问 100 个面试者会哪些设计模式,至少 99 个都会提工厂模式。这说明工厂模式确实是一般开发人员最常遇到的设计模式之一,另外也说明它是最直观最容易理解的设计模式之一(无论是从概念上还是实现上)。
不过,如果继续往下追问,比如工厂模式用来解决什么痛点?怎么解决的?它有什么缺点?什么时候不该用工厂模式?并非每个人都能说得明白的。
软件设计的复杂性
软件的本质是人类通过指令指导机器来处理人类世界的事务,因而人类世界的复杂性必然会反映到软件上。
高中物理告诉我们,运动是绝对的,静止是相对的,“唯一不变的就是变化本身”。正是事物的运动(动态性)造成了复杂性——用更容易听得懂的话讲叫“未来的不确定性”。需求总是无休止地改变,没有哪个软件是一成不变的。
运动的自然结果是熵增——就好像你家客厅总是越来越乱一样,随着时间的推移,软件系统不可避免地逐渐趋向混乱:随着旧逻辑的变动和新逻辑的增加(以及既有 bug 的“修复”),系统逻辑越来越复杂且难以理解,bug 越来越多,修改功能越来越困难。
人们一个直观但错误的认知是:通过修复 bug 能逐渐减少系统的 bug,最终将 bug 归零——除非该系统自发布后不用做任何迭代,否则无论你键盘敲多快都赶不上 bug 的增长速度(这一点在上层业务系统中表现得尤为明显)。
程序员们应对软件系统熵增的手段主要是重构和使用设计模式。
重构是在未来对系统进行重新构建,以消除或减少系统的混乱,其依据是人们在未来会比过去对系统/业务有更加深刻的认知,另一方面过去的设计已经达到其承载变化能力的极限——实践中重构(特别是大规模的)往往发生在系统崩溃边缘。
设计模式是在现在对系统进行预构建,以应对未来的复杂性(变化)。所谓设计模式,就是根据过往经验,将系统设计中共通的东西抽取出来,加以标准化(形成模式),以追求系统设计上的相对静止性(稳定性),以不变应对未来的变化(不确定性)。
设计模式解决复杂性的主要手段是抽象和隔离。
三种工厂
任何设计模式都是用来解决软件设计的复杂性问题,追求设计上的稳定性。工厂模式属于创建者模式之一(其它的创建者模式如单例、原型、建造者模式),用来解决对象创建的复杂性。
什么样的对象创建具有复杂性?
- 只需要一句 new 以及传几个简单参数的基本不存在创建复杂性,也就用不上工厂模式;
- 对象创建具有多态性:如需要根据配置创建不同的子类型对象,创建代码中有多个 if else 的;
- 对象创建过程比较复杂:虽然不需要创建不同的子类对象,但对象创建本身较复杂,必须需要读取配置文件、获取远程数据等;
在进一步讨论之前,我们先简单提下工厂模式的三种形式:简单工厂、工厂方法和抽象工厂(和 GoF 的划分有点不一样)。
简单工厂:在目标类中创建一个静态方法用于创建目标类对象,或者进一步,将该静态方法抽离成一个单独的工厂类;
工厂方法:对简单工厂的升级。定义一个工厂接口,利用多态,每个工厂实现类返回目标类/接口的一种特定子类实例。工厂方法解决了简单工厂可能过于复杂的问题,使得工厂本身更符合开闭原则和单一职责原则;
抽象工厂:对工厂方法的升级。它是用来解决目标实例本身的多维复杂性,防止工厂类随着目标类数量一起爆炸增长。工厂方法是一个工厂类只负责创建一种目标实例,而抽象工厂是一个工厂可以创建多种目标实例。
单听理论有点懵,大致只需要知道从工厂自身的复杂性以及用来解决问题的复杂性来说,简单工厂 < 工厂方法 < 抽象工厂(前者是后者的特例,后者是前者的升级)——注意,这里提到了两个复杂性(工厂自身复杂性和它需要解决的问题复杂性),这也预示着使用工厂的原则:尽可能使用简单工具解决问题,除非问题真的很复杂,简单工具不好解决。
接下来我们看看工厂模式是如何通过抽象和隔离来解决对象创建的复杂性的。
简单工厂
假如我们要给加油站开发个在线交易系统,车主可以通过该系统购买燃油、便利店商品,还可以购买虚拟商品(如优惠券)。其中下单环节包含三个类(简化版。为方便讨论,假设一个订单只能购买一种商品):交易类 Transaction、订单类 Order 和 商品类 Goods。交易类 Transaction 中会创建订单 Order,而 Order 依赖商品 Goods:

假设 Goods 的创建很复杂,需要组合多个相关对象,还要读取外部信息(如获取商品基本信息、库存信息)。
Order 依赖 Goods 的实现方式有两种:
- 在 Order 内部直接创建 Goods(外部传入 goodsId);
- 通过构造函数将 Goods 对象注入进去。
Order 内部创建 Goods(本文使用 PHP 实现伪代码,读者自行脑补成自己熟悉的语言即可):
class Order
{
private $goods;
public function __construct($goodsId, ...)
{
// 这里是一大坨创建 Goods 的代码
...
$this->goods = $goods;
}
}
这里的构造函数包含了大段的创建代码,不符合最佳实践,因而一般我们会抽取一个单独的方法来创建 Goods:
class Order
{
private $goods;
public function __construct($goodsId, ...)
{
$this->goods = self::createGoods($goodsId);
}
private static function createGoods($goodsId): Goods
{
// 一大坨创建 Goods 的代码
...
return $goods;
}
}
稍微好点了,但这里至少有三个问题:
- Order 承担了创建 Goods 的职责(而且做的事情还挺复杂的,以后可能还要修改的),违背了单一职责原则;
- Order 不得不去了解 Goods 的构成细节,违背了迪米特法则,破坏了封装性;
- 其他地方要创建 Goods 时也要这样做,降低了代码的可维护性(或者将 Order 的 createGoods() 公有化让其他类调用,但这增加了不必要的依赖关系,而且使得代码难以理解)。
迪米特法则(Law of Demeter):又叫作最少知识原则(The Least Knowledge Principle),一个类对于其他类知道的越少越好,即一个对象应当对其他对象有尽可能少的了解。
为了解决上述问题,我们将 createGoods() 从 Order 中移到 Goods 里面,让 Goods 自己负责创建自己,这样便对外封装了创建细节(复杂的创建细节由 Goods 自己内部消化掉):
class Goods
{
...
public static function create($id): self
{
// 一大坨代码逻辑,不过没关系,除了它自己,外面没人知道,乱就乱吧
...
return $goods;
}
}
class Order
{
private $goods;
public function __construct($goodsId,...)
{
$this->goods = Goods::create($goodsId);
}
}
这里解决了封装性问题,今后要修改 Goods 的创建逻辑,只需要修改 Goods 本身即可。很多项目也是通过这种方式实现简单工厂的,因为它足够简单,同时也较好的保证了设计稳定性。
在进一步讨论之前,我们看看 Order 依赖 Goods 的另一种实现:通过依赖注入将 Goods 注入到 Order 中。此时必须在 Transaction 中创建 Goods。我们看看 Transaction 应该如何创建这个“麻烦”的对象。
最直接的实现方式:
class Goods
{
...
}
class Order
{
private $goods;
public function __construct(Goods $goods, ...)
{
$this->goods = $goods;
}
}
class Transaction
{
// 下单方法,生成订单对象
public function order()
{
// 这里是一大坨创建 Goods 的代码
...
$goods = new Goods(...);
$order = new Order($goods, ...);
}
}
这和第一种实现存在一样的问题:Transaction 承担了创建 Goods 的工作,违背了单一职责原则,以后要改 Goods 的创建逻辑时,需要动 Transaction 的代码(而且更糟糕的是可能还存在 ClassX,ClassY 都在创建 Goods,多个地方都要改),解决方法也是将创建逻辑抽离到 Goods 中。
那么,将 Goods 的创建逻辑放到 Goods 中自我消化是否就万事大吉了呢?
得看具体情况。如果 Goods 仅仅是因为创建较复杂而已(复杂程度尚可接受,不会对 Goods 造成严重污染),今后预计不会修改其创建逻辑,那么放在里面是没有问题的(实际中有大量项目确实是这样做的)。但是,如果 Goods 的创建涉及到非常复杂的组装行为,而且今后预计会修改其创建逻辑,那么这些复杂性就影响到 Goods 自身的稳定性了。从本质上说,让 Goods 创建自身是违背单一职责原则的,“创建”行为属于使用者的职责,而非功能提供者的。
如此,一方面,我们不想让使用者(Transaction 和 Order)知道被使用者(Goods)的细节,影响使用者的设计稳定性,另一方面又不想让功能提供者自身(Goods)创建自己,影响提供者的设计稳定性,那如何解决该矛盾呢?
答案是引入第三者:工厂类,将对象创建的复杂性封装到独立的、功能单一的类中。
如下:
// 此处省略 Goods 和 Order 类定义
...
// 商品工厂类,封装 Goods 的创建细节
class GoodsFactory
{
public function create($goodsId): Goods
{
// 一大坨创建 Goods 对象的代码
...
return $goods;
}
}
// 在交易类中通过工厂创建 Goods 对象
class Transaction
{
public function order($goodsId, ...)
{
$factory = new GoodsFactory();
$order = new Order($factory->create($goodsId), ...);
}
}
今后要修改 Goods 的创建逻辑时,只需要修改 GoodsFactory 即可,不需要修改 Transaction、Order 或者 Goods。以上便是简单工厂的实现。
至此,我们看到工厂模式通过隔离解决了对象创建的复杂性:将 Goods 对象创建的复杂性(不确定性、未来变化性)放到单独的、职责单一的工厂类 GoodsFactory 中,从而将其带来的不稳定性从 Transaction、Order 和 Goods 中隔离开来,保证这三个类的设计稳定性。
工厂方法
上面的例子并没有很好地体现抽象(虽然从广义上说,工厂本身即提供了创建逻辑的抽象,但我们更多的是关注狭义上的抽象性)。
上面提到,车主可以购买燃油,也可以购买便利店非油品,还可购买券等虚拟商品,所以更可取的设计是将 Goods 抽象成接口并提供不同的商品实现类:
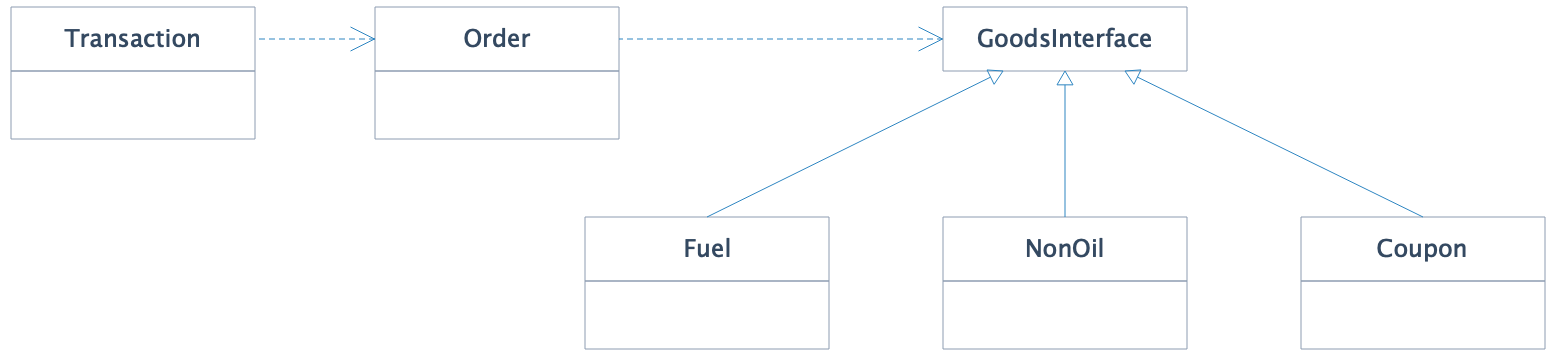
我们将 Order 对 Goods 的依赖改成了对接口 GoodsInterface 的依赖,由油品(Fuel)、非油品(NonOil)、券(Coupon)实现该接口。这样修改后,一般我们会通过依赖注入将 GoodsInterface 的实现类实例注入到 Order 中,如下:
// Goods 接口定义
interface GoodsInterface
{
...
}
// 油品
class Fuel implements GoodsInterface
{
...
}
// 非油品
class NonOil implements GoodsInterface
{
...
}
// 券
class Coupon implements GoodsInterface
{
...
}
// 订单,依赖 GoodsInterface 接口
class Order
{
private $goods;
public function __construct(GoodsInterface $goods, ...)
{
$this->goods = $goods;
}
}
// 交易
class Transaction
{
// 下单
public function order($goodsType, $goodsId, ...)
{
$goods = null;
if ($goodsType == 'fuel') {
// 一坨创建代码
...
$goods = new Fuel(...);
} elseif ($goodsType == 'nonOil') {
...
$goods = new NonOil(...);
} elseif ($goodsType == 'coupon') {
...
$goods = new Coupon(...);
} else {
// 其他逻辑
...
}
$order = new Order($goods, ...);
...
}
}
我们发现上面 Transaction 的代码有一大段 if else 用来创建 GoodsInterface 实例,根据前面的讨论我们知道应该要创建一个工厂类来解决此问题:
class GoodsFactory
{
public function create($goodsType, $goodsId): GoodsInterface
{
$goods = null;
if ($goodsType == 'fuel') {
// 一坨创建代码
...
$goods = new Fuel(...);
} elseif ($goodsType == 'nonOil') {
...
$goods = new NonOil(...);
} elseif ($goodsType == 'coupon') {
...
$goods = new Coupon(...);
} else {
// 其他逻辑
...
}
return $goods;
}
}
上面的简单工厂有什么问题呢?
当我们把 Goods 向上抽离出接口 GoodsInterface 时,往往意味着商品本身在未来的变数很大(变化性很强,比如未来可能会有其它商品类型),需要增加抽象层(接口)来提高设计的稳定性(让其它类依赖稳定的接口 GoodsInterface 而不是不稳定的实现类)——这也就意味着未来我们可能要不断的修改工厂类 GoodsFactory,在里面加很多 if else。也就是说,GoodsFactory 是不稳定的。特别是当每个实现类的创建都很复杂时,工厂本身也会变得很复杂。
和处理 Goods 的思路一样,我们也通过增加抽象层(接口)的方式来解决工厂自身面临的问题。
我们从 GoodsFactory 抽象出接口 FactoryInterface:
// 定义工厂接口
interface FactoryInterface
{
// create 返回 接口类型
public function create($goodsId): GoodsInterface;
}
// 油品工厂
class FuelFactory implements FactoryInterface
{
public function create($goodsId): GoodsInterface
{
// 创建 Fuel,此处逻辑可能很复杂
...
return new Fuel(...);
}
}
// 非油品工厂
class NonOilFactory implements FactoryInterface
{
public function create($goodsId): GoodsInterface
{
...
return new NonOil(...);
}
}
// 券工厂
class CouponFactory implements FactoryInterface
{
public function create($goodsId): GoodsInterface
{
...
return new Coupon(...);
}
}
等等!如此工厂是符合开闭原则了,怎么用?像下面这样?
class Transaction
{
public function order($goodsType, $goodsId, ...)
{
// 根据商品类型创建不同的工厂
$factory = null;
if ($goodsType == 'fuel') {
$factory = new FuelFactory();
} elseif ($goodsType == 'nonOil') {
$factory = new NonOilFactory();
} elseif ($goodsType == 'coupon') {
$factory = new CouponFactory();
} else {
...
}
// 通过工厂创建商品对象
$order = new Order($factory->create($goodsId));
...
}
}
开玩笑吗?Transaction 没有什么本质变化啊?为了创建商品工厂仍然在 Transaction 中引入了一堆 if else,而这些逻辑跟下单没有什么关系(属于对象创建逻辑),使 Transaction 类违反了单一职责原则,引入了设计上的不稳定性(以后每加一个工厂就要改 Transaction,但 Transaction 跟商品以及商品工厂的变化本应没有必然关系才对)。
所以,工厂方法模式还得有个“工厂的工厂”,将“工厂的创建”逻辑封装起来:
// 工厂容器(工厂的工厂)
class GoodsFactoryContainer
{
private static $container = [];
// 根据商品类型获取相应的商品工厂
public static function get($goodsType): FactoryInterface
{
// 先从缓存中获取
if (isset(self::$container[$goodsType])) {
return self::$container[$goodsType];
}
// 创建工厂
$factory = null;
if ($goodsType == 'fuel') {
$factory = new FuelFactory();
} elseif ($goodsType == 'nonOil') {
$factory = new NonOilFactory();
} else {
$factory = new CouponFactory();
}
// 保存到缓存中
self::$container[$goodsType] = $factory;
return $factory;
}
}
// 在交易类中使用工厂
class Transaction
{
public function order($goodsType, $goodsId, ...)
{
// 此时交易类不需要关注工厂和商品的创建细节,终于干净了
$goodsFactory = GoodsFactoryContainer::get($goodsType);
$goods = $goodsFactory->create($goodsId);
$order = new Order($goods, ...);
...
}
}
以上便是工厂方法模式的实现。
至此 Transaction 和各个工厂算是稳定了,而且各自的职责也足够单一,可扩展性也不错——唯一不稳定的是 GoodsFactoryContainer 了,确切的说是我们将不稳定因素从 Transaction 和 Order 中转移到了 GoodsFactoryContainer 中。在系统设计中,不稳定性只能转移,无法彻底消除,我们真正要做的是让不稳定性带来的修改最小化,从而让系统设计的整体稳定性趋向最大。
既然不稳定性只能转移,无法彻底消除,那这种转移又有什么意义呢?
在上面的例子中,商品的创建过程属于不稳定因素(该不稳定性来自现实世界未来业务的不确定性),由商品种类的不稳定又导致商品工厂的不稳定——我们要做的是将这些不稳定性从相对稳定的下单逻辑中抽离出来,并将它们抽象成稳定的接口,业务逻辑类依赖于这些接口,然后通过一个容器将实现细节封装起来。如此,商品创建逻辑上的变化将不会影响下单逻辑的代码。
我们注意 Transaction 类中的代码:
$goodsFactory = GoodsFactoryContainer::get($goodsType);
$goods = $goodsFactory->create($goodsId);
$order = new Order($goods, ...);
这几行代码诠释了如何面向接口(而不是实现)编程。
Order 类依赖 GoodsInterface 接口——那谁来提供 GoodsInterface 接口的实现呢?
答案是 FactoryInterface 接口——那谁来提供 FactoryInterface 接口的实现呢?
答案是 GoodsFactoryContainer 容器。
未来当我们需要调整商品创建逻辑时,所有的修改不会越过 GoodsFactoryContainer 的边界——也就是说只需要修改 GoodsFactoryContainer(及其内部依赖),而 GoodsFactoryContainer 就是干这件事的,所以因商品创建逻辑的变动而带来的修改并不会违反单一职责原则和开放封闭原则(相反,如果这些变动带来了 Transaction 或 Order 类的修改则违反了开放封闭原则,因为商品创建逻辑和这两个类的职责没有必然关联)。
至此,工厂模式从抽象和隔离两个维度很好地解决了对象创建的复杂性——除了一点:如果目标类/接口因本身的多维性而导致实现类非常多,从而对应的工厂类也非常多,导致类爆炸,严重影响系统的可维护性。比如目标接口有 2 个维度,每个维度有 3 种可能,那么实际类的数量就是 3^2 = 9 个类,要创建 9 个工厂。此时就要用到抽象工厂。抽象工厂将 2 维降成 1 维,具体实现方式是每个工厂类负责其中一个维度的所有类实例的创建(工厂方法是只创建一种类实例),比如此处每个工厂负责创建 3 种类实例,那么就只需要 3 个工厂即可。
反正我在实践中是没有用过这么复杂的模式(因而这里也不再给出抽象工厂的实现)。如果一个事物需要从多个维度去建立继承关系,很容易造成类爆炸(这也是继承特性被诟病的原因之一),此时更可取的方案是采用组合代替继承(比如使用装饰器模式)。
总结
工厂模式在实践中使用很多,我相信大家都遇到过的一个经典场景就是 IoC 容器。IoC 容器实际上就是一个超级工厂,它负责整个系统的对象的创建。一方面 IoC 容器帮我们自动解决对象之间复杂的依赖关系,另一方面我们可以在最外层(配置文件)中决定某个接口使用哪个实现类——这些正是工厂擅长做的事情。
我们实际使用工厂模式时,要遵循 KISS 原则(Keep it Simple and Stupid),能简单就不要搞复杂。建议从简单工厂开始,因为在系统的第一版设计中,我们对很多概念、结构的认知都不会太深,此时一上来就使用“牛刀”,往往会造成过度设计,要相信软件设计“没有银弹”,任何设计模式都可能带来可读性、易用性甚至是可维护性上的损失,工厂模式也不例外(比如在工厂方法模式中,我们要引入“工厂的工厂”,这本身增加了复杂性)。随着系统的迭代重构,我们的认知逐渐深入,真的发现问题了,才去逐渐采用更复杂的解决方案。
最后我们总结下:
- 软件系统设计的复杂性源于真实世界的复杂性;
- 软件系统遵循熵增定律,随着时间推移会越来越趋向混乱,而设计模式和重构则是用来解决复杂性的,是逆熵的过程;
- 工厂模式用来解决对象创建的复杂性;
- 具体地,工厂模式是通过抽象和隔离来解决对象创建的复杂性的;
- 从复杂性来说,简单工厂 < 工厂方法 < 抽象工厂,实践中要从简单的开始用,避免过度设计;
- 系统设计的目标是追求设计的稳定性;
- 系统中的不稳定因素只能转移,无法彻底消除,我们要做的是隔离不稳定因素,让变化带来的影响最小化,力求设计稳定性趋向最大化;
