这两天都是在跟文件打交道,很有趣,每一步都不会顺心如意,但每一步的解决都有所获益,首先是对文件变化的监测,能找到很多办法,例如通过ELK家族的Filebeat工具来探测,但是外部工具不好融合进Storm,最好是自己写Java程序来监测。
引入Java NIO 监控文件
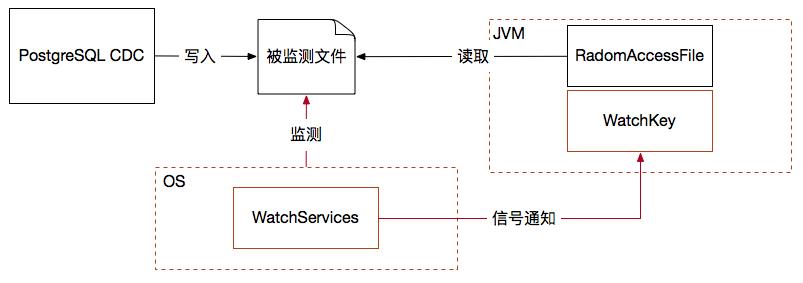
其实jdk7以上版本就有一个比较不错的选择,那就是nio包里的WatchService监控器,我觉得它有两方面的优点,其一就是由操作系统的信号通知机制,当文件目录中出现变化就发信号给应用层监控器,那么这种由操作系统主动通知的效率就远好于应用程序对文件的反复轮巡,而且不占用过多系统资源;其二编程模型并不采用观察者模式注册监听器的方案,而是将多线程问题隐藏起来,客户端对api采取循环阻塞的直观调用,这就非常有利于嵌入到各种运行容器当中去执行文件采集监控。
另外监测文件变化后按行采集变化记录我采用了RadmonAccessFile对象,这个文件操作对象常用于断点续传此类的需求,很方便,关键要设计一个可持久化的位移记录文件,保证采集器重启后总能从未读取的最新变化数据点位置开始采集数据。如下图所示:
文件监控与采集功能嵌入Storm集群之后又出现了一个新问题,那就是Storm spout实例不会如你所愿地运行在指定的机器上,而是完全由Storm集群随机地在节点上指定运行,但被监测的文件位置是固定的,反正总有笨办法:当Storm集群启动后,确定spout运行的机器节点,再由该机器执行cdc文件输出程序,但是这样耦合性太强,必须跟随Storm对spout实例的安排而变化采集位置,维护管理就会很麻烦,而且很容易出错。
引入分布式文件系统
因此我就引出了一个新的假设:通过分布式文件系统(dfs)来解决此问题,但是dfs的选型很重要,Hadoop hdfs肯定不行,它脱离了普通文件系统的操作方式,最终我挑选了两款dfs,一是ClusterFS,二是MooseFS,它们都具有fuse结合功能,通过Mount dfs到本地目录的方式,让访问dfs如同访问本地目录文件一样无缝结合,dfs的任一客户端节点对文件的修改,都会在所有dfs客户端节点上被通知,因此我让Storm的所有节点都成为dfs的客户端,这样无论spout随机运行在任何节点上,都可以在本节点的相同目录中去访问dfs中的被监测的文件,同时被监测文件还具有了多副本的高可靠性。

这种解决分布式计算过程中与分布式存储结合的方案,也就是Storm计算节点由于是集群动态分配位置,无法固定住Storm spout的文件采集位置,因此我选择了分布式文件系统的思路,主要是利用了GlusterFS连接Linux fuse(用户空间文件系统)的办法,使得每一个spout节点都是dfs客户端,那么无论spout被分配在哪个节点,都可以通过监测并读取本节点的GlusterFS客户端挂载(mount)的目录来实现对PostgreSQL cdc输出文件副本的数据采集。
但是测试中发现一个大bug,让我虎躯一震,bug原因分析:
制服Bug的艺术
内置在spout中的Java文件监控器(WatchService)监控目录变化是通过操作系统传递来的信号驱动的,这样spout就可以等待式文件变化实现监控,可是我想当然的以为就算PostgreSQL cdc输出节点与spout文件采集监控节点不是一台机器也可以,只要通过分布式文件系统同步副本,spout节点就一定能感知到当前目录副本的变化,事实上我错了,spout中的watchservice根本就感知不到目录副本的变化,因此想要得到操作系统的文件变化信号通知,必须对文件目录的读写是在一台机器上,才会有文件变化信号发送给上层应用,我之前的测试正确仅仅是因为PostgreSQL输出和spout监控是同一台服务器。
那么问题就来了,我的假设就是spout不用考虑采集点的目录位置,否则逆向根据storm集群分配好spout节点地址后才能进行pg监控,显然这是颠倒流程了,又试过MooseFS和NFS,结果一样,NFS还不如分布式文件系统高效。
当无路可走的时候,认为自己的假设即将失败的时候,一个新的思路开启了我的灵感,为什么非要spout只设置1个并行度呢?按照参与Storm集群拓扑的工作数是3个,那就设置spout并行度为3,这样每一个机器就都会有一个spout监控本地GlusterFS挂载目录,那么无论我的PostgreSQL cdc输出程序是在哪个节点启动,同时只会有一个spout感应到副本变化开始推送数据,其他都是wait,这样就解决了问题,同样也保证了即便是换一个节点进行PostgreSQL cdc文件输出,前一个spout实例自然wait,新的spout就工作了,依然完美地保证了PostgreSQL cdc程序与spout的可靠性冗余。