-
Flink-DataWorks第二部分:数据集成(第58天)
系列文章目录
- 数据集成
2.1 概述
2.1.1 离线(批量)同步简介
2.1.2 实时同步简介
2.1.3 全增量同步任务简介
2.2 支持的数据源及同步方案
2.3 创建和管理数据源
前言
本文主要详解了DataWorks的数据集成,为第二部分:
由于篇幅过长,分章节进行发布。
后续:
数据集成的使用
数据开发流程及操作
运维中心的使用2. 数据集成
2.1 概述
2.1.1 离线(批量)同步简介
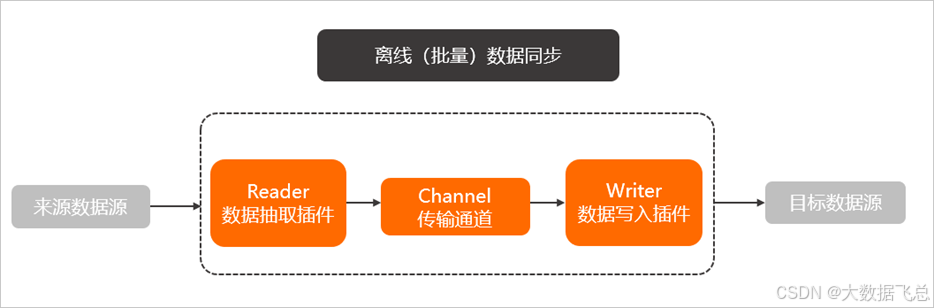
数据集成主要用于离线(批量)数据同步。离线(批量)的数据通道通过定义数据来源和去向的数据源和数据集,提供一套抽象化的数据抽取插件(Reader)、数据写入插件(Writer),并基于此框架设计一套简化版的中间数据传输格式,从而实现任意结构化、半结构化数据源之间数据传输。
2.1.2 实时同步简介
数据集成的实时同步包括实时读取、转换和写入三种基础插件,各插件之间通过内部定义的中间数据格式进行交互。
一个实时同步任务支持多个转换插件进行数据清洗,并支持多个写入插件实现多路输出功能。同时针对某些场景,支持整库实时同步全增量同步任务,用户可以一次性实时同步多个表。2.1.3 全增量同步任务简介
实际业务场景下,数据同步通常不能通过一个或多个简单离线同步或者实时同步任务完成,而是由多个离线同步、实时同步和数据处理等任务组合完成,这就会导致数据同步场景下的配置复杂度非常高。
为了解决上述问题,DataWorks提出了面向业务场景的同步任务配置化方案,支持不同数据源的一键同步功能,例如,“一键实时同步至Elasticsearch”、“一键实时同步至Hologres”和“一键实时同步至MaxCompute”功能等,通过此类功能,用户只需要进行简单的配置,就可以完成一个复杂业务场景。
全增量同步任务具有如下优势:
全量数据初始化。
增量数据实时写入。
增量数据和全量数据定时自动合并写入新的全量表分区。2.2 支持的数据源及同步方案
数据集成包括离线同步、实时同步和全增量同步任务三个功能模块,可以根据各模块对数据源的支持情况,选择对应的功能模块进行同步任务的配置。
支持的数据源及同步方案详见下表:https://help.aliyun.com/zh/dataworks/user-guide/supported-data-source-types-and-read-and-write-operations?spm=a2c4g.11186623.0.0.6d9e7bca0fYAUx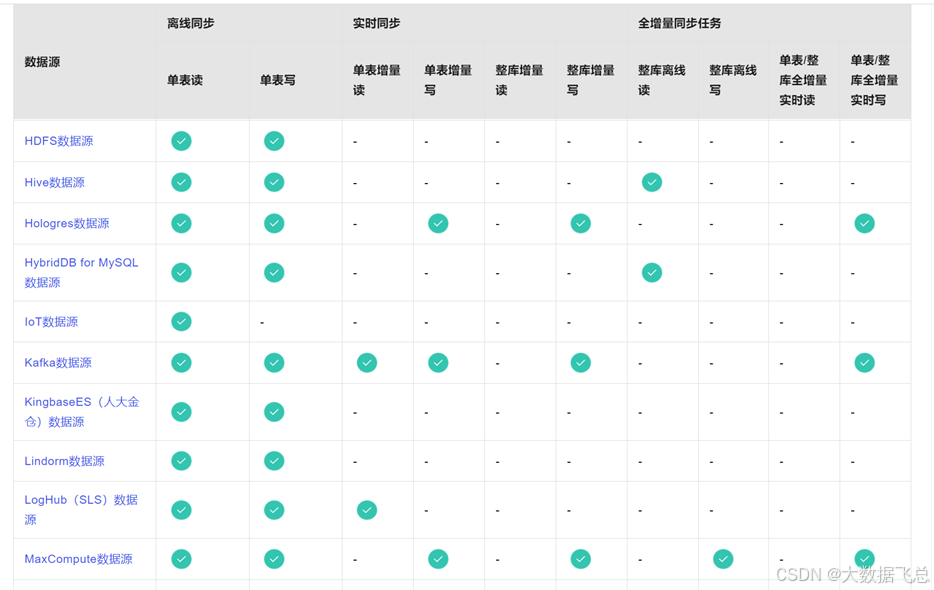
2.3 创建和管理数据源
按照配置文档进行配置即可。下面以MySQL为例进行学习。
(1)数据同步前准备:MySQL环境准备
1)确认MySQL版本
登录数据库管理系统https://dms.aliyun.com/,打开SQL Console,运行以下命令:select version();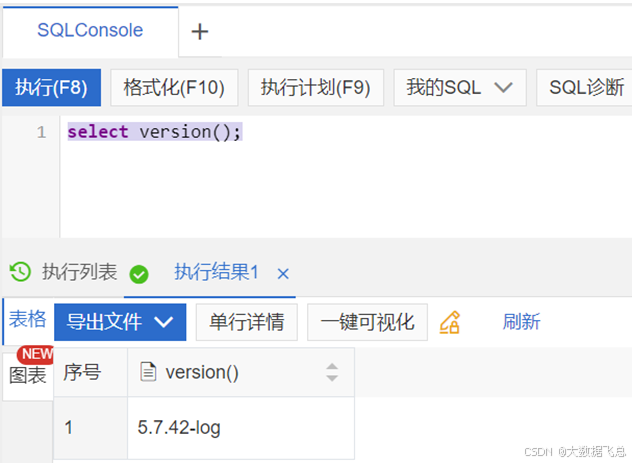
2)配置账号权限
建议提前规划并创建一个专用于DataWorks访问数据源的MySQL账号,操作如下。CREATE USER 'dw'@'%' IDENTIFIED BY 'xxxxx666!'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'dw'@'%';3)(仅实时同步需要)开启MySQL Binlog
数据集成通过实时订阅MySQL Binlog实现增量数据实时同步,需要在DataWorks配置同步前,先开启MySQL Binlog服务。操作如下。
注意:
如果Binlog在消费中,则无法被数据库删除。如果实时同步任务运行延迟将可能导致源端Binlog长时间被消费,请合理配置任务的延迟告警,并及时关注数据库的磁盘空间。
Binlog至少保留72小时以上,避免任务失败后因Binlog已经消失,再启动无法重置位点到故障发生前而导致的数据丢失(此时只能使用全量离线同步来补齐数据)。
① 检查Binlog是否开启。
使用如下语句检查Binlog是否开启。show variables like "log_bin";返回结果为ON时,表明已开启Binlog。
如果返回的结果与上述结果不符:
o 开源MySQL请参考MySQL官方文档开启Binlog。
o 阿里云RDS MySQL请参考日志备份开启Binlog。
② 查询Binlog的使用格式。
使用如下语句查询Binlog的使用格式。show variables like "binlog_format";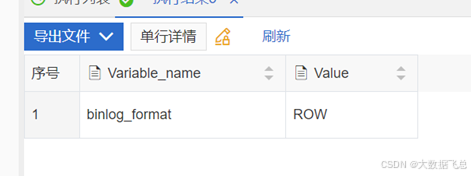
返回结果说明:
返回ROW,表明开启的Binlog格式为ROW。
返回STATEMENT,表明开启的Binlog格式为STATEMENT。
返回MIXED,表明开启的Binlog格式为MIXED。
注意:DataWorks实时同步仅支持同步MySQL服务器Binlog配置格式为ROW。如果返回非ROW请修改Binlog Format。
(2)新增数据源
1)打开DataWorks控制台,点击工作空间列表,打开dwhmcx,点击管理中心
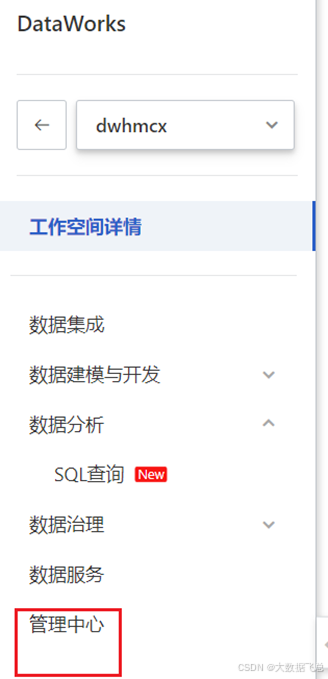
2)点击数据源,点击新增数据源,选择MySQL
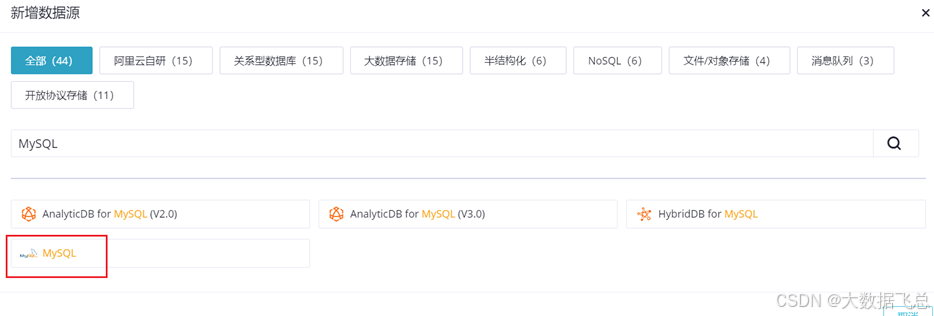
3)首次创建数据源源需要在对话框中点击前往RAM进行角色授权
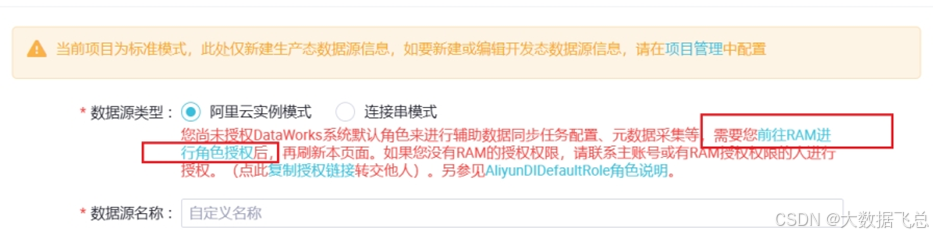
点击同意授权。
4)填写配置信息
数据源名称:rdsmysql
适用环境:开发、生产
注意:在实际工作中开发和生产对应不同的数据库,一个是测试数据库一个是生产数据库。
地区:北京
实例所属账号:当前云账号
RDS实例ID: rm-cn-x0r3fp1lj000qa
注意:RDS实例ID需要打开RDS控制台,在实例列表中,复制实例ID
默认数据库名:test
用户名:dw
密码:xxxxx666!
点击测试连通性
点击完成
(3)管理数据源
可以在数据源管理页面,根据数据源类型、数据源名称等条件筛选需要查看的数据源。同时,支持用户对目标数据源进行编辑、删除、克隆、权限管理等操作。

编辑:可以单击编辑按钮,在弹出的数据源配置窗口,修改数据源的配置信息。
删除:
删除开发环境和生产环境的数据源:需确认是否存在生产环境关联的同步任务,操作不可逆,删除后,在开发环境配置同步任务时此数据源不可见。
如果生产环境在使用此数据源配置的同步任务,删除后,生产环境任务不可正常运行。请删除同步任务后再删除此数据源。
删除开发环境的数据源:需确认是否存在生产环境关联的同步任务,操作不可逆,删除后,在开发环境配置同步任务时此数据源不可见。
如果生产环境在使用此数据源配置的同步任务,删除后,任务编辑时将不能获取到元数据信息,但生产环境任务可以正常运行。
删除生产环境的数据源:需确认是否存在生产环境关联的同步任务,删除后,在开发环境使用此数据源配置的同步任务将不能提交生产发布。
如果生产环境在使用此数据源配置的同步任务,删除后,生产环境任务不可正常运行。克隆:可以单击克隆,在弹出的克隆数据源窗口,输入新数据源名称,单击克隆,即可生成一个相同数据源类型且连接信息相同的新数据源。
权限管理:可以分享数据源权限给相应的工作空间,并进入被分享的工作空间查看该数据源。详情请参见:管理数据源权限。
篇幅原因:后续会接着发 - 数据集成
-
相关阅读:
JavaScript变量及声明
服务器扩展安装(一)之安装宝塔和堡垒机
【PPT】修改新建文本框默认字体
parted磁盘分区 教程
安利个神器, Python 脚本可轻松打包为 exe
LabVIEW中使用Get LV Class Default Value 出现错误1498
RexNet片段记录
国产化Kettle、JDK、MySQL下载安装操作步骤
【VUE】elementUI table表格 列表错位
企业电子招投标采购系统源码之电子招投标的组成
- 原文地址:https://blog.csdn.net/syhiiu/article/details/140933719