-
存储课程学习笔记5_iouring的练习(io_uring,rust_echo_bench,fio)
我们知道,在处理大量高并发网络时,一般考虑并发,以及设计对应的方案(比如select,poll,epoll)等。
那么如果频繁进行文件或者磁盘的操作,如何考虑性能和并发,这里就可以考虑用到io_uring。
0:总结
1:实际上主要用liburing库对io_uring的使用进行测试。
2:使用新的开源库,实际上从库中对应的example中开始进行逻辑分析是最合理的。
3:io_uring 高效异步IO方案,可以用于磁盘,数据库,大规模io处理,网络等方向(这里以作为tcp server测试)。
4:可以用开源库rust_echo_bench 对服务器性能进行测试。
5:可以用fio对磁盘读写性能进行测试
1:环境准备
使用io_uring需要linux内核的支持,linux内核(注意版本)中提供了对io_uring的支持,主要是三个系统调用io_uring_setup,io_uring_register,ui_uring_enter。
使用liburing(已经进行必要的封装)对io_uring的调用测试(可以分析相关源码调用上面三个接口的逻辑)。
安装liburing库,测试相关demo。
tar -zxvf liburing-liburing-2.6.tar.gz cd liburing-liburing-2.6/ ./configure make sudo make install2:简单分析实现流程。
总流程分析:
===》1:初始化一个struct io_uring 对象,核心对象。
===》2:构造必要的struct io_uring_sqe对象,该结构体有个字段opcode,作为操作码识别要执行的操作。 比如缓冲区的读,写,以及网络支持的connect或者accept,以及其他相关。
===》3:把构造的sqe提交给内核。
===》4:等待事件的完成 io_uring_wait_cqe会阻塞等待cqe的返回。 (可以研究等待时间)
===》5:从cqe中取出已经完成的事件,进行处理。
===》6:最后,依次重复上面的循环,按业务进行处理。
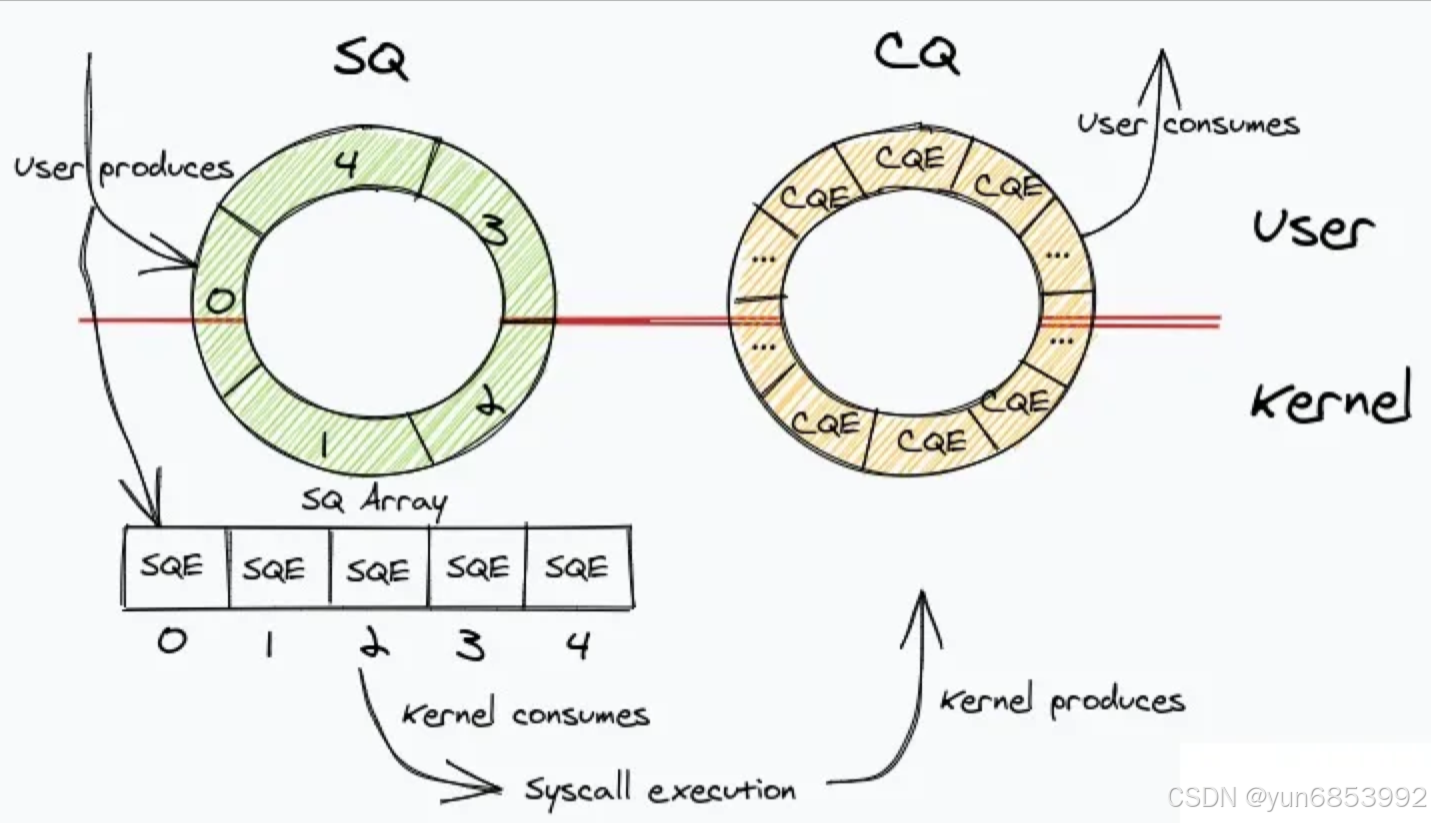
//可以参考liburing下的相关example有各种功能的demo //初始化一个struct io_uring 对象 struct io_uring ring; int ret = io_uring_queue_init(128, &ring, 0); //设置ringbuffer大小128 //构造sqe对象 这里构造支持的是accept接收的对象 直接用liburing中封装的接口 struct io_uring_sqe *sqe = io_uring_get_sqe(ring); io_uring_prep_accept(sqe, sockfd, addr, addrlen, flags); //每一个cqe构造后,要提交后才有效 //这里以网络场景为demo 文件fd的操作逻辑一样。 while(1) { io_uring_submit(&ring); //等待已经完成的事件 liburing会把上面的sqe事件请求结果放入cqe中 进行处理 struct io_uring_cqe *cqe; io_uring_wait_cqe(&ring, &cqe); //阻塞等待至少一个事件完成 //直接拿出多个已完成事件 struct io_uring_cqe *cqes[10]; int cqecount = io_uring_peek_batch_cqe(&ring, cqes, 10); //对cqes中的事件进行处理 其他业务... }在网上随便找了一个图,实际上要处理的事件放入sq队列中,已经完成的事件从下面的cq队列中取出,其他由内核底层支持:
3:简单实现一个tcp server代码demo
异步io
io_uring提供了两个进程和内核共享的队列:提交队列(submission queue, SQ)和完成队列(completion queue, CQ)。进程只需要向队列提交I/O请求即可,支持一次性多个io请求提交。这里在测试时想到有关非阻塞io的概念,非阻塞时针对操作fd时read write函数时的操作,这里异步不涉及。
#include#include #include #include #include "liburing.h" #include #include #include #include enum { EVENT_ACCEPT = 0, EVENT_READ, EVENT_WRITE }; typedef struct _conninfo { int connfd; int event; } conninfo; int init_sock(); void print_client_info(struct sockaddr_in *client_addr); void set_accept_event(struct io_uring *ring, int sockfd, struct sockaddr *addr, socklen_t *addrlen, int flags); void set_recv_event(struct io_uring *ring, int sockfd, void *buf, size_t len, int flags) ; void set_send_event(struct io_uring *ring, int sockfd, void *buf, size_t len, int flags); int main() { //初始化socket 创建并bind listen int sockfd = init_sock(); if(sockfd < 0){ return -1; } //初始化io_uring实例 简单的用io_uring_queue_init 额外参数设置可以用 io_uring_queue_init_params //实际上io_uring_queue_init 内部调用的也是 io_uring_queue_init_params struct io_uring ring; int ret = io_uring_queue_init(128, &ring, 0); if (ret < 0) { fprintf(stderr, "queue_init: %s\n", strerror(-ret)); { return 1; } //可以用额外参数设置 特定行为 研究参数结构体struct io_uring_params,设置sqe cqe 大小,设置iopoll模式来进行 I/O 完成事件等待,默认是通过阻塞方式等待 // struct io_uring_params params; // memset(¶ms, 0, sizeof(params)); // struct io_uring ring; // io_uring_queue_init_params(1024, &ring, ¶ms); //定义用于执行accept操作事件 这里定义用于存储连接客户端的信息。 struct sockaddr_in clientaddr; socklen_t clilen = sizeof(struct sockaddr); //获取sqe用于提交异步执行的accept操作 需要设置sqe中对应的user_data 的标志 用于标志对应事件 set_accept_event(&ring, sockfd, (struct sockaddr*)&clientaddr, &clilen, 0); //只是简单的测试demo 打印回环发送 公用一个buffer char buffer[1024] = {0}; //已经accept了,开始进行服务器实现。 conninfo ci; while(1) //每一次的事件都要进行提交才有效 io_uring_submit(&ring); //等待已经完成的事件 liburing会把上面的sqe事件请求结果放入cqe中 进行处理 struct io_uring_cqe *cqe; io_uring_wait_cqe(&ring, &cqe); struct io_uring_cqe *cqes[10]; int cqecount = io_uring_peek_batch_cqe(&ring, cqes, 10); //已经获取到已经完成的事件 一一进行分别处理 for(int i=0; i<cqecount; i++) { cqe = cqes[i]; //获取对应的事件 一一进行处理 获取自己上面设置过的事件 进行实际处理 memcpy(&ci, &cqe->user_data, sizeof(ci)); //对不同的事件进行处理 if(ci.event == EVENT_ACCEPT){ if (cqe->res < 0) continue; // 对完成结果先进行判断 如果负数 则表示失败 正数 则返回的连接fd //说明已经有了一个连接 进行打印 printf("connectfd : %d ", cqe->res); print_client_info(&clientaddr); //对原有的fd进行继续accent set_accept_event(&ring, ci.connfd, (struct sockaddr*)&clientaddr, &clilen, 0); //对新的fd进行recv事件的监听 set_recv_event(&ring, cqe->res, buffer, 1024, 0); } else if (ci.event == EVENT_READ) { //投递读请求 注意读完数据 简单demo if (cqe->res < 0) continue; // 对完成结果先进行判断 如果负数 则表示失败 正数 则返回的数据长度吧 if (cqe->res == 0) { //这里用户数据已经放入了 连接fd了 printf("close socket fd: %d \n", ci.connfd); close(ci.connfd); } else { printf("recv --> %s, %d\n", buffer, cqe->res); //根据业务 简单实现 回复事件的投递 set_send_event(&ring, ci.connfd, buffer, cqe->res, 0); } } else if (ci.event == EVENT_WRITE) { // 上面set_send_event 投递了发送 这里已经发送完成了 if (cqe->res < 0) //cqe只展示了返回结果 { printf("send data error: %d \n", cqe->res); // continue; }else printf("send success --> %s, %d\n", buffer, cqe->res); //继续进行监听 那如果超过1024字节 会怎样? memset(buffer, 0, 1024); set_recv_event(&ring, ci.connfd, buffer, 1024, 0); //注意 这里的res是send返回的结果 不是上面的connfd } } io_uring_cq_advance(&ring, cqecount); } return 0; } void print_client_info(struct sockaddr_in *client_addr) { char client_ip[INET_ADDRSTRLEN]; // 缓存用于存储IP地址的字符串 int client_port; // 将IP地址转换为字符串形式 inet_ntop(AF_INET, &(client_addr->sin_addr), client_ip, INET_ADDRSTRLEN); // 将端口号从网络字节序转换为主机字节序 client_port = ntohs(client_addr->sin_port); // 打印客户端的IP地址和端口 printf("Client IP:Port===> %s:%d \n", client_ip, client_port); } int init_sock() { int sockfd = socket(AF_INET, SOCK_STREAM, 0); // io struct sockaddr_in servaddr; memset(&servaddr, 0, sizeof(struct sockaddr_in)); // servaddr.sin_family = AF_INET; servaddr.sin_addr.s_addr = htonl(INADDR_ANY); // 0.0.0.0 servaddr.sin_port = htons(9999); int reuse = 1; // 开启可重用选项 if (setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse)) < 0) { perror("setsockopt(SO_REUSEADDR) failed"); // 处理错误情况 return -1; } if (-1 == bind(sockfd, (struct sockaddr*)&servaddr, sizeof(struct sockaddr))) { printf("bind failed: %s", strerror(errno)); return -1; } listen(sockfd, 10); printf("socket fd has listen: 9999。\n"); return sockfd; } void set_accept_event(struct io_uring *ring, int sockfd, struct sockaddr *addr, socklen_t *addrlen, int flags) { // 获取一个空闲的SQE(Submission Queue Entry)来设置要提交的I/O操作请求 struct io_uring_sqe *sqe = io_uring_get_sqe(ring); io_uring_prep_accept(sqe, sockfd, addr, addrlen, flags); conninfo info_accept = { .connfd = sockfd, .event = EVENT_ACCEPT, }; memcpy(&sqe->user_data, &info_accept, sizeof(info_accept)); } //同样获取sqe 投递recv事件 同时修改userdata标志 方便后面处理 void set_recv_event(struct io_uring *ring, int sockfd, void *buf, size_t len, int flags) { struct io_uring_sqe *sqe = io_uring_get_sqe(ring); io_uring_prep_recv(sqe, sockfd, buf, len, flags); conninfo info_recv = { .connfd = sockfd, .event = EVENT_READ, }; memcpy(&sqe->user_data, &info_recv, sizeof(info_recv)); } //投递发送数据 buffer已经放入 void set_send_event(struct io_uring *ring, int sockfd, void *buf, size_t len, int flags) { struct io_uring_sqe *sqe = io_uring_get_sqe(ring); io_uring_prep_send(sqe, sockfd, buf, len, flags); conninfo info_send = { .connfd = sockfd, .event = EVENT_WRITE, }; memcpy(&sqe->user_data, &info_send, sizeof(info_send)); } 4:编译后进行测试
这里实现的是一个回环的功能,客户端发来的数据会原本回馈
#这是对应测试代码的测试结果 两个网络助手 一个telnet进行测试 ubuntu@ubuntu:~/start_test$ gcc uring_server.c -o uring_server -luring ubuntu@ubuntu:~/start_test$ ./io_uring socket fd has listen: 9999。 connectfd : 5 Client IP:Port===> 127.0.0.1:44104 connectfd : 6 Client IP:Port===> 192.168.40.1:63174 recv --> http://www.cmsoft.cn QQ:10865600, 32 send success --> http://www.cmsoft.cn QQ:10865600, 32 connectfd : 7 Client IP:Port===> 192.168.40.1:63186 recv --> 123456789, 9 send success --> 123456789, 9 close socket fd: 5 close socket fd: 7 close socket fd: 6 #同时 这里发现 客户端发送很长的数据,服务端也能依次正常收到 然后发送给客户端客户端用网络传输助手,和telnet 指令进行测试
ubuntu@ubuntu:~$ telnet 127.0.0.1 9999 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. 123456789 123456789 ^] telnet> quit #这里的退出 按键ctrl+] 进入指令这里 输入quit退出telnet Connection closed.5:借助开源库rust_echo_bench可以测试服务器网络请求性能(测试io_uring和epoll之间的性能)
ubuntu@ubuntu:~/uring$ git clone https://github.com/haraldh/rust_echo_bench.git ubuntu@ubuntu:~/uring/rust_echo_bench$ cat .git/config [core] repositoryformatversion = 0 filemode = true bare = false logallrefupdates = true [remote "origin"] url = https://github.com/haraldh/rust_echo_bench.git fetch = +refs/heads/*:refs/remotes/origin/* [branch "master"] remote = origin merge = refs/heads/master #启动io_uring实现的tcp server服务 ubuntu@ubuntu:~/uring/rust_echo_bench$ gcc uring_server.c -o uring_server -luring ubuntu@ubuntu:~/uring/rust_echo_bench$ ./uring_server #测试io_uring ubuntu@ubuntu:~/uring/rust_echo_bench$ cargo run --release -- --address "127.0.0.1:9999" --number 1000 --duration 20 --length 512 Finished release [optimized] target(s) in 0.09s Running `target/release/echo_bench --address '127.0.0.1:9999' --number 1000 --duration 20 --length 512` Benchmarking: 127.0.0.1:9999 1000 clients, running 512 bytes, 20 sec. Speed: 43747 request/sec, 43716 response/sec Requests: 874941 Responses: 874321 ubuntu@ubuntu:~/uring/rust_echo_bench$ cargo run --release -- --address "192.168.40.129:9999" --number 1000 --duration 20 --length 512 Finished release [optimized] target(s) in 0.07s Running `target/release/echo_bench --address '192.168.40.129:9999' --number 1000 --duration 20 --length 512` Benchmarking: 192.168.40.129:9999 1000 clients, running 512 bytes, 20 sec. Speed: 45077 request/sec, 45047 response/sec Requests: 901542 Responses: 900947 #测试epoll 启动对应epoll实现的tcp server服务 ubuntu@ubuntu:~/uring/uring-main$ gcc multi-io.c -o multi-io ubuntu@ubuntu:~/uring/uring-main$ ./multi-io #进行测试 ubuntu@ubuntu:~/uring/rust_echo_bench$ cargo run --release -- --address "192.168.40.129:9999" --number 1000 --duration 20 --length 512 Finished release [optimized] target(s) in 0.09s Running `target/release/echo_bench --address '192.168.40.129:9999' --number 1000 --duration 20 --length 512` Benchmarking: 192.168.40.129:9999 1000 clients, running 512 bytes, 20 sec. Speed: 47051 request/sec, 47031 response/sec Requests: 941026 Responses: 940637 ===>经过测试 当前局域网环境,网络上 1000个链接 20s 512byte epoll和io_uring性能差距不大6:借助fio可以测试磁盘的读写性能。
6.1 安装fio
tar -zxvf fio-fio-3.37.tar.gz cd fio-fio-3.37/ ./configure make sudo make install6.2 fio相关参数 和结果报告中参数说明
#使用fio进行测试 相关参数描述 当使用FIO进行磁盘测试时,可以使用多个参数来配置测试的行为。以下是一些常用的参数及其作用: --name:指定测试作业的名称。 --ioengine:指定底层I/O引擎,例如sync、libaio、mmap等。 --rw:指定读写模式,如randread(随机读)、randwrite(随机写)、read(顺序读)、write(顺序写)等。 --bs:指定块大小,单位可以是字节(B)、千字节(KB)、兆字节(MB)或者块大小(如4K)。 --numjobs:指定并发线程数。 --size:指定测试数据的大小,单位同样可以是B、KB、MB或者以块大小为单位。 --runtime:指定测试运行时间。 除了上述基本参数外,还有其他一些高级配置选项可供选择: --iodepth: 指定每个工作线程在队列中同时挂起的I/O请求数量,默认值为1. 每个工作线程可以同时请求io的数量,一起执行,等待完成后再下一次。 --ramp_time: 指定测试开始前的预热时间,默认为0秒. --filename: 指定测试使用的文件名或设备路径. --group_reporting: 将报告显示合并为一个总结报告结果中相关参数说明:
#对结果进行分析 Run status group 0 (all jobs): READ: bw=16.0MiB/s (16.8MB/s), 16.0MiB/s-16.0MiB/s (16.8MB/s-16.8MB/s), io=321MiB (337MB), run=20001-20001msec READ: 表示该作业是一个读取操作。 bw=16.0MiB/s (16.8MB/s): 读取速度为16.0 MiB/s(或者可以理解为16.8 MB/s)。 16.0MiB/s-16.0MiB/s (16.8MB/s-16.8MB/s): 表示读取速度范围在16.0 MiB/s到16.0 MiB/s之间(或者可以理解为范围在16.8 MB/s到16.8 MB/s之间)。 io=321MiB (337MB): 总共读取了321 MiB的数据(或者可以理解为337 MB)。 run=20001-20001msec:该作业运行时间为20001毫秒。 这些统计信息提供了关于读取操作的性能和工作情况的细节 Disk stats (read/write): dm-0: ios=223993/4, sectors=1791944/32, merge=0/0, ticks=39208/0, in_queue=39208, util=98.14%, aggrios=225391/3, aggsectors=1803128/32, aggrmerge=0/1, aggrticks=36357/1, aggrin_queue=36359, aggrutil=98.06% sda: ios=225391/3, sectors=1803128/32, merge=0/1, ticks=36357/1, in_queue=36359, util=98.06% 这段输出结果描述了磁盘统计信息,包括读取和写入操作的情况。下面是对每个字段的解释: dm-0: 这是一个逻辑卷设备(logical volume)的名称。 ios=223993/4: 总共进行了223,993次读取操作和4次写入操作。 sectors=1791944/32: 读取了1,791,944个扇区(sector),写入了32个扇区。 merge=0/0: 没有发生合并操作。 ticks=39208/0: 读取操作耗时39,208个时钟滴答,写入操作没有耗时。 in_queue=39208: 当前队列中等待执行的I/O请求数量。 util=98.14%: 磁盘利用率达到了98.14%,表示磁盘处于高负载状态。 接下来是针对整个磁盘设备(sda)的统计信息: ios=225391/3: 总共进行了225,391次读取操作和3次写入操作。 sectors=1803128/32:读取了1,803,128个扇区,写入了32个扇区。 merge=0/1:未发生合并操作,但可能进行了一次分散或聚集操作。 ticks=36357/1:读取操作耗时36,357个时钟滴答,写入操作耗时1个时钟滴答。 in_queue=36359:当前队列中等待执行的I/O请求数量。 util=98.06%:磁盘利用率达到了98.06%,表示磁盘处于高负载状态。 这些统计信息可以帮助评估磁盘的性能和负载情况,例如通过观察读取和写入操作的数量、扇区数以及耗时情况,可以了解磁盘的工作状态和效率。同时也可以关注磁盘队列中等待执行的I/O请求数量,以及磁盘利用率来评估系统的整体性能。6.3 使用fio简单进行测试磁盘性能。
fio提供了不同的 读写磁盘的io引擎方式,比如sync,libaio, io_uring,mmap等,可以分别测试。
测试前可以用dd指令创建合适大小的文件,改变–filename参数进行测试,这里直接用nvme磁盘测试。
可以控制变量,改变不同的参数查看结果进行对比,如果,如果改变–numjobs指定并发线程数,观察性能变化。
#简单使用fio对磁盘读,写性能进行测试。 #测试posix api read/write psync (简写 io引擎) #查看支持的io引擎 root@ubuntu:/home/ubuntu/uring/fio-fio-3.37# ./fio --enghelp Available IO engines: cpuio mmap sync psync vsync pvsync pvsync2 null net netsplice ftruncate filecreate filestat filedelete dircreate dirstat dirdelete exec posixaio falloc e4defrag splice mtd sg io_uring io_uring_cmd libaio #测试随机读 root@ubuntu:/home/ubuntu/uring/fio-fio-3.37# ./fio --name=test --ioengine=psync --iodepth=1 --rw=randread --bs=4k --numjobs=1 --size=1G --runtime=20 --filename=/dev/nvme0n1 Run status group 0 (all jobs): READ: bw=19.8MiB/s (20.7MB/s), 19.8MiB/s-19.8MiB/s (20.7MB/s-20.7MB/s), io=396MiB (415MB), run=20001-20001msec Disk stats (read/write): nvme0n1: ios=100744/0, sectors=805952/0, merge=0/0, ticks=17283/0, in_queue=17283, util=99.71% #mmap root@ubuntu:/home/ubuntu/uring/fio-fio-3.37# ./fio --name=test --ioengine=mmap --iodepth=1 --rw=randread --bs=4k --numjobs=1 --size=1G --runtime=20 --filename=/dev/nvme0n1 Run status group 0 (all jobs): READ: bw=13.3MiB/s (13.9MB/s), 13.3MiB/s-13.3MiB/s (13.9MB/s-13.9MB/s), io=265MiB (278MB), run=20001-20001msec Disk stats (read/write): nvme0n1: ios=67590/0, sectors=540720/0, merge=0/0, ticks=17700/0, in_queue=17700, util=99.69% root@ubuntu:/home/ubuntu/uring/fio-fio-3.37# ./fio --name=test --ioengine=io_uring --iodepth=1 --rw=randread --bs=4k --numjobs=1 --size=1G --runtime=20 --filename=/dev/nvme0n1 Run status group 0 (all jobs): READ: bw=16.5MiB/s (17.3MB/s), 16.5MiB/s-16.5MiB/s (17.3MB/s-17.3MB/s), io=331MiB (347MB), run=20001-20001msec Disk stats (read/write): nvme0n1: ios=84263/0, sectors=674104/0, merge=0/0, ticks=17474/0, in_queue=17474, util=99.66% #改变每个线程挂起队列数 以及同时运行的线程数为4 root@ubuntu:/home/ubuntu/uring/fio-fio-3.37# ./fio --name=test --ioengine=io_uring --iodepth=128 --rw=randread --bs=4k --numjobs=4 --size=1G --runtime=20 --filename=/dev/nvme0n1 Run status group 0 (all jobs): READ: bw=61.4MiB/s (64.3MB/s), 5787KiB/s-21.9MiB/s (5925kB/s-22.9MB/s), io=2048MiB (2147MB), run=32290-33378msec Disk stats (read/write): nvme0n1: ios=251113/0, sectors=2008904/0, merge=0/0, ticks=5234262/0, in_queue=5234262, util=97.34% ###################################### #测试随机写 root@ubuntu:/home/ubuntu/uring/fio-fio-3.37# ./fio --name=test --ioengine=psync --iodepth=1 --rw=randwrite --bs=4k --numjobs=1 --size=1G --runtime=20 --filename=/dev/nvme0n1 Run status group 0 (all jobs): WRITE: bw=785MiB/s (823MB/s), 785MiB/s-785MiB/s (823MB/s-823MB/s), io=1024MiB (1074MB), run=1304-1304msec Disk stats (read/write): nvme0n1: ios=50/1809, sectors=2104/117296, merge=0/13018, ticks=19/1443, in_queue=1462, util=20.56% #mmap root@ubuntu:/home/ubuntu/uring/fio-fio-3.37# ./fio --name=test --ioengine=mmap --iodepth=1 --rw=randwrite --bs=4k --numjobs=1 --size=1G --runtime=20 --filename=/dev/nvme0n1 Run status group 0 (all jobs): WRITE: bw=3484KiB/s (3568kB/s), 3484KiB/s-3484KiB/s (3568kB/s-3568kB/s), io=137MiB (144MB), run=40339-40339msec Disk stats (read/write): nvme0n1: ios=35184/28647, sectors=283176/281072, merge=0/6487, ticks=9031/27289, in_queue=36321, util=27.70% #libaio root@ubuntu:/home/ubuntu/uring/fio-fio-3.37# ./fio --name=test --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4k --numjobs=1 --size=1G --runtime=20 --filename=/dev/nvme0n1 test: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1 Run status group 0 (all jobs): WRITE: bw=361MiB/s (379MB/s), 361MiB/s-361MiB/s (379MB/s-379MB/s), io=1024MiB (1074MB), run=2834-2834msec Disk stats (read/write): nvme0n1: ios=51/4434, sectors=2112/310064, merge=0/36071, ticks=26/14927, in_queue=14952, util=23.94% root@ubuntu:/home/ubuntu/uring/fio-fio-3.37# ./fio --name=test --ioengine=io_uring --iodepth=1 --rw=randwrite --bs=4k --numjobs=1 --size=1G --runtime=20 --filename=/dev/nvme0n1 Run status group 0 (all jobs): WRITE: bw=36.0MiB/s (37.8MB/s), 36.0MiB/s-36.0MiB/s (37.8MB/s-37.8MB/s), io=721MiB (756MB), run=20001-20001msec Disk stats (read/write): nvme0n1: ios=49/51479, sectors=2096/836976, merge=0/53143, ticks=13/82485, in_queue=82499, util=10.92% #每个工作线程在队列中同时挂起的I/O请求数量128 并指定线程数为4 root@ubuntu:/home/ubuntu/uring/fio-fio-3.37# ./fio --name=test --ioengine=io_uring --iodepth=128 --rw=randwrite --bs=4k --numjobs=4 --size=1G --runtime=20 --filename=/dev/nvme0n1 Run status group 0 (all jobs): WRITE: bw=638MiB/s (669MB/s), 160MiB/s-187MiB/s (167MB/s-196MB/s), io=4096MiB (4295MB), run=5470-6417msec Disk stats (read/write): nvme0n1: ios=51/23432, sectors=2112/2844440, merge=0/332175, ticks=13/227712, in_queue=227724, util=51.16%按需求需要,设置参数分析不同参数下的磁盘性能。
-
相关阅读:
复盘:python中函数传递参数是值传递还是引用传递
AUTOSAR介绍
QT使用MSVC编译时报错C2001: 常量中有换行符
如何开发一款基于 vite+vue3 的在线表格系统(下)
PAT乙级1023 组个最小数
Python少儿编程小课堂(三)入门篇(3)
C++编程法则365天一天一条(14)sizeof运算符使用
sass基本使用总结
这五个适合上班族的副业你知道多少
【台前调度】使用指南:如何打开和关闭iPadOS 16台前调度
- 原文地址:https://blog.csdn.net/yun6853992/article/details/142102152