-
SegNet & DeconvNet——论文阅读
一、DeconvNet
1、提出背景
此前的语义分割方法主要基于全卷积网络 (Fully Convolutional Networks, FCN),这种方法通过卷积层逐渐下采样并生成粗略的标签映射,随后用双线性插值或条件随机场 (CRF) 进行细化。然而,FCN 存在两个主要问题:
- 尺度不一致:FCN 使用固定大小的感受野,导致难以捕捉到大小相差悬殊的物体,较大的物体会被切割成不一致的部分,较小的物体可能被忽略。
- 细节损失:FCN 生成的标签图较为粗糙,导致物体的边缘细节难以恢复。
DeconvNet 引入了逆卷积网络 (Deconvolution Network),旨在解决上述问题,以实现更加精细的语义分割效果
2、模型设计
(1)整体架构

如上图,展示了整个深度网络的详细配置。我们训练的网络由卷积网络和反卷积网络两部分组成。卷积网络对应于将输入图像转换为多维特征表示的特征提取器,而反卷积网络是一个形状生成器,从卷积网络提取的特征中产生对象分割。网络的最终输出是一个与输入图像大小相同的概率图,表示每个像素属于预定义类之一的概率。
(2)Unpooling
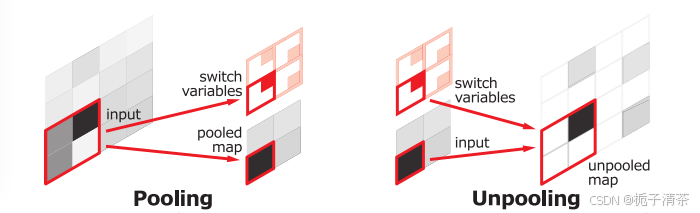
在卷积过程中,池化会导致空间信息丢失。DeconvNet 通过记录池化位置,并在反池化层中还原激活的空间位置,恢复细节。
(3)Deconvolution
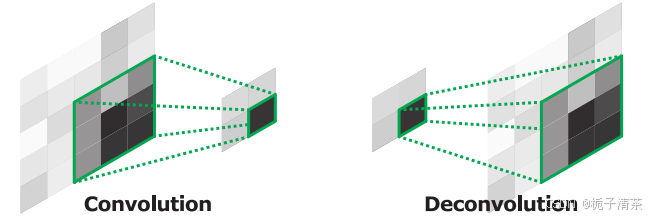
通过卷积反向操作,将稀疏的激活映射变为密集的输出。逆卷积的层次结构捕捉不同级别的细节,底层层次关注物体的粗略形状,高层则关注特定类别的细节信息。
3、优缺点
(1)优点:
- 细节保留:通过逆卷积和反池化操作,DeconvNet 能够逐层重建物体的细节结构,相较于 FCN 有显著提升。
- 多尺度处理:通过对每个对象候选区域单独处理,DeconvNet 能够自适应多尺度物体,不受固定感受野的限制。
- 优异表现:在 PASCAL VOC 2012 数据集上,该模型的性能超越了多数不使用外部数据的模型,与 FCN 的集成提升了整体分割精度。
(2)缺点:
- 计算复杂度高:DeconvNet 的双网络结构使其计算复杂度较高,对硬件资源要求较大。
- 依赖候选区域:由于使用候选区域进行实例级分割,依赖物体检测的准确性,可能会导致误检或漏检的情况。
- 训练数据量需求高:为了优化深层模型,模型设计了批归一化和分阶段训练策略,但仍对数据量较为依赖(DeconvNet)。
总的来说,DeconvNet 在解决 FCN 缺点的基础上,通过逆卷积网络结构在语义分割任务上取得了显著的效果。
二、SegNet
1、提出背景
SegNet旨在处理语义分割任务中的像素级标注。传统的图像分类网络在语义分割任务中表现较差,因为图像经过多次下采样后,分辨率降低,细节信息丢失,从而导致边界模糊。SegNet 主要针对这些问题,通过引入编码器-解码器结构实现更精确的边界定位,特别适用于场景理解等应用需求
2、模型设计

SegNet 的核心是一个编码器-解码器架构,分为三个主要部分:编码器、解码器和像素级分类层。
- 编码器:采用与 VGG16 网络类似的架构,由 13 层卷积层组成,用于提取特征。编码器执行最大池化操作以降低空间分辨率并增强特征的语义信息。
- 解码器:每个解码器层与相应的编码器层相匹配,通过编码器的池化索引进行非线性上采样,从而复原分辨率。在解码过程中,上采样后的稀疏特征图通过卷积操作变为密集特征图,以便进行像素级分类。与其他解码器不同,SegNet 的解码器无需学习上采样过程。
- 分类层:最终解码器输出的特征图被送入 softmax 分类器,为每个像素提供类别概率,从而实现精确的像素分类。
3、优缺点
(1)优点:
- 边界精度:通过保留编码器的池化索引,SegNet 能更好地恢复边界细节,提高物体边缘的精确性。
- 内存效率:由于仅存储池化索引而非特征图,SegNet 在推理过程中节省了大量内存,非常适合嵌入式应用。
- 模型轻量:相比其他包含全连接层的网络,SegNet 大幅减少了参数数量(从 VGG16 的 134M 降至 14.7M),因此更易于训练和部署。
(2)缺点:
- 缺乏多尺度信息:SegNet 的解码方式在处理复杂多尺度物体时表现欠佳,因为编码特征在多次池化后可能丢失细节。
- 边界细节依赖池化索引:虽然 SegNet 通过池化索引恢复细节,但与完整的特征图相比,其重建的细节不够丰富。
- 计算资源需求高:虽然 SegNet 在内存上具备优势,但依然需要较高的计算资源,尤其是在大数据集上的训练。
总的来说,SegNet 提供了一种高效、实用的语义分割解决方案,适用于需要精准边界细分且计算资源受限的场景,如自动驾驶和增强现实等。
三、SegNet 在 DeconvNet 上有哪些改进?
SegNet 在 DeconvNet 基础上优化了内存和计算需求,通过复用池化索引的上采样方法显著提升了边界细节的保留能力,并且更易于在端到端训练中获得良好性能,非常适合对效率和内存有要求的应用。
-
相关阅读:
使用Python将PDF转为图片
Codeforces Round 932 (Div. 2) ---- E. Distance Learning Courses in MAC ---- 题解
cesium实战记录(二)三维模式下测量工具的封装
vue3开发快速入门
8. 无线体内纳米网:基于蓝牙LE接口的数字ID系统
FFmpeg常用命令行讲解及实战一
Unix/C/C++进阶--pthread 跨平台
29.7.3 问题解决
小红书笔记详情API:挖掘小红书社区的秘密宝藏
C++学习 day--20 new和delete关键字
- 原文地址:https://blog.csdn.net/qq_55009448/article/details/143300369