-
HTTP 概述
HTTP 概述
HTTP 是一种用于获取资源(如 HTML 文档)的协议。 它是 Web 上任何数据交换的基础,它是一种客户端-服务器协议,这意味着请求由接收方(通常是 Web 浏览器)发起。 一个完整的文档是从获取的不同子文档中重建的,例如文本、布局描述、图像、视频、脚本等。
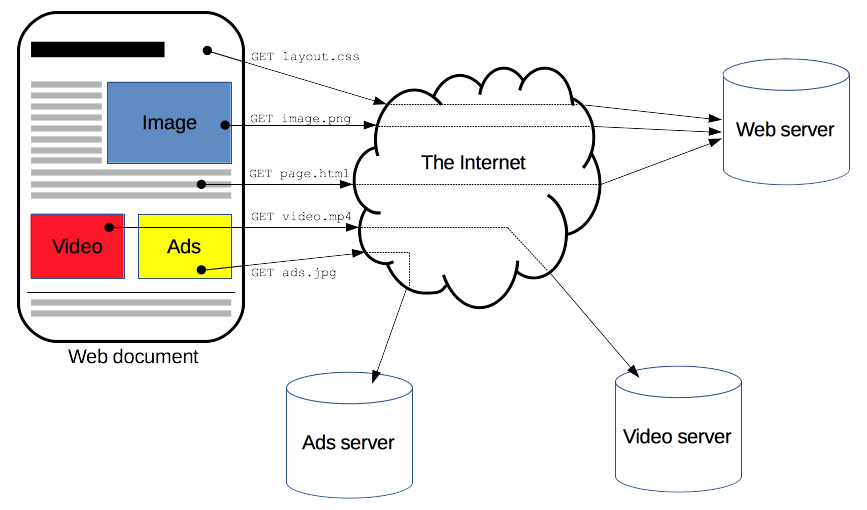
客户端和服务器通过交换单个消息(而不是数据流)进行通信。 客户端(通常是 Web 浏览器)发送的消息称为请求,服务器作为应答发送的消息称为响应。
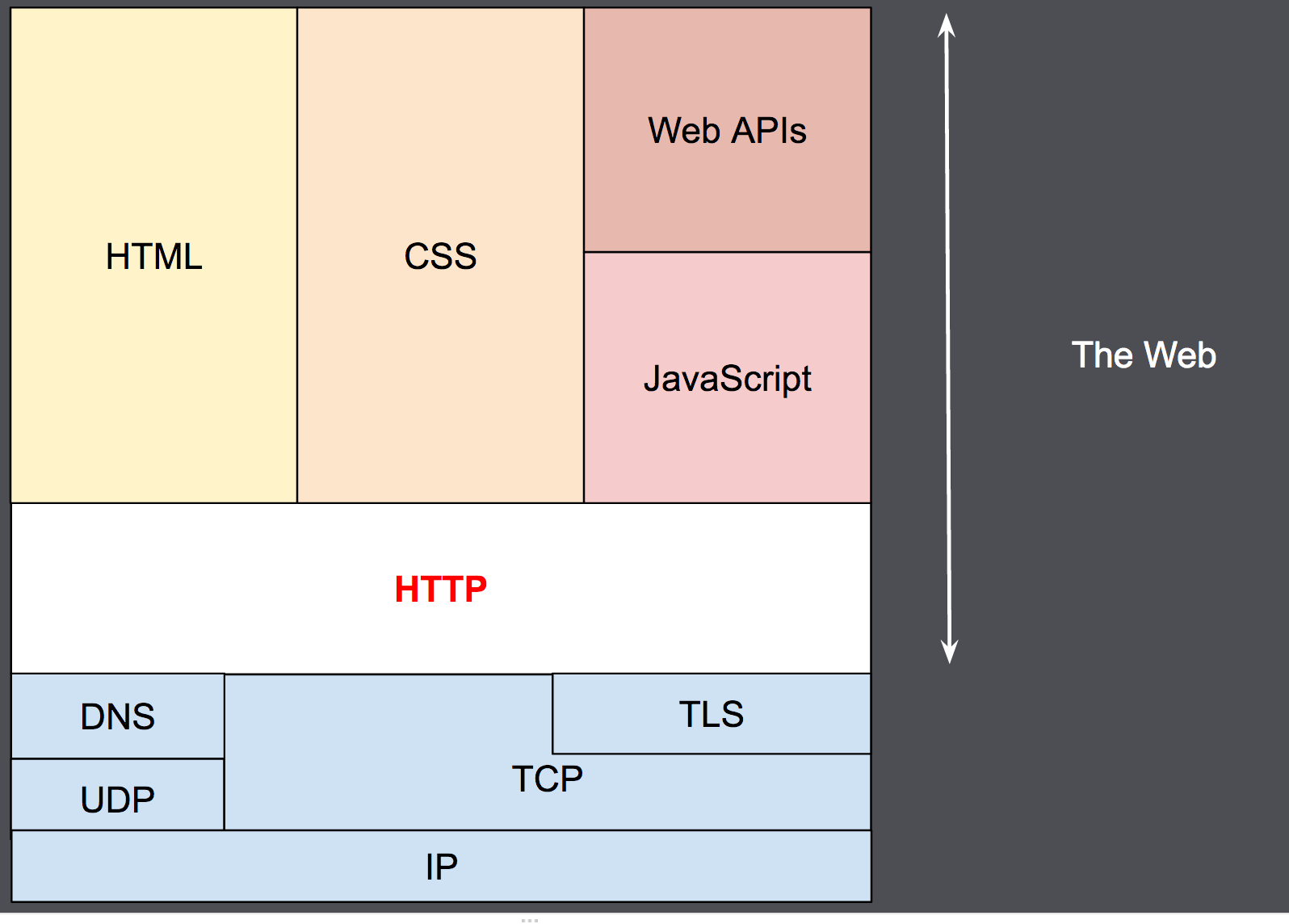
HTTP 设计于 1990 年代初期,是一种随着时间的推移而发展的可扩展协议。 它是一种通过 TCP 或 TLS 加密的 TCP 连接发送的应用层协议,尽管理论上可以使用任何可靠的传输协议。 由于其可扩展性,它不仅用于获取超文本文档,还用于获取图像和视频或将内容发布到服务器,例如 HTML 表单结果。 HTTP 还可用于获取文档的某些部分,以便按需更新网页。
基于 HTTP 的系统的组件
HTTP 是一种客户端-服务器协议:请求由一个实体、用户代理(或代表它的代理)发送。 大多数情况下,用户代理是一个 Web 浏览器,但它可以是任何东西,例如,一个爬网以填充和维护搜索引擎索引的机器人。
每个单独的请求都会发送到服务器,服务器会处理它并提供称为响应的答案。 例如,在客户端和服务器之间有许多实体,统称为代理,它们执行不同的操作并充当网关或缓存。

实际上,在浏览器和处理请求的服务器之间有更多的计算机:有路由器、调制解调器等。 由于 Web 的分层设计,这些都隐藏在网络和传输层中。 HTTP 位于应用程序层的顶部。 尽管对于诊断网络问题很重要,但底层大多与 HTTP 的描述无关。
客户端:用户代理
用户代理是代表用户执行操作的任何工具。 此角色主要由 Web 浏览器执行,但也可能由工程师和 Web 开发人员用来调试其应用程序的程序执行。
浏览器始终是发起请求的实体。 它从来都不是服务器(尽管多年来已经添加了一些机制来模拟服务器启动的消息)。
为了显示网页,浏览器会发送原始请求来获取表示该页面的 HTML 文档。 然后,它解析此文件,发出与执行脚本、要显示的布局信息 (CSS) 以及页面中包含的子资源(通常是图像和视频)相对应的其他请求。 然后,Web 浏览器将这些资源组合在一起,以显示完整的文档,即网页。 浏览器执行的脚本可以在以后的阶段获取更多资源,浏览器会相应地更新网页。
网页是超文本文档。 这意味着显示内容的某些部分是链接,可以激活(通常通过单击鼠标)以获取新网页,从而允许用户指导其用户代理并在 Web 中导航。 浏览器将这些指令转换为 HTTP 请求,并进一步解释 HTTP 响应以向用户提供清晰的响应。
Web 服务器
在通信通道的另一侧是服务器,它根据客户端的请求提供文档。 服务器实际上仅显示为一台计算机;但它实际上可能是共享负载(负载平衡)或其他软件(如缓存、数据库服务器或电子商务服务器)的服务器的集合,全部或部分按需生成文档。
一台服务器不一定是一台机器,但可以在同一台机器上托管多个服务器软件实例。 使用 HTTP/1.1 和 Host 标头,它们甚至可以共享相同的 IP 地址。
代理
在 Web 浏览器和服务器之间,许多计算机和机器中继 HTTP 消息。 由于 Web 堆栈的分层结构,其中大多数在传输、网络或物理级别运行,在 HTTP 层变得透明,并可能对性能产生重大影响。 那些在应用程序层操作的代理通常称为代理。 这些可以是透明的,在不以任何方式更改它们的情况下转发他们收到的请求,也可以是不透明的,在这种情况下,他们将在将请求传递给服务器之前以某种方式更改请求。 代理可以执行许多功能:
- 缓存(缓存可以是公共的或私有的,就像浏览器缓存一样)
- 过滤(如防病毒扫描或家长控制)
- 负载平衡(允许多个服务器处理不同的请求)
- 身份验证(用于控制对不同资源的访问)
- 日志记录(允许存储历史信息)
HTTP 的基本方面
HTTP 很简单
HTTP 通常被设计为简单且人类可读,即使在 HTTP/2 中通过将 HTTP 消息封装到帧中而增加了复杂性。 HTTP 消息可以被人类阅读和理解,为开发人员提供更轻松的测试,并为新手降低复杂性。
HTTP 是可扩展的
HTTP 标头在 HTTP/1.0 中引入,使该协议易于扩展和试验。 甚至可以通过客户端和服务器之间关于新标头语义的简单协议来引入新功能。
HTTP 是无状态的,但不是无会话的
HTTP 是无状态的:在同一连接上连续执行的两个请求之间没有链接。 对于试图与某些页面进行连贯交互的用户来说,这立即可能会成为问题,例如,使用电子商务购物篮。 但是,虽然 HTTP 本身的核心是无状态的,但 HTTP cookie 允许使用有状态会话。 使用标头扩展性,将 HTTP Cookie 添加到工作流中,从而允许在每个 HTTP 请求上创建会话以共享相同的上下文或相同的状态。
HTTP 和连接
连接在传输层进行控制,因此从根本上超出了 HTTP 的范围。 HTTP 不要求基础传输协议基于连接;它只要求它是可靠的,或者不会丢失消息(至少在这种情况下会出现错误)。 在 Internet 上最常见的两种传输协议中,TCP 是可靠的,而 UDP 则不可靠。 因此,HTTP 依赖于基于连接的 TCP 标准。
在客户端和服务器可以交换 HTTP 请求/响应对之前,它们必须建立 TCP 连接,该过程需要多次往返。 HTTP/1.0 的默认行为是为每个 HTTP 请求/响应对打开单独的 TCP 连接。 这比在连续发送多个请求时共享单个 TCP 连接效率低。
为了缓解此缺陷,HTTP/1.1 引入了流水线(事实证明很难实现)和持久连接:可以使用 Connection 标头部分控制底层 TCP 连接。 HTTP/2 更进一步,通过单个连接多路复用消息,有助于保持连接温暖和高效。
目前正在进行实验,以设计更适合HTTP的更好的传输协议。 例如,谷歌正在试验基于UDP构建的QUIC,以提供更可靠、更高效的传输协议。
HTTP可以控制什么
随着时间的流逝,HTTP 的这种可扩展性允许对 Web 进行更多的控制和功能。 缓存和身份验证方法是 HTTP 历史记录早期处理的函数。 相比之下,放宽原点限制的能力是在 2010 年代才添加的。
以下是可通过HTTP控制的常见功能列表:
- 缓存: 文档的缓存方式可以通过 HTTP 控制。 服务器可以指示代理和客户端缓存什么以及缓存多长时间。 客户端可以指示中间缓存代理忽略存储的文档。
- 放宽原点约束: 为了防止窥探和其他隐私侵犯,Web 浏览器在网站之间强制执行严格的隔离。 只有来自同一来源的页面才能访问网页的所有信息。 尽管这样的约束会给服务器带来负担,但 HTTP 标头可以放宽服务器端的这种严格分离,允许文档成为来自不同域的信息的拼凑;这样做甚至可能有与安全有关的原因。
- 身份验证: 某些页面可能受到保护,因此只有特定用户才能访问它们。 基本身份验证可以通过 HTTP 提供,可以使用 WWW-Authenticate 和类似的标头,或者通过使用 HTTP cookie 设置特定会话。
- 代理和隧道: 服务器或客户端通常位于 Intranet 上,并对其他计算机隐藏其真实 IP 地址。 然后,HTTP 请求通过代理来跨越此网络屏障。 并非所有代理都是 HTTP 代理。 例如,SOCKS协议在较低级别运行。 其他协议,如 ftp,可以由这些代理处理。
- 会议: 使用 HTTP cookie 允许您将请求与服务器的状态链接起来。 尽管基本 HTTP 是无状态协议,但这会创建会话。 这不仅对电子商务购物篮有用,而且对任何允许用户配置输出的网站也很有用。
HTTP 流
当客户端想要与服务器(最终服务器或中间代理)通信时,它将执行以下步骤:
- 打开 TCP 连接:TCP 连接用于发送一个或多个请求并接收应答。 客户端可以打开新连接、重用现有连接或打开多个与服务器的 TCP 连接。
- 发送 HTTP 消息:HTTP 消息(HTTP/2 之前)是人类可读的。 使用 HTTP/2 时,这些简单的消息被封装在帧中,使它们无法直接读取,但原理保持不变。 例如:
网址复制到剪贴板
GET / HTTP/1.1- Host: developer.mozilla.org
- Accept-Language: fr
- 读取服务器发送的响应,例如:
网址复制到剪贴板
HTTP/1.1 200 OK- Date: Sat, 09 Oct 2010 14:28:02 GMT
- Server: Apache
- Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
- ETag: "51142bc1-7449-479b075b2891b"
- Accept-Ranges: bytes
- Content-Length: 29769
- Content-Type: text/html
- DOCTYPE html>… (here come the 29769 bytes of the requested web page)
- 关闭或重用连接以进行进一步的请求。
如果激活了 HTTP 流水线,则可以发送多个请求,而无需等待完全接收到第一个响应。 事实证明,在现有网络中很难实现HTTP流水线,因为旧软件与现代版本共存。 HTTP 流水线已在 HTTP/2 中被替换为帧内更强大的多路复用请求。
HTTP 消息
HTTP/1.1 及更早版本中定义的 HTTP 消息是人类可读的。 在 HTTP/2 中,这些消息被嵌入到二进制结构(帧)中,允许压缩标头和多路复用等优化。 即使在此版本的 HTTP 中只发送了原始 HTTP 消息的一部分,每条消息的语义也不会改变,并且客户端会(虚拟地)重构原始 HTTP/1.1 请求。 因此,理解 HTTP/2.1 格式的 HTTP/1 消息很有用。
有两种类型的 HTTP 消息:请求和响应,每种都有自己的格式。
请求
HTTP 请求示例:
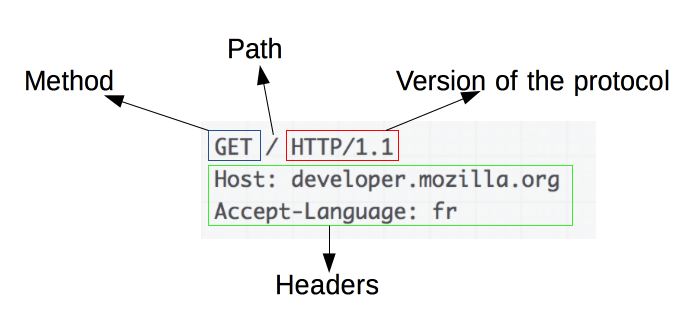
请求由以下元素组成:
- HTTP 方法,通常是动词(如 GET、POST)或名词(如 OPTIONS、HEAD),用于定义客户端要执行的操作。 通常,客户端希望获取资源(使用 )或发布 HTML 表单的值(使用 ),尽管在其他情况下可能需要更多操作。
GETPOST - The path of the resource to fetch; the URL of the resource stripped from elements that are obvious from the context, for example without the protocol (), the domain (here, ), or the TCP port (here, ).
http://developer.mozilla.org80 - The version of the HTTP protocol.
- 用于传达服务器附加信息的可选标头。
- 对于某些方法(如 ,类似于响应中的方法),正文包含发送的资源。
POST
反应
响应示例:
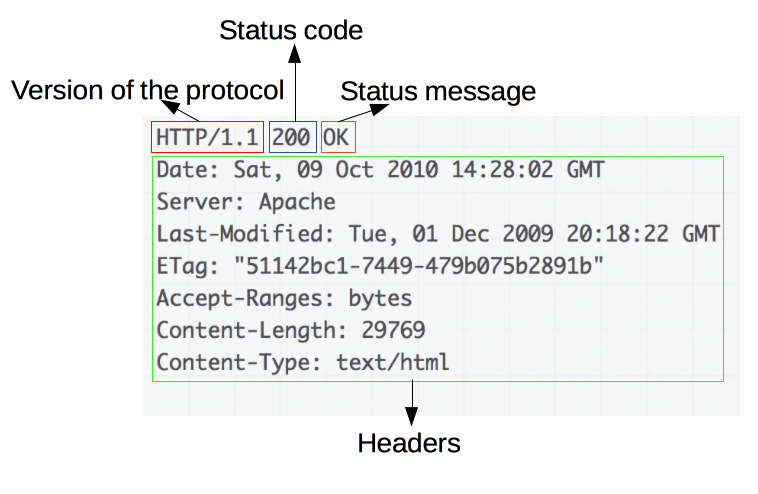
响应由以下要素组成:
基于 HTTP 的 API
基于 HTTP 最常用的 API 是 Fetch API,它可用于从 JavaScript 发出 HTTP 请求。Fetch API 取代了 XMLHttpRequest API。
另一个 API,即服务器发送的事件,是一种单向服务,它允许服务器使用 HTTP 作为传输机制向客户端发送事件。 使用 EventSource 接口,客户端打开连接并建立事件处理程序。 客户端浏览器会自动将到达 HTTP 流的消息转换为相应的 Event 对象。然后,如果已知,它会将它们传递给已为事件类型注册的事件处理程序,或者传递给 onmessage 事件处理程序(如果未建立特定于类型的事件处理程序)。
结论
HTTP 是一种易于使用的可扩展协议。 客户端-服务器结构,结合添加标头的能力,允许 HTTP 随着 Web 的扩展功能而发展。
-
相关阅读:
2023上半年薪资报告出炉!人均月入过万?!
优思学院|六西格玛将烹饪和美味提升至极致
word2vec
总结的HTTP比较详细的知识
java多线程编程:你真的了解线程中断吗?
基于 LLM 的知识图谱另类实践
uniApp webview 中调用底座蓝牙打印功能异常
P1554 梦中的统计--------洛谷 / 题目列表 / 题目详情
聊聊精益需求的产生过程
Android、缓存清理
- 原文地址:https://blog.csdn.net/A_nanda/article/details/139650357