-
spark 读操作
基本流程
Shuffle read的入口是ShuffleRDD的compute方法。它获取shuffleReader,执行对应的read方法。
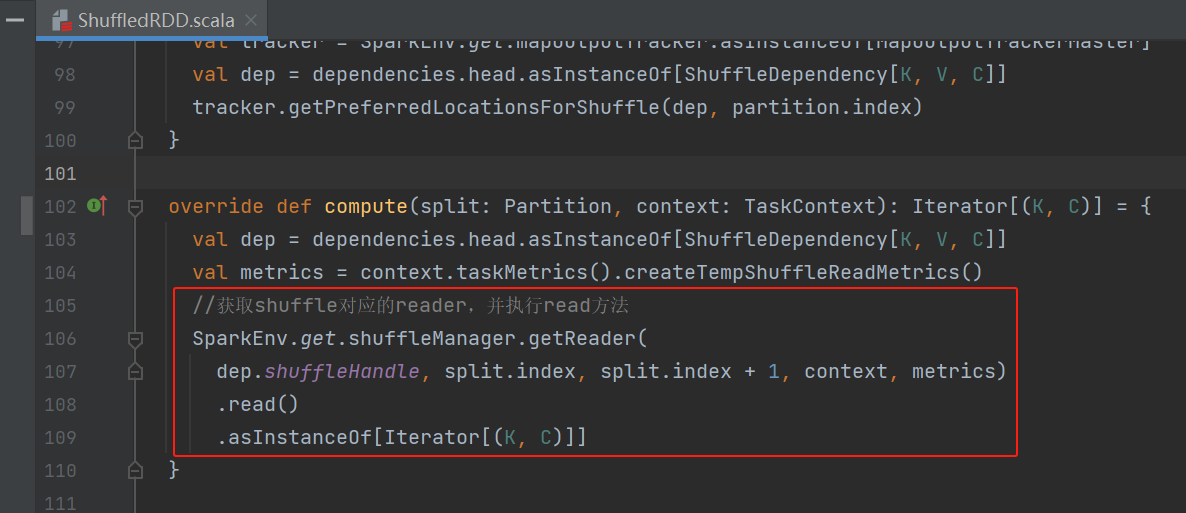
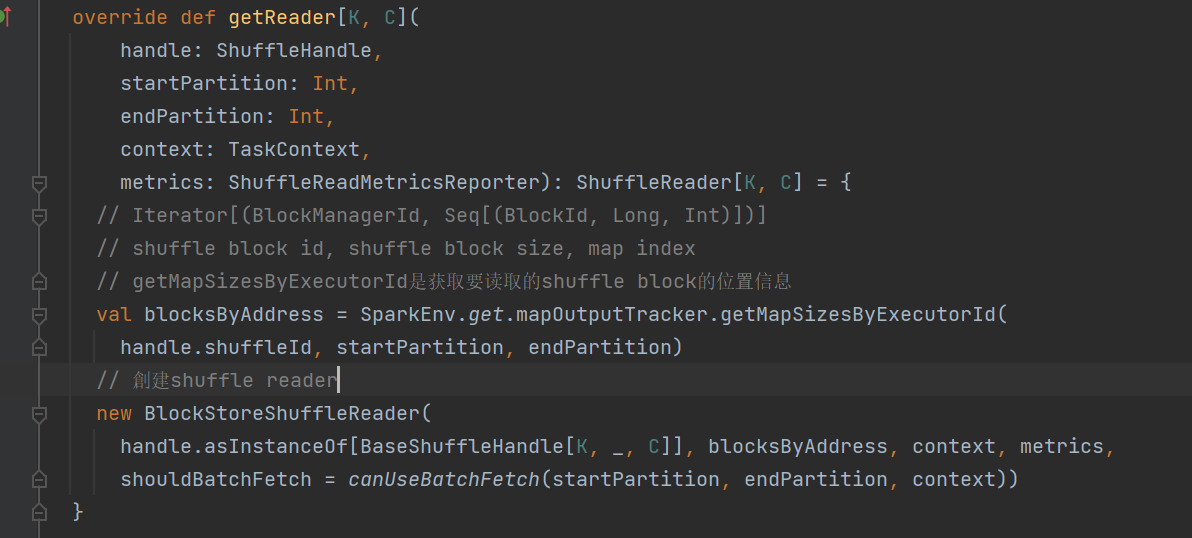
创建reader的时候首先获取要读的shuffle block对应的信息,创建shuffle reader。
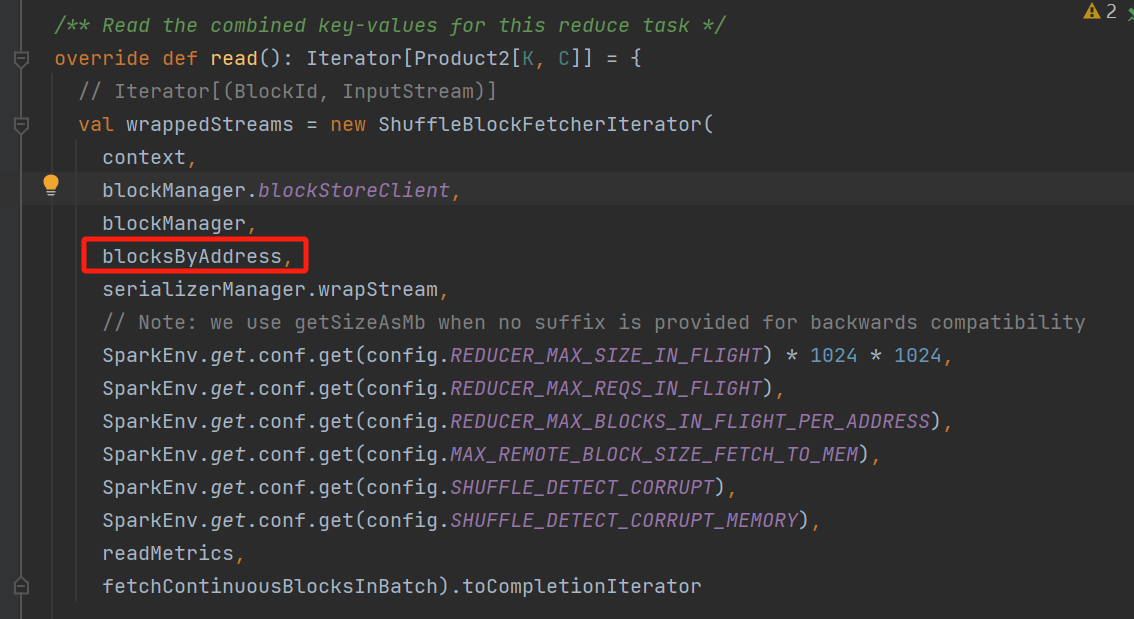
read
创建wrappedStreams:Iterator[(BlockId, InputStream)],一个block对应一个input stream
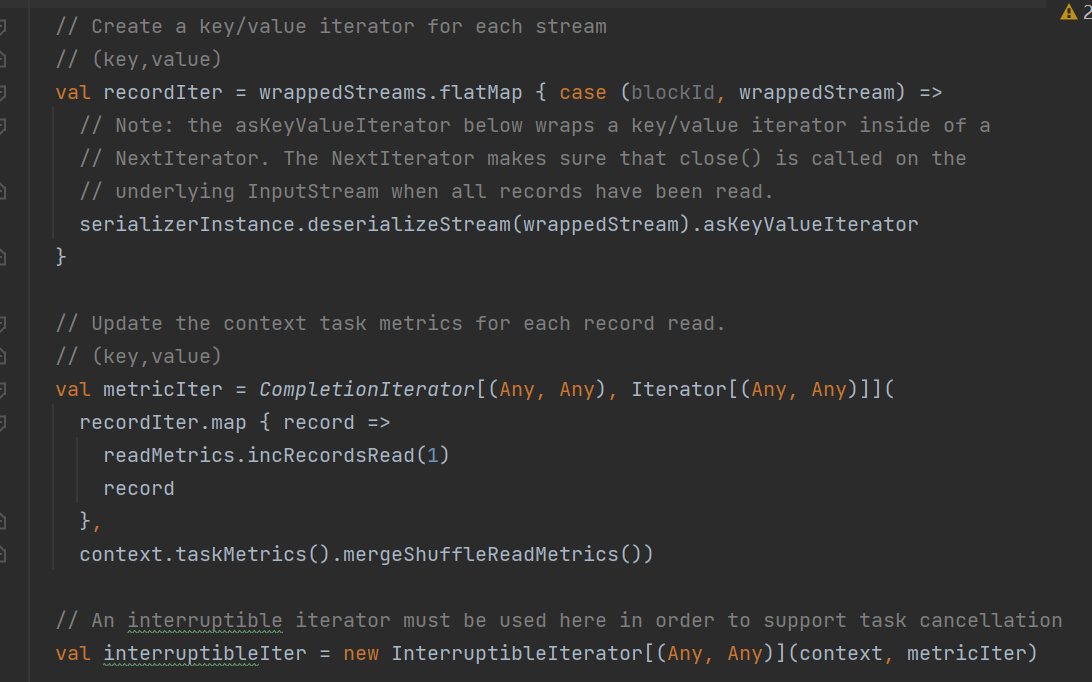
recordIter 将stream中数据反序列成(k,v)
metricIter 遍历统计
interruptibleIter 将iterator包装成可中断的iterator
aggregatedIter 处理聚合
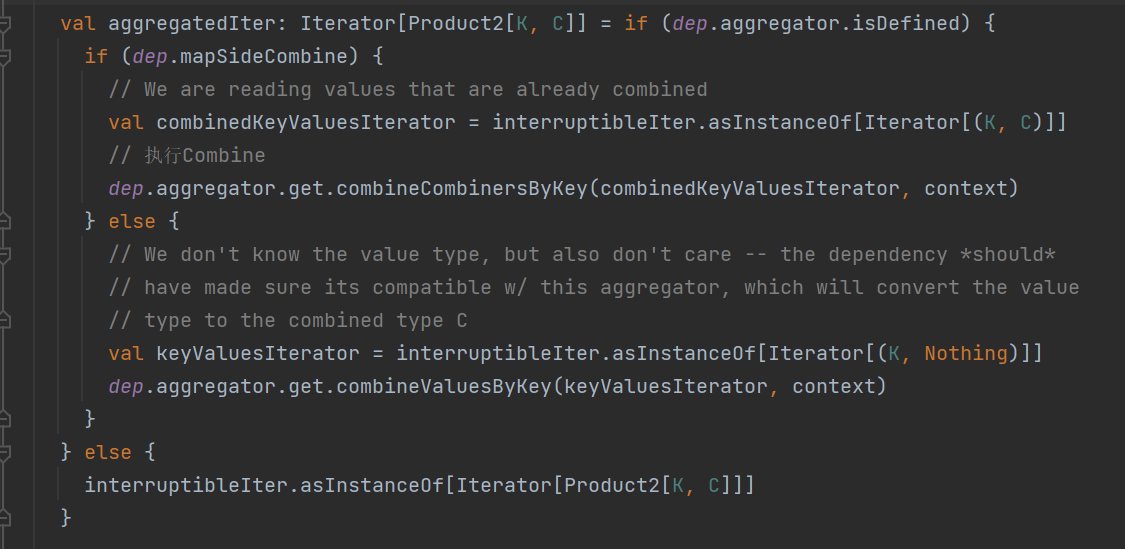
resultIter 处理排序
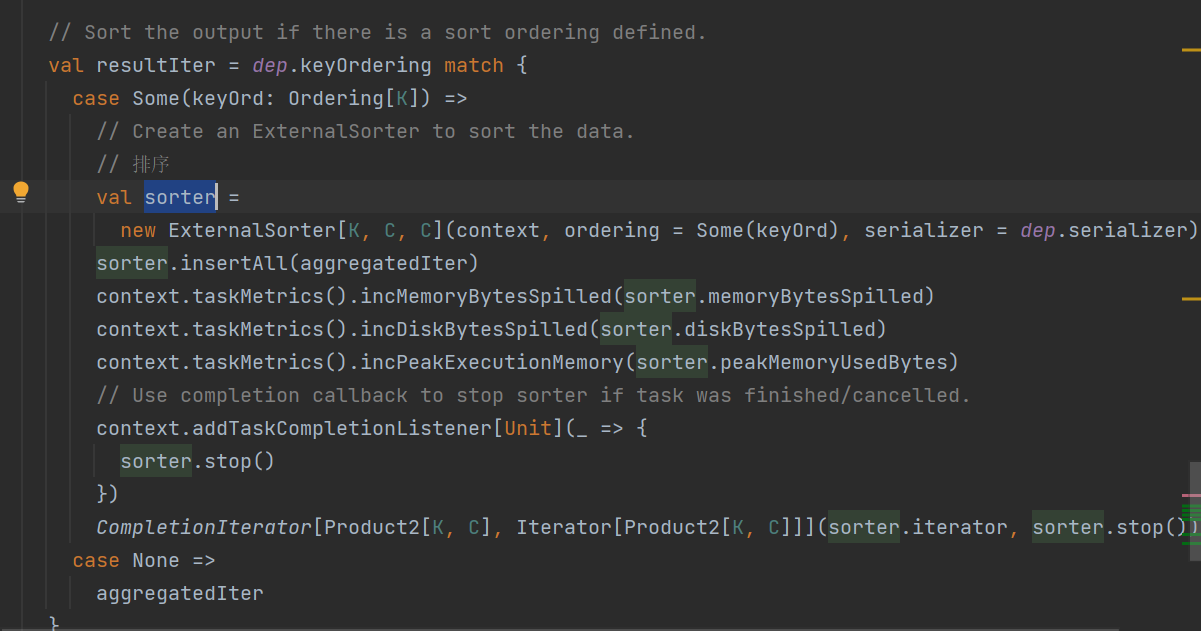
最后返回resultIter
ShuffleBlockFetcherIterator详解
ShuffleBlockFetcherIterator是read方法中最重要的部分,它读取了block转换成stream。
ShuffleBlockFetcherIterator在获取远程block数据的数据有很多限制参数,避免内存溢出。
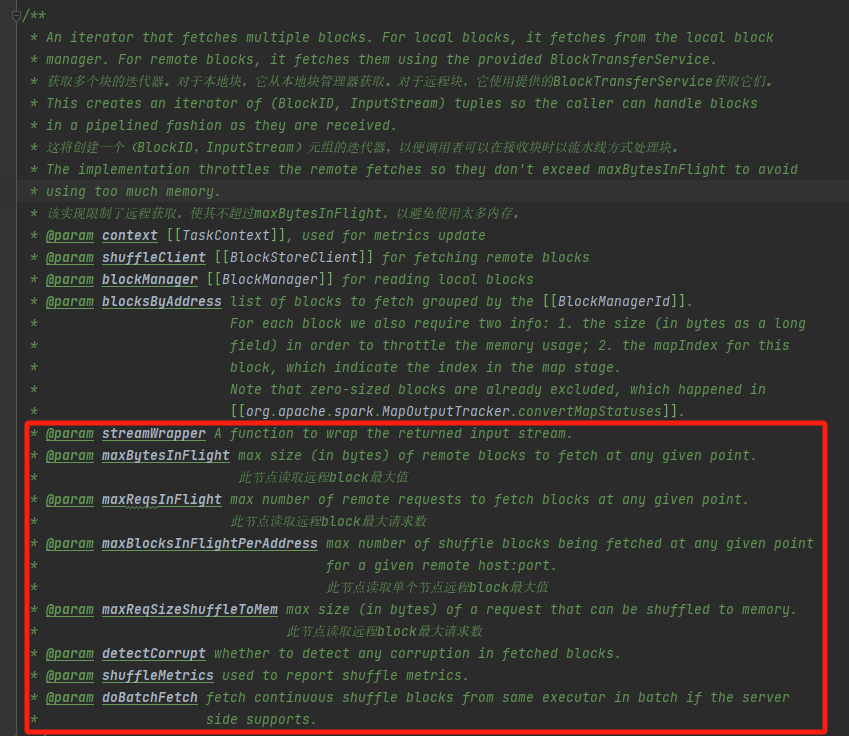
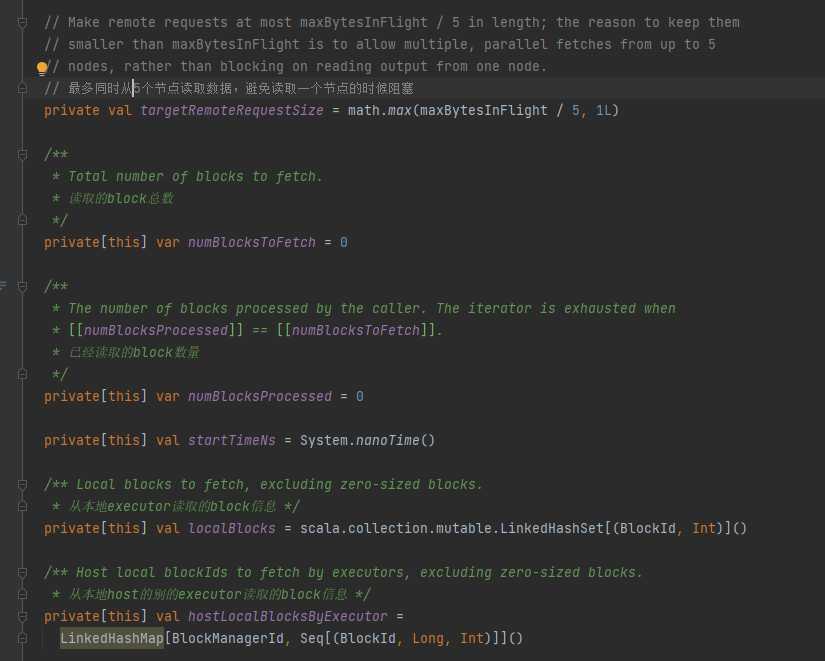
其他主要参数如下:- numBlocksToFetch 要读取的block数量
- numBlocksProcessed 已经读取的block数量
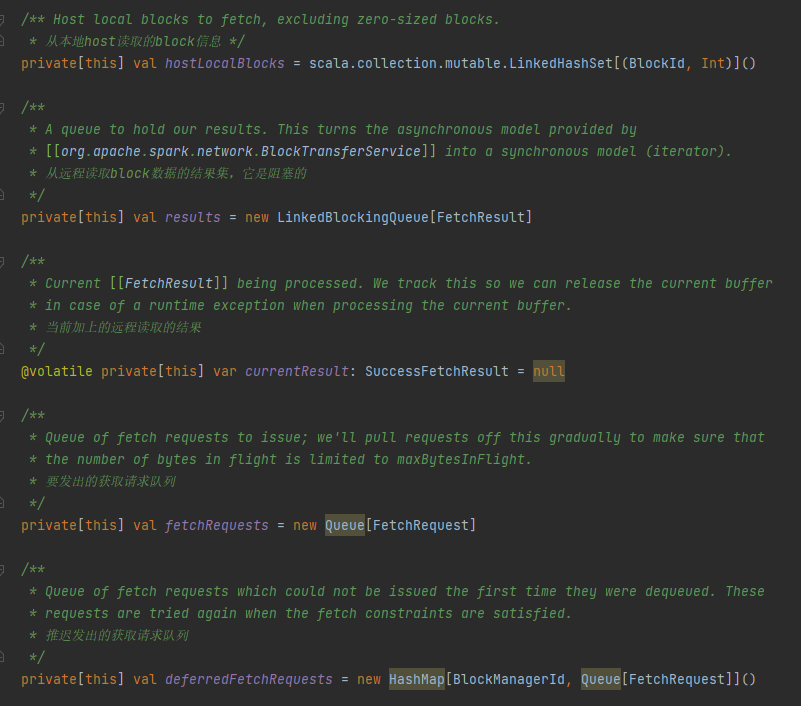
- results 读取block的结果集
- fetchRequests 全部请求
- deferredFetchRequests 延迟的请求
initialize
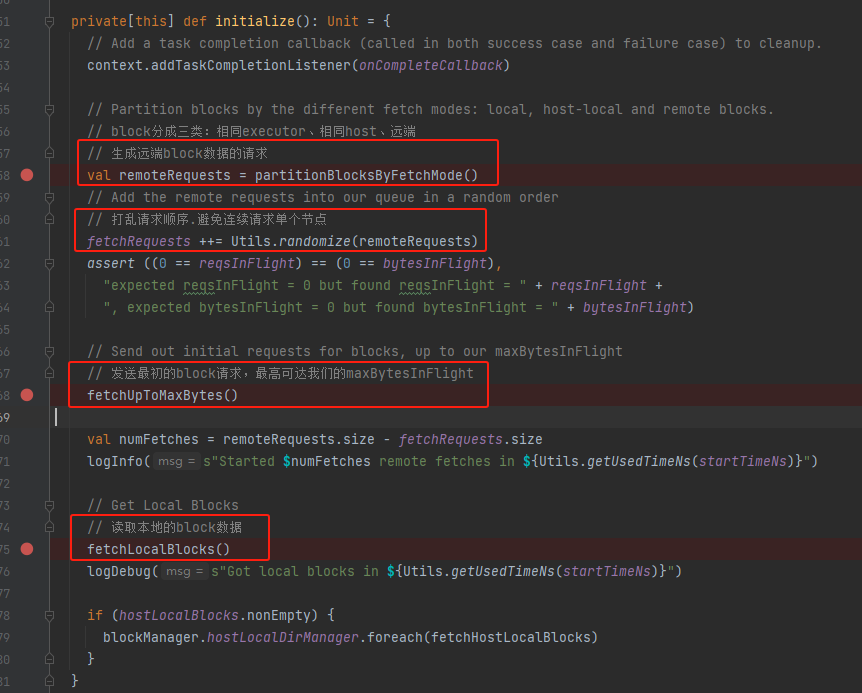
ShuffleBlockFetcherIterator创建的时候会执行initialize方法。
- 将block分类(相同executor、相同host、远端),生成远端block数据的请求
- 打乱请求顺序
- 发送读取远端block的请求
- 读取本地block
partitionBlocksByFetchMode请求分类
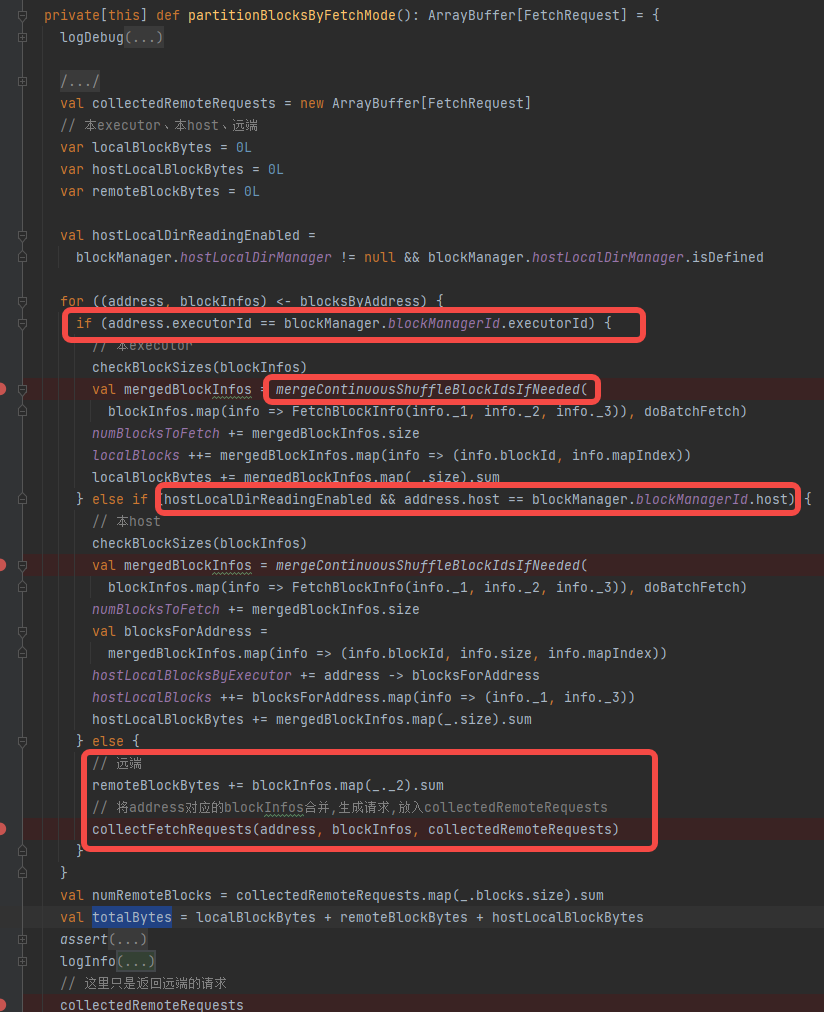
根据executorId和hostId将block分成三类,相同executor、相同host、远端。
其中相同executor、相同host都调用了mergeContinuousShuffleBlockIdsIfNeeded方法进行合并再更新相关变量
远端是调用collectFetchRequests方法,创建远端block的请求
mergeContinuousShuffleBlockIdsIfNeeded
将相同mapId、shuffleId的block请求进行合并。
例如:输入:shuffle_0_0_0, shuffle_0_0_1, shuffle_0_1_0 输出:shuffle_0_0_0_2, shuffle_0_1_0_1
输入:shuffle_0_0_0_2, shuffle_0_0_2, shuffle_0_0_3 输出:shuffle_0_0_0_4
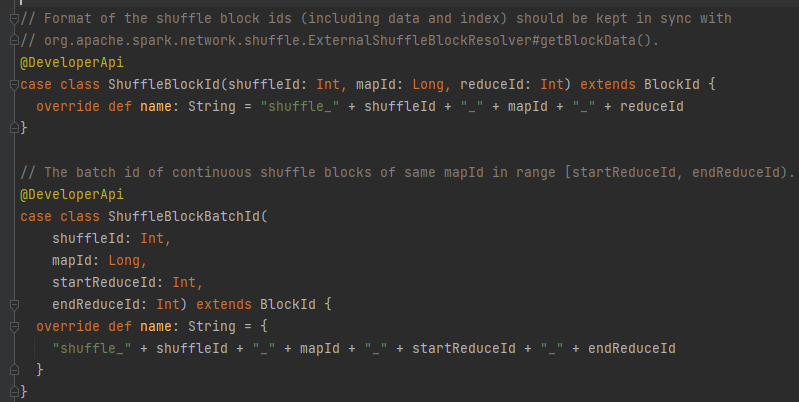
遍历block,进行合并。逻辑比较简单。
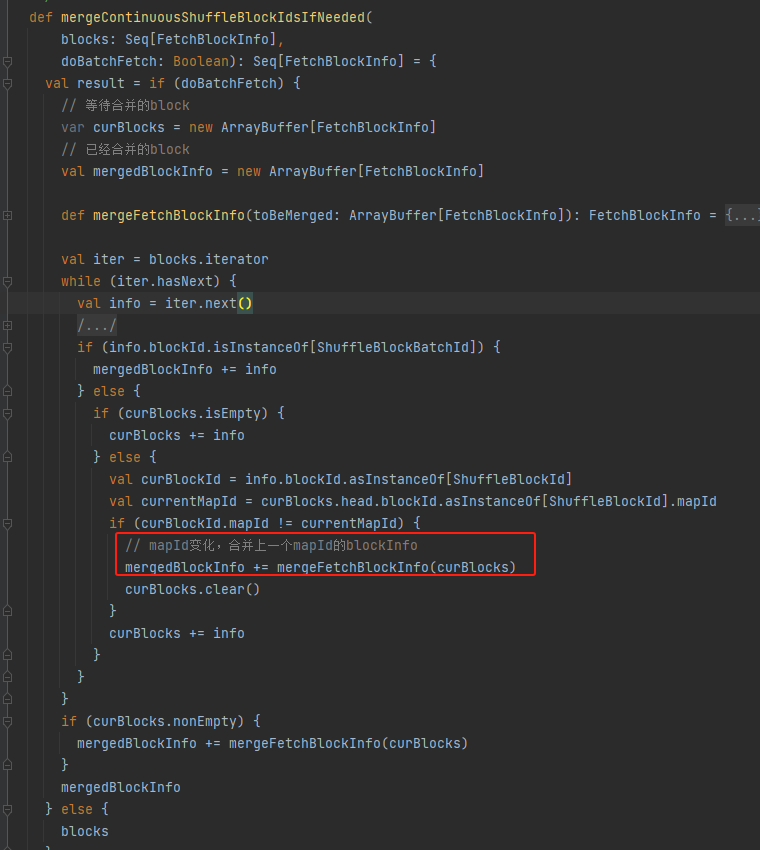
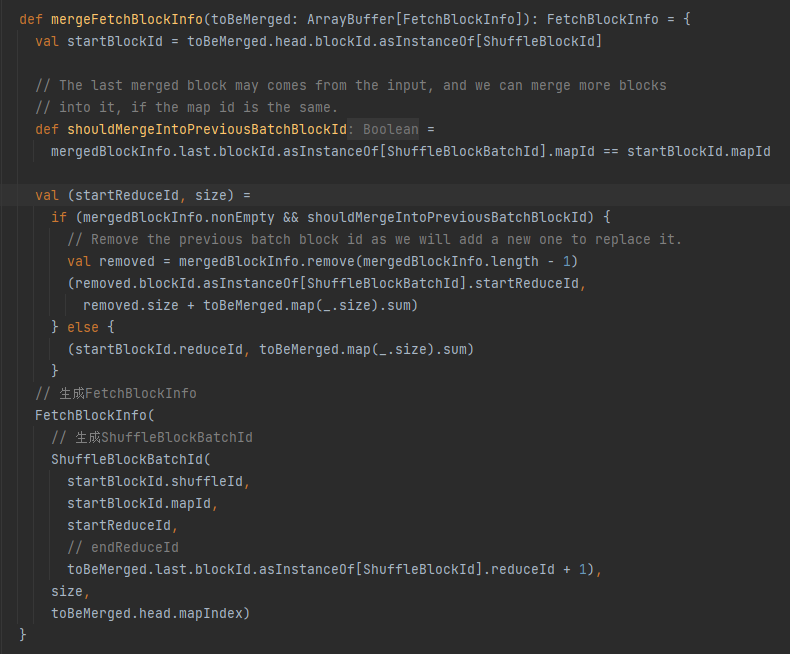
collectFetchRequests
遍历远端block,创建FetchBlockInfo加入到curBlocks先缓存。如果缓存curBlocks超过限制,就调用createFetchRequests方法,合并curBlocks的请求,写入collectedRemoteRequests。
collectedRemoteRequests中保存实际远端block的请求。
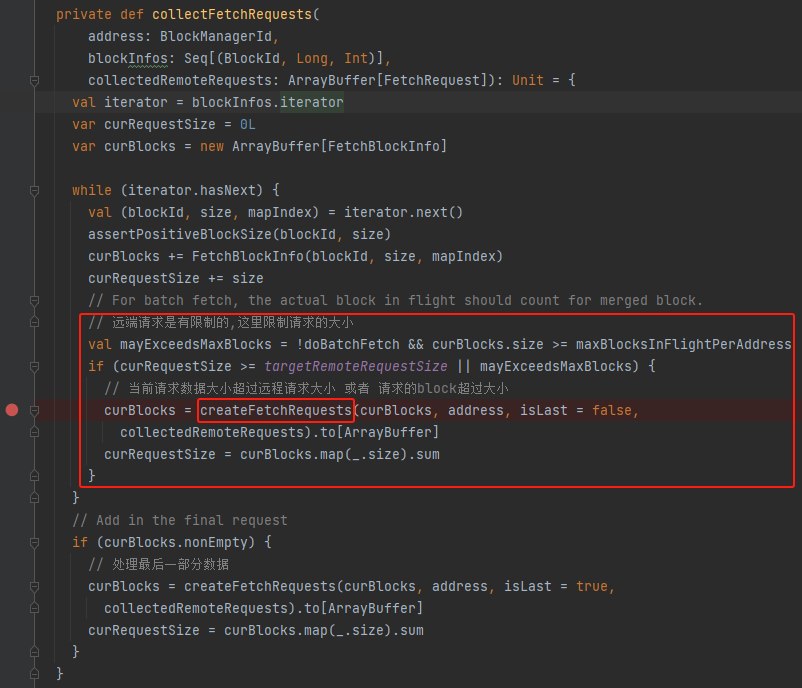
createFetchRequests
先调用mergeContinuousShuffleBlockIdsIfNeeded进行block合并成blockBatch。
如果合并后的block太大,就进行分割,生成fetch request。小的话就直接生成fetch request。
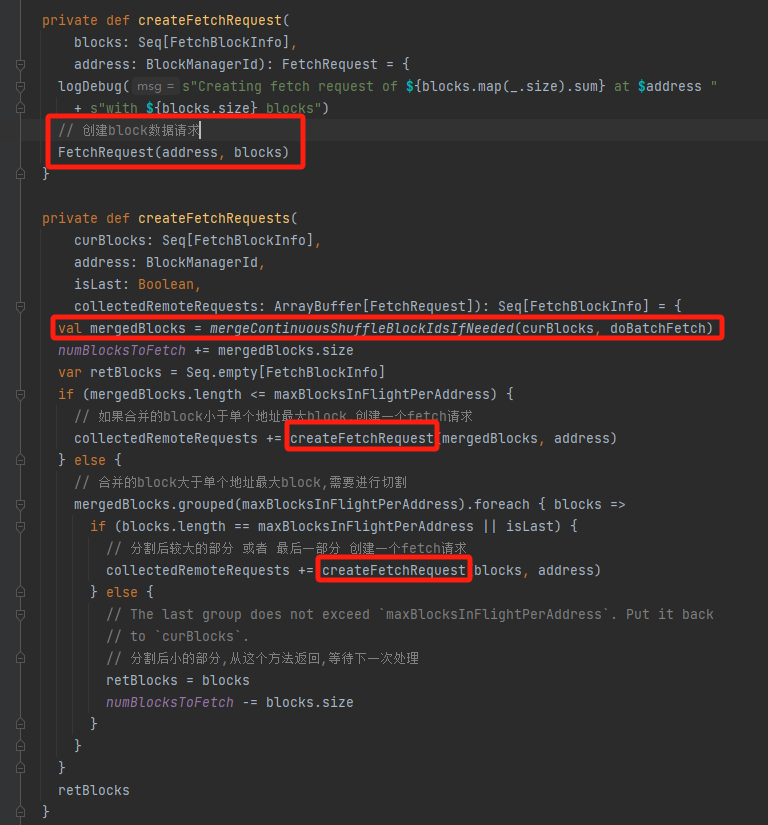
fetchUpToMaxBytes获取远程block
遍历fetchRequests,如果超过了请求限制就先放入deferredFetchRequests中,等待下一次发送。没有超过请求就调用send方法。
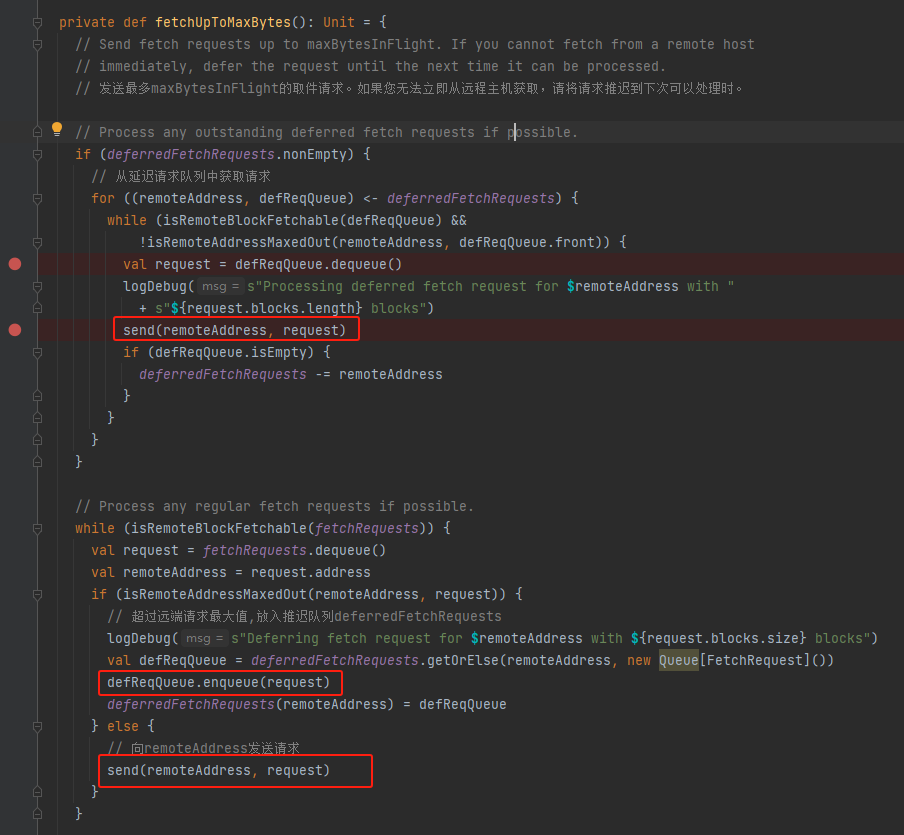
send
调用sendRequest方法。
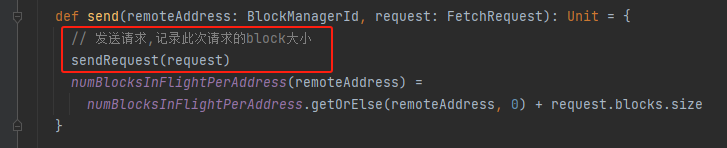
sendRequest
使用shuffleClient调用fetchBlocks方法获取block数据。如果请求的数据超过maxReqSizeShuffleToMem就写入文件,不超过的话就放入内存。同时还注册了一个监听器blockFetchingListener,在成功获取block数据后就结果放入results中。
shuffleClient是NettyBlockTransferService
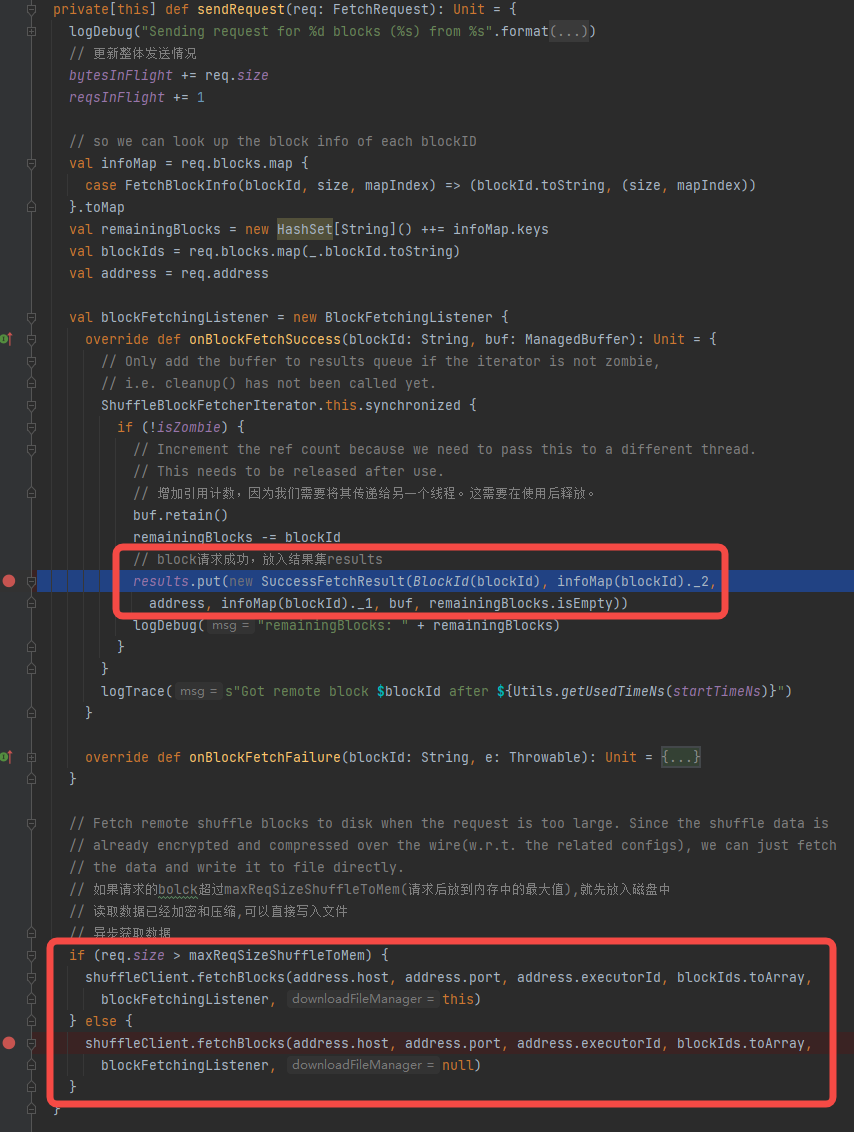
fetchBlocks
调用createAndStart方法,createAndStart方法中是先创建远程服务的client,再生成OneForOneBlockFetcher对象,调用对应的start方法。
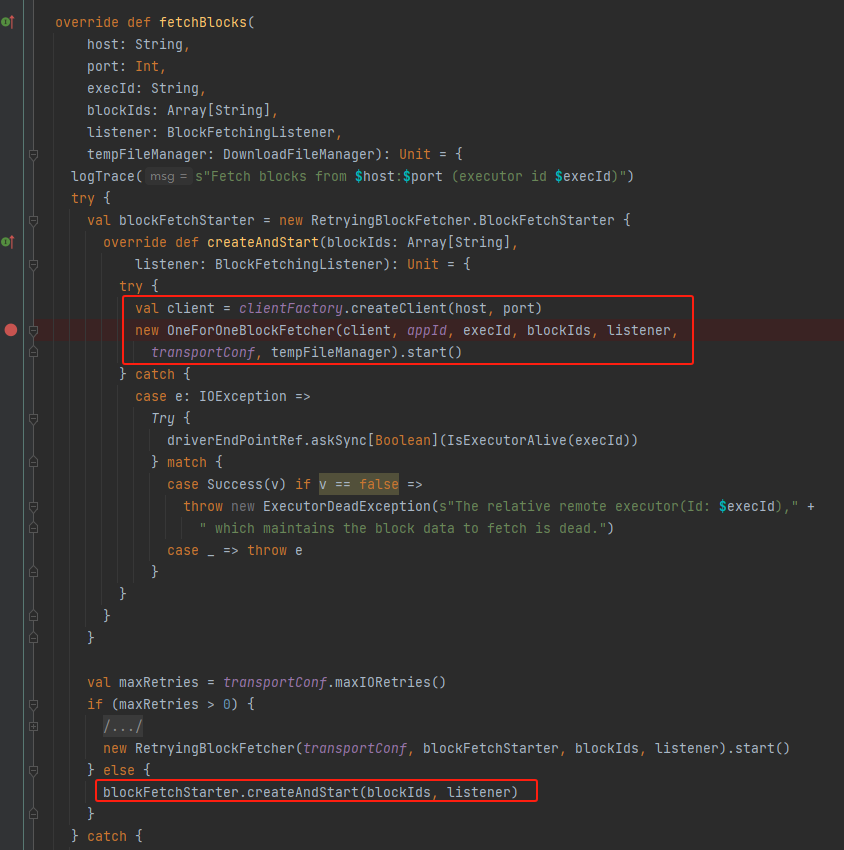
start
client发送message消息,注册回调方法,在成功后将response转换成StreamHandle,根据情况写入文件或者内存中。
message是OpenBlocks类。

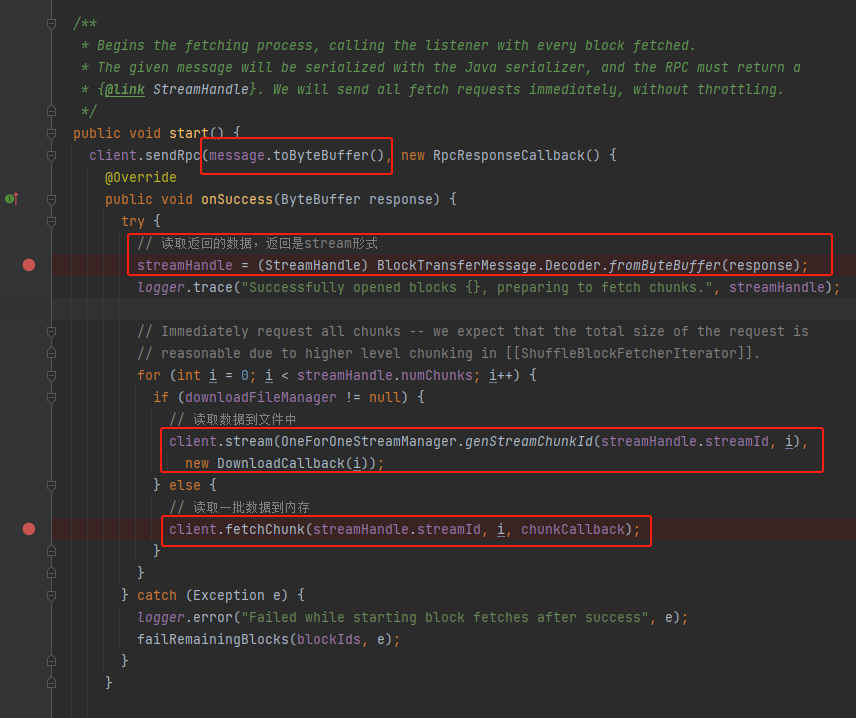
截止目前已经使用client向远端服务发送了OpenBlocks消息。
client对应的是worker中shuffleService服务,worker中创建了一个server,server中有对应处理的handler即ExternalBlockHandler。
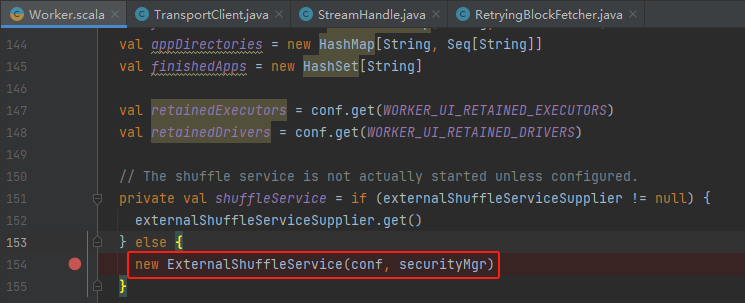
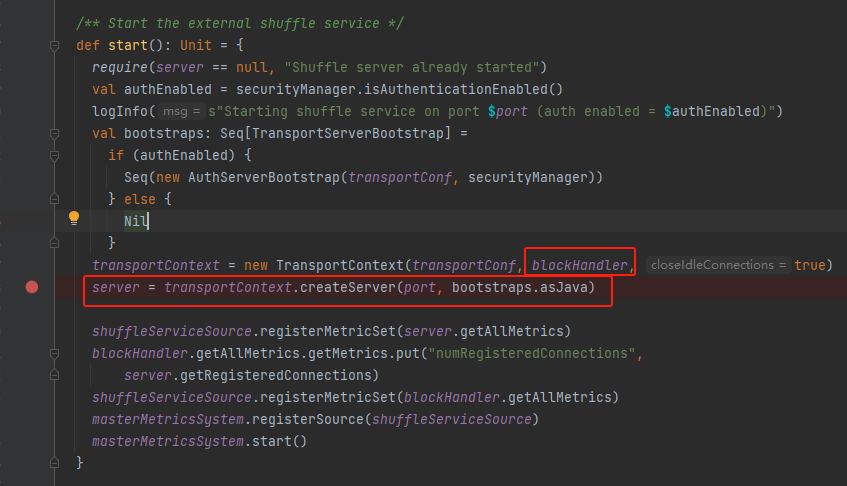
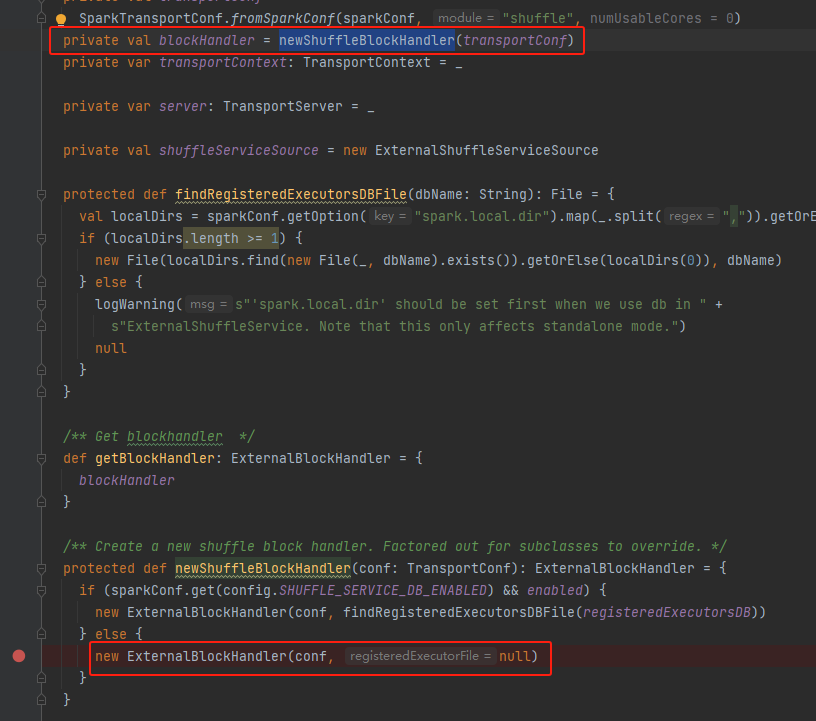
在ExternalBlockHandler会调用handleMessage处理收到的消息。
当msg是OpenBlocks消息,调用streamManager的registerStream生成streamId,然后调用回调方法的onSuccess方法(onSuccess方法是在请求端的方法)
ManagedBufferIterator
ManagedBufferIterator在构造器中,初始化了一个函数blockDataForIndexFn,可以根据index获取对应的数据(使用getBlockData方法)。

在next方法中调用blockDataForIndexFn创建ManagedBuffer数据。

registerStream
注册stream就是将buffers放入streams缓存中。后续可以根据streamId来分批获取数据。

最后调用回调方法onSuccess。到这里被请求端部分完结,转到请求端。
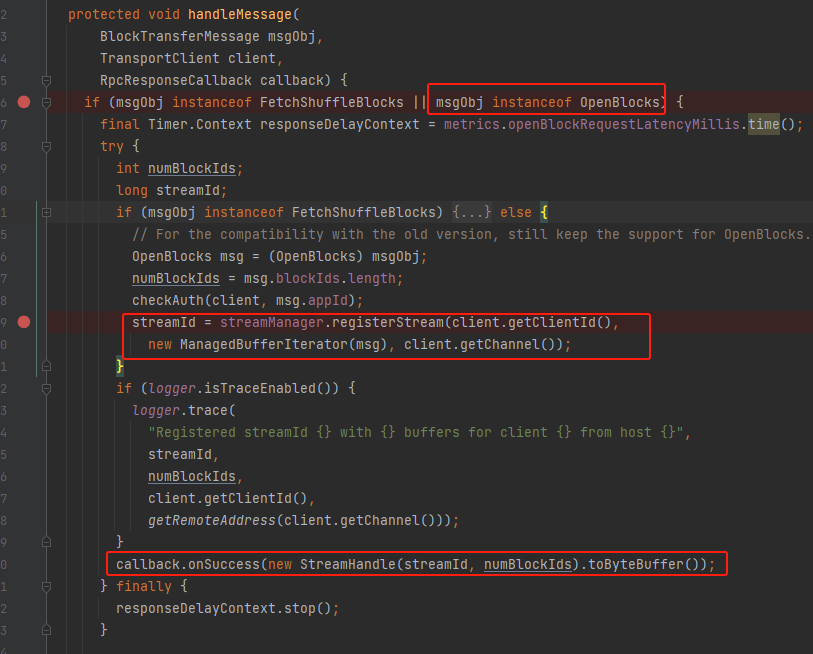
onSuccess
将response序列化为StreamHandle,根据情况选择将数据放入文件或者内存中。
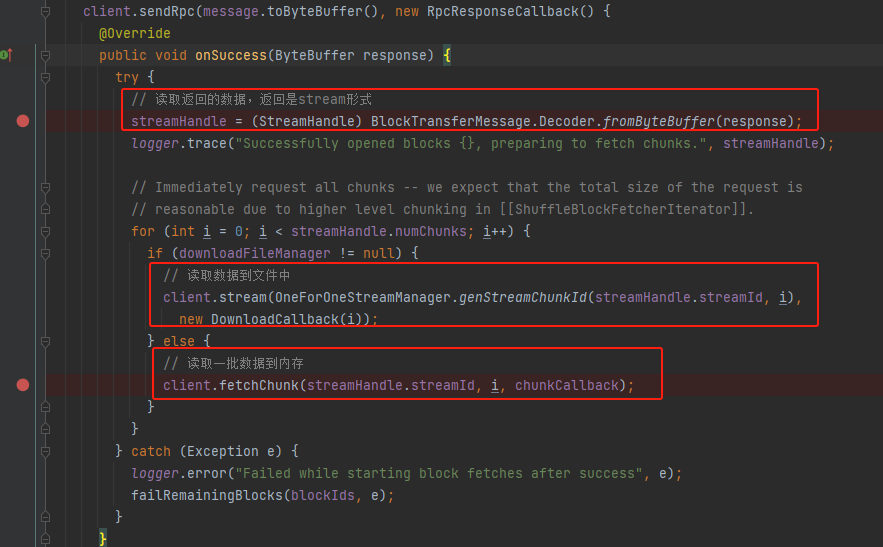
fetchChunk
根据streamId和chunkIndex生成要读取的StreamChunkId,先远端服务发送ChunkFetchRequest消息,同时注册了一个监听器listener。
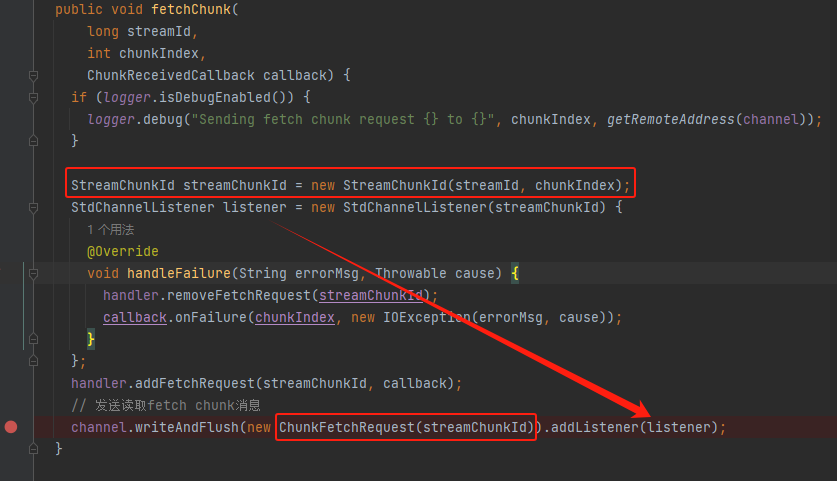
stream
同fetchChunk类似,不过是发送了StreamRequest消息。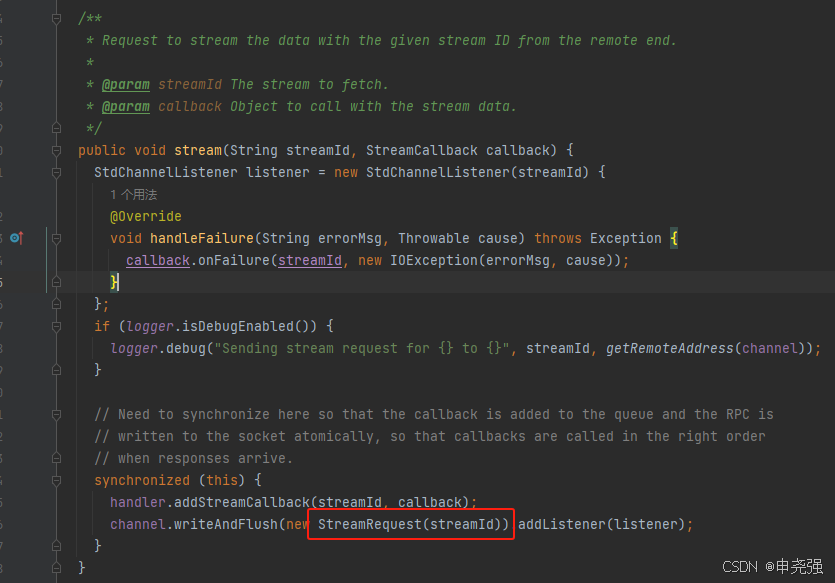
至此请求端部分结束,下面到被请求端。
请求端对应的处理类TransportRequestHandler
处理方法是processFetchRequest和processStreamRequest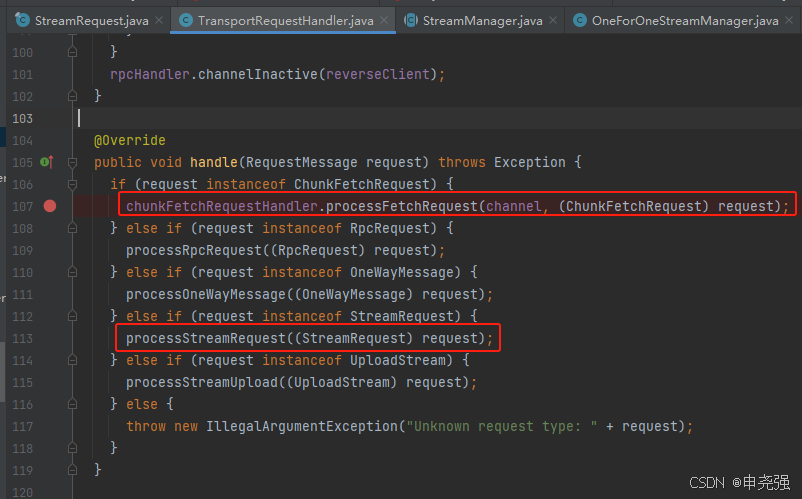
processFetchRequest
调用streamManager的getChunk方法获取到ManagedBuffer,包装成ChunkFetchSuccess,调用respond方法将数据返回给请求端。
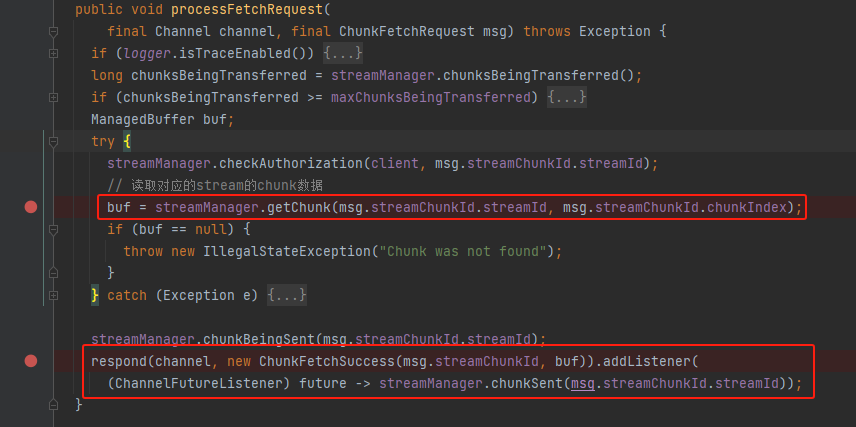
getChunk
streamManager对应的OneForOneStreamManager类。getChunk就是从streams中获取新的chunk,也就是ManagedBuffer。streams是上面在处理OpenBlocks消息的时候就已经放入了对应的数据。

respond
result是包装了ManagedBuffer的ChunkFetchSuccess消息。使用channel将数据返回给请求端。
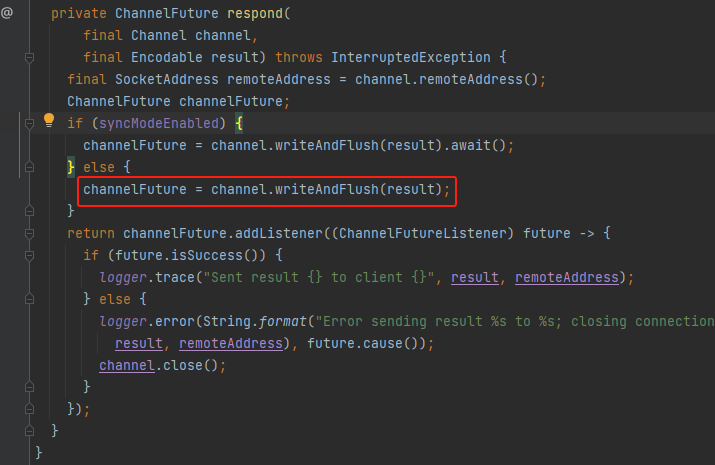
至此,被请求端处理ChunkFetchRequest返回ChunkFetchSuccess消息完成。
processStreamRequest
调用streamManager的openStream获取到ManagedBuffer,将其包装成StreamResponse消息返回给请求端。
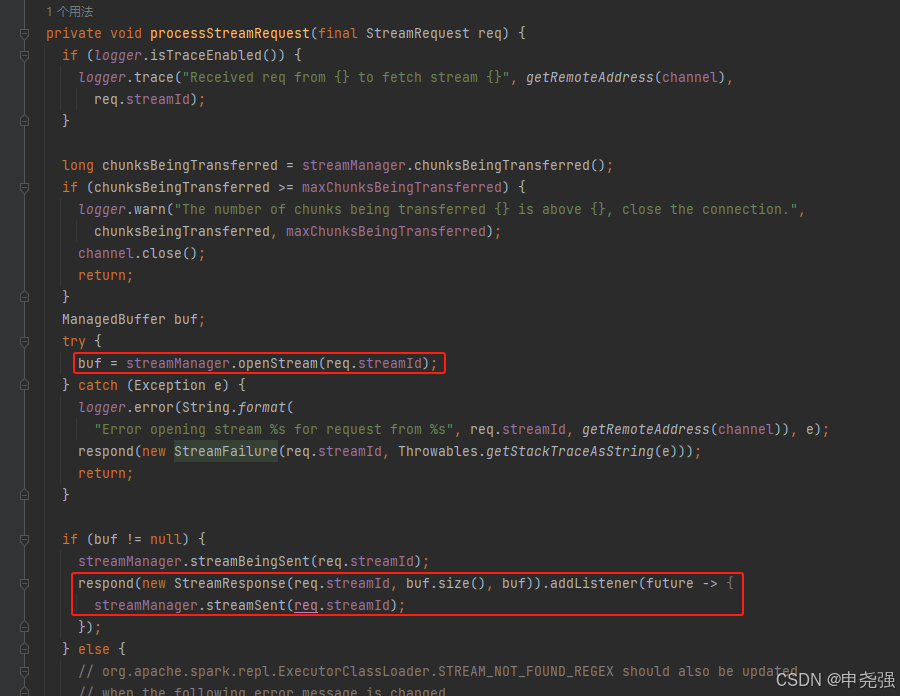
openStream
调用getChunk方法获取ManagedBuffer,getChunk方法上面已经提过。
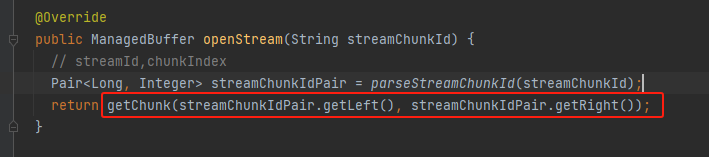
respond
result是封装了ManagedBuffer的StreamResponse消息,将其返回给请求端。
至此,被请求端处理StreamRequest返回StreamResponse消息完成。
在请求端处理ChunkFetchSuccess和StreamResponse消息的类是TransportResponseHandler
处理ChunkFetchSuccess消息
从outstandingFetches中获取对应的listener,调用listener的onSuccess方法。
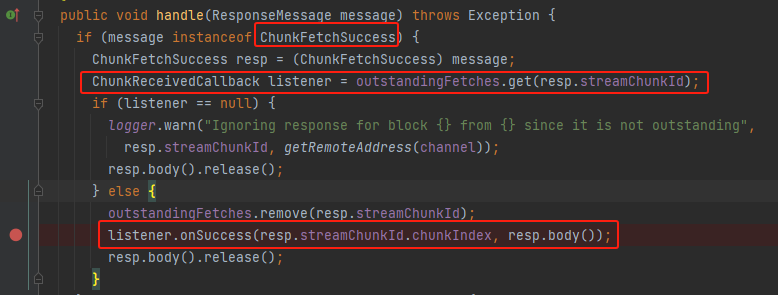
对应的listener是chunkCallback,最后调用的是onBlockFetchSuccess方法

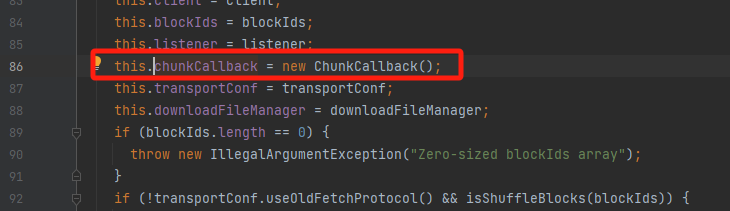
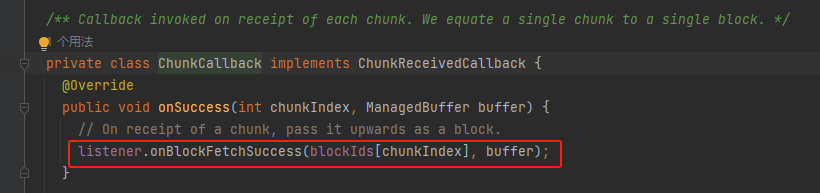
onBlockFetchSuccess
将结果ManagedBuffer包装成SuccessFetchResult放入results结果集。
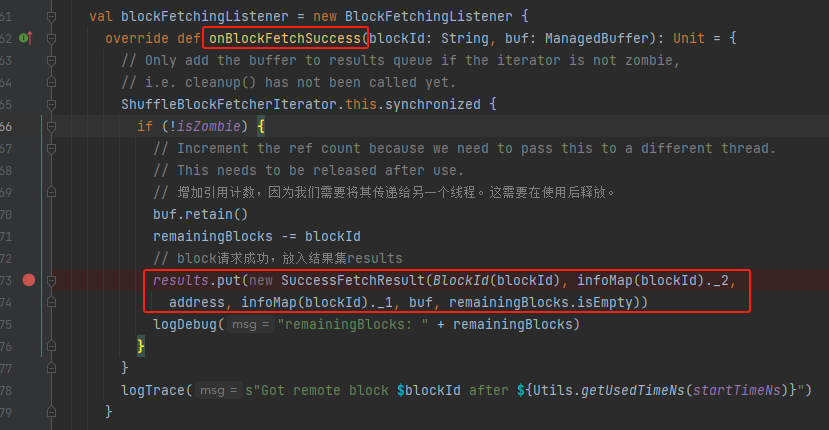
至此,请求端处理ChunkFetchSuccess部分完成,SuccessFetchResult结果放入results结果集。
处理StreamResponse消息
生成StreamInterceptor拦截器,出来处理stream消息。将拦截器注册到InboundHandler。
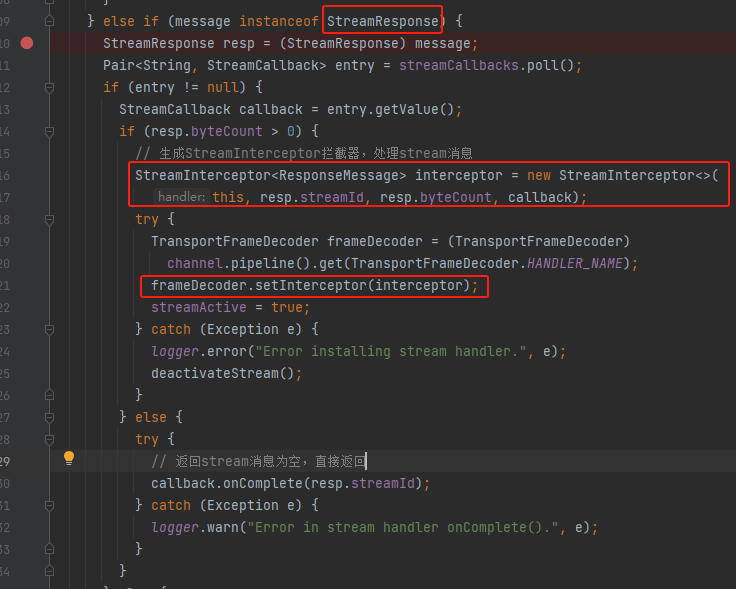
channelRead
收到data后,是调用feedInterceptor处理
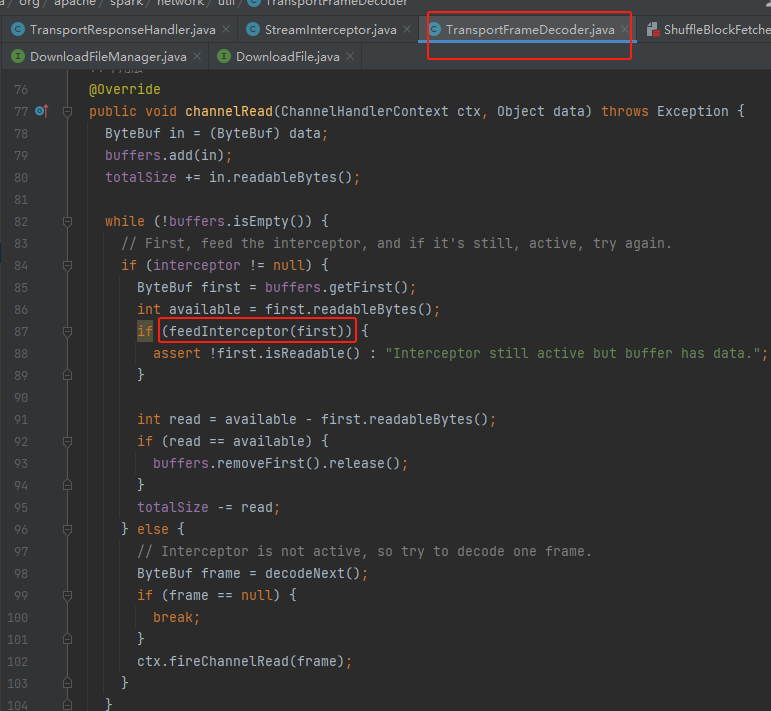
feedInterceptor
调用拦截器的handle方法
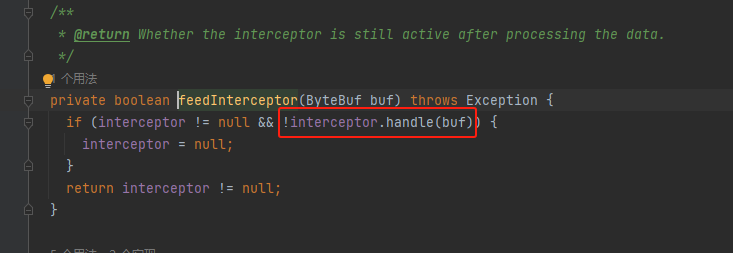
handle
分批读取数据,调用onData方法。完成后调用onComplete方法。
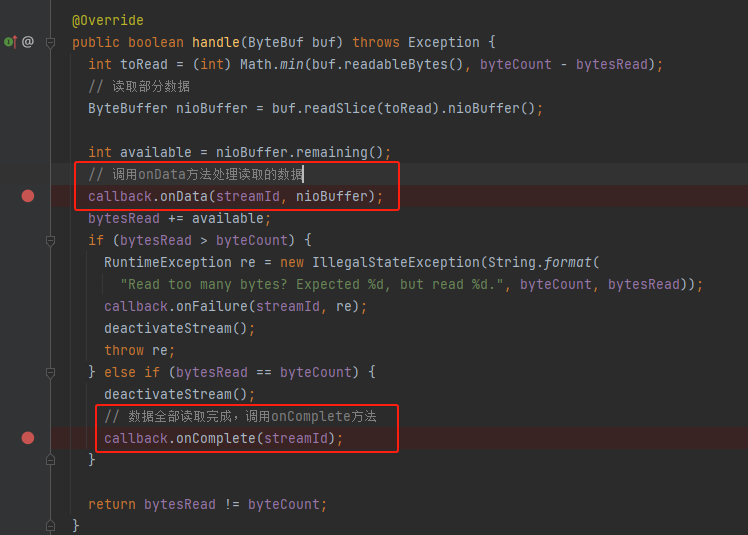
DownloadCallback回调方法
onData是将数据写入到文件中。
onComplete是同上面一样调用onBlockFetchSuccess完成,将结果ManagedBuffer包装成SuccessFetchResult放入results结果集。
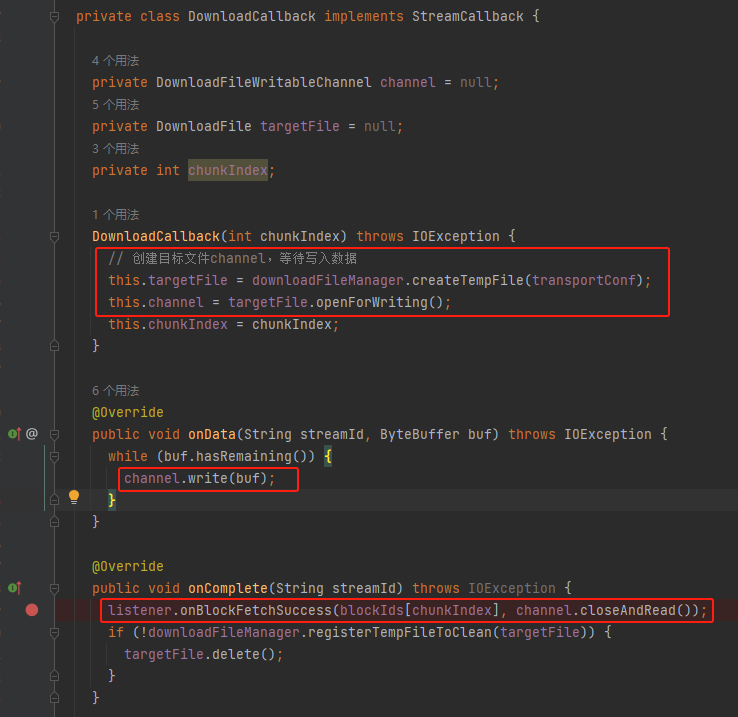
至此,请求端处理StreamResponse部分完成,SuccessFetchResult结果放入results结果集。
读取本地block数据
分成读取相同executor的数据和相同host的数据
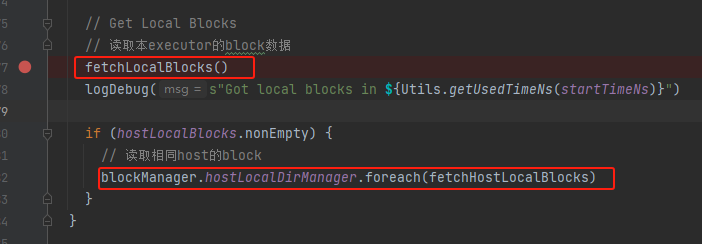
fetchLocalBlocks
根据blockId读取本地block数据,将结果放入results中。
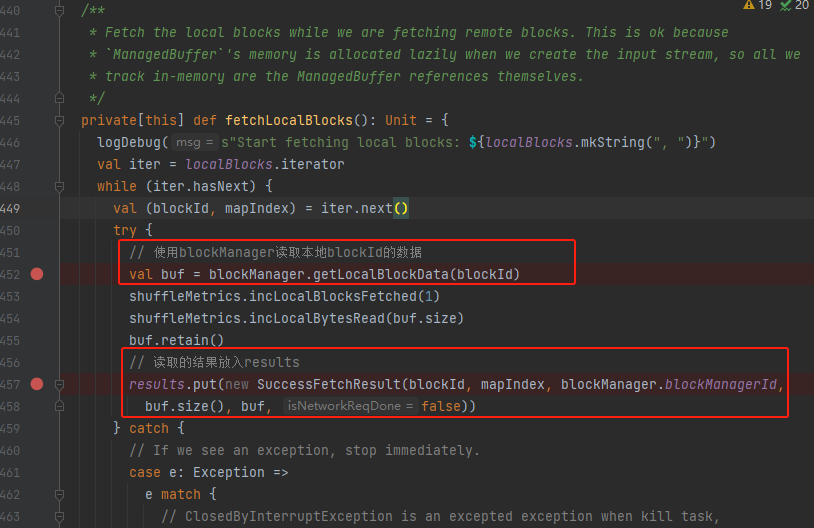
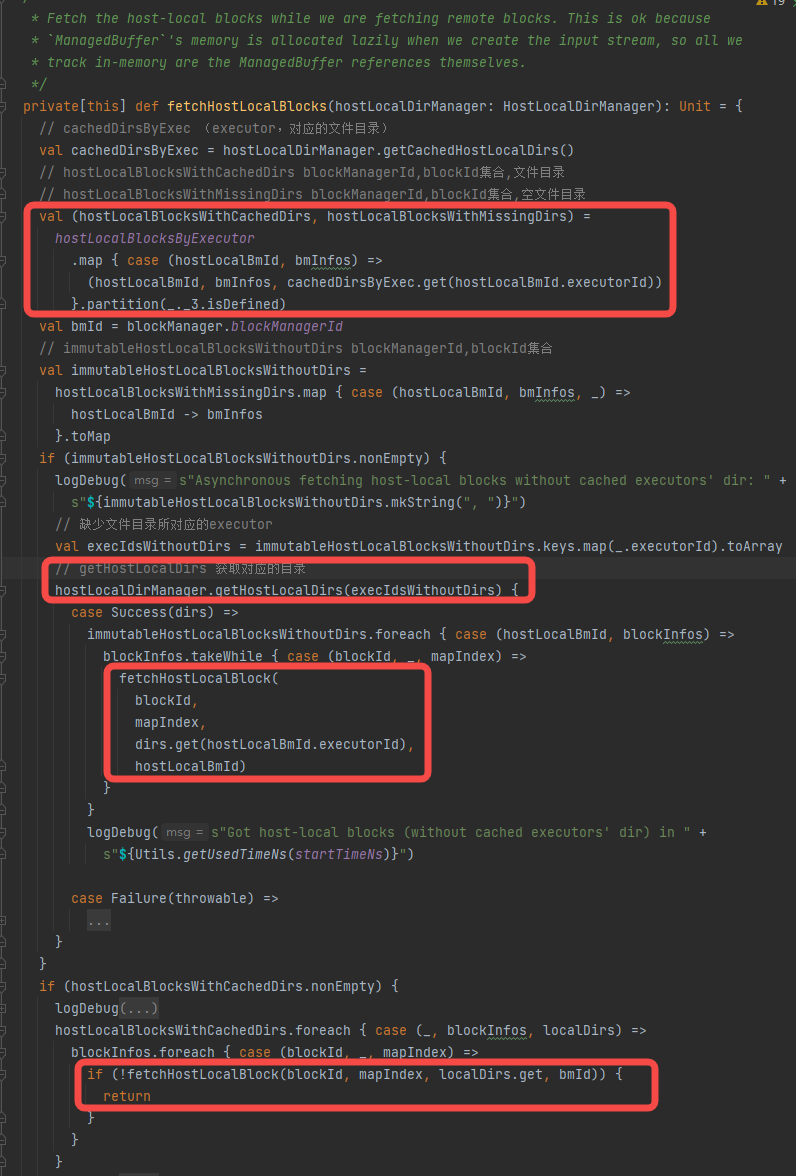
fetchHostLocalBlocks读取本地block
分成两类,一类缓存中有对应目录的blockManager,一类是缓存没有对应目录的blockManager。
没有对应目录的就调用getHostLocalDirs获取对应目录并更新相关的缓存。
最后都是调用fetchHostLocalBlock
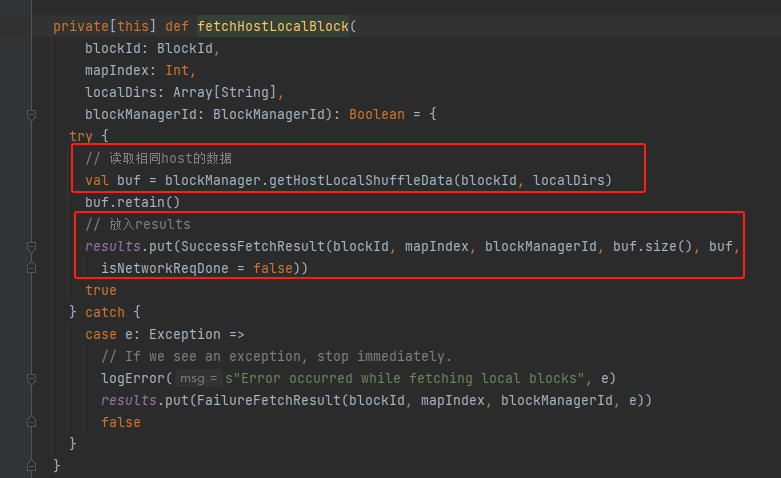
fetchHostLocalBlock
根据blockId和对应的目录读取数据,将结果放入results中
至此ShuffleBlockFetcherIterator的initialize方法完成。读取block数据的结果都放入到了results中。next
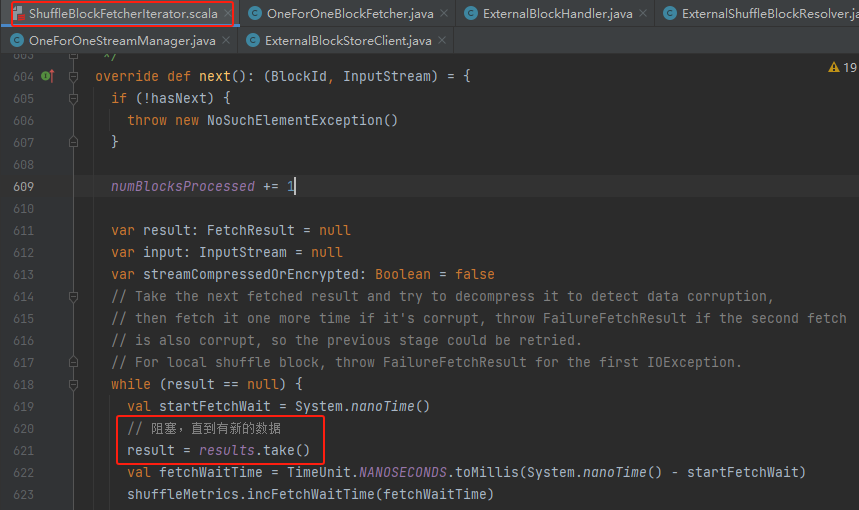
从results中获取result,results是阻塞队列,所以这里是阻塞的。
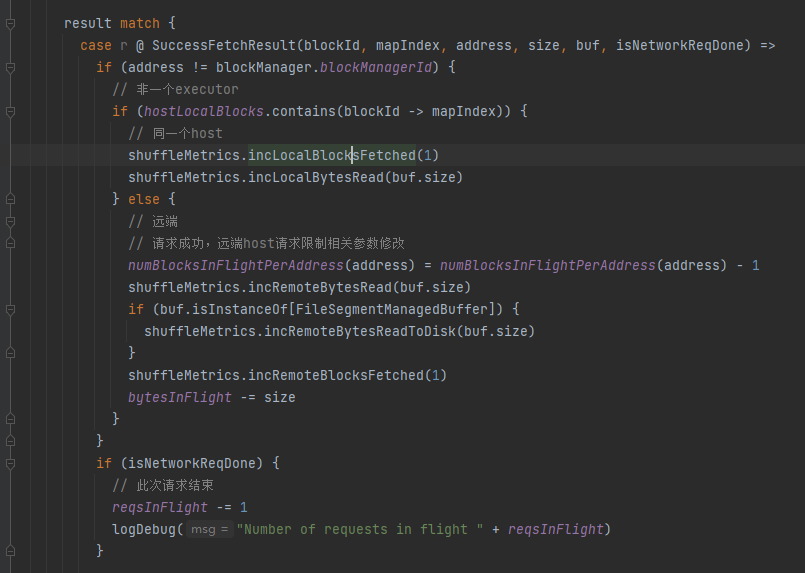
根据result更新对应的缓存数据
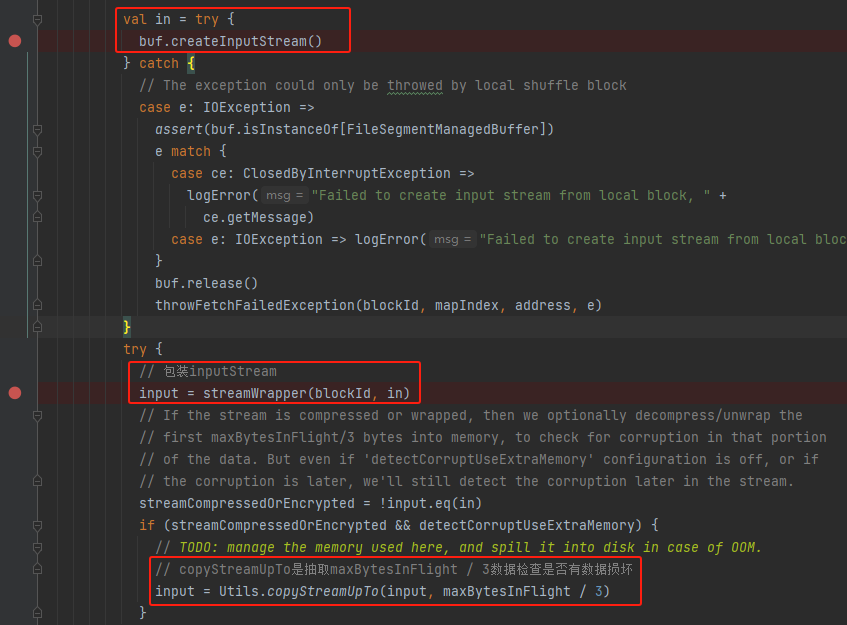
将buf转换成input stream,同时使用streamWrapper封装input stream
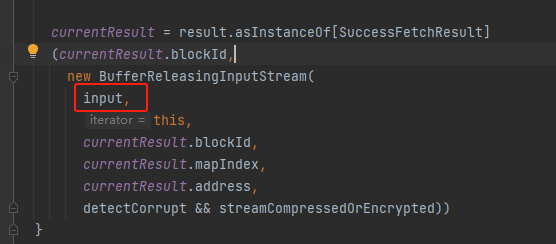
将input封装成BufferReleasingInputStream并返回。
-
相关阅读:
《HTML+CSS+JavaScript》之第7章 图片
SQL触发器
《JavaSE-第十七章》之LinkedList
linux为所有用户安装conda
框架分析(6)-Ruby on Rails
Java之线程的详细解析二
(五)Gluster 管理员(小节-1)
CMake Day 7 —— option
应广单片机实现红蓝双色爆闪灯
JAVA基础算法(6)----- 国际象棋 α 皇后问题
- 原文地址:https://blog.csdn.net/weixin_43839095/article/details/140438491