-
头条系统-05-延迟队列精准发布文章-概述&添加任务(db和redis实现延迟任务)、取消&拉取任务&定时刷新(redis管道、分布式锁setNx)
文章目录
延迟任务精准发布文章
1)文章定时发布
2)延迟任务概述
2.1)什么是延迟任务
- 定时任务:有固定周期的,有明确的触发时间
- 延迟队列:没有固定的开始时间,它常常是由一个事件触发的,而在这个事件触发之后的一段时间内触发另一个事件,任务可以立即执行,也可以延迟


应用场景:
场景一:订单下单之后30分钟后,如果用户没有付钱,则系统自动取消订单;如果期间下单成功,任务取消
场景二:接口对接出现网络问题,1分钟后重试,如果失败,2分钟重试,直到出现阈值终止
2.2)技术对比
2.2.1)DelayQueue
JDK自带DelayQueue 是一个支持延时获取元素的阻塞队列, 内部采用优先队列 PriorityQueue 存储元素,同时元素必须实现 Delayed 接口;在创建元素时可以指定多久才可以从队列中获取当前元素,只有在延迟期满时才能从队列中提取元素

DelayQueue属于排序队列,它的特殊之处在于队列的元素必须实现Delayed接口,该接口需要实现compareTo和getDelay方法
getDelay方法:获取元素在队列中的剩余时间,只有当剩余时间为0时元素才可以出队列。
compareTo方法:用于排序,确定元素出队列的顺序。
实现:
1:在测试包jdk下创建延迟任务元素对象DelayedTask,实现compareTo和getDelay方法,
2:在main方法中创建DelayQueue并向延迟队列中添加三个延迟任务,
3:循环的从延迟队列中拉取任务
public class DelayedTask implements Delayed{ // 任务的执行时间 private int executeTime = 0; public DelayedTask(int delay){ Calendar calendar = Calendar.getInstance(); calendar.add(Calendar.SECOND,delay); this.executeTime = (int)(calendar.getTimeInMillis() /1000 ); } /** * 元素在队列中的剩余时间 * @param unit * @return */ @Override public long getDelay(TimeUnit unit) { Calendar calendar = Calendar.getInstance(); return executeTime - (calendar.getTimeInMillis()/1000); } /** * 元素排序 * @param o * @return */ @Override public int compareTo(Delayed o) { long val = this.getDelay(TimeUnit.NANOSECONDS) - o.getDelay(TimeUnit.NANOSECONDS); return val == 0 ? 0 : ( val < 0 ? -1: 1 ); } public static void main(String[] args) { DelayQueue<DelayedTask> queue = new DelayQueue<DelayedTask>(); queue.add(new DelayedTask(5)); queue.add(new DelayedTask(10)); queue.add(new DelayedTask(15)); System.out.println(System.currentTimeMillis()/1000+" start consume "); while(queue.size() != 0){ DelayedTask delayedTask = queue.poll(); if(delayedTask !=null ){ System.out.println(System.currentTimeMillis()/1000+" cosume task"); } //每隔一秒消费一次 try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } }DelayQueue实现完成之后思考一个问题:
使用线程池或者原生DelayQueue程序挂掉之后,任务都是放在内存,需要考虑未处理消息的丢失带来的影响,如何保证数据不丢失,需要持久化(磁盘)
2.2.2)RabbitMQ实现延迟任务
-
TTL:Time To Live (消息存活时间)
-
死信队列:Dead Letter Exchange(死信交换机),当消息成为Dead message后,可以重新发送另一个交换机(死信交换机)
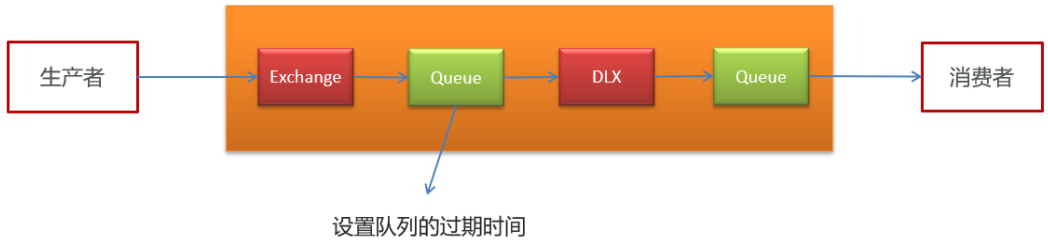
Queue有过期时间,到时间后会将消息转发出去,如第一个Queue的消息到期后自动发送到DLX2.2.3)redis实现
zset数据类型的去重有序(分数排序)特点进行延迟。例如:时间戳作为score进行排序

例如:
生产者添加到4个任务到延迟队列中,时间毫秒值分别为97、98、99、100。当前时间的毫秒值为90
消费者端进行监听,如果当前时间的毫秒值匹配到了延迟队列中的毫秒值就立即消费本项目就采用redis实现!!
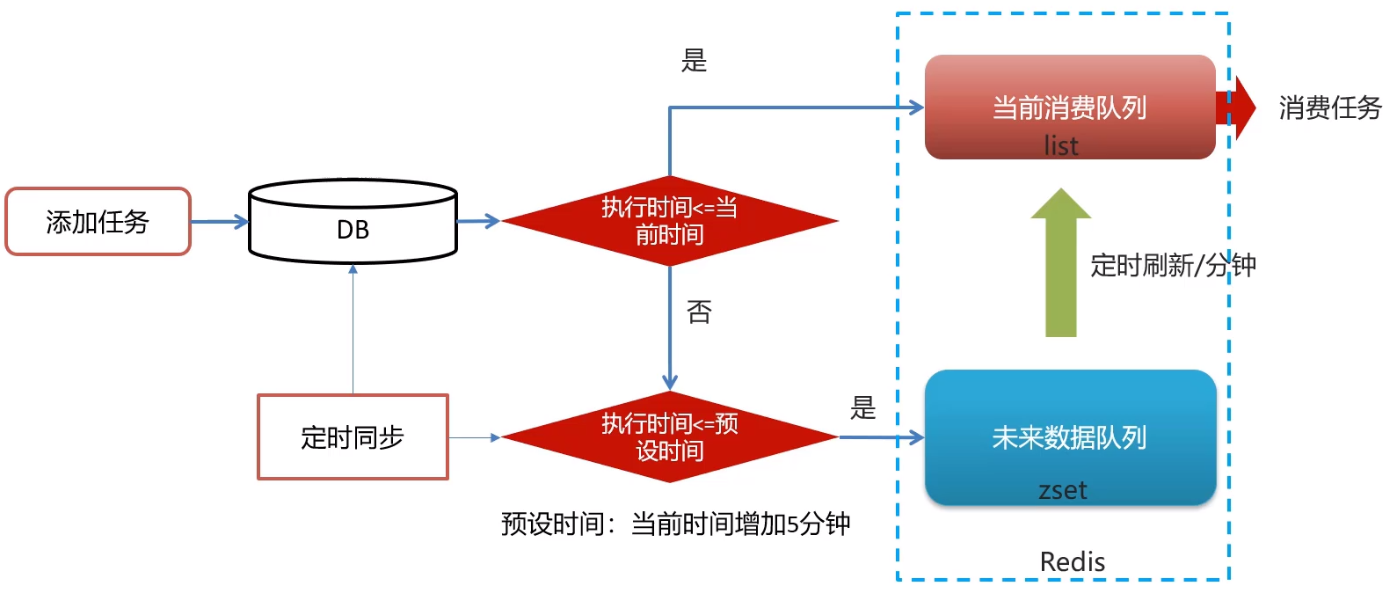
3)redis实现延迟任务
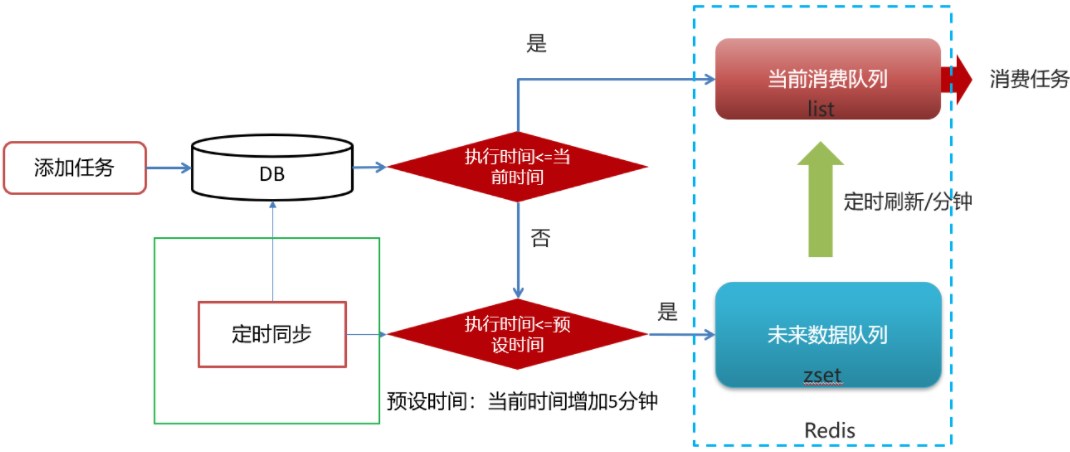
实现思路
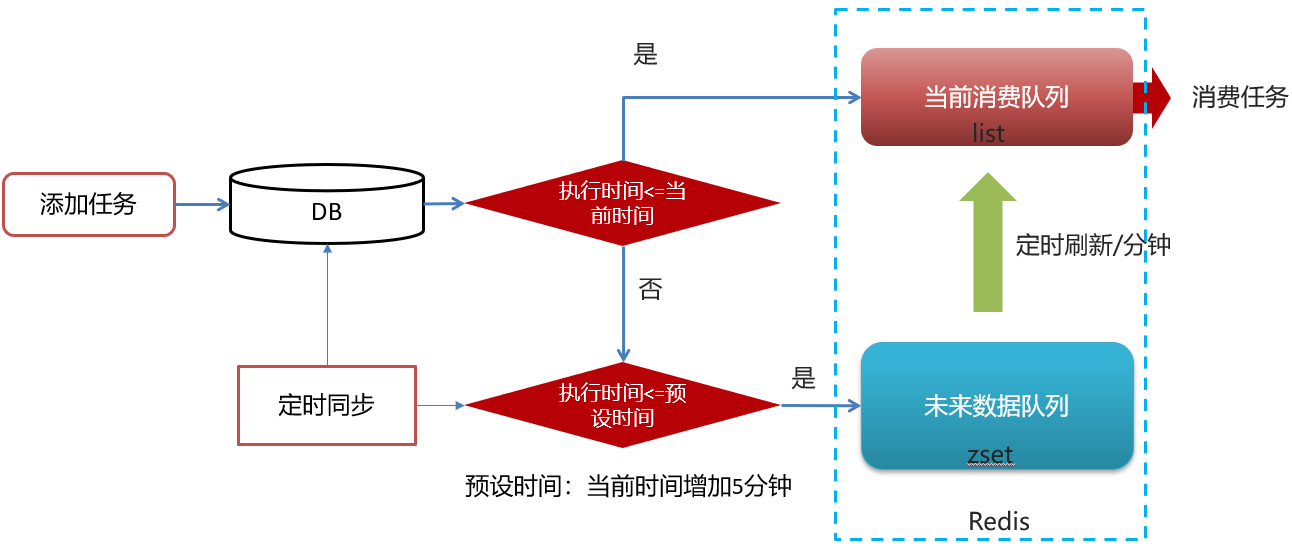
- 执行时间<=当前时间 需要立即执行 进入list队列 lpush 配合 rpop
- 执行时间>当前时间 延迟执行 手动再配置一进入zset
2.1 还手动设置了一个预设(延迟)时间,比如5分钟内要执行得任务,才允许加入zset队列中 - 只有list队列才是消费队列,只会去list队列找任务来消费,所以每隔一段时间需要定时刷新zset队列,把到期的任务放到list中去
问题思路
1.为什么任务需要存储在数据库中?
延迟任务是一个通用的服务,任何需要延迟得任务都可以调用该服务,需要考虑数据持久化的问题,存储数据库中是一种数据安全的考虑。
2.为什么redis中使用两种数据类型,list和zset?
效率问题,算法的时间复杂度
redis的list是一个双向链表,数据量大时,相对于zset,list的插入删除查找效率要高得多得多
list(当前消费队列):存放立即要执行的任务
zset(未来数据队列):存放未来要执行的任务
3.在添加zset数据的时候,为什么不需要预加载?
任务模块是一个通用的模块,项目中任何需要延迟队列的地方,都可以调用这个接口,要考虑到数据量的问题,如果数据量特别大,为了防止阻塞,只需要把未来几分钟要执行的数据存入缓存即可。
4)延迟任务服务实现
4.1)搭建heima-leadnews-schedule模块
leadnews-schedule是一个通用的服务,单独创建模块来管理任何类型的延迟任务
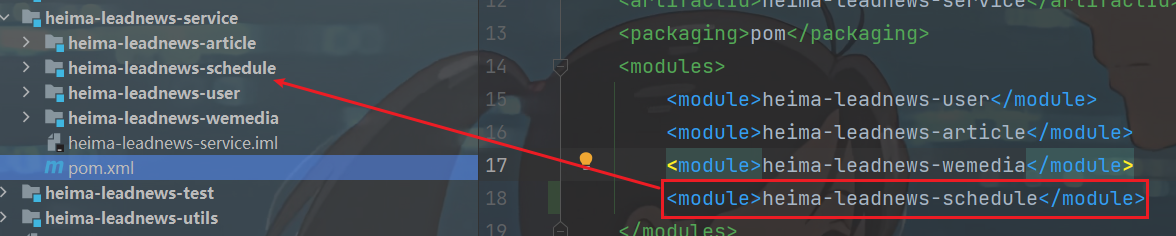
①:导入资料文件夹下的heima-leadnews-schedule模块到heima-leadnews-service下,如下图所示:
heima-leadnews-service的pom.xml内导入:(记得刷新maven)
②:添加bootstrap.yml
server: port: 51701 spring: application: name: leadnews-schedule cloud: nacos: discovery: server-addr: 192.168.141.102:8848 # nacos热配置中心 config: server-addr: 192.168.141.102:8848 file-extension: yml注意server-addr的ip换成自己的
③:在nacos中添加对应配置,并添加数据库及mybatis-plus的配置
spring: datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/leadnews_schedule?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC username: root password: 1234 # 设置Mapper接口所对应的XML文件位置,如果你在Mapper接口中有自定义方法,需要进行该配置 mybatis-plus: mapper-locations: classpath*:mapper/*.xml # 设置别名包扫描路径,通过该属性可以给包中的类注册别名 type-aliases-package: cn.whu.model.schedule.pojos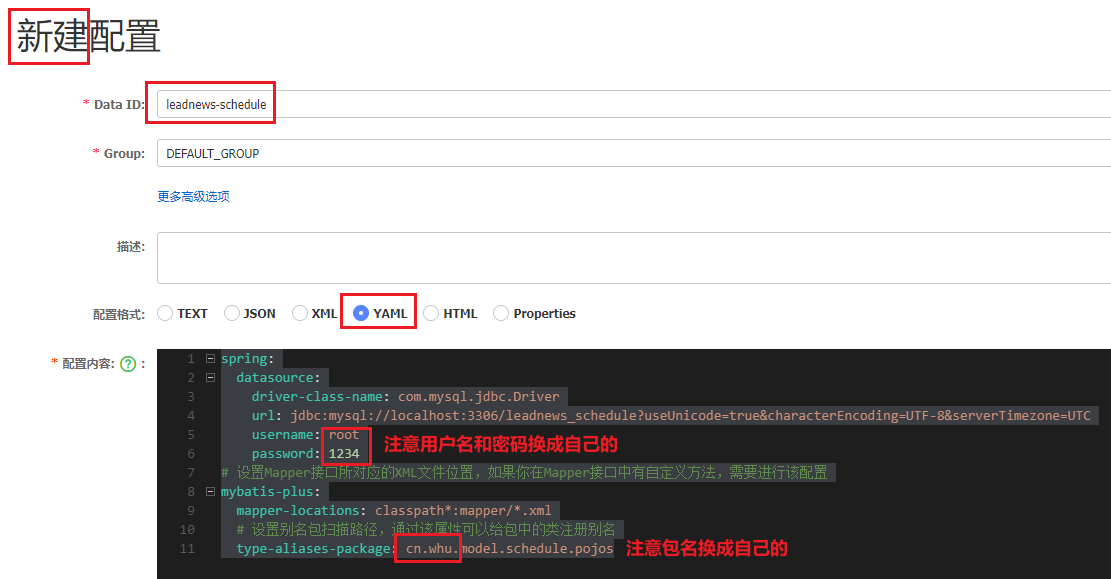
4.2)数据库准备
导入资料中leadnews_schedule数据库

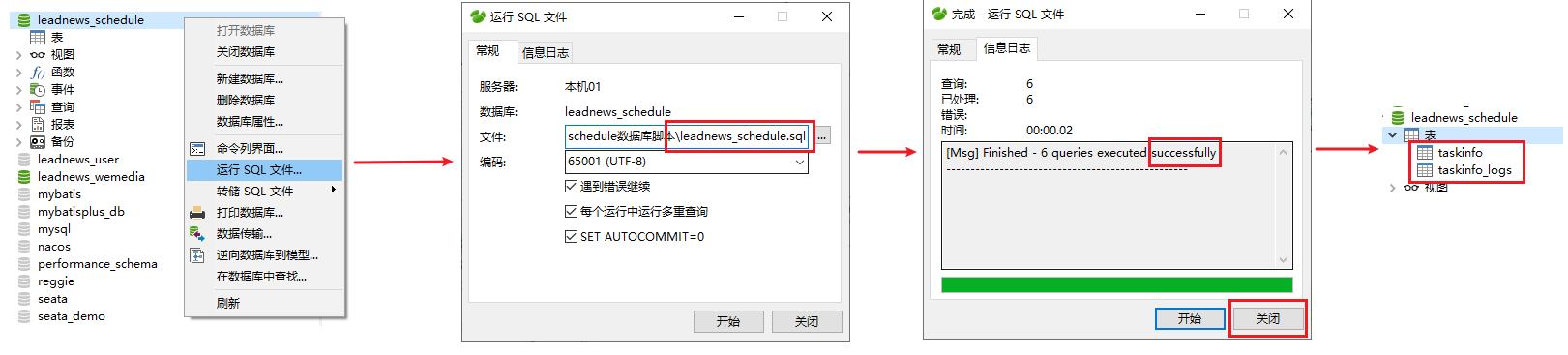
taskinfo 任务表

MySQL中,BLOB是一个二进制大型对象,是一个可以存储大量数据的容器;LongBlob 最大存储 4G (上面parameters就这个类型)实体类
heima-leadnews-model模块下新建包: cn.whu.model.schedule.pojos
package cn.whu.model.schedule.pojos; import com.baomidou.mybatisplus.annotation.IdType; import com.baomidou.mybatisplus.annotation.TableField; import com.baomidou.mybatisplus.annotation.TableId; import com.baomidou.mybatisplus.annotation.TableName; import lombok.Data; import java.io.Serializable; import java.util.Date; @Data @TableName("taskinfo") public class Taskinfo implements Serializable { private static final long serialVersionUID = 1L; /** * 任务id */ @TableId(type = IdType.ID_WORKER) private Long taskId; /** * 执行时间 */ @TableField("execute_time") private Date executeTime; /** * 参数 */ @TableField("parameters") private byte[] parameters; /** * 优先级 */ @TableField("priority") private Integer priority; /** * 任务类型 */ @TableField("task_type") private Integer taskType; }taskinfo_logs 任务日志表

实体类
heima-leadnews-model模块的 cn.whu.model.schedule.pojos包下
package cn.whu.model.schedule.pojos; import com.baomidou.mybatisplus.annotation.*; import lombok.Data; import java.io.Serializable; import java.util.Date; @Data @TableName("taskinfo_logs") public class TaskinfoLogs implements Serializable { private static final long serialVersionUID = 1L; /** * 任务id */ @TableId(type = IdType.ID_WORKER) private Long taskId; /** * 执行时间 */ @TableField("execute_time") private Date executeTime; /** * 参数 */ @TableField("parameters") private byte[] parameters; /** * 优先级 */ @TableField("priority") private Integer priority; /** * 任务类型 */ @TableField("task_type") private Integer taskType; /** * 版本号,用乐观锁 */ @Version private Integer version; /** * 状态 0=int 1=EXECUTED 2=CANCELLED */ @TableField("status") private Integer status; }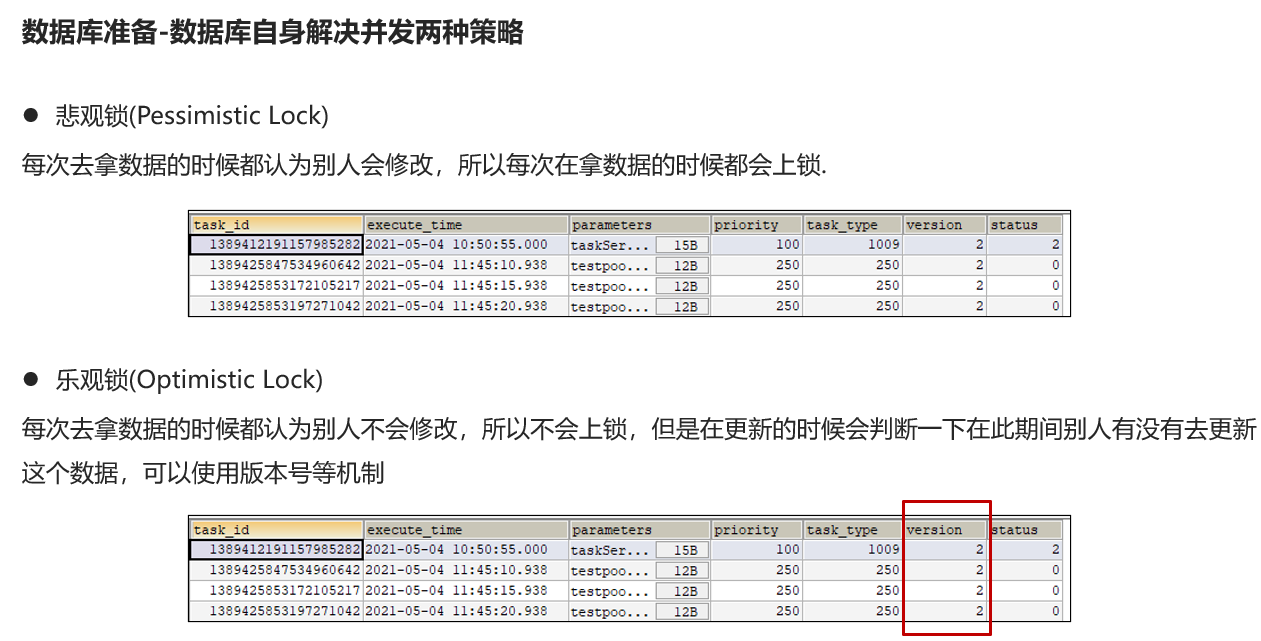
悲观锁:每次修改之前都将该行数据上锁,直到我修改结束才解锁
乐观锁:每次修改过程中不上锁,但是修改前记录数据原始值副本,修改那一刻判断是否一致,一致才允许修改(当然这里是比较的版本号) 两种方法都有人用,但是乐观锁可能效率会更高一点
@Version修饰的字段,每次修改MP应该会自动帮你自增
乐观锁支持: ScheduleApplication.java启动类里加
/** * mybatis-plus乐观锁支持 * @return */ @Bean public MybatisPlusInterceptor optimisticLockerInterceptor(){ MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor()); return interceptor; }4.3)安装redis
①拉取镜像
docker pull redis提供的虚拟机镜像已经下载了redis镜像,
docker images可查看。
此步可略过,直接执行第二步即可② 创建容器
docker run -d --name redis --restart=always -p 6379:6379 redis --requirepass "leadnews"指定密码:leadnews
③链接测试
打开资料中的Redis Desktop Manager,输入host、port、password链接测试
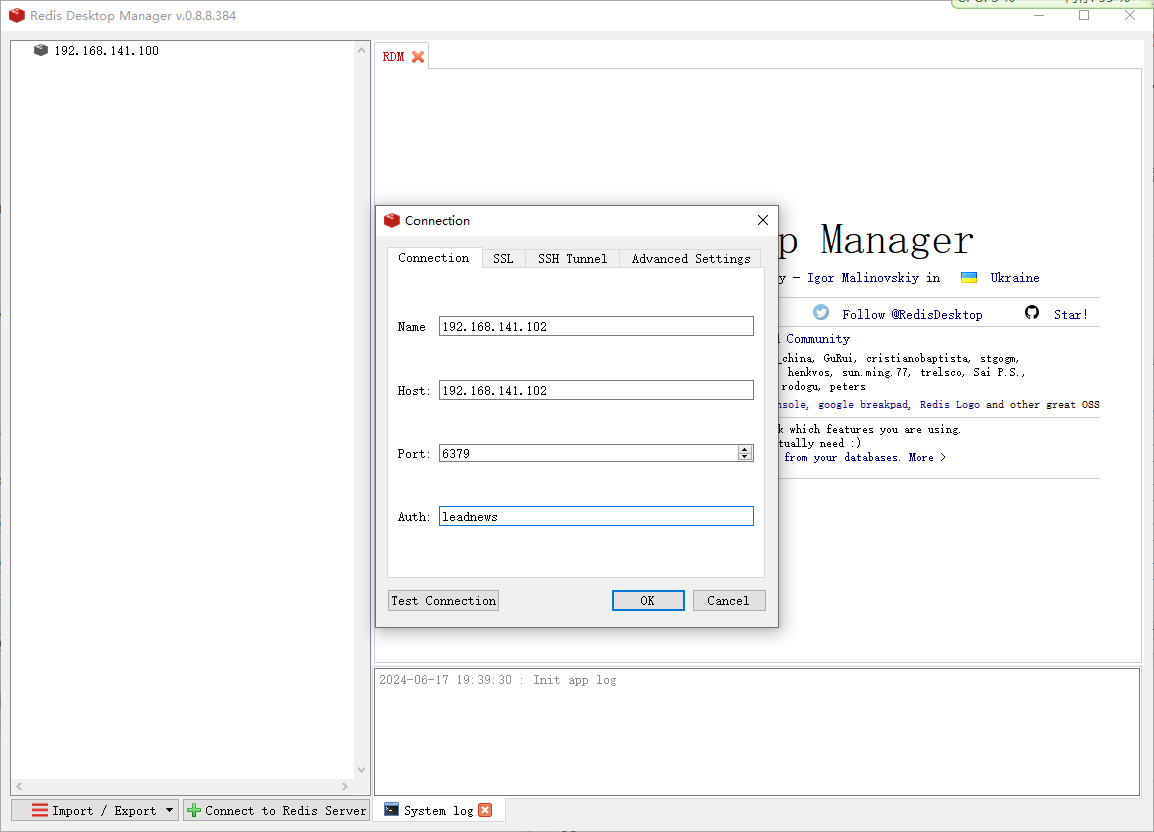
能链接成功,即可
4.4)项目集成redis
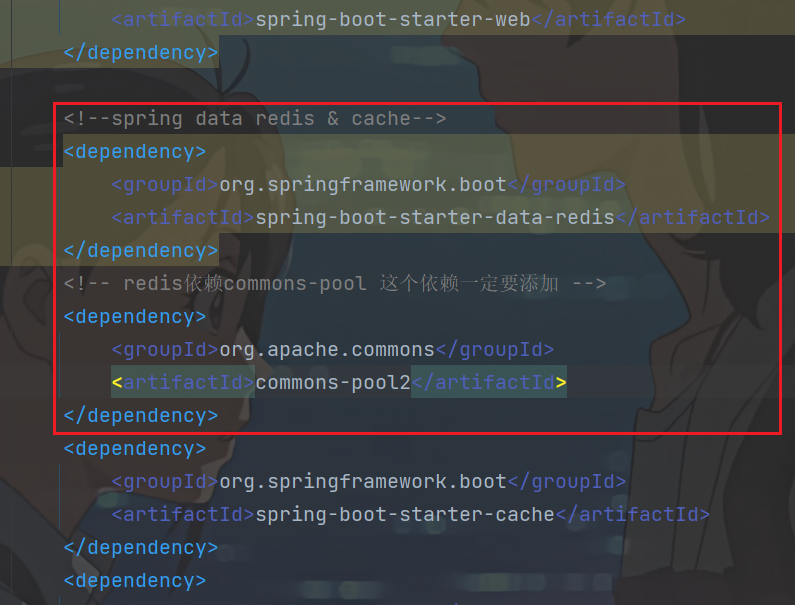
① 在项目导入redis相关依赖,已经完成
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-redisartifactId> dependency> <dependency> <groupId>org.apache.commonsgroupId> <artifactId>commons-pool2artifactId> dependency>其实在heima-leadnews-common模块下早就已经引入了redis依赖,所以之前本地不开redis,项目都启动不了
② 在heima-leadnews-schedule中集成redis,添加以下nacos配置,链接上redis
谁要用redis,就谁配置呗
spring: redis: host: 192.168.141.102 password: leadnews port: 6379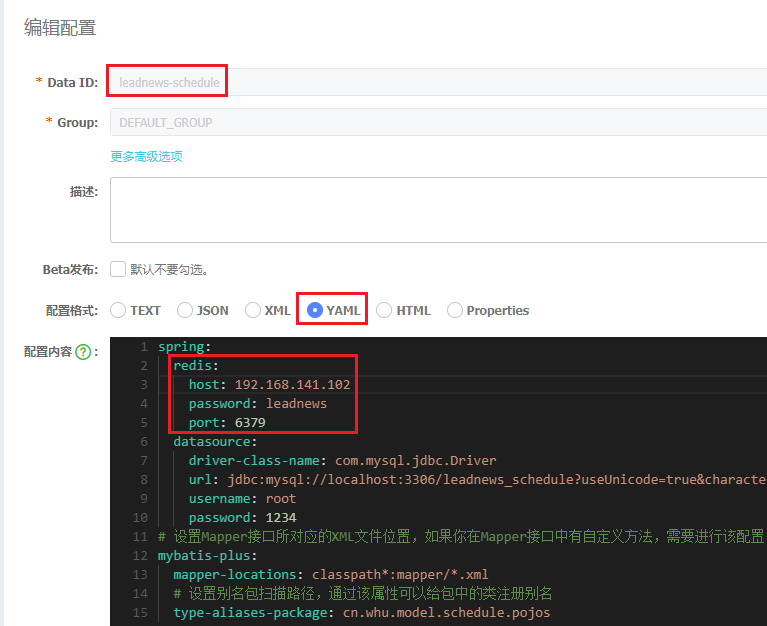
③ 拷贝资料文件夹下的类:CacheService到heima-leadnews-common模块下,并添加自动配置
工具类加了@Component注解,其他微服务导入后不一定直到要扫描这个包,这里手动配置一下
就是将StringRedisTemplate封装成了工具类
1415行的一个工具类,非常不容易了④:测试
heima-leadnews-schedule模块的test/java下面新建cn.whu.schedule.test.RedisTest
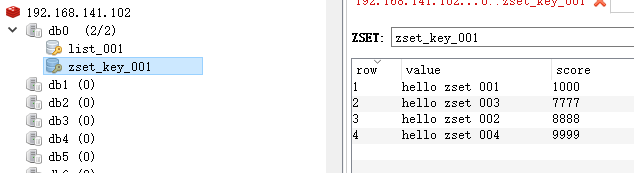
package cn.whu.schedule.test; import cn.whu.common.redis.CacheService; import cn.whu.schedule.ScheduleApplication; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import javax.annotation.Resource; import java.util.Set; @SpringBootTest(classes = ScheduleApplication.class) @RunWith(SpringRunner.class) public class RedisTest { @Resource private CacheService cacheService; @Test public void testList1(){ // 在list的左边添加元素 cacheService.lLeftPush("list_001","hello,redis1");//点进去看一下api的封装就是往list头部插入 cacheService.lLeftPush("list_001","hello,redis2");//点进去看一下api的封装就是往list头部插入 } @Test public void testList2(){ // 在list的右边获取元素,并删除 String list001 = cacheService.lRightPop("list_001"); System.out.println(list001); // hello,redis1 } @Test public void testZset1(){ // 添加数据到zset中 有分值的 cacheService.zAdd("zset_key_001","hello zset 001",1000); cacheService.zAdd("zset_key_001","hello zset 002",8888); cacheService.zAdd("zset_key_001","hello zset 003",7777); cacheService.zAdd("zset_key_001","hello zset 004",9999); } @Test public void testZset2(){ // 按照分值获取数据 // 获取分值在0~8888内的元素,且(应该自动是)按照分值升序排列 Set<String> zsetKey001 = cacheService.zRangeByScore("zset_key_001", 0, 8888); System.out.println(zsetKey001); // [hello zset 001, hello zset 003, hello zset 002] } }

4.5)添加任务
①:拷贝mybatis-plus生成的文件,mapper
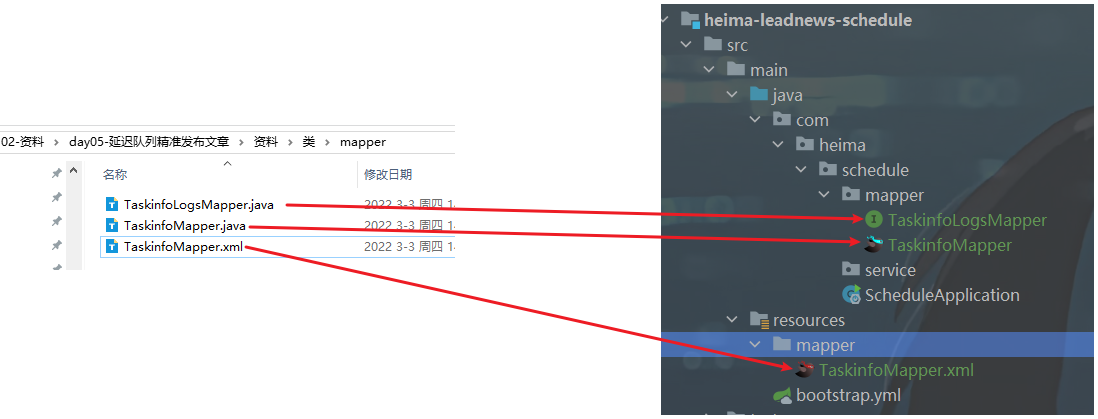
②:创建task类,用于接收添加任务的参数
heima-leadnews-model模块下的cn.whu.model.schedule.dtos.Task
package cn.whu.model.schedule.dtos; import lombok.Data; import java.io.Serializable; @Data public class Task implements Serializable { /** * 任务id */ private Long taskId; /** * 类型 */ private Integer taskType; /** * 优先级 */ private Integer priority; /** * 执行id */ private long executeTime; /** * task参数 */ private byte[] parameters; }③:创建TaskService
heima-leadnews-schedule模块下
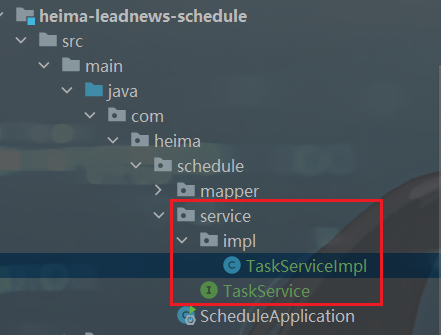
package cn.whu.schedule.service; import cn.whu.model.schedule.dtos.Task; /** * 对外访问接口 */ public interface TaskService { /** * 添加任务 * @param task 任务对象 * @return 任务id */ public long addTask(Task task) ; }实现:
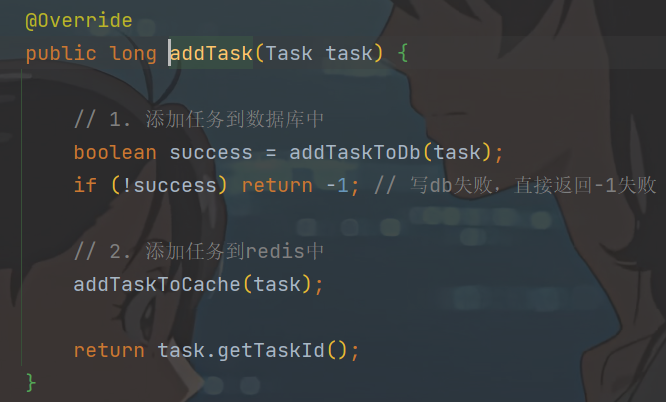
package cn.whu.schedule.service.impl; import cn.whu.common.constants.ScheduleConstants; import cn.whu.common.redis.CacheService; import cn.whu.model.schedule.dtos.Task; import cn.whu.model.schedule.pojos.Taskinfo; import cn.whu.model.schedule.pojos.TaskinfoLogs; import com.alibaba.fastjson.JSON; import cn.whu.schedule.mapper.TaskinfoLogsMapper; import cn.whu.schedule.mapper.TaskinfoMapper; import cn.whu.schedule.service.TaskService; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.BeanUtils; import org.springframework.beans.BeansException; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; import javax.annotation.Resource; import java.util.Date; @Service @Slf4j @Transactional public class TaskServiceImpl implements TaskService { // 访问db的两个mapper @Resource private TaskinfoMapper taskinfoMapper; @Resource private TaskinfoLogsMapper taskinfoLogsMapper; // 操作redis @Resource private CacheService cacheService; /** * 添加任务 * * @param task 任务对象 * @return 任务id */ @Override public long addTask(Task task) { // 1. 添加任务到数据库中 boolean success = addTaskToDb(task); if (!success) return -1; // 写db失败,直接返回-1失败 // 2. 添加任务到redis中 addTaskToCache(task); return task.getTaskId(); } private void addTaskToCache(Task task) { // 任务类型+优先级 就可以唯一标定一个task String key = task.getTaskType() + "_" + task.getPriority(); long delay = 5 * 60 * 1000;//延迟时间 5min if (task.getExecuteTime() <= System.currentTimeMillis()) { // 2.1 如果任务的执行时间<=当前时间,存入list (redis的list结构) cacheService.lLeftPush(ScheduleConstants.TOPIC + key, JSON.toJSONString(task)); } else if (task.getExecuteTime() <= System.currentTimeMillis() + delay) { // 2.2 如果任务的执行时间>当前时间 && 小于等于预设时间(未来5分钟) 存入zset (redis的zset结构) cacheService.zAdd(ScheduleConstants.FUTURE + key, JSON.toJSONString(task), task.getExecuteTime()); // 分值就是任务执行时间的ms值 } } /** * 添加任务到数据库中 * * @param task * @return */ private boolean addTaskToDb(Task task) { boolean flag = true; try { // 1. 保存任务表 // 1.1 准备数据 Taskinfo taskinfo = new Taskinfo(); // 1)拷贝数据 BeanUtils.copyProperties(task, taskinfo); // 2)特殊字段处理:执行时间的类型不一样,long->Date, 需要手动处理 taskinfo.setExecuteTime(new Date(task.getExecuteTime())); // 1.2 写db taskinfoMapper.insert(taskinfo); // 设置一下taskId task引用传递,可以返回到主调方 task.setTaskId(taskinfo.getTaskId()); // 2. 保存任务日志数据 // 2.1 准备数据 TaskinfoLogs taskinfoLogs = new TaskinfoLogs(); // 1)拷贝数据 BeanUtils.copyProperties(taskinfo, taskinfoLogs); // 2)特殊字段处理 taskinfoLogs.setVersion(1); // 乐观锁版本号 taskinfoLogs.setStatus(ScheduleConstants.SCHEDULED); // 初始化(init)状态0 // 2.2 写DB taskinfoLogsMapper.insert(taskinfoLogs); } catch (BeansException e) { flag = false; log.info("TaskServiceImpl-addTaskToDb exception task.id:{}", task.getTaskId(), e); e.printStackTrace(); } return flag; } }ScheduleConstants常量类
heima-leadnews-common模块的cn.whu.common.constants包下
package cn.whu.common.constants; public class ScheduleConstants { //task状态 public static final int SCHEDULED=0; //初始化状态 public static final int EXECUTED=1; //已执行状态 public static final int CANCELLED=2; //已取消状态 public static String FUTURE="future_"; //未来数据key前缀 public static String TOPIC="topic_"; //当前数据key前缀 }④:测试
- addTask方法测试
package cn.whu.schedule.service.impl; import cn.whu.model.schedule.dtos.Task; import cn.whu.schedule.ScheduleApplication; import cn.whu.schedule.service.TaskService; import org.junit.jupiter.api.Test; import org.junit.runner.RunWith; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import javax.annotation.Resource; @SpringBootTest(classes = ScheduleApplication.class) @RunWith(SpringRunner.class) class TaskServiceImplTest { @Resource private TaskService taskService; @Test void addTask() { Task task = new Task(); task.setTaskType(100); task.setPriority(50); task.setParameters("task test".getBytes()); task.setExecuteTime(System.currentTimeMillis()); long taskId = taskService.addTask(task); System.out.println("taskId = " + taskId); } }
taskinfo表

taskinfo_logs表:

redis: topic_前缀,表示当前就要执行的任务
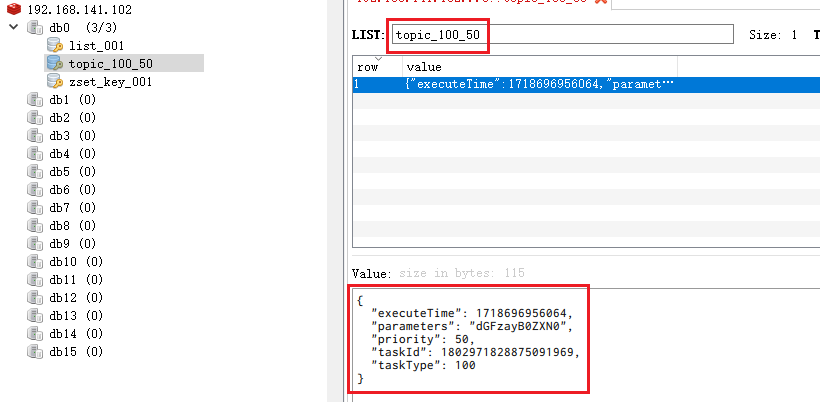
@SpringBootTest(classes = ScheduleApplication.class) @RunWith(SpringRunner.class) class TaskServiceImplTest { @Resource private TaskService taskService; @Test void addTask() { Task task = new Task(); task.setTaskType(100); task.setPriority(50); task.setParameters("task test".getBytes()); //task.setExecuteTime(System.currentTimeMillis()); task.setExecuteTime(System.currentTimeMillis()+500); long taskId = taskService.addTask(task); System.out.println("taskId = " + taskId); } }
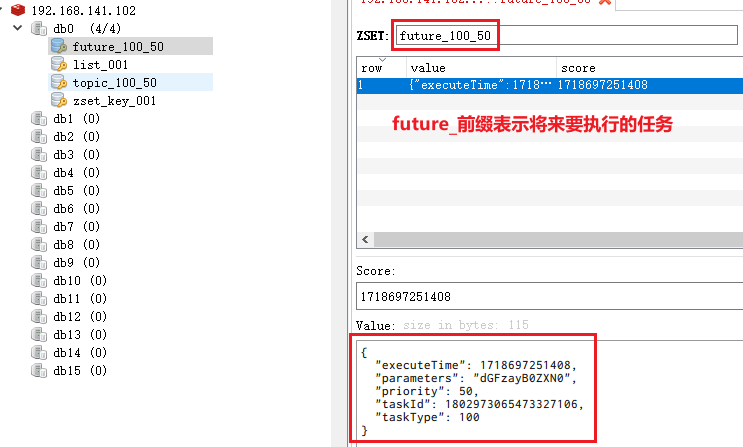
task.setExecuteTime(System.currentTimeMillis()+500000); // 超过5分钟 redis中就没有新记录了4.6)取消任务
在TaskService中添加方法
/** * 取消任务 * @param task 任务对象 * @return 取消成功还是失败 */ public boolean cancelTask(long taskId);实现
/*---------------------------删除任务-----------------------------*/ /** * 取消任务 * * @param taskId * @return 取消成功还是失败 */ @Override public boolean cancelTask(long taskId) { boolean flag = false; // 删除任务,更新任务日志 (taskinfo表删除一条记录 taskinfo_logs表更新一条记录) Task task = updateDb(taskId, ScheduleConstants.CANCELLED); // 删除redis需要task的两个字段找到key,以及执行时间判断在哪里 // 所以更新完db干脆直接返回task // 删除redis的数据(任务记录) if (task != null) { removeTaskFromCache(task); flag = true; } return flag; } /** * 删除redis中的数据 (就是那条任务记录) * * @param task */ private void removeTaskFromCache(Task task) { // 任务类型+优先级 确定一个任务队列 list String key = task.getTaskType() + "_" + task.getPriority(); if (task.getExecuteTime() <= System.currentTimeMillis()) { // 删除根据value来删的 key只是找到了那个任务队列 cacheService.lRemove(ScheduleConstants.TOPIC + key, 0, JSON.toJSONString(task)); } else { // 注意这里没有index参数了 (因为set不会重复的) cacheService.zRemove(ScheduleConstants.FUTURE + key, JSON.toJSONString(task)); } } private Task updateDb(long taskId, int status) { Task task = null; try { // 删除db表-taskinfo 记录 taskinfoMapper.deleteById(taskId); // 更新db表-taskinfo_logs 记录 TaskinfoLogs taskinfoLogs = taskinfoLogsMapper.selectById(taskId); taskinfoLogs.setStatus(status); taskinfoLogsMapper.updateById(taskinfoLogs); // 返回刚删除的task数据 task = new Task(); BeanUtils.copyProperties(taskinfoLogs, task); task.setExecuteTime(taskinfoLogs.getExecuteTime().getTime()); } catch (BeansException e) { log.error("task cancel exception taskId={}", taskId); e.printStackTrace(); } return task; }- 测试
@SpringBootTest(classes = ScheduleApplication.class) @RunWith(SpringRunner.class) class TaskServiceImplTest { @Resource private TaskService taskService; @Test public void cancelTask(){ taskService.cancelTask(1802971828875091969l); } }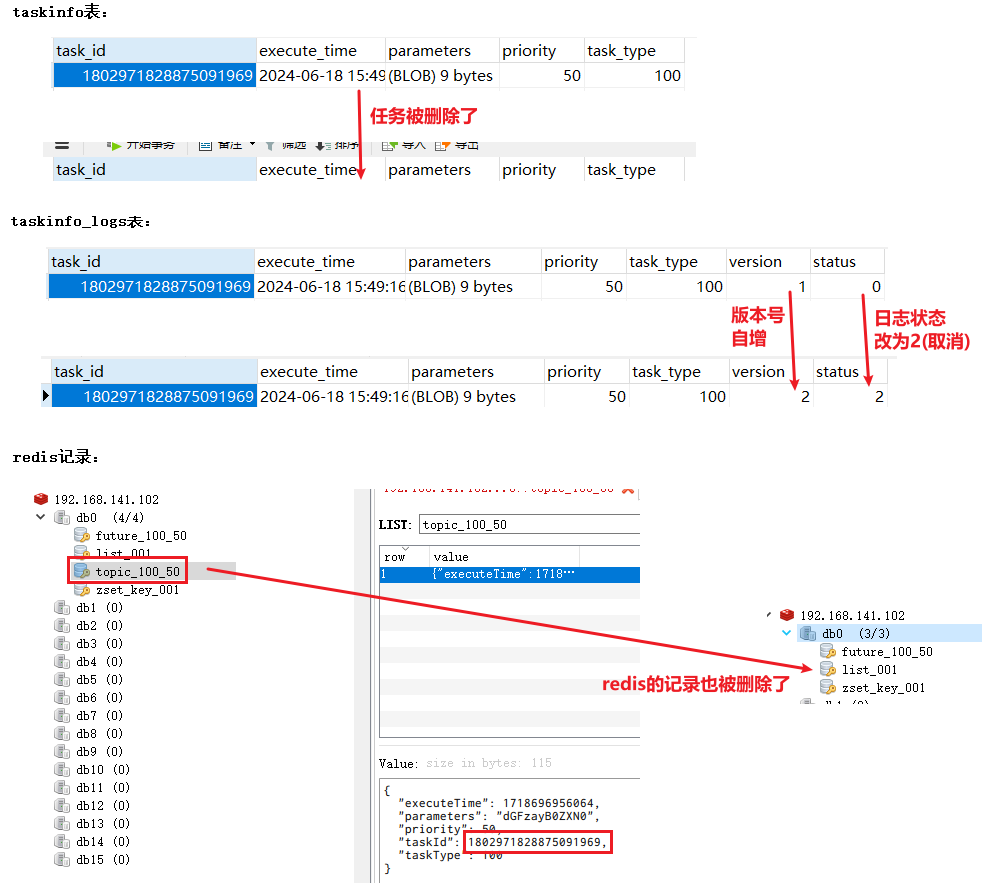
4.7)消费任务
在TaskService中添加方法
/** * 按照类型和优先级拉取任务 * 类型+优先级 -》 确定任务队列 * @param type * @param priority * @return */ public Task poll(int type,int priority);实现
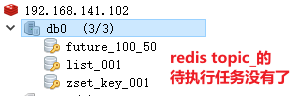
/** * 按照类型和优先级拉取任务 * 类型+优先级 -》 确定任务队列 * * @param type * @param priority * @return */ @Override public Task poll(int type, int priority) { Task task = null; try { // 1. 从redis拉取数据 String key = type + "_" + priority; // 待消费的任务只能在list中 String taskJson = cacheService.lRightPop(ScheduleConstants.TOPIC + key); if (StringUtils.isNotBlank(taskJson)) { task = JSON.parseObject(taskJson, Task.class); // 2. 修改db数据 // 删除任务 日志状态修改为已执行 updateDb(task.getTaskId(), ScheduleConstants.EXECUTED); } } catch (Exception e) { log.error("TaskServiceImpl.poll task error taskType={},taskPriority={}", type, priority); e.printStackTrace(); } return task; }-
测试
先addTask一个,再poll@SpringBootTest(classes = ScheduleApplication.class) @RunWith(SpringRunner.class) class TaskServiceImplTest { @Resource private TaskService taskService; @Test void addTask() { Task task = new Task(); task.setTaskType(100); task.setPriority(50); task.setParameters("task test".getBytes()); task.setExecuteTime(System.currentTimeMillis()); long taskId = taskService.addTask(task); System.out.println("taskId = " + taskId); } @Test public void poll(){ Task task = taskService.poll(100, 50); System.out.println("task = " + task); } }1)addTask后
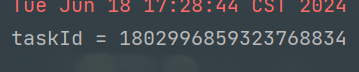


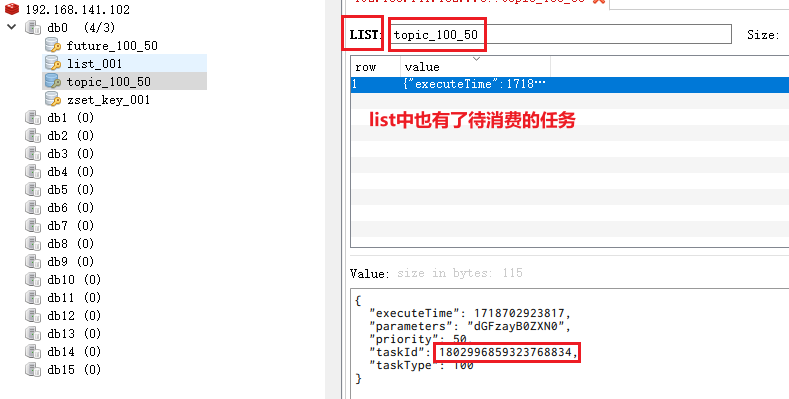
2)poll后

task = Task(taskId=1802996859323768834, taskType=100, priority=50, executeTime=1718702923817, parameters=[116, 97, 115, 107, 32, 116, 101, 115, 116])

4.8)未来数据定时刷新
定时刷新zset到list中
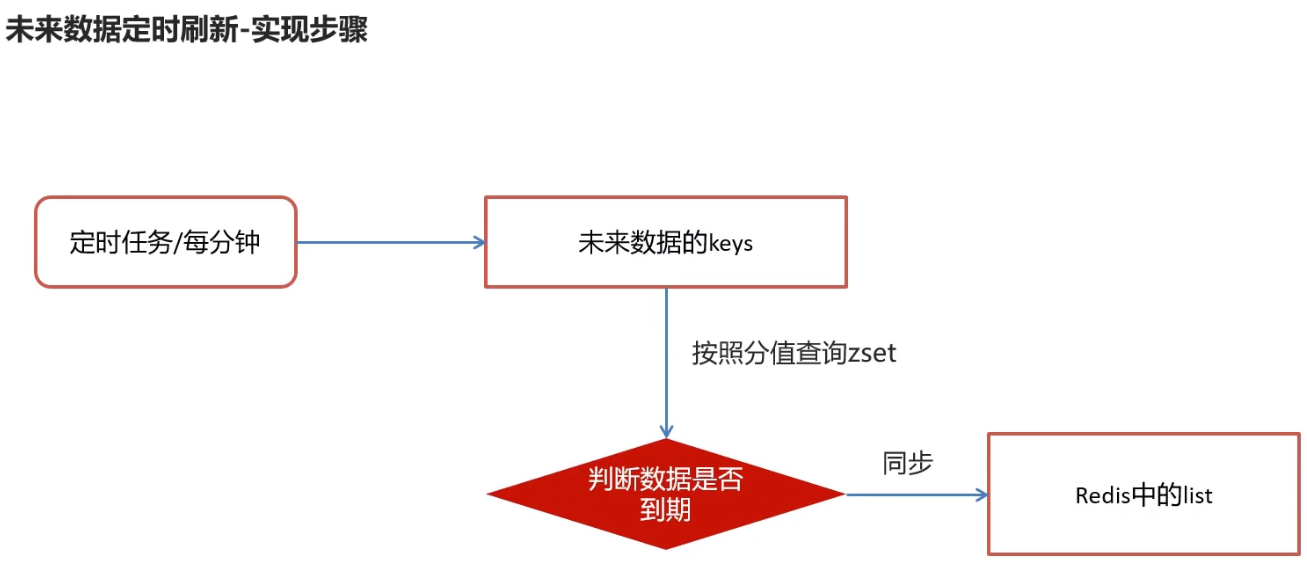
4.8.1)reids key值匹配
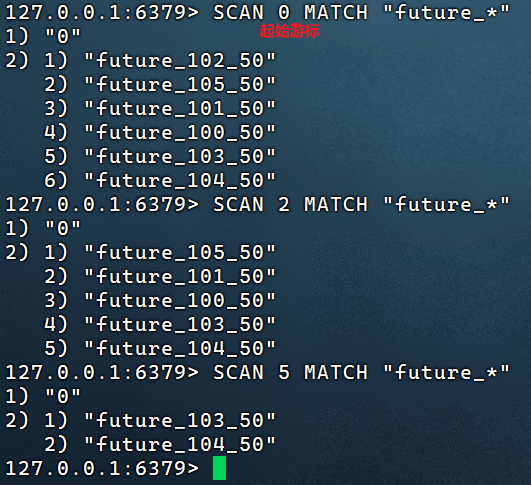
要判断数据是否到期,首先得获取zset中所有的key,然后遍历才能得到,那么问题来了:如何获取redis中zset的所有的key呢
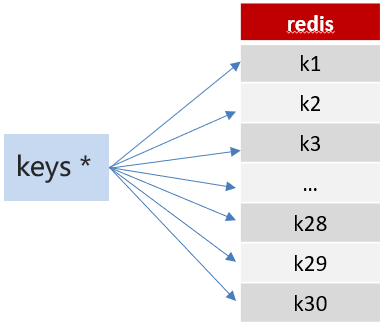
方案1:keys 模糊匹配
keys的模糊匹配功能很方便也很强大,但是在生产环境需要慎用!开发中使用keys的模糊匹配却发现redis的CPU使用率极高,所以公司的redis生产环境将keys命令禁用了!redis是单线程,会被堵塞
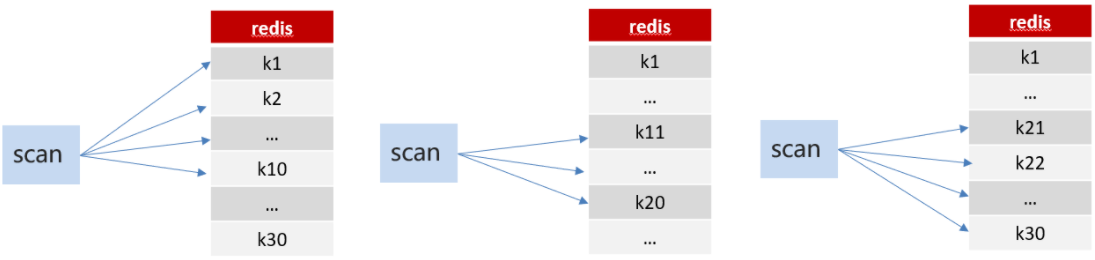
方案2:scan ★
SCAN 命令是一个基于游标的迭代器,SCAN命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为SCAN命令的游标参数, 以此来延续之前的迭代过程。
代码案例:
先执行这个新建一些任务
@Test void addTasks() { Task task = new Task(); task.setTaskType(100); task.setPriority(50); task.setParameters("task test".getBytes()); for (int i = 101; i <= 105; i++) { task.setTaskType(i); task.setExecuteTime(System.currentTimeMillis() + 500); task.setTaskId(null);//写db时不能有id long taskId = taskService.addTask(task); System.out.println("taskId = " + taskId); } }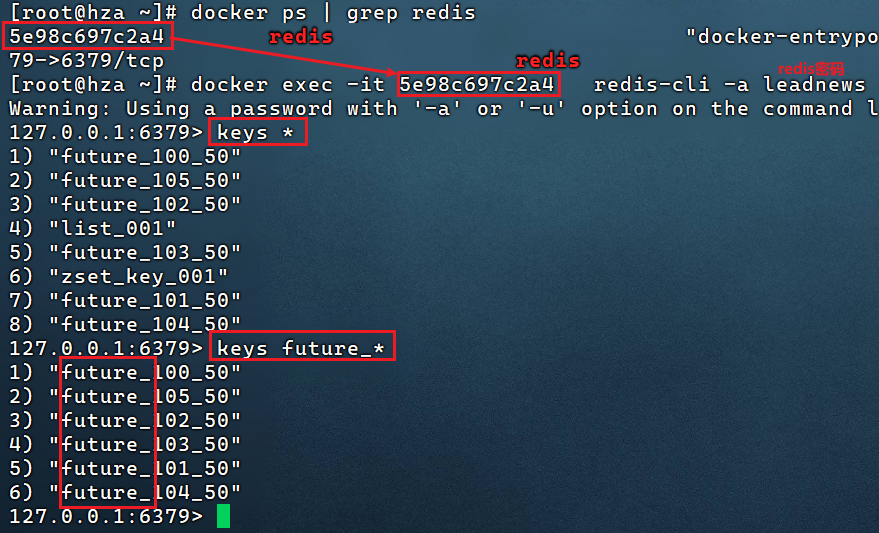
再执行下面查询keys
@Test public void testKeys(){ Set<String> keys = cacheService.keys("future_*"); System.out.println(keys); Set<String> scan = cacheService.scan("future_*"); // 一般情况下都用scan System.out.println(scan); }
4.8.2)reids管道
普通redis客户端和服务器交互模式
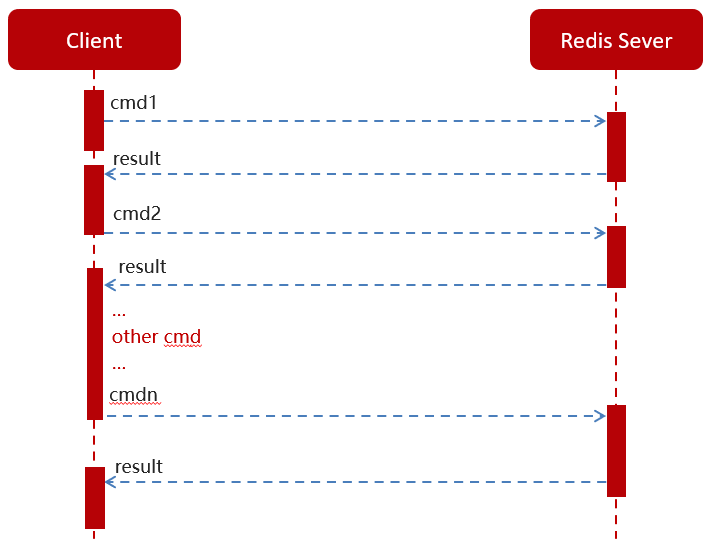
1.上面的方式就是一条条地查,然后一条条地写redis,就是每个命令单独执行,可以,但是数据量大时效率会非常低,需要经常与redis建立连接。 (客户端每执行一条命令肯定是要与服务端建立一次连接的)
2.特点:每执行一条命令,服务端都返回一次结果
3.为了解决效率问题,redis提供了管道请求模型Pipeline请求模型
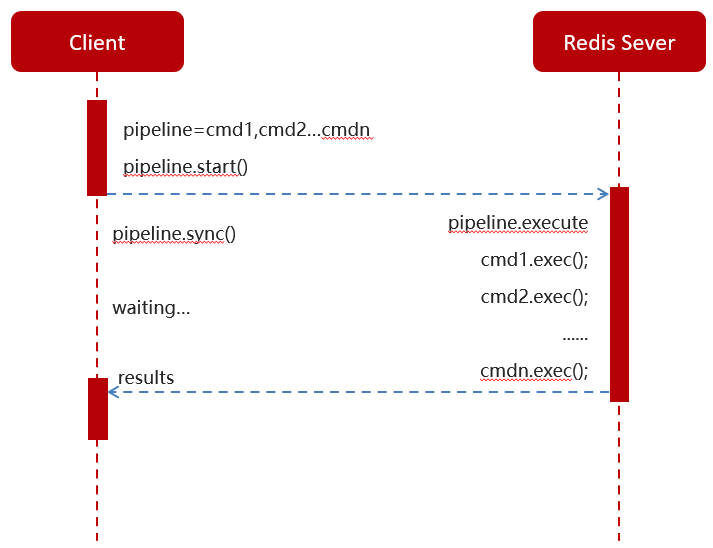
管道模式下,会将发送的命令存放到管道,待所有命令执行完毕,服务端再统一返回一次结果。效率大大增加了!!
官方测试结果数据对比
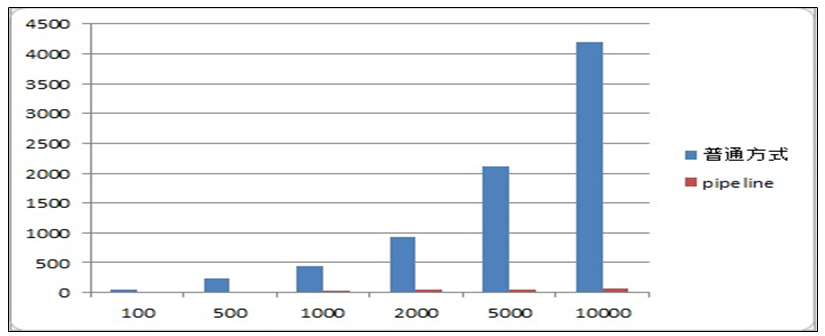
测试案例对比:
//耗时4864 @Test public void testPipe1(){ long start =System.currentTimeMillis(); for (int i = 0; i <10000 ; i++) { Task task = new Task(); task.setTaskType(1001); task.setPriority(1); task.setExecuteTime(new Date().getTime()); // 只push到list中 redis的一个list中(一个队列中新增1w条数据) cacheService.lLeftPush("1001_1", JSON.toJSONString(task)); } System.out.println("耗时"+(System.currentTimeMillis()- start));//耗时4864 } // 642毫秒 @Test public void testPipe2(){ long start = System.currentTimeMillis(); //使用管道技术 List<Object> objectList = cacheService.getstringRedisTemplate().executePipelined(new RedisCallback<Object>() { @Nullable @Override public Object doInRedis(RedisConnection redisConnection) throws DataAccessException { for (int i = 0; i <10000 ; i++) { Task task = new Task(); task.setTaskType(1001); task.setPriority(1); task.setExecuteTime(new Date().getTime()); redisConnection.lPush("1001_1".getBytes(), JSON.toJSONString(task).getBytes()); } return null; } }); System.out.println("使用管道技术执行10000次自增操作共耗时:"+(System.currentTimeMillis()-start)+"毫秒"); // 使用管道技术执行10000次自增操作共耗时:642毫秒 }同样10000条数据,管道只需642ms,而普通的命令方式却需要4864ms,管道快了7.6倍
4.8.3)未来数据定时刷新-功能完成
在TaskService中添加方法
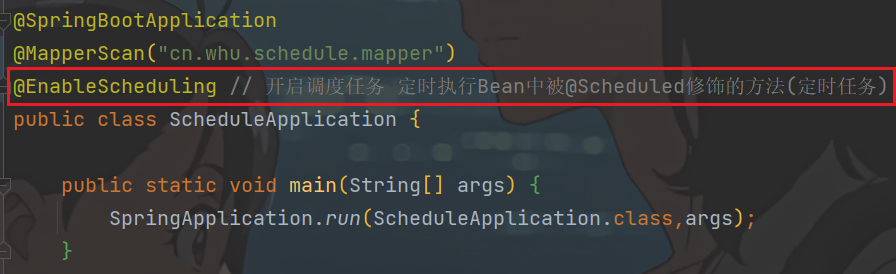
/** * 未来数据定时刷新 * * @Scheduled注解就是任务调度注解 括号内容配置的含义就是每分钟执行1次 * @Scheduled修饰的定时方法必须是无参且无返回值的方法 */ @Scheduled(cron = "0 */1 * * * ?") public void refresh() { log.info("未来数据定时刷新---定时任务"); // 获取所有未来数据的keys (就zset未来任务所有队列名称) Set<String> futureKeys = cacheService.scan(ScheduleConstants.FUTURE + "*"); for (String futureKey : futureKeys) { // 获取当前任务到list执行队列后的key String topicKey = ScheduleConstants.TOPIC + futureKey.substring("future_".length()); // futureKey: future_100_50 // topicKey: topic_100_50 // 按照key和分值查询符合条件的数据 // 0~当前时间的分数范围内查找 其实就是查(futureKey队列中)小于当前时间的记录 Set<String> tasks = cacheService.zRangeByScore(futureKey, 0, System.currentTimeMillis()); // 同步数据 (futureKey队的数据) if (!tasks.isEmpty()) { // 将数据tasks,从futureKey,移动到,topicKey cacheService.refreshWithPipeline(futureKey, topicKey, tasks); log.info("成功地将 {} 刷新到 {}, 本次共刷新 {} 个任务", futureKey, topicKey, tasks.size()); } } }在引导类中添加开启任务调度注解:
@EnableScheduling
- 测试
先确保redis中有future数据 (没有就用上面的测试类添加)
然后启动ScheduleApplication即可
Tue Jun 18 22:44:45 CST 2024 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. 2024-06-18 22:45:00.024 INFO 20188 --- [ scheduling-1] c.h.s.service.impl.TaskServiceImpl : 未来数据定时刷新---定时任务 2024-06-18 22:45:00.134 INFO 20188 --- [ scheduling-1] c.h.s.service.impl.TaskServiceImpl : 成功地将 future_104_50 刷新到 topic_104_50, 本次共刷新 1 个任务 2024-06-18 22:45:00.156 INFO 20188 --- [ scheduling-1] c.h.s.service.impl.TaskServiceImpl : 成功地将 future_102_50 刷新到 topic_102_50, 本次共刷新 1 个任务 2024-06-18 22:45:00.163 INFO 20188 --- [ scheduling-1] c.h.s.service.impl.TaskServiceImpl : 成功地将 future_105_50 刷新到 topic_105_50, 本次共刷新 1 个任务 2024-06-18 22:45:00.169 INFO 20188 --- [ scheduling-1] c.h.s.service.impl.TaskServiceImpl : 成功地将 future_103_50 刷新到 topic_103_50, 本次共刷新 1 个任务 2024-06-18 22:45:00.176 INFO 20188 --- [ scheduling-1] c.h.s.service.impl.TaskServiceImpl : 成功地将 future_101_50 刷新到 topic_101_50, 本次共刷新 1 个任务 2024-06-18 22:45:00.181 INFO 20188 --- [ scheduling-1] c.h.s.service.impl.TaskServiceImpl : 成功地将 future_100_50 刷新到 topic_100_50, 本次共刷新 1 个任务 2024-06-18 22:46:00.004 INFO 20188 --- [ scheduling-1] c.h.s.service.impl.TaskServiceImpl : 未来数据定时刷新---定时任务
4.9)分布式锁解决集群下的方法抢占执行
4.9.1)问题描述
启动两台heima-leadnews-schedule服务,每台服务都会去执行refresh定时任务方法

- 测试,同一个微服务启动两次
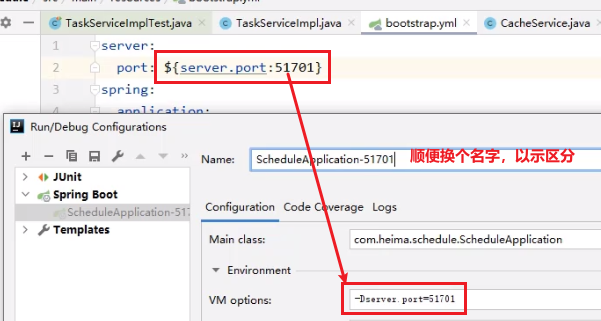
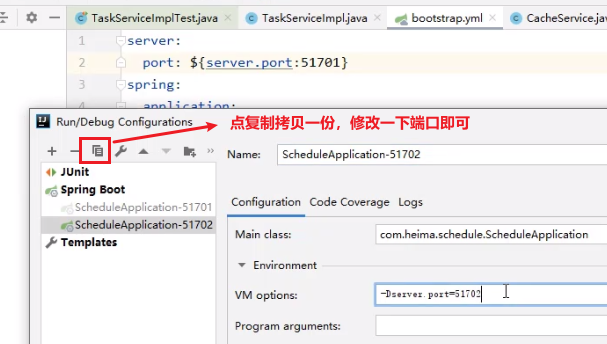
参数名最好换成别的,不然容易导致循环引用问题:
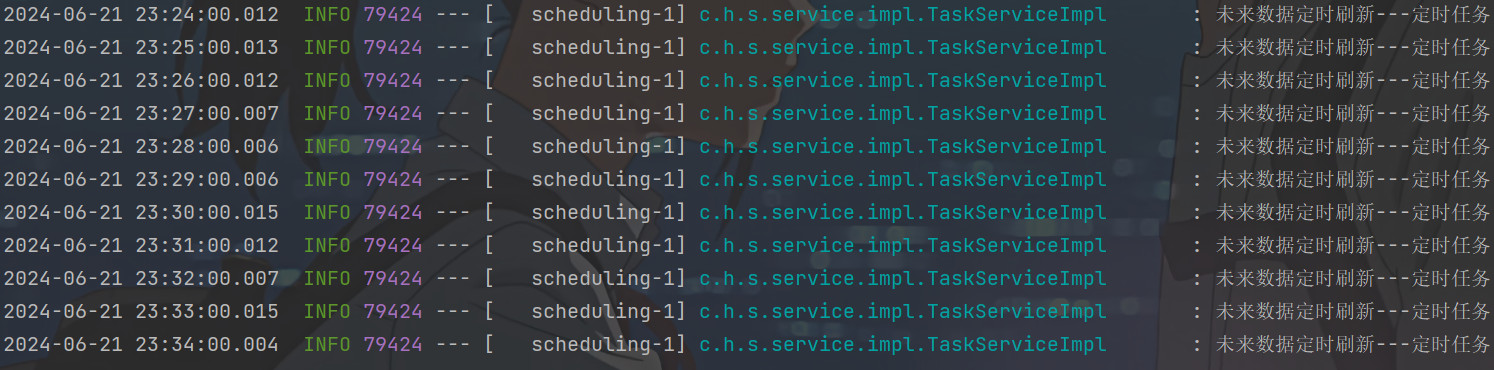
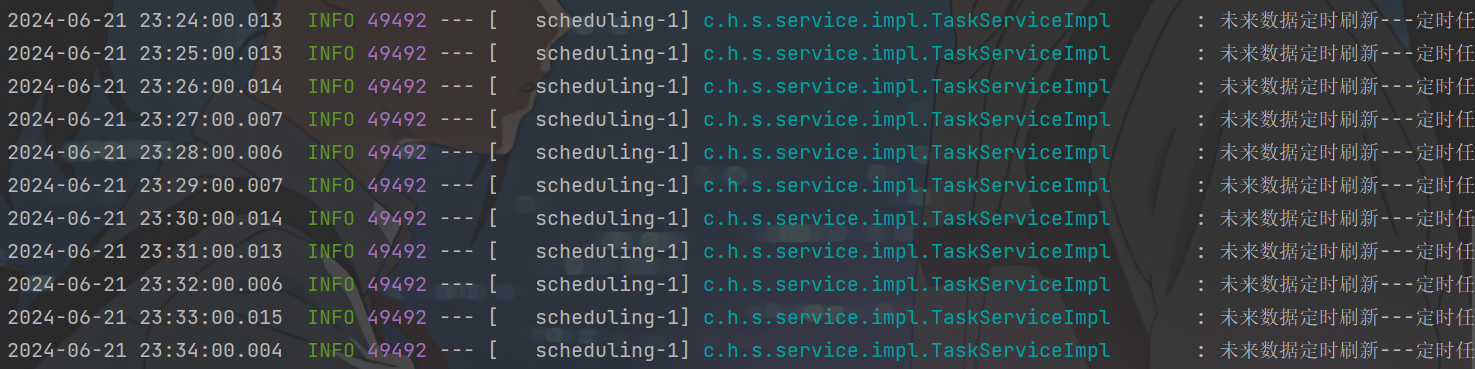
可以看到同一时刻完全相同的操作4.9.2)分布式锁
分布式锁:控制分布式系统有序的去对共享资源进行操作,通过互斥来保证数据的一致性。
解决方案:

4.9.3)redis分布式锁
sexnx (SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值。

这种加锁的思路是,如果 key 不存在则为 key 设置 value,如果 key 已存在则 SETNX 命令不做任何操作
- 客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
- 客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
- 客户端A执行代码完成,删除锁
- 客户端B在等待一段时间后再去请求设置key的值,设置成功
- 客户端B执行代码完成,删除锁
4.9.4)在工具类CacheService中添加方法
heima-leadnews-common模块的cn.whu.common.redis.CacheService
/** * 加锁 * * @param name * @param expire * @return */ public String tryLock(String name, long expire) { name = name + "_lock"; String token = UUID.randomUUID().toString(); RedisConnectionFactory factory = stringRedisTemplate.getConnectionFactory(); RedisConnection conn = factory.getConnection(); try { //参考redis命令: //set key value [EX seconds] [PX milliseconds] [NX|XX] Boolean result = conn.set( name.getBytes(), token.getBytes(), Expiration.from(expire, TimeUnit.MILLISECONDS), RedisStringCommands.SetOption.SET_IF_ABSENT //NX ); if (result != null && result) return token; } finally { RedisConnectionUtils.releaseConnection(conn, factory,false); } return null; }修改未来数据定时刷新的方法,如下:
/** * 加锁 * * @param name * @param expire * @return */ public String tryLock(String name, long expire) { name = name + "_lock"; String token = UUID.randomUUID().toString(); RedisConnectionFactory factory = stringRedisTemplate.getConnectionFactory(); RedisConnection conn = factory.getConnection(); try { //参考redis命令: //set key value [EX seconds] [PX milliseconds] [NX|XX] Boolean result = conn.set( name.getBytes(), token.getBytes(), Expiration.from(expire, TimeUnit.MILLISECONDS),//规定时间内不释放锁,保证同一时刻只有一个能加锁成功 RedisStringCommands.SetOption.SET_IF_ABSENT //NX ); if (result != null && result) return token; } finally { RedisConnectionUtils.releaseConnection(conn, factory,false); } return null; }重启ScheduleApplication的两个实例
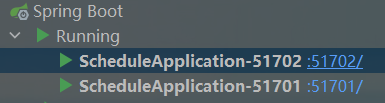


(schedule设置的是每分钟执行一次,setNx之前是多个微服务一起执行,现在是严格交叉执行了,每分钟内只有一个实例抢占到锁,执行refresh,这种事儿也确实同一时刻执行一次就够了嘛)- 小结:

4.10)数据库同步到redis
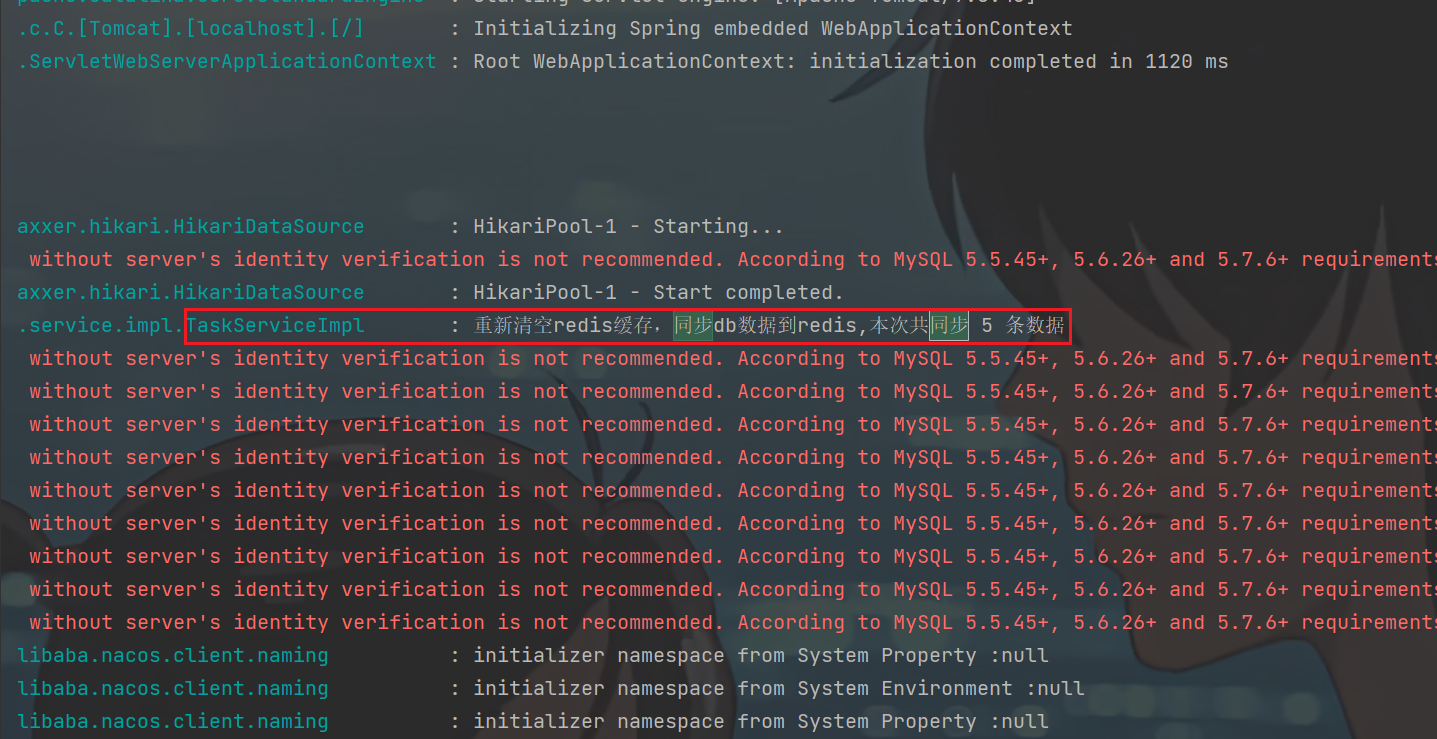
定时同步模块。DB–》redis/** * 数据库任务定时同步到redis中 */ @PostConstruct // 微服务启动时会立即执行一次 (防止服务挂掉后重启不能立即同步) @Scheduled(cron = "0 */5 * * * ?") // 每5分钟执行一次 public void reloadData() { // 清理缓存中的数据 list zset (db里面重新同步最近的数据到redis 原来的redis缓存可以都不要了) clearCache(); // 查询符合条件的任务 // 先获取5分钟后的时间实例 Calendar calendar = Calendar.getInstance(); calendar.add(Calendar.MINUTE, 5); // calendar类很方便就能实现 // long ms = calendar.getTimeInMillis(); // ms值 // Date date = calendar.getTime(); // date日期值 // 把任务添加到redis List<Taskinfo> taskinfoList = taskinfoMapper.selectList(Wrappers.<Taskinfo>lambdaQuery() .lt(Taskinfo::getExecuteTime, calendar.getTime()) ); // 把任务添加到redis if (taskinfoList != null && taskinfoList.size() > 0) { // !!! 安全性呀 for (Taskinfo taskinfo : taskinfoList) { Task task = new Task(); BeanUtils.copyProperties(taskinfo, task); task.setExecuteTime(taskinfo.getExecuteTime().getTime()); addTaskToCache(task); } } log.info("重新清空redis缓存,同步db数据到redis,本次共同步 {} 条数据", taskinfoList.size()); } /** * 清理缓存(redis)中的数据 */ public void clearCache() { Set<String> topicKeys = cacheService.scan(ScheduleConstants.TOPIC + "*"); Set<String> futureKeys = cacheService.scan(ScheduleConstants.FUTURE + "*"); cacheService.delete(topicKeys); cacheService.delete(futureKeys); }- 测试:
先执行上面的addTasks测试方法,往db里面新增一些任务(会自动同步到redis,需要手动删了)
执行之前可以先清空一下db和redis

@Test void addTasks() { Task task = new Task(); task.setTaskType(100); task.setPriority(50); task.setParameters("task test".getBytes()); for (int i = 101; i <= 105; i++) { task.setTaskType(i); task.setExecuteTime(System.currentTimeMillis() + 500); task.setTaskId(null);//写db时不能有id long taskId = taskService.addTask(task); System.out.println("taskId = " + taskId); } }taskInfo表:
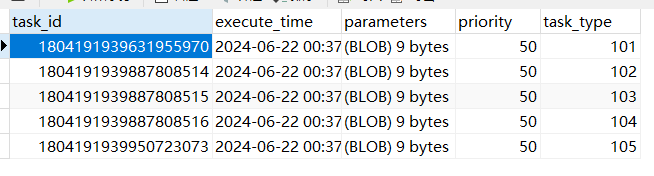
redis:
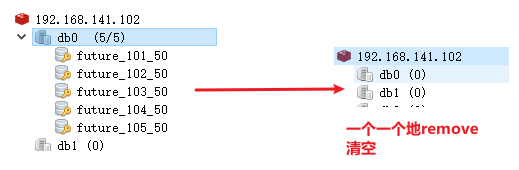
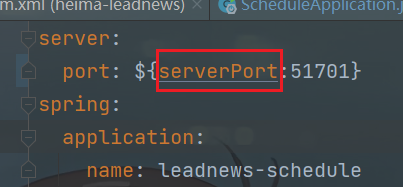
重启schdule微服务,一个即可(server.port可能得改成serverPort)
微服务初始化时就执行了这个方法:
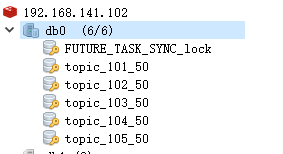
topic是因为这个:

5)延迟队列解决精准时间发布文章
5.1)延迟队列服务提供对外接口
提供远程的feign接口,在heima-leadnews-feign-api编写类如下:
package cn.whu.apis.schedule; import cn.whu.model.common.dtos.ResponseResult; import cn.whu.model.schedule.dtos.Task; import org.springframework.cloud.openfeign.FeignClient; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestBody; @FeignClient(value = "leadnews-schedule") // 也可以加个fallback吧 public interface IScheduleClient { /** * 添加任务 * @param task 任务对象 * @return 任务id long */ @PostMapping("/api/v1/task/add") public ResponseResult addTask(@RequestBody Task task) ; /** * 取消任务 * @param task 任务对象 * @return 取消成功还是失败 boolean */ @GetMapping("/api/v1/task/{taskId}") public ResponseResult cancelTask(@PathVariable("taskId") long taskId); /** * 按照类型和优先级拉取任务 * 类型+优先级 -》 确定任务队列 * @param type * @param priority * @return Task */ @GetMapping("/api/v1/task/{type}/{priority}") public ResponseResult poll(@PathVariable("type") int type,@PathVariable("priority") int priority); }在heima-leadnews-schedule微服务下提供对应的实现
package cn.whu.schedule.feign; import cn.whu.apis.schedule.IScheduleClient; import cn.whu.model.common.dtos.ResponseResult; import cn.whu.model.schedule.dtos.Task; import cn.whu.schedule.service.TaskService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.*; @RestController public class ScheduleClient implements IScheduleClient { @Autowired private TaskService taskService; /** * 添加任务 * @param task 任务对象 * @return 任务id */ @PostMapping("/api/v1/task/add") @Override public ResponseResult addTask(@RequestBody Task task) { return ResponseResult.okResult(taskService.addTask(task)); } /** * 取消任务 * @param taskId 任务id * @return 取消结果 */ @GetMapping("/api/v1/task/cancel/{taskId}") @Override public ResponseResult cancelTask(@PathVariable("taskId") long taskId) { return ResponseResult.okResult(taskService.cancelTask(taskId)); } /** * 按照类型和优先级来拉取任务 * @param type * @param priority * @return */ @GetMapping("/api/v1/task/poll/{type}/{priority}") @Override public ResponseResult poll(@PathVariable("type") int type, @PathVariable("priority") int priority) { return ResponseResult.okResult(taskService.poll(type,priority)); } }test中已经测试过,这里就不再测试接口了,远程接口的提供到这就完成了
5.2)发布文章集成添加延迟队列接口
再创建WmNewsTaskService
heima-leadnews-wemedia模块的cn.whu.wemedia.service包下
package cn.whu.wemedia.service; import java.util.Date; public interface WmNewsTaskService { /** * 添加任务到延迟队列中 * @param id 文章的id * @param publishTime 发布时间 可以作为任务的执行时间 */ public void addNewsToTask(Integer id, Date publishTime); }实现:
package cn.whu.wemedia.service.impl; import cn.whu.apis.schedule.IScheduleClient; import cn.whu.model.common.enums.TaskTypeEnum; import cn.whu.model.schedule.dtos.Task; import cn.whu.model.wemedia.pojos.WmNews; import cn.whu.utils.common.ProtostuffUtil; import cn.whu.wemedia.service.WmNewsService; import cn.whu.wemedia.service.WmNewsTaskService; import lombok.extern.slf4j.Slf4j; import org.springframework.scheduling.annotation.Async; import org.springframework.stereotype.Service; import javax.annotation.Resource; import java.util.Date; @Service @Slf4j public class WmNewsTaskServiceImpl implements WmNewsTaskService { @Resource private IScheduleClient scheduleClient; @Resource private WmNewsService wmNewsService; /** * 添加任务到延迟队列中 * * @param id 文章的id * @param publishTime 发布时间 可以作为任务的执行时间 */ @Override @Async public void addNewsToTask(Integer id, Date publishTime) { log.info("添加任务到到延迟服务中------begin"); // 1. 封装task Task task = new Task(); task.setExecuteTime(publishTime.getTime()); task.setTaskType(TaskTypeEnum.NEWS_SCAN_TIME.getTaskType()); task.setPriority(TaskTypeEnum.NEWS_SCAN_TIME.getPriority()); // 参数比较麻烦,本来传id就行了,但是需要一个序列化对象 WmNews wmNews = new WmNews(); wmNews.setId(id); task.setParameters(ProtostuffUtil.serialize(wmNews)); // 2. feign接口调用定时任务,添加任务到db和redis scheduleClient.addTask(task); log.info("添加任务到到延迟服务中------end"); } }枚举类:
heima-leadnews-model模块下package cn.whu.model.common.enums; import lombok.AllArgsConstructor; import lombok.Getter; @Getter @AllArgsConstructor public enum TaskTypeEnum { NEWS_SCAN_TIME(1001, 1,"文章定时审核"), REMOTE_ERROR(1002, 2,"第三方接口调用失败,重试"); private final int taskType; //对应具体业务 private final int priority; //业务不同级别 private final String desc; //描述信息 }序列化工具对比
- JdkSerialize:java内置的序列化能将实现了Serilazable接口的对象进行序列化和反序列化, ObjectOutputStream的writeObject()方法可序列化对象生成字节数组
- Protostuff:google开源的protostuff采用更为紧凑的二进制数组,表现更加优异,然后使用protostuff的编译工具生成pojo类
拷贝资料中的两个类到heima-leadnews-utils下
拷贝到:heima-leadnews-utils的cn.whu.utils.common包下面Protostuff需要引导依赖:heima-leadnews-utils下的pom.xml
<dependency> <groupId>io.protostuffgroupId> <artifactId>protostuff-coreartifactId> <version>1.6.0version> dependency> <dependency> <groupId>io.protostuffgroupId> <artifactId>protostuff-runtimeartifactId> <version>1.6.0version> dependency>比较:
/** * jdk序列化与protostuff序列化对比 * @param args */ public static void main(String[] args) { long start =System.currentTimeMillis(); for (int i = 0; i <1000000 ; i++) { WmNews wmNews =new WmNews(); JdkSerializeUtil.serialize(wmNews); } System.out.println(" jdk 花费 "+(System.currentTimeMillis()-start)); start =System.currentTimeMillis(); for (int i = 0; i <1000000 ; i++) { WmNews wmNews =new WmNews(); ProtostuffUtil.serialize(wmNews); } System.out.println(" protostuff 花费 "+(System.currentTimeMillis()-start)); }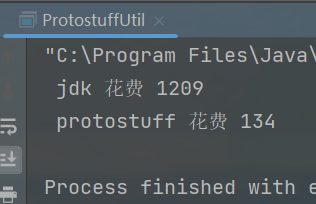
修改发布文章代码:
把之前的异步调用修改为调用延迟任务
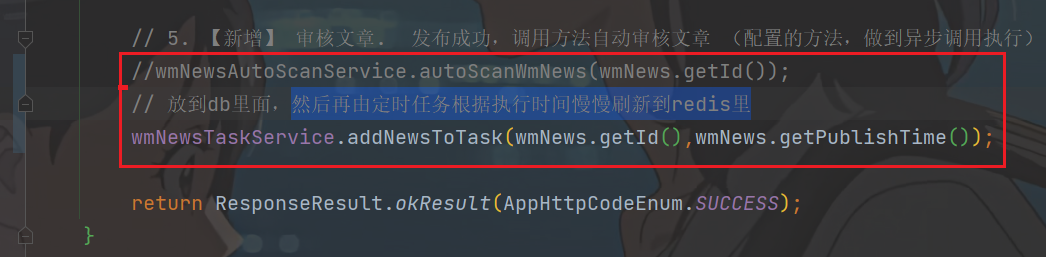
heima-leadnews-wemedia模块的cn.whu.wemedia.service.impl.WmNewsServiceImpl#submitNews方法
@Autowired private WmNewsTaskService wmNewsTaskService; /** * 发布修改文章或保存为草稿 * @param dto * @return */ @Override public ResponseResult submitNews(WmNewsDto dto) { //0.条件判断 if(dto == null || dto.getContent() == null){ return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID); } //1.保存或修改文章 WmNews wmNews = new WmNews(); //属性拷贝 属性名词和类型相同才能拷贝 BeanUtils.copyProperties(dto,wmNews); //封面图片 list---> string if(dto.getImages() != null && dto.getImages().size() > 0){ //[1dddfsd.jpg,sdlfjldk.jpg]--> 1dddfsd.jpg,sdlfjldk.jpg String imageStr = StringUtils.join(dto.getImages(), ","); wmNews.setImages(imageStr); } //如果当前封面类型为自动 -1 if(dto.getType().equals(WemediaConstants.WM_NEWS_TYPE_AUTO)){ wmNews.setType(null); } saveOrUpdateWmNews(wmNews); //2.判断是否为草稿 如果为草稿结束当前方法 if(dto.getStatus().equals(WmNews.Status.NORMAL.getCode())){ return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS); } //3.不是草稿,保存文章内容图片与素材的关系 //获取到文章内容中的图片信息 List<String> materials = ectractUrlInfo(dto.getContent()); saveRelativeInfoForContent(materials,wmNews.getId()); //4.不是草稿,保存文章封面图片与素材的关系,如果当前布局是自动,需要匹配封面图片 saveRelativeInfoForCover(dto,wmNews,materials); //审核文章 // wmNewsAutoScanService.autoScanWmNews(wmNews.getId()); // 放到db里面,然后再由定时任务根据执行时间慢慢刷新到redis里 wmNewsTaskService.addNewsToTask(wmNews.getId(),wmNews.getPublishTime()); return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS); }
- 测试1:
启动ScheduleApplication、WemediaApplication、WemediaGatewayApplication
先清空schedule库的两个表,和redis,然后新增新闻
http://localhost:8802/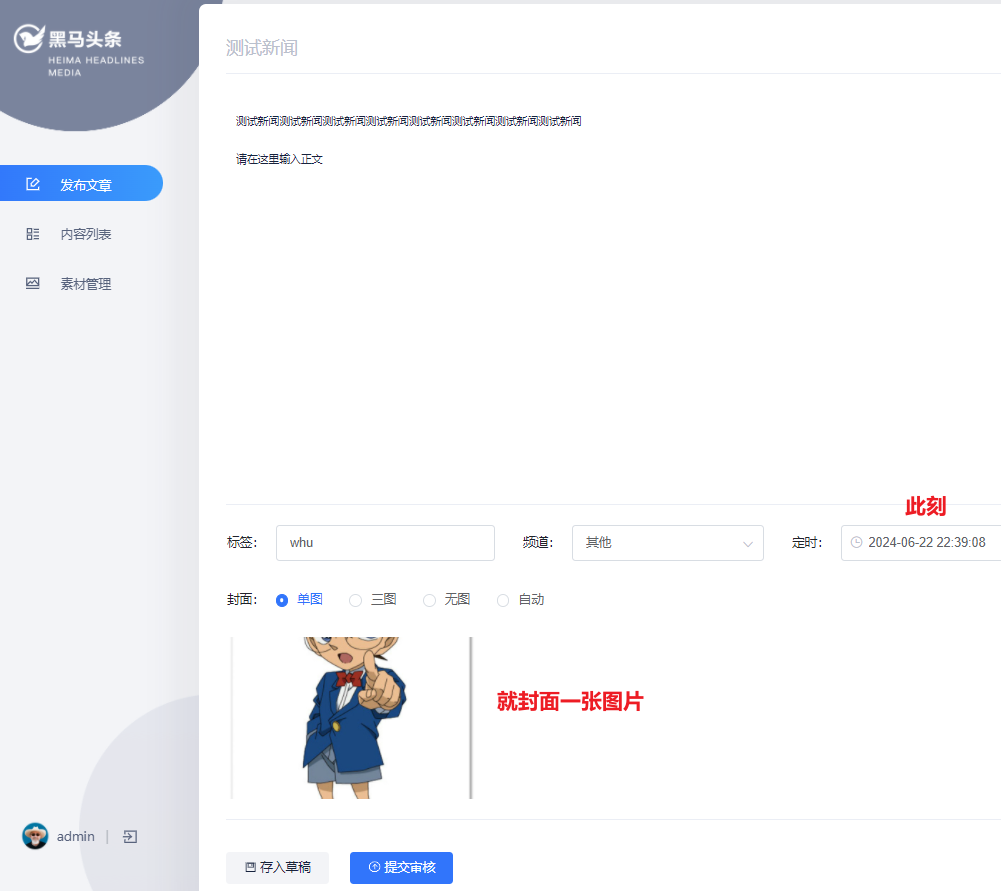
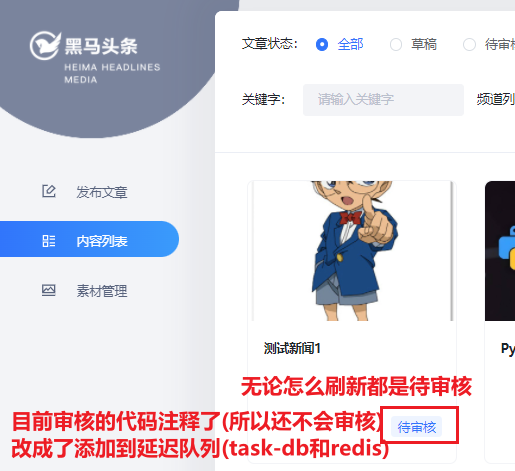
提交完新闻后,会feign远程调用到schedule的微服务的addTask方法(全放入db,最近的一部分放到redis缓存)

于是添加完毕查看db:


和redis
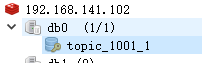
任务虽然没有审核,但都存在db或redis中了,不着急,后面可以慢慢来写审核代码,任务丢不掉的- 测试2:
http://localhost:8802/
再发布两篇文章,1)一个未来6分钟,2)一个未来3分钟,而不是此刻
1)会只有db中新增记录,redis不会
2)会db中新增记录,redis新增future记录
topic是当前就可以消费的任务,future是未来5分钟之内待要消费的任务。
1)

2)
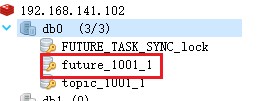
到时间后再看redis,future会刷新到topic中
5.3)消费任务进行审核文章
现在审核文章的任务都已经缓存到db或redis中啦,下面就得扫描redis消费这些任务,进行文章审核啦
heima-leadnews-wemedia模块下
WmNewsTaskService中添加方法
/** * 消费延迟队列数据 */ public void scanNewsByTask();实现
@Autowired private WmNewsAutoScanServiceImpl wmNewsAutoScanService; /** * 消费延迟队列数据 * 定时自动执行的任务 */ @Override @Scheduled(fixedRate = 1000) // 每秒执行一次 public void scanNewsByTask() { log.info("文章审核---消费任务执行---begin---"); ResponseResult responseResult = scheduleClient.poll( TaskTypeEnum.NEWS_SCAN_TIME.getTaskType(), TaskTypeEnum.NEWS_SCAN_TIME.getPriority() ); if (responseResult.getCode().equals(200) && responseResult.getData() != null) { // responseResult.getData()返回类型是T,强转不合适,用json转 String jsonString = JSON.toJSONString(responseResult.getData()); Task task = JSON.parseObject(jsonString, Task.class); WmNews wmNews = ProtostuffUtil.deserialize(task.getParameters(), WmNews.class); wmNewsAutoScanService.autoScanWmNews(wmNews.getId()); log.info("文章审核----文章id:{}", wmNews.getId()); } log.info("文章审核---消费任务执行---end---"); }在WemediaApplication自媒体的引导类中添加开启任务调度注解
@EnableScheduling- 测试
启动ScheduleApplication、WemediaApplication、WemediaGatewayApplication、ArticleApplication
1)发布文章,定时选择此刻,刷新自动审核,显示已上架
2)发布文章,定时修改为1分钟以后,刷新不自动上架,1分钟后才会上架对于2)可以查看日志:


-
相关阅读:
逻辑漏洞----权限类漏洞
多线程与高并发(二)—— Synchronized 加锁解锁流程
【面经】2022社招软件测试面试(6)-德科
Github2024-04-25 开源项目日报Top10
电脑怎么设置定时关机?
上机实验四 图的最小生成树算法设计 西安石油大学数据结构
【WEEK15】学习目标及总结【Spring Boot】【中文版】
【c#】委托
paddleocr检测模型训练记录
【文件上传漏洞绕过方式】
- 原文地址:https://blog.csdn.net/hza419763578/article/details/139744164