-
【Oracle篇】rman全库异机恢复:从RAC环境到单机测试环境的转移(第四篇,总共八篇)
💫《博主介绍》:✨又是一天没白过,我是奈斯,DBA一名✨
💫《擅长领域》:✌️擅长Oracle、MySQL、SQLserver、阿里云AnalyticDB for MySQL(分布式数据仓库)、Linux,也在扩展大数据方向的知识面✌️
💖💖💖大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注💖💖💖

在上一篇文章中,我们深入探讨了RMAN备份策略的重要性及其制定方法,相信各位对如何构建一个稳健的备份体系已经有了清晰的认识。从这篇文章开始,我们将继续这一话题,但方向将转向RMAN的恢复流程,特别是如何从RAC(Real Application Clusters)环境的RMAN备份片中恢复数据到单机环境。
在企业的数据库运维过程中,备份和恢复是密不可分的两个环节。备份提供了数据安全的保障,而恢复则是确保在数据丢失或系统崩溃时能够迅速恢复业务运行的关键。特别是在RAC环境到单机环境的迁移过程中,恢复流程的正确性和高效性更是至关重要。
本文将详细介绍 如何使用RMAN从RAC环境的备份片中恢复数据到单机环境 。我们将从恢复前的准备工作讲起,涵盖恢复步骤的每一个环节,包括恢复控制文件、数据文件、参数文件、归档等关键组件。同时,我们还将讨论在恢复过程中可能遇到的问题和解决方案,以确保整个恢复过程的顺利进行。
然而,RMAN所涉及的内容之广、之深,使得难以在单篇文章中全面涵盖。所以我将理论、命令、备份策略、异机恢复、坏块处理等分成八篇文章去讲,即使分为八篇也有不少内容没有涵盖到,所以这八篇文章都是精华,看完这八篇就可以解决95%以上的RMAN相关工作内容了。八篇文章的内容分别如下:
- 第一篇:rman物理备份工具的基础理论概述
- 第二篇:rman工具实用指南:常用命令详解与实践
- 第三篇:rman标准化全库备份策略:完整备份or增量备份
- 第四篇:rman全库异机恢复:从RAC环境到单机测试环境的转移(当前篇)
- 第五篇:rman全库异机恢复:从单机环境到RAC测试环境的转移
- 第六篇:rman时间点异机恢复:从单机环境到单机测试环境的转移
- 第七篇:Oracle数据库物理坏块处理:rman修复坏块实践与案例分析
- 第八篇:逻辑备份工具expdp(exp)/impdp(imp)和物理备份工具rman的区别和各自的使用场景总汇
恢复所使用的rman备份片:
在上篇文章中, 我们都知道了rman有完整备份or增量备份,所以通过那种备份都可以实现全库的异机恢复 ,但是我的建议使用rman完整备份+归档备份即可 ,而不建议使用rman基本增量备份+rman差异增量备份+归档备份(为什么使用完整备份可以参考上篇文章的原因哦,我有详细介绍,直通车👉【Oracle篇】rman标准化全库备份策略:完整备份or增量备份(第三篇,总共八篇)_rman 全量备份-CSDN博客👈),所以这篇文章所使用的rman备份片为rman完整备份+归档备份。
那么废话不多说,开始今天的恢复内容!!!
RAC源机:
一、对在RAC上的实例进行全库备份。包括数据文件、控制文件、参数文件、归档。备份策略参考👉【Oracle篇】rman标准化全库备份策略:完整备份or增量备份(第三篇,总共八篇)_rman 全量备份-CSDN博客👈

二、通过nfs或者scp到目标FS数据库。源库和异机的备份片的路径要一致,不然报找不到备份片。如果路径不一致可以通过catalog将未识别的RMAN备份集注册到控制文件:
scp拷贝到FS异机的/backup/full目录下:

FS异机:
一、FS已经安装好了一套单机,与源库实例名可以保持一致,也可以不一致。进行还原文件。
(1)定义一个空实例的SID名,启动到nomount状态
注意:db_unique_name、service_names、instance_name不会涉及在控制文件里,但db_name会涉及到控制文件和数据文件头部中。所以db_name进行异机迁移,不管迁移到FS还是迁移到rac环境,db_name是不能变的。想要变动db_name就只能通过expdp这种逻辑迁移等。
- [oracle@11g dbs]$ vi /oracle/app/oracle/product/11.2.0/db_1/dbs/initorcl.ora
- *.db_name='orcl'
- *.instance_name='orcl'
- [oracle@11g ~]$ export ORACLE_SID=orcl
- SQL> startup nomount
(2)还原参数文件
- [oracle@rac1 ~]$ rman target /
- run {
- ALLOCATE CHANNEL ch00 TYPE disk;
- restore spfile to '/oracle/app/oracle/product/11.2.0/db_1/dbs/spfileorcl.ora' from '/backup/full/orcl_spfile_1684_1_20240123';
- release channel ch00;
- }
- SQL> create pfile='/oracle/app/oracle/product/11.2.0/db_1/dbs/pfileorcl.ora' from spfile='/oracle/app/oracle/product/11.2.0/db_1/dbs/spfileorcl.ora';
- [oracle@11g dbs]$ vi /oracle/app/oracle/product/11.2.0/db_1/dbs/pfileorcl.ora
- *.audit_file_dest='/oracle/app/oracle/admin/orcl/adump'
- *.audit_trail='NONE'
- *.compatible='11.2.0.4.0'
- *.db_block_size=8192
- *.db_domain=''
- *.db_files=8192
- *.db_name='orcl'
- *.instance_name='orcl'
- *.diagnostic_dest='/oracle/app/oracle'
- *.dispatchers='(PROTOCOL=TCP) (SERVICE=orclXDB)'
- *.log_archive_format='%t_%s_%r.arc'
- *.memory_target=2306867200
- *.remote_login_passwordfile='exclusive'
- *.log_archive_dest_1='location=/oracle/app/oracle/product/11.2.0/db_1/dbs/arch'
- SQL> create spfile='/oracle/app/oracle/product/11.2.0/db_1/dbs/spfileorcl.ora' from pfile='/oracle/app/oracle/product/11.2.0/db_1/dbs/pfileorcl.ora';
- SQL> shutdown immediate
- SQL> startup nomount
- SQL> show parameter spfile

(3)还原控制文件
- [oracle@lf ~]$ rman target /
- run {
- ALLOCATE CHANNEL ch00 TYPE disk;
- restore controlfile to '/oracle/app/oracle/oradata/orcl/control.ctl' from '/backup/full/orcl_ctl_1683_1_20240123';
- release channel ch00;
- }
- 修改控制文件的参数,启动至mount状态:
- SQL> show parameter control
- SQL> alter system set control_files='/oracle/app/oracle/oradata/orcl/control.ctl' scope=spfile;
- SQL> shutdown immediate
- SQL> startup mount
- SQL> show parameter control

(4)重命名redo日志组
注意:1)通过rman定义set newname for logfile设置路径失败,所以只能在sqlplus中重命名redo日志组。12c版本之后可能支持了在rman中定义set newname for logfile(待验证)
2)只进行重命名redo日志组操作,先不进行删除和重建redo日志组,如果同时进行重建redo日志组,就会导致在后续追归档日志阶段不能应用归档日志(执行recover database using backup controlfile until cancel;命令,报错ORA-01547: warning: RECOVER succeeded but OPEN RESETLOGS would get error below ORACLE)
3)先还原数据文件,然后再重命名redo日志组,可能会导致v$logfile里面日志组的路径全部直接成为了+ASM磁盘组没有具体路径的情况,比如:全部都成了+DATA这样,这样的话部分日志组因为当前在用删除不了,并且重命名redo日志组是需要具体路径的,但是都变成了+DATA就没有办法识别到是哪一个日志组。所以先进行redo日志组的重命名,然后再进行数据文件还原,就可以避免这个问题。
- SQL> select * from v$logfile; ---重做日志组
- SQL> select * from v$standby_log; ---镜像日志组(dg)

- SQL>
- alter database rename file '+DATA/orcl/onlinelog/group_1.266.1140875825' to '/oracle/app/oracle/oradata/orcl/redo1.log';
- alter database rename file '+DATA/orcl/onlinelog/group_2.257.1140875825' to '/oracle/app/oracle/oradata/orcl/redo2.log';
- alter database rename file '+DATA/orcl/onlinelog/group_3.275.1140875827' to '/oracle/app/oracle/oradata/orcl/redo3.log';
- alter database rename file '+DATA/orcl/onlinelog/group_4.276.1140875827' to '/oracle/app/oracle/oradata/orcl/redo4.log';
- alter database rename file '+DATA/orcl/onlinelog/group_5.281.1140882455' to '/oracle/app/oracle/oradata/orcl/redo5.log';
- alter database rename file '+DATA/orcl/onlinelog/group_6.293.1140883981' to '/oracle/app/oracle/oradata/orcl/redo6.log';
- alter database rename file '+DATA/orcl/onlinelog/group_7.294.1140883981' to '/oracle/app/oracle/oradata/orcl/redo7.log';
- alter database rename file '+DATA/orcl/onlinelog/group_8.295.1140883981' to '/oracle/app/oracle/oradata/orcl/redo8.log';
(5)还原数据文件
注意:rman备份记录在控制文件中,启动到mount状态时,就可以查到rman的备份信息。在恢复数据文件时,会自动找备份片的位置进行恢复,所以源库和异机的备份片的路径要一致,不然报找不到备份片。如果路径不一致可以通过catalog将未识别的RMAN备份集注册到控制文件。
- RMAN> CATALOG START WITH '/backup/full'; ---注册目录(多用于批量注册归档,也可以用于注册备份片)
- RMAN> report schema; ---显示实例的信息。根据数据文件和临时文件ID恢复

- RMAN>
- run {
- ALLOCATE CHANNEL ch00 TYPE disk;
- ALLOCATE CHANNEL ch01 TYPE disk;
- ###还原数据文件到新的路径
- set newname for datafile 1 to '/oracle/app/oracle/oradata/orcl/system.259.1140874089';
- set newname for datafile 2 to '/oracle/app/oracle/oradata/orcl/sysaux.260.1140874091';
- set newname for datafile 3 to '/oracle/app/oracle/oradata/orcl/undotbs1.261.1140874091';
- set newname for datafile 4 to '/oracle/app/oracle/oradata/orcl/undotbs2.263.1140874093';
- set newname for datafile 5 to '/oracle/app/oracle/oradata/orcl/users.264.1140874093';
- set newname for datafile 6 to '/oracle/app/oracle/oradata/orcl/itpux.277.1140877153';
- set newname for datafile 7 to '/oracle/app/oracle/oradata/orcl/liu.472.1158545801';
- set newname for datafile 8 to '/oracle/app/oracle/oradata/orcl/liu.427.1153721763';
- ###还原临时文件到新的路径
- set newname for tempfile 1 to '/oracle/app/oracle/oradata/orcl/temp.262.1140874091';
- ###自动全库恢复。restore database会导致所有文件覆盖还原所以谨慎,restore datafile是指定单个文件从rman中还原。
- restore database;
- ###将已发出SET NEWNAME for DATAFILE命令的所有数据文件切换为其新名称。如果是asm管理的文件可能在设置路径时出现问题,导致控制文件的路径和物理路径不对应。所以建议源库为asm转文件系统时不设置这个参数,手动注册和通知控制文件路径catalog datafilecopy和switch datafile。
- switch datafile all;
- release channel ch00;
- release channel ch01;
- }
(6)查看数据文件头部和控制文件头部还原的时间
- SQL> select name from v$datafile;
- SQL> SELECT FILE#,to_char(checkpoint_change#,'999999999999') ,TO_CHAR(CHECKPOINT_TIME,'YYYY-MM-DD HH24:MI:SS') CPTIME FROM v$datafile_header; ---数据文件头部
- SQL> SELECT FILE#,to_char(checkpoint_change#,'999999999999'),TO_CHAR(CHECKPOINT_TIME,'YYYY-MM-DD HH24:MI:SS') CPTIME FROM V$DATAFILE; ---控制文件头部
二、恢复数据
(1)还原归档
注意:先执行一遍recover database using backup controlfile until cancel;和v$datafile_header、V$DATAFILE就会输出当前恢复的SCN时间,然后根据时间再决定恢复几天的归档,或者也会显示从那个归档开始恢复,确定了开始恢复的归档号之后,就按照序列号恢复RESTORE ARCHIVELOG sequence,恢复到最新的序列号通过list backup查看最后一个备份的归档号。
- RMAN>
- run{
- ALLOCATE CHANNEL ch00 TYPE disk;
- set archivelog destination to '/backup/arch';
- restore archivelog from time 'sysdate-10';
- release channel ch00;
- } ---如果恢复报错no backup of archived log,根据序列号恢复RESTORE ARCHIVELOG sequence BETWEEN 5877 AND 5971 thread 2;
(2)追归档日志(使用备份的控制文件恢复时,控制文件会根据归档追scn,同时数据文件的scn也会恢复的最新)
- SQL> set logsource /backup/arch; ---set logsource +路径:设置的是数据库读取归档的路径,默认的读取的路径是archive log list,如果通过rman恢复的是其他路径,那么就需要重新设置一下读取归档的路径。
- SQL> recover database using backup controlfile until cancel;
- auto
- SQL> recover database using backup controlfile until cancel;
- Cancel
- SQL> SELECT FILE#,to_char(checkpoint_change#,'999999999999') ,TO_CHAR(CHECKPOINT_TIME,'YYYY-MM-DD HH24:MI:SS') CPTIME FROM v$datafile_header; ---数据文件头部
- SQL> SELECT FILE#,to_char(checkpoint_change#,'999999999999'),TO_CHAR(CHECKPOINT_TIME,'YYYY-MM-DD HH24:MI:SS') CPTIME FROM V$DATAFILE; ---控制文件头部
(3)删除不必要的redo日志组
- SQL> select * from v$logfile; ---重做日志组
- SQL> select * from v$standby_log; ---镜像日志组(dg)

- SQL>
- alter database drop logfile group 5;
- alter database drop logfile group 6;
- alter database drop logfile group 7;
- alter database drop logfile group 8;
(4)重建临时文件
- SQL> shutdown immediate
- SQL> startup
- SQL> alter database open resetlogs;
- SQL> select * from v$tablespace; ---表空间中有temp表空间但是告警日志中显示需要重建信息的temp数据文件


- temp临时文件的路径还是+ASM磁盘组,所以新增一个临时文件,然后删除临时文件为1的+ASM磁盘组的临时文件:
- SQL> select * from v$tempfile;
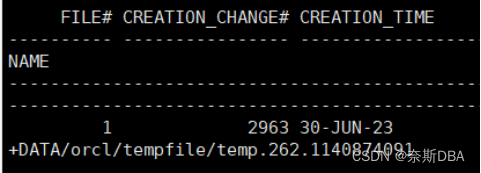
- SQL> alter tablespace temp add tempfile '/oracle/app/oracle/oradata/orcl/temp.dbf' size 31G autoextend off;
- SQL> alter tablespace temp drop tempfile 1;
- 注意:如果删除临时文件失败,需要先删除临时表空间,然后重建。
(5)禁用重做日志线程2。因为原先是rac环境,所以每个实例都是独立的redo线程,现在恢复到单机只需要1个redo线程,单机只会在线程1的日志组来回切换
- SQL> select * from v$logfile; ---重做日志组
- SQL> select * from v$standby_log; ---镜像日志组(dg)
- SQL> select * from v$log; ---rac环境下有多个线程的重做日志组,所以在单机环境下重做日志只保留线程1

- SQL> alter database disable thread 2; ---禁用重做日志线程2
- SQL>
- alter database drop logfile group 3;
- alter database drop logfile group 4;
(6)删除UNDOTBS2表空间(undo同redo一样是分线程的)
SQL> drop tablespace UNDOTBS2 including contents and datafiles;三、启动单机数据库
- SQL> shutdown immediate
- SQL> startup
四、物理迁移完成查看状态
(1)通过rman恢复的实例是和生产环境一模一样的,所以只需要做后续参数部分的优化
参数优化参考RAC环境的配置即可😄
(2)检查实例情况
- 数据库文件和undo:
- set linesize 500
- set pagesize 99
- col file_name for a70
- col file_id for 9999999
- col status for a10
- col ts_name for a25
- col cur_mb for 99999
- col max_mb for 99999
- select status, file_id, file_name, tablespace_name ts_name,blocks/128 tolal_mb, maxblocks/128 max_mb,AUTOEXTENSIBLE from dba_data_files order by file_name;
- temp临时表空间:
- select username,temporary_tablespace from dba_users;
- set linesize 230
- col file_name for a65
- select FILE_ID,FILE_NAME,TABLESPACE_NAME,bytes/1024/1024 tolal_mb,status,AUTOEXTENSIBLE,MAXBYTES/1024/1024 max_mb from dba_temp_files;
- redo重做日志:
- set linesize 230
- col member for a50
- select * from v$logfile;
- select * from v$log;
- 查看数据库实例的状态和模式:
- select instance_name , status from v$instance ;
- select name, open_mode from v$database ;
兄弟们关于《rman全库异机恢复:从RAC环境到单机测试环境的转移》这篇文章就到这里啦,我自己觉得这篇文章写的非常详细了,并且我自己也在多次恢复中验证过,所以各位希望各位可以 收藏、点赞、加关注 ,既然讲解了从生产RAC环境到单机测试恢复,那么就不得不提从生产单机环境到RAC测试恢复,那么下篇将带来《rman全库异机恢复:从单机环境到RAC测试环境的转移》哦。
-
相关阅读:
定时器及其应用
Practice Exam: Oracle Cloud Infrastructure Generative AI Professional
C语言中,基本数据类型介绍
Ajax系列之错误处理
专访D-Wave CEO:量子计算的过去、现在和未来
在githhub上创建个人展示主页的方法
JavaScript 71 JavaScript JSON 71.9 JSON 服务器
牛客网刷题(一)
Java编码规范--OOP规约
WPF基础:在Canvas上绘制图形
- 原文地址:https://blog.csdn.net/naisiing/article/details/139396420