵,肯定是改用一个小型矩阵来存储,比如1000 x 64 的小型矩阵。
- 转换机制 :所以需要有一个机制,把 367 这个高维嵌入表的 row index 映射到这个小型低维矩阵的 row index,通过一系列复杂的操作用时间来换取空间。这也就是 DistributedSlotSparseEmbeddingHash 的一系列成员变量所起到的作用。
2.2 代码
DistributedSlotSparseEmbeddingHash 的定义如下,主要变量/概念为:
CSR相关,可以结合CSR定义来印证。
- @param row_offset :row_offset (CSR format of input sparse tensors)。
- @param hash_key :value (CSR format of input sparse tensors)。
- @param nnz :non-zero feature number per batch。
输入/输出数据:
- embedding_data_ :这里包括很多数据。
- 前面提到的 DataReader.output_ 就会被保存在这里,就是 sparse input 信息。
- 这里的 train_output_tensors_ 成员变量则是嵌入层最终的输出,就是多个GPU之间互相作用之后得出的输出。注意,train_output_tensors_ 在反向传播时候居然还被用来作为输入梯度。
Hash相关:
- hash_tables_ :这是一个哈希表vector,每一个元素都是一个hash_table(NvHashTable),本地每一个GPU对应这个vector之中的一个NvHashTable。目的是为了把高维矩阵的row offset 转换为低维矩阵的 row offset。
- 在 hash_table 内部,逻辑上来看每一个元素可以认为是 <key, value_index>(其实内部是个黑盒子,只是对外逻辑表示为一个哈希表 <key, value_index>);
- 哈希表中的键称为 hash_table_key,其格式是 CSR (CSR format of input sparse tensors)相关。
- 哈希表中的值称为 hash_table_value_index,表示 CSR 对应的嵌入特征在嵌入表中的行号。
- hash_value_index_tensors_ :embedding vector表的row index。就是低维矩阵的 row offset。
- 需要注意,其类型是 Tensors2,其类型是 std::vector<Tensor2
>,所以每一个GPU对应了该vector之中的一个元素。 - index 和 value 的行数相关。
- 内容是hash table value_index(row index of embedding)。
- 需要注意,其类型是 Tensors2,其类型是 std::vector<Tensor2
- hash_table_value_tensors_ :embedding vector表的value。就是低维矩阵。
- 需要注意,其类型是 Tensors2,其类型是 std::vector<Tensor2
>,所以每一个GPU对应了该vector之中的一个元素。 - 其内容是embedding vector。
- 用hash_value_index_tensors_的结果在这里查找一个 embedding vector。
- 需要注意,其类型是 Tensors2,其类型是 std::vector<Tensor2
中间数据:
- embedding_feature_tensors_ : 嵌入层前向传播的中间输出,就是上面查找到的embedding vector的结果,但是没有经过GPU之间的操作( reduce-scatter等);
- row_offset_allreduce_tensors_ :allreduce之后的row_offset。
反向传播:
- wgrad_tensors_ :后向传播的梯度,是backward之后产生的结果;
- embedding_optimizers_ : 嵌入层对应的优化器。
这里有两点说明:
- 为了方便起见,hash_value_index_tensors_ 这样虽然是一个向量的向量,我们后续都省略一步,当作向量来考虑。
- 需要对 hash_value_index_tensors_ 做进一步解释:
- hash_value_index_tensors_ 起到了解耦合的作用,把低维矩阵和哈希表进行解耦合。因为解耦合的原因,hash_value_index_tensors_ 并不应该知道 哈希表内部把高维矩阵的维度映射到了多大的低维矩阵,而 hash_value_index_tensors_ 大小也不应该随之变化。
- 所以,hash_value_index_tensors_ 大小被固定为:batch_size * nnz_per_slot,可以认为就是CSR之中元素个数。因此 hash_value_index_tensors_ 实际上记录了每个元素对应的低维矩阵offset 数值,hash_value_index_tensors_ 其事实上就是和CSR之中元素位置一一对应。
- 因此,最终嵌入表查找时候,是通过CSR row offset 来找到 CSR之中每个元素,也找到了hash_value_index_tensors_ 这个表的index,从而就能找到其低维矩阵offset。
我们再从源码之中找出部分注释给大家看看几个变量之间的关系,其查找逻辑是从上到下。

DistributedSlotSparseEmbeddingHash 具体定义如下:
template <typename TypeHashKey, typename TypeEmbeddingComp>
class DistributedSlotSparseEmbeddingHash : public IEmbedding {
using NvHashTable = HashTable<TypeHashKey, size_t>;
private:
// 前面提到的 DataReader.output_ 就会被保存在这里。就是sparse input信息
EmbeddingData<TypeHashKey, TypeEmbeddingComp> embedding_data_;
// 是 hash_value, hash_value_index的实际存储位置
std::vector<DistributedFilterKeyStorage<TypeHashKey>> filter_keys_storage_;
std::vector<std::shared_ptr<NvHashTable>> hash_tables_; /**< Hash table. */
// define tensors
Tensors2<float> hash_table_value_tensors_; /**< Hash table value. */
Tensors2<size_t> hash_value_index_tensors_; /**< Hash table value index. The index is
corresponding to the line number of the value. */
Tensors2<TypeEmbeddingComp>
embedding_feature_tensors_; /**< the output tensor of the forward(). */
Tensors2<TypeEmbeddingComp> wgrad_tensors_; /**< the input tensor of the backward(). */
Tensors2<TypeHashKey>
row_offset_allreduce_tensors_; /**< The temp memory to store the row_offset after all_reduce
operation among multi-gpu in forward(). */
Tensors2<TypeEmbeddingComp> utest_forward_temp_tensors_;
size_t max_vocabulary_size_; /**< Max vocabulary size for each GPU. */
size_t max_vocabulary_size_per_gpu_; /**< Max vocabulary size for each GPU. */
SparseEmbeddingFunctors functors_;
std::vector<EmbeddingOptimizer<TypeHashKey, TypeEmbeddingComp>> embedding_optimizers_;
}
因为定义是模版类,所以具体拓展为如下:
template class DistributedSlotSparseEmbeddingHash<unsigned int, float>;
template class DistributedSlotSparseEmbeddingHash<long long, float>;
template class DistributedSlotSparseEmbeddingHash<unsigned int, __half>;
template class DistributedSlotSparseEmbeddingHash<long long, __half>;
0x03 HashTable
因为DistributedSlotSparseEmbeddingHash 用到了 using NvHashTable = HashTable<TypeHashKey, size_t>,所以我们先看看 HashTable。这部分对应的是上面总图第一步,就是如何从 hash table 之中拿到低维嵌入表的 index。在后文之中,我们用 HashTable/哈希表来指定 DistributedSlotSparseEmbeddingHash 内部使用的真正的哈希表。
3.1 定义
HashTable 之中,很重要的成员变量是container_。
/**
* The HashTable class is wrapped by cudf library for hash table operations on single GPU.
* In this class, we implement the GPU version of the common used operations of hash table,
* such as insert() / get() / set() / dump()...
*/
template <typename KeyType, typename ValType>
class HashTable {
const KeyType empty_key = std::numeric_limits<KeyType>::max();
private:
static const int BLOCK_SIZE_ =
256; /**< The block size of the CUDA kernels. The default value is 256. */
const float LOAD_FACTOR = 0.75f;
const size_t capacity_;
HashTableContainer<KeyType, ValType>* container_; /**< The object of the Table class which is
defined in the concurrent_unordered_map class. */
// Counter for value index
size_t* d_counter_; /**< The device counter for value index. */
size_t* d_container_size_;
};
3.2 HashTableContainer
container_ 的类型是HashTableContainer,其是 concurrent_unordered_map 的派生类,所以我们还是需要看看 concurrent_unordered_map。
template <typename KeyType, typename ValType>
class HashTableContainer
: public concurrent_unordered_map<KeyType, ValType, std::numeric_limits<KeyType>::max()> {
public:
HashTableContainer(size_t capacity)
: concurrent_unordered_map<KeyType, ValType, std::numeric_limits<KeyType>::max()>(
capacity, std::numeric_limits<ValType>::max()) {}
};
3.3 调用
为了更好的分析,在看 concurrent_unordered_map 之前,我们需要看看如何调用HashTable。调用代码是HugeCTR/src/embeddings/forward_per_gpu_functor.cu 之中的forward_per_gpu方法。这里已经是 CUDA 代码了。
emplate <typename TypeHashKey, typename TypeEmbeddingComp>
void SparseEmbeddingFunctors::forward_per_gpu(
size_t batch_size, size_t slot_num, size_t embedding_vec_size, int combiner, bool train,
const Tensor2<TypeHashKey> &row_offset, const Tensor2<TypeHashKey> &hash_key, size_t nnz,
HashTable<TypeHashKey, size_t> &hash_table, const Tensor2<float> &hash_table_value,
Tensor2<size_t> &hash_value_index, Tensor2<TypeEmbeddingComp> &embedding_feature,
cudaStream_t stream) {
try {
if (train) {
// 这里会调用插入代码
hash_table.get_insert(hash_key.get_ptr(), hash_value_index.get_ptr(), nnz, stream);
} else {
hash_table.get_mark(hash_key.get_ptr(), hash_value_index.get_ptr(), nnz, stream);
}
// do sum reduction
// 省略其他代码
return;
}
可以看到,hash_key.get_ptr(), hash_value_index.get_ptr() 分别对应的是 _d_keys, _d_vals。
template <typename KeyType, typename ValType>
void NvHashTable<KeyType, ValType>::get_insert(const void *d_keys, void *d_vals, size_t len, cudaStream_t stream) {
const KeyType *_d_keys = reinterpret_cast<const KeyType*>(d_keys);
ValType *_d_vals = reinterpret_cast<ValType*>(d_vals);
return hashtable_.get_insert(_d_keys, _d_vals, len, stream);
}
然后调用到 get_insert。
template <typename KeyType, typename ValType>
void HashTable<KeyType, ValType>::get_insert(const KeyType* d_keys, ValType* d_vals, size_t len,
cudaStream_t stream) {
if (len == 0) {
return;
}
const int grid_size = (len - 1) / BLOCK_SIZE_ + 1;
get_insert_kernel<<<grid_size, BLOCK_SIZE_, 0, stream>>>(container_, d_keys, d_vals, len,
d_counter_);
}
template <typename Table>
__global__ void get_insert_kernel(Table* table, const typename Table::key_type* const keys,
typename Table::mapped_type* const vals, size_t len,
size_t* d_counter) {
ReplaceOp<typename Table::mapped_type> op;
const size_t i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < len) {
auto it = table->get_insert(keys[i], op, d_counter);
vals[i] = it->second;
}
}
所以最终调用到 concurrent_unordered_map 的 get_insert。
3.4 concurrent_unordered_map
concurrent_unordered_map 定义在 HugeCTR/include/hashtable/cudf/concurrent_unordered_map.cuh。
这是位于显存中的map。从其注释可知,其支持并发插入,但是不支持同时insert和probping。结合HugeCTR看,hugeCTR是同步训练,pull操作只会调用 get,push操作只会调用insert,不存在同时insert和probping,所以满足需求。
/**
* Does support concurrent insert, but not concurrent insert and probping.
*
* TODO:
* - add constructor that takes pointer to hash_table to avoid allocations
* - extend interface to accept streams
*/
template <typename Key, typename Element, Key unused_key, typename Hasher = default_hash<Key>,
typename Equality = equal_to<Key>,
typename Allocator = managed_allocator<thrust::pair<Key, Element>>,
bool count_collisions = false>
class concurrent_unordered_map : public managed {
public:
using size_type = size_t;
using hasher = Hasher;
using key_equal = Equality;
using allocator_type = Allocator;
using key_type = Key;
using value_type = thrust::pair<Key, Element>;
using mapped_type = Element;
using iterator = cycle_iterator_adapter<value_type*>;
using const_iterator = const cycle_iterator_adapter<value_type*>;
private:
const hasher m_hf;
const key_equal m_equal;
const mapped_type m_unused_element;
allocator_type m_allocator;
size_type m_hashtbl_size;
size_type m_hashtbl_capacity;
value_type* m_hashtbl_values; // 这个才是hash数据结构位置
unsigned long long m_collisions;
};
3.4.1 get
我们先看看get操作,就是find方法。
// __forceinline__ 的意思是编译为内联函数
// __host__ __device__ 表示是此函数同时为主机和设备编译
__forceinline__ __host__ __device__ const_iterator find(const key_type& k) const {
// 对key进行hash操作
size_type key_hash = m_hf(k);
// 进而得到table的相应index
size_type hash_tbl_idx = key_hash % m_hashtbl_size;
value_type* begin_ptr = 0;
size_type counter = 0;
while (0 == begin_ptr) {
value_type* tmp_ptr = m_hashtbl_values + hash_tbl_idx;
const key_type tmp_val = tmp_ptr->first;
// 找到key,跳出
if (m_equal(k, tmp_val)) {
begin_ptr = tmp_ptr;
break;
}
// key的位置是空,或者在table之内没有找到
if (m_equal(unused_key, tmp_val) || counter > m_hashtbl_size) {
begin_ptr = m_hashtbl_values + m_hashtbl_size;
break;
}
hash_tbl_idx = (hash_tbl_idx + 1) % m_hashtbl_size;
++counter;
}
return const_iterator(m_hashtbl_values, m_hashtbl_values + m_hashtbl_size, begin_ptr);
}
3.4.2 insert
插入操作我们就看看之前的 get_insert。
hash_table.get_insert(hash_key.get_ptr(), hash_value_index.get_ptr(), nnz, stream);
就是以 csr 部分信息作为 hash key,来获得一个低维嵌入表之中的index,在 hash_value_index之中返回。我们首先看一个CSR示例。
* For example data:
* 3356
* 667
* 588
* Will be convert to the form of:
* row offset: 0,1,2,3
* value: 3356,667,588,3
我们就是使用 3356 作为 hash_key,获取 3356 对应的 hash_value_index,如果能找到就返回,找不到就插入一个构建的value,然后这个 value 会返回给 hash_value_index。
但是这里有几个绕的地方,因为 HashTable内部也分桶,也有自己的key,hash_value,容易和其他数据结构弄混。具体逻辑是:
- 传入一个数字 3356(CSR格式相关),还有一个 value_counter,就是目前 hash_value_index 的数值。
- 先 hash_value = m_hf(3356)。
- 用 current_index = hash_value % hashtbl_size 找到 m_hashtbl_values 之中的位置。
- 用 current_hash_bucket = &(hashtbl_values[current_index]) 这找到了一个bucket。
- key_type& existing_key = current_hash_bucket->first,这个才是 hash table key
- volatile mapped_type& existing_value = current_hash_bucket->second,这个才是我们最终需要的 table value。如果没有,就递增传入的 value_counter。
所以,CSR 3356 是一个one-hot 的index,它对应了embeding表的一个index,但是因为没有那么大的embedding,所以后面会构建一个小数据结构(低维矩阵) hash_value,传入的 value_counter 就是这个 hash_value的index,value_counter 是递增的,因为 hash_value 的行号就是递增的。
比如一共有1亿个单词,3356表示第3356个单词。如果想表示 3356,667,588 这三个位置在这一亿个单词是有效的,最笨的办法是弄个1亿长度数组,把3356,667,588这三个位置设置为 1,其他位置设置为0,但是这样太占据空间且没有意义。如果想省空间,就弄一个hash函数 m_hf,假如是选取最高位数为 value,则得到:
m_hf(3356)=3
m_hf(667)=6
m_hf(588)=5
3,5,6 就是内部的 hash_value,叫做 hash_value(对应下面代码),对应的内部存储数组叫做 hashtbl_values。再梳理一下:3356是哈希表的key,3 是哈希表的value,但是因为分桶了,所以在哈希表内部是放置在 hashtbl_values 之中。
hashtbl_values[3] = 1,hashtbl_values[6] = 2, hashtbl_values[5] =3
于是 1,2,3 就是我们外部想得到的 3356, 667, 588 对应的数据,就是低维矩阵的 row offset,对应下面代码就是 existing_value。简化版本的逻辑如下:
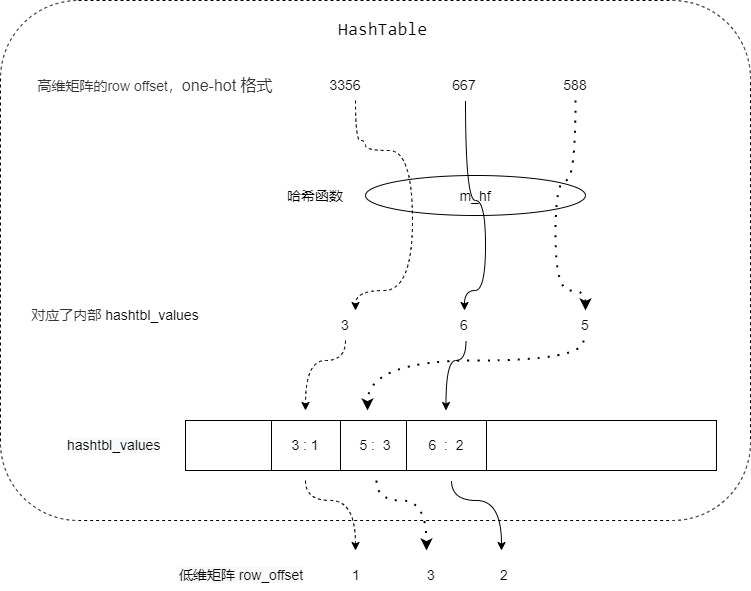
具体代码如下:
// __forceinline__ 的意思是编译为内联函数
// __host__ __device__ 表示是此函数同时为主机和设备编译
template <typename aggregation_type, typename counter_type, class comparison_type = key_equal,
typename hash_value_type = typename Hasher::result_type>
__forceinline__ __device__ iterator get_insert(const key_type& k, aggregation_type op,
counter_type* value_counter,
comparison_type keys_equal = key_equal(),
bool precomputed_hash = false,
hash_value_type precomputed_hash_value = 0) {
const size_type hashtbl_size = m_hashtbl_size;
value_type* hashtbl_values = m_hashtbl_values;
hash_value_type hash_value{0};
// If a precomputed hash value has been passed in, then use it to determine
// the write location of the new key
if (true == precomputed_hash) {
hash_value = precomputed_hash_value;
}
// Otherwise, compute the hash value from the new key
else {
hash_value = m_hf(k); // 3356作为key,得到了一个hash_value
}
size_type current_index = hash_value % hashtbl_size; // 找到哪个位置
value_type* current_hash_bucket = &(hashtbl_values[current_index]); // 找到该位置的bucket
const key_type insert_key = k;
bool insert_success = false;
size_type counter = 0;
while (false == insert_success) {
// Situation %5: No slot: All slot in the hashtable is occupied by other key, both get and
// insert fail. Return empty iterator
// hash表已经满了
if (counter++ >= hashtbl_size) {
return end();
}
key_type& existing_key = current_hash_bucket->first; // 这个才是table key
volatile mapped_type& existing_value = current_hash_bucket->second; // 这个才是table value
// 如果 existing_key == unused_key时,则当前哈希位置为空,所以existing_key由atomicCAS更新为insert_key。
// 如果 existing_key == insert_key时,这个位置已经被插入这个key了。
// 在任何一种情况下,都要执行existing_value和insert_value的atomic聚合,因为哈希表是用聚合操作的标识值初始化的,所以在existing_value仍具有其初始值时,执行该操作是安全的
// Try and set the existing_key for the current hash bucket to insert_key
const key_type old_key = atomicCAS(&existing_key, unused_key, insert_key);
// If old_key == unused_key, the current hash bucket was empty
// and existing_key was updated to insert_key by the atomicCAS.
// If old_key == insert_key, this key has already been inserted.
// In either case, perform the atomic aggregation of existing_value and insert_value
// Because the hash table is initialized with the identity value of the aggregation
// operation, it is safe to perform the operation when the existing_value still
// has its initial value
// TODO: Use template specialization to make use of native atomic functions
// TODO: How to handle data types less than 32 bits?
// Situation #1: Empty slot: this key never exist in the table, ready to insert.
if (keys_equal(unused_key, old_key)) { // 如果没有找到hash key
existing_value = (mapped_type)(atomicAdd(value_counter, 1)); // hash value 就递增
break;
} // Situation #2+#3: Target slot: This slot is the slot for this key
else if (keys_equal(insert_key, old_key)) {
while (existing_value == m_unused_element) {
// Situation #2: This slot is inserting by another CUDA thread and the value is not yet
// ready, just wait
}
// Situation #3: This slot is already ready, get successfully and return (iterator of) the
// value
break;
}
// Situation 4: Wrong slot: This slot is occupied by other key, get fail, do nothing and
// linear probing to next slot.
// 此位置已经被其他key占了,只能向后遍历
current_index = (current_index + 1) % hashtbl_size;
current_hash_bucket = &(hashtbl_values[current_index]);
}
return iterator(m_hashtbl_values, m_hashtbl_values + hashtbl_size, current_hash_bucket);
}
0x04 构建
4.1 初始化
我们接下来看看如何构建 DistributedSlotSparseEmbeddingHash,代码之中需要留意的是:
- hash_tables_ 之中,每一个元素对应一个GPU。
- train_keys 就是前面提到的 sparse_input,就是CSR format 相关的 row offset。
具体就是分配内存,hash_tables_的大小是本地GPU数目,即每个GPU对应一个hash表,用一个gpu卡上的最大sparse key 的个数来初始化hash table,这样每个hash table能容纳元素的最大数值就被固定住了。
template <typename TypeHashKey, typename TypeEmbeddingComp>
DistributedSlotSparseEmbeddingHash<TypeHashKey, TypeEmbeddingComp>::
DistributedSlotSparseEmbeddingHash(const SparseTensors<TypeHashKey> &train_keys,
const SparseTensors<TypeHashKey> &evaluate_keys,
const SparseEmbeddingHashParams &embedding_params,
const std::shared_ptr<ResourceManager> &resource_manager)
: embedding_data_(Embedding_t::DistributedSlotSparseEmbeddingHash, train_keys, evaluate_keys,
embedding_params, resource_manager) {
try {
// 得到一个gpu卡上最大sparse key个数
max_vocabulary_size_per_gpu_ = embedding_data_.embedding_params_.max_vocabulary_size_per_gpu;
max_vocabulary_size_ = max_vocabulary_size_per_gpu_ *
embedding_data_.get_resource_manager().get_global_gpu_count();
// 构建上下文
CudaDeviceContext context;
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); id++) {
context.set_device(embedding_data_.get_local_gpu(id).get_device_id());
// buf用来分配内存
// new GeneralBuffer objects
const std::shared_ptr<GeneralBuffer2<CudaAllocator>> &buf = embedding_data_.get_buffer(id);
embedding_optimizers_.emplace_back(max_vocabulary_size_per_gpu_,
embedding_data_.embedding_params_, buf);
{ // train_value_tensors_ 配置内存
Tensor2<TypeHashKey> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(true),
embedding_data_.embedding_params_.max_feature_num},
&tensor);
embedding_data_.train_value_tensors_.push_back(tensor);
}
{ // evaluate_value_tensors_ 配置内存
Tensor2<TypeHashKey> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(false),
embedding_data_.embedding_params_.max_feature_num},
&tensor);
embedding_data_.evaluate_value_tensors_.push_back(tensor);
}
{ // train_row_offsets_tensors_配置内存
Tensor2<TypeHashKey> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(true) *
embedding_data_.embedding_params_.slot_num +
1},
&tensor);
embedding_data_.train_row_offsets_tensors_.push_back(tensor);
}
{ // evaluate_row_offsets_tensors_ 配置内存
Tensor2<TypeHashKey> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(false) *
embedding_data_.embedding_params_.slot_num +
1},
&tensor);
embedding_data_.evaluate_row_offsets_tensors_.push_back(tensor);
}
{ embedding_data_.train_nnz_array_.push_back(std::make_shared<size_t>(0)); }
{ embedding_data_.evaluate_nnz_array_.push_back(std::make_shared<size_t>(0)); }
// new hash table value vectors
{ // hash_table_value_tensors_ 配置内存
Tensor2<float> tensor;
buf->reserve(
{max_vocabulary_size_per_gpu_, embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
hash_table_value_tensors_.push_back(tensor);
}
// new hash table value_index that get() from HashTable
{ // hash_value_index_tensors_配置内存,注意,这里配置的大小是 batch_size * max_feature_number
Tensor2<size_t> tensor;
buf->reserve({1, embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.max_feature_num},
&tensor);
hash_value_index_tensors_.push_back(tensor);
}
// new embedding features reduced by hash table values(results of forward)
{ // embedding_feature_tensors_ 配置内存
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
embedding_feature_tensors_.push_back(tensor);
}
// new wgrad used by backward
{ // wgrad_tensors_ 配置内存
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(true) *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
wgrad_tensors_.push_back(tensor);
}
// new temp tensors used by update_params
{ // row_offset_allreduce_tensors_ 配置内存
Tensor2<TypeHashKey> tensor;
buf->reserve({1, embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.slot_num +
1},
&tensor);
row_offset_allreduce_tensors_.push_back(tensor);
}
{ // utest_forward_temp_tensors_ 配置内存
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
utest_forward_temp_tensors_.push_back(tensor);
}
// temp storage for filter keys
{
size_t max_nnz = embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.max_feature_num;
size_t rowoffset_count = embedding_data_.embedding_params_.slot_num *
embedding_data_.embedding_params_.get_universal_batch_size() +
1;
filter_keys_storage_.emplace_back(
buf, max_nnz, rowoffset_count, embedding_data_.get_local_gpu(id).get_global_id(),
embedding_data_.get_resource_manager().get_global_gpu_count());
}
// init GenenralBuffers to do real allocation
}
// hash_tables_的大小是本地GPU数目,即每个GPU对应一个hash表
hash_tables_.resize(embedding_data_.get_resource_manager().get_local_gpu_count());
#pragma omp parallel num_threads(embedding_data_.get_resource_manager().get_local_gpu_count())
{ // 并行分配内存
size_t id = omp_get_thread_num();
CudaDeviceContext context(embedding_data_.get_local_gpu(id).get_device_id());
// construct HashTable object: used to store hash table <key, value_index>
// 用一个gpu卡上的最大sparse key的个数来初始化hash table,这样每个hash table能容纳元素的最大数值就被固定住了。
hash_tables_[id].reset(new NvHashTable(max_vocabulary_size_per_gpu_));
embedding_data_.get_buffer(id)->allocate();
}
// 遍历本地的GPU
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); id++) {
context.set_device(embedding_data_.get_local_gpu(id).get_device_id());
embedding_optimizers_[id].initialize(embedding_data_.get_local_gpu(id));
} // end of for(int id = 0; id < embedding_data_.get_local_gpu_count(); id++)
if (!embedding_data_.embedding_params_.slot_size_array.empty()) {
std::vector<TypeHashKey> embedding_offsets;
TypeHashKey slot_sizes_prefix_sum = 0;
for (size_t i = 0; i < embedding_data_.embedding_params_.slot_size_array.size(); i++) {
embedding_offsets.push_back(slot_sizes_prefix_sum);
slot_sizes_prefix_sum += embedding_data_.embedding_params_.slot_size_array[i];
}
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); ++id) {
CudaDeviceContext context(embedding_data_.get_local_gpu(id).get_device_id());
CK_CUDA_THROW_(
cudaMemcpy(embedding_data_.embedding_offsets_[id].get_ptr(), embedding_offsets.data(),
embedding_offsets.size() * sizeof(TypeHashKey), cudaMemcpyHostToDevice));
}
}
functors_.sync_all_gpus(embedding_data_.get_resource_manager());
} catch (const std::runtime_error &rt_err) {
std::cerr << rt_err.what() << std::endl;
throw;
}
return;
}
4.2 配置内存
我们要看看几个关键变量的内存配置。
4.2.1 hash_table_value_tensors_
hash_table_value_tensors_ 的内存是 max_vocabulary_size_per_gpu_ * embedding_vec_size。
{ // hash_table_value_tensors_ 配置内存
Tensor2<float> tensor;
buf->reserve(
{max_vocabulary_size_per_gpu_, embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
hash_table_value_tensors_.push_back(tensor);
}
而 max_vocabulary_size_per_gpu_计算如下:
max_vocabulary_size_per_gpu_ = embedding_data_.embedding_params_.max_vocabulary_size_per_gpu;
max_vocabulary_size_per_gpu 是在这里做了配置。
SparseEmbedding::SparseEmbedding(Embedding_t embedding_type, size_t workspace_size_per_gpu_in_mb,
size_t embedding_vec_size, const std::string& combiner_str,
std::string sparse_embedding_name, std::string bottom_name,
std::vector<size_t>& slot_size_array,
std::shared_ptr<OptParamsPy>& embedding_opt_params,
const HybridEmbeddingParam& hybrid_embedding_param)
: embedding_type(embedding_type),
workspace_size_per_gpu_in_mb(workspace_size_per_gpu_in_mb),
embedding_vec_size(embedding_vec_size),
sparse_embedding_name(sparse_embedding_name),
bottom_name(bottom_name),
slot_size_array(slot_size_array),
embedding_opt_params(embedding_opt_params),
hybrid_embedding_param(hybrid_embedding_param) {
if (combiner_str == "sum") {
combiner = 0;
} else if (combiner_str == "mean") {
combiner = 1;
} else {
CK_THROW_(Error_t::WrongInput, "No such combiner type: " + combiner_str);
}
max_vocabulary_size_per_gpu =
(workspace_size_per_gpu_in_mb * 1024 * 1024) / (sizeof(float) * embedding_vec_size);
}
4.2.2 hash_value_index_tensors_
hash_value_index_tensors_ 大小为 batch_size * max_feature_number。
// new hash table value_index that get() from HashTable
{ // hash_value_index_tensors_配置内存,注意,这里配置的大小是 batch_size * max_feature_number
Tensor2<size_t> tensor;
buf->reserve({1, embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.max_feature_num},
&tensor);
hash_value_index_tensors_.push_back(tensor);
}
max_feature_number 按照如下规则计算。
DataReaderSparseParam(const std::string& top_name_, const std::vector<int>& nnz_per_slot_,
bool is_fixed_length_, int slot_num_)
: top_name(top_name_),
nnz_per_slot(nnz_per_slot_),
is_fixed_length(is_fixed_length_),
slot_num(slot_num_),
type(DataReaderSparse_t::Distributed) {
max_feature_num = std::accumulate(nnz_per_slot.begin(), nnz_per_slot.end(), 0);
max_nnz = *std::max_element(nnz_per_slot.begin(), nnz_per_slot.end());
}
所以,hash_value_index_tensors_ 大小就是 batch_size * nnz_per_slot。
0x05 EmbeddingData
前面提到了 DistributedSlotSparseEmbeddingHash 如下成员变量会保存一些嵌入表信息。
EmbeddingData<TypeHashKey, TypeEmbeddingComp> embedding_data_;
我们来挖掘一下。
5.1 定义
EmbeddingData 定义如下,这里有两套成员变量,Tensors2 和 SparseTensors。
- Tensors2 如下:
- train_value_tensors_ 这个就会记录sparse input,是CSR 的value。
- train_row_offsets_tensors_ 是CSR 的 row offset。
- train_nnz_array_ 是CSR 相关的nnz。
- train_output_tensors_ 这个是前向传播的输出。
- SparseTensors 如下:
- train_keys_ 会把 value,offset,nnz都整合在一起,这里怀疑是在接口迁移,所以维护了两套。为何迁移?因为
train_value_tensors_,train_row_offsets_tensors_,train_nnz_array_ 都是Tensor2,是普通张量,而 train_keys_ 是 SparseTensors,可以一个变量就搞定前面所有概念。 - evaluate_keys_ 是验证集相关。
- train_keys_ 会把 value,offset,nnz都整合在一起,这里怀疑是在接口迁移,所以维护了两套。为何迁移?因为
所以,embedding_data_ 就是包揽了嵌入层的输入和输出。需要注意的是,这里都是 Tensors2,可以认为是 Tensor2 的列表,列表之中每一个Tensor2 对应了一个GPU。
template <typename TypeKey, typename TypeEmbeddingComp>
class EmbeddingData {
public:
const Embedding_t embedding_type_;
SparseEmbeddingHashParams embedding_params_; /**< Sparse embedding hash params. */
std::vector<std::shared_ptr<GeneralBuffer2<CudaAllocator>>>
bufs_; /**< The buffer for storing output tensors. */
Tensors2<TypeEmbeddingComp> train_output_tensors_; /**< The output tensors. */
Tensors2<TypeEmbeddingComp> evaluate_output_tensors_; /**< The output tensors. */
Tensors2<TypeKey> train_row_offsets_tensors_; /**< The row_offsets tensors of the input data. */
Tensors2<TypeKey> train_value_tensors_; /**< The value tensors of the input data. */
std::vector<std::shared_ptr<size_t>> train_nnz_array_;
Tensors2<TypeKey>
evaluate_row_offsets_tensors_; /**< The row_offsets tensors of the input data. */
Tensors2<TypeKey> evaluate_value_tensors_; /**< The value tensors of the input data. */
std::vector<std::shared_ptr<size_t>> evaluate_nnz_array_;
std::shared_ptr<ResourceManager> resource_manager_; /**< The GPU device resources. */
SparseTensors<TypeKey> train_keys_;
SparseTensors<TypeKey> evaluate_keys_;
Tensors2<TypeKey> embedding_offsets_;
}
5.2 构建
这里有两套构建函数,可能维护者在从旧接口切换到新接口。结合前后文,sparse_input 在 DistributedSlotSparseEmbeddingHash 构造函数之中是 train_keys 参数,在EmbeddingData 这里就是train_value_tensors,所以,value_tensors 就是我们要关注的,从注释可以知道,这是输入数据的value tensors,指向了稀疏矩阵的 value vector。
/**
* The constructor of Embedding class.
* @param row_offsets_tensors the row_offsets tensors of the input data(refer to row offset vector
* in sparse matrix CSR format).
* @param value_tensors the value tensors of the input data(refer to value vector in sparse matrix
* CSR format).
* @param batchsize the batch size of the input data
* @param slot_num the number of slots of the hash table
* @param embedding_vec_size the dim size of the embedding feature vector.
* @param resource_manager the GPU device resource group
* @param scaler scaler factor for mixed precision
*/
EmbeddingData(const Tensors2<TypeKey>& train_row_offsets_tensors,
const Tensors2<TypeKey>& train_value_tensors,
const std::vector<std::shared_ptr<size_t>>& train_nnz_array,
const Tensors2<TypeKey>& evaluate_row_offsets_tensors,
const Tensors2<TypeKey>& evaluate_value_tensors,
const std::vector<std::shared_ptr<size_t>>& evaluate_nnz_array,
const Embedding_t embedding_type, const SparseEmbeddingHashParams& embedding_params,
const std::shared_ptr<ResourceManager>& resource_manager)
: embedding_type_(embedding_type),
embedding_params_(embedding_params),
train_row_offsets_tensors_(train_row_offsets_tensors),
train_value_tensors_(train_value_tensors),
train_nnz_array_(train_nnz_array),
evaluate_row_offsets_tensors_(evaluate_row_offsets_tensors),
evaluate_value_tensors_(evaluate_value_tensors),
evaluate_nnz_array_(evaluate_nnz_array),
resource_manager_(resource_manager) {
try {
// Error check
if (embedding_params.train_batch_size < 1 || embedding_params.evaluate_batch_size < 1 ||
embedding_params.slot_num < 1 || embedding_params.embedding_vec_size < 1) {
CK_THROW_(Error_t::WrongInput, "batchsize < 1 || slot_num < 1 || embedding_vec_size < 1");
}
if (embedding_params.embedding_vec_size > 1024) {
CK_THROW_(Error_t::WrongInput,
"the embedding_vec_size can not be more than 1024 in embedding layer");
}
size_t total_gpu_count = resource_manager_->get_global_gpu_count();
size_t local_gpu_count = resource_manager_->get_local_gpu_count();
if (train_row_offsets_tensors.size() != local_gpu_count ||
train_value_tensors.size() != local_gpu_count ||
evaluate_row_offsets_tensors.size() != local_gpu_count ||
evaluate_value_tensors.size() != local_gpu_count) {
CK_THROW_(
Error_t::WrongInput,
"either row_offsets_tensors.size() or value_tensors.size() isn't local_gpu_count_");
}
assert(bufs_.empty());
for (size_t i = 0; i < local_gpu_count; i++) {
std::shared_ptr<GeneralBuffer2<CudaAllocator>> buf =
GeneralBuffer2<CudaAllocator>::create();
bufs_.push_back(buf);
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({get_batch_size_per_gpu(true), embedding_params_.slot_num,
embedding_params_.embedding_vec_size},
&tensor);
train_output_tensors_.push_back(tensor);
buf->reserve({get_batch_size_per_gpu(false), embedding_params_.slot_num,
embedding_params_.embedding_vec_size},
&tensor);
evaluate_output_tensors_.push_back(tensor);
}
// value,offset,nnz又整合了进来
for (size_t i = 0; i < local_gpu_count; i++) {
train_keys_.emplace_back(train_value_tensors_[i], train_row_offsets_tensors_[i],
train_nnz_array_[i]);
evaluate_keys_.emplace_back(evaluate_value_tensors_[i], evaluate_row_offsets_tensors_[i],
evaluate_nnz_array_[i]);
}
} catch (const std::runtime_error& rt_err) {
std::cerr << rt_err.what() << std::endl;
throw;
}
return;
}
我们最终拓展如下,经过第 C 步之后,DistributedSlotSparseEmbeddingHash的成员变量 也指向了 GPU 内存,这里依据构建函数的不同,train_output_tensors_,和 train_keys_ 可能(可能是因为有两种不同的构造方式,目前只是讨论其中一种)都会指向用户输入训练数据。
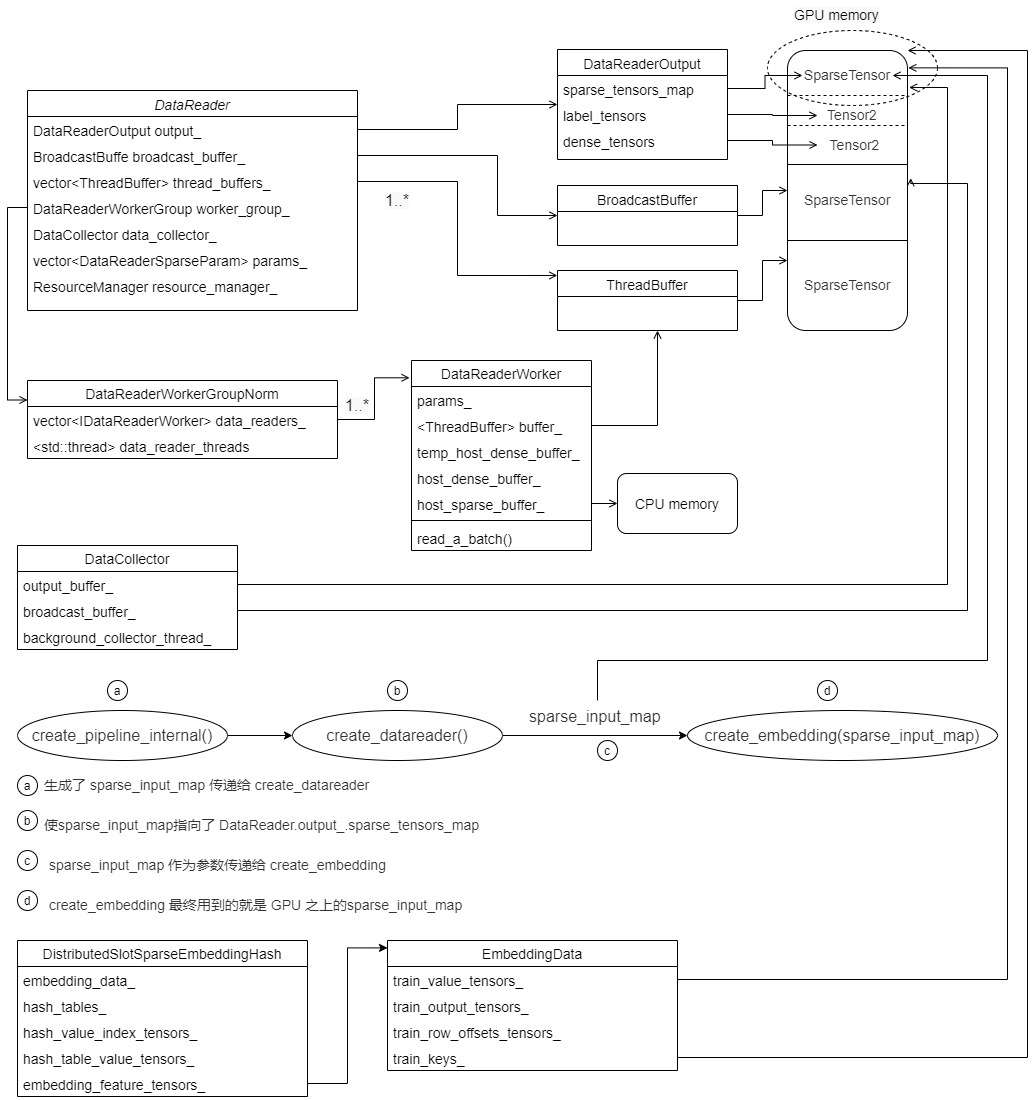
5.3 怎么得到row_offset
5.3.1 问题
目前,我们只设置了EmbeddingData的train_keys/train_value_tensors_,但这是SparseTensor,其内部不仅仅有value,还有row_offset等专门针对稀疏矩阵的信息,所以这部分也要进行设置。
我们提前看看前向传播,会发现其使用了类似 embedding_data_.get_row_offsets_tensors 进行运算。但是我们目前并没有配置这样的参数,只是配置了 train_keys。这个地方很绕,仔细看代码,原来在前向传播之中有使用 filter_keys_per_gpu 进行设置类似参数。
void forward(bool is_train, int eval_batch = -1) override {
// Read data from input_buffers_ -> look up -> write to output_tensors
#pragma omp parallel num_threads(embedding_data_.get_resource_manager().get_local_gpu_count())
{
size_t i = omp_get_thread_num();
CudaDeviceContext context(embedding_data_.get_local_gpu(i).get_device_id());
if (embedding_data_.embedding_params_.is_data_parallel) {
// 在这里有操作
filter_keys_per_gpu(is_train, i, embedding_data_.get_local_gpu(i).get_global_id(),
embedding_data_.get_resource_manager().get_global_gpu_count());
}
// 部分前向操作
functors_.forward_per_gpu(embedding_data_.embedding_params_.get_batch_size(is_train),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size, 0, is_train,
embedding_data_.get_row_offsets_tensors(is_train)[i],
embedding_data_.get_value_tensors(is_train)[i],
*embedding_data_.get_nnz_array(is_train)[i], *hash_tables_[i],
hash_table_value_tensors_[i], hash_value_index_tensors_[i],
embedding_feature_tensors_[i],
embedding_data_.get_local_gpu(i).get_stream());
}
// 省略后面代码
// do reduce scatter
// scale for combiner=mean after reduction
// do average
}
return;
}
5.3.2 引用
我们仔细看看 EmbeddingData 的一些成员函数,发现他们都返回了引用。这就是关键,这些成员函数可以修改 EmbeddingData的内部成员变量,比如:get_row_offsets_tensors返回了一个引用。
Tensors2<TypeKey>& get_row_offsets_tensors(bool is_train) {
if (is_train) {
return train_row_offsets_tensors_;
} else {
return evaluate_row_offsets_tensors_;
}
}
类似的,比如get_output_tensors,get_input_keys,get_row_offsets_tensors,get_value_tensors,get_nnz_array 都返回引用,这说明 EmbeddingData 大部分成员变量都是可以被引用来修改的。
5.3.3 修改
具体配置就是在 filter_keys_per_gpu 这里进行,就是利用 train_keys 进行配置其他成员变量,具体方法涉及到CUDA一些集合运算,有兴趣的读者可以自行研究。
template <typename TypeHashKey, typename TypeEmbeddingComp>
void DistributedSlotSparseEmbeddingHash<TypeHashKey, TypeEmbeddingComp>::filter_keys_per_gpu(
bool is_train, size_t id, size_t global_id, size_t global_num) {
const SparseTensor<TypeHashKey> &all_gather_key = embedding_data_.get_input_keys(is_train)[id];
// 这里拿到了get_row_offsets_tensors
Tensor2<TypeHashKey> rowoffset_tensor = embedding_data_.get_row_offsets_tensors(is_train)[id];
Tensor2<TypeHashKey> value_tensor = embedding_data_.get_value_tensors(is_train)[id];
std::shared_ptr<size_t> nnz_ptr = embedding_data_.get_nnz_array(is_train)[id];
auto &filter_keys_storage = filter_keys_storage_[id];
auto &stream = embedding_data_.get_local_gpu(id).get_stream();
if (all_gather_key.get_dimensions().size() != 2) {
CK_THROW_(Error_t::WrongInput, "distributed embedding all gather key dimension != 2");
}
size_t batch_size = embedding_data_.embedding_params_.get_batch_size(is_train);
size_t slot_num = (all_gather_key.rowoffset_count() - 1) / batch_size;
size_t rowoffset_num = batch_size * slot_num + 1;
size_t rowoffset_num_without_zero = rowoffset_num - 1;
if (rowoffset_tensor.get_num_elements() != rowoffset_num) {
std::cout << rowoffset_tensor.get_num_elements() << " " << rowoffset_num << std::endl;
CK_THROW_(Error_t::WrongInput, "filter rowoffset size not match.");
}
// select value
{
distributed_embedding_kernels::HashOp<TypeHashKey> select_op{global_id, global_num};
size_t size_in_bytes = filter_keys_storage.temp_value_select_storage.get_size_in_bytes();
cub::DeviceSelect::If(filter_keys_storage.temp_value_select_storage.get_ptr(), size_in_bytes,
all_gather_key.get_value_ptr(), value_tensor.get_ptr(),
filter_keys_storage.value_select_num.get_ptr(), all_gather_key.nnz(),
select_op, stream);
}
// select rowoffset
{
cudaMemsetAsync(filter_keys_storage.rowoffset_select.get_ptr(), 0,
filter_keys_storage.rowoffset_select.get_size_in_bytes(), stream);
{
constexpr int block_size = 512;
int grid_size = (rowoffset_num_without_zero - 1) / block_size + 1;
distributed_embedding_kernels::select_rowoffset<<<grid_size, block_size, 0, stream>>>(
all_gather_key.get_rowoffset_ptr(), rowoffset_num_without_zero,
all_gather_key.get_value_ptr(), filter_keys_storage.rowoffset_select.get_ptr(), global_id,
global_num);
}
{
// 这里会进行修改设置rowoffset_tensor
size_t size_in_bytes =
filter_keys_storage.temp_rowoffset_select_scan_storage.get_size_in_bytes();
cub::DeviceScan::InclusiveSum(
filter_keys_storage.temp_rowoffset_select_scan_storage.get_ptr(), size_in_bytes,
filter_keys_storage.rowoffset_select.get_ptr(), rowoffset_tensor.get_ptr(), rowoffset_num,
stream);
}
// select nnz
cudaMemcpyAsync(nnz_ptr.get(), filter_keys_storage.value_select_num.get_ptr(), sizeof(size_t),
cudaMemcpyDeviceToHost, stream);
}
}
于是,在进行具体前向操作之前,会把EmbeddingData内部都进行配置,分别指向GPU之中的相应数据。
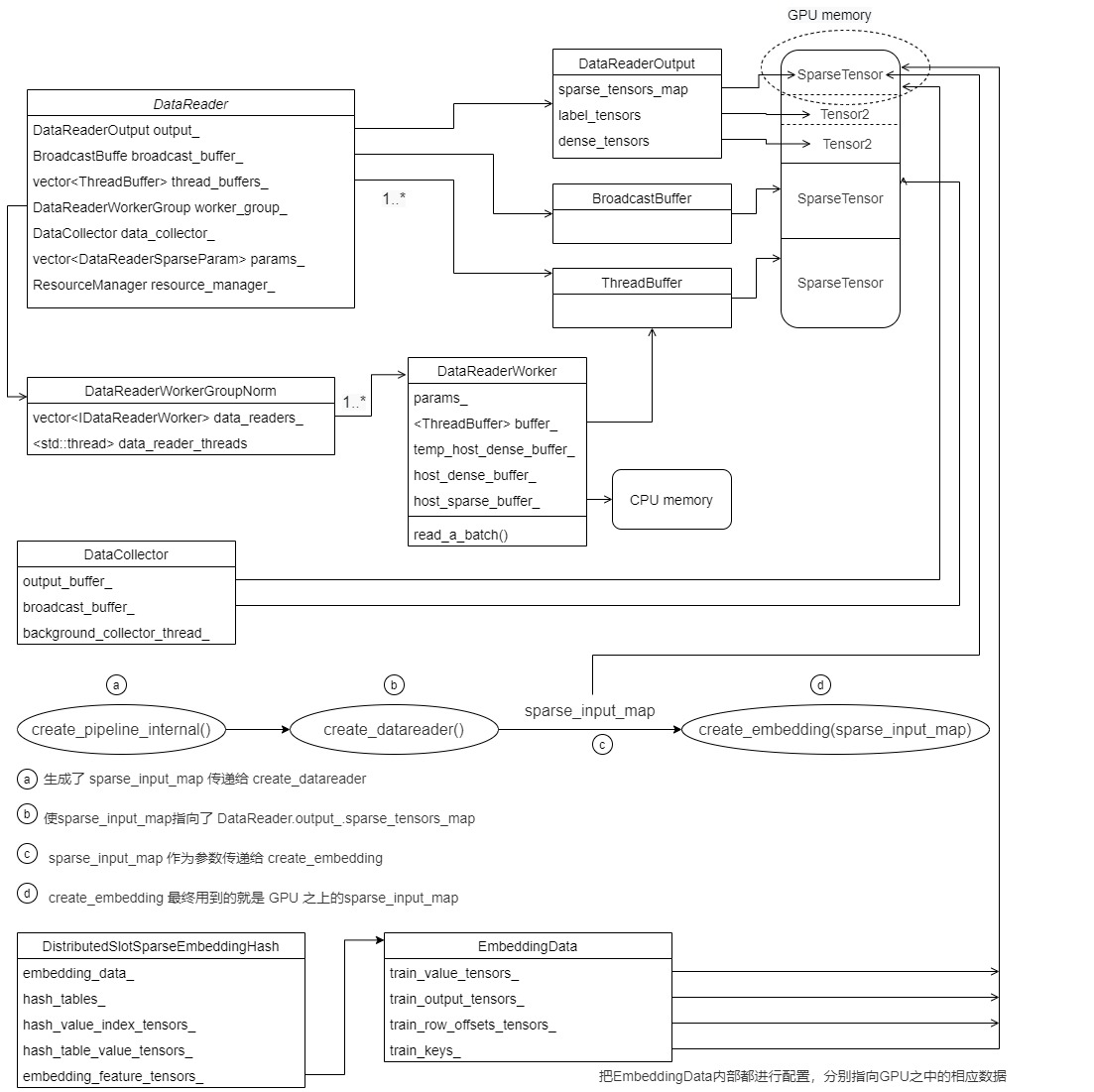
0x06 优化器
DistributedSlotSparseEmbeddingHash 内部也存在一些优化器。
std::vector<EmbeddingOptimizer<TypeHashKey, TypeEmbeddingComp>> embedding_optimizers_;
我们接下来分析一下。
6.1 定义
优化器定义如下:
template <typename TypeHashKey, typename TypeEmbeddingComp>
class EmbeddingOptimizer {
Tensor2<void> temp_storage_encode_tensors_;
Tensor2<void> temp_storage_sort_tensors_; /**< The temp memory for the CUB lib sorting
API in update_params(). */
Tensor2<void> temp_storage_scan_tensors_; /**< The temp memory for the CUB lib scaning API
in update_params(). */
Tensor2<TypeHashKey> sample_id_tensors_; /**< The temp memory to store the sample ids of hash
table value in update_params(). */
Tensor2<TypeHashKey> sample_id_sort_tensors_; /**< The temp memory to store the sorted sample
ids of hash table value in update_params(). */
Tensor2<size_t> hash_value_index_sort_tensors_; /**< The temp memory to store the sorted hash
table value indexes in update_params(). */
Tensor2<size_t> hash_value_index_sort_unique_tensors_;
Tensor2<uint32_t> hash_value_index_count_tensors_;
Tensor2<uint32_t> new_hash_value_flag_tensors_;
Tensor2<uint32_t> hash_value_flag_sumed_tensors_;
Tensor2<uint32_t>
hash_value_index_count_offset_tensors_; /**< The temp memory to store the offset of each count
of hash table value indexes in update_params(). */
Tensor2<uint32_t> hash_value_index_count_counter_tensors_; /**< The temp memory to store the
counter of the count of hash table
value indexes in update_params(). */
SparseEmbeddingHashParams& param;
public:
OptimizerTensor<TypeEmbeddingComp> opt_tensors_;
EmbeddingOptimizer(size_t max_vocabulary_size_per_gpu_, SparseEmbeddingHashParams& param,
const std::shared_ptr<GeneralBuffer2<CudaAllocator>>& buf);
void initialize(const GPUResource& local_gpu);
void reset(GPUResource const& local_gpu) { initialize(local_gpu); }
void update(size_t batch_size, size_t slot_num, size_t embedding_vec_size,
size_t max_vocabulary_size_per_gpu, size_t nnz,
const Tensor2<TypeHashKey>& row_offset, Tensor2<size_t>& hash_value_index,
const Tensor2<TypeEmbeddingComp>& wgrad, Tensor2<float>& hash_table_value,
size_t sm_count, cudaStream_t stream);
};
6.2 更新
其内部主要是通过 opt_adagrad_kernel 进行更新。
template <typename TypeHashKey, typename TypeEmbeddingComp>
void EmbeddingOptimizer<TypeHashKey, TypeEmbeddingComp>::update(
size_t batch_size, size_t slot_num, size_t embedding_vec_size,
size_t max_vocabulary_size_per_gpu, size_t nnz, const Tensor2<TypeHashKey> &row_offset,
Tensor2<size_t> &hash_value_index, const Tensor2<TypeEmbeddingComp> &wgrad,
Tensor2<float> &hash_table_value, size_t sm_count, cudaStream_t stream) {
OptimizerTensor<TypeEmbeddingComp> &opt_tensor = opt_tensors_;
OptParams &opt_params = param.opt_params;
Tensor2<TypeHashKey> &sample_id = sample_id_tensors_;
Tensor2<TypeHashKey> &sample_id_sort = sample_id_sort_tensors_;
Tensor2<size_t> &hash_value_index_sort = hash_value_index_sort_tensors_;
Tensor2<uint32_t> &hash_value_index_count_offset = hash_value_index_count_offset_tensors_;
Tensor2<uint32_t> &new_hash_value_flag = new_hash_value_flag_tensors_;
Tensor2<uint32_t> &hash_value_flag_sumed = hash_value_flag_sumed_tensors_;
Tensor2<uint32_t> &hash_value_index_count_counter = hash_value_index_count_counter_tensors_;
Tensor2<void> &temp_storage_sort = temp_storage_sort_tensors_;
Tensor2<void> &temp_storage_scan = temp_storage_scan_tensors_;
size_t block_size, grid_size;
try {
// step1: expand sample IDs
block_size = 64;
grid_size = (batch_size * slot_num - 1) / block_size + 1;
sample_id_expand_kernel<<<grid_size, block_size, 0, stream>>>(
batch_size, slot_num, row_offset.get_ptr(), sample_id.get_ptr());
if (opt_params.optimizer == Optimizer_t::SGD &&
opt_params.hyperparams.sgd.atomic_update) { // for SGD, do atomic update
const size_t block_size = embedding_vec_size;
const size_t grid_size = min(max(1ul, nnz), sm_count * 32);
float lr_scale = opt_params.lr / opt_params.scaler;
opt_sgd_atomic_kernel<<<grid_size, block_size, 0, stream>>>(
nnz, embedding_vec_size, lr_scale, hash_value_index.get_ptr(), sample_id.get_ptr(),
wgrad.get_ptr(), hash_table_value.get_ptr());
} else {
// step3: sort by hash_value_index
int end_bit = static_cast<int>(log2(static_cast<float>(max_vocabulary_size_per_gpu))) + 1;
size_t temp_storage_sort_size = temp_storage_sort.get_size_in_bytes();
CK_CUDA_THROW_(cub::DeviceRadixSort::SortPairs(
temp_storage_sort.get_ptr(), temp_storage_sort_size, hash_value_index.get_ptr(),
hash_value_index_sort.get_ptr(), sample_id.get_ptr(), sample_id_sort.get_ptr(), nnz, 0,
end_bit, stream, false));
// step4: count the number for each unduplicated hash_value_index
CK_CUDA_THROW_(
cudaMemsetAsync(hash_value_index_count_counter.get_ptr(), 0, sizeof(uint32_t), stream));
constexpr size_t max_grid_size = 384;
block_size = 256;
grid_size = min(max_grid_size, (nnz - 1) / block_size + 1);
value_count_kernel_1<<<grid_size, block_size, 0, stream>>>(
nnz, hash_value_index_sort.get_ptr(), new_hash_value_flag.get_ptr());
// a pinned memroy
CK_CUDA_THROW_(cudaMemcpyAsync(&hash_hash_value_index_count_num,
hash_value_index_count_counter.get_ptr(), sizeof(uint32_t),
cudaMemcpyDeviceToHost, stream));
// step5: use optimizer method to compute deltaw and update the parameters
block_size = embedding_vec_size;
grid_size = max(1, hash_hash_value_index_count_num);
switch (opt_params.update_type) {
case Update_t::Global: {
switch (opt_params.optimizer) {
case Optimizer_t::Adam: {
}
case Optimizer_t::AdaGrad: {
opt_adagrad_kernel<<<grid_size, block_size, 0, stream>>>(
hash_hash_value_index_count_num, embedding_vec_size, opt_params.lr,
opt_params.hyperparams.adagrad, opt_tensor.opt_accm_tensors_.get_ptr(),
sample_id_sort.get_ptr(), hash_value_index_sort.get_ptr(),
hash_value_index_count_offset.get_ptr(), wgrad.get_ptr(),
hash_table_value.get_ptr(), opt_params.scaler);
break;
}
case Optimizer_t::MomentumSGD:
case Optimizer_t::Nesterov:
case Optimizer_t::SGD:
default:
CK_THROW_(Error_t::WrongInput, "Error: Invalid opitimizer type");
} // switch (optimizer)
break;
}
case Update_t::Local: {
switch (opt_params.optimizer) {
case Optimizer_t::Adam: {
}
case Optimizer_t::AdaGrad: {
opt_adagrad_kernel<<<grid_size, block_size, 0, stream>>>(
hash_hash_value_index_count_num, embedding_vec_size, opt_params.lr,
opt_params.hyperparams.adagrad, opt_tensor.opt_accm_tensors_.get_ptr(),
sample_id_sort.get_ptr(), hash_value_index_sort.get_ptr(),
hash_value_index_count_offset.get_ptr(), wgrad.get_ptr(),
hash_table_value.get_ptr(), opt_params.scaler);
break;
}
case Optimizer_t::MomentumSGD:
case Optimizer_t::Nesterov:
case Optimizer_t::SGD:
default:
CK_THROW_(Error_t::WrongInput, "Error: Invalid opitimizer type");
} // switch (optimizer)
break;
}
case Update_t::LazyGlobal: {
switch (opt_params.optimizer) {
case Optimizer_t::Adam: {
}
case Optimizer_t::AdaGrad:
case Optimizer_t::MomentumSGD:
case Optimizer_t::Nesterov:
case Optimizer_t::SGD: {
CK_THROW_(Error_t::WrongInput,
"Error: lazy global update is only implemented for Adam");
break;
}
default:
CK_THROW_(Error_t::WrongInput, "Error: Invalid opitimizer type");
}
break;
}
default:
CK_THROW_(Error_t::WrongInput, "Error: Invalid update type");
} // switch (update type)
}
#ifndef NDEBUG
cudaDeviceSynchronize();
CK_CUDA_THROW_(cudaGetLastError());
#endif
} catch (const std::runtime_error &rt_err) {
std::cerr << rt_err.what() << std::endl;
throw;
}
return;
}
其本质就是更新 hash_table_value,也就是嵌入层的权重。具体我们后文会结合反向传播进行分析。
// Local update for the Adagrad optimizer: compute the gradients and update the accumulators and the
// weights
template <typename TypeKey, typename TypeEmbeddingComp>
__global__ void opt_adagrad_kernel(uint32_t hash_value_index_count_num, int embedding_vec_size,
float lr, const AdaGradParams adagrad,
TypeEmbeddingComp *accum_ptr, const TypeKey *sample_id,
const size_t *hash_value_index_sort,
const uint32_t *hash_value_index_count_offset,
const TypeEmbeddingComp *wgrad, float *hash_table_value,
float scaler) {
int bid = blockIdx.x;
int tid = threadIdx.x;
if (tid < embedding_vec_size && bid < hash_value_index_count_num) {
uint32_t offset = hash_value_index_count_offset[bid];
float gi = accumulate_gradients(embedding_vec_size, sample_id, hash_value_index_count_offset,
wgrad, scaler, offset, bid, tid);
size_t row_index = hash_value_index_sort[offset];
size_t feature_index = row_index * embedding_vec_size + tid;
float accum =
TypeConvertFunc<float, TypeEmbeddingComp>::convert(accum_ptr[feature_index]) + gi * gi;
accum_ptr[feature_index] = TypeConvertFunc<TypeEmbeddingComp, float>::convert(accum);
float weight_diff = -lr * gi / (sqrtf(accum) + adagrad.epsilon);
hash_table_value[feature_index] += weight_diff; // 更新权重
}
}
至此,Distributed hash表 基本概念介绍完成,我们接下来介绍前向传播,敬请期待。
0xFF 参考
https://web.eecs.umich.edu/~justincj/teaching/eecs442/notes/linear-backprop.html
稀疏矩阵存储格式总结+存储效率对比:COO,CSR,DIA,ELL,HYB
求通俗讲解下tensorflow的embedding_lookup接口的意思?
【技术干货】聊聊在大厂推荐场景中embedding都是怎么做的
ctr预估算法对于序列特征embedding可否做拼接,输入MLP?与pooling
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/operations.html