-
EfficientNet-V1论文阅读笔记
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
论文链接:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
摘要
(1)本文系统地研究了模型的缩放,并且研究确定通过仔细平衡网络深度、宽度和分辨率可以带来更好的性能。
(2)本文提出了一种新的缩放方法,使用一个简单而高效的复合系数统一缩放深度/宽度/分辨率的所有维度。
(3)本文使用神经结构搜索来设计一个新的基线网络,并将其扩大到获得一个模型系列,称为EfficientNets。
(4)本文在数据集上进行实验,发现均能取得最先进的准确性,而参数却少了一个数量级。
Introduction—简介
在以前的工作中,通常都是在深度,宽度,和图像大小三个维度其中之一进行缩放。任意缩放需要繁琐的人工调参,同时可能产生的是一个次优的精度和效率。
本文通过NAS同时探索深度、宽度、分辨率对性能的影响,之前一般都是对一个维度进行探索。
具体方法是使用一组固定的缩放系数来统一缩放网络的宽度、深度和分辨率。
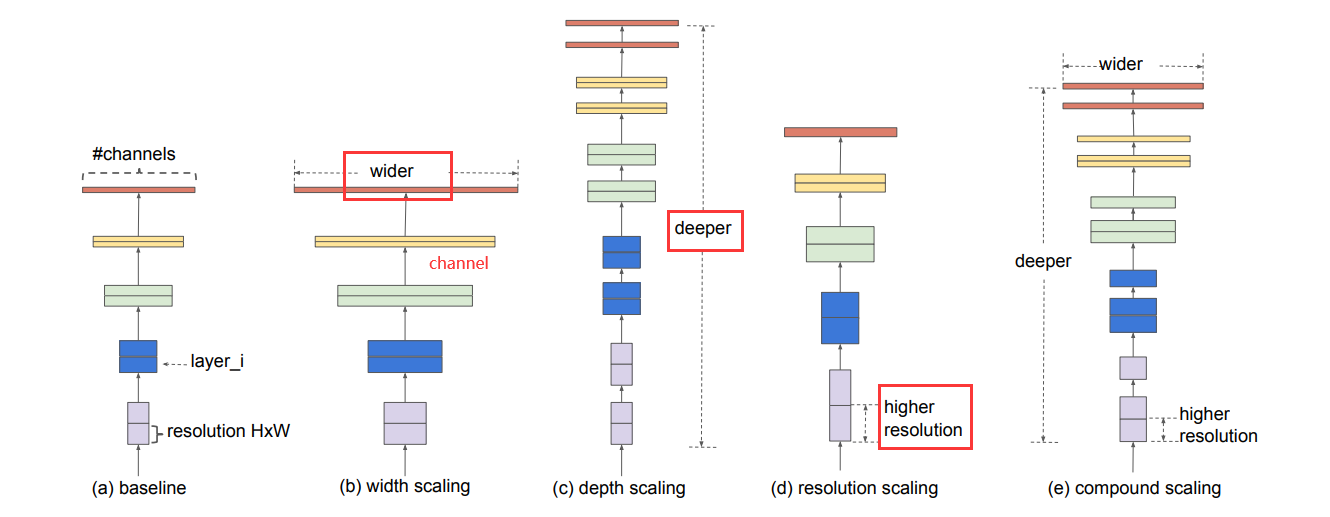
Compound Model Scaling—混合模型缩放
Problem Formulation—范式化问题(理论基础)
假设一个卷积层i 可以被定义为一个函数:Yi = Fi ( Xi )
其中的Xi表示输入的特征图,而Yi是输出特征矩阵,Fi就表示这i层的卷积操作。其中Xi的tensor形状为
,其中Hi与Wi为空间维度,Ci为通道维度。而卷积网络可以由一系列这样的层结构组成:
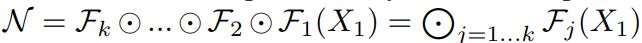
在实践中,ConvNet层往往被划分为多个阶段,每个阶段的所有层都具有相同的架构。
作者回顾了目前网络设计的套路,总结为以下的公式:
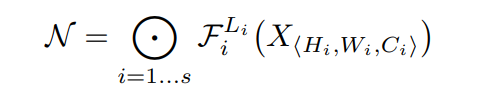
其中,Fi^(Li)为第i阶段重复了Li次的层Fi;其中Xi的tensor形状为< Hi,Wi,Ci >
之前的网络设计注重模块化的设计,也就是对Fi的设计,比如ResNet中的Basic Block和Bottleneck Block。
但分别考虑每个阶段的变化,这个搜索空间无疑太大了,因此作者对整个模型采用一种统一的缩放策略,转化为一个优化问题,如下(d,w,r表示对宽度、深度、分辨率的缩放系数):

Scaling Dimensions—维度缩放
Depth:根据以往的经验,增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。
缩放网络深度是一种常用的提高卷积网络精度的方法,但是由于梯度消失问题,更深层次的网络也更难训练。
Width:小型模型通常使用缩放网络宽度来提取更多的特征,增加网络的width(增加卷积核的个数)能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。
Resolution:增加输入网络的图像分辨率能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小。并且大分辨率图像会增加计算量。
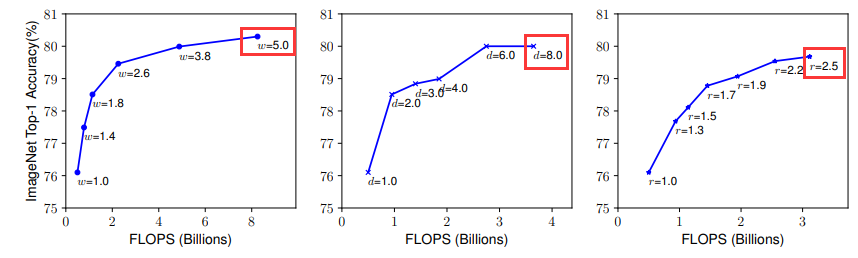
本文第一个结论: 扩大网络宽度、深度或分辨率的任何维度都能提高精确度,但对于更大的模型来说,精确度的提高会减弱。
Compound Scaling—混合缩放
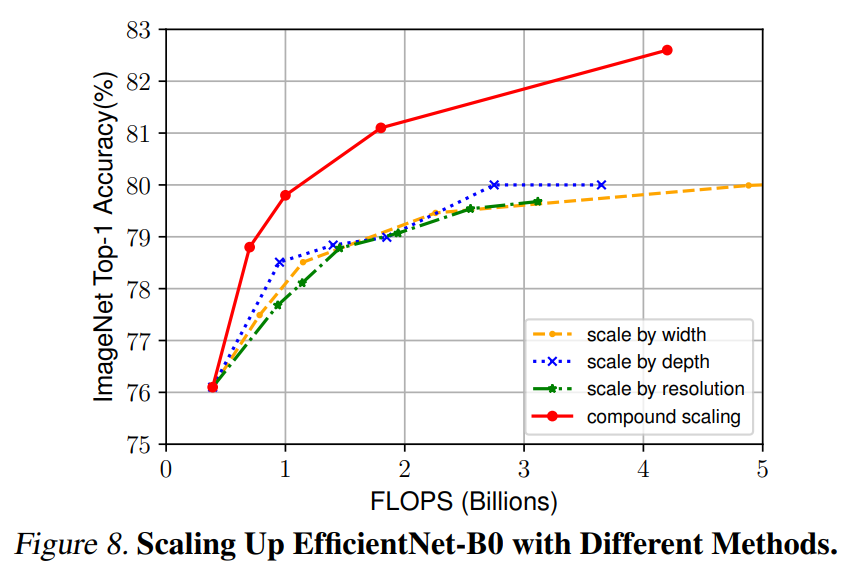
从下图可以看出,对于d和r,单独进行缩放均能提升精度,但是同时进行缩放精度的饱和点更高。
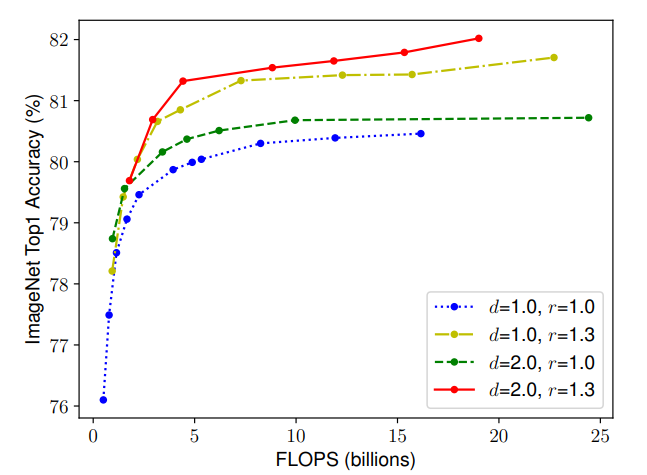
本文第二个结论: 为了追求更好的精度和效率,在连续网络缩放过程中平衡网络宽度、深度和分辨率的所有维度是至关重要的。
基于上述验证,本文提出新的复合尺度方式
该方法利用复合系数φ来均匀尺度网络的宽度、深度和分辨率:
α,β,γ是可以通过小网格搜索确定的常数。
φ是一个用户指定的系数,它控制有多少资源可用于模型缩放,而α、β、γ则指定如何将这些额外的资源分别分配给网络宽度、深度和分辨率。
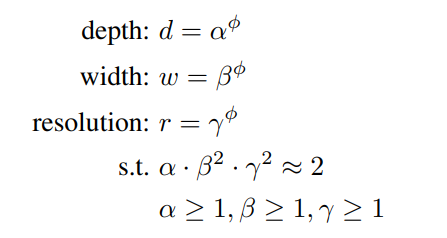
EfficientNet Architecture—EfficientNet结构
EfficientNet-B0
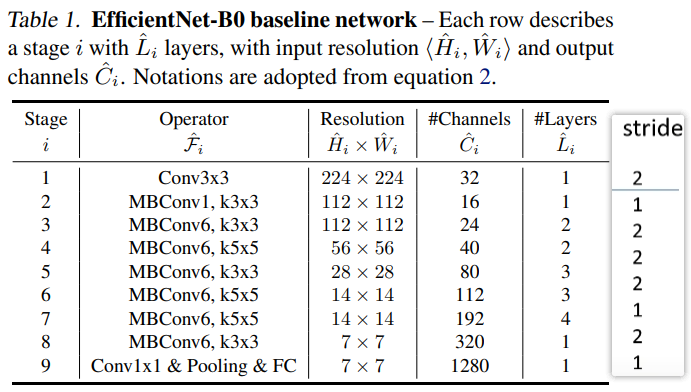
EfficientNet-B0各参数如下表,在 B0 中一共分为 9 个 stage,表中的卷积层都默认后面跟了BN层和Swish激活函数。Stage 1 就是一个 3×3 的卷积层。对于 stage 2 到 stage 8 就是在重复堆叠 MBConv。
Layers表示这一层重复堆叠该结构多少次,比如Stage5表示该层对MBConv6这个结构重复堆叠了三次。
stride表示每个stage中的第一个结构(第一个operator)的stride,其他的stride默认为1。
MBConv 模块
MBConv 模块其实就是mobilenetV3的模块

(1)首先是一个 1×1 卷积用于升维,其输出 channel 是输入 channel 的 n 倍(MBConv6就表示n = 6)。
(2)紧接着通过一个 DW 卷积。
(3)然后通过一个 SE 模块,使用注意力机制调整特征矩阵。
(4)之后再通过 1×1 卷积进行降维。注意这里只有 BN,没有 swish 激活函数(其实就是对应线性激活函数)。
(5)最后跟一个dropout层。
注意:
EfficientNet-B0的stage2中,MBConv1由于n = 1,因此没有升维,是没有这一层的。
第一个1x1卷积、DW后面都是接BN + Swish,而最后的1x1降维卷积是没用激活函数的,要用Identity函数。
这里的Dropout用的是Drop path,而不是传统的Dropout。
关于shortcut连接,当且仅当输入MBConv结构的特征矩阵和输出的特征矩阵的shape相同且DW卷积的stride=1时才使用。
SE模块(与mobilenetV3有些许不同)
第一个全连接层的节点个数是输入该MBConv特征矩阵(上图的输入矩阵)channels的1/4(MobileNetV3中第一个全连接层的节点个数是下图feature map中的1/4),且使用Swish激活函数。
第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels(执行下图中点×操作),且使用Sigmoid激活函数。
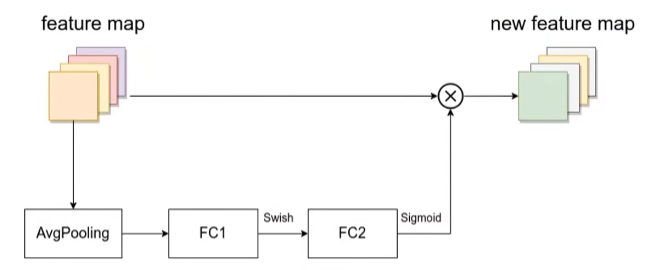
MBConv 模块详细结构图如下

性能评估
之前的所有的缩放方法都是以更多的FLOPS为代价来提高准确性,但是本文的复合缩放方法可以进一步提高准确性。
总结
- 这篇论文是Google在2019年发布的文章,作者系统地研究ConvNet的缩放,并确定仔细平衡网络宽度、深度和分辨率的重要性。
- 论文最主要的创新点是Model Scaling,作者提出了一种简单而高效的复合缩放方法,使我们能够以更原则(深度、宽度、分辨率,组合起来按照一定规则缩放)的方式轻松地将基线ConvNet缩放到任何目标资源约束,同时保持模型效率。
-
相关阅读:
Aragon创建DAO polygon BSC测试网
基于ansible批量实现部署数据库主从复制
我的前端成长之路:中医药大学毕业的业务女前端修炼之路
优优嗨聚集团:美团代运营服务,对美团外卖商家有何促进
总结:linux笔记-004
架构篇(八)架构师的职责和能力模型
雷军造车1年+,手机“打法”真的适合小米汽车吗?
ASP.NET WebForm--事件
使用阿里云OSS实现视频上传功能
Mac pt-online-schema-change 图文并茂、不锁表在线修改 MySQL 表结构
- 原文地址:https://blog.csdn.net/weixin_47365232/article/details/139925307