Docker 核心知识回顾
最近公司为了提高项目治理能力、提升开发效率,将之前的CICD项目扩展成devops进行项目管理。开发人员需要对自己的负责的项目进行流水线的部署,包括写Dockerfile 对自己的服务制作服务镜像。之前看过的东西,一段时间不用现在突然用起来还有些生疏。此篇对之前的Docker知识进行回顾加深。
对于docker 基本使用命令不再提及,遇到命令忘记或者不知道含义的时候可以使用 help 来进行查看。
基本架构#
Docker 采用的是经典的C/S架构,包括客户端 和 服务端两大 核心组件。
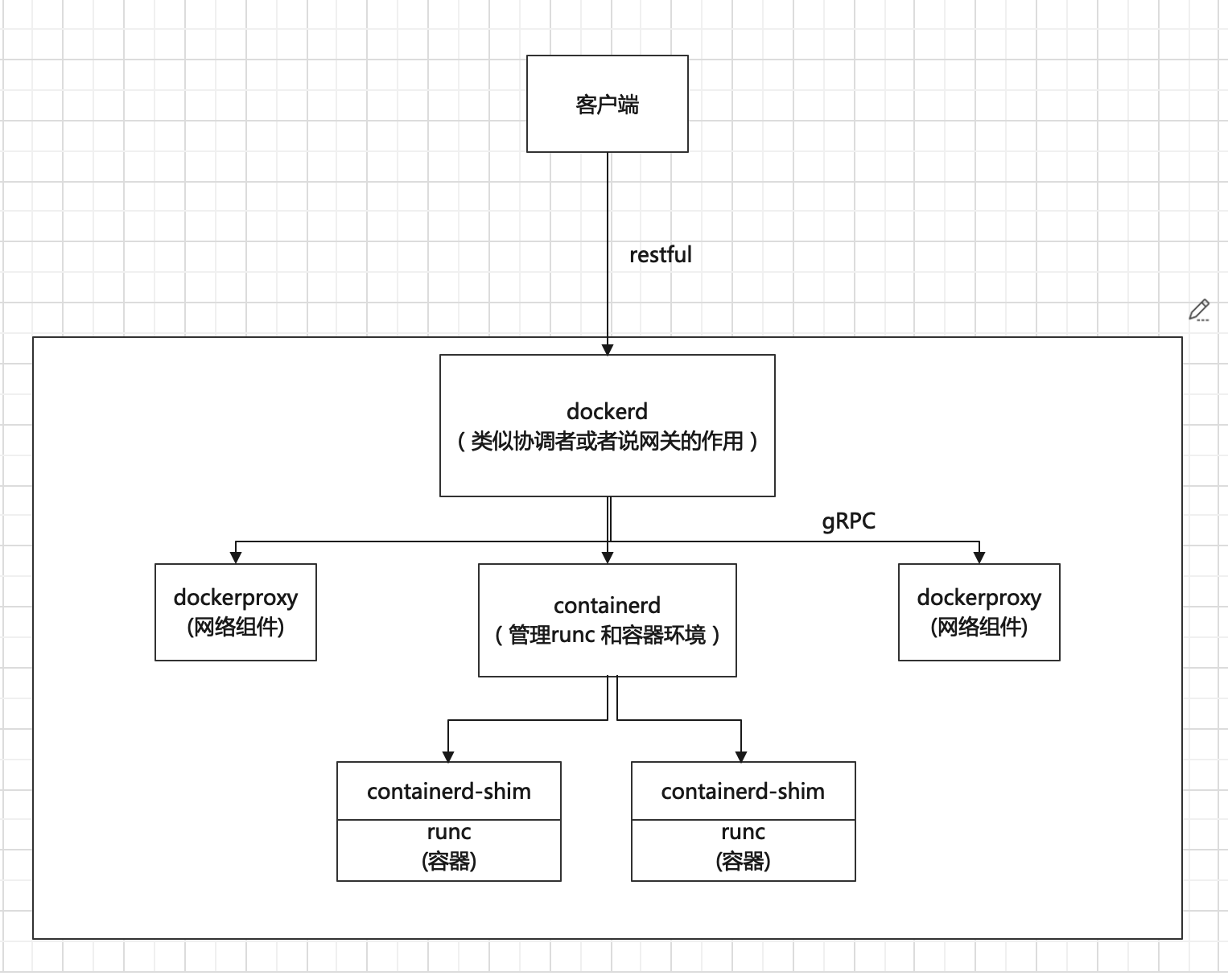
Containers-shim:是containerd的子进程,为runc容器提供支持,也是容器内进程的 根进程
Dockerfile#
这里主要说一下Dockerfile 的编写注意的事项:
-
EXPOSE:只是申明镜像内监听端口,并不会完成自动映射。
-
ENV:当一条EVN指令 中同时为多个环境变量赋值 并且 值也是从环境变量中读取,会为变量都赋值后才更新
ENV key1 = valu1
ENV key1= valu2
ENV key2 = ${key1}
此时key1=valu2,key2=valu1
-
Context: 因为Docker是 C/S 架构的,在编写完Dockerfile 使用build 命令创建镜像的时候会将Dockerfile 所在路径下的数据作为上下文,传输给 服务端来创建镜像。所以如果我们Dockerfile同级目录下有多个文件,最好使用.dockerignore 来进行忽略,防止过多的数据发送到 docker服务端。
-
ADD\COPY : 都支持 go 语言格式的正则表达式。还有要注意路径的问题。
因为dockerfile 可以多步骤创建,所以最好 进行单一职责的划分,制作的镜像省略掉中间的环境,这样可以精简最终镜像的大小。
命名空间(重要)#
命名空间是(namespace)是linux 内核的一个强大 特性。
操作系统中,包括内核,文件系统、网络、进程号、用户号、进程间通信 等资源都是进程间 直接共享的。想要虚拟化,那么除对 内存、cpu、网络IO等进行限制分割外,还需要实现文件系统、网络、PID、UID、IPC 等相互隔离。前面的好做限制,关键是后面的 文件系统、网络之类的如何隔离,这就需要系统的支持,也就是命名空间的引入了。
-
进程命名空间(较为重要):
每个进程命名空间有一套自己的进程号管理方法,
我们从 前面 基本架构 可以看到,他们的进程是进行继承的。
子空间对于父亲空间是可见,父空间对子空间不可见
linux 通过进程命名空间管理进程号,对于同一进程,在不同命名空间中,看到的进程号不一样。
$ ps -ef|grep docker root 3393 1 0 Jan18 ? 0:43:02 /usr/bin/dcokerd .. root 3398 3393 0 Jan18 ? 0:34:32 docker-containerd ...我们在创建一个新的容器,执行 sleep 命令,然后在看看容器的 进程号(注意查看 父进程号)
$ docker run --name test -d linux sleep 9999 $ ps -ef|grep docker root 21535 3398 0 0:57 ? docker-containerd-shim....然后我们在 宿主机 查看新建容器的进程,也是 docker-containerd-shim 进程
$ ps -ef|grep sleep 9999 root 21569 21535 0 06:57 ? sleep 9999重点:我们在容器内 查看进程
$ docker exec -it 3a bash -c 'ps -ef' UID PID PPID C STME TTY TIME CMD root 1 0 0 06:57 ? 00:00:00 sleep 9999可以使用 pstree 命令,查看到完整的进程树
-
IPC命名空间:
容器中 进程交互 还是使用linux 进程间的交互方法,包括信号量、消息队列。同一个IPC命名空间,进程可以彼此可见,不同的则无法访问。
-
网络命名空间(重点)
有了进程间的命名空间,不用命名空间的进程信号可以相互隔离,但是,网络端口还是公用的,所以可以使用网络命名空间。
docker 采用虚拟网络设备,将不用命名空间的网络设备连接到一起。(默认网桥)
docker 可以使用四种网络模式:
-
Host :和主机公用一个网络,容器没有虚拟的网卡,没有独立的ip,和主机的网络是一样的。(但是文件之类的还是隔离的)
-
Container模式:和其他已存在的容器共享一个 Network Namespace, 不是和主机共享。
-
None模式:放在自己容器的网络内部中,外部访问不到,内部也访问不到外部。容器内部只能使用loopback网络设备不会再有其他网络资源。只能使用127.0.0.1的本机网络
-
Bridge模式:容器独立的使用 network Namespace,并链接到docker0虚拟网卡,通过docker0网桥以及Iptables nat表配置与宿主机通信;bridge模式是Docker默认的网络设置
当Docker server启动时,会在主机上创建一个名为docker0的虚拟网桥,
此主机上启动的Docker容器会连接到这个虚拟网桥上。
虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
接下来就要为容器分配IP了,
Docker会从RFC1918所定义的私有IP网段中,选择一个和宿主机不同的IP地址和子网分配给docker0,
连接到docker0的容器就从这个子网中选择一个未占用的IP使用。
如一般Docker会使用172.17.0.0/16这个网段,并将172.17.0.1/16分配给docker0网桥(在主机上使用ifconfig命令是可以看到docker0的,可以认为它是网桥的管理接口,在宿主机上作为一块虚拟网卡使用)。
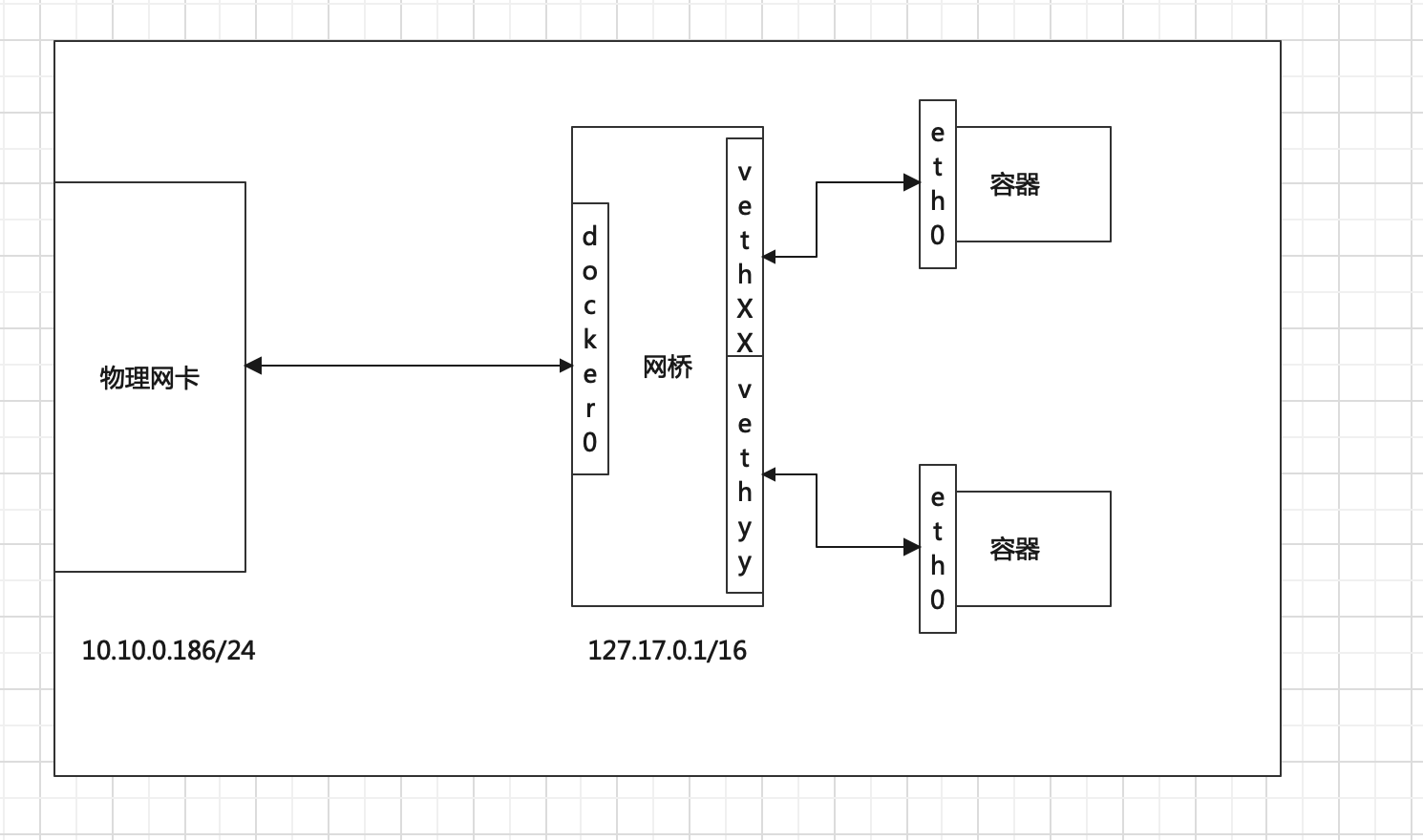
这里容器的访问控制 主要通过linux的 iptables 防火墙软件来控制的,
-
容器间的访问,这里是需要两个方面的支持
-
网络拓扑是否已经联通(默认都链接到docker0上一般都是互通的)
-
本地系统的防火墙软件iptables 是否允许访问通过,这取决于防火墙的规则
-
访问所有端口
当启动docker ,默认会添加一条‘允许’转发策略到iptables的 forward 链上,通过配置 -- icc=true|false 参数控制(启动docker 手动指定 iptables规则,不会影响 宿主机的iptables规则)
-
访问指定端口
可以通过 --link=container_name:allas 指定。(两个容器之间通过添加一条 ACCEPT规则)
-
-
-
对于容器访问外部。
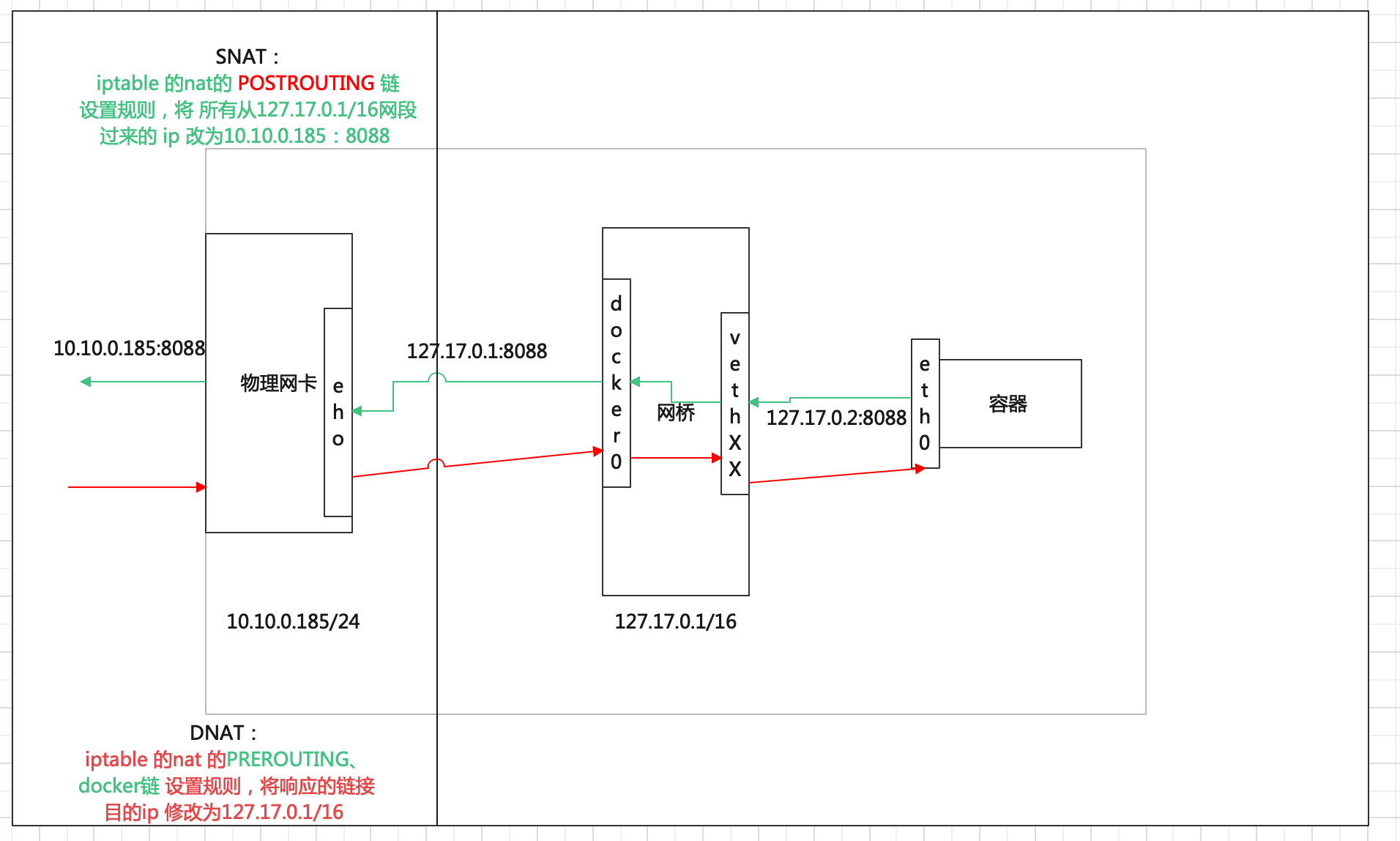
转发过程:我们可以从上图看到,容器将请求通过 veth pair 接口给到docker 网桥,然后网桥通过docker0 发送到宿主机物理网卡上(其实dock er0 对应的就是一个网卡的端口) 网桥就是和交换机类似的作用。
- 这里请求要到外部,需要宿主机进行辅助转发,在宿主机器内查看是否允许 转发
sudo sysctl net.ipv4.ip_forward - forward =1 则是转发,0则是关闭转发。
转发IP 变化:外部访问内部肯定不止直接访问 容器的IP了,需要进行源地址映射 SNAT(Source NAT),修改为宿主机 IP地址 10.0.2.2
具体操作:内部容器请求到达到主机向外部发送请求前,主机的ipstable 伪装源地址,ipstable 的 nat 表添加规则,将其源地址改为 主机地址 10.0.2.2(这个规则适用所用从docker 网桥的请求ip)
#iptables -t nat -A POSTROUTING -s 127.17.0.1/16 -o eth1 -j SNAT --to-source 10.10.0.186 ## 解释规则:就是给nat表中 POSTROUTING 链 添加一条规则:从 s 过来的网段 (127.17.0.1/16) 都进行 snat 动作,即转换ip 为10.10.0.186上边是针对企业中常应用的,但在家庭当中,很少有固定地址,一般都是动态地址,也就是说,出去的跳板是变动的,这样刚才所设置的规则就不行了,不过现在可以通过一个叫做 MASQUERADE—- 地址伪装来解决,即 snat 换成 MASQUERADE。
- 这里请求要到外部,需要宿主机进行辅助转发,在宿主机器内查看是否允许 转发
-
外部访问内部容器。
我们通过 容器启动时映射端口命令 -p 来添加容器到本机的端口映射,这其实也是在本地的 ipstable 添加 nat 规则,将外部IP 进行目标地址DNAT,将目标地址修改为容器内部ip 地址。
这里nat表设计两条链:
- PREROUTING 链 负责包到 网络接口时,改写器目的地址,其中的规则流量都到 docker 链,
- Docker 链将所有不是从docker0 进来的包(非本机器的产生的包),同时目标 端口为 docker0 映射的物理端口号(或者容器映射的端口号),修改目标地址为 172.2.0.2,目标端口使用 容器映射端口。
-
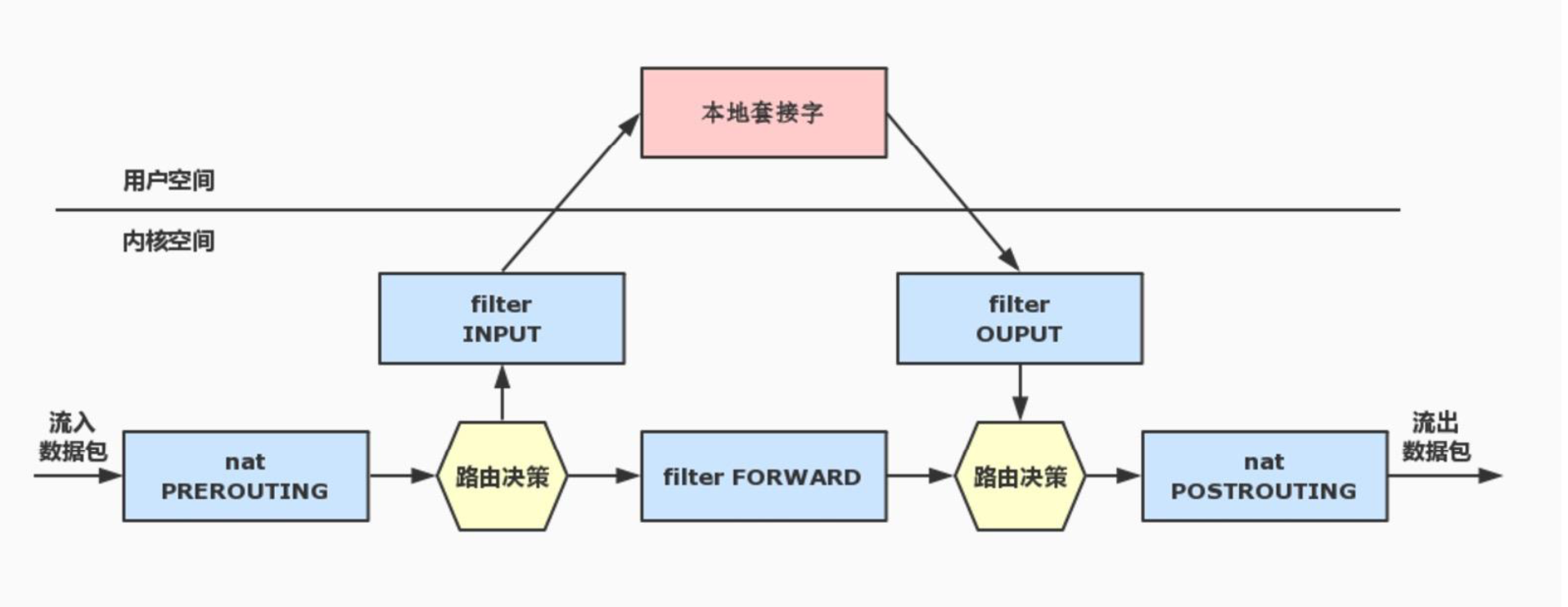
该图片来源于网络【https://blog.csdn.net/beanewself/article/details/78317626】
报文流向:
流入本机:PREROUTING --> INPUT-->用户空间进程 流出本机:用户空间进程-->OUTPUT--> POSTROUTING 转发:PREROUTING --> FORWARD --> POSTROUTING
不过还是建议,自定义一个网桥,这样方便自己管理容器的网络 。(使用openvswitch)
DNS#
-
docker 服务启动后会默认启用一个 内嵌的 dns 服务,来自动解析同一个网络中的容器主机名和地址,如果无法解析,则通过容器内的dns 相关配置进行解析。
-
Docker启动容器时,会从宿主机 复制/etc/resolv.conf 文件,并删除掉无法链接的Dns 服务器。
-
挂载命名空间
挂载命名空间允许 不同命名空间的进程看到的本地文件位于宿主机的不同路径下,每个命名空间的进程看到的目录是彼此隔离的。
这里有 联合文件系统的知识,网络上很多讲解,这里我自己的理解为:
Docker 容器内部使用 联合文件系统,我们宿主机上看到的还是一个文件目录,只不过在docker 容器中相互隔离了。
这里要注意一点,对于可写层要读取下面的对象,如果 较为深层的对象 数据太大,意味着较差的IO性能。所以对于IO敏感型,推荐将容器通过 volume 方式挂载。

-
UTS命名空间
UTS 命名空间 允许每个容器拥有独立的主机名和域名,从而可以虚拟出一个独立的主机名 和网络空间的环境
-
用户命名空间
每个容器可以有不同的用户 和 组ID,也就是说,可以在容器内使用特定的内部用户 执行程序,而非本地系统存在的用户
控制组#
这个是linux 内核的一个特性,主要用来对共享资源进行隔离、限制、审计。
-
资源限制:可以将组设置一定对内存限制,内存子系统可以对对进程组 设定一个内存使用上线
-
优先级:通过优先级 让一些组 优先得到更多的cpu 资源
-
资源审计:用来统计系统实际上把多少资源用到合适的目的上。
-
隔离:为组隔离命名空间,使得另一个组不会看到进程、网络等
-
控制:执行挂起、恢复 和重启
用户可以 /sys/fs/cgroup/memory/docker/目录下看到Docker组应用的各种限制项,用户可以修改这些值,来进行限制docker 应用资源。
compose#
作为Docker 三剑客之一,它最主要的功能是服务编排。
这里只是简单的介绍 和 说明一些常用的语法
我们通过Dockerfile 可以快速的编写一个应用的镜像,但是我们的服务往往是 多个服务协作进行的:
比如前后端分离:前端一个服务、后端一个服务、再有一个数据库。。。
所以如果一个一个的写dockerfile 那么部署的时候也要进行先后配置,这显然不是Devpos初衷,我们想要的是一键部署,所以这就用到compose了。
我们可以使用compose 将各个服务进行依赖编写,然后同时部署多个容器。(在compose中,这叫做服务栈)
- 任务:一个容器被称为一个任务,任务有个独一无二的ID
- 服务:某个相同镜像的容器副本(一个前端,对应多个后端,多个后端就是副本)
- 服务栈:多个服务组成,相互配合完成特定业务。
使用一个web 应用作为例子:
version: '3' ##使用的compose版本
services: ## 定义一个服务
mall-admin: ## 服务容器配置信息
image: mall/mall-admin:1.0-SNAPSHOT ##镜像,也可通过build 构建镜像,
container_name: mall-admin
ports: ##容器端口
- 8080:8080
volumes: ##任务挂载路径
- /mydata/app/mall-admin/logs:/var/logs
- /etc/localtime:/etc/localtime
environment: ##启动入口
- 'TZ="Asia/Shanghai"'
external_links: ## 链接,通过这个可以做任务之间的依赖,容器之间可以访问。
- mysql:db #可以用db这个域名访问mysql服务
- nacos-registry:nacos-registry #可以用nacos-registry这个域名访问nacos服务
mysql:
image: mysql:5.7
container_name: mysql
command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
restart: always
environment:
MYSQL_ROOT_PASSWORD: root #设置root帐号密码
ports:
- 3306:3306
volumes:
- /mydata/mysql/data/db:/var/lib/mysql #数据文件挂载
- /mydata/mysql/data/conf:/etc/mysql/conf.d #配置文件挂载
- /mydata/mysql/log:/var/log/mysql #日志文件挂载
swarm#
我们上面解决了服务栈,也就是服务之间的依赖问题,但是我们现在都是微服务,需要的是一个服务部署多个机器,如果有上百个服务,成千的机器群,那我们部署排查,那不得忙的不可开交了么。所以docker 推出了swarm 来解决这个问题,就是对服务集群部署的解决。
Swarm 集群是一组被统一管理起来的docker 主机,集群是swarm 所管理的 对象,这些主机通过docker引擎的swarm模式相互沟通,
说白了,swarm是定义一个服务 部署多少个节点(部署在多少个主机上),然后对每个节点的容器服务进行监控管理的。这才是docker 真正运用在企业生产的地方。
Kubernetes#
和swarm 拥有相同 的能力,只不过它更优秀,是谷歌公司开源的项目。
用户可以将配置模版提交之后,kubernetes 会自动管理(包括部署、发布、伸缩、更新)应用容器来维护指定状态。实现了十分高的可靠性 ,用户无需关心细节。
他的核心概念:每个对象包括三大属性:元数据、规范、状态。通过这三个属性,用户可以定义让某个对象处于给定的状态。这些对象存储在 Etcd高可用键值存储对象上(就是key-value形式,这个是分布式的存储,采用简洁的Raft共识算法(这里可以看之前的文章)),他自己本身也用的Raft共识算法来保证 一致性。
这里很重要,但是越来越觉得开发和运维分不开了,这完全是要开发做了运维的工作啊。。。目前用不到,之前尝试搭建过环境,直接把我云主机给干崩了(3个4G内存的机器),等以后用的时候可以在深入的看用法。
参考源:#
- 《Docker技术入门与实战第三版》:机械工业出版社
- 网络博客【https://blog.csdn.net/beanewself/article/details/78317626】