研究这个前前后后也有快两三个月了,因为之前也一直在弄模板匹配方面的东西,所以偶尔还是有不少朋友咨询或者问你有没有研究过linemod这个算法啊,那个效率啥的还不错啊,有段时间一直不以为然,觉得我现在用的那个匹配因该很不错的,没必要深究了。后来呢,还是忍不住手痒,把论文打出来看了看,又找了点资料研究了下,结果没想到一弄又是两个月过去了,中间也折腾了很久,浪费了不少时间。总算还是有点收获,稍微整理下做个交流。
至于linemod的具体数学原理,我也不需要详谈,毕竟论文和opencv的代码就摆在那里, github上也有一些别人改进的版本。
我就觉得啊,linemod这个基于计算边缘的模板匹配啊,他使用的是选中的特征点的梯度的角度方向作为特征,而不是梯度的值,而后计算模板和测试不同位置角度的余弦的绝对值,这个都是常规的操作。 作者把这个角度线性量化为一些特定的值,这个本质上呢降低了算法的精度,但是由于特征点较多,基本不会影响识别结果。 关键是这个量化啊,能够带来很多很多的好处,有些真的是意想不到。
论文里呢把360的角度量化为8个值,即以45度为间隔,分别用整数0、1、2、3、4、5、6、7表示,这样呢不同的两个角度之间的差异绝对值呢,只有0、1、2、3、4这5种可能,分别对应5个得分,比如模板的某个特征点的角度为210度,则量化值为4,目标中某个位置的角度值为52度,则量化值为1,这样角度之间差异值为3,则对应的得分为1。
接着论文里说为了减少微小的变形引起的识别误差,建议将量化后的值进行扩散,这个扩散也是设计的非常有技巧,很有意思,充分利用了或运算的优异特性。
后续说为了减少计算量呢,可以提前计算出8个响应图,这样匹配计算时就可以直接查表,而无需实时计算。
再后续还有一个线性化内存,算了,我已经没看那个了,到前面这一步就已经打止了,因为我已经开始编程了。
第一步呢,我就是在考虑算法的优化问题,我看了下opencv的代码,写的很好,又很不好,让你读的很难受,但是写的确实稳健,考虑到了很多不同的硬件配置,这也许就是大工程的特性吧。
角度量化的问题和代码方面我不想提,也有很多可优化的地方,大家可自行考虑。
在谈到提速之前,我说一个重点,那就是所谓的梯度扩散、计算响应图都是在查找模板时进行的, 对不同的图都要有重新计算,而不是离线玩。所以这里的每个耗时,都和检测速度有关。
第一:那个梯度扩散,CV的代码有下面这一大堆:

/****************************************************************************************\
* Response maps *
\****************************************************************************************
static void orUnaligned8u(const uchar * src, const int src_stride,
uchar * dst, const int dst_stride,
const int width, const int height)
{
#if CV_SSE2
volatile bool haveSSE2 = checkHardwareSupport(CPU_SSE2);
#if CV_SSE3
volatile bool haveSSE3 = checkHardwareSupport(CPU_SSE3);
#endif
bool src_aligned = reinterpret_cast<unsigned long long>(src) % 16 == 0;
#endif
for (int r = 0; r < height; ++r)
{
int c = 0;
#if CV_SSE2
// Use aligned loads if possible
if (haveSSE2 && src_aligned)
{
for ( ; c < width - 15; c += 16)
{
const __m128i* src_ptr = reinterpret_cast<const __m128i*>(src + c);
__m128i* dst_ptr = reinterpret_cast<__m128i*>(dst + c);
*dst_ptr = _mm_or_si128(*dst_ptr, *src_ptr);
}
}
#if CV_SSE3
// Use LDDQU for fast unaligned load
else if (haveSSE3)
{
for ( ; c < width - 15; c += 16)
{
__m128i val = _mm_lddqu_si128(reinterpret_cast<const __m128i*>(src + c));
__m128i* dst_ptr = reinterpret_cast<__m128i*>(dst + c);
*dst_ptr = _mm_or_si128(*dst_ptr, val);
}
}
#endif
// Fall back to MOVDQU
else if (haveSSE2)
{
for ( ; c < width - 15; c += 16)
{
__m128i val = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src + c));
__m128i* dst_ptr = reinterpret_cast<__m128i*>(dst + c);
*dst_ptr = _mm_or_si128(*dst_ptr, val);
}
}
#endif
for ( ; c < width; ++c)
dst[c] |= src[c];
// Advance to next row
src += src_stride;
dst += dst_stride;
}
}
/**
* \brief Spread binary labels in a quantized image.
*
* Implements section 2.3 "Spreading the Orientations."
*
* \param[in] src The source 8-bit quantized image.
* \param[out] dst Destination 8-bit spread image.
* \param T Sampling step. Spread labels T/2 pixels in each direction.
*/
static void spread(const Mat& src, Mat& dst, int T)
{
// Allocate and zero-initialize spread (OR'ed) image
dst = Mat::zeros(src.size(), CV_8U);
// Fill in spread gradient image (section 2.3)
for (int r = 0; r < T; ++r)
{
int height = src.rows - r;
for (int c = 0; c < T; ++c)
{
orUnaligned8u(&src.at<unsigned char>(r, c), static_cast<int>(src.step1()), dst.ptr(),
static_cast<int>(dst.step1()), src.cols - c, height);
}
}
}
我翻译成我容易接受的代码,并且剔除一些对硬件环境的判断的语句,如下所示:
void IM_Spread_Ori(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int T)
{
memset(Dest, 0, Height * Stride);
for (int J = 0; J < T; J++)
{
int H = Height - J;
for (int I = 0; I < T; I++)
{
int W = Width - I;
int BlockSize = 16, Block = W / BlockSize;
unsigned char *SrcP = Src + J * Stride + I;
unsigned char *DestP = Dest;
for (int Y = 0; Y < H; Y++)
{
for (int X = 0; X < Block * BlockSize; X += BlockSize)
{
__m128i SrcV = _mm_loadu_si128((__m128i*)(SrcP + X));
__m128i DstV = _mm_loadu_si128((__m128i*)(DestP + X));
_mm_storeu_si128((__m128i *)(DestP + X), _mm_or_si128(SrcV, DstV));
}
for (int X = Block * BlockSize; X < W; X++)
{
DestP[X] |= SrcP[X];
}
SrcP += Stride;
DestP += Stride;
}
}
}
}
要说啊,这个代码本身来说有是个比较高效的代码了,但是,我一想到论文中的T=8,那就意味着差不多是8*8=64次全图这样的数据or操作,哪怕就算or操作再快, 这个也不太可能快过 64次memcpy的,特别当一个图比较大的时候,这个就有点明显了,我测试了下,对于一个3000*3000的灰度图(工业上遇到这么大的图应该不算离谱吧),初步测试了下,居然需要大概200ms的时间,对于模板匹配这种需要高频操作的需求来说,单独这一步的耗时还是大了点。
有么有在不改变效果的情况下,进一步提高这个算法的方法呢,其实是有的,我们知道or操作时不分前后顺序的,即多个数据or可以随便谁和谁先操作,因此,我们可以安排T行之间先or,然后再对结果记性T列之间or操作,这样则只需要2*T次or计算,而且有一些额外的好处就是避免很多cache miss,这是隐藏的速度提升。
改写后的代码如下所示:
void IM_Spread(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int T)
{
// 利用了或运算的行和列分离特性
memset(Dest, 0, Height * Stride);
int BlockSize = 16, Block = Width / BlockSize;
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Dest + Y * Stride;
for (int J = 0; J < ((Y + T > Height) ? Height - Y : T); J++)
{
// 高度方向依次向下进行T次或运算
for (int X = 0; X < Block * BlockSize; X += BlockSize)
{
__m128i SrcV = _mm_loadu_si128((__m128i*)(LinePS + X));
__m128i DstV = _mm_loadu_si128((__m128i*)(LinePD + X));
_mm_storeu_si128((__m128i *)(LinePD + X), _mm_or_si128(SrcV, DstV));
}
for (int X = Block * BlockSize; X < Width; X++)
{
LinePD[X] |= LinePS[X];
}
LinePS += Stride; // 源数据向下移动,目标数据不动
}
}
BlockSize = 16, Block = (Width - T) / BlockSize;
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePD = Dest + Y * Stride;
for (int X = 0; X < Block * BlockSize; X += BlockSize)
{
__m128i Value = _mm_setzero_si128();
for (int I = 0; I < T; I++)
{
__m128i SrcV = _mm_loadu_si128((__m128i*)(LinePD + X + I));
Value = _mm_or_si128(Value, SrcV);
}
// 这个读取和写入是没有重叠的,所以可以不利用中间内存
_mm_storeu_si128((__m128i *)(LinePD + X), Value);
}
for (int X = Block * BlockSize; X < Width; X++)
{
int Value = 0;
for (// 此处删除部分代码,供读者自行补充 )
{
Value = Value | LinePD[X + I];
}
LinePD[X] = Value;
}
}
}
同样的测试图,同样的T=8,速度一下子提升到了45ms左右,有近5倍的速度提升。
为什么我会分享这段代码呢,因为后面我发现他根本没什么卵用。
第二:那个计算响应图的代码,也可以继续优化。
// Auto-generated by create_similarity_lut.py
CV_DECL_ALIGNED(16) static const unsigned char SIMILARITY_LUT[256] = {0, 4, 3, 4, 2, 4, 3, 4, 1, 4, 3, 4, 2, 4, 3, 4, 0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 0, 3, 4, 4, 3, 3, 4, 4, 2, 3, 4, 4, 3, 3, 4, 4, 0, 1, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 3, 3, 4, 4, 4, 4, 3, 3, 3, 3, 4, 4, 4, 4, 0, 2, 1, 2, 0, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 0, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 0, 3, 2, 3, 1, 3, 2, 3, 0, 3, 2, 3, 1, 3, 2, 3, 0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 0, 4, 3, 4, 2, 4, 3, 4, 1, 4, 3, 4, 2, 4, 3, 4, 0, 1, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 0, 3, 4, 4, 3, 3, 4, 4, 2, 3, 4, 4, 3, 3, 4, 4, 0, 2, 1, 2, 0, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 0, 2, 3, 3, 4, 4, 4, 4, 3, 3, 3, 3, 4, 4, 4, 4, 0, 3, 2, 3, 1, 3, 2, 3, 0, 3, 2, 3, 1, 3, 2, 3, 0, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4};
/**
* \brief Precompute response maps for a spread quantized image.
*
* Implements section 2.4 "Precomputing Response Maps."
*
* \param[in] src The source 8-bit spread quantized image.
* \param[out] response_maps Vector of 8 response maps, one for each bit label.
*/
static void computeResponseMaps(const Mat& src, std::vector<Mat>& response_maps)
{
CV_Assert((src.rows * src.cols) % 16 == 0);
// Allocate response maps
response_maps.resize(8);
for (int i = 0; i < 8; ++i)
response_maps[i].create(src.size(), CV_8U);
Mat lsb4(src.size(), CV_8U);
Mat msb4(src.size(), CV_8U);
for (int r = 0; r < src.rows; ++r)
{
const uchar* src_r = src.ptr(r);
uchar* lsb4_r = lsb4.ptr(r);
uchar* msb4_r = msb4.ptr(r);
for (int c = 0; c < src.cols; ++c)
{
// Least significant 4 bits of spread image pixel
lsb4_r[c] = src_r[c] & 15;
// Most significant 4 bits, right-shifted to be in [0, 16)
msb4_r[c] = (src_r[c] & 240) >> 4;
}
}
#if CV_SSSE3
volatile bool haveSSSE3 = checkHardwareSupport(CV_CPU_SSSE3);
if (haveSSSE3)
{
const __m128i* lut = reinterpret_cast<const __m128i*>(SIMILARITY_LUT);
for (int ori = 0; ori < 8; ++ori)
{
__m128i* map_data = response_maps[ori].ptr<__m128i>();
__m128i* lsb4_data = lsb4.ptr<__m128i>();
__m128i* msb4_data = msb4.ptr<__m128i>();
// Precompute the 2D response map S_i (section 2.4)
for (int i = 0; i < (src.rows * src.cols) / 16; ++i)
{
// Using SSE shuffle for table lookup on 4 orientations at a time
// The most/least significant 4 bits are used as the LUT index
__m128i res1 = _mm_shuffle_epi8(lut[2*ori + 0], lsb4_data[i]);
__m128i res2 = _mm_shuffle_epi8(lut[2*ori + 1], msb4_data[i]);
// Combine the results into a single similarity score
map_data[i] = _mm_max_epu8(res1, res2);
}
}
}
else
#endif
{
// For each of the 8 quantized orientations...
for (int ori = 0; ori < 8; ++ori)
{
uchar* map_data = response_maps[ori].ptr<uchar>();
uchar* lsb4_data = lsb4.ptr<uchar>();
uchar* msb4_data = msb4.ptr<uchar>();
const uchar* lut_low = SIMILARITY_LUT + 32*ori;
const uchar* lut_hi = lut_low + 16;
for (int i = 0; i < src.rows * src.cols; ++i)
{
map_data[i] = std::max(lut_low[ lsb4_data[i] ], lut_hi[ msb4_data[i] ]);
}
}
}
}
看上去又是一大堆代码,简化后如下所示:
void IM_ComputeResponseMaps_Slow(unsigned char *Src, unsigned char **ResponseMaps, int Width, int Height)
{
static const unsigned char SIMILARITY_LUT[256] = { 0, 4, 3, 4, 2, 4, 3, 4, 1, 4, 3, 4, 2, 4, 3, 4, 0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 0, 3, 4, 4, 3, 3, 4, 4, 2, 3, 4, 4, 3, 3, 4, 4, 0, 1, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 3, 3, 4, 4, 4, 4, 3, 3, 3, 3, 4, 4, 4, 4, 0, 2, 1, 2, 0, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 0, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 0, 3, 2, 3, 1, 3, 2, 3, 0, 3, 2, 3, 1, 3, 2, 3, 0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 0, 4, 3, 4, 2, 4, 3, 4, 1, 4, 3, 4, 2, 4, 3, 4, 0, 1, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 0, 3, 4, 4, 3, 3, 4, 4, 2, 3, 4, 4, 3, 3, 4, 4, 0, 2, 1, 2, 0, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 0, 2, 3, 3, 4, 4, 4, 4, 3, 3, 3, 3, 4, 4, 4, 4, 0, 3, 2, 3, 1, 3, 2, 3, 0, 3, 2, 3, 1, 3, 2, 3, 0, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4 };
unsigned char *lsb4 = (unsigned char *)malloc(Width * Height);
unsigned char *msb4 = (unsigned char *)malloc(Width * Height);
for (int Y = 0; Y < Height * Width; Y++)
{
lsb4[Y] = Src[Y] & 15;
msb4[Y] = (Src[Y] & 240) >> 4;
}
int BlockSize = 16, Block = (Width * Height) / BlockSize;
for (int Z = 0; Z < 8; Z++)
{
for (int Y = 0; Y < Block * BlockSize; Y += BlockSize)
{
__m128i Res1 = _mm_shuffle_epi8(_mm_loadu_si128((__m128i *)(SIMILARITY_LUT + 32 * Z + 0)), _mm_loadu_si128((__m128i *)(lsb4 + Y)));
__m128i Res2 = _mm_shuffle_epi8(_mm_loadu_si128((__m128i *)(SIMILARITY_LUT + 32 * Z + 16)), _mm_loadu_si128((__m128i *)(msb4 + Y)));
_mm_storeu_si128((__m128i *)(ResponseMaps[Z] + Y), _mm_max_epu8(Res1, Res2));
}
for (int Y = Block * BlockSize; Y < Width * Height; Y++)
{
ResponseMaps[Z][Y] = IM_Max(SIMILARITY_LUT[lsb4[Y] + 32 * Z], SIMILARITY_LUT[msb4[Y] + 32 * Z + 16]);
}
}
free(lsb4);
free(msb4);
}
同样3000*3000的测试图,这个函数平均耗时80ms,也算是非常快的。
那有没有改进空间呢,其实是有的,下面这两句明显也是可以用SIMD指令优化的嘛,&操作直接由对应的_mm_loadu_si128指令,至于byte类型数据的移位,确实没有直接指令可以使用,但是自己写个又有什么难度呢.
lsb4[Y] = Src[Y] & 15;
msb4[Y] = (Src[Y] & 240) >> 4;
比如这样就可以:
// 无符号字节数据右移四位
inline __m128i _mm_srli4_epu8(__m128i v)
{
v = _mm_srli_epi16(v, 4);
v = _mm_and_si128(v, _mm_set1_epi8(0x0f));
return v;
}
好了,其他的代码就不需要我写了吧,优化后这个速度能够提高到50ms。
我从这个代码里最大的收获不是其他的,就是_mm_shuffle_epi8这个语句,利用这个很巧妙的实现了一个查找表的过程,其实我想起来了,在我的博文【算法随记七】巧用SIMD指令实现急速的字节流按位反转算法。 里就已经使用了这个技巧。他能轻松的实现少于16个元素的字节类型的查找表。而且效率比普通的C语言查表方式不知道高了多少倍,后面文章我们还会说道这个指令的一个更为优异的特性。
说到这里,大家也许会认为我会继续谈下后续的线性内存方面的优化,但是可惜了,后面的我就没有看了,因为我觉得到了这一步,我就已经有了我自己的路可以走了,不需要后续的那个东西。那个可能对我来说还是累赘。于是我耐着性子,在我以前的大框架的基础上,修改局部函数,终于能跑出了初步的效果, 比如下图,我们取T=8时,得到的匹配结果如下:
整个的基本都错位了。
而当我们的T取为3时,结果就比较好了。

但是仔细观察,可以明显的发现目标还是会有一到2个像素的偏移,如果我们T取值为1时,结果如下:

整体的准确度明显有所提高,为了证明这个结果,在T=1时,我还测试了很多其他图像,结果都表面是完全的,比如一下几幅图像:
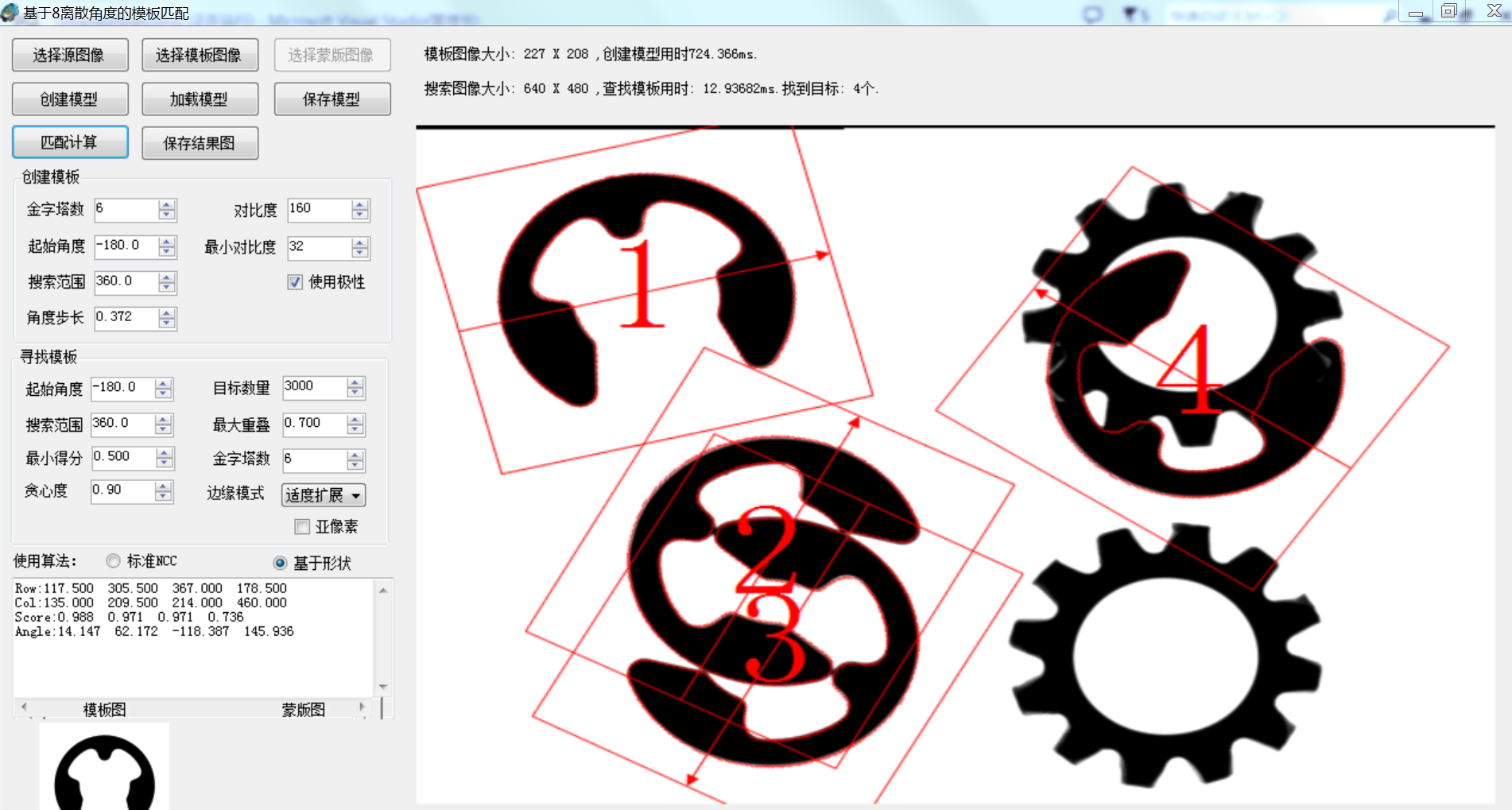
这是两幅很具有代表性的测试图像,一个是高重叠,第二个是强边缘,可以看到效果很准确。
T=1意味这什么,即不需要进行扩散。所以我们由此没有理由不怀疑论文里结论的准确性。为此,我尝试分析深层次的原因。
我的测试方法是:从一副图像中剪切一块小的图像,然后直接按照上述代码计算这个小块图像在原图中的各个不同位置的得分,注意到我们得分通常是按照计算后的总分值除以4*特征点的数量。
具体的测试代码详见附件工程: 扩散结果验证(生成的RAW图像保存D盘根目录下), 这里对算了做一些简单的简化,但不影响实质。
以下面两幅图为例:


小图在大图中的准确坐标位置为【 104,76】。
为了显示方便,我们把计算得到的得分值,量化到0和32768之间,然后保存为RAW文件,这样就可以用PS打开查看其像素结果了。当T=1时,可得到如下视觉结果(下左图),明显图中有个最亮的点,我们放大后查看其结果(下右图)。
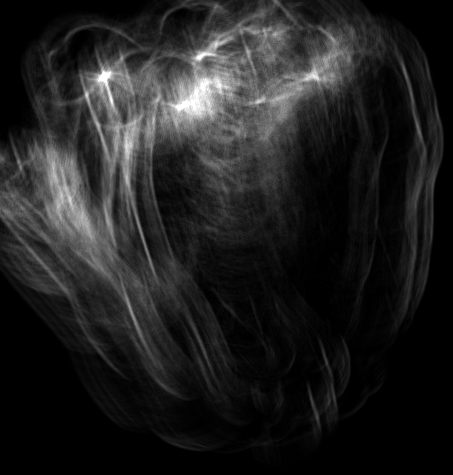
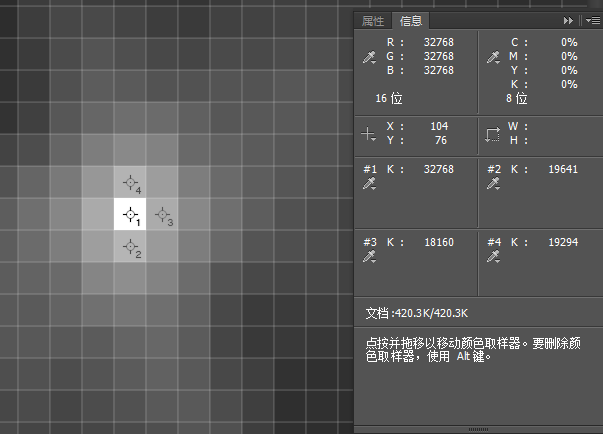
可以看到准确的定位到了104,76这个坐标。
当我们选择T=3时,同样的结果如下面所示:

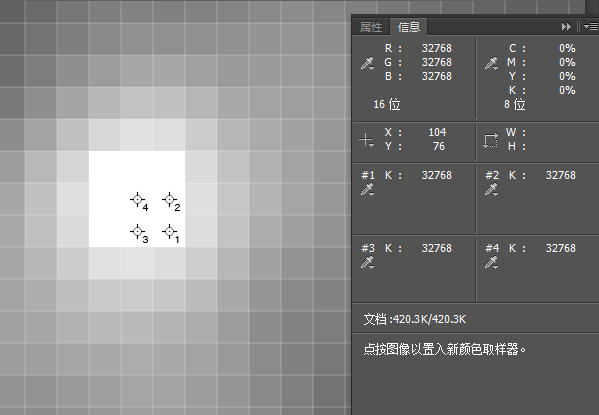
我们可以看到,坐标104,76此处依旧是最大值,但是由于扩散的作用,使得周边也出现了同样的最大值,由于PS只能同时有四个取样点,所以实际上还不止,如果把T扩大到8,那么将会有更多的同样的最大值,这就导致了一个问题,程序无法确定这些最大值那个才是真正的准确的位置了,而又必须确定一个,否则无法得到最终的结果,因此,在上述的T=8的匹配中,由于程序无原则的去了一个最值,然后逐层像金字塔上层传递,每层传递都有可能出现错误,所以导致最终误差越来越大。
那么结论来了,要想准确的匹配,根本就不需要扩散过程。
好希望我的结论是错误的啊,本来还想用这扩散来解决模型的建立慢的问题,以及实现可同时检查带有缩放和旋转的匹配呢。可惜,都是泡影。
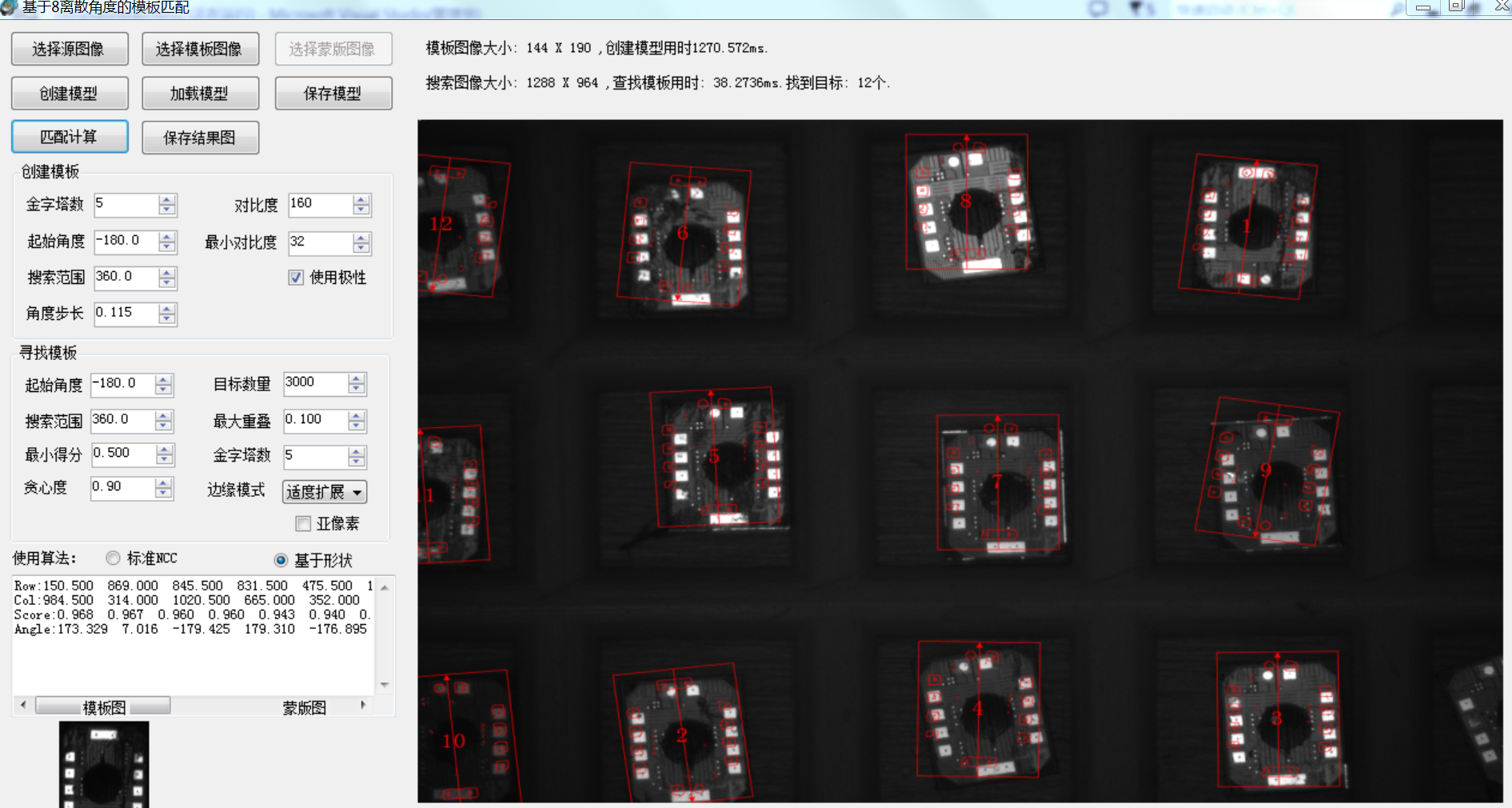
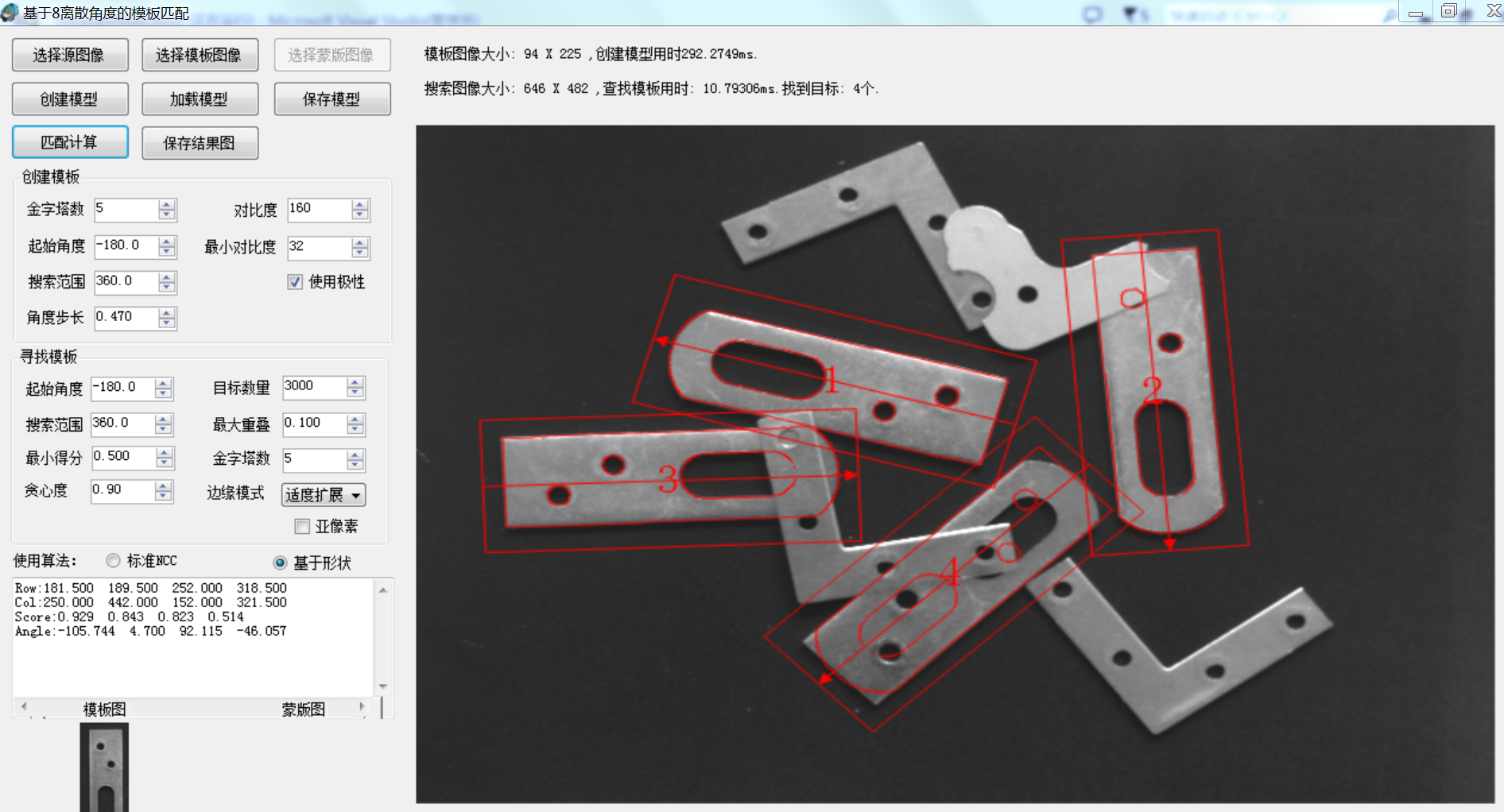
虽然如此,但是这个算法还是有很好的价值的,下一篇文章将讲述基于T=1时改算法的进一步扩展和优化,以及如何实现更高效率的算法效果,先分享一个测试工具了:16角度高速模板匹配。
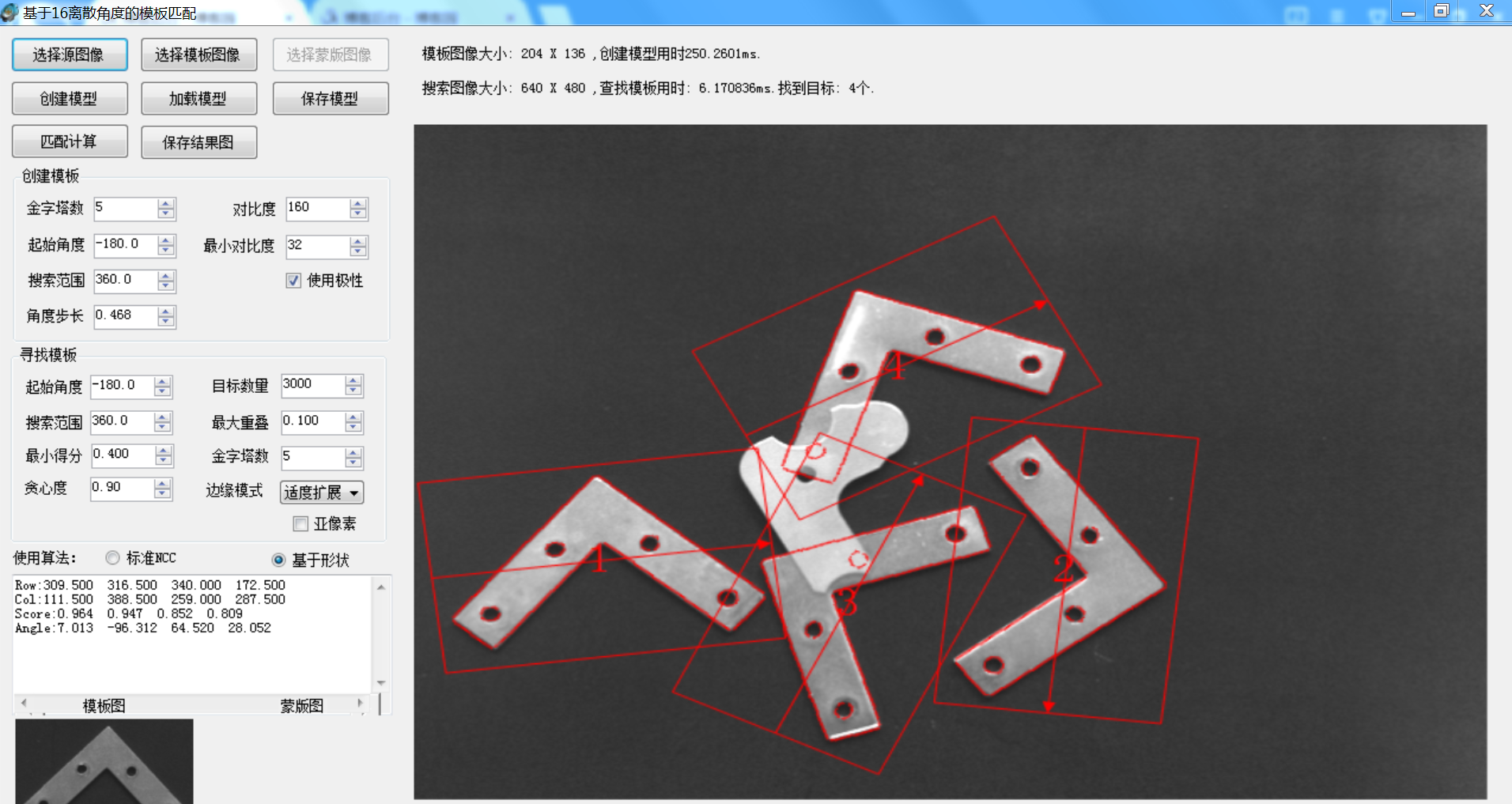
如果想时刻关注本人的最新文章,也可关注公众号:
