-
Python学习打卡:day11
day11
笔记来源于:黑马程序员python教程,8天python从入门到精通,学python看这套就够了
目录
83、自定义 Python 包
如果Python的模块太多了,就可能造成一定的混乱,那么就需要通过Python包的功能来管理。
从物理上看,包就是一个文件夹,在该文件夹下包含了一个
__init__.py文件,该文件夹可用于包含多个模块文件;从逻辑上看,包的本质依然是模块。
创建包
构建包的步骤如下:
-
新建包
my_package;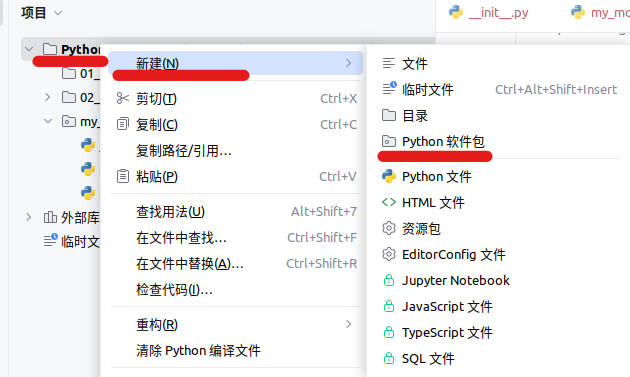
-
新建包内模块:
my_module1和my_module2; -
模块内代码如下:
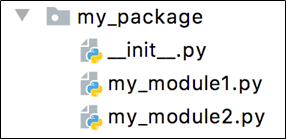


tips:新建包后,包内部会自动创建
__init__.py文件,这个文件控制着包的导入行为。导入包
方式1
import 包名.模块名 包名.模块名.目标示例代码:
import my_package_83.my_module1_83 import my_package_83.my_module2_83 my_package_83.my_module1_83.info_print1() my_package_83.my_module2_83.info_print2()方式2
from 包名 import 模块名 模块名.目标示例代码:
from my_package_83 import my_module1_83 from my_package_83 import my_module2_83 my_module1_83.info_print1() my_module2_83.info_print2()方式3
from 包名.模块名 import 目标 目标示例代码:
from my_package_83.my_module1_83 import info_print1 from my_package_83.my_module2_83 import info_print2 info_print1() info_print2()方式4
from 包名 import * 模块名.目标示例代码:
# 通过 __all__ 变量,控制 import* from my_package_83 import * my_module1_83.info_print1() # error,__init__.py 文件中设置了 __all__ 只导入:my_module1_83,因此 my_module2_83 不管用 # my_module2_83.info_print2()tips:必须在
__init__.py文件中添加__all__ = [],控制允许导入的模块列表84、安装第三方包
在Python程序的生态中,有许多非常多的第三方包(非Python官方),可以极大的帮助我们提高开发效率,如:
- 科学计算中常用的:numpy包
- 数据分析中常用的:pandas包
- 大数据计算中常用的:pyspark、apache-flink包
- 图形可视化常用的:matplotlib、pyecharts
- 人工智能常用的:tensorflow
- 等
但是由于是第三方,所以Python没有内置,所以我们需要安装它们才可以导入使用。
安装第三方包——pip
第三方包的安装非常简单,我们只需要使用Python内置的pip程序即可。
打开我们许久未见的:命令提示符程序,在里面输入:
pip install 包名称即可通过网络快速安装第三方包。
pip的网络优化
由于pip是连接的国外的网站进行包的下载,所以有的时候会速度很慢。
我们可以通过如下命令,让其连接国内的网站进行包的安装:
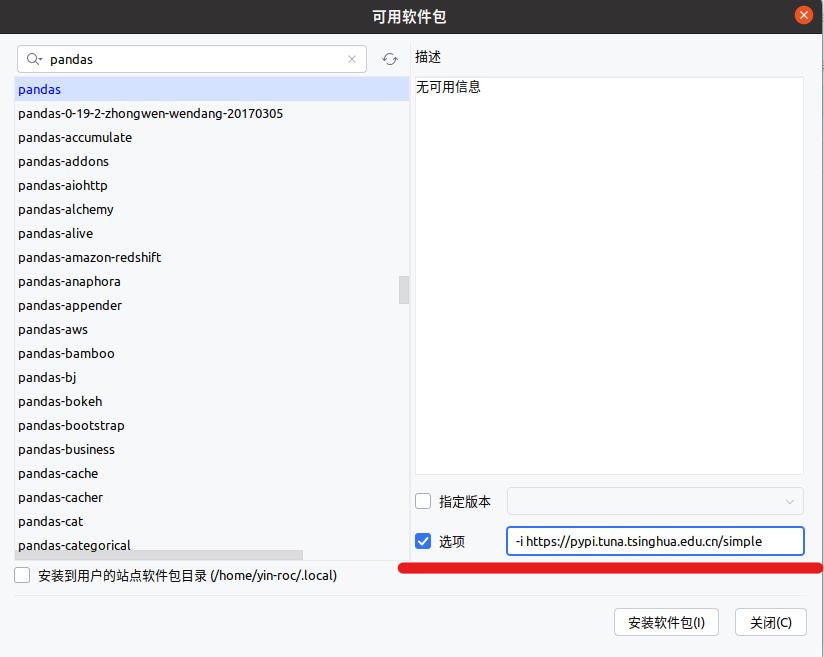
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称安装第三方包——PyCharm

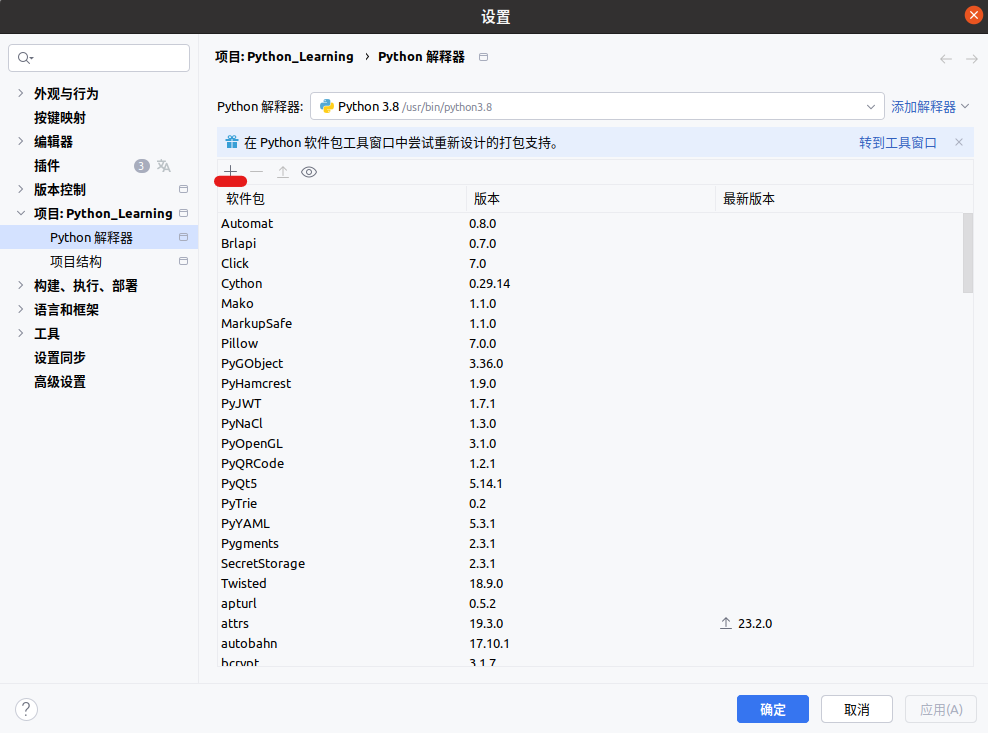
同样使用国内清华镜像源进行下载:
85、异常—模块—包综合案例

模块1
自写
# 自写 def str_reverse(s): str = "" for element in s: str = element + str return str def substr(s, x, y): str1 = "" str2 = "" str3 = "" list = [] i = 0 if x > y: tmp = x x = y y = tmp while i < x: str1 += s[i] i += 1 list.append(str1) while i < y: str2 += s[i] i += 1 list.append(str2) while i < len(s): str3 += s[i] i += 1 list.append(str3) return list if __name__ == '__main__': # print(f"{str_reverse(' hello world ')}") print(f"{substr('helloworld', 1, 3)}")视频写法
# 视频写法 def str_reverse(s): """ 功能:反转字符串 :param s: 将被反转的字符串 :return: 反转后的字符串 """ return s[::-1] def substr(s, x, y): """ 功能:按照给定的下标完成字符串的切片 :param s: 即将被切片的字符串 :param x: 切片的开始下标 :param y: 切片的结束下标 :return: 切片完成后的字符串 """ return s[x:y] if __name__ == '__main__': print(str_reverse("黑马程序员")) print(substr("黑马程序员", 1, 3))模块2
自写
def print_file_info(file_name): try: f = open(file_name, "r", encoding="UTF-8") print(f"文件存在,读取的内容为:\n{f.read()}") except: print("文件不存在") finally: f.close() def append_to_file(filename, data): f = open(filename, "a", encoding="UTF-8") f.write(data) f.close() if __name__ == '__main__': # print_file_info("/home/yin-roc/1-Github/Ubuntu20.04-VMware/pythonProject/Python_Learning/02_Python入门语法/74_test.txt") append_to_file("84_test.txt", "helloworld")视频写法
def print_file_info(file_name): """ 功能: 将指定路径的文件内容输出到控制台 :param file_name: 即将读取文件的路径 :return: None """ f = None try: f = open(file_name, "r", encoding="UTF-8") content = f.read() print("文件内容如下:") print(content) except Exception as e: print(f"程序出现异常,原因是:{e}") finally: if f: f.close() def append_to_file(filename, data): """ 功能:将指定的数据追加到指定的文件中 :param filename: 指定文件的路径 :param data: 指定的数据 :return: None """ f = open(filename, "a", encoding="UTF-8") f.write(data) f.write("\n") f.close() if __name__ == '__main__': # print_file_info("84_test.txt") append_to_file("84_test.txt", "good")总结
-
函数写法的规范要记得,包括函数功能的描述、参数的解释
-
字符串的切片操作除了
split,还有:my_str = "01234567" result4 = my_str[::-1]
86、JSON数据格式的转换
基础概念
JSON是一种轻量级的数据交互格式。可以按照JSON指定的格式去组织和封装数据。
JSON本质上是一个带有特定格式的字符串
主要功能:json就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互。
各种编程语言存储数据的容器不尽相同,在Python中有字典dict这样的数据类型,而其它语言可能没有对应的字典。
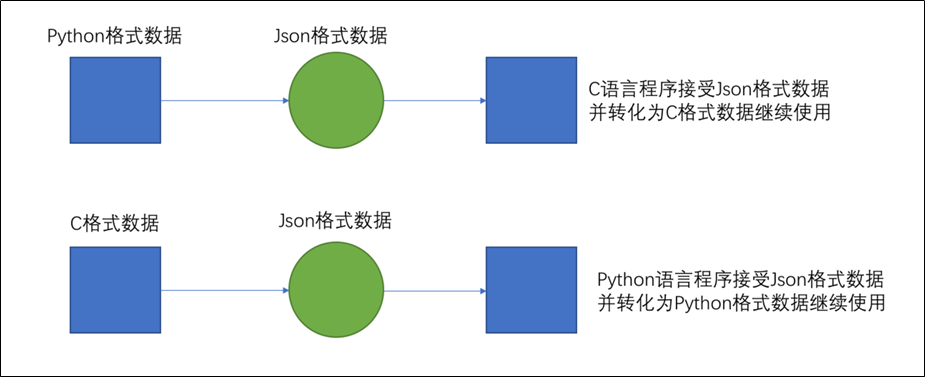
为了让不同的语言都能够相互通用的互相传递数据,JSON就是一种非常良好的中转数据格式。如下图,以Python和C语言互传数据为例:
json 数据的格式:字典以及 内部元素都是字典的列表
# json数据的格式可以是: {"name":"admin","age":18} # 也可以是: [{"name":"admin","age":18},{"name":"root","age":16},{"name":"张三","age":20}]Python 数据和 Json 数据的相互转化
# 导入json模块 import json # 准备符合格式json格式要求的python数据 data = [{"name": "老王", "age": 16}, {"name": "张三", "age": 20}] # 通过 json.dumps(data) 方法把python数据转化为了 json数据 data = json.dumps(data) # 通过 json.loads(data) 方法把json数据转化为了 python数据 data = json.loads(data)示例代码:
""" 演示 JSON 数据和 Python 字典的相互转换 """ import json # 准备列表,列表内的每一个元素都是字典,将其转化为 JSON data = [{"name":"张大山", "age":11}, {"name":"王大锤", "age":13}, {"name":"赵小虎", "age":16}] json_str = json.dumps(data, ensure_ascii=False) print(type(json_str)) print(json_str) print("--------------------------------------------------------------") # 准备字典,将字典转换为 JSON d = {"name":"zhoujielun", "addr":"taibei"} json_str = json.dumps(d) print(type(json_str)) print(json_str) print("--------------------------------------------------------------") # 将 JSON 字符串转换为 Python 数据类型 [{k:v, k:v}, {k:v, k:v}] s = '[{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]' l = json.loads(s) print(type(l)) print(l) print("--------------------------------------------------------------") # 将 JSON 字符串转换为 Python 数据类型 {k:v, k:v} s = '{"name": "zhoujielun", "addr": "taibei"}' d = json.loads(s) print(type(d)) print(d) # 结果 <class 'str'> [{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}] ----------------------------------------------------------------------- <class 'str'> {"name": "zhoujielun", "addr": "taibei"} ----------------------------------------------------------------------- <class 'list'> [{'name': '张大山', 'age': 11}, {'name': '王大锤', 'age': 13}, {'name': '赵小虎', 'age': 16}] ----------------------------------------------------------------------- <class 'dict'> {'name': 'zhoujielun', 'addr': 'taibei'}87、pyecharts 模块简介
如果想要做出数据可视化效果图, 可以借助pyecharts模块来完成
概况 :
Echarts 是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时pyecharts 诞生了。
快速安装
pip install pyecharts官方画廊
https://gallery.pyecharts.org
88、pyecharts的入门使用
基础折线图
# 导包 from pyecharts.charts import Line from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts,VisualMapOpts # 创建一个折线图对象 line = Line() # 给折线图对象添加 x 轴的数据 line.add_xaxis(["中国", "美国", "英国"]) # 给折线图对象添加 y 轴的数据 line.add_yaxis("GDP", [30, 20, 10]) # 通过 render 方法,将代码生成图像 line.render()结果如下:
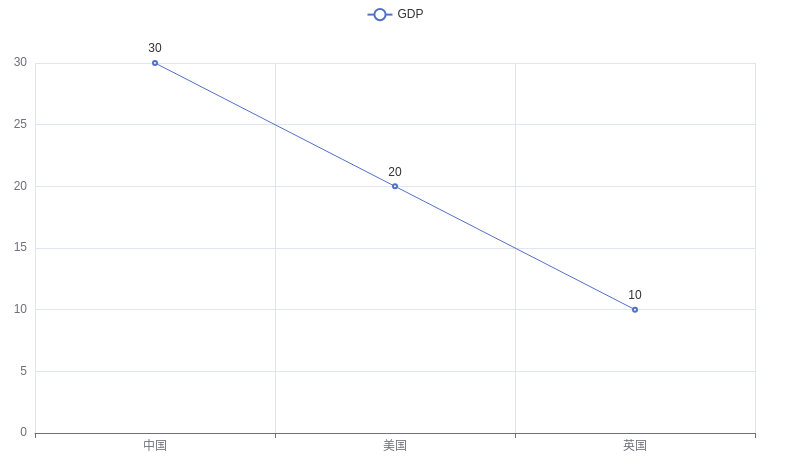
pyecharts配置选项
pyecharts模块中有很多的配置选项, 常用到2个类别的选项:
- 全局配置选项
- 系列配置选项
全局配置选项可以通过set_global_opts方法来进行配置, 相应的选项和选项的功能如下:
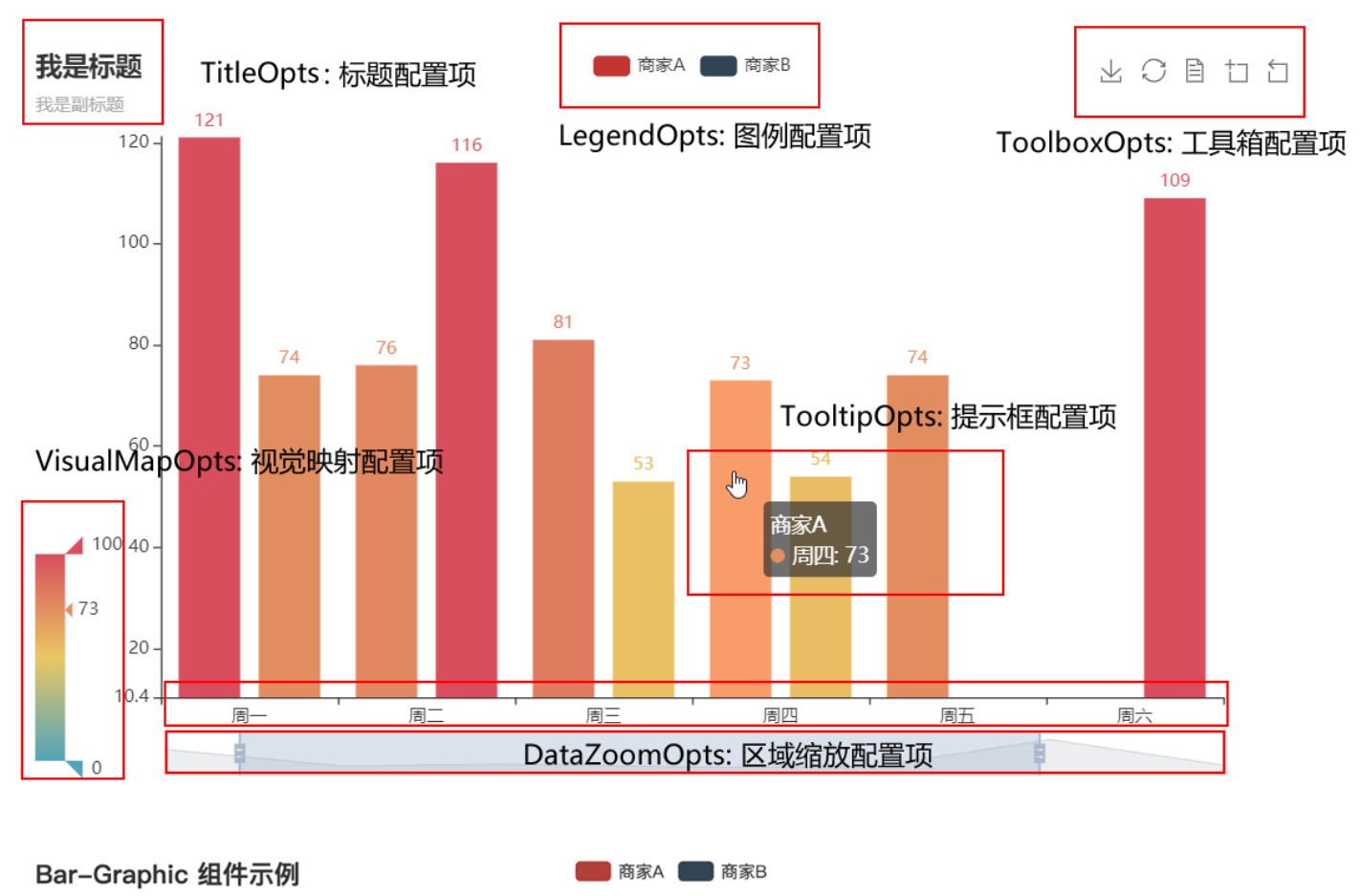
示例:
""" 演示 pyecharts 的基础入门 """ # 导包 from pyecharts.charts import Line from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts,VisualMapOpts # 创建一个折线图对象 line = Line() # 给折线图对象添加 x 轴的数据 line.add_xaxis(["中国", "美国", "英国"]) # 给折线图对象添加 y 轴的数据 line.add_yaxis("GDP", [30, 20, 10]) # 设置全局配置项 line.set_global_opts( title_opts=TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"), legend_opts=LegendOpts(is_show=True), toolbox_opts=ToolboxOpts(is_show=True), visualmap_opts=VisualMapOpts(is_show=True) ) # 通过 render 方法,将代码生成图像 line.render()结果:
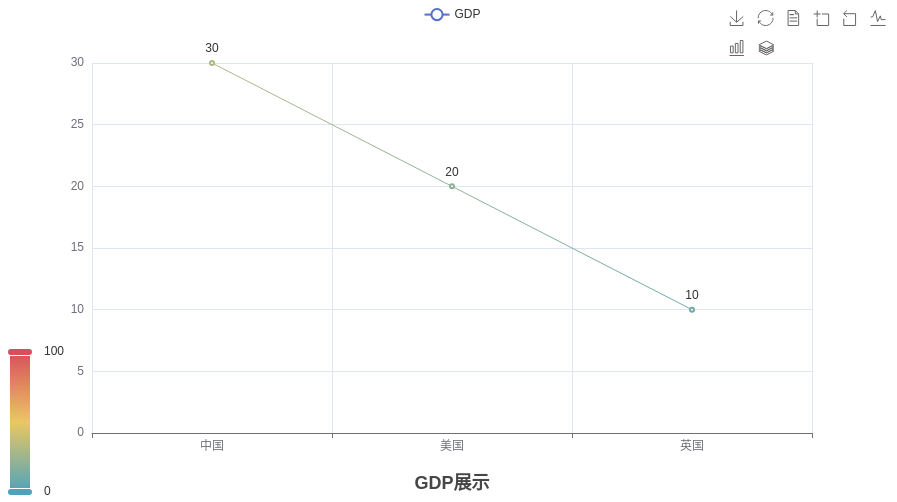
89、数据准备
原始数据格式

数据处理
导入模块:
import json对数据进行整理,让数据符合 json 格式:
# 处理数据 f_us = open("/home/yin-roc/1-Github/Ubuntu20.04-VMware/pythonProject/Python_Learning/02_Python入门语法/可视化案例数据/折线图数据/美国.txt", "r", encoding="UTF-8") us_data = f_us.read() # 美国的全部内容 # 去掉不合 JSON 规范的开头 us_data = us_data.replace("jsonp_1629344292311_69436(", "") # 去掉不合 JSON 规范的结尾 # us_data = us_data.replace(");", "") us_data = us_data[:-2] # JSON 转 Python 字典 us_dict = json.loads(us_data) # print(type(us_dict)) # print(us_dict) # 获取 trend key trend_data = us_dict['data'][0]['trend'] # print(type(trend_data)) # print(trend_data) # 获取日期数据,用于 x 轴,取2020年(到314下标结束) x_data = trend_data['updateDate'][:314] # print(x_data) # 获取确认数据,用于 y 轴,取2020年(到315下标结束) y_data = trend_data['list'][0]['data'][:314] # print(y_data)90、生成折线图
导入模块
from pyecharts.charts import Line from pyecharts.options import TitleOpts, LabelOpts折线图相关配置项
折线图相关配置项
配置项 作用 代码实例 init_opts 对折线图初始化设置宽高 init_opts=opts.InitOpts(width=“1600px”, height=“800px”) .add_xaxis 添加x轴数据 .add_xaxis(列表) .add_yaxis 添加y轴数据 .add_yaxis(纵坐标标题, 列表) 创建折线图

这里的**Line()**是构建类对象,我们先不必理解是什么意思,后续在Python高阶中进行详细讲解。添加数据

.add_yaxis相关配置选项
配置项 作用 代码实例 series_name 设置图例名称 series_name=“美国确诊人数” y_axis 输入y轴数据 y_axis=[“列表”] symbol_size 设置点的大小 symbol_size=10 label_opts 标签设置项:不显示标签 label_opts=opts.LabelOpts(is_show=False) linestyle_opts 线条宽度和样式 linestyle_opts=opts.LineStyleOpts(width=2) 示例:

效果如下:

全局配置选项(.set_global_opts)
配置项 作用 代码实例 title_opts 设置图标题和位置 title_opts=opts.TitleOpts(title=“标题”, pos_left=“center”) yaxis_opts y轴配置项 yaxis_opts=opts.AxisOpts(name=“累计确诊人数”) xaxis_opts x轴配置项 xaxis_opts=opts.AxisOpts(name=“时间”) legend_opts 图例配置项 legend_opts=opts.LegendOpts(pos_left=‘70%’) 示例代码:
.set_global_opts( # 设置图标题和位置 title_opts=opts.TitleOpts(title="2020年 印🇮🇳美🇺🇸日🇯🇵 累计确诊人数对比图",pos_left="center"), # x轴配置项 xaxis_opts=opts.AxisOpts(name=“时间”), # 轴标题 # y轴配置项 yaxis_opts=opts.AxisOpts(name=“累计确诊人数”), # 轴标题 # 图例配置项 legend_opts=opts.LegendOpts(pos_left=‘70%‘), # 图例的位置 )效果如下:

示例代码:
""" 演示 可视化需求1:折线图开发 """ import json from pyecharts.charts import Line from pyecharts.options import TitleOpts, LabelOpts # 处理数据 f_us = open("/home/yin-roc/1-Github/Ubuntu20.04-VMware/pythonProject/Python_Learning/02_Python入门语法/可视化案例数据/折线图数据/美国.txt", "r", encoding="UTF-8") us_data = f_us.read() # 美国的全部内容 f_jp = open("/home/yin-roc/1-Github/Ubuntu20.04-VMware/pythonProject/Python_Learning/02_Python入门语法/可视化案例数据/折线图数据/日本.txt", "r", encoding="UTF-8") jp_data = f_jp.read() # 日本的全部内容 f_in = open("/home/yin-roc/1-Github/Ubuntu20.04-VMware/pythonProject/Python_Learning/02_Python入门语法/可视化案例数据/折线图数据/印度.txt", "r", encoding="UTF-8") in_data = f_in.read() # 日本的全部内容 # 去掉不合 JSON 规范的开头 us_data = us_data.replace("jsonp_1629344292311_69436(", "") jp_data = jp_data.replace("jsonp_1629350871167_29498(", "") in_data = in_data.replace("jsonp_1629350745930_63180(", "") # 去掉不合 JSON 规范的结尾 # us_data = us_data.replace(");", "") us_data = us_data[:-2] jp_data = jp_data[:-2] in_data = in_data[:-2] # JSON 转 Python 字典 us_dict = json.loads(us_data) jp_dict = json.loads(jp_data) in_dict = json.loads(in_data) # print(type(us_dict)) # print(us_dict) # 获取 trend key us_trend_data = us_dict['data'][0]['trend'] jp_trend_data = jp_dict['data'][0]['trend'] in_trend_data = in_dict['data'][0]['trend'] # print(type(trend_data)) # print(trend_data) # 获取日期数据,用于 x 轴,取2020年(到314下标结束) us_x_data = us_trend_data['updateDate'][:314] jp_x_data = jp_trend_data['updateDate'][:314] in_x_data = in_trend_data['updateDate'][:314] # print(x_data) # 获取确认数据,用于 y 轴,取2020年(到315下标结束) us_y_data = us_trend_data['list'][0]['data'][:314] jp_y_data = jp_trend_data['list'][0]['data'][:314] in_y_data = in_trend_data['list'][0]['data'][:314] # print(y_data) # 生成图表 line = Line() # 构建折线图对象 # 添加 x 轴数据 line.add_xaxis(us_x_data) # x 轴是公用的,所以使用一个国家的数据即可 # 添加 y 轴数据 line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 设置全局选项 line.set_global_opts( # 标题设置 title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%") ) # 调用 render 方法生成图表 line.render() # 关闭文件对象 f_us.close() f_jp.close() f_in.close()91、数据可视化案例——地图——基础地图的使用
基础地图演示
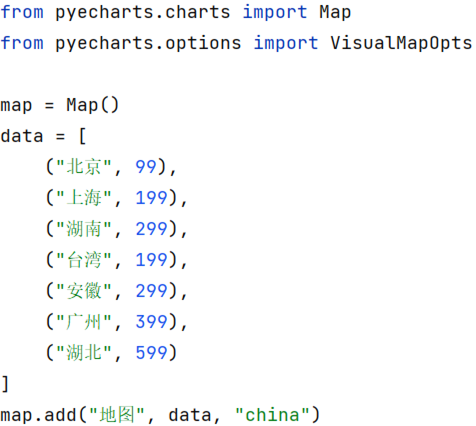
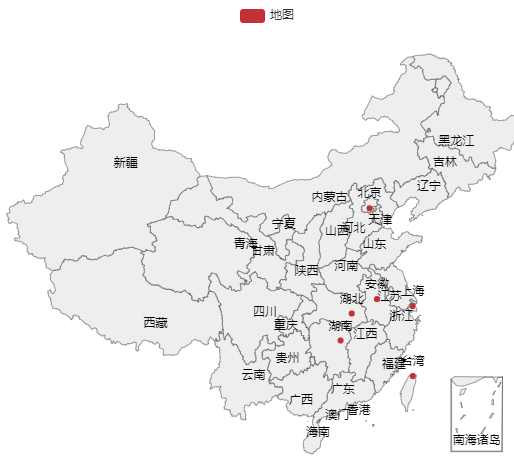
设置颜色级别:
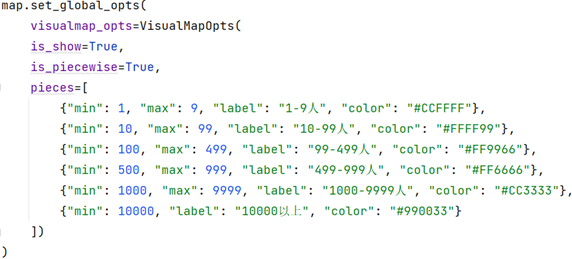
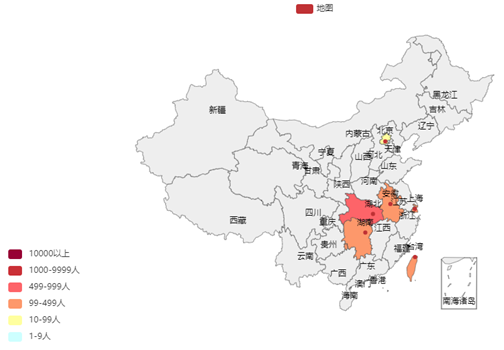
tips:RGB颜色查询对照表
-
-
相关阅读:
电影《加菲猫家族》观后感
数字化外协生产综合管理系统,实现信息自动同步,数据自动统计分析!
JavaScript中的包装类型详解
浅谈keras.preprocessing.text
Mongodb出现Error: couldn‘t add user: Could not find role: root@database 解决方法
tomcat 7 Request请求参数中文乱码问题
22张图带你深入剖析前缀、中缀、后缀表达式以及表达式求值
Android查看公钥与MD5
电子学会青少年软件编程 Python编程等级考试二级真题解析(判断题)2021年9月
路由器选择使用指南这三Openwrt
- 原文地址:https://blog.csdn.net/qq_45545681/article/details/139842741