本文介绍了ICASSP2022 DNS Challenge和AEC Challenge第一名百度的技术方案。该方案提出了一种信号处理-深度学习混合式方法(hybrid method),同时抑制回声、噪声和混响。其中信号处理部分利用线性回声消除算法为深度神经网络提供条件信息(conditional information);而深度学习部分提出了一种语音密集预测网络(speech dense-prediction backbone),其中包括麦克风接收信号和参考信号的相位编码器、多尺度时频处理和流式轴向注意力(axial attention)机制等策略。该系统在ICASSP2022年AEC和DNS挑战赛(非个性化赛道)中均排名第一,并扩展到多通道在ICASSP2022 L3DAS22 Challenge中获得第二名
论文题目:Multi-scale temporal frequency convolutional network with axial attention for speech enhancement
作者:Guochang Zhang, Libiao Yu, Chunliang Wang, Jianqiang Wei (百度语音技术部)
欢迎关注公众号[语音智能] 手机即可关注最新推文
背景动机
线性回声消除常用于语音通信中的声学回声抑制,然而,扬声器的非线性失真等效应严重影响线性回声消除的性能。由于深度神经网络相比传统信号处理对于残留回声、噪声和混响具有更强的抑制能力。因此本文结合信号处理和神经网络提出一个同时去噪去混响和回声抑制的系统。其中,信号处理部分包括基于广义互相关的时延对齐模块和基于PNLMS双滤波器结构的线性回声消除模块;而神经网络部分是作者提出的基于轴向自注意力的多尺度时频卷积神经网络(multi-scale temporal frequency convolutional network with axial self-attention, MTFAA-Net)框架,本论文主要有以下两点贡献:
- 为了消除回声,不同于以往的线性AEC与DNN的直接级联,本文只使用线性AEC输出作为DNN的条件信息,即:除了将线性AEC的输出和参考信号作为网络输入外,还将传声器接收信号作为网络输入,从而避免将线性AEC引起的失真引入到网络输入;
- 本文提出了一种语音密集预测任务的架构,设计了相位编码器(Phase Encoder, PE)、多尺度时频处理和流式轴向自注意力(Axial Self-attention, ASA)来提高模型性能。经过PE后利用频带合并模块(Band Merging, BM)将STFT域信号转换成等效矩形带宽(Equivalent Rectangular bandwidth, ERB)域以降低全带信号处理时的计算复杂度,并在经过网络学习后使用频带分解(Band Splitting, BS)操作变换回STFT域。
模型框架
下图展示了系统框架,其中MTFAA-Net由PE、BM和BS、掩码估计和应用(masking estimating and applying, MEA)模块和主网络(Main-Net)组成。主网络由频率下采样(Frequency Downsampling, FD)或频率上采样(Frequency Upsamling, FU)、T-F卷积和ASA组成的模块堆叠而成。
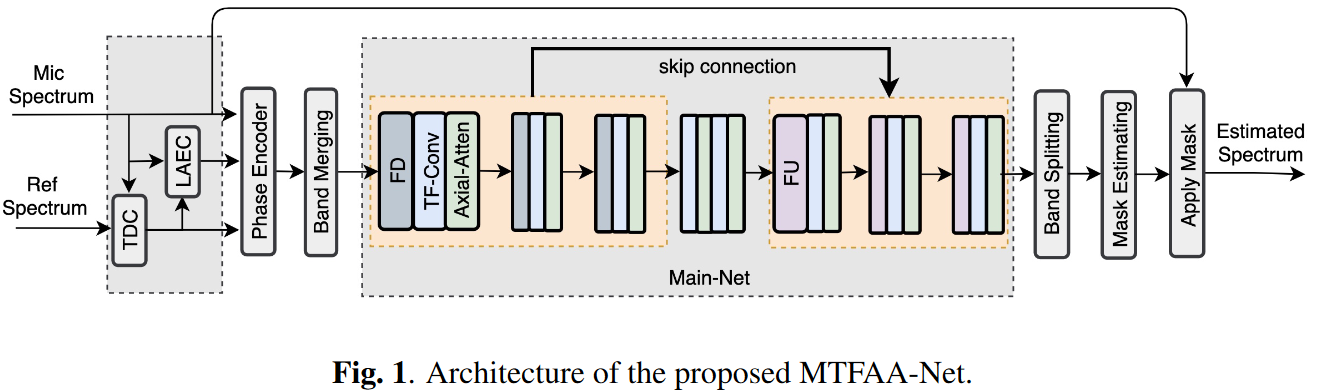
相位编码层:实值网络(这里的实值是指相对DCCRN等的复值网络的概念)更容易实现并在许多数据集上取得优异的结果,因此网络的主要部分采用实值网络。相位编码器用于将复数谱特征转换到实数域。在PE模块中,有三个复值卷积层,分别接收传声器接收信号、线性AEC输出和远端参考信号。复值卷积层的卷积核大小和步长分别为(3,1)和(1,1)。此外,PE还包含复值-实值转换层和特征动态范围压缩(feature dynamic range compression, FDRC)层(就是SDD-Net中的功率压缩),其中FDRC用于压缩语音特征的动态范围,使网络更鲁棒。

频带合并与分解:由于语谱信息在频率维度上分布不均匀,高频段存在大量冗余特征,本文将STFT域转换到ERB域以减少冗余。
时频卷积模块(TFCM):本文的卷积模块将时序卷积网络(Temporal Convolutional Network, TCN)中的一维空洞卷积代替为二维空洞卷积,卷积核大小为(3,3),B个空洞率从1到的二维卷积形成一个TFCM。依次达到小卷积核下多尺度建模时频信息的目的。

轴向自注意力机制:自注意力机制可以提高网络捕捉远距离特征之间关系的能力,本文提出的ASA可以减少对内存和计算的需求,更适合于语音等长序列信号,如下图所示。ASA的注意得分矩阵分别沿频率轴和时间轴计算,分别称为F-attention和T-attention。分数矩阵可以表示为
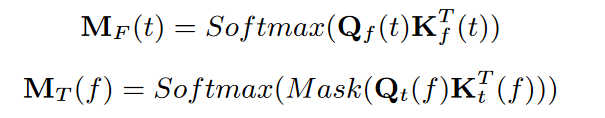
其中Mask()保证网络只是用输入矩阵的上三角部分,从而保证系统因果。

频率下采样和上采样:频率下采样(FD)层如下图左图所示,是一个包含二维卷积层、batchnorm 和PReLU的卷积模块;频率上采样(FU)层则是带门控融合的反卷积模块,如下图右图所示(应该是参考了SNNet)。FD和FU用于提取多尺度特征,然后在每个尺度上采用TFCM和ASA进行特征建模,提高了网络对特征的描述能力。二维卷积和反卷积层的卷积核大小为(1,7),步长为(1,4),分组数为2。

掩蔽估计和应用:掩蔽估计和应用包含两个阶段,第一阶段是按照DeepFilter的形式将尺寸为(2V+1,2U+1)的实值掩蔽作用在幅度谱上,第二阶段估计复值掩蔽作用在幅度和相位谱上(和PHASEN的形式一样)。


模型参数:帧长32ms、帧移8ms的STFT复谱作为网络输入,因此系统总延迟为40ms。FDRC压缩系数为0.5,ERB的频带数为256。PE中复数卷积层的输出通道数为4。3个FD的输出通道数分别为48、96、192。一个TFCM中含有6个二维卷积块。ASA中的通道数为输入通道的1/4。MEA的实值掩蔽尺寸为(3,1)(推测应该是V=1,U=0)。采用STFT一致的幂律压缩谱均方误差作为损失函数。我们以学习率为5e-4的Adam作为优化器。我们训练MTFAA-Net为300k步,batch size为16。
数据及结果
使用DNS挑战赛的语音和噪声进行训练,VCTK语音集和DEMAND噪声集进行评估。AEC挑战赛训练和验证集的远端单讲被用作AEC的训练和评估。采用镜像源法分别获取10万对和1000对混响时间在0.1s到0.8s的RIR进行训练和评估。所有语句均为48kHz采样率。训练时信噪比(SNR)和回波信号比(SER)分别为[-5,15]dB和[-10,10]dB,评估时SNR和SER分别为[0,10]dB和[- 5,5]dB。



在AEC Challenge和DNS Challenge中都取得第一名,并大幅度优于PoCoNet等语音增强模型。
MTFAA-Net的乘累加操作数约为每秒2.4G。Python实现的系统实时系数(RTF)约为0.6(在使用Intel Core i5 Core的MacBook Pro上),满足实时性处理要求。
本文所有图片均来自Multi-scale temporal frequency convolutional network with axial attention for speech enhancement