-
安装sbt利用开发工具IntelliJ IDEA编写Spark应用程序(Scala+SBT)参考林子雨教程
1、安装sbt
sbt(Simple Build Tool)是对Scala或Java语言进行编译的一个工具,类似于Maven或Ant,需要JDK1.8或更高版本的支持,并且可以在Windows和Linux两种环境下安装使用。sbt需要下载安装,可以访问“http://www.scala-sbt.org”下载安装文件sbt-1.3.8.tgz,保存到下载目录。假设下载目录为“~/Downloads”,安装目录为“/usr/local/sbt”,则执行如下命令将下载后的文件拷贝至安装目录中:
sudo mkdir /usr/local/sbt 创建安装目录 cd ~/Downloads sudo tar -zxvf ./sbt-1.3.8.tgz -C /usr/local cd /usr/local/sbt sudo chown -R hadoop /usr/local/sbt 此处的hadoop为系统当前用户名 cp ./bin/sbt-launch.jar ./ #把bin目录下的sbt-launch.jar复制到sbt安装目录下接着在安装目录中使用下面命令创建一个Shell脚本文件,用于启动sbt:
vim /usr/local/sbt/sbt该脚本文件中的代码如下:
#!/bin/bash SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M" java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"保存后,还需要为该Shell脚本文件增加可执行权限:
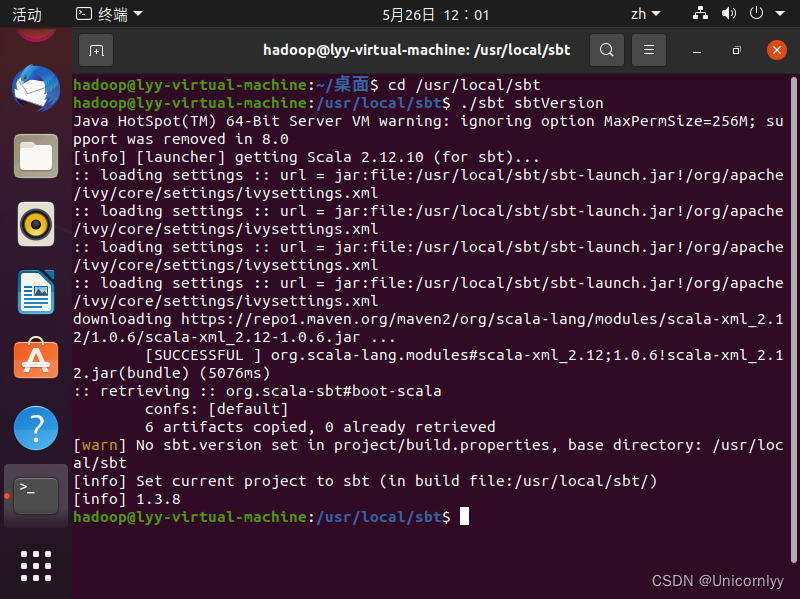
chmod u+x /usr/local/sbt/sbt然后,可以使用如下命令查看sbt版本信息:
cd /usr/local/sbt ./sbt sbtVersion上述查看版本信息的命令,可能需要执行几分钟,执行成功以后就可以看到版本为1.3.8。
2、下载安装IDEA
本次运行系统为Ubuntu20.04。
我们可以访问官网下载安装包。文件较大,一般需要20分钟左右。有两种下载选择,我们选择下载正版,教程将使用试用版的idea。
下载后,我们把压缩包解压并且改名。
cd ~/Downloads sudo tar -zxvf ideaIU-2024.1.2.tar.gz sudo mv idea-IU-241.17011.79 /usr/local/Intellij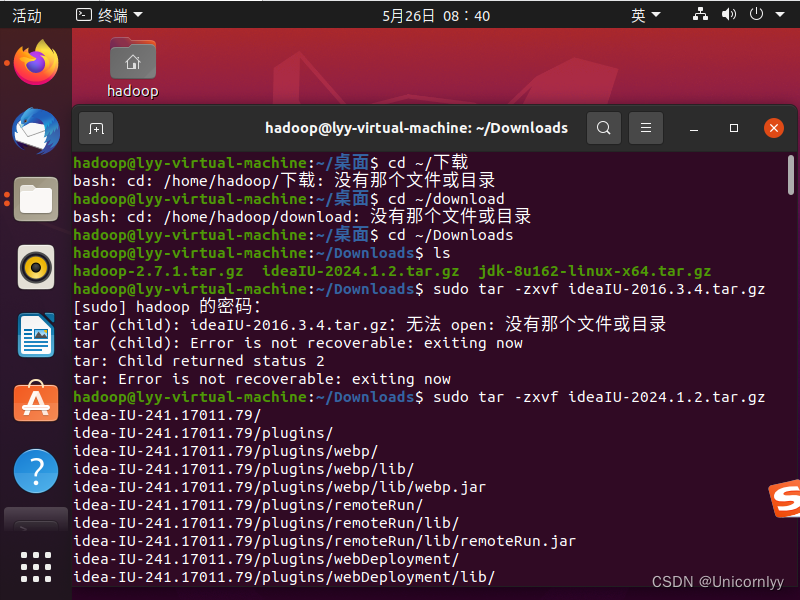
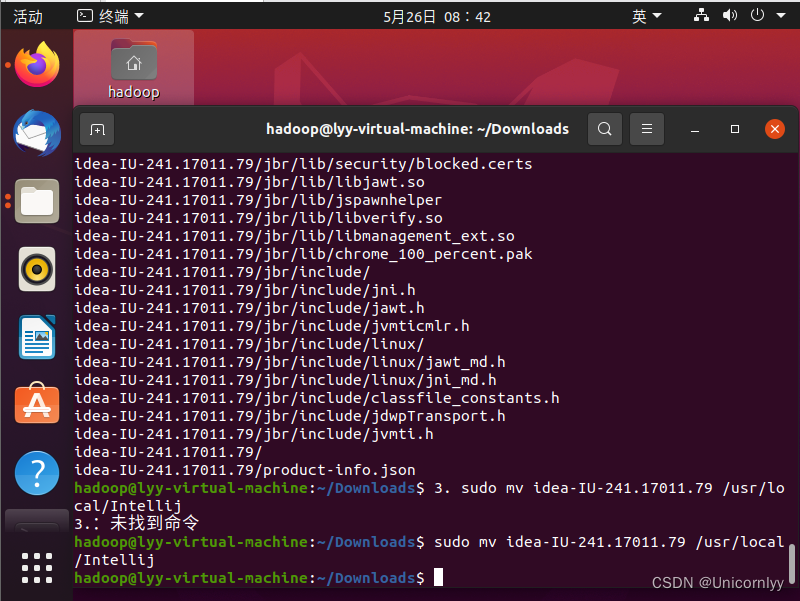
然后我们打开Intellij文件夹,并且使用其bin文件夹下的idea.sh打开程序。cd /usr/local/Intellij/bin ./idea.sh
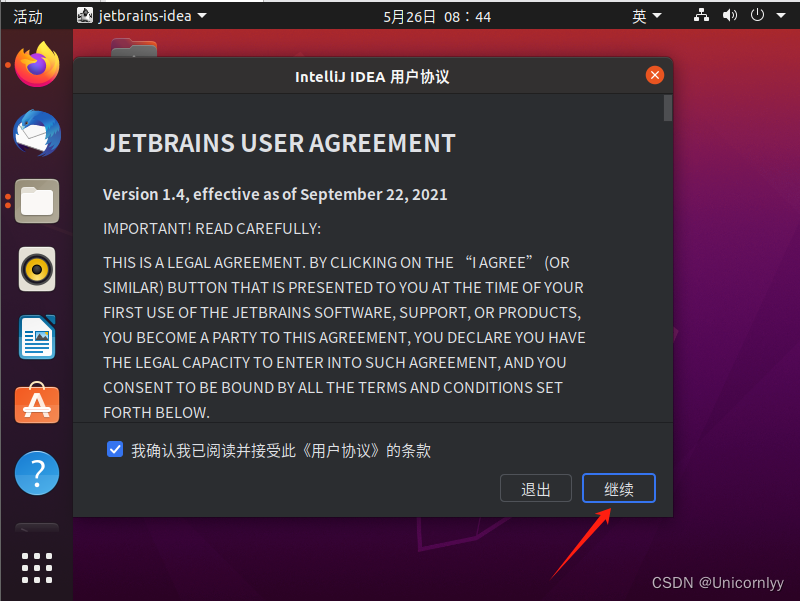
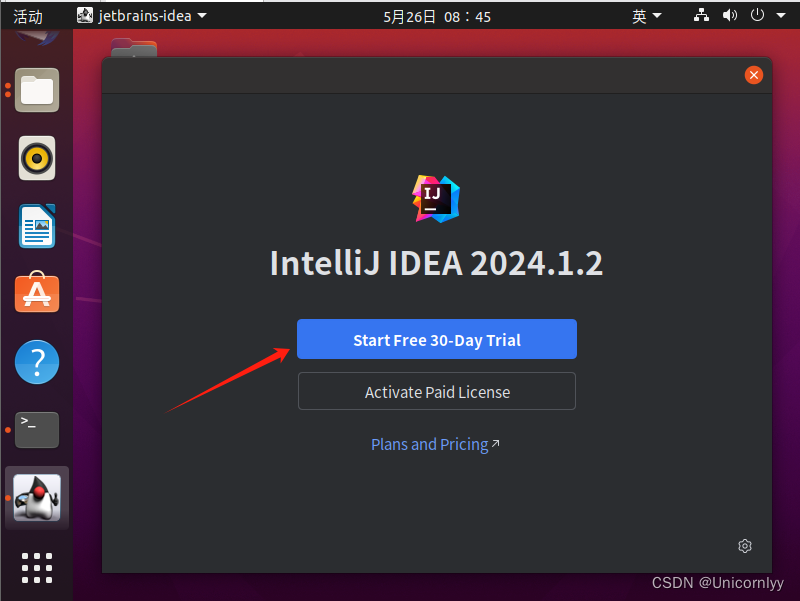
选择start free 30-day trial进入免费试用版。
接下来我们要把程序放到启动栏里快捷启动。
首先进入到applications文件夹下,并且编辑idea.desktop文件cd /usr/share/applications sudo gedit idea.desktop
在打开的文档里添加如下内容[Desktop Entry] Encoding=UTF-8 Version=1.0 Name=IntelliJ IDEA GenericName=Java IDE Comment=IntelliJ IDEA is a code-centric IDE focused on developer productivity. The editor deeply understands your code and knows its way around the codebase, makes great suggestions right when you need them, and is always ready to help you shape your code. Exec=/usr/local/Intellij/bin/idea.sh Icon=/usr/local/Intellij/bin/idea.png Terminal=false Type=Application Categories=Development;IDE然后保存(Ctrl+S)关闭,我们在启动栏里选择查找程序的那个应用(一般在启动栏第一个)。搜索Intellij即可找到程序,点击就可以启动idea。这时候我们就可以把程序锁定到启动栏使用了。如果搜索没找到,请重启系统。

3、给IDEA安装中文插件
首先如图打开plugins界面。

在顶部的搜索框里面,输入Chinese,就可以找到中文的汉化插件。

我们点击Install,就会开始下载安装插件,安装完成后,我们点击Restart IDE,重启后,就可以显示中文的IDEA界面了。4、在Intellij里安装scala插件,构建基于SBT的Scala项目
搜索并安装scala。
如下图,按顺序执行如下操作:
新建项目
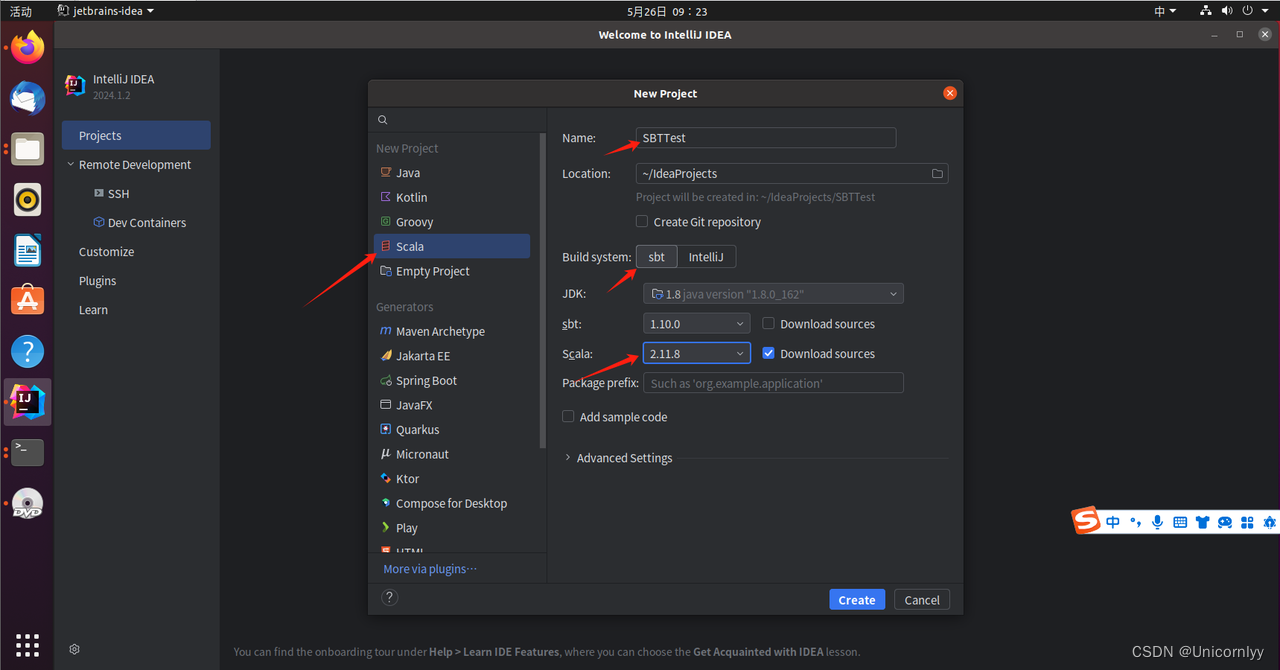
选择Scala—>SBT,设置项目名,这里需要设置Scala的版本必须2.11.*的版本号。因为Spark 2.0是基于Scala 2.11构建的。这个可以在Spark的官网查到,如下图:

点击create利用SBT 添加依赖包
利用Spark的官网查到Spark artifacts的相关版本号,如下图:
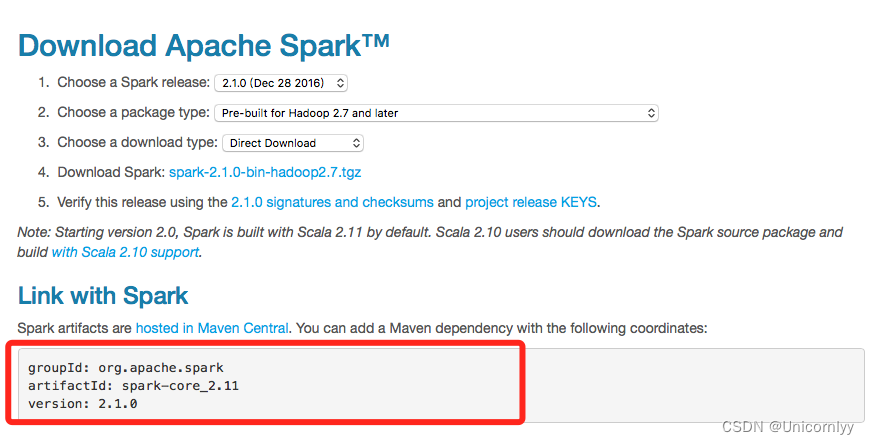
编辑Intellij Idea项目中是build.sbt:name := "SBTTest" version := "1.0" scalaVersion := "2.11.8" libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
编辑后,如果Intellij Idea弹出提示,如图:

可以选择Refresh Project手动刷新,也可以选择Enable auto-import让Intellij Idea以后每次遇到build.sbt更新后自动导入依赖包。创建WordCount实例
在Linux系统中新建一个命令行终端(Shell环境),在终端中执行如下命令,新建word.txt测试文件:
echo "hadoop hello spark hello world" > ~/word.txt
在Intellij Idea的src/main/scala项目目录下新建WordCount.scala文件,如下图(注意看图下面的备注):
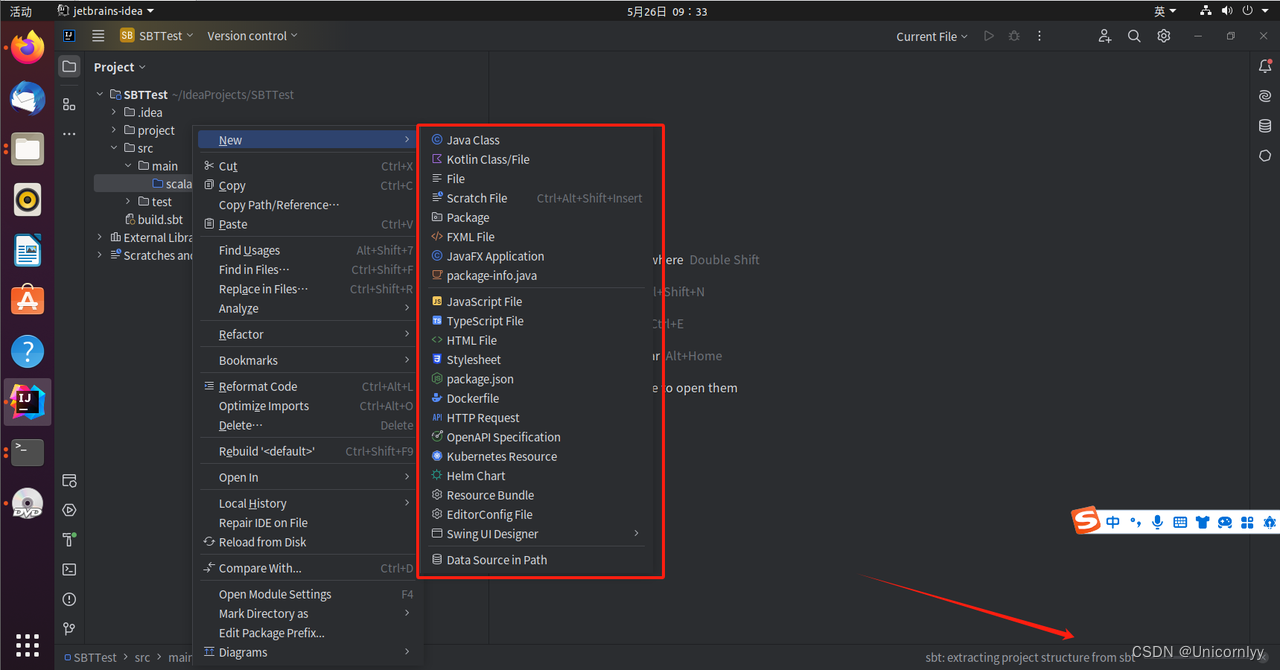
备注:这里需要注意,在Intellij Idea启动时,会执行“extracting project structure from sbt”的操作,也就是把sbt所需要的项目结构从远程服务器拉取到本地,在本地会生成sbt所需要的项目结构。由于是从国外的远程服务器下载,所以,这个过程很慢,笔者电脑上运行了15分钟。这个过程没有结束之前,上图中的“File->New”弹出的子菜单是找不到Scala Class这个选项的。所以,一定要等“extracting project structure from sbt”的操作全部执行结束以后,再去按照上图操作来新建Scala Class文件。
#解决SBT下载慢,dump project structure from sbt问题参考
有1个问题需要注意一下需要大写的D

终于有了wwu
新建Scala Class文件的代码如下:import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf import org.apache.log4j.{Level,Logger} object WordCount { def main(args: Array[String]) { //屏蔽日志 Logger.getLogger("org.apache.spark").setLevel(Level.WARN) Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF) val inputFile = "file:///home/hadoop/word.txt" val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]") val sc = new SparkContext(conf) val textFile = sc.textFile(inputFile) val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) wordCount.foreach(println) } }右键WordCount.scala,选择执行该文件,如下图:
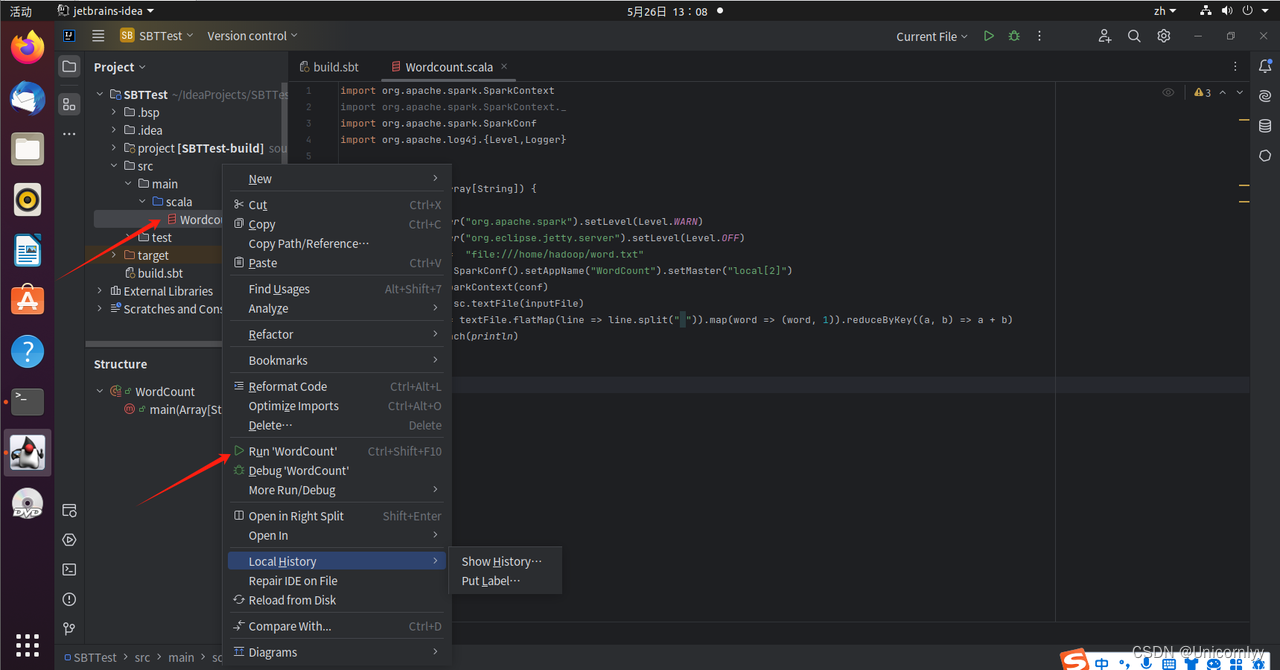
注意类名与文件名统一一下,不然会报错
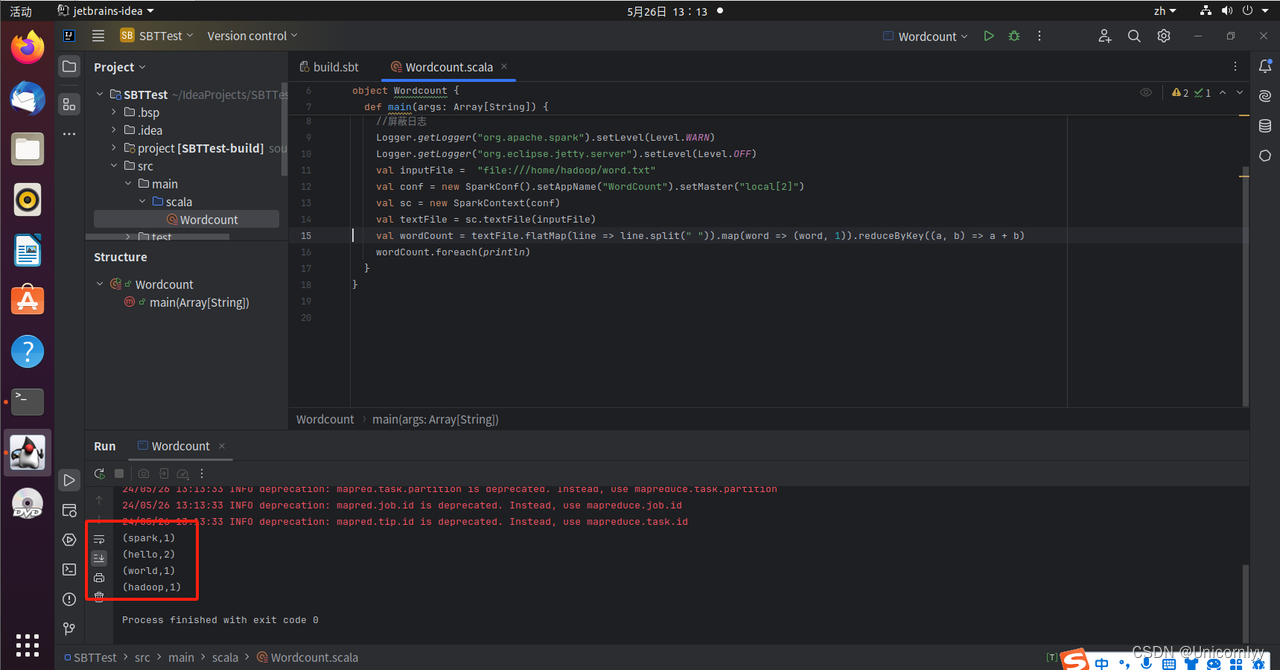
看到输出结果了终于,一上午没白干!!! -
相关阅读:
python 正则的简单用法
dmp广告系统
spinal HDL - 11 - 使用状态机语法编写“1001“序列检测
数据结构-----二叉排序树
const // It is a const object...class nullptr_t
医疗行业:容灾备份平台建设及运维难点
AJAX初
Pytorch入门实例
JVM--Java类加载器笔记
stable diffusion绘图(checkpoint:Hassaku, lora:blindbox)
- 原文地址:https://blog.csdn.net/m0_68165821/article/details/139225220