-
强化学习 (三) 动态规划
传统dp作用有限:
- 需要完备的环境模型
- 计算的复杂度极高
其它方法都是对dp的近似,近似的出发点是解决上面两个问题。
有一种说法是,强化学习其实就是拟动态规划。区别在于,动态规划假设所有参数可知。迭代法
在上一章中,最优价值函数v*和最优动作函数q*可以直接求解,也可以用迭代法逼近。

策略改进过程的解释:
在每个状态s时,对每个可能的动作a,都计算一下采取这个动作后到达的下一个状态的期望价值。看看哪个动作可以到达的状态的期望价值函数最大,就选取这个动作。以此更新π(s)。

两者的区别,值函数的更新不一样。
前者算V,是为了评估此次策略的好坏,所做动作基于策略;
后者算V,是为了寻找最优价值函数。
前者在过程中会产生很多的策略,而后者只在价值函数收敛后才产生一个策略。两种方法都被广泛使用,但哪种更优尚无定论。实际运用中,它们的收敛速度常常比理论最坏情况要快,尤其是使用了好的初始函数和策略的时候。
对于状态空间巨大的问题,比如双陆棋10^20,同步dp需要遍历整个状态空间,仅这一点都做不到。需要使用异步dp,状态的更新顺序是不确定的,因此各状态的更新次数有较大差距。但为了保证正确收敛,在某个节点之后,异步dp不能忽略任何一个状态。
网友认为的迭代策略评估与价值迭代的区别
1、策略迭代在价值评估阶段,每迭代一次都需要保证每个状态的值函数收敛,这是非常耗时的;而值迭代是采用动态规划的思想来收敛每个状态的值函数的。
3、策略迭代的收敛速度更快一些,在状态空间较小时,最好选用策略迭代方法。当状态空间较大时,值迭代的计算量更小一些。
4、侧重点不同:策略迭代最后是策略收敛,而值迭代是值函数收敛;收敛的方式也不同,策略迭代是argmax,而值函数是max。第四点容易理解。
第三点,收敛速度快是指轮数少吗?如果只是轮数少,但每轮的工作很多,那有什么意义?不考虑并发的情况下,不应该永远选择总计算量最小的方法来节省时间吗?迭代策略评估的进一步解释
general policy iteration 广义策略迭代

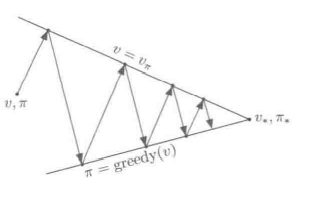
附录
不动点迭代
https://blog.csdn.net/jbb0523/article/details/52459797


-
相关阅读:
数据化管理洞悉零售及电子商务运营——数据化管理介绍
图形学 - 纹理的应用
Markdown语法入门
VMware 新建虚拟机
Qt开发思想探幽]QObject、模板继承和多继承
LeetCode·968.监控二叉树·贪心
思考型人格分析,思考型人格的职业发展方向
脑电眼动数据批处理脚本,基于EEGLAB和EYE-EEG
HTML5+CSS实现图片3D旋转效果,附音乐
人们越来越担心MogaFX外汇储备的减少
- 原文地址:https://blog.csdn.net/weixin_42100211/article/details/120646991