-
Redis常见数据类型及其常用命令详解
文章目录
- 一、Redis概述
- 二、Redis常用命令
- 1.通用命令
- 1.1 KEYS:查看符合模板的所有 key
- 1.2 DEL:删除一个指定的 key
- 1.3 EXISTS:判断 key 是否存在
- 1.4 EXPIRE:给一个 key 设置有效期,有效期到期时该 key 会被自动删除
- 1.5 TTL:查看一个 key 的剩余有效期
- 1.6 COPY:复制 Redis 数据库中的数据到另一个数据库中
- 1.7 MOVE:将 Redis 中的指定键移动到另一个数据库中
- 1.8 TOUCH:修改指定键的最后访问时间
- 1.9 RENAME: 修改一个键的名称
- 1.10 RENAMENX:新名称的键不存在时执行修改
- 1.11 TYPE:返回键所存储的值的类型
- 1.12 PERSIST:移除 Redis 键的过期时间
- 2.String类型
- 2.1 SET:添加或者修改已经存在的一个String类型的键值对
- 2.2 GET:根据key获取String类型的value
- 2.3 MSET:批量添加多个String类型的键值对
- 2.4 MGET:根据多个key获取多个String类型的value
- 2.5 INCR:让一个整型的key自增1
- 2.6 INCRBY:让一个整型的key自增并指定步长
- 2.7 INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
- 2.8 SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- 2.9 SETEX:添加一个String类型的键值对,并且指定有效期
- 2.10 MSETNX :设置多个键值对,但只有在所有指定的键都不存在时才执行设置操作
- 2.11 APPEND:将指定的值追加到已存在键的值末尾
- 2.12 DECR:将指定键的值减一
- 2.13 DECRBY:将指定键的值减去给定的整数
- 2.14 GETDEL:获取指定键的值并将该键删除
- 2.15 GETEX:获取一个键的值,并且可以选择性地设置该键的过期时间或者移除其过期时间
- 2.16 GETRANGE:获取指定键(key)的字符串值中参数指定的子字符串
- 2.17 GETSET:设置给定键(key)对应的值,同时返回该键的旧值
- 2.18 STRLEN:返回指定键(key)对应的字符串值的长度
- 2. 19 key结构
- 3.Hash类型
- 3.1 HSET:添加或者修改hash类型key的field的值
- 3.2 HGET :获取一个hash类型key的field的值
- 3.3 HMSET:批量添加多个hash类型key的field的值
- 3.4 HMGET:批量获取多个hash类型key的field的值
- 3.5 HGETALL:获取一个hash类型的key中的所有的field和value
- 3.6 HKEYS:获取一个hash类型的key中的所有的field
- 3.7 HINCRBY:让一个hash类型key的字段值自增并指定步长
- 3.8 HDEL:用于从哈希表中删除一个或多个字段
- 3.9 HEXISTS:检查哈希表中指定字段是否存在
- 3.10 HLEN:获取哈希表中字段的数量
- 4.List类型
- 5.Set类型
- 6. SortedSet类型
一、Redis概述
二、Redis常用命令
Redis为了方便我们学习,将操作不同数据类型的命令也做了分组,在官网( https://redis.io/commands )可以查看到不同的命令:

不同类型的命令称为一个group,我们也可以通过help命令来查看各种不同group的命令:

1.通用命令
1.1 KEYS:查看符合模板的所有 key

KEYS 命令在处理大量数据时可能会影响 Redis 服务器的性能,因为它会遍历所有 key 来寻找匹配的项。

在生产环境中,应该谨慎使用 KEYS 命令,尤其是在数据量巨大的情况下。
如果需要对符合特定模式的 key 进行操作,推荐使用 SCAN 命令和游标来逐步迭代进行处理,以减少对服务器的影响。
redis> MSET firstname Jack lastname Stuntman age 35 "OK" redis> KEYS *name* 1) "lastname" 2) "firstname" redis> KEYS a?? 1) "age" redis> KEYS * 1) "lastname" 2) "age" 3) "firstname" redis>首先使用
MSET命令设置了多个 key-value 对,分别为firstname、lastname和age。然后使用KEYS命令查找符合指定模式的 key。- 第一个
KEYS命令使用模式*name*,返回所有包含 “name” 的 key,即lastname和firstname。 - 第二个
KEYS命令使用模式a??,返回所有以字母 “a” 开头并且后面有两个字符的 key,即age。 - 最后一个
KEYS命令使用模式*,返回所有存在的 key,即lastname、age和firstname。
1.2 DEL:删除一个指定的 key

在 Redis 中,
DEL命令用于删除指定的 key,并返回成功删除的 key 的数量。
redis> SET key1 "Hello" "OK" redis> SET key2 "World" "OK" redis> DEL key1 key2 key3 (integer) 2 redis>使用
DEL命令删除了两个 key,即key1和key2。因为这两个 key 存在且被成功删除,所以返回的结果是(integer) 2。如果执行
DEL命令删除了不存在的 key,那么返回的结果将是(integer) 0,表示没有成功删除任何 key。
1.3 EXISTS:判断 key 是否存在

EXISTS命令用于判断给定的 key 是否存在于 Redis 中。它可以同时接受多个 key,并返回存在的 key 的数量。如果 key 存在,则返回 1;如果 key 不存在,则返回 0。
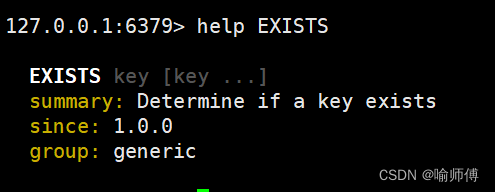
redis> SET key1 "Hello" "OK" redis> EXISTS key1 (integer) 1 redis> EXISTS nosuchkey (integer) 0 redis> SET key2 "World" "OK" redis> EXISTS key1 key2 nosuchkey (integer) 2 redis>使用
SET命令分别设置了key1和key2的值。然后使用EXISTS命令来检查指定的 key 是否存在。- 第一个
EXISTS命令执行EXISTS key1,返回结果为(integer) 1,表示key1存在。 - 第二个
EXISTS命令执行EXISTS nosuchkey,返回结果为(integer) 0,表示nosuchkey不存在。 - 接下来执行
EXISTS key1 key2 nosuchkey,返回结果为(integer) 2,表示其中两个 key 存在,即key1和key2,而nosuchkey不存在。
Tips:

如果在参数中多次提到相同的现有键,它将被计算多次。如果somekey存在,exists somekey somekey将返回2。
1.4 EXPIRE:给一个 key 设置有效期,有效期到期时该 key 会被自动删除
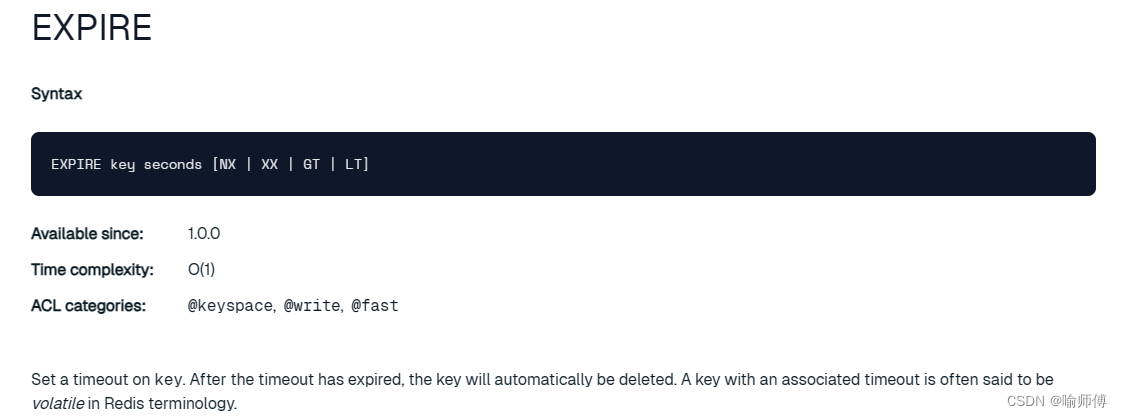
EXPIRE key seconds [NX | XX | GT | LT]-
key:要设置过期时间的键名。 -
seconds:过期时间,单位为秒。键在指定秒数后将会被自动删除。 -
NX:(可选)仅在键不存在时设置过期时间。 -
XX:(可选)仅在键已存在时设置过期时间。 -
GT:(可选)仅在键的当前过期时间大于给定过期时间时设置过期时间。 -
LT:(可选)仅在键的当前过期时间小于给定过期时间时设置过期时间。 -
当
NX和XX选项都未指定时,默认行为是设置键的过期时间,如果键不存在则创建键并设置过期时间。 -
NX和XX选项可以与GT或LT选项结合使用,从而提供更精确的过期时间控制。
-
设置键
mykey在 60 秒后过期:EXPIRE mykey 60 -
仅当键
mykey存在时,设置它在 120 秒后过期:EXPIRE mykey 120 XX -
仅当键
mykey不存在时,设置它在 300 秒后过期:EXPIRE mykey 300 NX -
仅当键
mykey的当前过期时间大于 180 秒时,设置它在 180 秒后过期:EXPIRE mykey 180 GT -
仅当键
mykey的当前过期时间小于 240 秒时,设置它在 240 秒后过期:EXPIRE mykey 240 LT

redis> SET mykey "Hello" "OK" redis> EXPIRE mykey 10 (integer) 1 redis> TTL mykey (integer) 10 redis> SET mykey "Hello World" "OK" redis> TTL mykey (integer) -1 redis> EXPIRE mykey 10 XX (integer) 0 redis> TTL mykey (integer) -1 redis> EXPIRE mykey 10 NX (integer) 1 redis> TTL mykey (integer) 10 redis>
1.5 TTL:查看一个 key 的剩余有效期

TTL命令用于获取 Redis 键的剩余生存时间(Time To Live,TTL)。TTL keykey:要查询剩余生存时间的键名。
返回值
redis> SET mykey "Hello" "OK" redis> EXPIRE mykey 10 (integer) 1 redis> TTL mykey (integer) 10 redis>- 返回键的剩余生存时间(TTL):
- 如果键不存在或者键没有设置过期时间,返回
-1。 - 如果键存在且设置了过期时间,返回剩余生存时间的秒数。
- 如果键不存在或者键没有设置过期时间,返回
注意事项
- 返回
-1表示键不存在或者键没有设置过期时间。 - 返回
0表示键存在并且没有剩余生存时间,即键已经过期。 - TTL 返回的时间单位是秒。
1.6 COPY:复制 Redis 数据库中的数据到另一个数据库中

COPY命令用于复制 Redis 数据库中的数据到另一个数据库中。COPY source destination [DB destination-db] [REPLACE]-
source:要复制数据的源键名。 -
destination:目标键名,复制后的数据将存储在这个键中。 -
DB destination-db:(可选)目标数据库的索引号。默认为 0(即默认数据库)。 -
REPLACE:(可选)如果目标键destination已存在且有数据,使用REPLACE选项将会覆盖现有数据。如果未指定REPLACE,并且目标键已存在,则COPY命令将会失败。 -
source和destination参数必须是有效的键名。 -
可以指定一个不同的目标数据库索引号,使数据被复制到该索引号对应的数据库中。
-
使用
REPLACE选项可以在目标键已存在时覆盖现有数据,否则命令会失败。
示例
-
将键
mykey中的数据复制到键mykey_copy中:COPY mykey mykey_copy -
将键
mylist中的数据复制到键mylist_backup中,并指定目标数据库索引号为 1:COPY mylist mylist_backup DB 1 -
将键
myset中的数据复制到键myset_new中,如果myset_new已存在则覆盖现有数据:COPY myset myset_new REPLACE
1.7 MOVE:将 Redis 中的指定键移动到另一个数据库中

MOVE命令用于将 Redis 中的指定键移动到另一个数据库中。MOVE key db-
key:要移动的键名。 -
db:目标数据库的索引号,用于指定移动到哪个数据库中。 -
key参数是要移动的键名,必须存在于当前数据库中。 -
db参数是目标数据库的索引号,用于指定移动到哪个数据库中。索引号从 0 开始,Redis 默认支持 16 个数据库,可以通过配置进行扩展。
-
将键
mykey移动到数据库索引号为 1 的数据库中:MOVE mykey 1
-
如果目标数据库
db不存在(例如超过了默认的 0 到 15 的范围),那么MOVE命令会返回错误。 -
如果键
key已经存在于目标数据库db中,那么MOVE命令将无效,不会导致任何数据移动。 -
当键成功移动到目标数据库时,返回
1。 -
如果键已经存在于目标数据库中,或者数据库索引号超出范围,返回
0。
1.8 TOUCH:修改指定键的最后访问时间

在 Redis 中,
TOUCH命令用于修改指定键的最后访问时间(last access time),从而更新键的过期时间。TOUCH key [key ...]-
key:一个或多个要更新最后访问时间的键名。 -
key参数是一个或多个键名,用空格分隔。 -
TOUCH命令主要用于更新 Redis 键的最后访问时间:- 持久化存储:如果键设置了过期时间,通过
TOUCH命令可以防止 Redis 自动清除这些键。 - 活跃用户追踪:可以用于跟踪哪些键最近被访问,用作活跃用户的标记或统计。
- LRU(最近最少使用)策略:Redis 在使用 LRU 策略管理内存时,可以通过
TOUCH命令更新键的访问时间,从而影响键的淘汰顺序。
- 持久化存储:如果键设置了过期时间,通过
-
更新键
mykey的最后访问时间:TOUCH mykey -
更新多个键的最后访问时间:
TOUCH key1 key2 key3
TOUCH命令仅更新键的最后访问时间,不改变键的值或其他属性。- 如果指定的键不存在,
TOUCH命令会忽略该键,不会报错。 TOUCH命令可以用于确保键不会在达到过期时间后被 Redis 主动清理,适用于需要持久化存储的场景。
返回值
redis> SET key1 "Hello" "OK" redis> SET key2 "World" "OK" redis> TOUCH key1 key2 (integer) 2 redis>- 返回更新的键数目,即成功更新了多少个键的最后访问时间。
1.9 RENAME: 修改一个键的名称

在 Redis 中,RENAME命令用于修改一个键的名称。RENAME key newkey-
key:要修改名称的键名。 -
newkey:键的新名称。 -
RENAME命令用于将一个键的名称修改为新的名称。如果新的键名已经存在,则会覆盖原有键的值。
示例
-
将键
mykey的名称修改为newkey:RENAME mykey newkey
- 如果键
key不存在,则RENAME命令会返回错误。 - 如果键
newkey已经存在,它的值将被覆盖。
返回值
redis> SET mykey "Hello" "OK" redis> RENAME mykey myotherkey "OK" redis> GET myotherkey "Hello" redis>- 当命令成功执行时,返回 OK。
1.10 RENAMENX:新名称的键不存在时执行修改
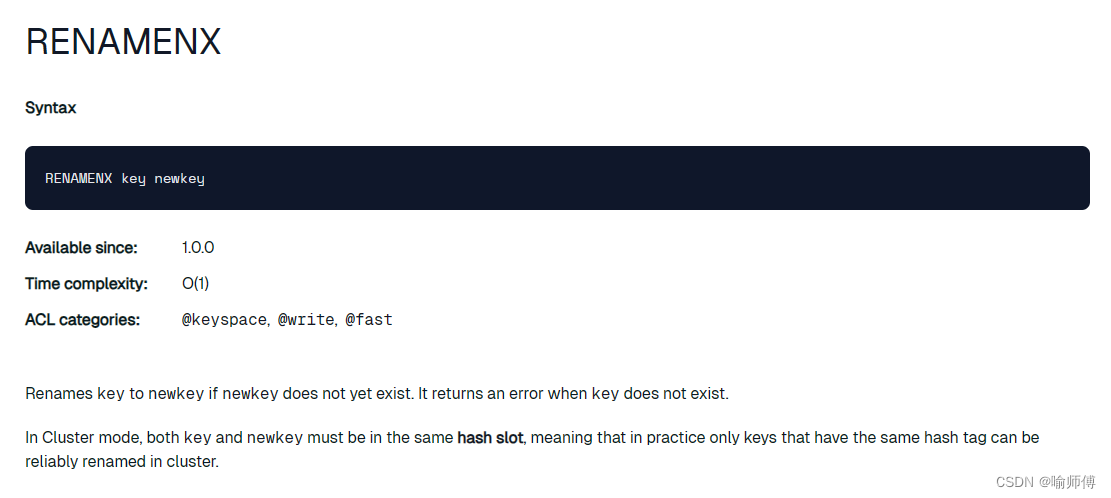
在 Redis 中,
RENAMENX命令用于将一个键的名称修改为新的名称,但只在新名称的键不存在时执行修改。RENAMENX key newkey-
key:要修改名称的键名。 -
newkey:键的新名称。 -
RENAMENX命令会检查新名称newkey是否已经存在。 -
如果
newkey已经存在,则不执行任何操作,返回0。 -
如果
newkey不存在,则将key的名称修改为newkey。 -
如果
key不存在,则RENAMENX命令会返回错误。 -
RENAMENX命令是原子操作,即在执行过程中不会出现部分成功的情况。
redis> SET mykey "Hello" "OK" redis> SET myotherkey "World" "OK" redis> RENAMENX mykey myotherkey (integer) 0 redis> GET myotherkey "World" redis>- 当成功将
key的名称修改为newkey时,返回1。 - 如果
newkey已经存在,没有执行修改操作,则返回0。
1.11 TYPE:返回键所存储的值的类型

TYPE命令用于返回键所存储的值的类型。TYPE keykey:要查询类型的键名。
redis> SET key1 "value" "OK" redis> LPUSH key2 "value" (integer) 1 redis> SADD key3 "value" (integer) 1 redis> TYPE key1 "string" redis> TYPE key2 "list" redis> TYPE key3 "set" redis>返回值
- 返回键存储值的类型,可能的返回值有:
"none":键不存在。"string":字符串类型。"list":列表类型。"set":集合类型。"zset":有序集合类型。"hash":哈希类型。"stream":流类型。
注意事项
- 如果键不存在,命令会返回
"none"。 - 如果键存储的值类型不在预期范围内,可能是由于该键已被其他操作修改。
- 在 Redis 中,同一个键可以在不同时间存储不同类型的值。
1.12 PERSIST:移除 Redis 键的过期时间

PERSIST命令用于移除 Redis 键的过期时间,使得键成为永久有效的,不再自动过期。PERSIST keykey:要移除过期时间的键名。
返回值
redis> SET mykey "Hello" "OK" redis> EXPIRE mykey 10 (integer) 1 redis> TTL mykey (integer) 10 redis> PERSIST mykey (integer) 1 redis> TTL mykey (integer) -1 redis>- 如果成功移除过期时间,返回
1。 - 如果键不存在过期时间,或者键不存在,返回
0。
注意事项
- 只有带有过期时间的键才能使用
PERSIST命令来移除过期时间。 - 如果键之前已经被设置为永不过期(即没有设置过期时间),
PERSIST命令会返回0。 - 移除过期时间后,键将永久存在于 Redis 中,直到显式删除。
更多的通用命令可以去官网https://redis.io/docs/latest/commands/?group=generic查看哦~
2.String类型
-
在 Redis 中,String 类型是最简单的存储类型,它的 value 可以是普通字符串、整数类型或浮点类型。不同格式的字符串在底层都是以字节数组形式存储,只是编码方式不同。
-
普通字符串类型的 value 可以存储任意文本数据,而整数类型和浮点类型的 value 则分别代表整数和浮点数,可以对其进行自增、自减等操作。
-
需要注意的是,无论是哪种格式,String 类型的 value 在 Redis 中的最大空间不能超过 512MB。这个限制是为了确保 Redis 在内存管理方面有较好的性能表现。
2.1 SET:添加或者修改已经存在的一个String类型的键值对

SET key value [EX seconds] [PX milliseconds] [NX|XX]其中:
key是要设置的键名。value是要设置的键值。- 可选参数
EX seconds或PX milliseconds用于设置键的过期时间,EX表示以秒为单位设置过期时间,PX表示以毫秒为单位设置过期时间。 - 可选参数
NX或XX用于控制是否只在 key 不存在时进行设置,NX表示只在 key 不存在时进行设置,XX表示只在 key 已经存在时进行设置。 - 如果命令执行成功,返回结果为
"OK"。
redis> SET mykey "Hello" "OK" redis> GET mykey "Hello" redis> SET anotherkey "will expire in a minute" EX 60 "OK" redis>使用
SET命令将值"Hello"存储在键mykey中,命令返回结果为"OK",表示设置成功。使用
GET命令来获取键mykey的值,返回的结果是"Hello",表示获取成功。使用
SET命令创建了另一个键值对anotherkey,并使用EX参数设置了它的过期时间为 60 秒,命令返回结果为"OK",表示设置成功。
2.2 GET:根据key获取String类型的value

redis> GET nonexisting (nil) redis> SET mykey "Hello" "OK" redis> GET mykey "Hello" redis>
2.3 MSET:批量添加多个String类型的键值对

MSET key1 value1 [key2 value2 ...]其中:
key1、key2等是要设置的键名。value1、value2等是对应键的值。
命令返回结果为
"OK",表示设置成功。redis> MSET key1 "Hello" key2 "World" "OK" redis> GET key1 "Hello" redis> GET key2 "World" redis>
2.4 MGET:根据多个key获取多个String类型的value

MGET 命令用于根据多个 key 获取对应的多个 String 类型的 value。
命令格式为:
MGET key1 [key2 ...]其中:
key1、key2等是要获取 value 的键名。
redis> SET key1 "Hello" "OK" redis> SET key2 "World" "OK" redis> MGET key1 key2 nonexisting 1) "Hello" 2) "World" 3) (nil) redis>nonexisting 这个键不存在,所以对应的值为 (nil)。
2.5 INCR:让一个整型的key自增1

INCR key其中:
key是要增加的整型键名。
使用
SET命令将整型值10存储在键mykey中,然后使用INCR命令对mykey的值进行自增操作,结果返回(integer) 11,表示增加后的值为 11。redis> SET mykey "10" "OK" redis> INCR mykey (integer) 11 redis> GET mykey "11" redis>- If the key does not exist, it is set to 0 before performing the operation. 如果该键不存在,则在执行操作前将其设置为0。
- This operation is limited to 64 bit signed integers.INCR 命令仅适用于64位有符号整数。
- An error is returned if the key contains a value of the wrong type or contains a string that can not be represented as integer. 如果键包含错误类型的值(非整数),或者字符串值无法表示为整数,将返回错误。
- this is a string operation because Redis does not have a dedicated integer type.The string stored at the key is interpreted as a base-10 64 bit signed integer to execute the operation. Redis没有专门的整数类型,因此存储在键中的字符串值将被解释为十进制的64位有符号整数来执行操作。
- Redis stores integers in their integer representation, so for string values that actually hold an integer, there is no overhead for storing the string representation of the integer.Redis以整数表示存储整数,因此对于实际保存整数的字符串值,不需要额外存储整数的字符串表示。
2.6 INCRBY:让一个整型的key自增并指定步长

通过使用
INCRBY命令,可以方便地对整型键的值进行按指定步长的自增或自减操作。INCRBY key increment其中:
key是要增加的整型键名。increment是增加的步长,可以是正数或负数。
使用
SET命令将整型值10存储在键mykey中
使用INCRBY命令对mykey的值增加5,结果返回(integer) 15,表示增加后的值为 15。
使用INCRBY命令对mykey的值减少3,结果返回(integer) 12,表示减少后的值为 12。redis> SET mykey 10 "OK" redis> INCRBY mykey 5 (integer) 15 redis> INCRBY mykey -3 (integer) 12- If the key does not exist, it is set to 0 before performing the operation. 如果该键不存在,则在执行操作前将其设置为0。
- This operation is limited to 64 bit signed integers.INCRBY 命令仅适用于64位有符号整数。
- An error is returned if the key contains a value of the wrong type or contains a string that can not be represented as integer. 如果键包含错误类型的值(非整数),或者字符串值无法表示为整数,将返回错误。
- Redis没有专门的整数类型,因此存储在键中的字符串值将被解释为十进制的64位有符号整数来执行操作。
- Redis以整数表示存储整数,因此对于实际保存整数的字符串值,不需要额外存储整数的字符串表示。
2.7 INCRBYFLOAT:让一个浮点类型的数字自增并指定步长

INCRBYFLOAT key increment其中:
key是要增加的浮点键名。increment是增加的步长,可以是正数或负数,且可以包含小数部分。
示例:
redis> SET mykey 10.5 "OK" redis> INCRBYFLOAT mykey 0.5 "11" redis> INCRBYFLOAT mykey -1.5 "9.5"redis> SET mykey 10.50 "OK" redis> INCRBYFLOAT mykey 0.1 "10.6" redis> INCRBYFLOAT mykey -5 "5.6" redis> SET mykey 5.0e3 "OK" redis> INCRBYFLOAT mykey 2.0e2 "5200" redis>- 如果键不存在,会先将其设置为 0.0。
- 如果键包含错误类型的值(非字符串),或者字符串值无法解析为浮点数,会返回错误。
- INCRBYFLOAT 使用双精度浮点数进行计算,但返回值的精确度固定为小数点后17位,多余的尾随零将被移除。
- 对于指数形式的输入,如 1.2e3,Redis 在存储计算结果时会保持其浮点数形式。
2.8 SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行

SETNX命令用于添加一个 String 类型的键值对,前提是指定的 key 不存在,如果 key 已经存在,则不执行任何操作。SETNX is short for “SET if Not eXists”.
SETNX key value其中:
key是要设置的键名。value是要设置的值。
示例:
redis> SETNX mykey "Hello" (integer) 1 redis> SETNX mykey "World" (integer) 0 redis> GET mykey "Hello"使用
SETNX命令尝试将"Hello"设置为键mykey的值,由于mykey之前不存在,所以成功执行,返回(integer) 1。再次使用
SETNX命令尝试将"World"设置为键mykey的值,但由于mykey已经存在,所以不执行任何操作,返回(integer) 0。最后使用
GET命令获取mykey的值,结果返回"Hello"。
2.9 SETEX:添加一个String类型的键值对,并且指定有效期

SETEX命令用于添加一个 String 类型的键值对,并为该键值对设置指定的过期时间(单位为秒)。如果键已经存在,则会覆盖已有的值,并设置新的过期时间。SETEX key seconds valuekey是要设置的键名。seconds是键值对的过期时间,单位为秒。value是要设置的值。
示例:
redis> SETEX mykey 10 "Hello" "OK" redis> TTL mykey (integer) 10使用
SETEX命令将值为"Hello"的键值对设置到键mykey中,并且指定过期时间为10秒。使用
TTL命令查询mykey的剩余过期时间,返回(integer) 10,表示该键值对还有 10 秒过期。
2.10 MSETNX :设置多个键值对,但只有在所有指定的键都不存在时才执行设置操作

Sets the given keys to their respective values. MSETNX will not perform any operation at all even if just a single key already exists.
设置多个键值对,但只有在所有指定的键都不存在时才执行设置操作。
如果至少有一个键已经存在,则不会对任何键进行设置。
通过
MSETNX命令,可以在特定条件下批量设置多个键的值,从而简化多个单独设置的操作。MSETNX key value [key value ...]key value:成对出现的键值对,可以指定多个键值对。
返回值
redis> MSETNX key1 "Hello" key2 "there" (integer) 1 redis> MSETNX key2 "new" key3 "world" (integer) 0 redis> MGET key1 key2 key3 1) "Hello" 2) "there" 3) (nil) redis>命令执行后,返回一个整数值:
1表示所有键都设置成功,且没有一个键存在。0表示至少有一个键已经存在,没有键被设置。
注意事项
MSETNX是一个原子操作,要么所有键都被设置,要么一个键都不被设置。- 如果需要设置的键值对中有某个键已经存在,可以考虑使用
MSET命令来替代,MSET会覆盖已存在的键值。 - 在分布式环境下,使用
MSETNX可以确保多个键的设置操作是原子的,避免并发操作导致的问题。
2.11 APPEND:将指定的值追加到已存在键的值末尾

APPEND命令是 Redis 中用于将指定的值追加到已存在键的值末尾。如果键不存在,
APPEND将创建一个新的键并将给定值作为其初始值。通过
APPEND命令,可以方便地向已有字符串末尾追加数据,而不需要读取和重写整个字符串。APPEND key valuekey:要操作的键。value:要追加的值。
返回值
redis> EXISTS mykey (integer) 0 redis> APPEND mykey "Hello" (integer) 5 redis> APPEND mykey " World" (integer) 11 redis> GET mykey "Hello World" redis>命令执行后,返回一个整数值,表示追加操作完成后键的值的长度。
示例
-
追加值到一个不存在的键:
APPEND mykey "Hello"如果
mykey不存在,这个命令会创建mykey并将其值设置为"Hello"。返回值是5,因为"Hello"的长度是5。 -
追加值到一个已有的键:
APPEND mykey " World"假设
mykey的当前值是"Hello",这个命令会将" World"追加到"Hello"后面,因此mykey的新值变成"Hello World"。返回值是11,因为"Hello World"的长度是11。
注意事项
APPEND针对的是字符串类型的键。如果键的现有值不是字符串类型,会返回错误。- 尽管
APPEND操作可以处理非常大的字符串,但在实际使用中需要注意字符串的大小,以避免内存问题。
2.12 DECR:将指定键的值减一

DECR命令是 Redis 中用于将指定键的值减一的命令。该键的值必须是一个可以解析为整数的字符串。
如果键不存在,Redis 会将其初始化为
0然后再执行递减操作。DECR keykey:要递减值的键。
返回值
redis> SET mykey "10" "OK" redis> DECR mykey (integer) 9 redis> SET mykey "234293482390480948029348230948" "OK" redis> DECR mykey (error) value is not an integer or out of range redis>命令执行后,返回一个整数值,表示键在递减之后的值。
示例
-
键存在且值为整数:
假设
mykey的当前值是10:DECR mykey这个命令会将
mykey的值减一,因此新的值为9。返回值是9。 -
键不存在:
如果
mykey不存在:DECR mykeyRedis 会将
mykey初始化为0,然后对其执行递减操作。新的值为-1。返回值是-1。 -
键的值不是整数:
如果
mykey的当前值是"hello"这样一个无法解析为整数的字符串:DECR mykey这个命令会返回一个错误,因为
"hello"不能被解析为整数。
注意事项
DECR命令只能对可以解析为整数的字符串值进行操作。- This operation is limited to 64 bit signed integers.对于超出 64 位带符号整数范围的值,Redis 会返回一个错误。因此需要确保数值在合理范围内。
DECR操作是原子的,可以在并发环境中安全使用。
2.13 DECRBY:将指定键的值减去给定的整数

DECRBY命令是 Redis 中用于将指定键的值减去给定的整数 decrement 的命令。该键的值必须是一个可以解析为整数的字符串。
如果键不存在,Redis 会将其初始化为
0然后再执行递减操作。DECRBY key decrementkey:要递减值的键。decrement:要减去的整数值。
返回值
redis> SET mykey "10" "OK" redis> DECRBY mykey 3 (integer) 7 redis>命令执行后,返回一个整数值,表示键在递减之后的值。
示例
-
键存在且值为整数:
假设
mykey的当前值是10:DECRBY mykey 3这个命令会将
mykey的值减去3,因此新的值为7。返回值是7。 -
键不存在:
如果
mykey不存在:DECRBY mykey 5Redis 会将
mykey初始化为0,然后对其执行递减操作,即0 - 5 = -5。返回值是-5。 -
键的值不是整数:
如果
mykey的当前值是"hello"这样一个无法解析为整数的字符串:DECRBY mykey 2这个命令会返回一个错误,因为
"hello"不能被解析为整数。
注意事项
DECRBY命令只能对可以解析为整数的字符串值进行操作。- 对于超出 64 位带符号整数范围的值,Redis 会返回一个错误。因此需要确保数值在合理范围内。
DECRBY操作是原子的,可以在并发环境中安全使用。
2.14 GETDEL:获取指定键的值并将该键删除

GETDEL命令是 Redis 6.2 版本中引入的一个命令,用于获取指定键的值并将该键删除。它结合了
GET和DEL操作:返回键的值,并在读取值之后删除这个键。GETDEL keykey:要获取并删除的键。
返回值
redis> SET mykey "Hello" "OK" redis> GETDEL mykey "Hello" redis> GET mykey (nil) redis>- 如果键存在,返回键的值。
- 如果键不存在,返回
nil。
示例
-
键存在:
假设
mykey的当前值是"Hello":GETDEL mykey这个命令会返回
"Hello"并删除键mykey。 -
键不存在:
如果
mykey不存在:GETDEL mykey这个命令会返回
nil。
使用场景
- 一次性读取和删除:在某些情况下,你可能需要读取一个键的值并在读取后立即删除它,比如处理消息队列中的单个消息。
- 简化操作:通过一个命令实现读取和删除操作,减少网络通信次数和代码复杂度。
注意事项
- 原子性:
GETDEL命令是原子的,即读取和删除操作是在同一个原子性操作中完成的,确保了数据一致性。 - 版本要求:
GETDEL命令需要 Redis 6.2 或更高版本支持,如果使用的是较低版本的 Redis,需要通过其他方式组合GET和DEL操作。

2.15 GETEX:获取一个键的值,并且可以选择性地设置该键的过期时间或者移除其过期时间

GETEX命令是 Redis 6.2 引入的一个命令,它用于获取一个键的值,并且可以选择性地设置该键的过期时间或者移除其过期时间。这个命令结合了
GET和EXPIRE的功能。GETEX key [EX seconds | PX milliseconds | EXAT unix-time-seconds | PXAT unix-time-milliseconds | PERSIST]key:要获取值并设置过期时间的键。EX seconds:以秒为单位设置过期时间。PX milliseconds:以毫秒为单位设置过期时间。EXAT unix-time-seconds:指定到 Unix 时间戳(秒)设置过期时间。PXAT unix-time-milliseconds:指定到 Unix 时间戳(毫秒)设置过期时间。PERSIST:移除键的过期时间。
返回值
redis> SET mykey "Hello" "OK" redis> GETEX mykey "Hello" redis> TTL mykey (integer) -1 redis> GETEX mykey EX 60 "Hello" redis> TTL mykey (integer) 60 redis>- 如果键存在,返回键的值。
- 如果键不存在,返回
nil。
示例
-
用
EX设置过期时间:假设
mykey的当前值是"Hello":GETEX mykey EX 10这个命令会返回
"Hello",同时将mykey的过期时间设置为 10 秒。 -
用
PX设置过期时间:GETEX mykey PX 5000这个命令会返回
"Hello",同时将mykey的过期时间设置为 5000 毫秒(5 秒)。 -
用
EXAT设置过期时间:GETEX mykey EXAT 1654291200这个命令会返回
"Hello",同时将mykey的过期时间设置为 Unix 时间戳 1654291200(例如某个具体日期和时间)。 -
用
PXAT设置过期时间:GETEX mykey PXAT 1654291200000这个命令会返回
"Hello",同时将mykey的过期时间设置为 Unix 时间戳 1654291200000 毫秒。 -
移除过期时间:
GETEX mykey PERSIST这个命令会返回
"Hello",同时移除mykey的过期时间,使其变成永久键。
使用场景
- 延长过期时间:在某些情况下,你可能需要读取一个键的值并延长其过期时间,例如用户会话管理。
- 设置绝对过期时间:需要在特定时间点让键过期,而不是相对时间。
- 移除过期时间:有时你可能需要使一个临时键变为永久键,移除其过期时间。
注意事项
- 原子性:
GETEX命令是原子的,即读取和设置过期时间操作是在同一个原子性操作中完成的,确保了数据一致性。 - 版本要求:
GETEX命令需要 Redis 6.2 或更高版本支持,如果使用的是较低版本的 Redis,需要通过其他方式组合GET和EXPIRE操作。

2.16 GETRANGE:获取指定键(key)的字符串值中参数指定的子字符串

GETRANGE命令用于获取指定键(key)的字符串值中,由start和end参数指定的子字符串。这个命令在 Redis 2.4 版本以后可用。
GETRANGE key start endkey:要获取子字符串的键。start:子字符串的起始位置(包括该位置的字符)。end:子字符串的结束位置(包括该位置的字符)。
返回值
redis> SET mykey "This is a string" "OK" redis> GETRANGE mykey 0 3 "This" redis> GETRANGE mykey -3 -1 "ing" redis> GETRANGE mykey 0 -1 "This is a string" redis> GETRANGE mykey 10 100 "string" redis>命令返回指定键的字符串值中,由
start和end参数指定的子字符串。示例
假设有个键
mykey的值为"Hello, World!"。GETRANGE mykey 0 4这个命令会返回
"Hello",因为从位置 0 开始到位置 4 的子字符串是"Hello"。GETRANGE mykey 7 11这个命令会返回
"World",因为从位置 7 开始到位置 11 的子字符串是"World"。GETRANGE mykey 7 -1这个命令会返回
"World!",因为从位置 7 开始到末尾的子字符串是"World!"。注意事项
GETRANGE命令使用的是 0-based 索引,即第一个字符的索引为 0。- 如果
start参数超出字符串的范围,或者end参数小于start参数,那么返回的子字符串为空字符串。 - 如果
start或end参数为负数,则表示从字符串末尾开始的偏移量,例如-1表示倒数第一个字符。 - 在 Redis 中,字符串的长度是按照字节数来计算的,而非字符数。所以如果字符串包含多字节字符(如 UTF-8 编码的字符),需要特别注意子字符串的起始和结束位置。
2.17 GETSET:设置给定键(key)对应的值,同时返回该键的旧值

GETSET命令用于设置给定键(key)对应的值,同时返回该键的旧值。GETSET key valuekey:要设置值的键。value:新的值。
返回值
redis> SET mykey "Hello" "OK" redis> GETSET mykey "World" "Hello" redis> GET mykey "World" redis>- 如果键存在,返回键的旧值。
- 如果键不存在,返回
nil。
示例
假设有个键
mykey的当前值为"Hello":-
使用
GETSET命令设置新值:GETSET mykey "World"这个命令会返回
"Hello",因为这是mykey的旧值。执行完该命令后,mykey的值变为"World"。 -
如果键不存在:
假设没有
newkey这个键:GETSET newkey "Foo"这个命令会返回
nil,因为newkey键之前不存在。执行完该命令后,newkey的值变为"Foo"。
使用场景
-
原子操作:
GETSET命令是原子的,它可以确保在设置新值和返回旧值之间没有其他操作干扰,这在某些需要确保数据一致性的场景中非常重要。 -
缓存机制:在缓存的实现中,可以使用
GETSET来确保在更新缓存值时获取到旧的缓存内容。
注意事项
GETSET会覆盖键的现有值,因此要谨慎使用,确保不会意外覆盖关键数据。- 如果键的值非常大,使用
GETSET可能会导致较高的网络带宽消耗,因为它会返回旧值并传输到客户端。
2.18 STRLEN:返回指定键(key)对应的字符串值的长度

STRLEN命令用于返回指定键(key)对应的字符串值的长度。STRLEN keykey:要获取长度的键。
返回值
redis> SET mykey "Hello world" "OK" redis> STRLEN mykey (integer) 11 redis> STRLEN nonexisting (integer) 0 redis>命令返回指定键的字符串值的长度。
示例
假设有个键
mykey的值为"Hello, World!"。STRLEN mykey这个命令会返回
13,因为字符串"Hello, World!"包含 13 个字符。注意事项
STRLEN命令可以用于获取字符串的长度,无论是 ASCII 字符还是包含多字节字符(如 UTF-8 编码的字符)。- 如果键不存在,那么返回值为
0。 - 如果键对应的值不是字符串类型,那么会返回一个错误。
更多的string命令可以去官网https://redis.io/docs/latest/commands/?group=string查看哦~

2. 19 key结构
Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key呢?
例如,需要存储用户、商品信息到redis,有一个用户id是1,有一个商品id恰好也是1,此时如果使用id作为key,那就会冲突了,该怎么办?
在 Redis 中,为了区分不同类型的键并避免冲突,可以采用给键添加前缀的方式。这种方法能够有效地组织数据,并确保数据的结构清晰可见。
举个例子,假设我们在 Redis 中存储了用户和文章两种类型的数据。为了区分它们,我们可以使用以下格式定义键:
- 用户相关的键:user:1
- 文章相关的键:article:1
这样,即使我们有相同 ID 的用户和文章,由于前缀的存在,它们也会成为不同的键,不会发生冲突。
如果我们要将一个 Java 对象存储到 Redis 中,可以先将对象序列化为 JSON 字符串,然后将其作为键的值存储。比如,我们有一个名为 “user1” 的用户对象,我们可以将其序列化为以下 JSON 字符串:
{ "id": 1, "name": "yushifu", "age": 23 }然后将其存储为键值对:
user:1 -> {"id": 1, "name": "yushifu", "age": 23}这样做既能保持数据的结构,又能方便地进行数据的反序列化和操作。
3.Hash类型
-
Redis中的Hash类型可以存储类似于Java中HashMap结构的无序字典,它提供了对单个字段进行CRUD操作的能力。
-
相比于将整个对象序列化为字符串再存储的String类型,使用Hash类型可以更方便地修改和访问对象的各个字段。
-
在Hash结构中,每个字段都对应一个值,这使得我们可以针对单个字段进行操作,而不需要反序列化整个对象。这样可以提高效率,并且更加灵活地处理字段的增删改查。
3.1 HSET:添加或者修改hash类型key的field的值

HSET命令用于将一个或多个字段-值对设置到哈希表中。如果字段已经存在于哈希表中,它的值将被更新。HSET key field value [field value ...]key:要操作的哈希表键。field:要设置的字段。value:字段对应的值。
返回值
redis> HSET myhash field1 "Hello" (integer) 1 redis> HGET myhash field1 "Hello" redis> HSET myhash field2 "Hi" field3 "World" (integer) 2 redis> HGET myhash field2 "Hi" redis> HGET myhash field3 "World" redis> HGETALL myhash 1) "field1" 2) "Hello" 3) "field2" 4) "Hi" 5) "field3" 6) "World" redis>- 当字段是哈希表中的一个新字段时,返回 1。
- 当字段已经存在于哈希表中,且值被更新时,返回 0。
示例
假设有个键
myhash的哈希表如下:myhash: field1: value1 field2: value2使用
HSET命令设置新字段和更新字段的值:HSET myhash field3 value3这个命令会在
myhash中设置新字段field3,其值为value3。由于field3是一个新字段,所以命令返回 1。HSET myhash field2 newvalue2这个命令会将
field2的值更新为newvalue2。由于field2已经存在于哈希表中,所以命令返回 0。
3.2 HGET :获取一个hash类型key的field的值

HGET命令用于获取哈希表中指定字段的值。HGET key fieldkey:要操作的哈希表键。field:要获取值的字段。
返回值
redis> HSET myhash field1 "foo" (integer) 1 redis> HGET myhash field1 "foo" redis> HGET myhash field2 (nil) redis>- 当字段存在于哈希表中时,返回字段的值。
- 当字段不存在时,返回
nil。
示例
myhash: field1: value1 field2: value2 field3: value3使用
HGET命令获取字段的值:HGET myhash field2这个命令会返回
value2,因为field2的值是value2。HGET myhash field4这个命令会返回
nil,因为field4不存在于哈希表中。
3.3 HMSET:批量添加多个hash类型key的field的值

HMSET命令用于同时设置哈希表中多个字段的值。HMSET key field value [field value ...]key:要操作的哈希表键。field:要设置的字段。value:字段对应的值。
返回值
redis> HMSET myhash field1 "Hello" field2 "World" "OK" redis> HGET myhash field1 "Hello" redis> HGET myhash field2 "World" redis>命令不返回任何值。
示例
myhash: field1: value1 field2: value2使用
HMSET命令同时设置多个字段的值:HMSET myhash field3 value3 field4 value4这个命令会将
field3的值设置为value3,并将field4的值设置为value4。如果字段已经存在于哈希表中,则会被更新;如果字段不存在,则会被创建。现在,
myhash的哈希表如下:myhash: field1: value1 field2: value2 field3: value3 field4: value4
3.4 HMGET:批量获取多个hash类型key的field的值

HMGET命令用于同时获取哈希表中一个或多个字段的值。HMGET key field [field ...]key:要操作的哈希表键。field:一个或多个要获取值的字段。
返回值
redis> HSET myhash field1 "Hello" (integer) 1 redis> HSET myhash field2 "World" (integer) 1 redis> HMGET myhash field1 field2 nofield 1) "Hello" 2) "World" 3) (nil) redis>返回一个数组,数组中的元素为对应字段的值。如果字段不存在,则返回
nil。示例
myhash: field1: value1 field2: value2 field3: value3使用
HMGET命令获取多个字段的值:HMGET myhash field1 field2 field4这个命令会返回一个数组
["value1", "value2", nil]。因为field1对应的值是value1,field2对应的值是value2,而field4不存在于哈希表中,所以返回nil。HMGET命令允许一次性获取多个字段的值,非常方便。- 返回的值顺序与请求的字段顺序相同,即使某些字段的值为
nil,数组中也会对应位置返回nil。 - 如果
key不存在,则返回一个空数组。
3.5 HGETALL:获取一个hash类型的key中的所有的field和value

HGETALL命令用于获取哈希表中所有字段和对应的值。HGETALL keykey:要操作的哈希表键。
返回值
redis> HSET myhash field1 "Hello" (integer) 1 redis> HSET myhash field2 "World" (integer) 1 redis> HGETALL myhash 1) "field1" 2) "Hello" 3) "field2" 4) "World" redis>返回一个数组,数组中的元素为字段和对应的值交替排列。如果哈希表为空,返回一个空数组。
示例
myhash: field1: value1 field2: value2 field3: value3使用
HGETALL命令获取哈希表中所有字段和对应的值:HGETALL myhash这个命令会返回一个数组
["field1", "value1", "field2", "value2", "field3", "value3"]。注意
- 返回的数组中,字段和对应的值是交替排列的。
- 如果哈希表为空,返回一个空数组。
3.6 HKEYS:获取一个hash类型的key中的所有的field

HKEYS命令用于获取哈希表中所有的字段(键)。HKEYS keykey:要操作的哈希表键。
返回值
redis> HSET myhash field1 "Hello" (integer) 1 redis> HSET myhash field2 "World" (integer) 1 redis> HKEYS myhash 1) "field1" 2) "field2" redis>返回一个数组,数组中的元素为哈希表中所有的字段(键)。
示例
myhash: field1: value1 field2: value2 field3: value3使用
HKEYS命令获取哈希表中所有的字段(键):HKEYS myhash这个命令会返回一个数组
["field1", "field2", "field3"],其中包含了哈希表中的所有字段。注意
- 返回的数组中的字段顺序不确定。
- 如果哈希表为空,返回一个空数组。
3.7 HINCRBY:让一个hash类型key的字段值自增并指定步长

HINCRBY命令用于为哈希表中的字段值加上指定增量值。如果字段不存在,
HINCRBY会先将其值设为 0,然后再执行增加操作。HINCRBY很适合用于需要对计数进行递增或递减操作的场景,例如统计点击量、计数器等。HINCRBY key field incrementkey:要操作的哈希表键。field:要增加值的字段。increment:要增加的值,可以为负数。
返回值
redis> HSET myhash field 5 (integer) 1 redis> HINCRBY myhash field 1 (integer) 6 redis> HINCRBY myhash field -1 (integer) 5 redis> HINCRBY myhash field -10 (integer) -5 redis>返回字段的增量操作后的值。
示例
假设有个键
myhash的哈希表如下:myhash: field1: 5 field2: 10使用
HINCRBY命令增加字段field1的值:HINCRBY myhash field1 3这个命令会将
field1的值增加 3,因此新的值为 8,并返回 8。如果字段不存在:
HINCRBY myhash field3 7这个命令会先将
field3的值设为 0,然后增加 7,因此新的值为 7,并返回 7。注意
HINCRBY只适用于值为整数的字段,如果字段值不能转换为整数(例如是字符串),则会返回一个错误。increment可以为负数,这样可以实现减法操作。- 如果哈希表或者字段不存在,会自动创建并进行相应的增量操作。
3.8 HDEL:用于从哈希表中删除一个或多个字段

HDEL命令用于从哈希表中删除一个或多个字段。HDEL key field [field ...]key:要操作的哈希表键。field [field ...]:要删除的字段列表,可以同时删除多个字段。
返回值
redis> HSET myhash field1 "foo" (integer) 1 redis> HDEL myhash field1 (integer) 1 redis> HDEL myhash field2 (integer) 0 redis>返回被成功移除的字段数量,不包括那些不存在的字段。
示例
假设有个键
myhash的哈希表如下:myhash: field1: value1 field2: value2 field3: value3使用
HDEL命令删除字段field1:HDEL myhash field1这个命令会删除哈希表
myhash中的field1字段,并返回 1,表示成功移除了一个字段。如果要删除多个字段,可以在命令中同时指定多个字段:
HDEL myhash field2 field3这个命令会删除哈希表
myhash中的field2和field3字段,并返回 2,表示成功移除了两个字段。如果删除的字段不存在,不会报错,而是简单地忽略。
注意
- 删除哈希表中不存在的字段将被忽略,不会报错。
- 如果指定的键不存在,
HDEL命令将返回 0,表示没有字段被移除。
3.9 HEXISTS:检查哈希表中指定字段是否存在

HEXISTS命令用于检查哈希表中指定字段是否存在。HEXISTS key fieldkey:要操作的哈希表键。field:要检查的字段。
返回值
redis> HSET myhash field1 "foo" (integer) 1 redis> HEXISTS myhash field1 (integer) 1 redis> HEXISTS myhash field2 (integer) 0 redis>返回整数:
- 1:如果字段在哈希表中存在。
- 0:如果字段在哈希表中不存在,或者键不存在。
示例
假设有一个键
myhash的哈希表如下:myhash: field1: value1 field2: value2 field3: value3使用
HEXISTS命令检查字段field1是否存在:HEXISTS myhash field1这个命令会返回
1,表示字段field1存在。如果检查一个不存在的字段,例如
field4:HEXISTS myhash field4这个命令会返回
0,表示字段field4不存在。如果哈希表
myhash本身不存在:HEXISTS nonexistent_hash somefield这个命令也会返回
0,表示字段不存在,因为哈希表本身就不存在。使用场景
HEXISTS命令通常用于以下场景:- 在更新哈希表中的某个字段之前,先检查该字段是否已经存在。
- 确认某个字段是否已经被设置,以决定下一步操作。
- 在业务逻辑中需要进行条件判断时使用。
3.10 HLEN:获取哈希表中字段的数量

HLEN命令用于获取哈希表中字段的数量。HLEN keykey:要操作的哈希表键。
返回值
redis> HSET myhash field1 "Hello" (integer) 1 redis> HSET myhash field2 "World" (integer) 1 redis> HLEN myhash (integer) 2 redis>返回整数,表示哈希表中字段的数量。
示例
假设有一个键
myhash的哈希表如下:myhash: field1: value1 field2: value2 field3: value3使用
HLEN命令获取哈希表中字段的数量:HLEN myhash这个命令会返回 3,表示哈希表中共有 3 个字段。
如果指定的键不存在,或者键对应的值不是哈希表类型,那么
HLEN命令会返回 0。HLEN nonexistent_key这个命令会返回 0,表示指定的键不存在。
HLEN nonhash_key这个命令也会返回 0,表示指定的键不是哈希表类型。
使用场景
HLEN命令可以用于以下场景:- 统计哈希表中字段的数量,用于监控和分析数据。
- 判断哈希表是否为空,以便进行相应的处理逻辑。
- 在业务逻辑中根据哈希表字段的数量进行条件判断。
更多的Hash命令可以去官网https://redis.io/docs/latest/commands/?group=hash查看哦~
4.List类型
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
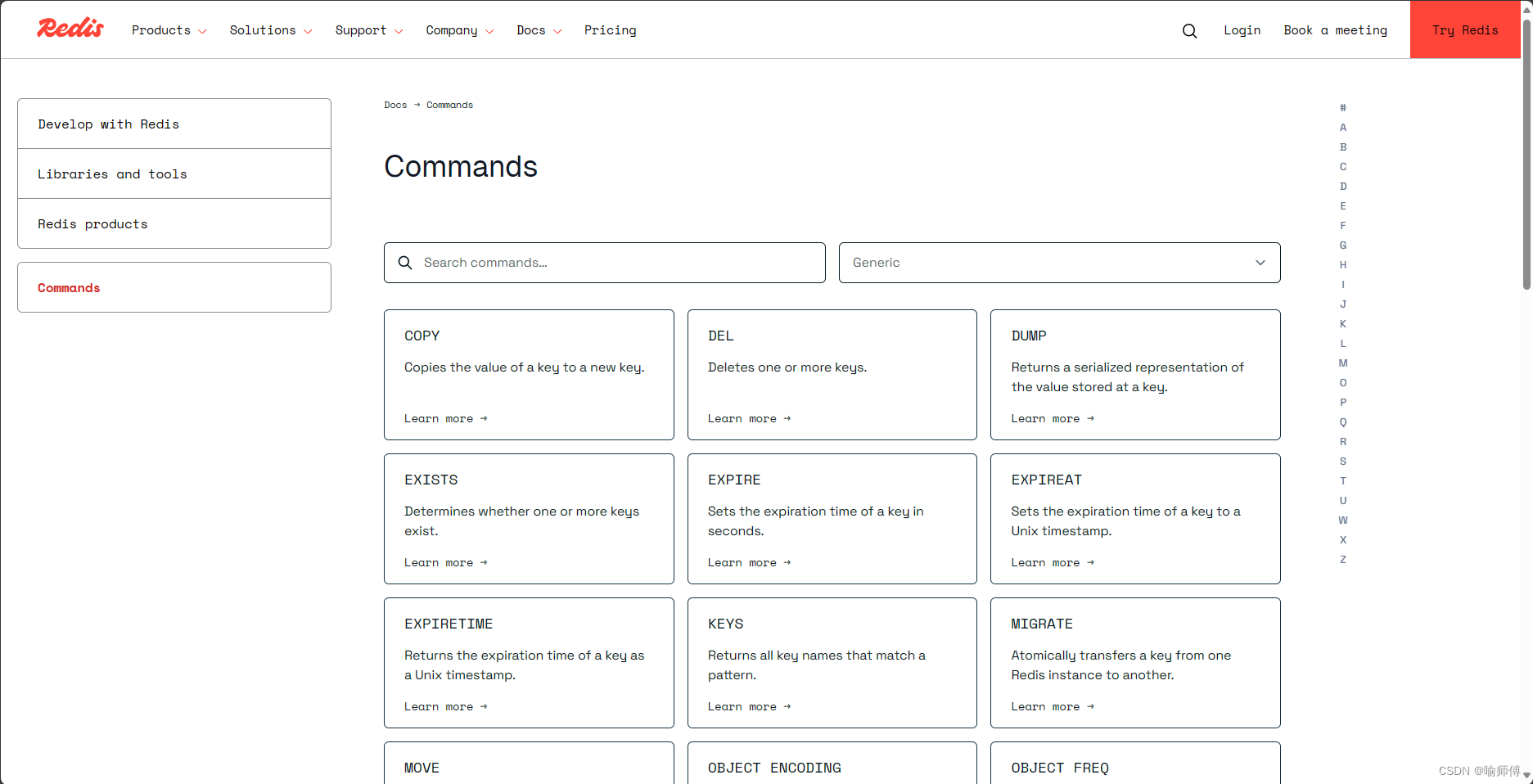
4.1 LPUSH:将一个或多个值插入到列表头部
LPUSH是 Redis 中用于将一个或多个值插入到列表头部的命令。该命令会将指定的值按顺序推入列表的左侧,即列表的头部。
如果列表不存在,会创建一个新的列表。
LPUSH key value [value ...]key: 列表的键名。value: 要插入到列表头部的一个或多个值。
示例
假设我们有一个空列表
mylist。- 将单个值插入列表:
LPUSH mylist "world"执行后,
mylist的内容是:["world"]- 将多个值插入列表(按从左到右的顺序依次插入):
LPUSH mylist "hello"执行后,
mylist的内容是:["hello", "world"]- 再次插入多个值:
LPUSH mylist "a" "b" "c"执行后,
mylist的内容变为:["c", "b", "a", "hello", "world"]返回值
redis> LPUSH mylist "world" (integer) 1 redis> LPUSH mylist "hello" (integer) 2LPUSH命令返回插入后列表的长度。使用场景
- 消息队列:可以使用
LPUSH和RPOP组合实现一个简单的消息队列,生产者使用LPUSH将消息推入队列,消费者使用RPOP从队列尾部取出消息。 - 栈操作:与
LPOP配合,可以实现栈的功能(后进先出)。 - 维持最近访问记录:可以通过
LPUSH将最新访问的记录插入到列表头部,再结合LTRIM限制列表长度,维持一个固定大小的最近访问记录列表。
注意事项
- 列表的最大长度受限于 Redis 配置和可用内存。在大多数应用中,请确保不会无限制地增加列表大小,以避免潜在的性能问题。
- Redis 列表在内部使用双向链表实现,因此在列表头部和尾部进行插入和删除操作的时间复杂度都是 O(1)。

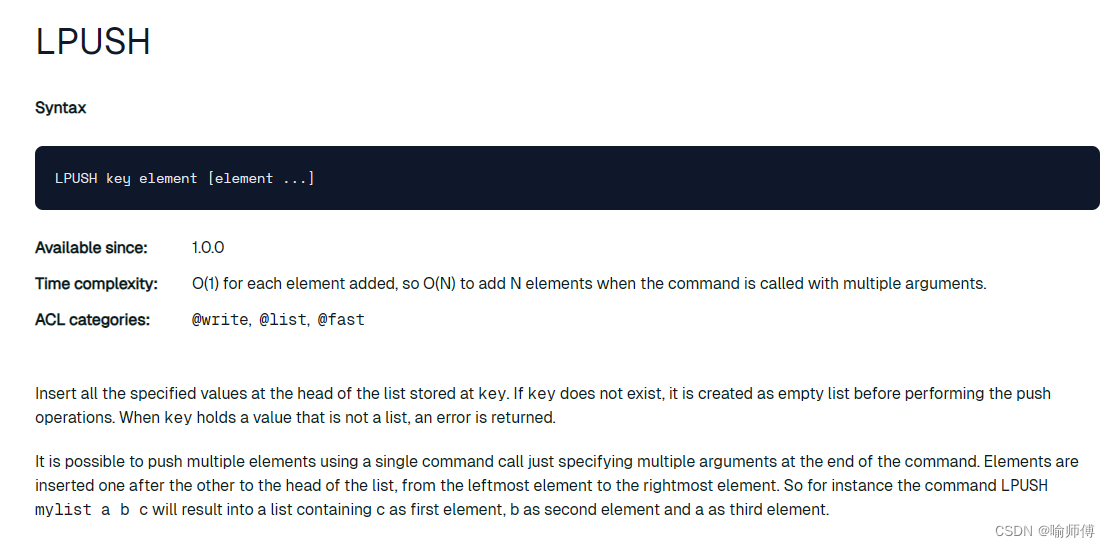
4.2 RPUSH:将一个或多个值插入到列表尾部
RPUSH是 Redis 中用于将一个或多个值插入到列表尾部(右侧)的命令。该命令会将指定的值按顺序推入列表的右侧,如果列表不存在,会创建一个新的列表。
RPUSH key value [value ...]key: 列表的键名。value: 要插入到列表尾部的一个或多个值。
示例
假设我们有一个空列表
mylist。- 将单个值插入列表:
RPUSH mylist "hello"执行后,
mylist的内容是:["hello"]- 将多个值插入列表(按从左到右的顺序依次插入):
RPUSH mylist "world" "!"执行后,
mylist的内容是:["hello", "world", "!"]- 再次插入多个值:
RPUSH mylist "a" "b" "c"执行后,
mylist的内容变为:["hello", "world", "!", "a", "b", "c"]返回值
redis> RPUSH mylist "hello" (integer) 1 redis> RPUSH mylist "world" (integer) 2RPUSH命令返回插入后列表的长度。使用场景
- 消息队列:可以使用
RPUSH和LPOP组合实现一个简单的消息队列,生产者使用RPUSH将消息推入队列,消费者使用LPOP从队列头部取出消息。 - 队列操作:与
LPOP配合,可以实现先进先出的队列功能。 - 日志记录:可以使用
RPUSH将日志条目追加到列表末尾,方便按时间顺序记录和查看日志。
注意事项
- 列表的最大长度受限于 Redis 配置和可用内存。在大多数应用中,请确保不会无限制地增加列表大小,以避免潜在的性能问题。
- Redis 列表在内部使用双向链表实现,因此在列表头部和尾部进行插入和删除操作的时间复杂度都是 O(1)。
4.3 LPOP:从列表头部弹出并移除一个或多个元素
LPOP是 Redis 中用于从列表头部(左侧)弹出并移除一个或多个元素的命令。该命令返回被弹出的元素,如果列表为空则返回
nil。在 Redis 6.2 及其之后的版本中,
LPOP命令得到了扩展,增加了一个可选的count参数。这个扩展使得
LPOP可以一次从列表头部弹出多个元素,而不仅仅是一个。LPOP key [count]key: 列表的键名。count: (可选)要弹出的元素数量,如果不指定,则默认为 1。
示例
假设我们有一个列表
mylist,其内容是:["a", "b", "c", "d", "e"]- 从列表头部弹出一个元素:
LPOP mylist执行后,返回值是
"a",列表的内容变为:["b", "c", "d", "e"]- 一次弹出多个元素(如弹出 3 个元素):
LPOP mylist 3执行后,返回值是
["b", "c", "d"],列表的内容变为:["e"]- 如果弹出的数量超过列表的长度,例如列表只剩下一个元素:
LPOP mylist 2执行后,返回值是
["e"],列表变为空:[]- 如果列表已经为空,再次尝试弹出:
LPOP mylist执行后,返回值是
nil,因为列表为空。返回值
redis> RPUSH mylist "one" "two" "three" "four" "five" (integer) 5 redis> LPOP mylist "one" redis> LPOP mylist 2 1) "two" 2) "three" redis> LRANGE mylist 0 -1 1) "four" 2) "five" redis>- 当
count未指定时,LPOP返回被弹出的单个元素(字符串)。 - 当
count指定时,LPOP返回一个包含被弹出元素的列表。 - 如果列表不存在或为空,
LPOP返回nil。
使用场景
- 批量处理:可以使用带
count的LPOP实现批量数据处理,从列表中一次性获取多个元素,提高处理效率。 - 队列操作:结合
RPUSH和LPUSH,可以实现复杂的队列和栈操作。 - 流式数据处理:可以用来逐批获取数据进行流式处理,适用于需要高吞吐量的应用。
注意事项
- 在使用带
count的LPOP时,请注意列表的长度,以避免请求弹出超过列表长度的元素。如果count超过列表长度,LPOP只返回当前列表中所有的元素。 - 如果频繁进行批量弹出操作,可能会对性能产生影响,需要根据具体使用场景进行性能测试和优化。
4.4 RPOP:从列表尾部弹出一个或多个元素

在 Redis 6.2 及其之后的版本中,RPOP命令得到了扩展,增加了一个可选的count参数。这个扩展使得
RPOP可以一次从列表尾部弹出多个元素,而不仅仅是一个。RPOP key [count]key: 列表的键名。count: (可选)要弹出的元素数量,如果不指定,则默认为 1。
示例
假设我们有一个列表
mylist,其内容是:["a", "b", "c", "d", "e"]- 从列表尾部弹出一个元素:
RPOP mylist执行后,返回值是
"e",列表的内容变为:["a", "b", "c", "d"]- 一次弹出多个元素(如弹出 3 个元素):
RPOP mylist 3执行后,返回值是
["d", "c", "b"],列表的内容变为:["a"]- 如果弹出的数量超过列表的长度,例如列表只剩下一个元素:
RPOP mylist 2执行后,返回值是
["a"],列表变为空:[]- 如果列表已经为空,再次尝试弹出:
RPOP mylist执行后,返回值是
nil,因为列表为空。返回值
- 当
count未指定时,RPOP返回被弹出的单个元素(字符串)。 - 当
count指定时,RPOP返回一个包含被弹出元素的列表。 - 如果列表不存在或为空,
RPOP返回nil。
使用场景
- 批量处理:可以使用带
count的RPOP实现批量数据处理,从列表中一次性获取多个元素,提高处理效率。 - 队列操作:结合
RPUSH和LPUSH,可以实现复杂的队列和栈操作。 - 流式数据处理:可以用来逐批获取数据进行流式处理,适用于需要高吞吐量的应用。
注意事项
- 在使用带
count的RPOP时,请注意列表的长度,以避免请求弹出超过列表长度的元素。如果count超过列表长度,RPOP只返回当前列表中所有的元素。 - 如果频繁进行批量弹出操作,可能会对性能产生影响,需要根据具体使用场景进行性能测试和优化。
4.5 LLEN:获取 Redis 列表的长度
LLEN命令用于获取 Redis 列表的长度。它返回指定键所对应的列表中元素的数量。如果键不存在,则返回 0。
LLEN keykey: 列表的键名。
示例
["a", "b", "c", "d", "e"]- 获取列表的长度:
LLEN mylist执行后,返回值是
5,因为列表中有 5 个元素。- 如果列表为空:
假设我们清空了
mylist:DEL mylist LLEN mylist执行后,返回值是
0,因为列表不存在。- 如果键不存在:
LLEN nonexistentlist执行后,返回值也是
0,因为该键不存在。返回值
redis> LPUSH mylist "World" (integer) 1 redis> LPUSH mylist "Hello" (integer) 2 redis> LLEN mylist (integer) 2LLEN返回指定列表的长度(整数)。
4.6 LRANGE:获取 Redis 列表中指定范围内的元素
LRANGE命令用于获取 Redis 列表中指定范围内的元素。该命令可以从列表的任意位置开始,返回一段子序列。
LRANGE key start stopkey: 列表的键名。start: 起始索引,可以是正数或负数。如果为负数,则表示从列表末尾开始计数,例如 -1 表示最后一个元素,-2 表示倒数第二个元素。stop: 结束索引,可以是正数或负数。如果为负数,则表示从列表末尾开始计数,例如 -1 表示最后一个元素,-2 表示倒数第二个元素。
返回值
redis> RPUSH mylist "one" (integer) 1 redis> RPUSH mylist "two" (integer) 2 redis> RPUSH mylist "three" (integer) 3 redis> LRANGE mylist 0 0 1) "one" redis> LRANGE mylist -3 2 1) "one" 2) "two" 3) "three" redis> LRANGE mylist -100 100 1) "one" 2) "two" 3) "three" redis> LRANGE mylist 5 10 (empty array) redis>返回一个包含指定范围内的元素的列表。如果
start大于stop,则返回空列表;如果键不存在,则返回空列表。示例
["a", "b", "c", "d", "e"]- 获取列表中从索引 1 到 3 的元素:
LRANGE mylist 1 3执行后,返回值是:
["b", "c", "d"]- 获取列表中从第一个元素到第三个元素:
LRANGE mylist 0 2执行后,返回值是:
["a", "b", "c"]- 获取列表的最后两个元素:
LRANGE mylist -2 -1执行后,返回值是:
["d", "e"]- 获取整个列表:
LRANGE mylist 0 -1执行后,返回值是:
["a", "b", "c", "d", "e"]- 如果
start大于stop,返回空列表:
LRANGE mylist 3 1执行后,返回值是:
[]- 如果列表为空或键不存在,返回空列表:
LRANGE emptylist 0 -1 LRANGE nonexistentlist 0 -1执行后,返回值都是:
[]使用场景
- 分页:可以使用
LRANGE实现简单的分页功能,从列表中取出特定范围内的元素进行展示。 - 流式数据处理:适用于需要从列表中按块读取和处理数据的场景。
- 子序列获取:在数据分析中,
LRANGE可以方便地获取列表中的子序列进行进一步处理。
注意事项
- 索引从 0 开始计数,负数索引从列表末尾开始计数。
start和stop参数超出实际列表长度时,Redis 会自动调整为有效范围内的最大索引。- 操作时间复杂度为 O(S+N),其中 S 是要跳过的元素数量,N 是要返回的元素数量,因此对于非常大的列表应注意性能问题。
4.7 LPUSHX:将一个或多个元素插入到已存在的列表头部
LPUSHX是 Redis 中用于将一个或多个元素插入到已存在的列表头部的命令。如果指定的列表不存在,则该操作无任何效果。
通过
LPUSHX,可以在 Redis 中对已存在的列表高效地进行头部插入操作,而无需担心意外创建新的列表。LPUSHX key element [element ...]key: 列表的键名。element: 要插入列表头部的一个或多个元素。
返回值
redis> LPUSH mylist "World" (integer) 1 redis> LPUSHX mylist "Hello" (integer) 2 redis> LPUSHX myotherlist "Hello" (integer) 0 redis> LRANGE mylist 0 -1 1) "Hello" 2) "World" redis> LRANGE myotherlist 0 -1 (empty array) redis>返回插入操作后列表的长度。
示例
假设我们有一个列表
mylist,其内容是:["c", "d"]- 将元素
"a"和"b"插入到列表头部:
LPUSHX mylist a b执行后,列表变为:
["b", "a", "c", "d"]返回值是:
4,表示列表现在包含 4 个元素。- 尝试向不存在的列表
nonexistentlist插入元素:
LPUSHX nonexistentlist x因为列表
nonexistentlist不存在,所以此操作不起作用,返回值是:0。使用场景
- 条件性插入:适用于只有在列表已存在时才需要插入新元素的场景。例如,在提供某种特定服务时,只在服务已经启动并存在相关记录的情况下添加新的请求。
- 数据更新:可以用于在列表已经初始化的情况下,更新列表前端的数据。
注意事项
- 与
LPUSH不同,LPUSHX不会创建新的列表,因此使用这个命令之前要确保列表已经存在。 - 如果需要确保在不存在列表时创建列表,可以使用
LPUSH命令。
4.8 RPUSHX:将一个或多个元素插入到已存在的列表尾部
RPUSHX:与LPUSHX类似,这里就不再赘述。
redis> RPUSH mylist "Hello" (integer) 1 redis> RPUSHX mylist "World" (integer) 2 redis> RPUSHX myotherlist "World" (integer) 0 redis> LRANGE mylist 0 -1 1) "Hello" 2) "World" redis> LRANGE myotherlist 0 -1 (empty array) redis>
4.9 LSET:设置列表中指定索引位置的元素值

LSET是 Redis 中用于设置列表中指定索引位置的元素值的命令。LSET key index elementkey: 列表的键名。index: 要设置的元素位置的索引。正数索引从 0 开始,负数索引从 -1 开始表示最后一个元素,以此类推。element: 要设置的新值。
返回值
redis> RPUSH mylist "one" (integer) 1 redis> RPUSH mylist "two" (integer) 2 redis> RPUSH mylist "three" (integer) 3 redis> LSET mylist 0 "four" "OK" redis> LSET mylist -2 "five" "OK" redis> LRANGE mylist 0 -1 1) "four" 2) "five" 3) "three" redis>-
成功时返回
OK。如果索引超出范围或列表不存在,会返回错误。 -
如果指定的索引超出了列表的范围(即索引在列表长度范围之外),会报错。
-
如果列表不存在,也会报错。
示例
假设我们有一个列表
mylist,其内容是:["a", "b", "c", "d"]- 将索引为 1 的元素设置为
"x":
LSET mylist 1 x执行后,列表变为:
["a", "x", "c", "d"]返回值是:
OK- 使用负数索引将最后一个元素设置为
"z":
LSET mylist -1 z执行后,列表变为:
["a", "x", "c", "z"]返回值是:
OK- 尝试设置超出索引范围的元素:
LSET mylist 10 y因为索引 10 超出范围,所以会报错:
(error) ERR index out of range- 尝试对不存在的列表进行操作:
LSET nonexistentlist 0 y因为列表
nonexistentlist不存在,所以会报错:(error) ERR no such key使用场景
- 更新特定元素:适用于需要更新列表中某个特定位置的元素值的场景,例如修改某个用户在等待队列中的优先级。
- 修正数据:可以用于修正列表中已经存在的数据,而无需重新创建整个列表。
注意事项
- 索引超出范围会报错,因此在进行
LSET操作前最好检查列表的长度。 - 如果列表不存在,不会自动创建列表而是直接报错,所以确保列表已存在再进行
LSET操作。
4.10 BLPOP:与LPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil

BLPOP是 Redis 中用于从一个或多个列表的头部弹出元素的命令,它是一个阻塞命令,即如果列表为空,它会等待直到有元素可弹出或超时。BLPOP key [key ...] timeoutkey [key ...]: 一个或多个列表的键名。如果指定多个列表,BLPOP会按顺序检查并弹出第一个非空列表的头部元素。timeout: 超时时间,单位为秒。如果在超时时间内没有元素可弹出,则命令返回nil。
返回值
如果有可弹出的元素,则返回一个包含两个元素的数组
[key, element],其中key是被弹出元素的列表的键名,element是被弹出的元素值。如果超时时间到达仍无元素可弹出,则返回nil。行为说明
BLPOP会按照列表参数的顺序检查每个列表,并弹出第一个非空列表的头部元素。- 如果列表不存在或为空,
BLPOP会阻塞等待直到超时或有元素可弹出。 - 超时时间设为 0 表示阻塞时间无限长。
示例
假设我们有两个列表
list1和list2,分别包含以下元素:list1: ["a", "b"] list2: ["c"]- 弹出
list1的头部元素:
BLPOP list1 0执行后,返回值是:
["list1", "a"],并且list1变为["b"]。- 尝试弹出
list2和list1,以list2优先:
BLPOP list2 list1 0执行后,返回值是:
["list2", "c"],并且list2变为空列表。- 当所有列表都为空时,设置超时等待:
BLPOP list1 list2 10如果在 10 秒内任何列表有元素可弹出,返回相应的键名和元素;否则,超过 10 秒后返回
nil。使用场景
- 队列处理:适用于实现简单的消息队列,例如任务分发和异步处理。
- 阻塞等待:当需要从多个列表中获取数据,并且希望在列表为空时进行阻塞等待时,使用
BLPOP可以有效地实现此功能。
注意事项
BLPOP是阻塞命令,会一直等待直到超时或有元素可弹出,因此需要谨慎
4.11 BRPOP:同BLPOP

同BLPOP,这里就不再赘述。
更多的List命令可以去官网https://redis.io/docs/latest/commands/?group=list查看哦~
5.Set类型
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
-
无序
-
元素不可重复
-
查找快
-
支持交集、并集、差集等功能
5.1 SADD:向集合(Set)中添加一个或多个成员

SADD是 Redis 中用于向集合(Set)中添加一个或多个成员的命令。SADD key member [member ...]key: 集合的键名。member: 要添加到集合中的一个或多个成员。
返回值
redis> SADD myset "Hello" (integer) 1 redis> SADD myset "World" (integer) 1 redis> SADD myset "World" (integer) 0返回被添加到集合中的新成员的数量,不包括已经存在于集合中的成员。
行为说明
- 对于每个指定的成员,如果该成员不在集合中,则将其添加到集合中。
- 如果集合不存在,则会创建一个新的集合并添加指定的成员。
- 如果指定的成员已经是集合的成员,则该成员不会重复添加,操作不产生任何变化。
示例
假设有一个集合
myset,初始时是空集合。- 向集合
myset中添加成员"apple":
SADD myset apple执行后,集合变为
{"apple"},返回值是:1。- 继续向集合
myset中添加成员"orange"和"banana":
SADD myset orange banana执行后,集合变为
{"apple", "orange", "banana"},返回值是:2。因为"orange"和"banana"都是新添加的成员。- 尝试重复添加成员
"apple":
SADD myset apple由于
"apple"已经是集合myset的成员,不会重复添加,集合保持不变。返回值是:0。使用场景
- 集合操作:适用于需要管理独特成员集合的场景,例如存储用户的标签、记录已处理的任务等。
- 去重:用于确保集合中的元素是唯一的,避免重复数据的存在。
- 快速查找:集合支持快速的成员查找和操作,适合需要频繁检查成员存在性的场景。
注意事项
- 集合中的成员是唯一的,重复添加同一成员不会导致集合内容重复。
- 如果集合不存在,Redis 会自动创建空集合并执行添加操作。
5.2 SCARD:获取集合(Set)中成员数量

SCARD是 Redis 中用于获取集合(Set)中成员数量的命令。SCARD keykey: 集合的键名。
返回值
redis> SADD myset "Hello" (integer) 1 redis> SADD myset "World" (integer) 1 redis> SCARD myset (integer) 2返回集合中的成员数量。
行为说明
- 如果指定的键不存在,返回 0,表示空集合。
- 如果指定的键对应的值不是集合类型,会返回错误。
示例
假设有一个集合
myset,其中包含了一些成员。- 获取集合
myset中的成员数量:
SCARD myset假设集合
myset中有 3 个成员,那么返回值就是:3。- 获取一个空集合的成员数量:
SCARD emptyset假设集合
emptyset是一个空集合,返回值就是:0。注意事项
- 如果键对应的值不是集合类型,会返回错误,因此在使用
SCARD命令前最好确认键对应的值确实是集合类型。
5.3 SDIFF:获取多个集合之间的差集

SDIFF是 Redis 中用于获取多个集合之间的差集(差异)的命令。SDIFF key [key ...]key: 要计算差集的集合键名,可以指定多个集合键名。
返回值
redis> SADD key1 "a" (integer) 1 redis> SADD key1 "b" (integer) 1 redis> SADD key1 "c" (integer) 1 redis> SADD key2 "c" (integer) 1 redis> SADD key2 "d" (integer) 1 redis> SADD key2 "e" (integer) 1 redis> SDIFF key1 key2 1) "a" 2) "b"返回一个包含差集成员的列表,即第一个集合与其他集合之间的差异部分。
行为说明
- 对于给定的多个集合,计算它们之间的差集。
- 结果集中包含的是第一个集合与其他集合之间的差异部分,即第一个集合中存在,而其他集合中不存在的成员。
示例
假设有两个集合
set1和set2,分别含有一些成员。- 计算
set1与set2之间的差集:
SDIFF set1 set2假设
set1中有成员{"a", "b", "c"},而set2中有成员{"b", "c", "d"},那么执行上述命令后,返回值就是{"a"},表示set1中存在而set2中不存在的成员。使用场景
- 数据比较:用于比较多个集合之间的成员差异,找出不同部分的数据。
- 数据清洗:可以利用差集操作从数据集中排除一些特定的成员。
注意事项
- 差集操作只能计算两个集合之间的差异,如果需要计算多个集合之间的差集,需要多次调用
SDIFF命令。 - 如果指定的某个集合不存在,将视为空集合处理。
5.4 SDIFFSTORE:计算多个集合之间的差集,并将结果存储在指定的目标集合中

SDIFFSTORE是 Redis 中用于计算多个集合之间的差集,并将结果存储在指定的目标集合中的命令。SDIFFSTORE destination key [key ...]destination: 差集结果要存储的目标集合的键名。key: 要计算差集的一个或多个集合键名。
返回值
返回存储在目标集合中的成员数量。
行为说明
- 计算多个集合之间的差集(即第一个集合与其他集合之间的差异部分),并将差集结果存储在指定的目标集合中。
- 如果目标集合已经存在,它将被覆盖。
- 如果指定的某个集合不存在,将视为空集合处理。
示例
假设有两个集合
set1和set2,分别包含一些成员,并且要将它们的差集存储到集合resultSet中。- 计算
set1与set2之间的差集,并将结果存储到resultSet:
SDIFFSTORE resultSet set1 set2假设
set1中有成员{"a", "b", "c"},而set2中有成员{"b", "c", "d"},执行上述命令后,resultSet将包含{"a"},表示set1中存在而set2中不存在的成员。返回值是1,表示结果集中有一个成员。
5.5 SMEMBERS:获取指定集合中所有成员

SMEMBERS是 Redis 中用于获取指定集合中所有成员的命令。SMEMBERS keykey: 要获取成员列表的集合键名。
返回值
redis> SADD myset "Hello" (integer) 1 redis> SADD myset "World" (integer) 1 redis> SMEMBERS myset 1) "Hello" 2) "World"返回一个包含集合中所有成员的列表。
行为说明
- 返回指定集合中的所有成员。
- 如果集合不存在(被认为是一个空集合),则返回空列表。
- 结果集中的成员顺序不固定,因为它们是无序的。
示例
假设有一个集合
myset,其中包含一些成员:SMEMBERS myset如果
myset中有成员{"member1", "member2", "member3"},那么执行上述命令后,将返回{"member1", "member2", "member3"},即集合中的所有成员列表。注意事项
- 对于大型集合,考虑成员数量可能会对性能产生影响,因此在处理大型数据时需谨慎使用。
- 集合中的成员顺序是无序的,因此不能依赖返回的顺序。
5.6 SISMEMBER:检查指定成员是否存在于集合中

SISMEMBER是 Redis 中用于检查指定成员是否存在于集合中的命令。SISMEMBER key memberkey: 要检查的集合键名。member: 要检查是否存在的成员。
返回值
redis> SADD myset "one" (integer) 1 redis> SISMEMBER myset "one" (integer) 1 redis> SISMEMBER myset "two" (integer) 0返回布尔值:
1表示成员存在于集合中。0表示成员不存在于集合中或者集合本身不存在。
行为说明
- 检查指定成员是否存在于指定的集合中。
- 如果集合不存在,或者成员不在集合中,则返回
0。 - 如果成员存在于集合中,则返回
1。
示例
假设有一个集合
myset,其中包含成员{"member1", "member2", "member3"}:-
检查成员
"member1"是否存在于集合myset中:SISMEMBER myset "member1"如果
"member1"存在于myset中,该命令将返回1。 -
检查成员
"member4"是否存在于集合myset中:SISMEMBER myset "member4"因为
"member4"不在myset中,该命令将返回0。
注意事项
SISMEMBER命令在集合不存在或成员不存在时都会返回0,因此需要根据返回值来判断具体情况。- 成员的存在性检查是集合操作中的常见需求,因为 Redis 的集合数据结构支持高效的成员查找和检索。
5.7 SREM:从集合中移除一个或多个成员

SREM是 Redis 中用于从集合中移除一个或多个成员的命令。SREM key member [member ...]key: 要操作的集合键名。member [member ...]: 要从集合中移除的一个或多个成员。
返回值
redis> SADD myset "one" (integer) 1 redis> SADD myset "two" (integer) 1 redis> SADD myset "three" (integer) 1 redis> SREM myset "one" (integer) 1 redis> SREM myset "four" (integer) 0返回被成功移除的成员数量,不包括不存在的成员。
行为说明
- 从指定集合中移除一个或多个成员。
- 如果成员在集合中不存在,则被忽略,不会报错。
- 如果集合在执行操作前不存在,则会被视为空集合处理。
示例
集合
myset,其中包含成员{"member1", "member2", "member3"}:-
移除单个成员
"member2":SREM myset "member2"执行后,集合
myset中将只剩下{"member1", "member3"}。 -
移除多个成员
"member1"和"member3":SREM myset "member1" "member3"执行后,集合
myset将变为空集合。 -
尝试移除不存在的成员
"nonexistent":SREM myset "nonexistent"因为
"nonexistent"不在myset中,该命令不会产生任何影响,并返回0。
注意事项
SREM操作是原子的,即在执行期间不会有其他客户端能够对同一集合进行操作。- 虽然
SREM对不存在的成员不会报错,但执行过程中会返回实际移除的成员数量。
5.8 SINTER:计算多个集合的交集

SINTER是 Redis 中用于计算多个集合的交集的命令。

SINTER key [key ...]key [key ...]: 一个或多个集合键名。
返回值
返回一个包含交集成员的列表。
行为说明
- 计算给定多个集合的交集。
- 如果其中一个或多个集合不存在,则返回空列表(空集合)。
- 结果集中的每个成员都是同时存在于所有输入集合中的成员。
示例
假设有两个集合
set1和set2:set1中包含成员{"member1", "member2", "member3"}。set2中包含成员{"member2", "member3", "member4"}。
计算它们的交集:
SINTER set1 set2执行后,返回的结果将是
{"member2", "member3"},因为这两个成员是同时存在于set1和set2中。注意事项
- 如果输入的集合中有一个或多个不存在,结果将是空集合。
SINTER命令返回的交集结果是一个新的集合,并不会修改输入的任何集合。
5.9 SMOVE:将一个成员从一个集合移动到另一个集合

SMOVE是 Redis 中用于将一个成员从一个集合移动到另一个集合的命令。SMOVE source destination membersource: 源集合的键名。destination: 目标集合的键名。member: 要移动的成员。
返回值
返回整数值:
1:如果成员被成功移动。0:如果成员未被移动,即成员不存在于源集合中或者成员已存在于目标集合中。
行为说明
- 如果源集合中存在该成员,则将其从源集合移除并添加到目标集合中。
- 如果目标集合中已经存在该成员,或者源集合中不存在该成员,则不会进行任何操作。
- 如果源集合和目标集合是同一集合,该命令相当于什么都不做,但会返回
0。
示例
假设有两个集合
set1和set2:set1中包含成员{"member1", "member2", "member3"}。set2中包含成员{"member4", "member5"}。
移动成员
member2从set1到set2:SMOVE set1 set2 "member2"执行后:
set1将变成{"member1", "member3"}。set2将变成{"member4", "member5", "member2"}。- 返回值为
1。
尝试移动不存在的成员
member6从set1到set2:SMOVE set1 set2 "member6"执行后:
set1和set2保持不变。- 返回值为
0。
注意事项
SMOVE命令是原子的,命令执行过程中不会有其他客户端能够对这两个集合进行操作。- 即使源集合和目标集合是同一个集合,命令也不会报错,但返回
0。
更多的Set命令可以去官网https://redis.io/docs/latest/commands/?group=set查看哦~

6. SortedSet类型
-
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。
-
SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(
SkipList)加 hash表。
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
6.1 ZADD:向有序集合添加成员
添加一个或多个元素到sorted set ,如果已经存在则更新其score值

ZADD是 Redis 中用于向有序集合添加成员的命令。ZADD key [NX|XX] [GT|LT] [CH] [INCR] score member [score member ...]key: 有序集合的键名。NX或XX(可选):用于指定操作的条件,NX表示只在成员不存在时才添加,XX表示只在成员已经存在时才添加。GT或LT(可选):用于指定操作的条件,GT表示只添加比给定分数大的成员,LT表示只添加比给定分数小的成员。CH(可选):表示将返回值设置为新增成员的数量,即使是更新已经存在成员的分数。INCR(可选):表示将成员的分数与给定的增量相加,而不是将成员的分数设置为给定的值。score member [score member ...]: 分数和成员组成的列表,可以一次性添加多个成员。
返回值
返回值为整数,表示添加的成员数量,不包括已经存在并且分数被更新的成员。
行为说明
- 将一个或多个成员添加到有序集合中,或者更新已经存在成员的分数。
- 如果有序集合不存在,将会创建一个新的有序集合并添加成员。
- 如果成员已经存在于有序集合中,它的分数将被更新。
示例
向有序集合
zset1中添加成员member1和member2,并指定分数:ZADD zset1 10 member1 20 member2执行后:
- 如果
zset1不存在,将会被创建并添加成员。 - 如果
member1不存在,则添加member1到zset1并设置分数为10。 - 如果
member2不存在,则添加member2到zset1并设置分数为20。 - 返回值为添加的成员数量,这里是
2。
使用场景
- 排行榜:用于存储和更新排行榜中的成员和分数。
- 数据排序:在需要对数据进行排序和检索时使用。
6.2 ZREM:从有序集合中移除一个或多个成员

ZREM是 Redis 中用于从有序集合中移除一个或多个成员的命令。ZREM key member [member ...]key: 有序集合的键名。member: 要从有序集合中移除的成员。
返回值
返回整数值,表示被成功移除的成员数量。
行为说明
- 从有序集合中移除给定的成员,如果成员不存在于有序集合中,则忽略。
- 如果有序集合在移除成员后变为空集,将自动删除该有序集合的键。
示例
有序集合
zset1,其中包含成员member1、member2和member3:ZADD zset1 10 member1 20 member2 30 member3从有序集合
zset1中移除成员member2:ZREM zset1 member2执行后:
zset1中将只剩下成员member1和member3。- 返回值为
1,表示成功移除了一个成员。
尝试移除不存在的成员
member4:ZREM zset1 member4执行后:
zset1保持不变,因为成员member4不存在。- 返回值为
0,表示没有移除任何成员。
注意事项
ZREM命令是原子的,这意味着在命令执行过程中不会有其他客户端能够对该有序集合进行操作。- 如果有序集合在移除成员后变为空集,将自动删除该有序集合的键。
6.3 ZSCORE : 获取sorted set中的指定元素的score值

ZSCORE是 Redis 中用于获取有序集合中指定成员的分数的命令。ZSCORE key memberkey: 有序集合的键名。member: 要查询分数的成员。
返回值
redis> ZADD myzset 1 "one" (integer) 1 redis> ZSCORE myzset "one" "1"返回字符串形式的成员分数。如果成员不存在于有序集合中,则返回
nil。行为说明
- 查询并返回有序集合中指定成员的分数。
- 如果有序集合或成员不存在,将返回
nil。
示例
有序集合
zset1,其中包含成员member1、member2和member3,其分数分别为10、20和30:ZADD zset1 10 member1 20 member2 30 member3查询
member2的分数:ZSCORE zset1 member2执行后:
- 返回值为
"20",表示member2的分数是20。
查询不存在的成员
member4的分数:ZSCORE zset1 member4执行后:
- 返回值为
nil,因为member4不存在于zset1中。
注意事项
ZSCORE命令是只读的,不会修改有序集合的内容。- 返回值是字符串形式的分数,即使实际分数是一个整数。
6.4 ZRANK:获取sorted set 中的指定元素的排名

ZRANK是 Redis 中用于获取有序集合中指定成员的排名(索引)的命令。ZRANK key member [WITHSCORE]key: 有序集合的键名。member: 要查询排名的成员。WITHSCORE: 可选参数,如果指定了WITHSCORE,则返回成员的排名和分数。
返回值
redis> ZADD myzset 1 "one" (integer) 1 redis> ZADD myzset 2 "two" (integer) 1 redis> ZADD myzset 3 "three" (integer) 1 redis> ZRANK myzset "three" (integer) 2 redis> ZRANK myzset "four" (nil) redis> ZRANK myzset "three" WITHSCORE 1) (integer) 2 2) "3" redis> ZRANK myzset "four" WITHSCORE (nil)如果成员存在于有序集合中,返回成员的排名(从 0 开始)。如果成员不存在于有序集合中,返回
nil。如果指定了
WITHSCORE参数,返回值将是一个包含排名和分数的数组:[排名, 分数]。行为说明
- 查询并返回有序集合中指定成员的排名。
- 如果有序集合中存在多个相同分数的成员,排名按照成员的字典顺序进行排序。
示例
有序集合
zset1,其中包含成员member1、member2和member3,其分数分别为10、20和30:ZADD zset1 10 member1 20 member2 30 member3查询
member2的排名:ZRANK zset1 member2执行后:
- 返回值为
1,表示member2在有序集合中的排名是第二位(索引从 0 开始)。
查询
member4的排名:ZRANK zset1 member4执行后:
- 返回值为
nil,因为member4不存在于zset1中。
使用
WITHSCORE参数查询member2的排名和分数:ZRANK zset1 member2 WITHSCORE执行后:
- 返回值为
["1", "20"],表示member2的排名是第二位,分数是20。
注意事项
ZRANK命令只读,不会修改有序集合的内容。- 如果有序集合中存在多个相同分数的成员,排名将按照成员的字典顺序进行排序。
6.5 ZCARD:获取sorted set中的元素个数

redis> ZADD myzset 1 "one" (integer) 1 redis> ZADD myzset 2 "two" (integer) 1 redis> ZCARD myzset (integer) 26.6 ZCOUNT:统计score值在给定范围内的所有元素的个数

ZCOUNT是 Redis 中用于获取有序集合中指定分数范围内的成员数量的命令。ZCOUNT key min maxkey: 有序集合的键名。min: 分数范围的下限。max: 分数范围的上限。
返回值
redis> ZADD myzset 1 "one" (integer) 1 redis> ZADD myzset 2 "two" (integer) 1 redis> ZADD myzset 3 "three" (integer) 1 redis> ZCOUNT myzset -inf +inf (integer) 3 redis> ZCOUNT myzset (1 3 (integer) 2返回指定分数范围内的成员数量。
行为说明
- 查询并返回有序集合中分数在给定范围内的成员数量,包括边界的成员。
示例
有序集合
zset1,其中包含成员member1、member2和member3,其分数分别为10、20和30:ZADD zset1 10 member1 20 member2 30 member3查询分数在
[15, 25]范围内的成员数量:ZCOUNT zset1 15 25执行后:
- 假设有序集合中没有相同分数的成员,返回值将是
1,因为只有member2的分数在15到25之间。
6.7 ZINCRBY:让sorted set中的指定元素自增,步长为指定的increment值

ZINCRBY是 Redis 中用于对有序集合中指定成员的分数进行增加或减少的命令。ZINCRBY key increment memberkey: 有序集合的键名。increment: 要增加(正数)或减少(负数)的分数。member: 要增加或减少分数的成员。
返回值
redis> ZADD myzset 1 "one" (integer) 1 redis> ZADD myzset 2 "two" (integer) 1 redis> ZINCRBY myzset 2 "one" "3" redis> ZRANGE myzset 0 -1 WITHSCORES 1) "two" 2) "2" 3) "one" 4) "3"返回成员的新分数。
行为说明
- 如果给定的成员不存在于有序集合中,将会新增该成员并设置初始分数。
- 如果给定的成员在有序集合中存在,将会更新该成员的分数。
示例
有序集合
zset1,其中包含成员member1和member2,它们的分数分别是10和20:ZADD zset1 10 member1 20 member2将
member1的分数增加5:ZINCRBY zset1 5 member1执行后:
- 返回值为
15,表示member1的新分数是15。
再将
member2的分数减少3.5:ZINCRBY zset1 -3.5 member2执行后:
- 返回值为
16.5,表示member2的新分数是16.5。
注意事项
ZINCRBY命令可以增加或减少有序集合中成员的分数,如果成员不存在,会新增该成员并设置初始分数。
6.8 ZRANGE:按照score排序后,获取指定排名范围内的元素

ZRANGE是 Redis 中用于获取有序集合中指定范围内成员的命令。支持多种选项来定制输出结果,包括按分数、字典顺序排序,反向排序,以及包含成员分数等。
ZRANGE key start stop [BYSCORE | BYLEX] [REV] [LIMIT offset count] [WITHSCORES]key: 有序集合的键名。start: 开始位置(索引)。stop: 结束位置(索引)。BYSCORE: 按分数排序。BYLEX: 按字典顺序排序。REV: 反向排序。LIMIT offset count: 返回结果的限制和偏移量。WITHSCORES: 包含分数在输出结果中。
参数说明
start和stop可以是负数,表示从集合末尾开始计算。例如,-1表示最后一个元素,-2表示倒数第二个元素,依此类推。BYSCORE和BYLEX不能同时使用。REV可与BYSCORE或BYLEX一起使用,使得结果按指定顺序的反向输出。LIMIT offset count用于分页,offset表示偏移量,count表示返回的最大元素数量。WITHSCORES将成员的分数一起返回。
示例
有序集合
zset1,其中包含以下成员和分数:ZADD zset1 1 "one" 2 "two" 3 "three" 4 "four"获取索引从 0 到 2 的成员:
ZRANGE zset1 0 2返回:
1) "one" 2) "two" 3) "three"获取索引从 0 到 2 的成员,并包含分数:
ZRANGE zset1 0 2 WITHSCORES返回:
1) "one" 2) "1" 3) "two" 4) "2" 5) "three" 6) "3"按分数范围获取成员,从分数 1 到 3:
ZRANGE zset1 1 3 BYSCORE返回:
1) "one" 2) "two" 3) "three"按字典顺序获取成员,并反向排列:
ZRANGE zset1 - + BYLEX REV返回:
1) "two" 2) "three" 3) "one" 4) "four"使用
LIMIT选项来进行分页,获取按分数排序后的前两个成员:ZRANGE zset1 -inf +inf BYSCORE LIMIT 0 2返回:
1) "one" 2) "two"
6.9 ZDIFF、ZINTER、ZUNION:求差集、交集、并集
- ZDIFF

ZDIFF用于计算多个有序集合之间的差集,并将结果存储在新的有序集合中。ZDIFF numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]numkeys: 要进行差集计算的有序集合数量。key: 要进行差集计算的有序集合键名。WEIGHTS weight [weight ...]: 可选参数,用于指定每个有序集合的权重,默认为 1。AGGREGATE SUM|MIN|MAX: 可选参数,指定计算交集时如何聚合分数,默认为SUM。
示例:
ZDIFF 3 zset1 zset2 zset3 WEIGHTS 2 3 1 AGGREGATE MAX- ZINTER

ZINTER用于计算多个有序集合的交集,并将结果存储在新的有序集合中。ZINTER numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]参数说明与
ZDIFF类似,不同之处在于计算的是交集。示例:
ZINTER 3 zset1 zset2 zset3 WEIGHTS 2 3 1 AGGREGATE MAX- ZUNION

ZUNION用于计算多个有序集合的并集,并将结果存储在新的有序集合中。ZUNION numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]参数说明与
ZDIFF和ZINTER类似,不同之处在于计算的是并集。示例:
ZUNION 3 zset1 zset2 zset3 WEIGHTS 2 3 1 AGGREGATE MAX
更多的SortedSet命令可以去官网https://redis.io/docs/latest/commands/?group=sorted-set查看哦~


-
相关阅读:
java-php-python-ssm药房药品采购集中管理系统计算机毕业设计
企业实施设备管理系统的价值?
中国传统节日春节网页HTML代码 春节大学生网页设计制作成品下载 学生网页课程设计期末作业下载 DW春节节日网页作业代码下载
JavaWeb概念视频笔记
基于 ActionFilters 的限流库DotNetRateLimiter使用
Java基础——final关键字
docker 开启 tcp 端口
Python自学教程4-数据类型学什么
Oracle 中文排序 Oracle 中文字段排序
程序员的520花式绘制爱心代码大全
- 原文地址:https://blog.csdn.net/weixin_48935611/article/details/139725213