Gin 简介#
Gin is a HTTP web framework written in Go (Golang). It features a Martini-like API with much better performance -- up to 40 times faster. If you need smashing performance, get yourself some Gin.
-- 这是来自 github 上 Gin 的简介
Gin 是一个用 Go 写的 HTTP web 框架,它是一个类似于 Martini 框架,但是 Gin 用了 httprouter 这个路由,它比 martini 快了 40 倍。如果你追求高性能,那么 Gin 适合。
当然 Gin 还有其它的一些特性:
- 路由性能高
- 支持中间件
- 路由组
- JSON 验证
- 错误管理
- 可扩展性
Gin 文档:
Gin 快速入门 Demo#
我以前也写过一些关于 Gin 应用入门的 demo,在这里。
Gin v1.7.0 , Go 1.16.11
官方的一个 quickstart:
package main
import "github.com/gin-gonic/gin"
// https://gin-gonic.com/docs/quickstart/
func main() {
r := gin.Default()
r.GET("/ping", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "pong",
})
})
r.Run() // 监听在默认端口8080, 0.0.0.0:8080
}
上面就完成了一个可运行的 Gin 程序了。
分析上面的 Demo#
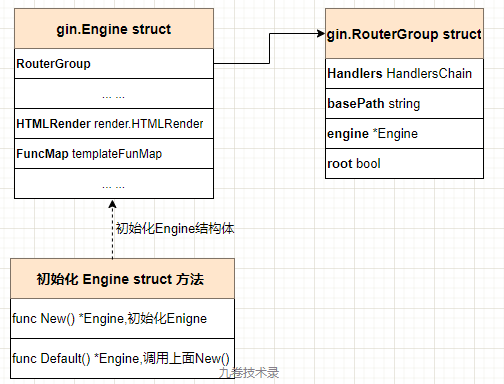
第一步:gin.Default()#
Engine struct 是 Gin 框架里最重要的一个结构体,包含了 Gin 框架要使用的许多字段,比如路由(组),配置选项,HTML等等。
New() 和 Default() 这两个函数都是初始化 Engine 结构体。
RouterGroup struct 是 Gin 路由相关的结构体,路由相关操作都与这个结构体有关。
- A. Default() 函数
这个函数在 gin.go/Default(),它实例化一个 Engine,调用 New() 函数:
// https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L180
// 实例化 Engine,默认带上 Logger 和 Recovery 2 个中间件,它是调用 New()
// Default returns an Engine instance with the Logger and Recovery middleware already attached.
func Default() *Engine {
debugPrintWARNINGDefault() // debug 程序
engine := New() // 新建 Engine 实例,原来 Default() 函数是最终是调用 New() 新建 engine 实例
engine.Use(Logger(), Recovery()) // 使用一些中间件
return engine
}
Engine 又是什么?
- B. Engine struct 是什么和 New() 函数:
Engine 是一个 struct 类型,里面包含了很多字段,下面代码只显示主要字段:
// https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L57
// gin 中最大的一个结构体,存储了路由,设置选项和中间件
// 调用 New() 或 Default() 方法实例化 Engine struct
// Engine is the framework's instance, it contains the muxer, middleware and configuration settings.
// Create an instance of Engine, by using New() or Default()
type Engine struct {
RouterGroup // 组路由(路由相关字段)
... ...
HTMLRender render.HTMLRender
FuncMap template.FuncMap
allNoRoute HandlersChain
allNoMethod HandlersChain
noRoute HandlersChain
noMethod HandlersChain
pool sync.Pool
trees methodTrees
maxParams uint16
trustedCIDRs []*net.IPNet
}
type HandlersChain []HandlerFunc
gin.go/New() 实例化 gin.go/Engine struct,简化的代码如下:
这个 New 函数,就是初始化 Engine struct,
// https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L148
// 初始化 Engine,实例化一个 engine
// New returns a new blank Engine instance without any middleware attached.
// By default the configuration is:
// - RedirectTrailingSlash: true
// - RedirectFixedPath: false
// - HandleMethodNotAllowed: false
// - ForwardedByClientIP: true
// - UseRawPath: false
// - UnescapePathValues: true
func New() *Engine {
debugPrintWARNINGNew()
engine := &Engine{
RouterGroup: RouterGroup{
Handlers: nil,
basePath: "/",
root: true,
},
FuncMap: template.FuncMap{},
... ...
trees: make(methodTrees, 0, 9),
delims: render.Delims{Left: "{{", Right: "}}"},
secureJSONPrefix: "while(1);",
}
engine.RouterGroup.engine = engine // RouterGroup 里的 engine 在这里赋值,下面分析 RouterGroup 结构体
engine.pool.New = func() interface{} {
return engine.allocateContext()
}
return engine
}
- C. RouterGroup
gin.go/Engine struct 里的 routergroup.go/RouterGroup struct 这个与路由有关的字段,它也是一个结构体,代码如下:
//https://github.com/gin-gonic/gin/blob/v1.7.0/routergroup.go#L41
// 配置存储路由
// 路由后的处理函数handlers(中间件)
// RouterGroup is used internally to configure router, a RouterGroup is associated with
// a prefix and an array of handlers (middleware).
type RouterGroup struct {
Handlers HandlersChain // 存储处理路由
basePath string
engine *Engine // engine
root bool
}
// https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L34
type HandlersChain []HandlerFunc
https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L31
// HandlerFunc defines the handler used by gin middleware as return value.
type HandlerFunc func(*Context)
第二步:r.GET()#
r.GET() 就是路由注册和路由处理handler。
routergroup.go/GET(),handle() -> engine.go/addRoute()
// https://github.com/gin-gonic/gin/blob/v1.7.0/routergroup.go#L102
// GET is a shortcut for router.Handle("GET", path, handle).
func (group *RouterGroup) GET(relativePath string, handlers ...HandlerFunc) IRoutes {
return group.handle(http.MethodGet, relativePath, handlers)
}
handle 处理函数:
// https://github.com/gin-gonic/gin/blob/v1.7.0/routergroup.go#L72
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath)
handlers = group.combineHandlers(handlers)
group.engine.addRoute(httpMethod, absolutePath, handlers)
return group.returnObj()
}
combineHandlers() 函数把所有路由处理handler合并起来。
addRoute() 这个函数把方法,URI,处理handler 加入进来, 这个函数主要代码如下:
// https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L276
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
... ...
// 每一个http method(GET, POST, PUT...)都构建一颗基数树
root := engine.trees.get(method) // 获取方法对应的基数树
if root == nil { // 如果没有就创建一颗新树
root = new(node) // 创建基数树的根节点
root.fullPath = "/"
engine.trees = append(engine.trees, methodTree{method: method, root: root})
}
root.addRoute(path, handlers)
... ...
}
上面这个root.addRoute函数在 tree.go 里,而这里的代码多数来自 httprouter 这个路由库。
gin 里号称 40 times faster。
到底是怎么做到的?
httprouter 路由数据结构Radix Tree#
httprouter文档#
在 httprouter 文档里,有这样一句话:
The router relies on a tree structure which makes heavy use of common prefixes, it is basically a compact prefix tree (or just Radix tree)
用了 prefix tree 前缀树 或 Radix tree 基数树。与 Trie 字典树有关。
Radix Tree 叫基数特里树或压缩前缀树,是一种更节省空间的 Trie 树。
Trie 字典树#
Trie,被称为前缀树或字典树,是一种有序树,其中的键通常是单词和字符串,所以又有人叫它单词查找树。
它是一颗多叉树,即每个节点分支数量可能为多个,根节点不包含字符串。
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
除根节点外,每一个节点只包含一个字符。
每个节点的所有子节点包含的字符都不相同。
优点:利用字符串公共前缀来减少查询时间,减少无谓的字符串比较
Trie 树图示:
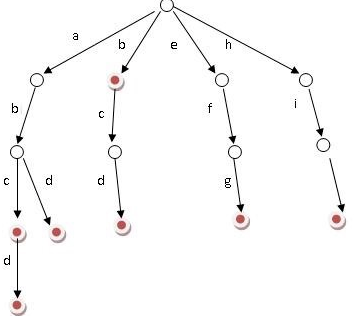
(为 b,abc,abd,bcd,abcd,efg,hii 这7个单词创建的trie树, https://baike.baidu.com/item/字典树/9825209)
trie 树的代码实现:https://baike.baidu.com/item/字典树/9825209#5
Radix Tree基数树#
认识基数树:#
Radix Tree,基数特里树或压缩前缀树,是一种更节省空间的 Trie 树。它对 trie 树进行了压缩。
看看是咋压缩的,假如有下面一组数据 key-val 集合:
{
"def": "redisio",
"dcig":"mysqlio",
"dfo":"linux",
"dfks":"tdb",
"dfkz":"dogdb",
}
用上面数据中的 key 构造一颗 trie 树:
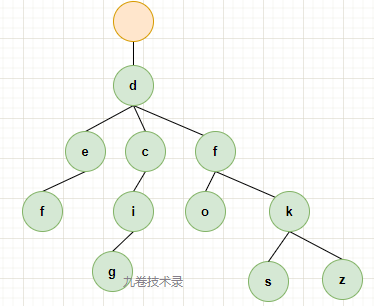
现在压缩 trie 树(Compressed Trie Tree)中的唯一子节点,就可以构建一颗 radix tree 基数树。
父节点下第一级子节点数小于 2 的都可以进行压缩,把子节点合并到父节点上,把上图 <2 子节点数压缩,变成如下图:
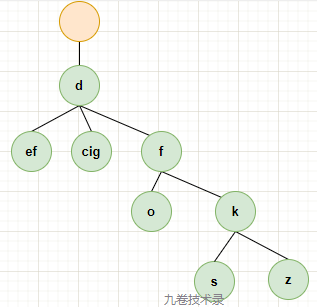
把 c,f 和 c,i,g 压缩在一起,这样就节省了一些空间。压缩之后,分支高度也降低了。
这个就是对 trie tree 进行压缩变成 radix tree。
在另外看一张出现次数比较多的 Radix Tree 的图:
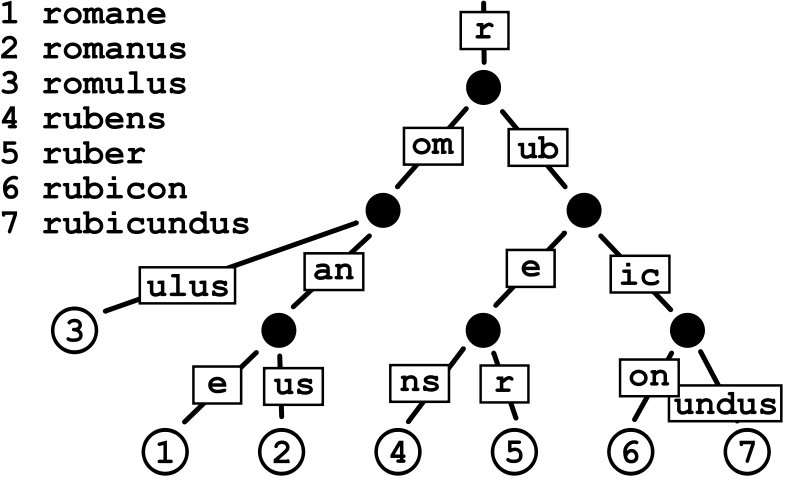
(图Radix_tree 来自:https://en.wikipedia.org/wiki/Radix_tree)
基数树唯一子节点都与其父节点合并,边沿(edges)既可以存储多个元素序列也可以存储单个元素。比如上图的 r, om,an,e。
基数树的图最下面的数字对应上图的排序数字,比如  ,就是 ruber 字符,
,就是 ruber 字符,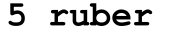
。
什么时候使用基数树合适:#
字符串元素个数不是很多,且有很多相同前缀时适合使用基数树这种数据结构。
基数树的应用场景:#
httprouter 中的路由器。
使用 radix tree 来构建 key 为字符串的关联数组。
很多构建 IP 路由也用到了 radix tree,比如 linux 中,因为 ip 通常有大量相同前缀。
Redis 集群模式下存储 slot 对应的所有 key 信息,也用到了 radix tree。文件 rax.h/rax.c 。
radix tree 在倒排索引方面使用也比较广。
httprouter中的基数树#
node 节点定义:#
// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L46
type node struct {
path string // 节点对应的字符串路径
wildChild bool // 是否为参数节点,如果是参数节点,那么 wildChild=true
nType nodeType // 节点类型,有几个枚举值可以看下面nodeType的定义
maxParams uint8 // 节点路径最大参数个数
priority uint32 // 节点权重,子节点的handler总数
indices string // 节点与子节点的分裂的第一个字符
children []*node // 子节点
handle Handle // http请求处理方法
}
节点类型 nodeType 定义:
// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L39
// 节点类型
const (
static nodeType = iota // default, 静态节点,普通匹配(/user)
root // 根节点
param // 参数节点(/user/:id)
catchAll // 通用匹配,匹配任意参数(*user)
)
indices 这个字段是缓存下一子节点的第一个字符。
比如路由: r.GET("/user/one"), r.GET("/user/two"), indices 字段缓存的就是下一节点的第一个字符,即 "ot" 2个字符。这个就是对搜索匹配进行了优化。
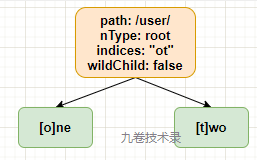
如果 wildChild=true,参数节点时,indices=""。
addRoute 添加路由:#
addRoute(),添加路由函数,这个函数代码比较多,
分为空树和非空树时的插入。
空树时直接插入:
n.insertChild(numParams, path, fullPath, handlers)
n.nType = root // 节点 nType 是 root 类型
非空树的处理:
先是判断树非空(non-empty tree),接着下面是一个 for 循环,下面所有的处理都在 for 循环面。
-
更新 maxParams 字段
-
寻找共同的最长前缀字符
// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L100 // Find the longest common prefix. 寻找字符相同前缀,用 i 数字表示 // This also implies that the common prefix contains no ':' or '*',表示没有包含特殊匹配 : 或 * // since the existing key can't contain those chars. i := 0 max := min(len(path), len(n.path)) for i < max && path[i] == n.path[i] { i++ } -
split edge 开始分裂节点
比如第一个路由 path 是 user,新增一个路由 uber,u 就是它们共同的部分(common prefix),那么就把 u 作为父节点,剩下的 ser,ber 作为它的子节点
// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L107 // Split edge if i < len(n.path) { child := node{ path: n.path[i:], // 上面已经判断了匹配的字符共同部分用i表示,[i:] 从i开始计算取字符剩下不同部分作为子节点 wildChild: n.wildChild, // 节点类型 nType: static, // 静态节点普通匹配 indices: n.indices, children: n.children, handle: n.handle, priority: n.priority - 1, // 节点降级 } // Update maxParams (max of all children) for i := range child.children { if child.children[i].maxParams > child.maxParams { child.maxParams = child.children[i].maxParams } } n.children = []*node{&child} // 当前节点的子节点修改为上面刚刚分裂的节点 // []byte for proper unicode char conversion, see #65 n.indices = string([]byte{n.path[i]}) n.path = path[:i] n.handle = nil n.wildChild = false } -
i<len(path),将新节点作为子节点插入
https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L137
- 4.1 n.wildChild = true,对特殊参数节点的处理 ,: 和 *
// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L133
if n.wildChild {
n = n.children[0]
n.priority++
// Update maxParams of the child node
if numParams > n.maxParams {
n.maxParams = numParams
}
numParams--
// Check if the wildcard matches
if len(path) >= len(n.path) && n.path == path[:len(n.path)] &&
// Adding a child to a catchAll is not possible
n.nType != catchAll &&
// Check for longer wildcard, e.g. :name and :names
(len(n.path) >= len(path) || path[len(n.path)] == '/') {
continue walk
} else {
// Wildcard conflict
var pathSeg string
... ...
}
}
- 4.2 开始处理 indices
// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L171
c := path[0] // 获取第一个字符
// slash after param,处理nType为参数的情况
if n.nType == param && c == '/' && len(n.children) == 1
// Check if a child with the next path byte exists
// 判断子节点是否和当前path匹配,用indices字段来判断
// 比如 u 的子节点为 ser 和 ber,indices 为 u,如果新插入路由 ubb,那么就与子节点 ber 有共同部分 b,继续分裂 ber 节点
for i := 0; i < len(n.indices); i++ {
if c == n.indices[i] {
i = n.incrementChildPrio(i)
n = n.children[i]
continue walk
}
}
// Otherwise insert it
// indices 不是参数和通配匹配
if c != ':' && c != '*' {
// []byte for proper unicode char conversion, see #65
n.indices += string([]byte{c})
child := &node{
maxParams: numParams,
}
// 新增子节点
n.children = append(n.children, child)
n.incrementChildPrio(len(n.indices) - 1)
n = child
}
n.insertChild(numParams, path, fullPath, handle)
-
i=len(path)路径相同
如果已经有handler处理函数就报错,没有就赋值handler
insertChild 插入子节点:#
getValue 路径查找:#
上面2个函数可以独自分析下 - -!
可视化radix tree操作#
https://www.cs.usfca.edu/~galles/visualization/RadixTree.html
radix tree 的算法操作可以看这里,动态展示。
参考#
- https://github.com/gin-gonic/gin/tree/v1.7.0 gin 源码
- https://github.com/julienschmidt/httprouter httprouter地址
- https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go httprouter tree源码
- https://gin-gonic.com/docs/quickstart/ gin doc
- https://www.cs.usfca.edu/~galles/visualization/RadixTree.html radix tree算法步骤可视化
- https://baike.baidu.com/item/字典树/9825209 百科基数树
- 《算法》 5.2 单词查找树 trie tree 作者: Robert Sedgewick / Kevin Wayne
- https://en.wikipedia.org/wiki/Trie 维基trie树(en)
- https://en.wikipedia.org/wiki/Radix_tree 维基radix tree(en)
- https://zh.wikipedia.org/wiki/基数树 维基基数树(zh)
- https://github.com/redis/redis/blob/6.0.14/src/rax.c redis 中 radix tree 使用
- https://github.com/redis/redis/blob/6.0.14/src/rax.h redis 中 radix tree 使用