-
数据库容灾 | MySQL MGR与阿里云PolarDB-X Paxos的深度对比
开源生态
众所周知,MySQL主备库(两节点)一般通过异步复制、半同步复制(Semi-Sync)来实现数据高可用,但主备架构在机房网络故障、主机hang住等异常场景下,HA切换后大概率就会出现数据不一致的问题(简称RPO!=0),因此但凡业务数据有一定的重要性,都不应该选择MySQL主备架构(两节点)的数据库产品,推荐选择RPO=0的多副本架构。
MySQL社区,对于RPO=0的多副本技术演进:
- MySQL官方开源,推出了基于组复制的MySQL Group Replication(MGR)高可用解决方案,内部通过XCOM封装了 Paxos 协议提供了数据一致性的保障。
- 阿里云 PolarDB-X,来源于阿里电商双十一、异地多活的业务打磨和验证,在2021年10月份进行了全内核开源,全面拥抱MySQL开源生态。PolarDB-X 定位为一款集中分布式一体化数据库,其数据节点Data Node(DN)采用了自研的X-Paxos协议,高度兼容MySQL 5.7/8.0,不仅提供了金融级高可用能力,还同时具备高扩展的事务引擎、灵活的运维容灾、低成本的数据存储的特点,参考:《PolarDB-X 开源 | 基于Paxos的MySQL三副本》。
PolarDB-X集中分布式一体化的理念:数据节点DN可以被独立出来作为集中式(标准版)形态,完全兼容单机数据库形态。当业务增长到需要分布式扩展的时候,架构原地升级成分布式形态,分布式组件无缝对接到原有的数据节点,不需要数据迁移,也不需要应用侧做改造,即可享受分布式带来的可用性与扩展性,架构说明:《集中分布式一体化》

MySQL的MGR和PolarDB-X的标准版DN,两者从最底层的原理上都采用了Paxos协议,那么在实际使用上,具体的表现和差异如何呢?本文从架构对比、关键差异、测试对比方面进行分别详细阐述。
MGR/DN简称说明:MGR代表MySQL MGR的技术形态、DN代表PolarDB-X 单DN集中式(标准版)的技术形态。
TL;DR
详细对比分析比较长,可以先看一下总结和结论,有兴趣的话可以顺着总结在后续文章中找一下线索。
MySQL MGR,一般的业务和公司都不建议使用,因为需要有专业的技术知识和运维团队才有机会用好,本文也复现了MySQL MGR三个业界流传已久的"暗坑":
- 暗坑1:MySQL MGR,XCOM协议走了全内存模式,默认是不满足RPO=0的数据一致性保证(本文后续有testcase复现丢数的问题),需要显示配置一个参数才可以保证,目前MGR的设计上性能和RPO无法兼得
- 暗坑2:MySQL MGR在有网络延迟下性能比较拉胯,文章中测试了4钟网络场景的对比(包括同城3机房、两地三中心),性能参数配置下跨城只有同城的1/5,如果再开启RPO=0的数据保证,性能更没法看。因此,MySQL MGR更适合用在同机房场景,跨机房容灾不适合
- 暗坑3:MySQL MGR的多副本架构,备节点的故障都会让主节点Leader出现流量跌0,不太符合常理。文章中重点尝试开启MGR的单Leader模式(对标MySQL以前的主备副本架构),模拟备副本的宕机和恢复的两个动作,备节点的运维操作也会让主节点(Leader)出现流量跌0(持续10来秒),整体的可运维性比较差。因此,MySQL MGR在主机运维上要求比较高,需要专业的DBA团队
PolarDB-X Paxos相比于MySQL MGR,在数据一致性、跨机房容灾、节点运维上都没有MGR类似的坑,但也有个别小缺点、以及容灾上的优点:
- 简单的同机房场景下,小并发下的只读性能、高并发下的纯写性能,比MySQL MGR略低5%左右,同时多副本的网络发送,性能上有进一步的优化空间
- 优点:100%兼容MySQL 5.7/8.0的特性,同时在多副本的备库复制、故障切换路径上做了比较多的精简优化,高可用切换RTO<=8秒,业界常见的4钟容灾场景都表现不错,可以替换semi-sync(半同步)、MGR等
1. 架构对比
名词解释
MGR/DN简称说明:
- MGR:MySQL MGR的技术形态,后续内容简称:MGR
- DN:阿里云PolarDB-X 集中式(标准版)的技术形态,其中分布式下的数据节点DN可以被独立出来作为集中式(标准版)形态,完全兼容单机数据库,后续内容简称:DN
MGR

MGR 支持单主、多主模式,完全复用 MySQL 的复制系统,包括 Event、Binlog & Relaylog 、Apply、Binlog Apply Recovery、GTID。与DN的关键区别在于 MGR 事务日志多数派达成一致的切入点在主库事务提交之前。
- Leader:
-
- 事务提交前调用before_commit钩子函数group_replication_trans_before_commit,进入 MGR 的多数派复制
- MGR 借助 Paxos 协议,将 THD 上缓存的 Binlog Events 同步所有在线节点
- MGR 收到多数派应答后,确定可以提交事务
- THD 进入事务组提交流程 ,开始写本地 Binlog更新Redo回复客户端OK报文
- Follower:
-
- MGR 的 Paxos Engine 持续侦听来自 Leader 的协议消息
- 经过完整的一次 Paxos 共识过程,确认这个(批)Event 在集群已经达到多数派
- 将接收的Event写入 Relay Log,IO Thread Apply Relay Log
- Relay Log应用走完整的组提交流程,备库会最终会生成自己的binlog文件
MGR采用上述流程的原因,是因为MGR默认是多主模式,每个节点都可以写,所以单个Paxos Group内Follower节点需要将接受的日志先转成RelayLog,然后结合自身作为Leader接收的写事务提交,在两阶段组提交流程中生产Binlog文件提交最终事务。
DN

DN 复用了 MySQL的基础数据结构和函数级代码,但是将日志复制、日志管理、日志回放、崩溃恢复环节跟X-Paxos 协议紧密结合在了一起,形成了自己的一套多数派复制和状态机机制。与MGR的关键区别在于 DN 事务日志多数派达成一致的切入点在主库事务提交过程中。
- Leader:
-
- 进入事务的组提交流程,在组提交的Flush阶段,将各THD 上的 Events 写入 Binlog 文件,然后再通过X-Paxos将日志异步广播给所有 Follower
- 在组提交的Sync阶段,先持久化Binlog,然后更新X-Paxos 持久化的位点
- 在组提交的Commit阶段,先要等待 X-Paxos 收到多数派应答后,然后提交这组事务,最后回复客户端OK报文
- Follower:
-
- X-Paxos 持续侦听来自 Leader 的协议消息
- 收到一个(组) Events,写入到本地 Binlog,回应答
- 收到下一个消息,其中携带了已经达成多数派的位点Commit index
- SQL Apply线程后台持续应用接收到的Binlog日志,最多只应用到多数派位点位置
这种设计的原因是,DN当前只支持单主模式,所以X-Paxos 协议层面的日志就是 Binlog 本身,Follower也省去了 Relay Log,其持久化的日志和 Leader 等的日志的数据内容是等价相同的。
2. 关键差异
2.1. Paxos协议效率

MGR
- MGR的Paxos协议基于Mencius协议实现,属于Multi-Paxos理论,区别在于Mencius在降低主节点负载提高吞吐量上做了优化改进
- MGR的Paxos协议的由XCOM组件实现,支持多主和单主模式部署,单主模式时Leader 上 Binlog 向 Follower 节点的原子广播,每批消息(一个事务)的广播是标准的一次Multi-Paxos 过程
- 一个事务的多数派的满足,XCOM至少需要经历Accept+AckAccept+Learn三个报文交互,即至少1.5个RTT开销。最多需要经历Prepare+AckPrepare+Accept+AckAccept+Learn三个报文交互,即最多一共2.5个RTT开销
- 由于Paxos协议是在XCOM模块内高内聚完成的,MySQL复制系统不感知, 所以Leader必须等待完整的 Paxos 过程完毕才能进行事务本地提交,包括Binlog的持久化和组提交
- Follower在完成多数派提交后,会异步进行Events的持久化到Relay Log,然后由SQL Thread应用和组提交生产Binlog
- 由于Paxos同步的日志是进入组提交流程前没有排序的Binlog,所以Leader 上 Binlog Event 的顺序,和 Follower 节点上 Relay Log 的 Event 顺序未必相同

DN
- DN的Paxos协议是基于Raft协议实现,也属于Multi-Paoxs理论,区别在于Raft协议更强Leadership保障和工程稳定性保证
- DN的Paxos协议由X-Paoxs组件完成,默认是单主模式,单主模式时Leader 上 Binlog 向 Follower 节点的原子广播,每批消息的广播是标准的一次 Raft过程。
- 一个事务的多数派的满足,X-Paoxs只需要经历Append+AckAppend 两个报文交互,只有1个RTT开销
- Leader 发给 Follower 日志后,只要多数派满足,它就提交事务,不等待第二阶段的 Commit Index 广播
- Follower在完成多数派提交的前提,需要要全部事务日志必须持久化,这点与MGR的XCOM有显著差别, MGR只需要在XCOM内存中接收到即可
- Commit Index 在后续消息和心跳消息中带过去,Follower在CommitIndex推高后,再进行Apply Event
- Leader 和 Follower 的 Binlog 内容顺序一致,Raft 日志无空洞,并且用 Batching/Pipeline机制加大日志复制吞吐量
- 相比MGR,事务提交时Leader始终只有一次来回的延迟,对延迟敏感的分布式应用十分很关键
2.2. RPO
理论上 Paxos 和 Raft 都可以保证数据一致性,以及 Crash Recovery 后已经达成多数派的日志不丢失,但是在具体工程上还是有区别。
MGR
XCOM 完全封装了 Paxos 协议,而它的所有协议数据又都是先缓存在内存中,默认情况事务达成多数派不要求日志持久化。 在多数派宕机、Leader故障的情况下,在会有 RPO != 0严重问题。假设一极端场景:
- MGR集群由三个节点ABC组成, 其中AB同城独立机房,C是跨城。A是Leader, BC是Follower节点
- 在Leader A节点上发起事务001, Leader A将事务001的日志广播给BC节点,通过Paxos协议满足多数派即可认为事务可以提交。AB节构成了多数派,C节点由于跨城网络延迟并没有收到事务001的日志
- 下一个时刻,Leader A提交了事务001并返回Client 成功,此时表示事务001已经提交到数据库
- 此刻 B节点的Follower上,事务001的日志还在XCOM 缓存中,还没来得及刷到 RelayLog中;此刻C节点的Follower上仍然没有接收到A节点的Leader的发过来的事务001日志
- 此时,AB节点宕机, A节点故障长时间不能恢复,B节点很快重启恢复, BC两节点继续提供读写服务
- 由于宕机时事务001日志并没有持久化到节点B的RelayLog中,也没有被节点C接收到,因此此刻BC节点其实都已经丢失了事务001,并且无法找回
- 这种多数派宕机的场景下,导致了RPO!=0
社区默认参数下,事务达成多数派不要求日志持久化,不保证RPO=0,可以认为是XCOM工程实现中为了性能的取舍。要想保证绝对的RPO=0, 需要将控制读写一致性的参数group_replication_consistency配置为AFTER,但这样的话,事务达成多数派除了需要1.5个RTT网络开销外,还需要一次日志IO开销,性能会很差。
DN
PolarDB-X DN采用X-Paxos实现分布式协议, 与MySQL的Group Commit流程深度绑定,在一个事务进行提交时,强制要求多数派确认落盘持久化后,才能允许真正提交。这里多数派落盘是指主库的Binlog落盘,备库的IO线程接收到主库的日志并落盘持久化到自己Binlog中。因此即使在极端场景下所有节点故障,数据也不会丢失,也能保证RPO=0。
2.3. RTO
RTO时间与系统本身冷重启的时间开销密切相关,反映到具体基础功能上,就是:故障检测机制->崩溃恢复机制->选主机制->日志追平
2.3.1. 故障检测
MGR
- 每个节点周期性向其他节点发送心跳包检测其他节点是否健康,心跳周期固定是1s,无法调整
- 当前节点如果发现其他节点超过group_replication_member_expel_timeout(默认5s)后没有响应则视为失效节点,并从集群中踢出
- 像网络闪断或者异常重启这种异常,待网络恢复后,单个故障节点自己会尝试自动加入集群,然后追平日志
DN
- Leader节点周期性向其他节点发生心跳检包检查其他节点是否健康,心跳周期为选举超时时间的1/5。选举超时时间由参数consensus_election_timeout控制, 默认5s,所以Leader节点心跳周期默认1s
- Leader如果发现其他掉线了,仍然继续周期性想其他所有节点发送心跳包,以确保其他节点崩溃恢复后能及时接入。但是Leader节点不再向已经掉线的节点发送事务日志
- 非Leader节点不发送心跳检测包,但是非Leader节点如果发现超过consensus_election_timeout时间没有收到Leader节点的心跳,则触发重新选举
- 像网络闪断或者异常重启这种异常,待网络恢复后,故障节点自己会自动加入集群
- 因此在故障检测方面,DN提供了更多运维配置接口,对于跨城部署场景故障的识别度会更加准确
2.3.2. 崩溃恢复
MGR
-
- XCOM实现的Paxos协议是内存态,多数派的达成不要求持久化,协议状态以存活的多数派节点内存状态为准。如果所有节点都挂掉,也就无法恢复协议了,集群重启后此时需要人工介入进行恢复
- 如果只是单个节点崩溃恢复,但是Follower节点落后Leader节点较多事务日志,此刻Leader 上的 XCOM 缓存的事务日志已经清除了,就只能走Global Recovery 或 Clone流程
- XCOM缓存大小由group_replication_message_cache_size控制,默认1GB
- Global Recovery 是指节点重新加入集群时,通过从其他节点获取所需的缺失事务日志(Binary Log)来恢复数据。这个过程依赖于集群中至少有一个节点保留了所有需要的事务日志
- Clone依赖Clone Plugin,用于数据量较大或缺失较多日志时的恢复。它通过将整个数据库的快照复制到崩溃的节点,然后通过最新事务日志进行最终同步
- Global Recovery 和 Clone 流程通常是自动化的,但在某些特殊情况下,如网络问题或者其他两个节点XCOM缓存都清除了,这时需要人工介入解决
DN
-
- X-Paxos协议使用Binlog持久化,崩溃恢复时,会先完整恢复已提交事务。对于悬挂事务,需要等待XPaxos协议层先达成一致确定主备关系后,再进行提交或者回滚处理。 整个流程全自动化。即使如果所有节点都挂掉,集群重启也能自动恢复
- 对于Follower节点落后Leader节点很多事务日志场景,只要Leader上Binlog文件没有删除,Follower节点就一定追上
- 因此在崩溃恢复方面,DN是完全不需要人工介入的
2.3.3. 选主
单主模式下, MGR的XCOM和DN X-Paxos 这种强 Leader 模式的选主,所遵循的基本原则是一样的--集群已共识的日志不能回退。 但是到未共识的日志时,存在差异
MGR
- 选主更多意义上是接下来哪个节点充当 Leader 服务,这个 Leader 当选时不一定拥有最新的共识日志,所以它需要从集群的其他节点同步最新日志,待日志追平后提供读写服务
- 这样的好处是,Leader 本身的选择是个策略化的产物,比如权重,比如顺序。 MGR通过group_replication_member_weight参数控制各节点权重
- 劣处是新当选的Leader本身可能复制延迟较多,需要继续追平日志,或者应用延迟较多,需要继续追平日志应用,才能提供读写服务。这会导致RTO时间较长
DN
- 选主就是协议意义上的,哪个节点拥有集群全部多数派的日志,它就可以当选 Leader,所以这个节点之前可能是 Follower,也可能是 Logger
- 而 Logger 是不能提供读写服务的,等它把日志同步给其他节点后,自己就主动让出 Leader 角色
- 为了能确保指定节点成为Leader,DN使用乐观权重策略+强制权重策略来限定当主顺序,使用策略化多数派机制确保新主零延迟立刻能提供读写服务
- 因此在选主方面,DN不仅支持与MGR一样的策略化选择,还支持强制权重策略
2.3.4. 日志追平
日志追平是指主备之间日志存在日志复制延迟,备库需要追平日志。对于重启恢复的节点,通常都是以备库开始恢复,并且已经和主库产生了比较的的日志复制延迟,需要向主库追平日志。对于那些和 Leader 物理距离较远的节点,多数派达成通常和它们没关系,它们总是存在复制日志延迟一直在追平日志。这些情况都需要具体工程实现来确保日志复制延迟的及时解决。
MGR
- 事务日志都在 XCOM 缓存中,而缓存默认只有1G,所以复制落后很多的 Follower 节点请求日志的时候,很容易缓存早已被清理
- 此时这个落后的 Follower 会自动踢出集群,然后以前面崩溃恢复提到Global Recovery 或 Clone流程,追平后再自动加入集群。如果遇到如网络问题,或者其他两个节点XCOM缓存都清除的情况,这时需要人工介入解决
- 为什么一定要先踢出集群,因为多写模式故障节点极大影响性能,且 Leader 的缓存对它没有任何作用,异步追平后再加进来
- 为什么不能使用直接读取Leader本地的Binlog文件,因为前面提到的XCOM协议是全内存态,Binlog 和 Relay Log 中没有任何关于 XCOM 的协议信息
DN
- 数据都在 Binlog 文件上,只要 Binlog 没有清理,那按需发送就好了,不存在踢出集群的情况
- 为了降低主库从Binlog文件中读取老的事务日志带来的IO抖动,DN优先从FIFO Cache中读取最近缓存的事务日志, FIFO Cache由参数consensus_log_cache_size控制,默认64M
- 如果FIFO Cache中老的事务日志已经更新的事务日志淘汰掉了,DN会尝试从Prefetch Cache中读取之前缓存的事务日志,Prefetch Cache有参数consensus_prefetch_cache_size控制,默认64M
- 如果Prefetch Cache中也没有需要的老的事务日志,DN会尝试发起异步IO任务,批量从Binlog文件中读取指定事务日志前后若干连续的日志,放置在Prefetch Cache中,等待DN下一次重试读取
- 因此在追平日志方面,DN完全不需要人工介入
2.4. 备库回放延迟
备库回放延迟是同一个事务在主库完成提交的时刻与在备库完成事务应用的时刻之间的延迟,这里考验的是备库Apply应用日志的性能。它影响的是异常发生时,备库成为新主后需要多久才能自身数据应用完毕可以提供读写服务。
MGR
- MGR备库从主库接收落盘的是RelayLog文件,Apply应用时需要重新将RelayLog读取,经历完整两阶段组提交流程,生产对应的数据和Binlog文件
- 这里事务应用效率与主库上事务提交效率相同,默认的双一配置(innodb_flush_log_at_trx_commit、sync_binlog)会导致备库应用同样资源开销较大
DN
- DN备库从主库接收落盘的就是Binlog文件,应用时需要重新将Binlog读取,只需要经历一阶段组提交流程,生产对应的数据即可
- 由于DN支持完整的Crash Recover,备库应用不需要开启innodb_flush_log_at_trx_commit=1,因此实际上不受双一配置的影响
- 因此在备库回放延迟方面,DN备库回放效率会远大于MGR
2.5. 大事务影响
大事务不仅影响普通事务提交,在分布式系统中还影响整个分布式协议运行的稳定性,严重情况下一个大事务就会导致整个集群较长时间的不可用。
MGR
- MGR对大事务的支持没有任何优化, 只是增加了参数group_replication_transaction_size_limit控制大事务上限,默认143M,最大2GB
- 当事务日志超过大事务限制后,会直接报错,事务无法提交
DN
- 针对大事务带来的分布式系统的不稳定问题, DN采取大事务拆分+大对象拆分的方案进行根治, DN会将大事务的事务日志进行逻辑拆分+物理拆分的方式拆分为一个个小块的的事务日志,每个小块的事务日志使用完整的Paxos提交保证
- 基于大事务拆分的方案,DN对大事务的大小不做任何限制,用户可以随意使用, 同样能保证RPO=0
- 详细说明见《PolarDB-X 存储引擎核心技术 | 大事务优化》
- 因此在大事务问题的处理上,DN能做到不受大事务影响
2.6. 部署形态
MGR
- MGR支持单主、多主的部署模式,多主模式下每个节点可读可写,单主模式时主库可读可写,备库只能只读
- MGR高可用部署至少三节点部署,也即至少三份数据和日志, 不支持日志副本Logger形态
- MGR不支持只读节点的扩展,但是支持MGR+主从复制模式的组合,实现类似拓扑扩展
DN
- DN支持单主模式部署,单主模式时单主模式时主库可读可写,备库只能只读
- DN高可用部署至少三节点部署,但支持日志副本Logger形态,也即Leader、Follower都是全功能副本,Logger相比缺少只有日志没有数据,并且没有被选举权。 这样的话三节点高可用部署只需要2份数据+3份日志的存储开销,低成本部署
- DN支持只读节点部署,支持只读副本Learner形态,相比全功能副本仅是不具备投票权,通过Learner副本实现下游对主库的订阅消费

2.7. 特性小结
MGR
DN
协议效率
事务提交耗时
1.5~2.5 RTT
1个 RTT
多数派持久化方式
XCOM内存保存
Binlog持久化
可靠性
RPO=0
默认不保证
完全保证
故障检测
所有节点相互检查,网络负载高
心跳周期无法调整
主节点周期检查其他节点
心跳周期参数可调
多数派崩溃恢复
人工介入
自动恢复
少数派崩溃恢复
大部分自动恢复,特殊情况人工介入
自动恢复
选主
自由指定选主顺序
自由指定选主顺序
日志追平
落后日志不能超过XCOM 1GB缓存
BInlog文件不删除
备库回放延迟
两阶段+双一,很慢
一阶段+双零,较快
大事务
默认限制不超过143MB
无大小限制
形态
高可用成本
全功能三副本,3份数据存储开销
Logger日志副本,2份数据存储
只读节点
借助主从复制实现
协议自带Leaner只读副本实现
3. 测试对比
MGR是MySQL 5.7.17开始引入的,但更多MGR相关特性都只在MySQL 8.0上才有,并且在MySQL 8.0.22及之后的版本,整体会更稳定可靠。因此我们选择双方的最新版8.0.32版本进行对比测试。
考虑到PolarDB-X DN和MySQL MGR在对比测试时,存在测试环境差异、编译方式差异、部署方式差异、运行参数差异、测试手段差异,进而可能导致测试对比数据不准确,本文在各项细节上采用如下方式进行:
测试准备
PolarDB-X DN
MySQL MGR[1]
硬件环境
使用同一台96C 754GB内存的物理机,SSD磁盘
操作系统
Linux 4.9.168-019.ali3000.alios7.x86_64
内核版本
使用基于社区8.0.32版本的内核基线
编译方式
使用相同的RelWithDebInfo编译
运行参数
使用相同的PolarDB-X官网售卖32C128G规格相同参数
部署方式
单主模式
注:
- MGR默认开启了流控,而PolarDB-X DN默认关闭流控。因此对MGR的group_replication_flow_control_mode单独配置关闭,这样MGR的性能会是最好的
- 点查时MGR有明显so读取瓶颈,因此对MGR的replication_optimize_for_static_plugin_config单独配置开启,这样MGR的只读性能会是最好的
3.1. 性能
性能测试是大家在选型数据库时首先关注的一点。这里我们使用官方sysbench工具,构建16张表,每张表1千万数据,进行OLTP场景的性能测试,测试对比不同OLTP场景下不同并发时两者的表现。考虑到实际部署的不同情况, 我们分别模拟下面4种部署场景
- 同机房,一个机房内部署三节点,机器之间互相ping带0.1ms的网络延迟
- 同城三中心,同地域三个机房部署三节点,机房之间互相ping带1ms的网络延迟(比如:上海地域的三个机房)
- 两地三中心,两地三个机房部署三节点,同城机房之间ping带1ms的网络,同城和异地之间带30ms的网络延迟(比如:上海/上海/深圳)
- 三地三中心,三地三个机房部署三节点(比如:上海/杭州/深圳),杭州-上海之间ping带5ms左右的网络延迟,杭州/上海 到深圳距离最远的为30ms的网络延迟
说明:
a. 考虑4个部署场景性能的横向对比,两地三中心、三地三中心都采用3副本的部署模式,真实生产业务可以扩展到5副本的部署形态。
b. 考虑到实际使用高可用数据库产品时对RPO=0的严格限制,但是MGR默认配置RPO<>0,这里在各部署场景下,我们继续增加MGR RPO<>0和RPO=0的对比测试。
- MGR_0 表示 MGR RPO = 0 情况的数据
- MGR_1 表示 MGR RPO <> 0 情况的数据
- DN 表示 DN RPO = 0 情况的数据
3.1.1. 同机房
1
4
16
64
256
oltp_read_only
MGR_1
688.42
2731.68
6920.54
11492.88
14561.71
MGR_0
699.27
2778.06
7989.45
11590.28
15038.34
DN
656.69
2612.58
7657.03
11328.72
14771.12
MGR_0 vs MGR_1
1.58%
1.70%
15.45%
0.85%
3.27%
DN vs MGR_1
-4.61%
-4.36%
10.64%
-1.43%
1.44%
DN vs MGR_0
-6.09%
-5.96%
-4.16%
-2.26%
-1.78%
oltp_read_write
MGR_1
317.85
1322.89
3464.07
5052.58
6736.55
MGR_0
117.91
425.25
721.45
217.11
228.24
DN
360.27
1485.99
3741.36
5460.47
7536.16
MGR_0 vs MGR_1
-62.90%
-67.85%
-79.17%
-95.70%
-96.61%
DN vs MGR_1
13.35%
12.33%
8.00%
8.07%
11.87%
DN vs MGR_0
205.55%
249.44%
418.59%
2415.07%
3201.86%
oltp_write_only
MGR_1
761.87
2924.1
7211.97
10374.15
16092.02
MGR_0
309.83
465.44
748.68
245.75
318.48
DN
1121.07
3787.64
7627.26
11684.37
15137.23
MGR_0 vs MGR_1
-59.33%
-84.08%
-89.62%
-97.63%
-98.02%
DN vs MGR_1
47.15%
29.53%
5.76%
12.63%
-5.93%
DN vs MGR_0
261.83%
713.78%
918.76%
4654.58%
4652.96%


从测试结果可以看出:
- 在只读场景,无论是对比MGR_1(RPO<>0)还是MGR_0(RPO=0),DN与MGR之间的差异稳定在-5%~10%之间,可以认为基本相同。RPO是否等于0对只读事务不影响
- 在读写混合、只写事务场景,在DN(RPO=0)相比MGR_1时(RPO<>0)性能提升了5%~47%,并且呈现低并发时DN性能优势明显,高并发时优势不明显的特点。 这是由于低并发时DN的协议效率更高,但高并发下DN和MGR的性能热点都在刷脏上所致
- 而在相同的RPO=0的前提下,在读写混合、只写事务场景,在DN相比MGR_0性能提升了2倍-46倍,并且随着并发提高,DN性能优势加强的特点。也难怪MGR默认也要为了性能而舍弃RPO=0
3.1.2. 同城三中心
TPS对比
1
4
16
64
256
oltp_read_only
MGR_1
695.69
2697.91
7223.43
11699.29
14542.4
MGR_0
691.17
2708.6
7849.98
11636.94
14670.99
DN
645.11
2611.15
7628.39
11294.36
14647.22
MGR_0 vs MGR_1
-0.65%
0.40%
8.67%
-0.53%
0.88%
DN vs MGR_1
-7.27%
-3.22%
5.61%
-3.46%
0.72%
DN vs MGR_0
-6.66%
-3.60%
-2.82%
-2.94%
-0.16%
oltp_read_write
MGR_1
171.37
677.77
2230
3872.87
6096.62
MGR_0
117.11
469.17
765.64
813.85
812.46
DN
257.35
1126.07
3296.49
5135.18
7010.37
MGR_0 vs MGR_1
-31.66%
-30.78%
-65.67%
-78.99%
-86.67%
DN vs MGR_1
50.17%
66.14%
47.82%
32.59%
14.99%
DN vs MGR_0
119.75%
140.01%
330.55%
530.97%
762.86%
oltp_write_only
MGR_1
248.37
951.88
2791.07
5989.57
11666.16
MGR_0
162.92
603.72
791.27
828.16
866.65
DN
553.69
2173.18
5836.64
10588.9
13241.74
MGR_0 vs MGR_1
-34.40%
-36.58%
-71.65%
-86.17%
-92.57%
DN vs MGR_1
122.93%
128.30%
109.12%
76.79%
13.51%
DN vs MGR_0
239.85%
259.96%
637.63%
1178.61%
1427.92%


从测试结果可以看出:
- 在只读场景,无论是对比MGR_1(RPO<>0)还是MGR_0(RPO=0),DN与MGR之间的差异稳定在-7%~5%之间,可以认为基本相同。RPO是否等于0对只读事务不影响
- 在读写混合、只写事务场景,在DN(RPO=0)相比MGR_1时(RPO<>0)性能提升了30%~120%,并且呈现低并发时DN性能优势明显,高并发时优势不明显的特点。 这是由于低并发时DN的协议效率更高,但高并发下DN和MGR的性能热点都在刷脏上所致
- 而在相同的RPO=0的前提下,在读写混合、只写事务场景,在DN相比MGR_0性能提升了1倍-14倍,并且随着并发提高,DN性能优势加强的特点。也难怪MGR默认也要为了性能而舍弃RPO=0
3.1.3. 两地三中心
TPS对比
1
4
16
64
256
oltp_read_only
MGR_1
687.76
2703.5
7030.37
11580.36
14674.7
MGR_0
687.17
2744.41
7908.44
11535.35
14656
DN
657.06
2610.58
7591.21
11174.94
14545.45
MGR_0 vs MGR_1
-0.09%
1.51%
12.49%
-0.39%
-0.13%
DN vs MGR_1
-4.46%
-3.44%
7.98%
-3.50%
-0.88%
DN vs MGR_0
-4.38%
-4.88%
-4.01%
-3.12%
-0.75%
oltp_read_write
MGR_1
29.13
118.64
572.25
997.92
2253.19
MGR_0
26.94
90.8
313.64
419.17
426.7
DN
254.87
1146.57
3339.83
5307.85
7171.95
MGR_0 vs MGR_1
-7.52%
-23.47%
-45.19%
-58.00%
-81.06%
DN vs MGR_1
774.94%
866.43%
483.63%
431.89%
218.30%
DN vs MGR_0
846.07%
1162.74%
964.86%
1166.28%
1580.79%
oltp_write_only
MGR_1
30.81
145.54
576.61
1387.64
3705.51
MGR_0
28.68
108.86
387.48
470.5
476.4
DN
550.11
2171.64
5866.41
10381.72
14478.38
MGR_0 vs MGR_1
-6.91%
-25.20%
-32.80%
-66.09%
-87.14%
DN vs MGR_1
1685.49%
1392.13%
917.40%
648.16%
290.73%
DN vs MGR_0
1818.10%
1894.89%
1413.99%
2106.53%
2939.12%


从测试结果可以看出:
- 在只读场景,无论是对比MGR_1(RPO<>0)还是MGR_0(RPO=0),DN与MGR之间的差异稳定在-4%~7%之间,可以认为基本相同。RPO是否等于0对只读事务不影响
- 在读写混合、只写事务场景,在DN(RPO=0)相比MGR_1时(RPO<>0)性能提升了2倍~16倍,并且呈现低并发时DN性能优势明显,高并发时优势不明显的特点。 这是由于低并发时DN的协议效率更高,但高并发下DN和MGR的性能热点都在刷脏上所致
- 而在相同的RPO=0的前提下,在读写混合、只写事务场景,在DN相比MGR_0性能提升了8倍-29倍,并且随着并发提高,DN性能优势加强的特点。也难怪MGR默认也要为了性能而舍弃RPO=0
3.1.4. 三地三中心
TPS对比
1
4
16
64
256
oltp_read_only
MGR_1
688.49
2747.69
7853.91
11722.71
15292.73
MGR_0
687.66
2756.3
8005.11
11567.89
15055.69
DN
656.06
2600.35
7657.85
11227.56
14562.86
MGR_0 vs MGR_1
-0.12%
0.31%
1.93%
-1.32%
-1.55%
DN vs MGR_1
-4.71%
-5.36%
-2.50%
-4.22%
-4.77%
DN vs MGR_0
-4.60%
-5.66%
-4.34%
-2.94%
-3.27%
oltp_read_write
MGR_1
26.01
113.98
334.95
693.34
2030.6
MGR_0
23.93
110.17
475.68
497.92
511.99
DN
122.06
525.88
1885.7
3314.9
5889.79
MGR_0 vs MGR_1
-8.00%
-3.34%
42.02%
-28.19%
-74.79%
DN vs MGR_1
369.28%
361.38%
462.98%
378.11%
190.05%
DN vs MGR_0
410.07%
377.34%
296.42%
565.75%
1050.37%
oltp_write_only
MGR_1
27.5
141.64
344.05
982.47
2889.85
MGR_0
25.52
155.43
393.35
470.92
504.68
DN
171.74
535.83
1774.58
4328.44
9429.24
MGR_0 vs MGR_1
-7.20%
9.74%
14.33%
-52.07%
-82.54%
DN vs MGR_1
524.51%
278.30%
415.79%
340.57%
226.29%
DN vs MGR_0
572.96%
244.74%
351.15%
819.15%
1768.36%
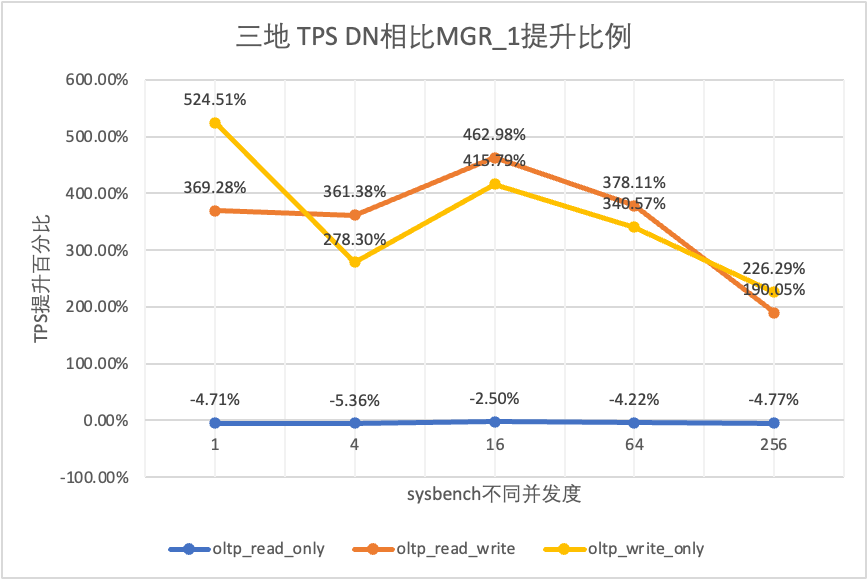

从测试结果可以看出:
- 在只读场景,无论是对比MGR_1(RPO<>0)还是MGR_0(RPO=0),DN与MGR之间的差异稳定在-5%~0%之间,可以认为基本相同。RPO是否等于0对只读事务不影响
- 在读写混合、只写事务场景,在DN(RPO=0)相比MGR_1时(RPO<>0)性能提升了2倍~5倍,并且呈现低并发时DN性能优势明显,高并发时优势不明显的特点。 这是由于低并发时DN的协议效率更高,但高并发下DN和MGR的性能热点都在刷脏上所致
- 而在相同的RPO=0的前提下,在读写混合、只写事务场景,在DN相比MGR_0性能提升了2倍-17倍,并且随着并发提高,DN性能优势加强的特点。也难怪MGR默认也要为了性能而舍弃RPO=0
3.1.5. 部署对比
为了明显对比不同部署方式下性能的变化差异,我们选择上述测试中oltp_write_only场景256并发下不同部署方式下的MGR和DN的TPS数据,以机房测试数据为基线,计算对比不同部署方式时TPS数据相比基线的比例,以此感知跨城部署时性能变化差异
MGR_1 (256并发)
DN (256并发)
DN相比于MGR的性能优势
同机房
16092.02
15137.23
-5.93%
同城三中心
11666.16 (72.50%)
13241.74 (87.48%)
+13.50%
两地三中心
3705.51 (23.03%)
14478.38 (95.64%)
+290.72%
三地三中心
2889.85 (17.96%)
9429.24 (62.29%)
+226.28%

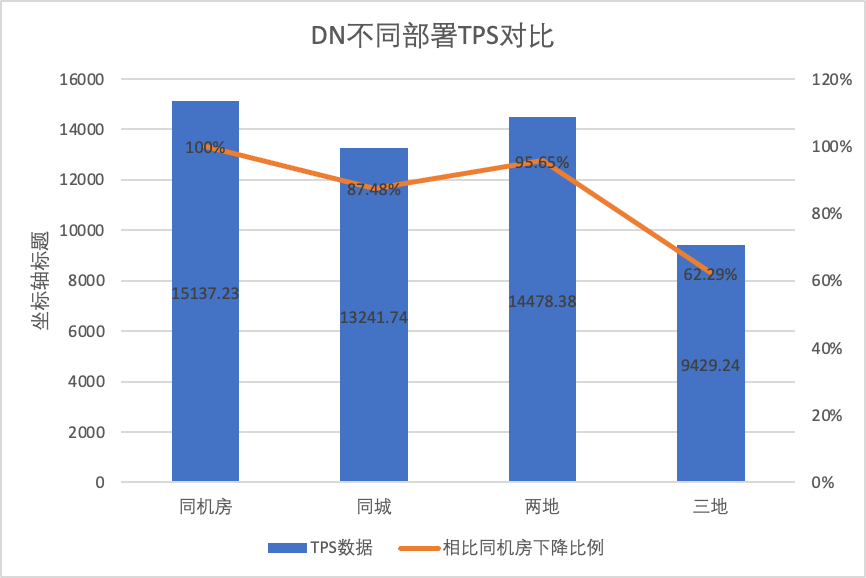
从测试结果可以看出:
- 随着部署方式的扩大化,MGR_1(RPO<>0)的TPS下降明显,相比同机房部署,同城跨机房部署性能下降27.5%, 跨城(两地三中心、三地三中心)部署性能下降77%~82%,这是由于跨城部署RT增加导致
- 而DN(RTO=0)则相对稳定,相比同机房部署,同城跨机房、两地三中心部署性能下降4%~12%, 三地三中心在高网络延迟下部署时性能下降37%,这也是由于跨城部署RT增加导致。不过得益于DN的Batch&Pipeline机制,跨城带来的影响可以通过提高并发的来解决,比如三地三中心架构下在>=512并发下基本可以对齐同城、两地三中心下的性能吞吐
- 由此可见跨城部署对MGR_1(RPO<>0)的影响很大
3.1.6. 性能抖动
实际使用中,我们不仅关注性能数据如何,还需要关注性能抖动情况。毕竟如果抖动像过山车一样,对实际用户的体验也非常差。我们对TPS实时输出数据监控展示,考虑到sysbenc工具本身不支持输出性能抖动的监测数据,于是采用数学上的变异系数作为对比指标:
- 变异系数(Coefficient of Variation, CV): 变异系数是标准差除以平均值,通常用来比较不同数据集的波动情况,尤其是当平均值差异较大时。CV 越大,数据相对于平均值的波动越大
以256并发下oltp_read_write场景为例,我们统计分析MGR_1(RPO<>0)、DN(RPO=0)在同机房、同城三中心、两地三中心、三地三中心五种部署模式下的TPS抖动情况。 实际抖动图如下,实际各场景抖动指标数据如下
CV
同机房
同城三中心
两地三中心
三地三中心
MGR_1
10.04%
8.96%
6.02%
8.63%
DN
3.68%
3.78%
2.55%
4.05%
MGR_1/DN
272.83%
237.04%
236.08%
213.09%

从测试结果可以看出:
- MGR在oltp_read_write场景下TPS呈现不稳定的状态,中间竟然无缘无故猛跌现象,在多个部署场景多次试验中均发现这个现象。 相比下DN就十分稳定
- 计算变异系数CV, MGR的CV很大6%~10%,同机房延迟最小的情况时竟然还达到最大值10%,而DN的CV为比较稳定2%~4%, DN比MGR的性能稳定性基本高到2倍
- 由此可见MGR_1(RPO<>0)的性能抖动比较大
3.2. RTO
分布式数据库的核心特点就是高可用,集群中任何一个节点的故障都不影响整体的可用性。针对同机房场景部署一主两备的3节点典型部署形态,我们尝试对对一下三种场景进行可用性的测试:
- 中断主库,然后重启,观察过程中集群恢复可用性的RTO时间
- 中断任意一个备库,然后重启,观察过程中主库的可用性表现
3.2.1. 主库宕机+重启
无负载情况下, kill leader, 监控集群各节点状态变化以及是否可写,
MGR
DN
起始正常
0
0
kill leader
0
0
发现异常节点时间
5
5
3节点降为2节点时间
23
8
MGR
DN
起始正常
0
0
kill leader,自动拉起
0
0
发现异常节点时间
5
5
3节点降为2节点时间
23
8
2节点恢复3节点时间
37
15

从测试结果可以看出,在无压力的情况下:
- DN的RTO在8-15s, 降为2节点需要8s,恢复3节点需要15s;
- MGR的RTO在23-37s, 降为2节点需要23s,恢复3节点需要37s
- RTO表现DN整体优于MGR
3.2.2. 备库宕机+重启
使用sysbench进行oltp_read_write场景下16个线程的并发压测,在图中第10s的时刻,手动kill一个备节点,观察sysbench的的实时输出TPS数据。



从测试结果图中可见:
- 中断备库后,MGR的主库TPS大幅下降,持续20s左右才恢复正常水平。根据日志分析,这里经历了检测故障节点变成unreachable状态、将故障节点踢出MGR集群两个过程。这个测试证实了MGR社区流传很久的一个缺陷,在3节点中即使只有1个节点不可用,整个集群就有一段时间的剧烈抖动不可用
- 针对单主时MGR存在单节点故障整个实例不可用的问题,社区从8.0.27中引入了MGR paxos single leader功能解决,但默认关闭。 这里我们将group_replication_paxos_single_leader开启后继续验证,这次中断备库后主库性能保持稳定,并且稍微还有所提升了,原因应该与网络负载降低有关
- 对于DN,中断备库后,主库TPS反而立刻上升约20%, 随后一直保持稳定,集群也一直处于可用状态。这里和MGR相反的表现,原因是中断一个备库后主库每次只用向剩下一个备库发送日志,网络收发包流程效率更高了
继续测试,我们将备库重启恢复,观察主库TPS数据变化



从测试结果图中可见:
- MGR在5s时刻从2节点恢复成3节点,但同样存在着主库不可用, 持续时间大约12s。尽管备库节点最终加入集群,但MEMBER_STATE状态一直为RECOVERING,说明此时正在追数据
- 对group_replication_paxos_single_leader开启后的场景同样进行备库重启的验证,结果MGR在10s时刻从2节点恢复成3节点,但仍然出现了持续时间大约7s的不可用时间,看来这个参数并不能完全解决单主时MGR存在单节点故障整个实例不可用的问题。
- 对于DN,备库在10s时刻从2节点恢复成3节点,主库一直保持可用状态。 这里TPS会有短暂的波动,这个是由于重启后备库日志复制延迟落后较多,需要从主库拉取落后的日志,因此对主库产生少量影响,待日志追评后,整体性能就处于稳定状态。
3.3. RPO
为了构造MGR多数派故障RPO<>0场景,我们使用社区自带的MTR Case方式,对MGR进行故障注入测试,设计的Case如下:
- --echo
- --echo ############################################################
- --echo # 1. Deploy a 3 members group in single primary mode.
- --source include/have_debug.inc
- --source include/have_group_replication_plugin.inc
- --let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
- --let $rpl_group_replication_single_primary_mode=1
- --let $rpl_skip_group_replication_start= 1
- --let $rpl_server_count= 3
- --source include/group_replication.inc
- --let $rpl_connection_name= server1
- --source include/rpl_connection.inc
- --let $server1_uuid= `SELECT @@server_uuid`
- --source include/start_and_bootstrap_group_replication.inc
- --let $rpl_connection_name= server2
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
- --echo
- --echo ############################################################
- --echo # 2. Init data
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
- --source include/rpl_sync.inc
- SELECT * FROM t1;
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- --echo
- --echo ############################################################
- --echo # 3. Mock crash majority members
- --echo # server 2 wait before write relay log
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- --echo # server 3 wait before write relay log
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- --echo # server 1 commit new transaction
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- INSERT INTO t1 VALUES(2);
- # server 1 commit t1(c1=2) record
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 1 crash
- --source include/kill_mysqld.inc
- --echo # sleep enough time for electing new leader
- sleep 60;
- --echo
- --echo # server 3 check
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 crash and restart
- --source include/kill_and_restart_mysqld.inc
- --echo # sleep enough time for electing new leader
- sleep 60;
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 crash and restart
- --source include/kill_and_restart_mysqld.inc
- --echo # sleep enough time for electing new leader
- sleep 60;
- --echo
- --echo ############################################################
- --echo # 4. Check alive members, lost t1(c1=2) record
- --echo # server 3 check
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- !include ../my.cnf
- [mysqld.1]
- loose-group_replication_member_weight=100
- [mysqld.2]
- loose-group_replication_member_weight=90
- [mysqld.3]
- loose-group_replication_member_weight=80
- [ENV]
- SERVER_MYPORT_3= @mysqld.3.port
- SERVER_MYSOCK_3= @mysqld.3.socket
Case运行结果如下:
- ############################################################
- # 1. Deploy a 3 members group in single primary mode.
- include/group_replication.inc [rpl_server_count=3]
- Warnings:
- Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
- Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
- [connection server1]
- [connection server1]
- include/start_and_bootstrap_group_replication.inc
- [connection server2]
- include/start_group_replication.inc
- [connection server3]
- include/start_group_replication.inc
- ############################################################
- # 2. Init data
- [connection server1]
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
- include/rpl_sync.inc
- SELECT * FROM t1;
- c1
- 1
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
- ############################################################
- # 3. Mock crash majority members
- # server 2 wait before write relay log
- [connection server2]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 3 wait before write relay log
- [connection server3]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 1 commit new transaction
- [connection server1]
- INSERT INTO t1 VALUES(2);
- SELECT * FROM t1;
- c1
- 1
- 2
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 1 crash
- # Kill the server
- # sleep enough time for electing new leader
- # server 3 check
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 3 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
- # server 2 check
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
- # server 2 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
- ############################################################
- # 4. Check alive members, lost t1(c1=2) record
- # server 3 check
- [connection server3]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
- # server 2 check
- [connection server2]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
复现丢数的Case大概逻辑是这样的:
- MGR由3个节点组成单主模式,Server 1/2/3,其中Server 1为主库,并初始化1条记录c1=1
- 故障注入Server 2/3在写Relay Log时会hang住
- 连接到Server 1节点,写入了c1=2的记录,事务commit也返回了成功
- 然后Mock server1的异常crash(机器故障,不能恢复,无法访问),此时剩下Server 2/3形成多数派
- 正常重启Server 2/3(快速恢复),但是Server 2/3无法恢复集群可用状态
- 连接Server 2/3节点,查询数据库记录,仅看到了c1=1的记录(Server 2/3都丢失了c1=2)
根据以上Case可见,对于MGR,当多数派宕机,主库不可用,备库恢复后,存在数据丢失的RPO<>0的情况,原本已返回客户端commit成功的记录丢了。
而对于DN,多数派的达成需要日志在多数派中都持久化,所以即使在上述场景下,数据也不会丢失,也能保证RPO=0。
3.4. 备库回放延迟
MySQL的传统主备模式下,备库一般会包含IO线程和Apply线程,引入了Paxos协议后替换了IO线程同步主备库binlog的工作,备库的复制延迟主要就看备库Apply回放的开销,我们这里成为备库回放延迟。
我们使用sysbench测试oltp_write_only场景,测试100并发下, 不同event数量时, 备库回放出现延迟的持续时间。备库回放延迟时间通过监控performance_schema.replication_applier_status_by_worker表的APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP列来实时查看各worker是否工作来断定复制是否结束

从测试结果图中可见:
- 相同写入数据量下,DN的备库回放所有日志的完成时间远远优于MGR,DN的的耗时仅是MGR的3%~4%。 这对主备切换的及时性十分关键。
- 随着写入数量的增加,DN相比MGR的备库回放延迟优势继续保持,十分稳定。
- 分析备库回放延迟原因,MGR的备库回放策略采用group_replication_consistency默认值为EVENTUAL,即RO和RW事务在执行之前都不等待应用前面的事务。这样可以保证主库写入性能的最大化,但是备库延迟就会比较大(通过牺牲备库延迟和RPO=0来换取主库的高性能写入,开启MGR的限流功能可以平衡性能和备库延迟,但主库的性能就会打折扣)
3.5. 测试小结
MGR
DN
性能
读事务
持平
持平
写事务
RPO<>0时性能不如DN
RPO=0时性能远不如DN
跨城部署性能下跌严重27%~82%
写事务性能远高于MGR
跨城部署性能下降较小4%~37%
抖动
性能抖动厉害,抖动范围6~10%
比较平稳3%,只有MGR一半
RTO
主库宕机
5s发现异常,23s降为两节点
5s发现异常,8s降为两节点
主库重启
5s发现异常,37s恢复三节点
5s发现异常,15s恢复三节点
备库宕机
主库持续20s出现流量跌0
需要显式开启group_replication_paxos_single_leader后可缓解
主库持续高可用
备库重启
主库持续10s出现流量跌0
显式开启group_replication_paxos_single_leader也无效
主库持续高可用
RPO
Case复现
多数派宕机时RPO<>0
性能和RPO=0两者不能兼得
RPO = 0
备库延迟
备库回放耗时
主备延迟很大,
性能和主备延迟两者不能兼得
整体备库回放的总耗时是MGR的4%, 是MGR的25倍
参数
关键参数
- group_replication_flow_control_mode流控默认开启,需要配置关闭提高性能
- replication_optimize_for_static_plugin_config静态插件优化默认关闭,需要开启提高性能
- group_replication_paxos_single_leader默认关闭,需要开启提升备库宕机主库稳定性
- group_replication_consistency默认关闭不保证RPO=0,强要求RPO=0时需要配置AFTER
- group_replication_transaction_size_limit默认143M,遇到大事务时需要调大
- binlog_transaction_dependency_tracking默认COMMIT_ORDER,MGR时需要调整为WRITESET来提高备库回放性能
默认配置,不需要专业人员定制化配置
4. 总结
经过深入的技术剖析与性能对比,PolarDB-X DN凭借其自研的X-Paxos协议和一系列优化设计,在性能、正确性、可用性及资源开销等方面展现出对MySQL MGR的多项优势,但MGR在MySQL生态体系内也占据重要地位,但需要考虑备库宕机抖动、跨机房容灾性能波动、稳定性等各种情况,因此如果想用好MGR,必须配备专业的技术和运维团队的支持。
在面对大规模、高并发、高可用性需求时,PolarDB-X存储引擎以其独特的技术优势和优异的性能表现,相比于MGR在开箱即用的场景下,PolarDB-X基于DN的集中式(标准版)在功能和性能都做到了很好的平衡,成为了极具竞争力的数据库解决方案。
-
相关阅读:
C++ Reference: Standard C++ Library reference: C Library: cstdio: FILE
【系统设计系列】 回顾可扩展性
排序:冒泡排序算法分析
C# Math.Round()四舍五入、四舍六入五成双
Filter过滤器
Linux中的/proc文件系统详解(C/C++代码实现)
常见的加密算法和类型
元数据治理利器 - Apache Atlas
【matplotlib】绘制散点图,为不同区域的点添加不同颜色+添加纵向\横向分割线(含Python代码实例)
【数据结构】复习汇总I
- 原文地址:https://blog.csdn.net/openApsaraDB/article/details/140269702