-
Kafka系列之高频面试题
基础
简介
特点:
- 高吞吐、低延迟:kafka每秒可以处理几十万条消息,延迟最低只有几毫秒,每个Topic可以分多个Partition,Consumer Group对Partition进行Consumer操作
- 可扩展性:Kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许
n-1个节点失败) - 高并发:支持数千个客户端同时读写
应用场景
包括:
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种Consumer,如Hadoop、HBase等
- 消息系统:解耦和生产者和消费者、缓存消息等
- 用户活动跟踪:记录web或app用户的各种活动,如浏览网页、搜索等,这些活动信息被各个服务器发布到Kafka的Topic中,然后订阅者通过订阅这些Topic来做实时的监控分析,或存储到Hadoop、数据仓库中做离线分析和挖掘
- 运营指标:记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告
- 流式处理:如Spark Streaming和Flink
概念
ISR:In-Sync Replicas,副本同步队列
OSR:Out-of-Sync Replicas,非副本同步队列
AR:Assigned Replicas所有副本ISR是由Leader维护,Follower从Leader同步数据有一些延迟,超过配置的阈值会把Follower剔除出ISR,存入OSR列表,新加入的Follower也会先存放在OSR中。AR=ISR+OSR。
Offset:偏移量
LEO:Log End Offset,当前日志文件中下一条,每个副本最大的Offset
HW:High Watermark,高水位,通常被用在流式处理领域,以表征元素或事件在基于时间层面上的进度。是ISR队列中最小的LEO。消费者最多只能消费到HW所在的位置上一条信息。
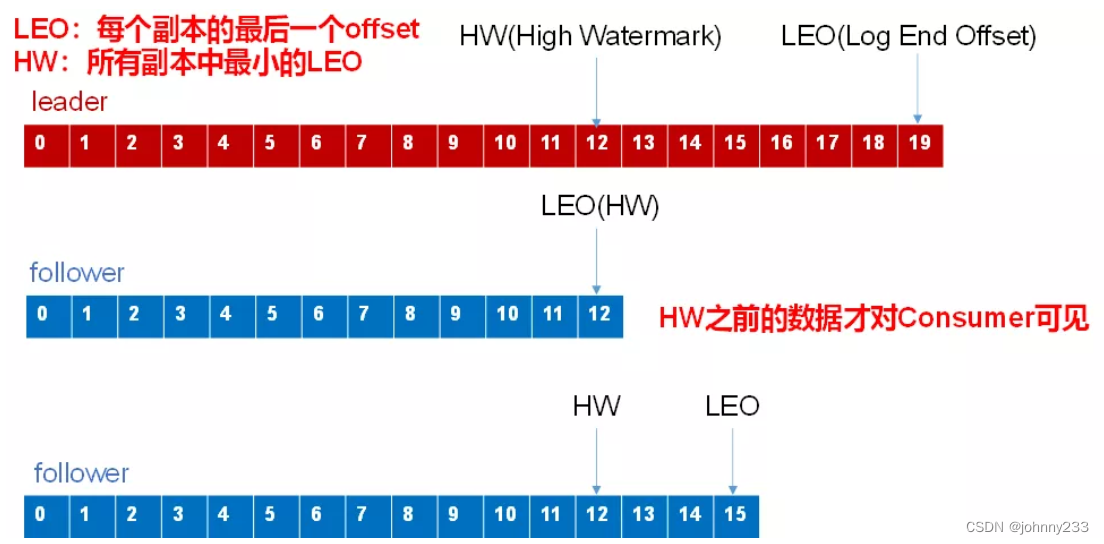
LSO:Last Stable Offset,对未完成的事务而言,LSO的值等于事务中第一条消息的位置(First Unstable Offset),对已完成的事务而言,它的值同HW相同
LW:Low Watermark,低水位,代表AR集合中最小的LSO值。负载均衡
Kafka的负载均衡就是每个Broker都有均等的机会为Kafka的客户端(生产者与消费者)提供服务,可以将负载分散到集群中的所有机器上。通过智能化的分区领导者选举来实现负载均衡,可在集群的所有机器上均匀分散各个Partition的Leader,从而整体上实现负载均衡。
故障处理与转移
故障分Follower故障和Leader故障:
- Follower故障
Follower发生故障后会被临时踢出ISR,待该Follower恢复后,Follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始与Leader进行同步。等该Follower的LEO大于等于该Partition的HW,即Follower追上Leader后,可重新加入ISR。
- Leader故障
Leader发生故障后,会从ISR中选出一个新的Leader,为保证多个副本之间的数据一致性,其余的Follower会先将各自的log文件高于HW的部分截掉,然后从新的Leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复
Kafka的故障转移是通过使用会话机制实现的,每台Kafka服务器启动后会以会话的形式把自己注册到ZK服务器上。一旦服务器运转出现问题,就会导致与ZK的会话不能维持从而超时断连,此时Kafka集群会选举出另一台服务器来完全替代这台服务器继续提供服务。
分区
Q:分区的作用?
A:实现Broker负载均衡。对于消费者来说,提高并发度。Q:一个Topic对应几个Partition?
Q:分区取值原则?
A:按照如下顺序判断:- 指明Partition的情况下,直接将指明的值作为Partition值
- 没有指明Partition值但有Key的情况下,将Key的Hash值与Topic的Partition值进行取余得到Partition值
- 既没有Partition值又没有Key值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与Topic可用的Partition总数取余得到Partition值,即round-robin算法
Q:Kafka分区数可以增加或减少吗?
A:可使用bin/kafka-topics.sh命令增加Kafka的分区数,但不支持减少分区数。Kafka分区数据不支持减少是由很多原因的,比如减少的分区内数据放到哪里去?是删除,还是保留?删除的话,这些没消费的消息不就丢了。如果保留这些消息如何放到其他分区里面?追加到其他分区后面的话那么就破坏Kafka单个分区的有序性。如果要保证删除分区数据插入到其他分区保证有序性,实现起来逻辑就会非常复杂。
Q:Kafka新建的分区会在哪个目录下创建?
A:在启动Kafka集群之前,需提前配置好log.dirs或log.dir参数,其值是Kafka数据的存放目录,可配置多个目录,使用逗号分隔,通常这些目录是分布在不同的磁盘上用于提高读写性能。如果
log.dirs参数只配置一个目录,那么分配到各个Broker上的分区肯定只能在这个目录下创建文件夹用于存放数据。如果
log.dirs参数配置多个目录,Kafka会在哪个文件夹中创建分区目录呢?Kafka会在含有分区目录最少的文件夹中创建新的分区目录,分区目录名为Topic名+分区ID。分区文件夹总数最少的目录,而不是磁盘使用量最少的目录!即,如果你给log.dirs参数新增一个新的磁盘,新的分区目录肯定是先在这个新的磁盘上创建直到这个新的磁盘目录拥有的分区目录不是最少为止。ACK
Producer有三种ACK机制
- 0:相当于异步操作,Producer不需要Leader给予回复,发送完就认为成功,继续发送下一批消息。此机制具有最低延迟,但是持久性可靠性也最差,当服务器发生故障时,很可能发生数据丢失
- 1:默认设置。表示Producer要Leader确认已成功接收数据才发送下一批消息。不等待Follower副本的确认。如果Leader宕机,Follower尚未复制时,数据就会丢失。此机制提供较好的持久性和较低的延迟性。
- -1:Leader接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都确认消息已同步,Producer才发送下一批消息。此机制持久性可靠性最好,但延时性最差。
副本同步策略
有两种:
方案 优点 缺点 半数以上完成同步,就发送ACK 延迟低 选举新Leader,容忍n台节点的故障,需 2n+1个副本全部完成同步,才发送ACK 选举新Leader,容忍n台节点的故障,需 n+1个副本延迟高 选方案二原因:
- 方案二只需
n+1个副本,因Kafka每个分区都有大量的数据,第一种方案会造成大量数据的冗余 - 虽然方案二的网络延迟会比较高,但网络延迟对Kafka的影响较小
不丢失
不能保证消息不丢失,只能尽力。措施如下:
- 持久性:Kafka使用磁盘存储消息,这样即使在断电等异常情况下,消息也不会丢失。Kafka使用日志文件(Log)来存储消息,每个分区都有一个或多个日志段(Log Segment)来持久化消息
- 复制机制:Kafka使用副本机制来保证消息的可靠性。每个分区都可以配置多个副本(Replica),一个Leader副本和若干个Follower副本。生产者发送的消息首先写入领导者副本,然后通过副本同步机制复制到追随者副本,只有在所有副本都成功写入后才认为消息提交成功
- 消息确认机制:即上文的ACK机制
去重
Kafka不能完全保证消息的重复发送和投递,需要借助于业务系统。可从三个端来保证消息的唯一性:
- Producer:通过在消息的键Key中包含某种唯一标识字段来实现。当相同键的消息发送到Kafka时,Kafka会根据键值对消息进行分区,因此相同键的消息会被发送到同一个分区中,从而保证相同键的消息在同一分区中的顺序和唯一性
- Kafka:可通过使用带有去重插件或Kafka Streams等工具来实现消息去重功能
- Consumer:引入缓存或数据库组件,判断是否已经消费过此条消息,判断依据需要依赖于Producer定义的唯一字段
幂等性
和上面的去重,很多场景下是一回事。
有序性
Kafka中的每个Partition中的消息在写入时都是有序的,一个Partition只能由一个消费者去消费,可以在里面保证消息的顺序性。但是分区之间的消息是不保证有序的。
消费者
在创建一个消费者程序时,如果没有指定消费者组ID,则该消费者程序会被分配到一个默认的消费者组。
对应源码
org.apache.kafka.clients.consumer.KafkaConsumer,实现Consumer接口。在Kafka 0.10.0.x版本以前,消费状态信息维护在ZK集群里,以后的版本,维护在两个地方:
- 内部主题
__consumer_offsets - 内存数据:解决读取内部Topic速度慢问题,构建三元组来维护最新的偏移量信息。支持外部存储化
__consumer_offsets
以消费者组(Group)、主题(Topic)和分区(Partition)作为组合主键,所有消费者程序产生的偏移量都会提交到该内部主题中进行存储。极端重要数据,故而设置其应答Ack级别设置为−1。再均衡
即Rebalance,重新均衡消费者消费,在同一个消费者组当中,分区的所有权从一个消费者转移到另外一个消费者。会触发Rebalance机制的场景:
- 消费者增加、减少(退出、下线、宕机)
- Partition增加
- Coordinator宕机
- 订阅的Topic数发生变化时
Rebalance的过程如下:
- 所有成员都向Coordinator发送JoinGroupRequest请求入组。一旦所有成员都发送请求,Coordinator会从中选择一个Consumer担任Leader角色,并把组成员信息以及订阅信息,即JoinGroupRespone发给Leader
- Leader开始分配消费方案,指明具体哪个Consumer负责消费哪些Topic的哪些Partition。
- 一旦完成分配,Leader会将这个方案,即SyncGroupRequest发给Coordinator。Coordinator接收到分配方案之后会把方案发给各个Consumer,这样组内的所有成员就都知道自己应该消费哪些分区
消费者组协调器
GroupCoordinator,负责协调多个消费者之间的行为,以确保他们能够正确地从Kafka主题中消费数据。由Kafka集群中的一个或多个服务器组成,主要作用包括:
- 分区分配策略:消费者协调器负责决定哪个消费者负责消费主题中的哪个分区。在消费者组内,每个分区只能被一个消费者消费,而消费者协调器会根据一定的算法(如轮询、粘性分区等)来分配分区给各个消费者。
- 消费者的加入和离开:当有新消费者加入或离开消费者组时,消费者协调器会负责处理相关的逻辑。新加入的消费者需要被分配新的分区,而离开的消费者需要将其负责的分区重新分配给其他消费者。
- 负载均衡:消费者协调器还会负责实现消费者的负载均衡。在有多个消费者的场景下,如果一个消费者的消费速度过快,而其他消费者消费速度较慢,可能会导致某些分区的数据被快速消费完,而其他分区的数据仍然保留在Kafka中。消费者协调器会根据消费者的消费情况,动态地调整分区的分配,以确保整个消费组的负载均衡。
- 故障转移:当某个消费者出现故障时,消费者协调器会将其负责的分区转移到其他健康的消费者上,以保证整个消费组的高可用性。
对应源码
org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:实现原理:
消费者和消费者组的关系
每个消费者从属于消费组。具体关系如下:
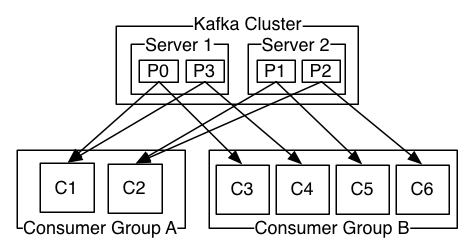
消费者组特性:- 一个消费者组,可以有一个或多个消费者程序;
- 消费者组名(GroupId)通常由一个字符串表示,具有唯一性;
- 如果一个消费者组订阅主题,则该主题中的每个分区只能分配给某一个消费者组中的某一个消费者程序。
消费者程序的数量尽量不要超过主题的最大分区数,多出来的消费者程序是空闲的,会浪费系统资源。
与其他MQ中间件的比较
比如RabbitMQ,ActiveMQ,RocketMQ,Apache Pulsar。
Kafka对比Pulsar
Apache Kafka和Apache Pulsar都是流处理平台,用于处理和传输大规模的实时数据流。尽管它们在目标上有很多相似之处,但在架构、特性、性能等方面存在显著差异。以下是两者的详细对比:
架构
- Kafka
单层架构:Kafka使用单层架构,所有消息存储和传输功能都由Kafka Broker负责。
存储:Kafka使用分区日志存储消息,每个分区在一个或多个Broker上持久化。
协调和管理:Kafka依赖Apache ZooKeeper进行集群元数据的管理、分区Leader选举等协调工作。 - Pulsar
多层架构:Pulsar采用多层架构,包括Pulsar Brokers、BookKeeper和ZooKeeper。
Pulsar Brokers:处理生产者和消费者的请求,执行负载均衡和元数据管理。
Apache BookKeeper:用于消息持久化,提供高效的分布式日志存储。
Apache ZooKeeper:用于协调和管理集群元数据。
存储:Pulsar使用BookKeeper进行存储,支持水平扩展和高性能的日志存储。
消息模型
- Kafka
主题和分区:Kafka的主题被分为多个分区,消息按顺序写入分区。
消息保留:消息保留策略可以基于时间或日志大小,保留期内的消息可以被多次消费。 - Pulsar
主题类型:Pulsar支持多种主题类型(独占、共享、失败转移和关键共享),灵活应对不同的消费模式。
分区主题:类似于Kafka,Pulsar也支持分区主题,但可以动态增加分区数量。
消息保留:Pulsar支持消息保留策略,可以按时间或大小配置,同时支持基于事件时间的TTL(Time-to-Live)。
性能和可扩展性
- Kafka
吞吐量:Kafka的高吞吐量得益于其高效的顺序写入和分区日志存储机制。
扩展性:Kafka可以水平扩展,通过增加Broker实例来提高集群容量,但增加分区数后无法减少。 - Pulsar
吞吐量:Pulsar通过分层架构和BookKeeper提供高吞吐量,适合低延迟写入和读取。
扩展性:Pulsar可以动态扩展,通过增加Brokers和Bookies实现无缝扩展,分区数可以动态调整。
消费者模型
- Kafka
消费模式:Kafka提供消费者组,通过分配分区给消费者实现负载均衡。一个分区只能由一个消费者组内的一个消费者消费。
消费位置管理:消费者偏移量存储在Kafka主题内或ZooKeeper中。 - Pulsar
消费模式:Pulsar支持多种消费模式,包括独占、共享、失败转移和关键共享,提供更灵活的消费方式。
消费位置管理:Pulsar的偏移量(游标)管理由Broker处理,并持久化在BookKeeper中。
功能特性
- Kafka
事务支持:Kafka支持事务消息,确保消息的原子写入和消费。
流处理:Kafka Streams和ksqlDB提供了强大的流处理功能,支持复杂的数据流处理任务。 - Pulsar
多租户支持:Pulsar原生支持多租户,通过命名空间实现隔离和资源限制。
延时消息:Pulsar支持消息定时发布,允许生产者设置消息的延迟时间。
函数(Functions):Pulsar Functions提供轻量级的流处理功能,可以在Broker内部运行用户定义的函数,处理流数据。
社区和生态系统
- Kafka
社区支持:Kafka拥有庞大且活跃的社区,丰富的文档和教程资源。
生态系统:Kafka拥有丰富的生态系统,如Confluent提供的商业支持和工具,Kafka Streams、ksqlDB等。 - Pulsar
社区支持:Pulsar的社区正在快速增长,提供官方文档、教程和示例代码。
生态系统:Pulsar生态系统也在扩展中,包括Pulsar Functions、Pulsar IO连接器等。
Kafka适合需要高吞吐量、简单架构以及现有生态系统支持的场景,尤其是在需要复杂流处理的情况下。
Pulsar则在多租户支持、动态扩展、延迟消息处理等方面表现出色,适合需要灵活消费模式和复杂存储管理的场景。Topic
删除Topic流程
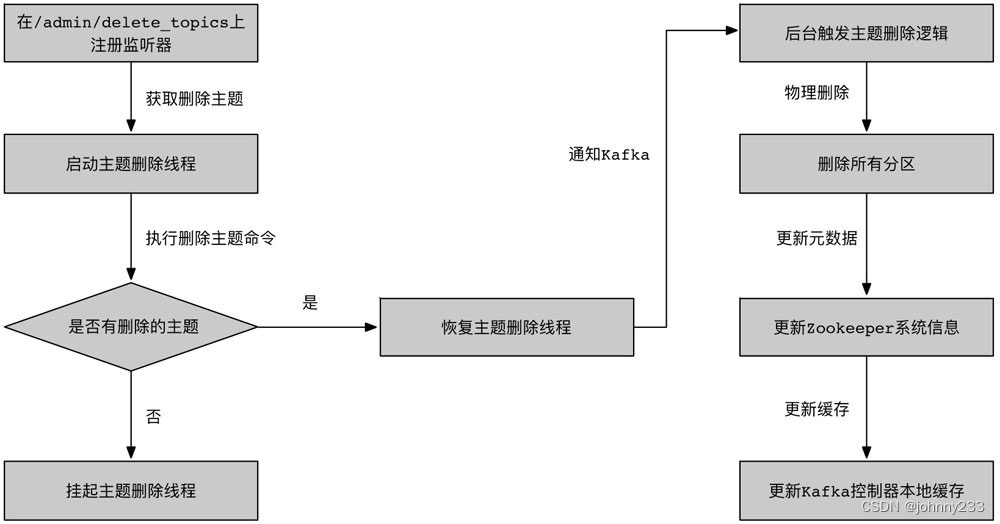
Kafka控制器在启动时会创建一个独立的删除线程,用来执行主题删除操作。删除线程会检测删除的主题集合是否为空:
- 如果删除主题的集合为空,则删除线程就会被挂起;
- 如果删除主题的集合不为空,则立即触发删除逻辑。删除线程会通知Kafka的所有代理节点,删除这个主题的所有分区。接着,Kafka控制器会更新ZK系统信息,清除各种缓存,将标记删除的主题信息移除。
ZooKeeper
Kafka各Broker在启动时都要在ZK上注册,由ZK统一协调管理。如果任何节点失败,可通过ZK从先前提交的偏移量中恢复,因为它会做周期性提交偏移量工作。同一个Topic的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与Broker的对应关系也是ZK在维护。
Kafka 2.8.0版本引入Kafka原生集群管理新特性,官方说法是Kafka Raft Metadata Mode。Kafka可以独立运行,不再强制依赖于ZK来提供集群管理和元数据存储功能。
基于Raft一致性协议实现,使得Kafka Broker可以直接通过Raft协议来选举领导者和维护元数据的一致性,减少外部依赖,使Kafka集群的部署和维护更简单。
Pull还是Push
Producer将消息Push到Broker集群,Consumer从Broker集群Pull消息。
纵观各大消息中间件,Producer将消息Push到Broker集群。Apache Pulsar可能是唯一的例外,Broker可以主动从Producer拉取消息,而不是等待Consumer。在某些特定场景下可能会有用,如需要Broker对消息进行一些处理或者过滤,然后再转发给Consumer。
消息如何从Broker触达到Consumer,各大中间件的实现有Push和Pull模式的不同。如Scribe和Flume采用push模式,即Broker将消息推送到下游的Consumer。
Push模式的缺点:由Broker决定消息推送的速率,对于不同消费速率的Consumer就不太好处理。消息系统都致力于让Consumer以最大的速率快速消费消息,当Broker推送速率远大于Consumer消费速率时,Consumer可能会崩溃。
Pull模式的好处:Consumer可以自主决定是否批量的从broker拉取数据。Push模式必须在不知道下游Consumer消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免Consumer崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪费。Pull模式下,Consumer就可以根据自己的消费能力去决定这些策略。
Pull的缺点:如果Broker没有可供消费的消息,将导致Consumer不断在循环中轮询,直到新消息到达。为了避免这点,Kafka有个参数可以让Consumer阻塞知道新消息到达(当然也可以阻塞直到消息的数量达到某个特定的量),这样就可以批量发。
消息事务
消息传输的事务(又叫消息投递语义)定义通常有以下三种级别:
- 最多一次:消息不会被重复发送,最多被传输一次,但也有可能一次不传输
- 最少一次:消息不会被漏发送,最少被传输一次,但也有可能被重复传输
- 精确一次:不会漏传输也不会重复传输,每个消息都传输一次
脚本
分为Linux和Windows版;随着Kafka版本的迭代更新,脚本数量一直在新增。每个脚本的使用又有相应的参数和用途,虽然不同脚本之间参数的命名和用途有迹可循,都有规律。
需要另起一篇。面试时提到2~3个即可。
工具
和上面的脚步有部分重复:
- Kafka迁移工具:它有助于将代理从一个版本迁移到另一个版本
- 消费者检查:对于指定的主题集和消费者组,可显示主题、分区、所有者
Broker
一台Kafka服务器就是一个Broker,集群由多个Broker组成,一个Broker可以容纳多个Topic。
如何判断一个Broker是否还存活?
- Broker必须可以维护和ZK的连接,通过心跳机制检查每个结点的连接。
- 如果Broker是个Follower,它必须能及时同步Leader的写操作,延时不能太久。
配置
配置文件:
server.properties:producer.properties:consumer.properties:zookeeper.properties:
优化
缺点
包括:
- 批量发送,数据并非真正的实时;
- 不支持MQTT协议;
- 不支持物联网传感数据直接接入;
- 仅支持统一分区内消息有序,无法实现全局消息有序;
- 监控不完善,需要安装插件;
- 低版本依赖ZK进行元数据管理;
进阶
批处理
吞吐量
Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失。技术要点:
- 顺序读写
- 文件分段
- 批量发送
- 数据压缩
顺序读写
操作系统每次从磁盘读写数据的时候,需要先寻址,也就是先要找到数据在磁盘上的物理位置,然后再进行数据读写,如果是机械硬盘,寻址就需要较长的时间。
Kafka的设计中,数据其实是存储在磁盘上面,一般来说,会把数据存储在内存上面性能才会好。
但是Kafka用的是顺序写,追加数据是追加到末尾,磁盘顺序写的性能极高,在磁盘个数一定,转数达到一定的情况下,基本和内存速度一致。
随机写的话是在文件的某个位置修改数据,性能会较低。零拷贝
消息格式
消息格式经过四次大变化。
文件存储
Kafka中消息是以Topic进行分类,生产者通过Topic向broker发送消息,消费者通过Topic读取数据。物理层面,一个Topic可以分成若干个Partition,Partition还可以细分为segment:
- Kafka把Topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位message和确定response的最大大小。
- 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
- 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小
多租户
多租户技术,Multi-Tenancy Technology,是一种软件架构技术,实现如何在多用户的环境下共用相同的系统或程序组件,并且仍可确保各用户间数据的隔离性。
通过配置哪个主题可以生产或消费数据来启用多租户,也有对配额的操作支持。管理员可以对请求定义和强制配额,以控制客户端使用的Broker资源。
监控
Kafka集群的监控是确保其性能和稳定性的重要组成部分。有效的监控可以帮助预防问题,快速定位和解决故障,保障系统的正常运行。
监控的关键指标如下:
- Broker指标:
Broker的CPU、内存和磁盘使用情况
网络流量和I/O性能
活跃的Controller数量- 主题和分区指标:
每个主题和分区的消息吞吐量。
副本同步情况ISR
分区的日志大小和滞后情况- 生产者指标:
生产者的消息发送速率和失败率
请求的延迟时间- 消费者指标:
消费者的消费速率和失败率
消费者延迟(消费滞后)- ZooKeeper指标:
ZK节点的状态和会话数
ZK的请求处理延迟常用监控方案:
- Kafka自带工具:适用于简单的监控和管理任务,但功能较为基础,缺乏可视化和综合的监控能力:
kafka-topics.sh:管理和查看主题信息kafka-consumer-groups.sh:管理和查看消费者组信息kafka-configs.sh:查看和修改配置kafka-run-class.sh kafka.tools.GetOffsetShell:获取主题的最新偏移量
- Kafka 自带的 JMX(Java Management Extensions):Kafka内部通过JMX暴露许多关键的指标,可用来监控Kafka集群的运行状态。使用JMX可以获取关于Broker、生产者、消费者、主题和分区的详细统计信息。
- 使用第三方监控工具和框架:包括Prometheus、Grafana、ELK Stack等。
- 定制化监控和告警:根据具体的业务需求,定制化监控方案和告警策略,如自定义指标收集、告警规则等。确保在关键指标出现异常时,能够及时收到告警并进行处理。
工具
- Kafka Manager:由Yahoo开发的Kafka监控和管理工具。提供集群管理、主题创建和删除、分区重分配、消费者监控等功能。适合中小型Kafka集群的管理和监控。
- Prometheus + Grafana:使用Prometheus JMX Exporter将Kafka的JMX指标导出到Prometheus。Grafana可与Prometheus集成,创建实时监控仪表盘。适合大规模Kafka集群的监控和数据可视化。
- Confluent Control Center:Confluent提供的商业化Kafka监控和管理工具。提供全面的Kafka集群监控、流处理监控、Schema Registry管理等功能。适合企业级Kafka部署,提供强大的监控和管理功能。
- Burrow:LinkedIn开发的Kafka消费者延迟监控工具。专注于监控消费者延迟,帮助识别和解决消费者消费滞后的问题。适合需要精确监控消费者延迟的场景。
- Elastic Stack(ELK):使用Filebeat或Metricbeat收集Kafka日志和指标存储到ES中,使用Kibana创建可视化仪表盘,实时监控Kafka集群状态。适合需要对Kafka集群进行日志分析和指标监控的场景。
安全
在0.9版本之前,Kafka集群是没有安全机制的。当前Kafka系统支持多种认证机制:SSL、SASL/Kerberos、SASL/PLAIN、SASL/SCRAM。
认证范围包括:
- 客户端和Broker节点之间的连接认证
- Broker节点之间的连接认证
- Broker节点与ZK系统之间的连接认证
参考
-
相关阅读:
MM-Camera架构-Open 流程分析
问题记录:飞腾板卡,系统时启动卡住
从北京到南京:偶数在能源行业的数据迁移实践
【Spring】SpringBoot的扩展点之ApplicationContextInitializer
Prometheus(普罗米修斯)监控架构简介
了解 Flutter 开发者们的 IDE 使用情况
【Vue】模板语法,插值、指令、过滤器、计算属性及监听属性(内含面试题及毕设等实用案例)上篇
二维数组练习
安卓实现简单砸地鼠游戏
kafka分布式安装部署
- 原文地址:https://blog.csdn.net/lonelymanontheway/article/details/118281221