-
Spring Boot集成antlr实现词法和语法分析
1.什么是antlr?
Antlr4 是一款强大的语法生成器工具,可用于读取、处理、执行和翻译结构化的文本或二进制文件。基本上是当前 Java 语言中使用最为广泛的语法生成器工具。Twitter搜索使用ANTLR进行语法分析,每天处理超过20亿次查询;Hadoop生态系统中的Hive、Pig、数据仓库和分析系统所使用的语言都用到了ANTLR;Lex Machina将ANTLR用于分析法律文本;Oracle公司在SQL开发者IDE和迁移工具中使用了ANTLR;NetBeans公司的IDE使用ANTLR来解析C++;Hibernate对象-关系映射框架(ORM)使用ANTLR来处理HQL语言
基本概念
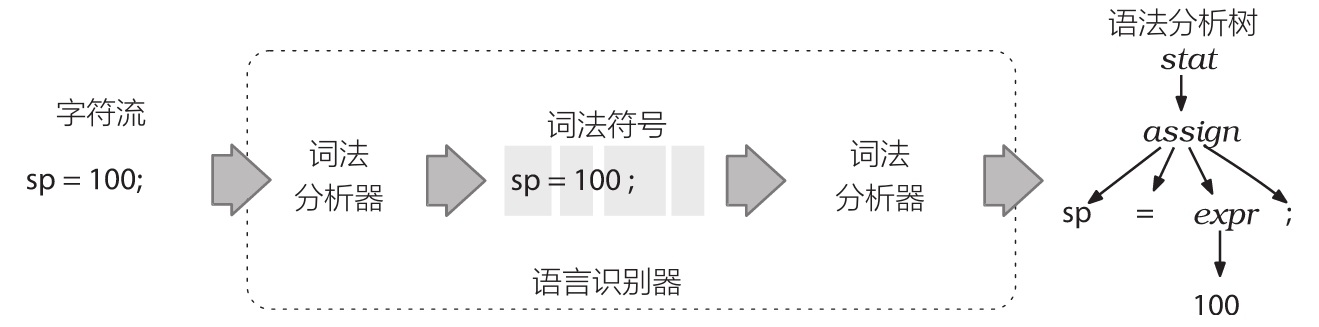
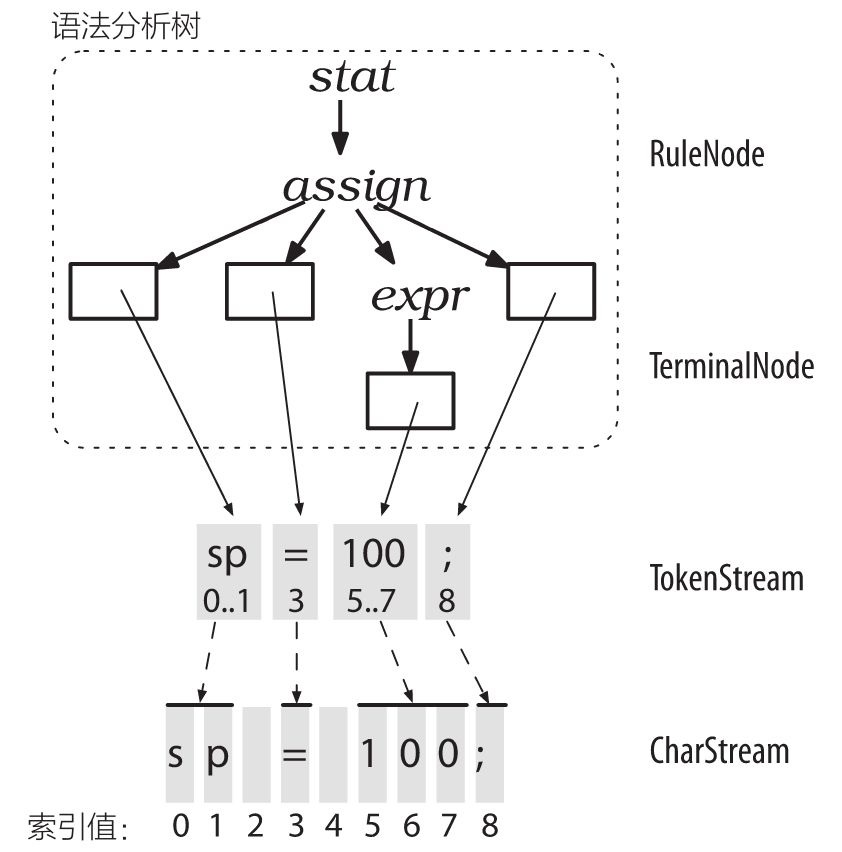
语法分析器(parser)是用来识别语言的程序,本身包含两个部分:词法分析器(lexer)和语法分析器(parser)。词法分析阶段主要解决的关键词以及各种标识符,例如 INT、ID 等,语法分析主要是基于词法分析的结果,构造一颗语法分析树。大致的流程如下图参考2所示。

因此,为了让词法分析和语法分析能够正常工作,在使用 Antlr4 的时候,需要定义语法(grammar),这部分就是 Antlr 元语言。

使用 ANTLR4 编程的基本流程是固定的,通常分为如下三步:
-
基于需求按照 ANTLR4 的规则编写自定义语法的语义规则, 保存成以 g4 为后缀的文件。
-
使用 ANTLR4 工具处理 g4 文件,生成词法分析器、句法分析器代码、词典文件。
-
编写代码继承 Visitor 类或实现 Listener 接口,开发自己的业务逻辑代码。
Listener 模式和 Visitor 模式的区别
Listener 模式:

Visitor 模式:

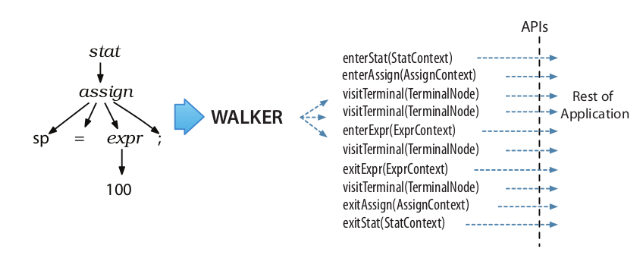
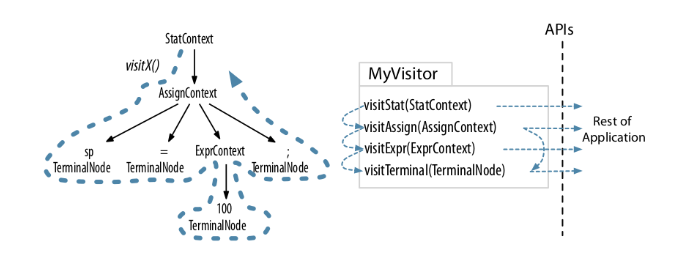
- Listener 模式通过 walker 对象自行遍历,不用考虑其语法树上下级关系。Vistor 需要自行控制访问的子节点,如果遗漏了某个子节点,那么整个子节点都访问不到了。
- Listener 模式的方法没有返回值,Vistor 模式可以设定任意返回值。
- Listener 模式的访问栈清晰明确,Vistor 模式是方法调用栈,如果实现出错有可能导致 StackOverFlow。
2.代码工程
实验目的:实现基于antlr的计算器
pom.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <parent>
- <artifactId>springboot-demo</artifactId>
- <groupId>com.et</groupId>
- <version>1.0-SNAPSHOT</version>
- </parent>
- <modelVersion>4.0.0</modelVersion>
- <artifactId>ANTLR</artifactId>
- <properties>
- <maven.compiler.source>8</maven.compiler.source>
- <maven.compiler.target>8</maven.compiler.target>
- <antlr4.version>4.9.1</antlr4.version>
- </properties>
- <dependencies>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-web</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-autoconfigure</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-test</artifactId>
- <scope>test</scope>
- </dependency>
- <dependency>
- <groupId>org.antlr</groupId>
- <artifactId>antlr4-runtime</artifactId>
- <version>${antlr4.version}</version>
- </dependency>
- </dependencies>
- <build>
- <plugins>
- <plugin>
- <groupId>org.antlr</groupId>
- <artifactId>antlr4-maven-plugin</artifactId>
- <version>${antlr4.version}</version>
- <configuration>
- <sourceDirectory>src/main/java</sourceDirectory>
- <outputDirectory>src/main/java</outputDirectory>
- <arguments>
- <argument>-visitor</argument>
- <argument>-listener</argument>
- </arguments>
- </configuration>
- <executions>
- <execution>
- <goals>
- <goal>antlr4</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
- </plugins>
- </build>
- </project>
元语言LabeledExpr.g4
- grammar LabeledExpr; // rename to distinguish from Expr.g4
- prog: stat+ ;
- stat: expr NEWLINE # printExpr
- | ID '=' expr NEWLINE # assign
- | NEWLINE # blank
- ;
- expr: expr op=('*'|'/') expr # MulDiv
- | expr op=('+'|'-') expr # AddSub
- | INT # int
- | ID # id
- | '(' expr ')' # parens
- ;
- MUL : '*' ; // assigns token name to '*' used above in grammar
- DIV : '/' ;
- ADD : '+' ;
- SUB : '-' ;
- ID : [a-zA-Z]+ ; // match identifiers
- INT : [0-9]+ ; // match integers
- NEWLINE:'\r'? '\n' ; // return newlines to parser (is end-statement signal)
- WS : [ \t]+ -> skip ; // toss out whitespace
简单解读一下 LabeledExpr.g4 文件。ANTLR4 规则是基于正则表达式定义定义。规则的理解是自顶向下的,每个分号结束的语句表示一个规则 。例如第一行:grammar LabeledExpr; 表示我们的语法名称是 LabeledExpr, 这个名字需要跟文件名需要保持一致。Java 编码也有相似的规则:类名跟类文件一致。
- 规则 prog 表示 prog 是一个或多个 stat。
- 规则 stat 适配三种子规则:空行、表达式 expr、赋值表达式 ID’=’expr。
- 表达式 expr 适配五种子规则:乘除法、加减法、整型、ID、括号表达式。很显然,这是一个递归的定义。
最后定义的是组成复合规则的基础元素,比如:规则 ID: [a-zA-Z]+表示 ID 限于大小写英文字符串;INT: [0-9]+; 表示 INT 这个规则是 0-9 之间的一个或多个数字,当然这个定义其实并不严格。再严格一点,应该限制其长度。
在理解正则表达式的基础上,ANTLR4 的 g4 语法规则还是比较好理解的。
定义 ANTLR4 规则需要注意一种情况,即可能出现一个字符串同时支持多种规则,如以下的两个规则:
ID: [a-zA-Z]+;
FROM: ‘from’;
很明显,字符串” from”同时满足上述两个规则,ANTLR4 处理的方式是按照定义的顺序决定。这里 ID 定义在 FROM 前面,所以字符串 from 会优先匹配到 ID 这个规则上。
其实在定义好与法规中,编写完成 g4 文件后,ANTLR4 已经为我们完成了 50%的工作:帮我们实现了整个架构及接口了,剩下的开发工作就是基于接口或抽象类进行具体的实现。实现上有两种方式来处理生成的语法树,其一 Visitor 模式,另一种方式是 Listener(监听器模式)。
生成词法和语法解析器
基于maven插件生成
- <plugin>
- <groupId>org.antlr</groupId>
- <artifactId>antlr4-maven-plugin</artifactId>
- <version>${antlr4.version}</version>
- <configuration>
- <sourceDirectory>src/main/java</sourceDirectory>
- <outputDirectory>src/main/java</outputDirectory>
- <arguments>
- <argument>-visitor</argument>
- <argument>-listener</argument>
- </arguments>
- </configuration>
- <executions>
- <execution>
- <goals>
- <goal>antlr4</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
执行命令
mvn antlr4:antlr4

使用ideal插件生成


实现运算逻辑
第一种:基于visitor实现
- package com.et.antlr;
- import java.util.HashMap;
- import java.util.Map;
- public class EvalVisitor extends LabeledExprBaseVisitor<Integer> {
- // Store variables (for assignment)
- Map<String, Integer> memory = new HashMap<>();
- /** stat : expr NEWLINE */
- @Override
- public Integer visitPrintExpr(LabeledExprParser.PrintExprContext ctx) {
- Integer value = visit(ctx.expr()); // evaluate the expr child
- // System.out.println(value); // print the result
- return value; // return dummy value
- }
- /** stat : ID '=' expr NEWLINE */
- @Override
- public Integer visitAssign(LabeledExprParser.AssignContext ctx) {
- String id = ctx.ID().getText(); // id is left-hand side of '='
- int value = visit(ctx.expr()); // compute value of expression on right
- memory.put(id, value); // store it in our memory
- return value;
- }
- /** expr : expr op=('*'|'/') expr */
- @Override
- public Integer visitMulDiv(LabeledExprParser.MulDivContext ctx) {
- int left = visit(ctx.expr(0)); // get value of left subexpression
- int right = visit(ctx.expr(1)); // get value of right subexpression
- if (ctx.op.getType() == LabeledExprParser.MUL) return left * right;
- return left / right; // must be DIV
- }
- /** expr : expr op=('+'|'-') expr */
- @Override
- public Integer visitAddSub(LabeledExprParser.AddSubContext ctx) {
- int left = visit(ctx.expr(0)); // get value of left subexpression
- int right = visit(ctx.expr(1)); // get value of right subexpression
- if (ctx.op.getType() == LabeledExprParser.ADD) return left + right;
- return left - right; // must be SUB
- }
- /** expr : INT */
- @Override
- public Integer visitInt(LabeledExprParser.IntContext ctx) {
- return Integer.valueOf(ctx.INT().getText());
- }
- /** expr : ID */
- @Override
- public Integer visitId(LabeledExprParser.IdContext ctx) {
- String id = ctx.ID().getText();
- if (memory.containsKey(id)) return memory.get(id);
- return 0; // default value if the variable is not found
- }
- /** expr : '(' expr ')' */
- @Override
- public Integer visitParens(LabeledExprParser.ParensContext ctx) {
- return visit(ctx.expr()); // return child expr's value
- }
- /** stat : NEWLINE */
- @Override
- public Integer visitBlank(LabeledExprParser.BlankContext ctx) {
- return 0; // return dummy value
- }
- }
第二种:基于listener实现
- package com.et.antlr;
- import org.antlr.v4.runtime.tree.ParseTreeProperty;
- import org.antlr.v4.runtime.tree.TerminalNode;
- import java.util.HashMap;
- import java.util.Map;
- public class EvalListener extends LabeledExprBaseListener {
- // Store variables (for assignment)
- private final Map<String, Integer> memory = new HashMap<>();
- // Store expression results
- private final ParseTreeProperty<Integer> values = new ParseTreeProperty<>();
- private int result=0;
- @Override
- public void exitPrintExpr(LabeledExprParser.PrintExprContext ctx) {
- int value = values.get(ctx.expr());
- //System.out.println(value);
- result=value;
- }
- public int getResult() {
- return result;
- }
- @Override
- public void exitAssign(LabeledExprParser.AssignContext ctx) {
- String id = ctx.ID().getText();
- int value = values.get(ctx.expr());
- memory.put(id, value);
- }
- @Override
- public void exitMulDiv(LabeledExprParser.MulDivContext ctx) {
- int left = values.get(ctx.expr(0));
- int right = values.get(ctx.expr(1));
- if (ctx.op.getType() == LabeledExprParser.MUL) {
- values.put(ctx, left * right);
- } else {
- values.put(ctx, left / right);
- }
- }
- @Override
- public void exitAddSub(LabeledExprParser.AddSubContext ctx) {
- int left = values.get(ctx.expr(0));
- int right = values.get(ctx.expr(1));
- if (ctx.op.getType() == LabeledExprParser.ADD) {
- values.put(ctx, left + right);
- } else {
- values.put(ctx, left - right);
- }
- }
- @Override
- public void exitInt(LabeledExprParser.IntContext ctx) {
- int value = Integer.parseInt(ctx.INT().getText());
- values.put(ctx, value);
- }
- @Override
- public void exitId(LabeledExprParser.IdContext ctx) {
- String id = ctx.ID().getText();
- if (memory.containsKey(id)) {
- values.put(ctx, memory.get(id));
- } else {
- values.put(ctx, 0); // default value if the variable is not found
- }
- }
- @Override
- public void exitParens(LabeledExprParser.ParensContext ctx) {
- values.put(ctx, values.get(ctx.expr()));
- }
- }
以上只是一些关键代码,所有代码请参见下面代码仓库
代码仓库
3.测试
测试vistor方式
- package com.et.antlr; /***
- * Excerpted from "The Definitive ANTLR 4 Reference",
- * published by The Pragmatic Bookshelf.
- * Copyrights apply to this code. It may not be used to create training material,
- * courses, books, articles, and the like. Contact us if you are in doubt.
- * We make no guarantees that this code is fit for any purpose.
- * Visit http://www.pragmaticprogrammer.com/titles/tpantlr2 for more book information.
- ***/
- import org.antlr.v4.runtime.*;
- import org.antlr.v4.runtime.tree.ParseTree;
- import java.io.FileInputStream;
- import java.io.InputStream;
- public class CalcByVisit {
- public static void main(String[] args) throws Exception {
- /* String inputFile = null;
- if ( args.length>0 ) inputFile = args[0];
- InputStream is = System.in;
- if ( inputFile!=null ) is = new FileInputStream(inputFile);*/
- ANTLRInputStream input = new ANTLRInputStream("1+2*3\n");
- LabeledExprLexer lexer = new LabeledExprLexer(input);
- CommonTokenStream tokens = new CommonTokenStream(lexer);
- LabeledExprParser parser = new LabeledExprParser(tokens);
- ParseTree tree = parser.prog(); // parse
- EvalVisitor eval = new EvalVisitor();
- int result =eval.visit(tree);
- System.out.println(result);
- }
- }
测试listener方式
- package com.et.antlr;
- import org.antlr.v4.runtime.ANTLRInputStream;
- import org.antlr.v4.runtime.CommonTokenStream;
- import org.antlr.v4.runtime.tree.ParseTree;
- import org.antlr.v4.runtime.tree.ParseTreeWalker;
- import java.io.FileInputStream;
- import java.io.IOException;
- import java.io.InputStream;
- /**
- * @author liuhaihua
- * @version 1.0
- * @ClassName CalbyLisenter
- * @Description todo
- * @date 2024年06月06日 16:40
- */
- public class CalbyLisener {
- public static void main(String[] args) throws IOException {
- /* String inputFile = null;
- if ( args.length>0 ) inputFile = args[0];
- InputStream is = System.in;
- if ( inputFile!=null ) is = new FileInputStream(inputFile);*/
- ANTLRInputStream input = new ANTLRInputStream("1+2*3\n");
- LabeledExprLexer lexer = new LabeledExprLexer(input);
- CommonTokenStream tokens = new CommonTokenStream(lexer);
- LabeledExprParser parser = new LabeledExprParser(tokens);
- ParseTree tree = parser.prog(); // parse
- ParseTreeWalker walker = new ParseTreeWalker();
- EvalListener evalListener =new EvalListener();
- walker.walk(evalListener, tree);
- int result=evalListener.getResult();
- System.out.println(result);
- }
- }
运行上述测试用例,计算结果符合预期
4.引用
-
-
相关阅读:
django migrate后数据库无表格
Kafka - This server does not host this topic-partition
银行存款问题:整存零取
非常非常地重试重试组件,使用杠铃的
Zookeeper
了解 OpenJDK 以及为什么要使用OpenJDK?
Golang:gin模板渲染base64图片出现#ZgotmplZ
Word控件Spire.Doc 【文档操作】教程(十一):如何在C#中按分页符拆分word文档
Netty
一零四、大数据可视化技术与应用实训(展示大屏幕)
- 原文地址:https://blog.csdn.net/dot_life/article/details/139641019