-
强化学习之Dueling DQN对DQN的改进——以倒立摆环境(Inverted Pendulum)为例
0.简介
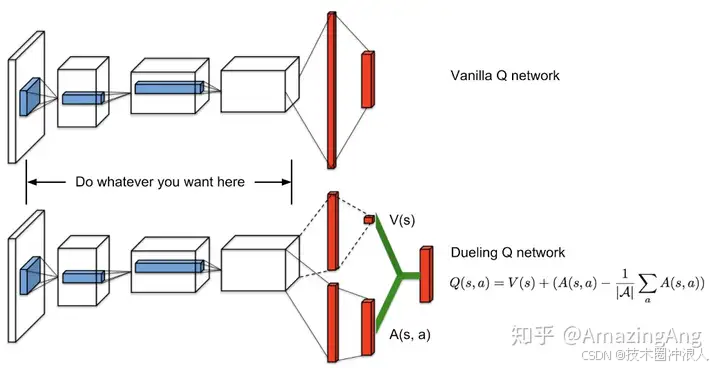

参考博客来源:DeepRL系列(10): Dueling DQN(DDQN)原理及实现
 https://zhuanlan.zhihu.com/p/114834834
https://zhuanlan.zhihu.com/p/114834834通过前面的推导,我们得到了Dueling Network的数学形式为
实际中将最大化形式变成均值形式效果更好,更稳定,其数学形式如下
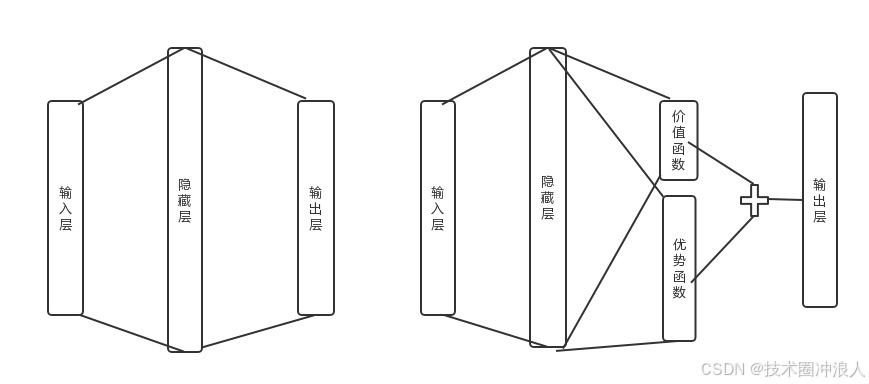

1.导库
- import torch
- import numpy as np
- import matplotlib.pyplot as plt
- from tqdm import tqdm
- import gym
- import collections
- import random
2.神经网络Qnet和VAnet构建
- class VAnet(torch.nn.Module):
- """ 只有一层隐藏层的A网络和V网络 """
- def __init__(self,statedim,hiddendim,actiondim):
- super(VAnet,self).__init__()
- self.fc1=torch.nn.Linear(statedim,hiddendim)
- self.fcA=torch.nn.Linear(hiddendim,actiondim)
- self.fcV=torch.nn.Linear(hiddendim,1)
- def forward(self,x):
- A=self.fcA(torch.nn.functional.relu(self.fc1(x)))
- V=self.fcV(torch.nn.functional.relu(self.fc1(x)))
- # Q=V+A-A.mean(1).unsqueeze(1)#unsqueeze 则用于在指定位置增加一个维度 本式子相当于下式
- Q=V+A-A.mean(1).view(-1,1)
- return Q
- def save(self, path):
- torch.save(self.state_dict(), path)
- def load(self, path):
- self.load_state_dict(torch.load(path))
- class Qnet(torch.nn.Module):
- """ 只有一层隐藏层的Q网络 """
- def __init__(self,statedim,hiddendim,actiondim):
- super(Qnet,self).__init()
- self.fc1=torch.nn.Linear(statedim,hiddendim)
- self.fc2=torch.nn.Linear(hiddendim,actiondim)
- def forward(self,x):
- x=torch.nn.functional.relu(self.fc1(x))
- return self.fc2(x)
- def save(self, path):
- torch.save(self.state_dict(), path)
- def load(self, path):
- self.load_state_dict(torch.load(path))
3.经验回放池实现
- class ReplayBuffer:
- """ 经验回放池 """
- def __init__(self,capacity):
- self.buffer=collections.deque(maxlen=capacity)
- def add(self,state,action,reward,nextstate,done):
- self.buffer.append((state,action,reward,nextstate,done))
- def sample(self,batchsize):
- transitions=random.sample(self.buffer,batchsize)
- state,action,reward,nextstate,done=zip(*transitions)
- return np.array(state),action,reward,np.array(nextstate),done
- def size(self):
- return len(self.buffer)
当然我们神经网络也可以写成如下形式,是等价的。
- class VAnet(torch.nn.Module):
- def __init__(self, statedim, hiddendim, actiondim):
- super(VAnet, self).__init__()
- self.A = torch.nn.Sequential(
- torch.nn.Linear(statedim, hiddendim),
- torch.nn.ReLU(),
- torch.nn.Linear(hiddendim, actiondim),
- # torch.nn.Softmax(dim=1)
- )
- self.V = torch.nn.Sequential(
- torch.nn.Linear(statedim, hiddendim),
- torch.nn.ReLU(),
- torch.nn.Linear(hiddendim, 1)
- )
- def forward(self, x):
- a_output = self.A(x)
- v_output = self.V(x)
- a_mean = a_output.mean(1).view(-1, 1)
- return a_output + v_output - a_mean
4.离散动作转为连续函数的实现函数
- def dis_to_con(actionid,env,actiondim):#离散动作转回连续函数
- actionlowbound=env.action_space.low[0]#连续动作最小值
- actionupbound=env.action_space.high[0]#连续动作最大值
- return actionlowbound+actionid*(actionupbound-actionlowbound)/(actiondim-1)
5.DQN算法实现
- class DQN:
- """ DQN算法,包括DoubleDQN和DuelingDQN """
- def __init__(self,statedim,hiddendim,actiondim,learningrate,gamma,epsilon,targetupdate,device,dqntype='VanillaDQN'):
- self.actiondim=actiondim
- self.gamma=gamma
- self.epsilon=epsilon
- self.targetupdate=targetupdate
- self.device=device
- self.dqntype=dqntype
- self.count=0
- if self.dqntype=='DuelingDQN':#Dueling DQN采取不一样的网络框架
- self.qnet=VAnet(statedim=statedim,hiddendim=hiddendim,actiondim=actiondim).to(self.device)
- self.targetqnet=VAnet(statedim=statedim,hiddendim=hiddendim,actiondim=actiondim).to(self.device)
- else:
- self.qnet=Qnet(statedim=statedim,hiddendim=hiddendim,actiondim=actiondim).to(self.device)
- self.targetqnet=Qnet(statedim=statedim,hiddendim=hiddendim,actiondim=actiondim).to(self.device)
- self.optimizer=torch.optim.Adam(self.qnet.parameters(),lr=learningrate)
- def takeaction(self,state):
- if np.random.random()action=np.random.randint(self.actiondim)else:state=torch.tensor([state],dtype=torch.float).to(self.device)action=self.qnet(state).argmax().item()return actiondef max_qvalue(self,state):state=torch.tensor([state],dtype=torch.float).to(self.device)return self.qnet(state).max().item()def update(self,transition_dict):states=torch.tensor(transition_dict['states'],dtype=torch.float).to(self.device)actions=torch.tensor(transition_dict['actions']).view(-1,1).to(self.device)rewards=torch.tensor(transition_dict['rewards'],dtype=torch.float).view(-1,1).to(self.device)nextstates=torch.tensor(transition_dict['nextstates'],dtype=torch.float).to(self.device)dones=torch.tensor(transition_dict['dones'],dtype=torch.float).view(-1,1).to(self.device)qvalues=self.qnet(states).gather(1,actions)#gather(1, actions) 中的参数 1 表示沿着第 1 维度(即列维度)进行收集操作,根据 actions 提供的索引来收集相应的 qvalues 。if self.dqntype=='DoubleDQN':maxaction=self.qnet(nextstates).max(1)[1].view(-1,1)#max(1)表示在第 1 个维度(通常是列维度)上求最大值;max(1)会返回两个值,第一个是每行的最大值,第二个是最大值所在的索引[1]。maxnextqvalues=self.targetqnet(nextstates).gather(1,maxaction)else:maxnextqvalues=self.targetqnet(nextstates).max(1)[0].view(-1,1)targetqvalues=rewards+self.gamma*maxnextqvalues*(1-dones)dqnloss=torch.mean(torch.nn.functional.mse_loss(qvalues,targetqvalues))self.optimizer.zero_grad()dqnloss.backward()self.optimizer.step()if self.count % self.targetupdate==0:self.targetqnet.load_state_dict(self.qnet.state_dict())self.count+=1
6.训练DQN函数实现
- def trainDQN(agent,env,episodesnum,pbarnum,printreturnnum,replaybuffer,minimalsize,batchsize):
- returnlist=[]
- maxqvaluelist=[]
- maxqvalue=0
- for k in range(pbarnum):
- with tqdm(total=int(episodesnum/pbarnum),desc='Iteration %d'%k) as pbar:
- for episode in range(int(episodesnum/pbarnum)):
- episodereturn=0
- state=env.reset(seed=10)[0]
- done=False
- while not done:
- action=agent.takeaction(state)
- maxqvalue=agent.max_qvalue(state)*0.005+maxqvalue*0.995#平滑处理
- maxqvaluelist.append(maxqvalue)#记录最大q值
- action_continuous=dis_to_con(actionid=action,env=env,actiondim=agent.actiondim)
- nextstate,reward,done,truncated,_=env.step([action_continuous])
- done=done or truncated
- replaybuffer.add(state,action,reward,nextstate,done)
- state=nextstate
- episodereturn+=reward
- if replaybuffer.size()>minimalsize:
- bs,ba,br,bns,bd=replaybuffer.sample(batchsize)
- transitiondict={'states':bs,'actions':ba,'rewards':br,'nextstates':bns,'dones':bd}
- agent.update(transitiondict)
- returnlist.append(episodereturn)
- if (episode+1)%printreturnnum==0:
- pbar.set_postfix({'episode':'%d'%(int(episodesnum/pbarnum)*k+episode+1),'return':'%.3f'%np.mean(returnlist[-printreturnnum:])})
- pbar.update(1)
- return returnlist,maxqvaluelist
7.移动平均函数实现
- def moving_average(a, window_size):
- cumulative_sum = np.cumsum(np.insert(a, 0, 0))
- middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
- r = np.arange(1, window_size-1, 2)
- begin = np.cumsum(a[:window_size-1])[::2] / r
- end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
- return np.concatenate((begin, middle, end))
8.参数设置
- lr=1e-2
- gamma=0.98
- epsilon=0.01
- target_update=10
- batchsize=64
- minimalsize=500
- episodesnum=500
- buffersize=10000
- hiddendim=128
- actiondim=11
- pbarnum=10
- printreturnnum=10
- device=torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
9.倒立摆环境下训练并实现可视化
- random.seed(10)
- np.random.seed(10)
- torch.manual_seed(10)
- replaybuffer=ReplayBuffer(buffersize)
- env=gym.make('Pendulum-v1')
- env.reset(seed=10)
- statedim=env.observation_space.shape[0]
- agent=DQN(statedim=statedim,hiddendim=hiddendim,actiondim=actiondim,learningrate=lr,gamma=gamma,epsilon=epsilon,targetupdate=target_update,device=device,dqntype='DuelingDQN')
- returnlist,maxqvaluelist=trainDQN(agent=agent,env=env,episodesnum=episodesnum,pbarnum=pbarnum,printreturnnum=printreturnnum,replaybuffer=replaybuffer,minimalsize=minimalsize,batchsize=batchsize)
- episodelist=np.arange(len(returnlist))#等价于np.linspace(0,len(returnlist)-1,len(returnlist))以及list(range(len(returnlist)))
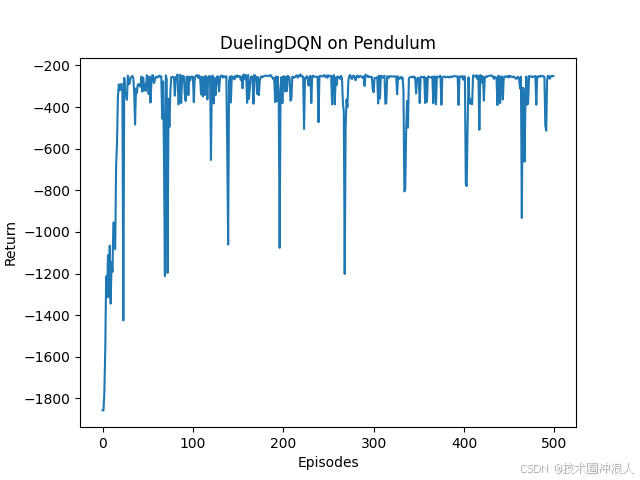
- plt.plot(episodelist,returnlist)
- plt.xlabel('Episodes')
- plt.ylabel('Return')
- plt.title(f'{agent.dqntype} on {env.spec.name}')
- plt.show()
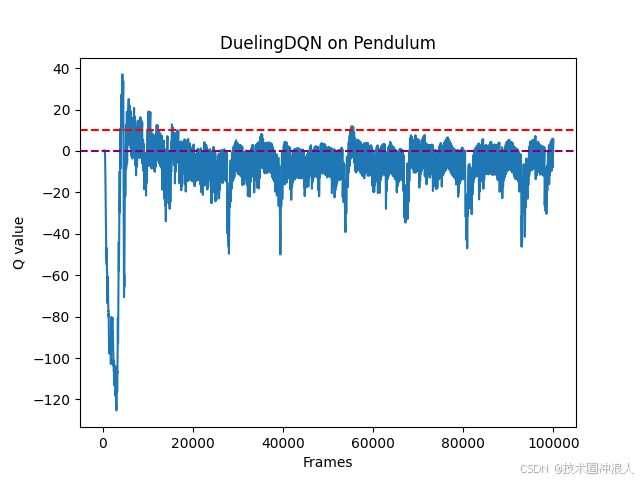
- framslist=np.arange(len(maxqvaluelist))
- plt.plot(framslist,maxqvaluelist)
- plt.axhline(y=0,color='purple',linestyle='--')
- plt.axhline(y=10,c='red',ls='--')
- plt.xlabel('Frames')
- plt.ylabel('Q value')
- plt.title(f'{agent.dqntype} on {env.spec.name}')
- plt.show()
- env.close()
9.可视化结果显示以及结论
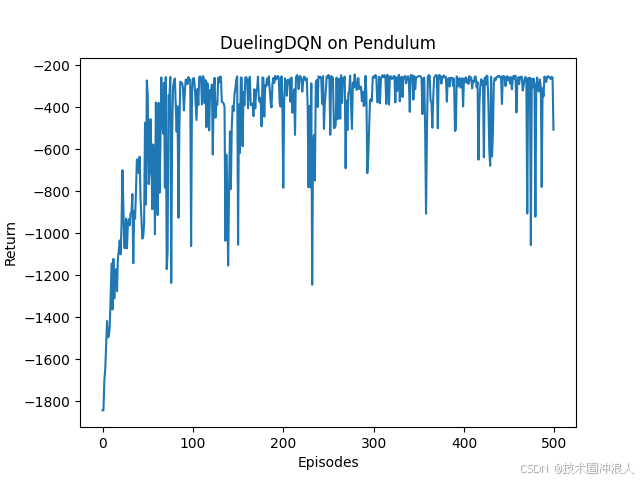
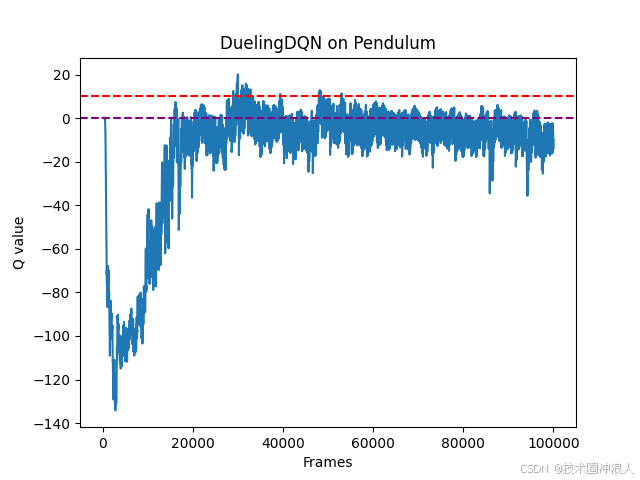

结论:相比传统的DQN,Dueing DQN在多个动作选择下的学习更加稳定,得到的回报最大值也更大,由Dueling DQN 原理知随着动作空间增大,Dueling DQN相比DQN优势更加明显。本实验中离散动作数设置为11,可以增加动作数(例如15,25,30等),继续对比实验,实验效果更为明显。
当然我们可以改变网络结构,加大隐藏层数量, 更改神经网络结构如下所示。
- class VAnet(torch.nn.Module):
- def __init__(self, statedim, hiddendim, actiondim):
- super(VAnet, self).__init__()
- self.A = torch.nn.Sequential(
- torch.nn.Linear(statedim, hiddendim),
- torch.nn.Tanh(), # 改变激活函数为 Tanh
- torch.nn.Linear(hiddendim, hiddendim), # 增加一层隐藏层
- torch.nn.ReLU(),
- torch.nn.Linear(hiddendim, actiondim),
- # torch.nn.Softmax(dim=1)
- )
- self.V = torch.nn.Sequential(
- torch.nn.Linear(statedim, hiddendim),
- torch.nn.Tanh(), # 改变激活函数为 Tanh
- torch.nn.Linear(hiddendim, hiddendim), # 增加一层隐藏层
- torch.nn.ReLU(),
- torch.nn.Linear(hiddendim, 1)
- )
- def forward(self, x):
- return self.A(x) + self.V(x) - self.A(x).mean(1).view(-1, 1)
- def save(self, path):
- torch.save(self.state_dict(), path)
- def load(self, path):
- self.load_state_dict(torch.load(path))
结果如下所示:
- 相关阅读:
Java设计模式 _行为型模式_观察者模式
对于手机号和邮箱的格式验证
【JVM系列】- 启航·JVM概论学习
企业架构LNMP学习笔记40
内创业革命
fplan-布局
【Eclipse】Plug-in Development 插件的安装
花青素染料Cy3NS NHS酯,Cy3NS 琥珀酰亚胺活化酯物理化学光谱特性及参数解析,激发波长(nm):554发射波长(nm):568
图论基础学习笔记
【3D图像分割】基于 Pytorch 的 VNet 3D 图像分割3(3D UNet 模型篇)
- 原文地址:https://blog.csdn.net/m0_56497861/article/details/141001674