-
【JAVA多线程】ForkJoinPool,为高性能并行计算量身打造的线程池
前言
JDK中与多线程相关的源码内容中会涉及大量的状态控制、状态判断,这些判断和控制是必须的,毕竟在多线程环境中上一刻和下一刻的状态可能是完全不同的。但是漫山遍野的状态判断和控制就像沙子一样揉在代码里,导致源码其实蛮乱的,从头到尾并不好阅读。更好的方式其实是先搞清楚核心理念,再翻过去看核心源码即可。所以本文不会一上来就手撕源码,而是先理念、后源码的方式,源码也不会漫山遍野去追,而是只关注核心的几行,化繁为简、方便阅读。

目录
1.概述
1.1.什么是ForkJoinPool
ForkJoin是JDK中一个用来处理分治任务的高级线程池。
如果说分治不好理解,换个说法吧——并行计算。
如果说并行计算也不好理解,再换个说法吧——MapReduce。
其实分治、并行计算、MapReduce说的都是一个东西,就是一个大的任务可以拆成很多个相互独立、互相之间没有依赖关系的子任务,最后汇总成结果。
ForkJoin就是专门用来处理这种可分治、可并行计算、可MapReduce的计算密集型任务的。将一个大任务拆成多个并行的小人物,从而拉快整个大任务的计算速度。ForkJoin也可以理解为一个单机版、利用多线程实现的MapReduce。
到这里可能有的读者会有疑惑:
JDK中有线程池了啊,这种并行计算,用线程池来实现多线程不就完成了?
答:
是的,用线程池当然是能实现的,只是没有ForkJoinPool方便和高效。ForkJoinPool比起普通线程池来就是在支持并行计算上做了强化。
ForkJoinPool在针对并行计算上做了哪些强化?怎么强化的?就将是本文接下来讨论的重点。
1.2.举个例子
先举一个快速排序的例子来感受一下ForkJoinPool。
假设有如下数组:
[7,4,6,9,5,8,3,2,1]
回忆一下快速排序:
各个分区,分而治之,最左、最右各一个指针,两者碰头即为结束。
伪代码:
- void quickSort(int array[], int left, int right) {
- if (left < right) {
- // 执行分区操作并获取基准值的位置
- int pivotIndex = partition(array, left, right);
- // 递归排序基准值左侧的子数组
- quickSort(array, left, pivotIndex - 1);
- // 递归排序基准值右侧的子数组
- quickSort(array, pivotIndex + 1, right);
- }
- }
快速排序详细过程:
-
第一步:选择基准值 我们选择数组的第一个元素作为基准值,这里是 7。
-
第二步:分区过程 我们将数组分为两部分,一部分包含小于等于基准值的元素,另一部分包含大于基准值的元素。 初始化两个指针,left 指向数组的第一个元素,right 指向最后一个元素。 移动 right 指针,直到找到一个小于等于 7 的元素。 移动 left 指针,直到找到一个大于 7 的元素。 交换这两个元素。 重复步骤 2 到 4,直到 left 和 right 指针相遇。 分区后的数组,所有小于 7 的元素都在它的左边,所有大于 7 的元素都在它的右边。
-
第三步:递归排序左右子数组 对基准值左边的子数组 [4, 6, 5, 3, 2, 1] 和右边的子数组 [9, 8] 重复上述过程。 左边子数组 [4, 6, 5, 3, 2, 1] 选择基准值 4 分区,得到 [3, 2, 1, 4, 6, 5] 递归排序 [3, 2, 1] 和 [6, 5] 右边子数组 [9, 8] 选择基准值 9 分区,得到 [8, 9] 递归排序 [8] (单个元素,无需排序)
-
第四步:组合结果 最终,数组将按升序排列。 排序后的数组 在经过上述步骤后,数组 [7,4,6,9,5,8,3,2,1] 将变为 [1, 2, 3, 4, 5, 6, 7, 8, 9]。
在上面的伪代码里面只有一条主线程在工作:
- void quickSort(int array[], int left, int right) {
- if (left < right) {
- // 执行分区操作并获取基准值的位置
- int pivotIndex = partition(array, left, right);
- // 递归排序基准值左侧的子数组
- quickSort(array, left, pivotIndex - 1);
- // 递归排序基准值右侧的子数组
- quickSort(array, pivotIndex + 1, right);
- }
- }
但很明显左右分区之间彼此独立相互都不影响,比起用单线程来顺序的处理各个分区,左右两个分区用不同的线程来处理明显要更高效。于是可以改为forkjoin的模式:
按照forkjoin的思想,伪代码可以改为:
- class SortTask extends RecursiveAction{
- @Override
- protected void compute{
- if (left < right) {
- // 执行分区操作并获取基准值的位置
- int pivotIndex = partition(array, left, right);
- // 递归排序基准值左侧的子数组
- SortTask leftTask=new SortTask(array, left, pivotIndex - 1);
- // 递归排序基准值右侧的子数组
- SortTask rightTask=new SortTask(array, pivotIndex + 1, right);
- //用多线程的方式来分治
- leftTask.fork();//fork会将任务提交给线程池,当线程被执行时会调用compute方法
- rightTask.fork();
- leftTask.join();//join会让线程等待其下面的所有任务完成,线程才结束,避免下面的子任务还没跑完,线程就G了,导致结果不对。
- rightTask.join();
- }
- }
- }
1.3.总结一下
看完上面的代码肯定会有一个疑惑:
join是拿来做什么的?
答:
主线程在fork的时候分成了两条线程分别去负责左右两个半区的排序任务,必须保证主线程要在分出来的两条线程完成后再完成,否则主线程的结果会不对。
翻译成多线程的术语就是,依赖者要阻塞在被依赖者上,直到被依赖者执行完毕。join就是来负责阻塞工作的。
这里就可以解释为什么ThreadPoolExecutor不适合处理分治喃?
就是因为没有原生自带的一套机制来保证分治后最终汇总时结果的准确性,而ForkJoinPool有这一套机制。
当然除了准确性外ThreadPoolExector还有一个巨大的优势就是实现了线程之间的负载均衡,在面对这种分治情景的时候,可以拉平线程之间的负载,拉高整个效率。
到这里我们就引出了ForkJoinPool的两大核心,也是本文的两大核心:
-
线程间的负载均很(工作窃取)
-
ForkJoin
2.数据结构
聊两大核心之前我们还是要先知道整个ForkJoinPool的数据结构是什么样的,因为这样才能知道它是怎么实现两个核心点的。
不同于ThreadPoolExector,ForkJoinPool不止一个队列,除了一个全局队列外,每个线程有一个自己的局部队列。

之所以用这种数据结构就是为了实现负载均衡,怎么实现的喃——工作窃取队列。
每个工作线程的内部队列就是窃取队列。为了实现工作窃取队列,ThreadPoolExector的局部队列故意做成了一个普通数组,而不是阻塞队列,目的就是为了线程不安全。
3.两大核心
3.1.工作窃取
3.1.1.工作窃取队列的概念
工作队列的概念出自两篇论文:
"Dynamic Circular Work-Stealing Deque" by Chase and Lev,SPAA 2005
"Idempote nt work stealing" by Michael,Saraswat,and Vechev,PPoPP 2009。
什么是工作窃取队列:
一个线程执行完自己的任务后,可以窃取别人队列中的任务来执行。
怎么实现:
将任务放在一个线程不安全的队列中,工作线程从头开始拿去执行,闲了的线程从屁股开始拿去执行。这样实现了负载均衡。

(1)Worker线程自己,在队列头部,通过对queueTop指针执行 加、减操作,实现入队或出队,这是单线程的。
(2)其他Worker线程,在队列尾部,通过对queueBase进行累 加,实现出队操作,也就是窃取,这是多线程的,需要通过CAS操作。 正因为如此,在上面的数据结构定义中,queueTop 不是 volatil e 的,queueBase 是 volatile类型。
(3)整个队列是环形的,也就是一个数组实现的RingBuffer。并 且queueBase会一直累加,不会减小;queueTop会累加、减小。最后, queueBase、queueTop的值都会大于整个数组的长度,只是计算数组下 标的时候,会取queueTop&(queue.length-1),queueBase&(queue. length-1)。因为queue.length是2的整数次方,这里也就是对queue. length进行取模操作。
3.1.2.如何进行任务窃取
任务窃取是ForJoin的核心点之一,另一个核心点是Fork和Join。
前面聊了为了实现任务能被窃取,每个线程的局部队列没有用阻塞队列来实现,而是用的普通的数组来实现。
在Worker的run方法里面会去调runWorker,runWorker方法里面回去扫描窃取任务:

scan方法里面很简单,会去遍历所有Worker,尝试去窃取它们的任务,要是没有窃取到再去全局队列中拿任务,这里代码太长了,收起来了一下,感兴趣可以自己去展开读读:

3.1.3.为什么要用窃取队列
有些读者到这里可能会有一个疑惑:
采用这种全局队列+局部队列的分级设计,空闲的线程去拿任务执行。像普通线程池ThreadPoolExecutor一样,就只有一个全局的队列,也是空闲的线程去拿任务执行,两者都是空闲的线程去执行任务,本质上效率差距会很大嘛?
其实可能不会很大。之所以采用这种全局+局部的设计,更多的是为了避免其它任务影响当前这个分支,让当前分支的任务能被线程集中的执行而已。
举个例子,一个主线程fork成两个子任务,那么我们肯定是希望这两个子任务能并行的被快速执行,如果全局只有一个队列,是无法保证这两个子任务能被连续执行的,中间可能间隔着其它任务,万一间隔的是耗时很高的任务,那就麻烦了。
3.2.ForkJoin
3.2.1.Fork
fork就是将fork出来的线程放入全局队列或者局部队列中去:
如果当前工作线程是ForkJoinWorkerThread,进行fork就将fork出来的任务放入当前线程的局部队列。
如果当前线程是普通线程,进行fork就将fork出来的任务放到全局队列中去。

3.2.2.join
前面我们聊过了,fork其实就是将当前线程的任务分成很多个子任务交给多个线程来执行。然后由于当前线程是依赖于这些线程的执行结果的,必须要等所有fork出来的线程都执行完,当前线程才能继续向下执行,结果才是正确的。join就是将当前线程wait在分出来的线程上面,各个线程执行完成后去唤醒当前线程。
画个图来理解就是,当前任务有worker在执行它,有worker因为调用join后在wait它,执行它的worker在执行完成后去notifyAll所有wait它的。这整个阻塞唤醒过程用JDK原生的wait/notify实现的,并没有多复杂。

4.任务提交全流程
前面已经聊了ForkJoin的两个核心点了,现在串起来看一下整个任务提交的流程。
这个流程里我们将看见:
-
任务是怎么被提交到全局队列或者局部队列中去的
-
怎么阻塞、唤醒线程
-
怎么通知线程来拿任务
由于ForkJoinPool里面有两个队列,一个全局队列,一个线程私有的局部队列,所以根据存放位置的不同,任务也分为两种,一种是全局队列里面的外部任务,一种是局部队列里的内部任务。
从fork进来:
通过线程类型判断提交给全局队列还是提交给局部队列。

以提交给全局队列的任务为例,signalWork(),通知空闲线程来取:


底层其实封装的就是JDK线程操作原语来阻塞或者唤醒:

提交给局部队列的任务是相似的,此处就不赘述了。
5.状态控制
本文之前,博主有一篇关于ThreadPoolExector线程池的文章,里面聊了ThreadPoolExector线程池的状态控制:
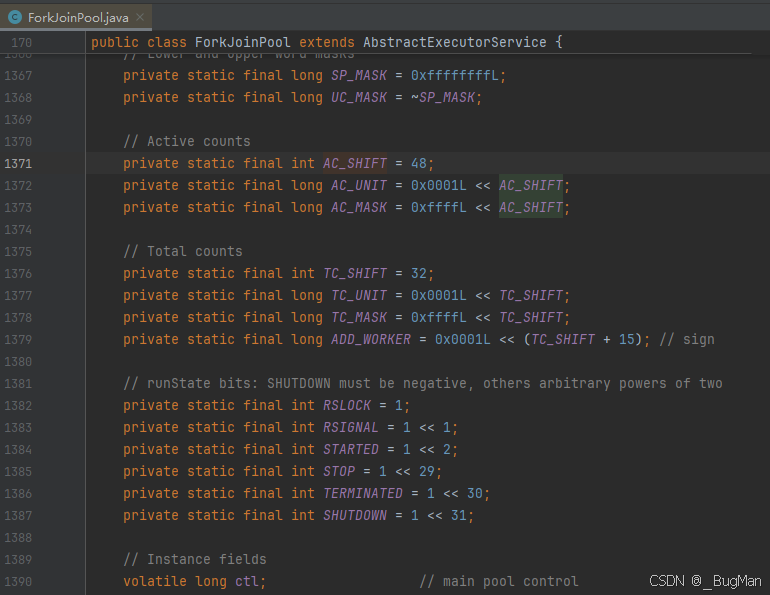
ForkJoinPool 中的 ctl 字段是一个 volatile long 类型的变量,它扮演着控制和状态信息的双重角色。ctl 字段的设计灵感来源于 ThreadPoolExecutor 中的类似概念,但 ForkJoinPool 的 ctl 字段具有自己独特的作用和结构。 ctl 字段的64位被划分为两个部分:
-
低16位:表示线程池中正在处理任务的线程数量。这部分被称为 workerCount,它反映了活跃线程的数量。初始化时,这个值通常被设为并行线程数的负值,这是因为初始时线程池还没有任何线程在运行,所以使用负数来表示预期的线程数。
-
高48位:这部分用于存储线程池的运行状态。这部分被称为 runState,它用于控制线程池的生命周期和行为,包括但不限于接收新任务、执行任务、停止和关闭线程池等。
ctl 字段的主要作用在于:
-
线程控制:通过 workerCount 部分,ForkJoinPool 可以监控和控制正在执行任务的线程数量,这对于工作窃取(work-stealing)算法至关重要,因为它需要知道哪些线程是空闲的,以便分配新任务
-
状态管理:runState 部分用于管理线程池的运行状态,包括线程池是否处于运行、关闭或停止状态。这使得线程池能够根据其当前状态作出相应的决策,比如是否接受新任务,或者是否应该停止并清理资源。
-
相关阅读:
java 的 static 和 final 用法和单例模式
复习C语言
ChatGPT模型api的python调用
性能测试常见问题总结
微信小程序 java网上宠物用品商城系统springboot
edu cf #137 Div.2(A~D)
Matplotlib双轴教程
lstat,fstat,unmask,chmod,chown,文件截断函数,空洞文件
Spring Cloud 升级之路 - 2020.0.x - 1. 背景知识、需求描述与公共依赖
Aspect Android埋点统计activity页面使用时长 onResume onPause,并保存时长
- 原文地址:https://blog.csdn.net/Joker_ZJN/article/details/140465239