-
基于多模态知识图谱的多模态推理-MR-MKG
MR-MKG论文中提出了一种新的多模态推理方法,即利用多模态知识图(Multimodal Knowledge Graph, MMKG)进行多模态推理的方法。这种方法旨在通过从MMKG中学习,扩展大型语言模型(LLMs)的多模态知识。
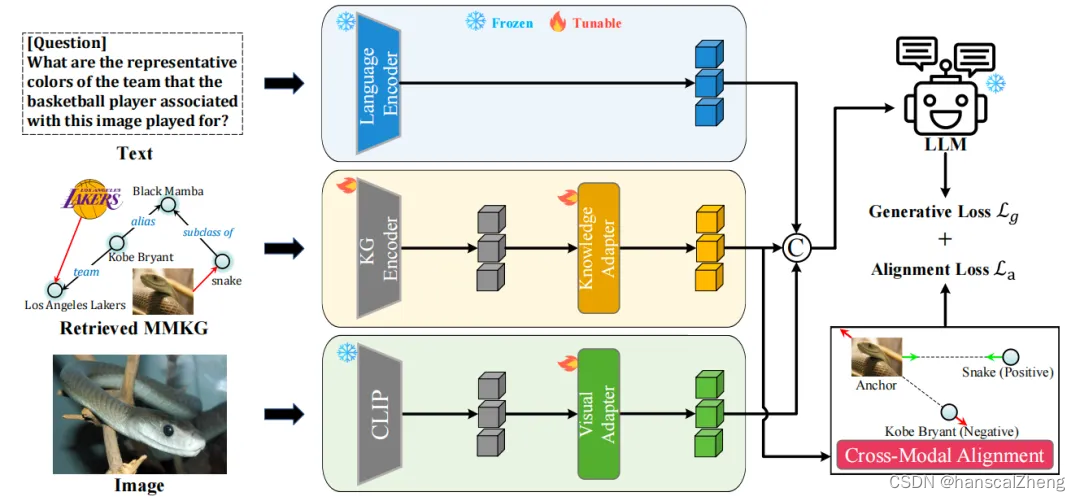
1 三个模块
MR-MKG方法主要包含以下三个模块,分别处理不同的模态信息:
文本编码(Language Encoder):将问题文本进行嵌入得到表征,随后将其输入LLMs以提供指导和指令。
MMKG编码(KG Encoder):使用关系图注意网络(Relation Graph Attention Network, RGAT)对检索到的MMKG子网络进行编码,生成能够捕捉复杂图结构的知识节点嵌入。
视觉图片编码(CLIP):利用CLIP将实体相关的图片信息进行嵌入得到图片的嵌入向量表示。
2 三个步骤
通过上述三个模块获得相应模态的特征表示之后,在进行下面几个步骤:
跨模态适配©:设计知识和视觉适配层,以跨越模态之间的差距,分别将知识节点嵌入和视觉图片嵌入映射到LLMs的文本嵌入中。
跨模态对齐(Alignment loss):引入新的跨模态对齐模块,通过MMKG内的匹配任务优化图像-文本对齐。
指令微调训练(Generative loss):在自定义的MMKG数据集上对MR-MKG进行微调训练,该数据集通过将每个VQA实例与相应的MMKG匹配构建,包含回答问题所需的基本知识。
3 结语
MR-MKG方法通过利用MMKG中的丰富知识(图像、文本和知识三元组),显著增强了LLMs的多模态推理能力,展示了其在多模态问答和类比推理任务上的有效性和优势。
论文题目:Multimodal Reasoning with Multimodal Knowledge Graph
论文链接:https://arxiv.org/abs/2406.02030
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!

-
相关阅读:
【Java 进阶篇】深入理解 Bootstrap 导航条与分页条
Direct3D网格(一)
Dubbo3应用开发——架构的演变过程
HarmonyOS 如何使用异步并发能力进行开发
两步随机接入机制的深度解析和未来增强
RabbitMQ---Spring AMQP
数据分析的概念
快速开发微信小程序之一登录认证
XAPI项目架构:应对第三方签名认证的设计与调整
如何设计数据可视化平台
- 原文地址:https://blog.csdn.net/weixin_43145427/article/details/140054605