-
网页中的音视频裁剪&拼接&合并
一、需求描述
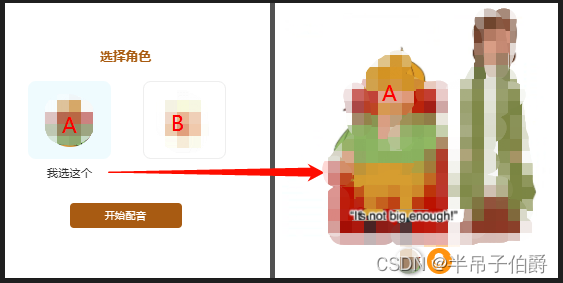
项目中有一个配音需求:
1)首先,前台会拿到一个英语视频,视频的内容是A和B用英语交流;
2)然后,用户可以选择为某一个角色配音,假如选择为A配音,那么视频在播放到A的位置时会静音,并录制用户的声音。以此类推,直到视频播放结束;
3)最后,将用户的录音替换到视频中,并生成新的视频文件,后续上传服务器。
另外,已知每个角色说话的起始时间和结束时间(这个由后台管理来配置)。
二、需求分析
2.1 实现方式
实现该功能的方式大体有两个:
1)使用ffmpeg.wasm
2)使用Web Audio API等原生JS
第二种方式我没实践,但理论上应该可以实现,只是估计会较复杂,代码较多;此处,我选择方式一。
2.2 功能拆分
根据该功能的操作流程,可将其拆分为:
1)音视频分离,获得纯音频文件和纯视频文件
2)音频剪切,从上一步得到的音频文件中裁剪到除配音角色外的其它音频片段
3)录音,获取到配音音频片段
4)音频拼接,将上面两步得到的音频片段按顺序拼接成一个
5)音视频合并,将纯视频文件和上一步得到的音频文件合并为一个文件

三、代码实现
3.1 引入依赖库
- <script src="/js/ffmpeg/umd/ffmpeg.js">script>
- <script src="/js/util/umd/index.js">script>
3.2 初始化ffmpeg
- const { fetchFile } = FFmpegUtil;
- const { FFmpeg } = FFmpegWASM;
- let ffmpeg = new FFmpeg();
- await ffmpeg.load({coreURL: "/js/core/umd/ffmpeg-core.js",});
3.3 音视频分离
- // 在Demo中,视频文件通过input[type=file]标签获得
- const { name, size } = files[0];
- await ffmpeg.writeFile(name, await fetchFile(files[0]));
- // 音视频分离
- await ffmpeg.exec(['-i', name, '-c:v', 'copy', '-an', 'output.mp4'])
- await ffmpeg.exec(['-i', name, '-vn', '-acodec', 'libmp3lame', 'output.mp3'])
在上面代码中-acodec标识了使用mp3音频编码器,如果使用copy原音频的编码方式,在网页中可能会报错“Invalid audio stream. Exactly one MP3 audio stream is required”
await ffmpeg.exec(['-i', name, '-vn', '-acodec', 'copy', 'output.mp3']); // 会报错3.4 音频剪切
- // -ss 起始时间,-t 持续时间
- await ffmpeg.exec(['-i', 'output.mp3', '-ss', '00:00:00.000', '-t', '00:00:10.000', 'split_0.mp3'])
- await ffmpeg.exec(['-i', 'output.mp3', '-ss', '00:00:20.000', '-t', '00:00:10.000', 'split_2.mp3'])
3.5 配音录制
- const record = (duration, callback) => {
- if (!duration) return;
- // 变量及函数声明
- recorder = [];
- recordTimer = null;
- let _isStop = false;
- async function startRecording () {
- const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
- mediaRecorder = new MediaRecorder(stream, { mimeType: 'audio/webm' });
- mediaRecorder.ondataavailable = handleDataAvailable;
- mediaRecorder.start();
- }
- function handleDataAvailable(event) {
- if (recorder) { recorder.push(event.data); }
- if (_isStop) {callback && callback();}
- }
- function stopRecording() {
- mediaRecorder.stop();
- _isStop = true;
- }
- // 调用
- startRecording();
- recordTimer = setTimeout(() => {
- stopRecording();
- }, duration);
- }
在上面这段代码中,需要注意的是:录音结束后的回调函数是放在handleDataAvailable中的,这是因为当mediaRecorder.stop()停止录制后,会再出发一次dataavailable事件,然后才把最后的数据分片存储到recorder中。所以代码中定义了一个_isStop变量来辅助完成这个过程。
- // 将配音数据保存到文件
- let split_1 = await audioChunks2Unit8Array(recorder);
- await ffmpeg.writeFile('split_1.mp3', split_1);
在上面这段代码中,之前获得的录音数据是个Blob数组,ffmpeg不支持直接对其进行操作,所以要将它转换为Unit8Array才能写到文件。
3.6 音频拼接
await ffmpeg.exec(['-i', 'split_0.mp3', '-i', 'split_1.mp3', '-i', 'split_2.mp3', '-filter_complex', '[0:a][1:a][2:a]concat=n=3:v=0:a=1', '-ac', '2', '-c:a', 'libmp3lame', '-q:a', '4', 'merge.mp3'])参数解释:
[0:a][1:a][2:a]concat=n=3: 将第一段素材的音频、a1和a2合并,n=3表示三段。
v=0:a=1: 不要声音,只要音频。
-ac:设定声音的channel数
-c:a:指定音频编码器
libmp3lame:mp3音频编码器
-q:a:表示输出的音频质量,一般是1到5之间(1为质量最高)
3.7 音视频合并
await ffmpeg.exec(['-i', 'output.mp4', '-i', 'merge.mp3', '-c:v', 'copy', '-c:a', 'copy', 'result.mp4'])参数解释:
-c:v copy:视频编码不变。
-c:a copy :音频编码不变。
最后得到合并后的视频数据(Unit8Array)。
四、附件
之前在网上查找ffmpeg.wasm资源时,很多都残缺不全,所以把相关的依赖库放在网盘了(文件来自官方github仓库,其中的示例页面我稍微美化了一下样式)。
https://download.csdn.net/download/xueshen1106/88772981
-
相关阅读:
[GYCTF2020]Ezsqli
【STM32】工程配置,存储空间分别情况,常用操作
内网穿透的应用-如何本地部署Elasticsearch搜索分析引擎实现并发布公网远程访问
SpringBoot与Loki的那些事
绿盾加密如何顺利切换成IP-Guard加密
水质查询接口
1997-2020年31省进出口总额
陕西cas:2055042-71-0N-(炔-四聚乙二醇)-生物素价格
Mysql的SQL调优-面试
动态规划之打家劫舍系列
- 原文地址:https://blog.csdn.net/xueshen1106/article/details/139300847