-
Mustango——音乐领域知识生成模型探索
Mustango:利用领域知识的音乐生成模型
论文地址:https://arxiv.org/pdf/2311.08355.pdf
源码地址:https://github.com/amaai-lab/mustango论文题为**“**利用音乐领域知识开发文本到音乐模型’Mustango’”。它利用音乐领域的知识从文本指令中生成音乐。本研究的实验表明,Mustang 在利用文本引导生成音乐方面的表现明显优于其他模型。而且,Mustango 是一种基于音乐理论的创新生成模式,具有扩大创意活动范围的潜力。

Mustango 模型结构
传播模型的最新发展大大提高了文本到音乐生成模型的性能。然而,现有模型完全没有考虑对生成音乐的节奏、和弦进行和调性等音乐方面的精细控制。
在这项研究中,Mustango 被提出作为一种能够生成具有音乐性的音乐的模型。具体来说,该模型设想的文字提示不仅包含一般的文字说明,还包含音乐元素,如
- 和弦进行
- 拍击
- 速度
- 密钥
Mustango 的模型结构如下。
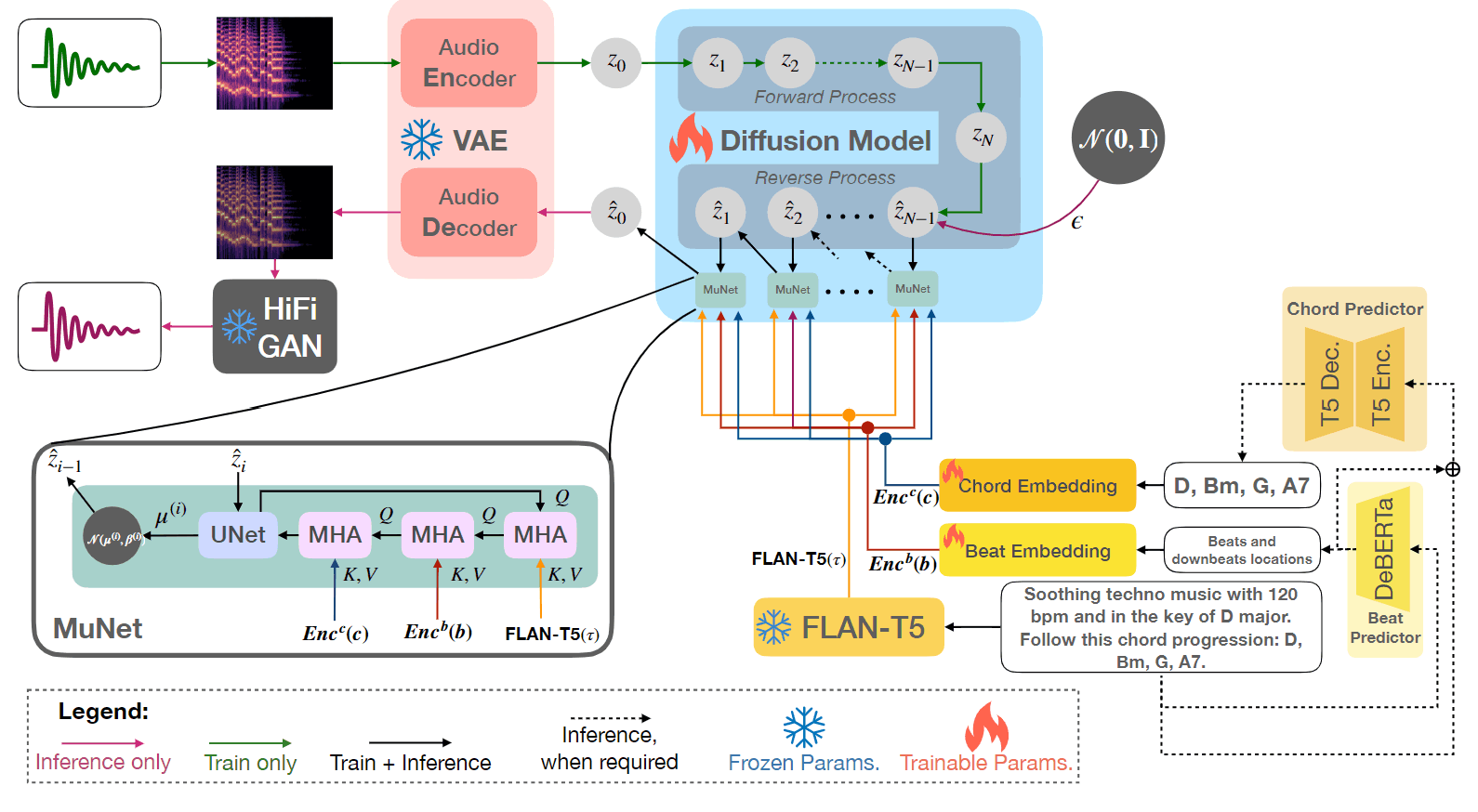
其基本结构以潜在扩散模型为基础,该模型将语音波形→mel-spectrogram→潜在表示(经 VAE 压缩)进行转换,并将扩散模型应用于潜在表示。本研究还采用了用于音乐生成的 UNet 专用版本MuNet 作为扩散模型。
具体来说,在使用 MuNet 去噪之后,通过将潜表征→mel-spectrogram(由 VAE 重构)→语音波形(由 HiFi GAN 重构)转换生成音乐。
MuNet 调节
如前所述,MuNet 是 UNet 针对音乐的扩散模型。在本研究中,它扮演着去噪的角色:对 MuNet 的调节按以下步骤进行。
- 文本编码器(FLAN-T5)从输入文本中获取嵌入信息
- 使用节拍和和弦编码器提取节拍和和弦特征
- 依次整合文本嵌入、节拍功能和代码功能的跨附件功能。
节拍编码器(DeBERTa Large)对文本提示中的节拍计数和节拍间隔进行编码。
和弦编码器(FLAN-T5 Large)还能根据文本提示和节拍信息对和弦进行编码。
建立大型数据集 “MusicBench”
在根据文本指令生成音乐领域,缺乏 "文本-音乐 "配对数据集也是一个问题。例如,近年来经常被用作音乐生成领域基准的数据集 "MusicCaps "仅包含约 5000 个条目。
这些数据的缺乏是进一步提高音乐生成模型性能的绊脚石。
为了弥补这些数据的不足,本研究以上述 MusicCaps 为基础,采用独特的数据扩展方法建立了一个大型数据集 MusicBench。

具体来说,MusicBench 是通过以下步骤从 5,479 个 MusicCaps 样本中建立起来的。
- 将 MusicCaps 分成 TrainA 和 TestA。
- 从 TrainA 和 TestA 音乐数据中提取节拍、和弦、调性和速度信息。
- 在步骤 2 中,在 TrainA 和 TestA 的标题中添加一句话来描述音乐特征,从而创建 TrainB 和 TestB。
- 在 ChatGPT 中转述 TrainB 的标题,创建 TrainC。
- 通过剔除低音质样本,从 TrainA 中提取了 3 413 个样本
- 在步骤 5 中,对音乐数据进行数据扩展,以改变音高、节奏和音量,生成 37,000 个样本。
- 在步骤 6 的样本中随机添加 0-4 个标题句子
- 使用 ChatGPT 对步骤 7 中的标题进行转述。
- 训练 A、训练 B、训练 C,结合步骤 5~8 扩展的数据
通过上述步骤,构建了一个大型数据集 MusicBench,其中包含 52 768 个最终训练数据样本(比 MusicCaps 大 11 倍)。
顺便提一下,在使用 ChatGPT 进行转述时,使用了以下提示。

音乐特征提取模型
在上述步骤 2 中,我们从音乐数据中提取了四种音乐特征–节拍、顺拍、和弦、调性和速度,并将其添加到现有的文本提示中。
在此过程中,一个名为 BeatNet 的模型被用于提取节拍和下拍的特征。
至于节奏(BPM),他们通过平均节拍之间时间间隔的倒数来估算。
与和弦进行相关的特征是通过一个名为 Chordino的模型提取的,而音调则是通过 Essentia 的 KeyExtractor 算法提取的。
音乐数据和文本数据的扩展方法
在上述步骤 6 中,对音乐数据进行数据扩展,以改变音高、节奏和音量。在此过程中,上述三个音乐特征会发生如下变化。
- 使用 PyRubberband 在 ±3 个半音的范围内移动音乐的音高
- 节奏变化范围为 ±5-25%。
- 音量渐变(包括渐强和渐弱)。
此时,扩充音乐数据附带的文本提示也会被采集,以与扩充音乐数据相匹配。
这种方法的效果
为了检验Mustango 生成的音乐的质量和数据集 MusicBench 的有效性,对客观和主观指标进行了评估。
客观指标评估
客观指标评价采用弗雷谢特距离(FD)、弗雷谢特音频距离(FAD)和 KL 发散来评估生成音乐的质量。
评估使用了 TestA、TestB 和 FMACaps 测试数据。
结果如下

使用 MusicCaps 训练的 Tango 模型不如其他模型,这说明了 MusicBench 的有效性。还可以看出,使用 MusicBench 微调的预训练 Tango 和 Mustango 模型在 FD 和 KL 上的表现不相上下,但 Mustango 在 FAD 上的表现明显更好。
此外,在所有测试集上,Mustango 的 FAD 和 KL 均优于 MusicGen 和 AudioLDM2。
除此评估外,还定义了节奏、调性、和弦和节拍等九个音乐特征指标,并评估生成的音乐是否按照文本的指示表达了这些音乐特征。
评估使用了 TestB 和 FMACaps 测试数据。
结果如下
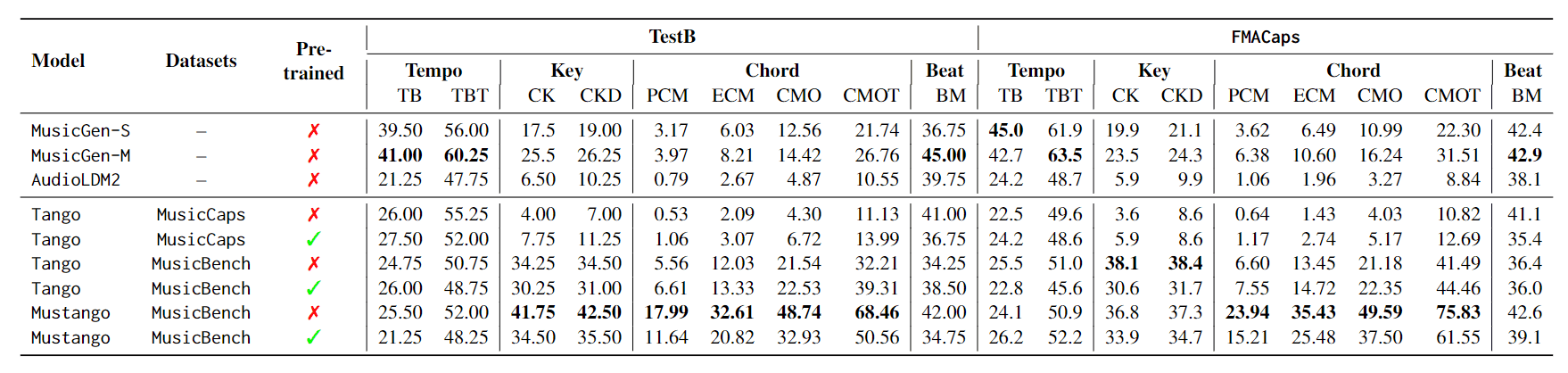
测试 B 显示,除 MusicGen 外,所有模型在节奏方面的表现都相当,而在节拍方面,不同模型之间的表现也相似。在关键字方面,在 MusicBench 中训练的模型明显优于在 MusicCaps 中训练的模型。其中,Mustango 在 TestB 中的表现优于所有其他模型,在 FMACaps 中排名第二。在和弦方面,Mustango 明显优于所有其他型号。
结果表明,Mustango 是控制和弦进行的最有效模型。
主观指标评估
主观评价包括对普通听众和专家(至少有五年音乐教育经验)进行问卷调查。
第一轮比较 Mustango 与 Tango,第二轮比较 Mustango 与 MusicGen 和 AudioLDM2。
结果如下
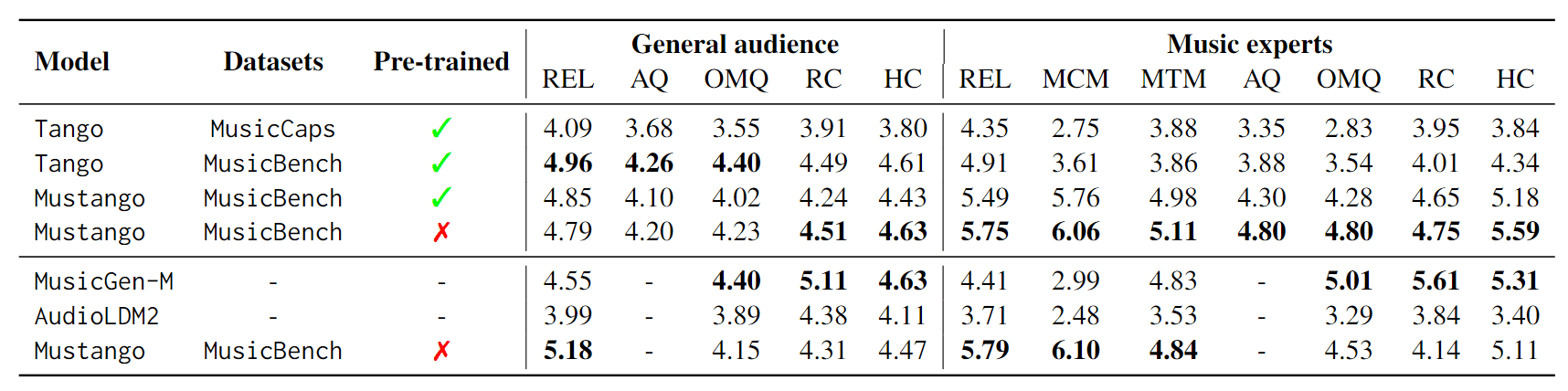
在第一轮中,用 MusicCaps 训练的 Tango 在所有指标上都不如用 MusicBench 训练的模型,这说明了 MusicBench 的有效性。还可以看出,Mustango 在许多指标上都表现最佳。
环境部署
git clone https://github.com/AMAAI-Lab/mustango cd mustango pip install -r requirements.txt cd diffusers pip install -e .import IPython import soundfile as sf from mustango import Mustango model = Mustango("declare-lab/mustango") prompt = "This is a new age piece. There is a flute playing the main melody with a lot of staccato notes. The rhythmic background consists of a medium tempo electronic drum beat with percussive elements all over the spectrum. There is a playful atmosphere to the piece. This piece can be used in the soundtrack of a children's TV show or an advertisement jingle." music = model.generate(prompt) sf.write(f"{prompt}.wav", audio, samplerate=16000) IPython.display.Audio(data=music, rate=16000)总结
本文介绍了对使用音乐领域知识的音乐生成人工智能 Mustango 的研究。这项研究的局限性之一是,由于计算资源的限制,目前的 Mustango 最多只能生成 10 秒钟的音乐。他们还说,目前的 Mustango 主要只能处理西方的音乐形式,在创作其他文化的音乐方面能力较弱。因此,作为未来的研究,他们计划 “生成时间更长的音乐”,并 “将其应用于更多样化的音乐流派,例如处理非西方音乐”。虽然 Mustango 在许多指标上都达到了 SOTA,但我感觉它在某些方面的性能仍然不如其他型号。尽管如此,就本研究中构建的数据集 MusicBench 而言,它似乎已被证明是有效的,因此在很大程度上可用作未来研究的基准。
-
相关阅读:
0093 二分查找算法,分治算法
《Linux 内核设计与实现》13. 虚拟文件系统
Autosar AP的基本构成
Sentinel规则持久化到Nacos教程
2、赛灵思-Zynq UltraScale+ MPSoC学习笔记:Petalinux 2021.2工具安装
MQ和分布式事务
Tomcat解析
微秒级 TCP 时间戳
什么是运营商精准大数据?又有什么作用?
javascript自定义事件的观察者模式写法和用法以及继承
- 原文地址:https://blog.csdn.net/matt45m/article/details/140112011