在上一篇中我们简单总结和介绍了Redis的几个方面
1.使用Redis背景
2.Redis通信多路复用的基本原理
3.Redis基本数据结构
4.Redis持久化方式
这一篇我们使用简单的业务场景来介绍Redis的分布式锁和集群
1.分布式锁
首先我们应该知道什么是分布式锁,用来做什么的,解决了什么问题,我们应该怎么做?
简单来说,分布式锁就是锁住进程的锁,通常我们分布式锁的使用场景在多实例的集群系统中,为了防止多个进程对资源的同时操作,而引发业务逻辑错误而诞生的,和我们的单个实例中的lock作用一样,一个是针对多实例单进程,一个是针对单实例多线程,具体在web中的表现在下面用实例的方式说明。
2.单进程单实例多线程
1.例如现在我们部署了一个服务,他的功能是提供用户来抢红包的接口,我们在发红包时,总共设置了10个红包,我们将红包剩余数存入数据库,所以用一张表来存储红包的个数信息,每当有一个人来抢,我们就需要将红包的个数减掉1,主要的核心业务逻辑如下:
-
1.用户发起抢红包请求,服务器首先查询,红包剩余个数,如果为0,则直接返回,告诉用户红包抢完了
-
2.如果红包个数不为0,则提示用户抢到了红包,然后扣减红包总数。
伪代码如下
//查询剩余红包个数
int RedEnvelopeCount = getRedEnvelopes();
if (RedEnvelopeCount.Count == 0)
{
//返回用户红包抢完了 do something
return;
}
//通知用户抢到了 do something
//扣减红包个数
subtracRedEnvelopeCount();
2.此时如果同一时间多个并发请求进来,我们就会发生多个线程同时执行这段核心逻辑,导致业务错误
-
1.发生
超抢,抢到的人大于实际个数,谁抢到的不算? -
2.发生
少抢,几个人同时抢到同一个,算谁的?
我相信这2种情况,要是在真实的抢红包中,发生到谁头上,都不爽吧?按东哥的话说我都气的想打人
所以我们要着手解决,解决的思路就是,核心业务的代码同一时刻只能被一个线程执行,所以为了保证原子性,我们就需要使用到锁来锁住核心业务代码,在这里我们使用C#的Lock来实现
//静态全局唯一
private readonly static object _lock = new object();
using (_lock)
{
int RedEnvelopeCount = getRedEnvelopes();
if (RedEnvelopeCount.Count == 0)
{
//返回用户红包抢完了
return;
}
//通知用户抢到了
//扣减红包个数
subtracRedEnvelopeCount();
}
3.单进程多实例多线程
上面我们列举并介绍了在单个实例中遇到并发产生的业务问题,我们通过锁的方式来暂时解决了问题,那么接下来我们继续思考,如果红包再多一点,抢的并发量起来了,单台服务器不能承载这么多并发,为了保证高可用,我们需要将红包服务,进行集群部署,利用nginx来负载均衡一下。
1.在单个实例中我们为了保证业务执行的原子性,锁住了核心业务代码,保证同一时刻只有一个线程执行,但是现在多个实例来处理请求,假设现在2个用户提交抢红包的请求,在同一时刻被服务器负载均衡到2台不同的实例,那么此时就会遇到2个进程同时操作核心业务逻辑,超抢和少抢的事情又会发生,瞬间头又大了,那么针对这种业务情况,我们应该使用分布式锁来解决不同进程之间争夺资源的情况。
2.接下来就是我们最后一个问题,如何实现分布式锁,其实对于集群系统实现分布式锁的方式有很多种,基于Zookeeper,Redis,包括数据库,等都可以实现,相较于Zookeeper和数据库 ,Redis单线程对于实现分布式锁拥有天生绝对的优势,而且它操作内存的方式就性能而言是非常优秀的,鉴于咱们这篇博客主要是跟Redis相关的,所以主要介绍使用Redis的方式,当然基于Redis中也存在不同的做法。
3.实现锁的核心业务就是加锁``释放锁这2个功能,我们根据Redis内部单线程执行的原理自己来初步实现一个
//设置key,加锁 防止死锁超时,设置60毫秒自动过期
bool result = database.StringSet("distributed-lock", "lock", expiry: TimeSpan.FromSeconds(60));
//失败说明锁已经被获取,直接返回
if (!result)
{
// "人有点多,再点点...";
return;
}
//获取剩余个数
int RedEnvelopeCount = getRedEnvelopes();
if (RedEnvelopeCount.Count == 0)
{
//返回用户红包抢完了
return;
}
//通知用户抢到了
//扣减红包个数
subtracRedEnvelopeCount();
//释放锁
database.KeyDelete("distributed-lock");
上面实现了最简单和最基础的分布式锁,但是还存在缺陷,仔细思考不难发现
-
1.执行业务的时间大于持有锁的最大时间,导致锁释放,业务还没执行完,乱了那也玩不了
-
2.获取锁后执行到业务代码时抛异常了,锁没及时释放,而是等待自动释放,所以需要加异常处理
我们根据这2个缺陷来进一步完善,解决上面的问题,首先需要先保证执行业务的情况下,谁加的锁由谁来释放,然后添加异常处理代码用于处理业务异常能及时释放锁
//获取Guid作为当前请求唯一身份信息
string value = Guid.NewGuid().ToString("N");
//设置key,加锁,防止死锁超时,设置60毫秒自动过期
bool result = database.StringSet("distributed-lock", value, expiry: TimeSpan.FromSeconds(60));
//失败说明锁已经被获取,直接返回
if (!result) return; // "人有点多,再点点...";
try
{
int RedEnvelopeCount = getRedEnvelopes(); //获取剩余个数
if (RedEnvelopeCount.Count == 0)return; //返回用户红包抢完了
//通知用户抢到了
//扣减红包个数
subtracRedEnvelopeCount();
}
finally
{
//保证由当前请求释放,不会别的进来释放导致乱套
if (value.Equals(database.StringGet("distributed-lock")))
{
//释放锁
bool isDelete = database.KeyDelete("distributed-lock");
}
}
4.最后我们使用StackExchange.Redis提供的方法来实现封装一个分布式锁,首先扩展IServiceCollection 将StackExchange.Redis 操作实例注入
//扩展连接客户端
public static class RedisServiceCollectionExtensions
{
public static IServiceCollection AddRedisCache(this IServiceCollection services, string connectionString)
{
ConfigurationOptions configuration = ConfigurationOptions.Parse(connectionString);
ConnectionMultiplexer connectionMultiplexer = ConnectionMultiplexer.Connect(connectionString);
services.AddSingleton(connectionMultiplexer);
return services;
}
}
//注入容器
services.AddRedisCache("127.0.0.1:6379,password=xxx,connectTimeout=2000");
5.具体利用LockTake通过轮训询问的方式获取锁,通过LockRelease释放锁,在实现的源码中,加锁的原理就是设置一个string类型的key value以及过期时间
public class DistributedLock
{
private readonly ConnectionMultiplexer _connectionMultiplexer;
private IDatabase db = null;
public DistributedLock(ConnectionMultiplexer connectionMultiplexer)
{
_connectionMultiplexer = connectionMultiplexer;
db = connectionMultiplexer.GetDatabase(0);
}
private void FetchLock()
{
while (true)
{
//当前锁的持有时间超过60毫秒就会被释放,这个时间应该设置比被锁住业务执行时间长
bool flag = db.LockTake("distributed-lock", Thread.CurrentThread.ManagedThreadId, TimeSpan.FromSeconds(60));
if (flag) // 1、如果加锁成功直接退出,否则继续获取锁
{
break;
}
Thread.Sleep(10); // 防止死循环。通过等待10毫秒时间,释放资源
}
}
public void UnLock()
{
bool flag = db.LockRelease("distributed-lock", Thread.CurrentThread.ManagedThreadId);
_connectionMultiplexer.Close();
}
}
6.基于Redis实现的分布式锁,在Redis主从或者哨兵乃至集群中,会存在锁丢失的情况,具体就是当请求给Master节点写入锁后,Master节点宕机,此时主从还没来得及同步,但此时已经选择了一个Slaver为主节点,而最开始的设置的锁不见了,针对这种情况比较极端,可以利用Zookeeper来实现分布式锁作为解决方案,因为在数据一致性上Zookeeper是优于Redis的,当然Redis的性能也是较Zookeeper更为突出一些,用CAP理论来定义的话,Zookeeper趋向于CP更关注一致性,Redis趋向于AP更关注可用性.
4.Redis容灾高可用
就服务实例而言,单个服务实例保证容灾和高可用基本很难,因为一个实例随时都有宕机的风险,所以引入了集群的概念,通过多个服务实例,来共同保证系统提供稳定的服务,其实在Redis中也一样,也有保证容灾和高可用的方案,在一定程度上,实现的方案在大的策略层面思路都差不多,只是具体实现的方式不同罢了,至于最终选择保证数据信息层面的高可用,还是性能资源层面的高可用,需要用户去根据自己业务来分析,选择使用哪一种方案。
在Redis中,有3种方式来实现高可用的方案,分别是
-
1.主从模式 (Master Slaver)
-
2.哨兵模式 (Sentinel)
-
3.数据分片 (Cluster)
1.主从模式和哨兵
主从模式是Redis提供高可用的第一种方案,理解起来也比较简单,一个主节点多个从节点,主节点负责写入,然后会把数据同步到从节点,从节点负责读取,但是会存在不可避免的缺陷
-
1.如果宕机,它不具备自动容错和恢复功能,需要手动切换从节点为主节点。
-
2.宕机导致数据未及时同步,降低可用性
-
3.所有节点数据一样,内存浪费,并且在线扩容复杂,伸缩性差,海量数据存储无法解决。
-
4.高并发主节点写入数据压力极大。
哨兵模式是Redis提供的第二种方案,可以说是第一种主从方案的完善版本,因为它在主从的基础上,增加了监控功能,主节点宕机后提供哨兵自动选举master并将其他的slave指向新的master,哨兵是一个独立运行的进程,它的实现原理是哨兵进程向所有的redis机器发送心跳消息,从而监控运行状况,同样由于是基于主从而诞生,那么也存在主从中的一些缺陷。
2.集群分片模式
1.集群和分片基本概念
前面2种方案归根结底,就是使用主从复制和读写分离的方式保证高可用,但是内存占用,主节点压力过大,相较于Redis提供的第三种集群和数据分片的方案,存在的缺陷也非常明显,下面我们介绍集群和数据分片。
1.
集群和数据分片简单理解就是将主从复制的核心策略,做了集群来横向扩展,包含多个主从节点,采用去中心化思想,数据按照 slot 存储分布在多个节点,并且节点间数据共享,可动态调整数据分布,
2.在集群中每一个节点都是
互相通信采用Gossip病毒协议,在一个节点写入的数据,其他任何节点都会查询到。
2.集群内部数据存取原理
1.
Slot槽,存储数据的容器,总共16384个Slot ,采用平均分配,并且只有主节点才能被分配
2.
Hash算法用于对数据进行计算,得到一个Hash值,然后对16384取模选择存到哪个区间的Slot
3.Windows下集群搭建
1.我们部署集群使用redis-trib.rb,首先下载环境 提取码1234
2.安装需要用到Ruby语言运行环境,然后进入安装目录Ruby22-x64中,通过gem命令安装文件
gem install –-local youFloder\redis-3.2.2.gem
3.准备Redis服务实例,此处准备6个实例,并配置Redis配置文件,然后启动每一个服务实例
redis-server redis-6380.conf
redis-server redis-6381.conf
....
....
port 6380 #节点端口
bind 127.0.0.1 #节点主机ip
appendonly yes 开启aof
appendfilename "appendonly.6380.aof"
cluster-enabled yes
cluster-config-file nodes.6380.conf
cluster-node-timeout 15000
cluster-slave-validity-factor 10
cluster-migration-barrier 1
cluster-require-full-coverage yes
3.进入到redis-trib.rb目录打开命令窗口,进行搭建集群
ruby redis-trib.rb create -–replicas 1 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385
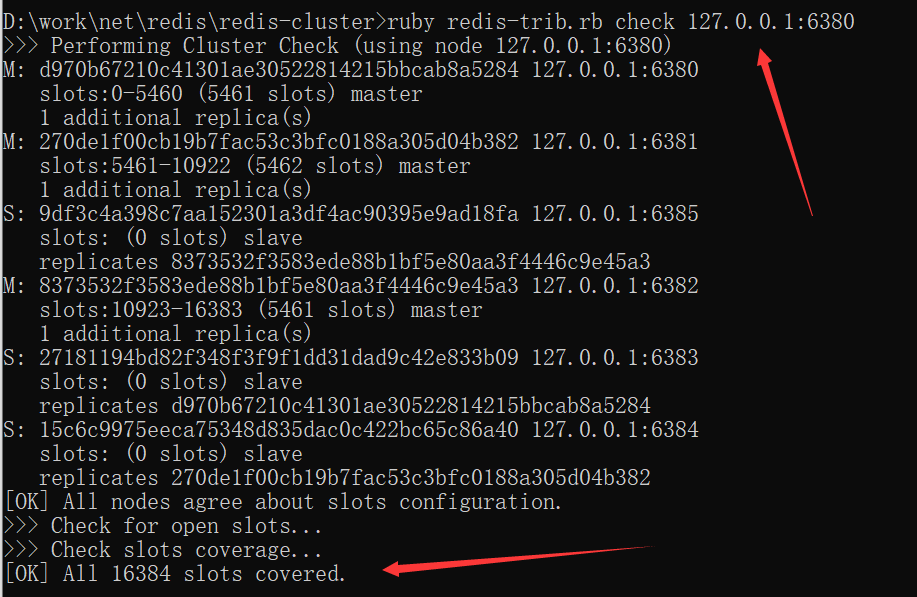
4.检查集群状态,出现图片中的提示代表搭建成功
ruby redis-trib.rb check 127.0.0.1:6380