-
目标检测中的解耦和耦合、anchor-free和anchor-base
解耦和耦合
写在前面
在目标检测中,objectness(或 objectness score)指的是一个评分,用来表示某个预测框(bounding box)中是否包含一个目标物体。
具体来说,YOLO等目标检测算法需要在每个候选区域(anchor box 或 grid cell)上进行多个任务的预测,比如:
- 类别分数:该区域是否属于某个特定类别(例如车、人、狗等)。
- 边界框回归参数:用于调整预测的边界框,使其更加贴合目标物体。
- objectness:表示该预测框中是否包含物体的概率(即,不关心它是什么物体,只关心是否有物体存在)。
YOLO(You Only Look Once)中的“耦合头”和“解耦头”主要与模型的输出层结构以及任务的分离程度有关,尤其是在分类和回归任务上的处理方式。它们的主要区别在于如何处理不同任务(如分类和边界框回归)之间的耦合程度。具体来说:
1. 耦合头(Coupled Head)
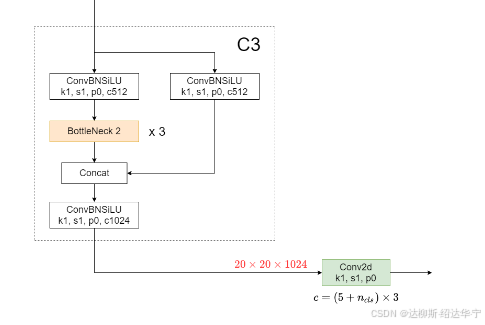
在耦合头中,分类和回归任务使用共享的特征图,并通过一个单一的网络层来同时预测类别和边界框。这意味着分类和回归是耦合在一起的,由同一个网络结构同时进行。这种设计通常能够简化模型的结构和计算量,并且在一定程度上能够让分类和回归任务共享特征,可能在简单任务上具有较好的表现。
- 优点:
- 计算效率更高,因为分类和回归任务共享特征和计算资源。
- 网络结构相对简单,参数更少。
- 缺点:
- 分类和回归任务可能相互影响,尤其是在处理复杂目标时,分类和回归的精度可能受到影响。
2. 解耦头(Decoupled Head)
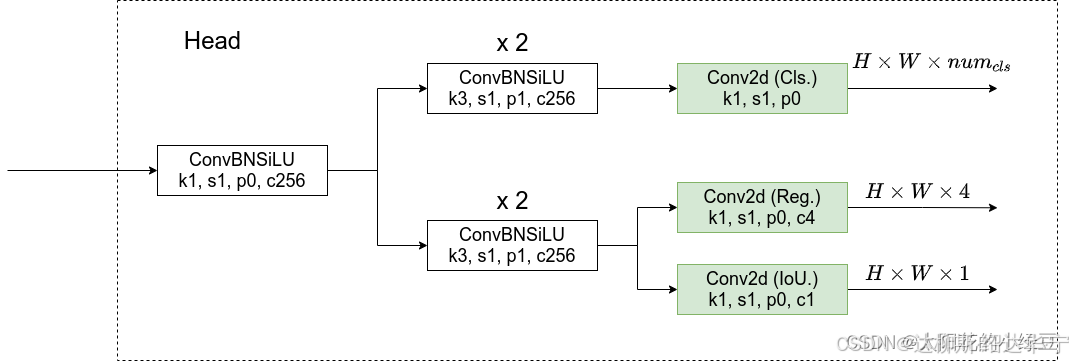
在解耦头中,分类和回归任务被分离为两个不同的分支。通常,会有两个独立的网络分支来分别处理分类和回归任务。每个任务有自己专门的特征提取和预测层,这种设计可以减少分类和回归之间的相互影响,从而在任务上达到更高的精度,尤其是在处理复杂场景时。
- 优点:
- 分类和回归的任务相对独立,减少相互干扰。
- 通常可以提高分类和边界框预测的精度,尤其是对于更复杂的目标检测任务。
- 缺点:
- 由于需要两个独立的分支,计算量和参数量增加。
- 计算效率比耦合头低。
总结
- 耦合头适合轻量化模型和计算资源有限的情况,追求更高的效率。
- 解耦头适合更复杂的目标检测任务,追求更高的精度。
anchor-free和anchor-base
Anchor-free 是一种目标检测方法,区别于传统的 Anchor-based 检测方法。Anchor-free 方法不依赖于预设的 Anchor box,而是直接预测目标物体的关键点或中心点来生成边界框。这种方法近年来在目标检测中变得越来越流行,尤其是在 YOLOv4, CenterNet, FCOS 等模型中都有应用。
Anchor-based 方法
在传统的 Anchor-based 方法中,目标检测器会在图像的每个位置放置多个预定义的 Anchor boxes。这些 Anchor boxes 是一组具有不同大小、纵横比的候选框,用于检测不同尺寸的物体。模型通过回归预测来调整这些 Anchor boxes,以拟合目标物体。
缺点:
- 需要设计和设置 Anchor box 的尺寸、比例,这通常需要根据数据集进行大量的调参。
- Anchor boxes 数量多,计算成本高。
- 小物体或大物体可能无法很好地与预定义的 Anchor 匹配,导致检测精度下降。
Anchor-free 方法
Anchor-free 方法的关键思想是摆脱对预定义的 Anchor boxes 的依赖,而是直接从图像的像素、特征图上推断目标的位置和大小。主要有以下几种常见策略:
- 关键点检测:通过检测物体的关键点或中心点,然后利用这些关键点回归出边界框的参数。例如,CenterNet 就是基于物体的中心点进行检测。
关键点检测 是 Anchor-free 目标检测的一种实现方式,具体通过检测物体的某些关键点(如中心点或角点),从而确定物体的位置和边界框。这与传统的 Anchor-based 方法有显著区别,因为它不依赖预先定义的 Anchor box,而是直接在特征图上推断出物体的几何信息。
让我们逐步解析它的工作原理,尤其是以 CenterNet 为例:
1. 关键点检测的核心思想
传统的 Anchor-based 方法是通过大量的预设框(Anchor box)去拟合物体位置,而关键点检测方法直接通过检测物体的关键点,比如:
- 中心点(CenterNet):直接预测物体的中心点。
- 角点(CornerNet):预测物体的左上角和右下角。
物体的这些关键点是目标检测的核心,用来确定物体的位置和边界框。
2. 以 CenterNet 为例:基于中心点的检测
在 CenterNet 中,检测器会学习每个物体的 中心点。具体步骤如下:
- 中心点的检测:CenterNet 的输入是图片,它通过卷积神经网络(CNN)生成一个特征图。对于每个物体,网络会预测一个特征点,表示物体的中心点。这个中心点用于回归物体的位置和大小。
- 边界框的回归:一旦确定了物体的中心点,网络还会预测该中心点到物体的边界的距离。这些距离可以直接用来构造物体的边界框(bounding box)。
- 具体来说,对于每个中心点,网络会输出该点到边界框四个边界的距离值(即左、右、上、下距离)。
- 这些距离可以用来计算边界框的大小,从而直接得到物体的完整位置。
3. 关键点检测的优势
- 不需要 Anchor box:相比于传统的 Anchor-based 方法,关键点检测完全不依赖预定义的 Anchor box,这避免了 Anchor box 尺寸和比例设置的不匹配问题。对于不同大小、形状的物体,关键点检测更加灵活。
- 减少了计算复杂度:传统 Anchor-based 方法通常需要生成大量的 Anchor boxes,这会带来计算的额外开销。而关键点检测只需要检测图像中的少数几个关键点,大大减少了冗余的候选框数量。
- 更好的小物体检测:由于关键点检测方法不依赖特定尺寸的框,它在检测非常小的物体时有优势,不需要通过 Anchor box 来匹配大小。
4. 具体例子:CenterNet 如何工作
- 输入:一张图片。
- 特征提取:通过卷积神经网络(如 ResNet 或 Hourglass)提取高维特征。
- 中心点预测:在特征图上,每个像素都会预测是否为物体的中心点,这个任务可以看作是一个分类问题,输出是一个热图(heatmap),每个像素的值表示它是物体中心的概率。
- 回归边界框:对于每个预测到的中心点,回归出到物体边界的四个距离(即边框的 left、right、top、bottom)。
- 生成边界框:根据回归的距离值生成最终的边界框。
5. 关键点检测的常见模型
- CenterNet:通过检测物体的中心点,并回归边界框的尺寸。
- CornerNet:通过检测物体的角点(左上角和右下角),然后将这些角点连接生成边界框。
- 边界框中心点回归:模型直接预测每个像素点相对于目标物体边界的偏移量和尺寸。这是像 FCOS(Fully Convolutional One-Stage Object Detection)这类方法的核心思想。
FCOS 的工作原理
1. 特征提取
- 输入图像:首先,FCOS 接收一张输入图像。
- 特征图生成:通过一个卷积神经网络(CNN),如 ResNet 或 VGG,提取图像的高维特征,并生成一个特征图。
2. 像素级别的回归
- 每个像素点的预测:FCOS 不依赖预定义的 Anchor boxes,而是对特征图上的每个像素进行回归,预测该像素点到目标边界框的四个边界的距离(即左、右、上、下的距离)。
- 左边界:每个像素点预测到目标的左边界的距离。
- 右边界:每个像素点预测到目标的右边界的距离。
- 上边界:每个像素点预测到目标的上边界的距离。
- 下边界:每个像素点预测到目标的下边界的距离。
- 目标中心点:除了预测边界框的四个边界距离外,FCOS 还会预测该像素点是否是目标的中心点。对于每个像素点,FCOS 生成一个热图(heatmap),表示该像素点是否为目标中心点的概率。这个热图帮助模型判断目标的存在位置。
3. 生成边界框
- 从回归值计算边界框:根据每个像素点预测的距离值,FCOS 可以直接计算目标物体的边界框。具体步骤如下:
- 左边界:通过预测的距离值从像素点向左推算得到目标的左边界。
- 右边界:通过预测的距离值从像素点向右推算得到目标的右边界。
- 上边界:通过预测的距离值从像素点向上推算得到目标的上边界。
- 下边界:通过预测的距离值从像素点向下推算得到目标的下边界。
4. 后处理
- 去除背景和重叠:FCOS 生成的边界框通过非极大值抑制(NMS)去除冗余的框,确保最终的检测结果准确且唯一。
FCOS 的优点
- 不需要 Anchor boxes:FCOS 不依赖于 Anchor boxes,简化了模型的设计和训练过程。无需预定义和调节 Anchor box 的尺寸和比例。
- 更高效的计算:由于不需要生成大量的 Anchor boxes,FCOS 在计算上更加高效,减少了冗余计算。
- 处理不同尺度的物体:通过回归每个像素点的边界框,FCOS 更加灵活地处理各种尺寸的物体,适应性强。
Anchor-free 方法的优点
- 无需设计 Anchor boxes:省去了手动设计和调参的工作,简化了模型的设置流程。
- 更高的计算效率:由于不需要生成大量的 Anchor boxes,减少了计算开销。
- 更自然的目标表示:直接回归关键点、中心点或边界框参数,使得模型更贴近图像本身的几何特性,特别是在处理不同尺寸的物体时,表现得更好。
典型的 Anchor-free 模型
- CenterNet:通过回归目标物体的中心点,然后预测宽高,从而生成边界框。
- FCOS:使用每个像素点相对于目标的距离(即边界框的四个边界到当前像素点的距离)来直接回归边界框。
- CornerNet:通过回归目标物体的左上角和右下角来确定边界框。
Anchor-based vs Anchor-free
- Anchor-based 方法:通过预定义的 Anchor boxes 提供了目标物体的粗略位置和大小,然后通过回归优化这些候选框。
- Anchor-free 方法:直接预测物体的特征(如中心点、边界)来回归边界框,不依赖预定义的框。
-
相关阅读:
Python实现自动重新运行指定python脚本
10月10日上课内容 Docker--harbor私有仓库部署与管理
node使用puppeteer生成pdf与截图
if else 替换方案
java-- 字符串+拼接详解, 性能调优 (底层原理实现)
当生成式AI遇到业务流程管理,大语言模型正在变革BPM
Git 命令详解
Yolov8改进交流
时间跟踪工具:Timemator Mac汉化版
每日一题 2731. 移动机器人(中等,模拟)
- 原文地址:https://blog.csdn.net/qq_55794606/article/details/142266086