很高兴和大家分享 Hugging Face 的一项新功能: KV 缓存量化 ,它能够把你的语言模型的速度提升到一个新水平。
太长不看版: KV 缓存量化可在最小化对生成质量的影响的条件下,减少 LLM 在长文本生成场景下的内存使用量,从而在内存效率和生成速度之间提供可定制的权衡。
你是否曾尝试过用语言模型生成很长的文本,却因为内存不足而望洋兴叹?随着语言模型的尺寸和能力不断增长,支持生成更长的文本意味着内存蚕食的真正开始。于是,磨难也随之而来了,尤其是当你的系统资源有限时。而这也正是 KV 缓存量化的用武之地。
KV 缓存量化到底是什么?如果你不熟悉这个术语,没关系!我们拆成两部分来理解: KV 缓存 和 量化 。
键值缓存或 KV 缓存是一种优化自回归模型生成速度的重要方法。自回归模型需要逐个预测下一个生成词元,这一过程可能会很慢,因为模型一次只能生成一个词元,且每个新预测都依赖于先前的生成。也就是说,要预测第 1000 个生成词元,你需要综合前 999 个词元的信息,模型通过对这些词元的表征使用矩阵乘法来完成对上文信息的抽取。等到要预测第 1001 个词元时,你仍然需要前 999 个词元的相同信息,同时还还需要第 1000 个词元的信息。这就是键值缓存的用武之地,其存储了先前词元的计算结果以便在后续生成中重用,而无需重新计算。
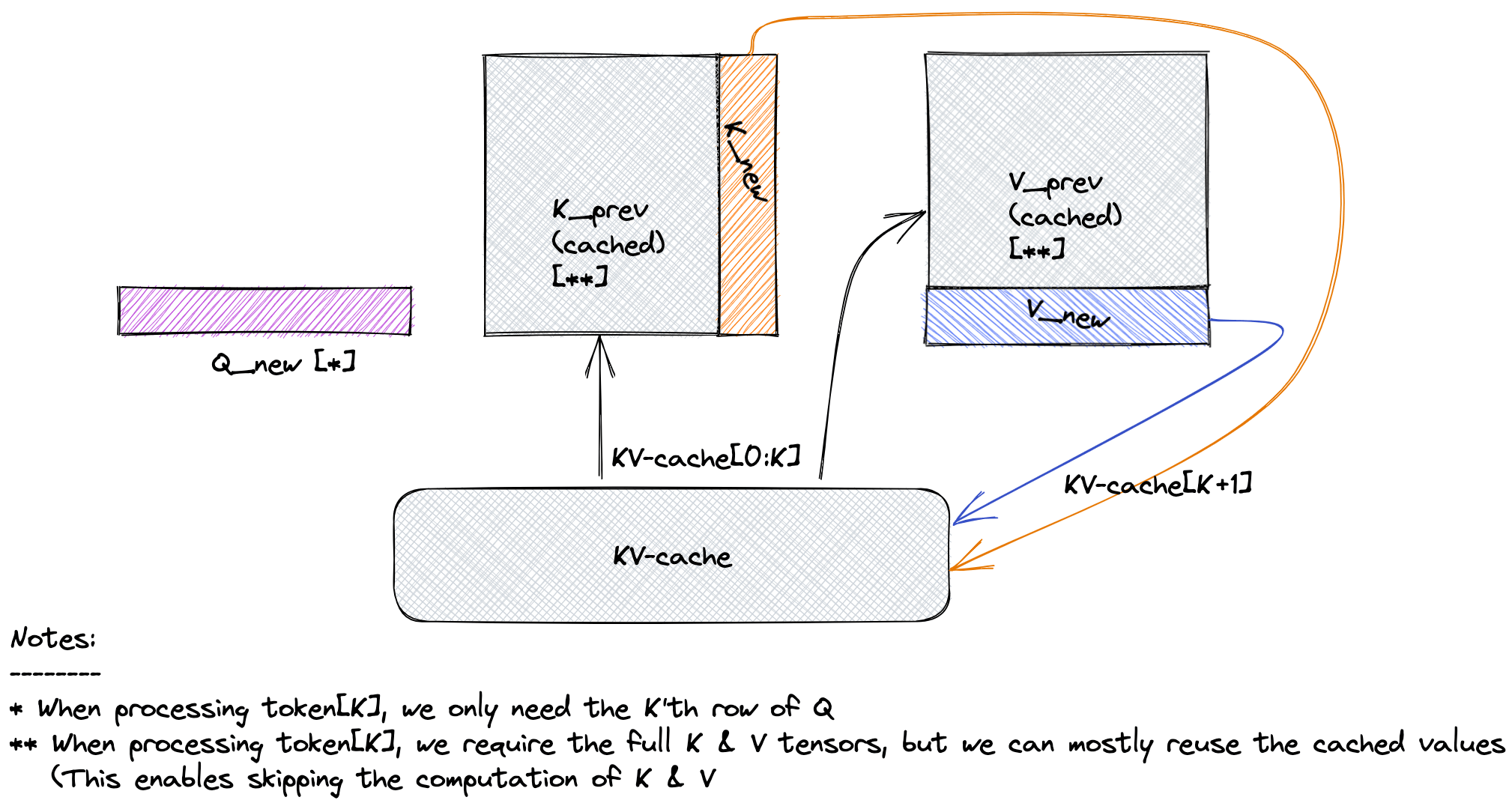
具体来讲,键值缓存充当自回归生成模型的内存库,模型把先前词元的自注意力层算得的键值对存于此处。在 transformer 架构中,自注意力层通过将查询与键相乘以计算注意力分数,并由此生成值向量的加权矩阵。存储了这些信息后,模型无需冗余计算,而仅需直接从缓存中检索先前词元的键和值。下图直观地解释了键值缓存功能,当计算第 K+1 个词元的注意力分数时,我们不需要重新计算所有先前词元的键和值,而仅需从缓存中取出它们并串接至当前向量。该做法可以让文本生成更快、更高效。
下一个名词是量化,它是个时髦词,主要用于降低数值的精度以节省内存。量化时,每个数值都会被舍入或截断以转换至低精度格式,这可能会导致信息丢失。然而,仔细选择量化参数和技术可以最大限度地减少这种损失,同时仍取得令人满意的性能。量化方法多种多样,如果你想知道更多信息以更深入了解量化世界,可查阅我们 之前的博文。
有一利必有一弊,KV 缓存能够加速自回归生成,但在文本长度或者 batch size 变大时,它也随之带来了内存瓶颈。估算一下,当用 7B Llama-2 模型处理 10000 个词元的输入时,我们需要多少内存来存储 KV 缓存。存储一个词元的 KV 缓存所需的内存大致为 2 * 2 * 层数 * 键值抽头数 * 每抽头的维度 ,其中第一个 2 表示键和值,第二个 2 是我们需要的字节数 (假设模型加载精度为 float16 )。因此,如果上下文长度为 10000 词元,仅键值缓存所需的内存我们就要:
2 * 2 * 32 * 32 * 128 * 10000 ≈ 5GB
该内存需求几乎是半精度模型参数所需内存的三分之一。
因此,通过将 KV 缓存压缩为更紧凑的形式,我们可以节省大量内存并在消费级 GPU 上运行更长上下文的文本生成。实验表明,通过将 KV 缓存量化为较低的精度,我们可以在不牺牲太多质量的情况下显著减少内存占用。借助这一新的量化功能,我们现在可以用同样的内存支持更长的生成,这意味着你可以扩展模型的上下文长度,而不必担心遇到内存限制。
实现细节
Transformers 中的键值缓存量化很大程度上受启发于 KIVI: A Tuning-Free Asymmetric 2bit Quantization for kv Cache 论文。该论文对大语言模型引入了 2 比特非对称量化,且不会降低质量。KIVI 采用按通道的量化键缓存以及按词元量化值缓存的方法,因为研究表明,就 LLM 而言,键在某些通道上容易出现高幅度的异常值,而值并无此表现。因此,采用按通道量化键和按词元量化值的方法,量化精度和原始精度之间的相对误差要小得多。
在我们集成至 transformers 时,键和值都是按通道量化的 [译者注: 原文为按词元量化,比照 代码 后改为按通道量化]。量化的主要瓶颈是每次添加新词元 (即每个生成步骤) 时都需要对键和值进行量化和反量化,这可能会减慢生成速度。为了解决这个问题,我们决定保留固定大小的余留缓存 (residual cache),以原始精度存储键和值。当余留缓存达到其最大容量时,存储在里面的键和值都会被量化,然后将其内容从余留缓存中清空。这个小技巧还有助于保持准确性,因为一些最新的键和值始终以其原始精度存储。设置余留缓存长度时主要需要考虑内存效率的权衡。虽然余留缓存以其原始精度存储键和值,但这可能会导致总体内存使用量增加。我们发现使用余留长度 128 作为基线效果不错。
因此,给定形状为 batch size, num of head, num of tokens, head dim 的键或值,我们将其分组为 num of groups, group size 并按组进行仿射量化,如下所示:
X_Q = round(X / S) - Z
这里:
- X_Q 是量化后张量
- S 是比例,计算公式为
(maxX - minX) / (max_val_for_precision - min_val_for_precision) - Z 是零点,计算公式为
round(-minX / S)
目前,支持 KV 量化的后端有: quanto 后端支持 int2 和 int4 量化; HQQ 后端支持 int2 、 int4 和 int8 量化。如欲了解 quanto 的更多详情,可参阅之前的 博文。尽管我们目前尚不支持其它量化后端,但我们对社区贡献持开放态度,我们会积极集成新后端相关的 PR。我们的设计支持社区贡献者轻松将不需要校准数据且可以动态计算低比特张量的量化方法集成进 transformers。此外,你还可以在配置中指定缺省量化参数,从而自主调整你的量化算法,如: 你可根据你的用例决定是使用按通道量化还是按词元量化。
比较 FP16 缓存和量化缓存的性能
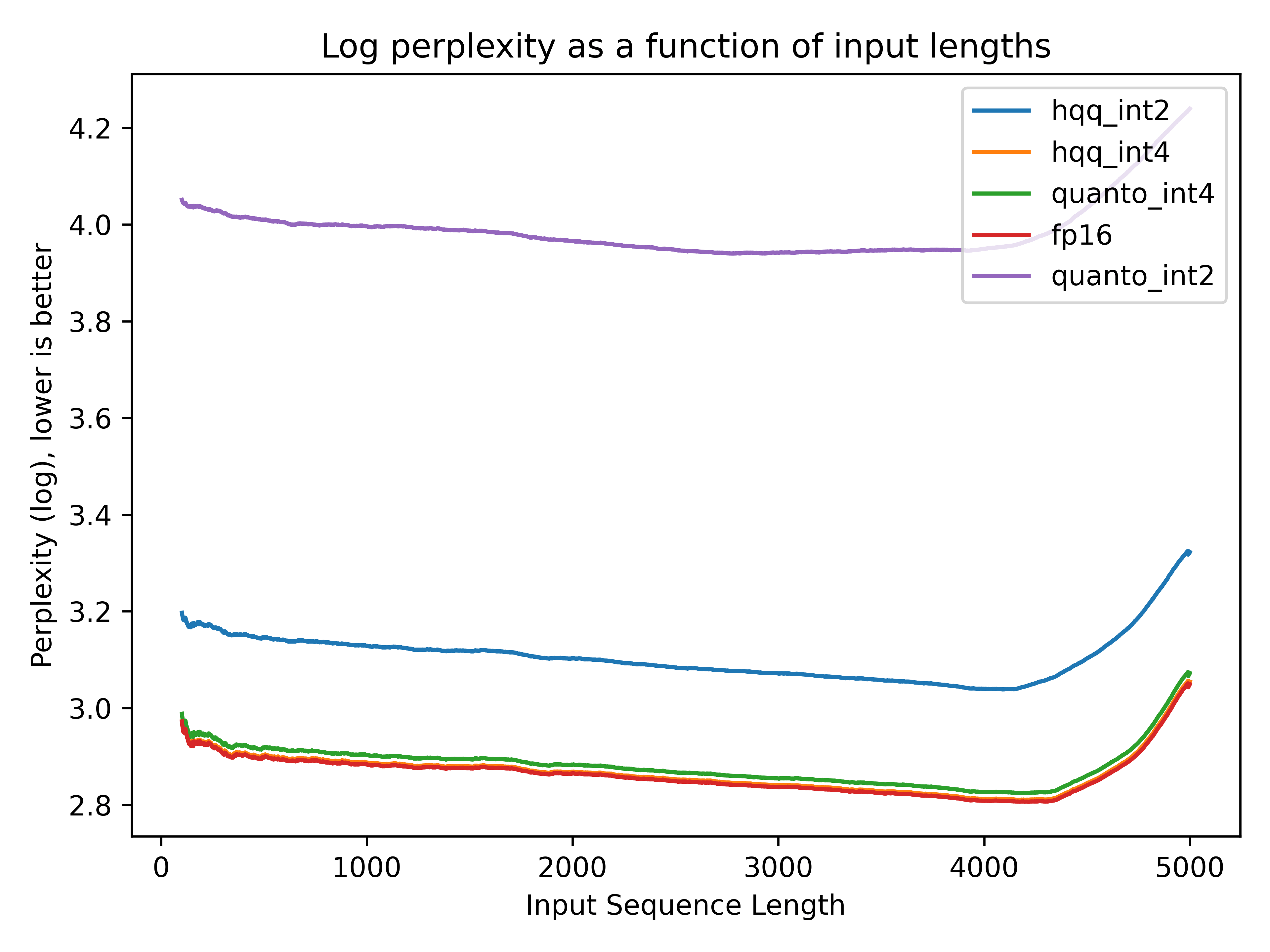
一图胜千言,我们准备了几幅图,以让大家一目了然了解量化缓存与 FP16 缓存的表现对比。这些图向大家展示了当我们调整 KV 缓存的精度设置时,模型生成的质量是如何随之变化的。我们在 PG-19 数据集上测量了 Llama2-7b-chat 的困惑度。实验中使用的量化参数为: nbits=4, group_size=64, resildual_length=128, per_token=True 。
可以看到,两个后端的 int4 缓存的生成质量与原始 fp16 几乎相同,而使用 int2 时出现了质量下降。你可在 此处 获取重现脚本。
我们还在 LongBench 基准上测量了生成质量,并将其与 KIVI 论文的结果进行比较,结论与上文一致。下表的结果表明,在所有测试数据集中, Quanto int4 的精度与 fp16 相当甚至略优 (数值越高越好)。
| 数据集 | KIVI fp16 | KIVI int2 | Transformers fp16 | Quanto int4 | Quanto int2 |
|---|---|---|---|---|---|
| TREC | 63.0 | 67.5 | 63.0 | 63.0 | 55.0 |
| SAMSum | 41.12 | 42.18 | 41.12 | 41.3 | 14.04 |
| TriviaQA | NA | NA | 84.28 | 84.76 | 63.64 |
| HotPotQA | NA | NA | 30.08 | 30.04 | 17.3 |
| Passage_retrieval_en | NA | NA | 8.5 | 9.5 | 4.82 |
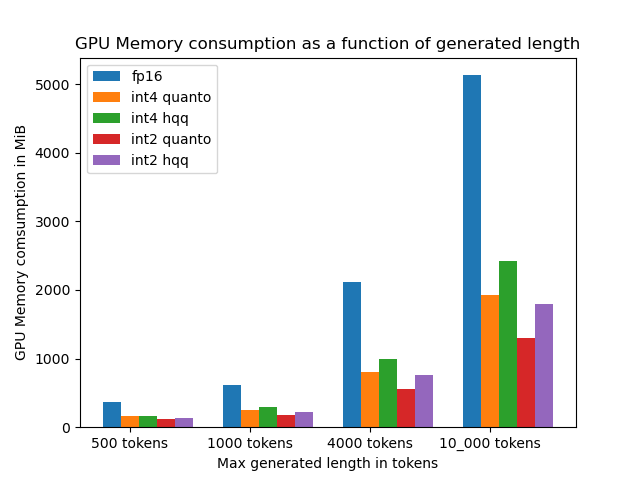
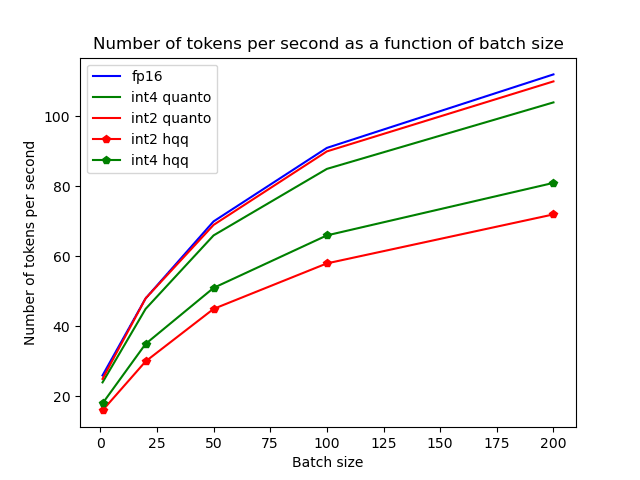
现在,我们来谈谈内存节省和速度之间的权衡。当我们量化模型中的 KV 缓存时,对内存的需求减少了,但有时这同时也会降低生成速度。虽然将缓存量化为 int4 可以节省大约 2.5 倍内存,但生成速度会随着 batch size 的增加而减慢。用户必须自己权衡轻重: 是否值得牺牲一点速度以换取内存效率的显著提高,这由你的实际用例的需求及其优先级排序决定。
以下给出了原始精度版和量化版 KV 缓存在各性能指标上的对比,复现脚本见 此处。
想知道再叠加权重量化会发生什么吗?当然,把这些技术结合使用可以进一步减少模型的内存占用,但也带来一个问题 - 它可能会进一步减慢速度。事实上,我们的实验表明,权重量化与 KV 缓存量化一起使用会导致速度降低三倍。但我们并未放弃,我们一直在努力寻找让这个组合无缝运行的方法。目前 quanto 库中缺少相应的优化算子,我们对社区任何有助于提高计算效率的贡献持开放态度。我们的目标是确保你的模型平稳运行,同时保持高水准的延迟和准确性。
还需要注意的是,对输入提示的首次处理 (也称为预填充阶段) 仍然需要一次性计算整个输入的键值矩阵,这可能是长上下文的另一个内存瓶颈。这就是为什么生成第一个词元相关的延迟往往比后续词元更高的原因。还有一些其他策略可以通过优化注意力计算来减少预填充阶段的内存负担,如 局部加窗注意力、Flash Attention 等。如果预填充阶段内存不足,你可以使用 🤗 Transformers 中的 FlashAttention 以及 KV 缓存量化来进一步减少长输入提示的内存使用量。更多详情,请参阅 文档。
如果你想知道如果将内存使用量推至极限,我们最长可以支持多少个词元的上下文,那么在 80GB A100 中启用 Flash Attention 时,量化 KV 缓存可以支持多达 128k 个词元。而使用半精度缓存时,最长为 40k 个词元。
如何在 🤗 Transformers 中使用量化 KV 缓存?
要在 🤗 Transformers 中使用 KV 缓存量化,我们必须首先运行 pip install quanto 安装依赖软件。要激活 KV 缓存量化,须传入 cache_implementation="quantized" 并以字典格式在缓存配置中设置量化参数。就这么多!此外,由于 quanto 与设备无关,因此无论你使用的是 CPU/GPU/MPS (苹果芯片),都可以量化并运行模型。
你可在此找到一个简短的 Colab 笔记本 及使用示例。
>>> import torch >>> from transformers import AutoTokenizer, AutoModelForCausalLM >>> tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf") >>> model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16, device_map="cuda:0") >>> inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device) >>> out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="quantized", cache_config={"backend": "quanto", "nbits": 4}) >>> print(tokenizer.batch_decode(out, skip_special_tokens=True)[0]) I like rock music because it's loud and energetic. It's a great way to express myself and rel >>> out = model.generate(**inputs, do_sample=False, max_new_tokens=20) >>> print(tokenizer.batch_decode(out, skip_special_tokens=True)[0]) I like rock music because it's loud and energetic. I like to listen to it when I'm feeling
总结
还有很多可以减少键值缓存内存占用的方法,如 MultiQueryAttention、GroupedQueryAttention 以及最近的 KV 缓存检索 等等。虽然其中一些方法与模型架构相耦合,但还是有不少方法可以在训后阶段使用,量化只是此类训后优化技术其中一种。总结一下本文:
- 需要在内存与速度之间折衷: 通过将 KV 缓存量化为较低精度的格式,内存使用量可以显著减少,从而支持更长的文本生成而不会遇到内存限制。但,用户必须根据实际用例决定能不能接受放弃一点点生成速度的代价。
- 保持准确性: 尽管精度有所降低,
int4KV 缓存量化仍可将模型准确性保持在令人满意的程度,确保生成的文本保持上下文相关性和一致性。 - 灵活性: 用户可以根据自己的具体要求灵活地选择不同的精度格式,以为不同的用例及需求进行定制。
- 进一步优化的潜力: 虽然 KV 缓存量化本身具有显著的优势,但它也可以与其他优化技术 (例如权重量化) 结合使用,以进一步提高内存效率和计算速度。
致谢
特别感谢 Younes 和 Marc 在量化技术上的帮助和建议,他们的专业知识极大地促进了此功能的开发。
此外,我还要感谢 Joao 的宝贵支持。
更多资源
- Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Braverman, V., Beidi Chen, & Hu, X. (2023). KIVI : Plug-and-play 2bit KV Cache Quantization with Streaming Asymmetric Quantization.
- Databricks 博文: LLM Inference Performance Engineering: Best Practices
- Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, & Amir Gholami. (2024). KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization.
- T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer, (2022). LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale.
- A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, (2021). A Survey of Quantization Methods for Efficient Neural Network Inference.
英文原文: https://hf.co/blog/kv-cache-quantization
原文作者: Raushan Turganbay
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。