-
Tensorflow Serving:Java调用saved_model.pb输出模型预测
使用背景
有个离线跑批的任务需要调用tensorflow模型写入大数据集群(hive/kudu/impala之流),Python的操作包impyla存在bug,插入kudu极其缓慢几乎不能用,尝试使用Python完成tensorflow模型训练产出pb文件,使用Java完成整个跑批调用算法入库的过程。
saved_model.pb是tensorflow的冻结图模型文件,是跨语言的,可以使用各种语言如Java,Python的tensorflow的包和API进行调用。
saved_model_cli检查冻结图,Python调用pb
saved_model_cli是安装tensorflow之后在Python执行目录bin下的工具,可以快速检查冻结图的
输入数量,输入类型,输入的tensor在图中的名称。看一个例子,pb文件以时间戳作为存储文件名saved_model_cli show --all --dir 1642827089/MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs: signature_def['my_signature']: The given SavedModel SignatureDef contains the following input(s): inputs['dropout_keep_prob'] tensor_info: dtype: DT_FLOAT shape: unknown_rank name: dropout_keep_prob:0 inputs['input_neigh_1'] tensor_info: dtype: DT_FLOAT shape: (-1, 10, 1433) name: input_neigh_1:0 inputs['input_neigh_2'] tensor_info: dtype: DT_FLOAT shape: (-1, 10, 10, 1433) name: input_neigh_2:0 inputs['input_self'] tensor_info: dtype: DT_FLOAT shape: (-1, 1433) name: input_self:0 The given SavedModel SignatureDef contains the following output(s): outputs['output'] tensor_info: dtype: DT_FLOAT shape: (-1, 7) name: softmax/probs:0 Method name is: tensorflow/serving/predict检查结果可知需要输入4个tensor,输入一个7维的预测得分,其中还包含一些关键信息,这些信息要在调用模型的时候使用
tag字符串: 'serve':模型图文件元数据的tag字符串,在Python saved_model的存储模型时调用add_meta_graph_and_variables指定为tag_constants.SERVING,即字符串serve,这个需要在调用冻结图预测时使用自定义签名:'my_signature':模型文件自定义签名,在Python saved_model存储模型时调用add_meta_graph_and_variables使用{'my_signature': signature}定义,这个自定义签名在调用tfserving服务时需要使用tensor节点名:每个inputs和outputs的name属性就是节点名,再调用PB恢复到Session之后,根据tensor节点名直接拿到节点或者给节点灌入数据即可完成模型预测tensor标签名称:每个inputs和outputs的key名称,是用户自定义的输入输出标示,在调用tfserving时需要使用
看一下在Python中如何调用冻结图
def predict_from_pb(): # 数据处理,准备一条测试数据 global test_nodes test_nodes = [test_nodes[0]] layer_neighbours = sample(test_nodes, neighbour_list, num_supports=[int(get_string("layer2_supports")), int(get_string("layer1_supports"))]) test_input_x = get_nodes_features(test_nodes, nodes_features) test_input_x_1 = get_nodes_features(sum(layer_neighbours[2], []), nodes_features) test_input_x_2 = get_nodes_features(sum(layer_neighbours[1], []), nodes_features) # 调用部分 tf.reset_default_graph() with tf.Session() as sess: tf.saved_model.loader.load(sess, [tag_constants.SERVING], "/home/myproject/MODEL_TEST/tfserving/1642827089") graph = tf.get_default_graph() # get tensor input_self = graph.get_tensor_by_name("input_self:0") input_neigh_1 = graph.get_tensor_by_name("input_neigh_1:0") input_neigh_2 = graph.get_tensor_by_name("input_neigh_2:0") dropout_keep_prob = graph.get_tensor_by_name("dropout_keep_prob:0") pred = graph.get_tensor_by_name("softmax/probs:0") prediction = sess.run(pred, feed_dict={input_self: test_input_x, input_neigh_1: test_input_x_1.A.reshape(-1, int(get_string("layer1_supports")), features_size), input_neigh_2: test_input_x_2.A.reshape(-1, int(get_string("layer1_supports")), int(get_string("layer2_supports")), features_size), dropout_keep_prob: 1.0}) print(prediction)整体流程就是调用
tf.saved_model.loader.load恢复图结构,根据tensor名获得tensor对象,使用feed_dict给tensor对象灌入数据进行预测。
Java调用pb快速开始
引入所需依赖,版本号和Python的tensorflow版本一致。
<dependencies> <dependency> <groupId>org.tensorflow</groupId> <artifactId>tensorflow</artifactId> <version>1.13.1</version> </dependency> </dependencies>package com.mycom.TENSORFLOW_SAVED_MODEL_TEST.main; import org.tensorflow.SavedModelBundle; import org.tensorflow.Session; import org.tensorflow.Tensor; import java.util.Arrays; import static com.mycom.TENSORFLOW_SAVED_MODEL_TEST.main.PreprocessTensor.*; public class TensorflowSavedModelTest { public static void main(String[] args) throws Exception { SavedModelBundle model = SavedModelBundle.loader("./model/1642827089").withTags("serve").load(); Session session = model.session(); float[][] inputSelf = getInputSelf(); float[][][] inputNeigh1 = getInputNeigh1(); float[][][][] inputNeigh2 = getInputNeigh2(); Tensor<?> output = session.runner() .feed("input_self:0", Tensor.create(inputSelf)) .feed("input_neigh_1:0", Tensor.create(inputNeigh1)) .feed("input_neigh_2:0", Tensor.create(inputNeigh2)) .feed("dropout_keep_prob:0", Tensor.create(1.0f)) .fetch("softmax/probs:0").run().get(0); float[][] resultValues = output.copyTo(new float[1][7]); System.out.println(Arrays.deepToString(resultValues)); } }代码量很少,运行看一下结果
2022-01-22 21:47:12.408812: I tensorflow/cc/saved_model/reader.cc:31] Reading SavedModel from: ./model/1642827089 2022-01-22 21:47:12.412897: I tensorflow/cc/saved_model/reader.cc:54] Reading meta graph with tags { serve } 2022-01-22 21:47:12.425125: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA 2022-01-22 21:47:12.455214: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 1800000000 Hz 2022-01-22 21:47:12.457091: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x7f5c40555350 executing computations on platform Host. Devices: 2022-01-22 21:47:12.457194: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): <undefined>, <undefined> 2022-01-22 21:47:12.503838: I tensorflow/cc/saved_model/loader.cc:182] Restoring SavedModel bundle. 2022-01-22 21:47:12.638208: I tensorflow/cc/saved_model/loader.cc:285] SavedModel load for tags { serve }; Status: success. Took 229411 microseconds. [[0.11804907, 0.07502167, 0.08551402, 0.5639879, 0.016195292, 0.08123174, 0.060000222]]最后输入是7个维度的预测概率,已经测通,下面测一下多个样本的批量调用,现将将数据准备时将所有float多维数据的第一维相应扩大,例如现在一个批次2个数据进行预测
float[][] array1 = new float[2][1433]; float[][][] array2 = new float[2][10][1433]; float[][][][] array3 = new float[2][10][10][1433];最后修改输出为一个2×7的二位数组即可
float[][] resultValues = output.copyTo(new float[2][7]);运行看输出结果
[[0.11804907, 0.07502167, 0.08551402, 0.56398803, 0.016195294, 0.08123175, 0.060000207], [0.11804907, 0.07502167, 0.08551402, 0.56398803, 0.016195294, 0.08123175, 0.060000207]]ok批量预测只需要batch_size那一个维度控制以下即可,数据输入的数组数量和数组维度不变。
Java调用pb代码分析
整体流程和Python一致,先用
SavedModelBundle.loader导入pb文件目录,指定tag字符串serve,然后调用session重构图结构。数据准备部分使用Java的Array数组,数据类型是float,double不支持,数组使用Tensor.create组装成tensor对象,在session中获得runner,将所有输入一个一个根据tensor名称和tersor对象一个一个feed进入,最后调用fetch指定输出tensor名拿到输出值,最终将结果copyTo到指定的多维数组即可。runner调用run的输出是一个List,size就是1直接get(0)即可。
Java调用pb代码完整示例
写一个单例模式的Java调用pb模型预测的模块
import org.tensorflow.SavedModelBundle; import org.tensorflow.Session; import org.tensorflow.Tensor; import java.io.IOException; import java.util.Arrays; import static com.mycom.TENSORFLOW_SAVED_MODEL_TEST.main.PreprocessTensor.*; public class SavedModelPBPredict { private SavedModelBundle model; private Session session; private static SavedModelPBPredict instance = null; public SavedModelPBPredict() { model = SavedModelBundle.loader("./model/1642827089").withTags("serve").load(); session = model.session(); } public static SavedModelPBPredict getInstance() { if (null == instance) { synchronized (SavedModelPBPredict.class) { if (null == instance) { instance = new SavedModelPBPredict(); } } } return instance; } public float[][] getPredictArray(float[][] inputSelf, float[][][] inputNeigh1, float[][][][] inputNeigh2) { Tensor<?> output = session.runner() .feed("input_self:0", Tensor.create(inputSelf)) .feed("input_neigh_1:0", Tensor.create(inputNeigh1)) .feed("input_neigh_2:0", Tensor.create(inputNeigh2)) .feed("dropout_keep_prob:0", Tensor.create(1.0f)) .fetch("softmax/probs:0").run().get(0); return output.copyTo(new float[2][7]); } public void close() { if (null != session) { session.close(); } if (null != model) { model.close(); } } public static void main(String[] args) throws IOException { float[][] inputSelf = getInputSelf(); float[][][] inputNeigh1 = getInputNeigh1(); float[][][][] inputNeigh2 = getInputNeigh2(); for (int i = 0; i < 10; i++) { float[][] res = SavedModelPBPredict.getInstance().getPredictArray(inputSelf, inputNeigh1, inputNeigh2); System.out.println(Arrays.deepToString(res)); } SavedModelPBPredict.getInstance().close(); } }学习策略调整建议
鉴于当前市场的积极态势,对于初学者而言,学习LLM不应仅仅停留在理论层面,更应注重实践能力和创新思维的培养。以下是一些针对当前行情的学习策略建议。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场
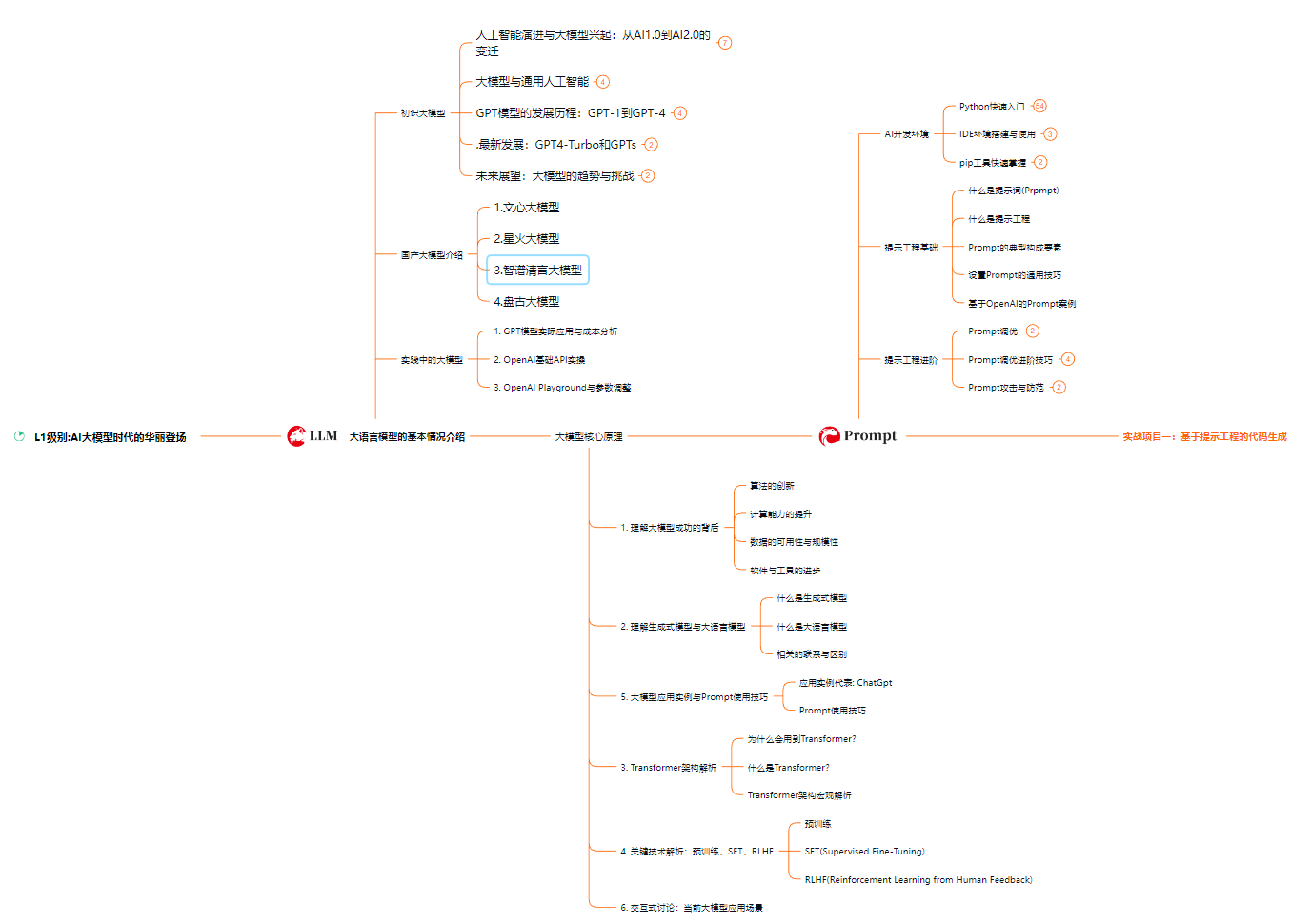
L2级别:AI大模型API应用开发工程
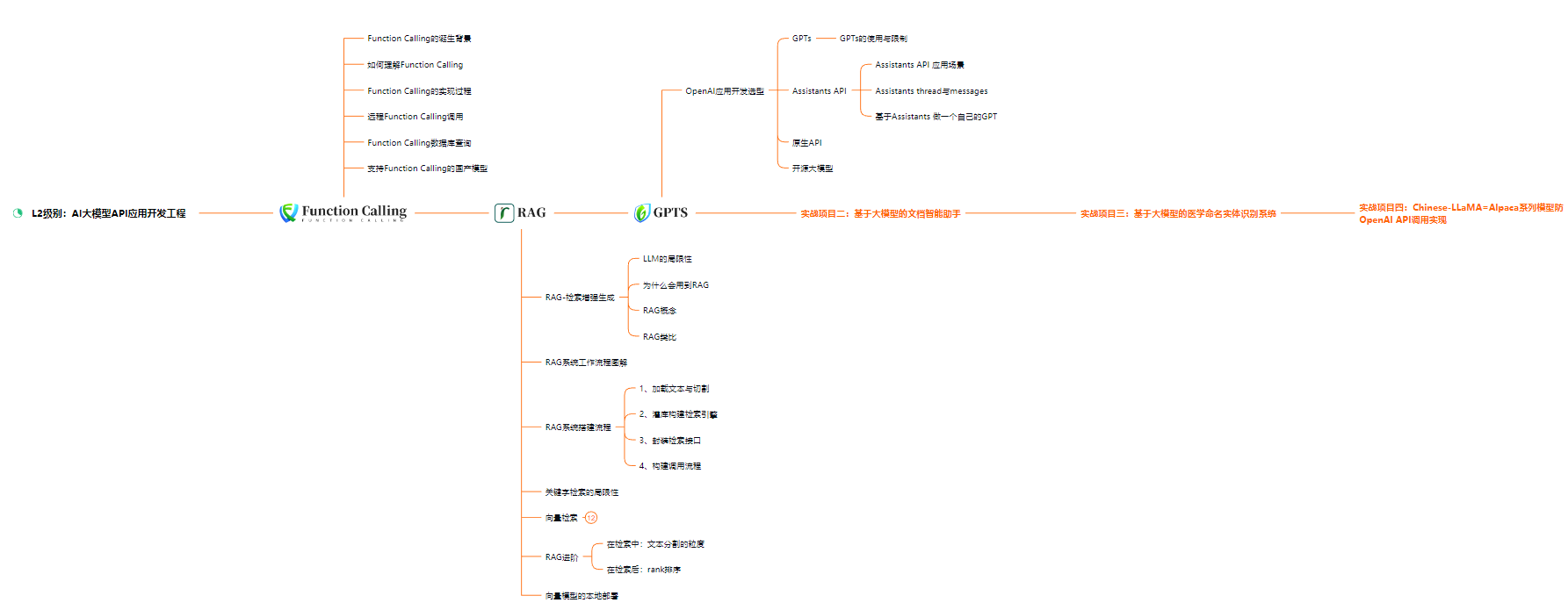
L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【
保证100%免费】
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
-
相关阅读:
想知道图片转表格怎么转?简单实用的转换方法分享
hive acid及事务表踩坑学习实录
机器学习小白理解之一元线性回归
Python基础入门篇【41】--python中的时间包
EFCore学习笔记(5)——生成值
2023秋招—大数据开发面经—闻泰科技
Java 反射机制详解
C语言进阶---动态内存管理
腾讯云CVM服务器5年可选2核4G和4核8G配置
SpringMVC项目整合SSM统一结果封装
- 原文地址:https://blog.csdn.net/2401_85327249/article/details/139277838