-
ClickHouse 使用技巧总结
数据导入、导出技巧
外部文件导入导技巧
ClickHouse作为OLAP即席分析引擎,不可避免地需要将数据从业务数据库、传统数据仓库等数据源中提取数据,当数据计算完成后,也可能需要将数据导出为外部数据文件供其他系统使用。

CSV、TSV文件导入建议
- 尽量使用TSV代替CSV,CSV 中如果真实数据中也出现了逗号,此时引擎无法区分这个逗号是分隔符还是数据
- 尽可能使用时间戳代替时间文本
- 将ODS层数据表的时间类型设置为String 先将ClickHouse中目标表时间日期类型的字段设置为string,先将数据导入,接着对这个ODS的表进行数据清洗,通过ClickHouse内置的SQL函数解决问题
数据导出技巧
-
通过INTO OUTFILE导出
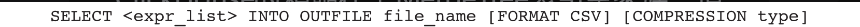
-
通过文件表引擎导入、导出数据,创建表文件引擎:

导入导出SQL:
-
通过命令行重定向导出

使用集成表引擎导入、导出数据
-
利用MySQL表引擎实现数据的导入、导出

在创建MySQL表引擎时,需要注意ClickHouse中本地表的列名必须和远程MySQL的列名完全一致。
MySQL 与 Clickhouse 数据类型映射关系如下: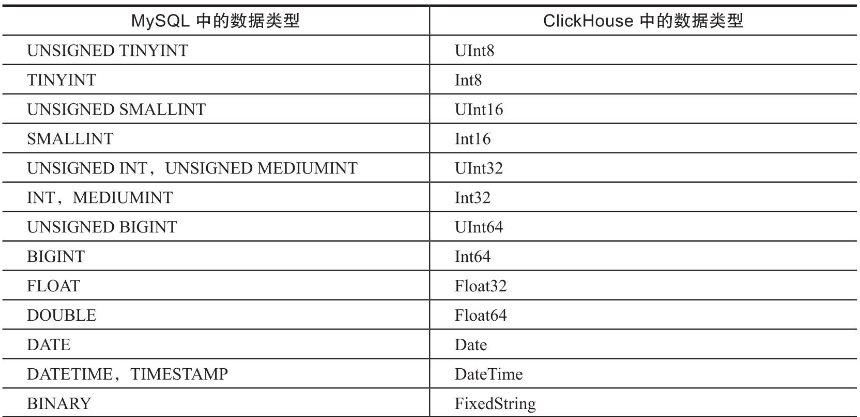
创建MySQL外部表后,即可通过下面的SQL语句实现数据的导入、导出。
-
利用MongoDB表引擎实现数据的导入、导出
利用下面的SQL语句创建外部MongoDB表引擎:

创建MongoDB外部表后,即可通过下面的SQL语句实现数据的导入:
-
利用HDFS表引擎实现数据的导入、导出
利用下面的SQL语句创建外部HDFS表引擎

HDFS表引擎还支持对HDFS的路径使用通配符进行模糊处理,以支持更灵活的HDFS文件夹策略。ClickHouse支持的通配符如下图所示: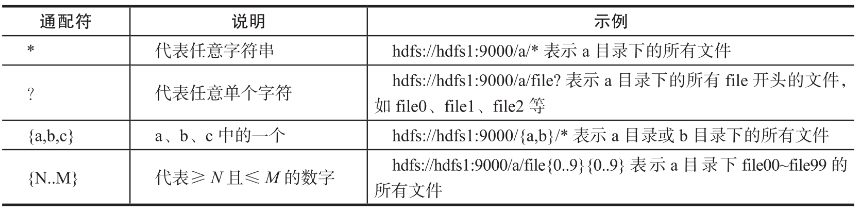
对数据进行导入、导出:
-
利用S3表引擎实现数据的导入、导出
表引擎创建:

-
利用PostgreSQL表引擎实现数据的导入、导出

PostgreSQL和ClickHouse数据类型的对应关系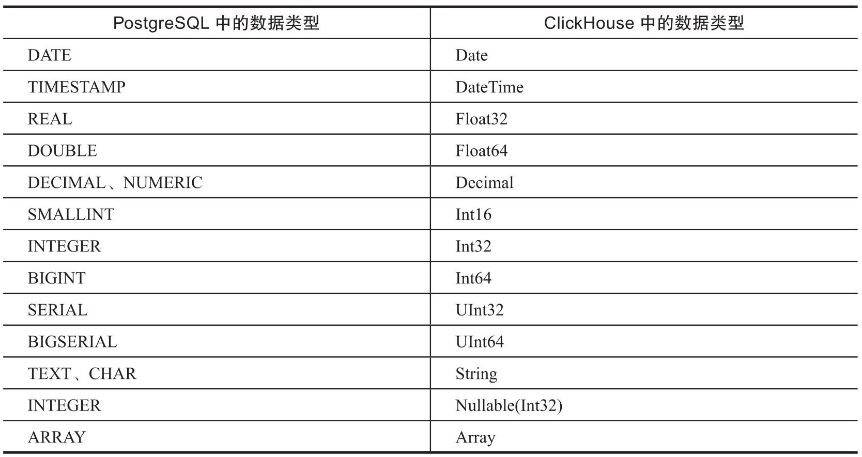
数据的导入、导出:
-
利用JDBC表引擎实现数据的导入、导出。
要使用JDBC表引擎,必须先运行一个名为clickhouse-jdbc-bridge的Java进程,并做适当的配置。关键要配置好数据库驱动和数据源地址。下面展示一段clickhouse-jdbc-bridge的配置信息。其中数据源驱动的地址可以是一个远程的地址,也可以配置成本地的文件路径:

表引擎创建: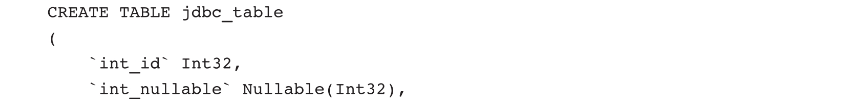

数据的导入、导出:
另外,JDBC表引擎由于配置信息已经存储在了clickhouse-jdbc-bridge的配置文件中,因此还有一种特殊的不需要创建ClickHouse虚拟表的访问方法。可以利用这种方式将数据导入ClickHouse本地表或外部数据文件,代码如下:
-
不要利用外部表引擎进行复杂查询
在很多情况下,复杂SQL查询性能很差,而且有可能对业务产生影响。只有在满足如下条件时,利用该SQL查询的技巧才能获得比较高的收益。
- 远程数据表经常发生变动。
- 远程数据表数据量比较小。
- 在ClickHouse中的查询语句是低频的。
- 不会影响其他业务的正常运行,能够忍受这些影响。
-
对数据量大的数据表进行迁移时,利用TSV进行中转
在应对大批量数据时,建议按照年、月或日对任务进行切分,启动多个进程并行执行。另外,将数据先导入TSV进行中转,避免中途出错导致整个任务重新运行。
-
利用Kafka表引擎实现数据的导入、导出
Kafka表引擎一般和ClickHouse的物化视图一起使用,否则ClickHouse只会读取Kafka中最新的消息。通过ClickHouse的物化视图,在后台将Kafka中的数据源源不断地写入本地,以实现Kafka数据的持久化。下面展示创建Kafka表引擎的SQL语句:

创建Kafka表引擎后,可以对该表引擎进行SELECT查询,但是对该表的查询只会查询到Kafka中最新的一条数据。需要从该时刻将Kafka中的数据源源不断地持久化保存,必须利用ClickHouse提供的物化视图的能力,代码如下:
建表技巧
表引擎选择技巧
-
优先选择MergeTree家族的表。
基于MergeTree表引擎所派生出来的多个表引擎说明如下:
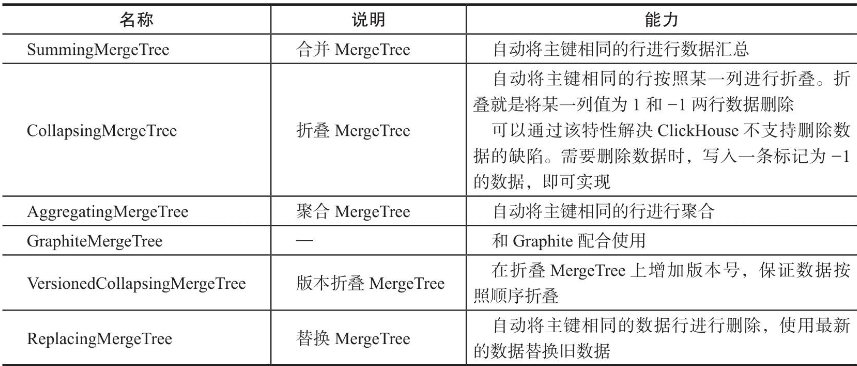
在使用时建议先创建基础的MergeTree表,在基础MergeTree表上再构建这些派生的MergeTree表引擎,避免由于使用不恰当的主键组合导致数据丢失。 -
利用Buffer表引擎解决大量INSERT带来的问题
由于Buffer表必须有底层物理表,因此创建Buffer表时不需要列出各列的类型,代码如下:

通过Buffer表,可以解决ClickHouse遇到突发大量INSERT语句时报错的问题,起到缓冲的作用。使用Buffer表也存在如下一些问题:- 由于ClickHouse没有使用WAL(Write Ahead Log,预写日志)技术,因此系统崩溃可能导致丢失数据。
- Buffer写入物理表时,可能由于物理表引擎的特性导致数据错乱。例如当底层表为折叠表时可能因为丢失顺序而造成错乱。
建议在满足如下条件的情况下使用Buffer表:
- 数据少量丢失不会影响业务。
- 底层表选择基础的MergeTree表引擎。
-
利用Memory表引擎提高并发查询能力
Memory也是一个内存表,和Buffer不同的是,Memory表引擎不需要底层的数据表。Memory表也不会将数据定期写入磁盘。
ClickHouse由于每次查询都会大量利用单机资源,因此并发能力并不高,解决该问题的一个策略是组建ClickHouse集群,在某些场景下还可以利用Memory表引擎提高ClickHouse的并发能力。
利用ClickHouse的Memory表引擎提高并发能力,并不是随意将查询所需的表载入内存后查询。而是根据业务进行判断,如果大量的并发查询是查询某一个固定的模型,那么需要将该模型固化为Cube,将Cube保存为Memory表,以应对高并发查询的需求。
Memory表引擎解决并发问题的核心在于,能够将模型转化为Cube,如果不能转化为Cube,那么使用Memory表引擎可能会得不偿失。需要根据业务的实际情况进行判断,千万不能将查询所涉及的表都塞入Memory表,否则ClickHouse的内存可能会溢出,导致服务器崩溃。
分区键选择技巧
ClickHouse的主键就是分区键,和传统事务数据库的主键不同,ClickHouse的主键不具备唯一性约束,只是分区键的别名,在选择分区键(主键)时也有一些技巧。
- 最左原则,一定要将最频繁使用的列放在最左边。很多情况下,放在右边的列可能无法得到加速。
- 适当冗余建表,ClickHouse是一个压缩率很高的数据库,我们完全不必强求数据在ClickHouse中只存一份,当遇到多个查询任务需要不同的排序键时,可以放心大胆地创建一个除了主键不同,其他都相同的数据表。
数据结构选择技巧
使用低基数类型
-
低基数类型(LowCardinality)是ClickHouse中的一个特殊的包装类型,通过该类型可以将数据类型进行字典编码,替换为更高效的存储格式。尤其当某一类去重后的数量少于10000时,可以大幅提高SELECT操作的效率。
-
LowCardinality支持对String、FixedString、Date、DateTime和不包含Decimal的数组类型进行自动化的字典编码:

-
在ClickHouse中可以使用低基数类型替换原始的String类型,也可以使用低基数类型替换枚举类型
分区技巧
慎重使用分区
- 不建议大量使用分区。在很多情况下,分区并不能提高查询效率,过多地分区有可能降低性能。ClickHouse中分区功能仅仅是为数据管理提供便利,例如以分区为单位进行删除等。
高级技巧
物化视图
使用物化视图代替视图
-
物化视图会将数据写入磁盘,而视图只是一个虚拟的表,并不会真正存储数据。通过使用物化视图可以大幅提高查询速度:

物化视图和物理表类型的区别在于物化视图会自动识别底层表的变动,当底层表变动时会自动映射到物化视图中。
投影
使用投影能力
-
ClickHouse的索引满足最左原则,当未按照最左原则进行查询时,速度会变慢,投影就是一个解决该问题的方案,其实现原理是将不满足最左原则的查询条件进行固化,本质上可以理解为创建了一个按照新的顺序排列的数据副本,当查询条件满足这个副本时,自动在该副本上查询,从而实现性能加速:

位图
使用位图结构
- 使用 Bitmap 等位图结构可以节省大量存储空间,并且位图的计算效率很高。
变更数据捕获
使用内置的CDC能力获取实时数据
- ClickHouse通过MaterializeMySQL和MaterializePostgreSQL两个引擎提供MySQL和PostgreSQL的CDC集成支持。
常见报错及处理方法
解决“too many parts”异常
- too many parts是ClickHouse经常会出现的错误,出现这种错误的原因在于短期内建立了太多的分区。要解决这个问题,可以在数据进入ClickHouse前进行预排序,或者使用前边提到的缓冲区表引擎。
解决“memory limit”异常
- 内存不足,优化SQL 或者将计算下推,使用 Spark 来查询复杂 SQL。
-
相关阅读:
【毕业设计】奥运会数据分析与可视化 - python 大数据
卡尔曼滤波C++代码
Java也能做OCR!SpringBoot 整合 Tess4J 实现图片文字识别
《乔布斯传》英文原著重点词汇笔记(三)【 chapter one】
Windows7、Windows8、Windows10修改磁盘大小
golang设计模式——命令模式
阿里巴巴JAVA开发手册----(一)
大数据精准营销一站式解决你的获客难题
go操作mysql
SpringBoot结合Liquibase实现数据库变更管理
- 原文地址:https://blog.csdn.net/qq_42586468/article/details/139318656