-
文档分类FastText模型 (pytorch实现)
FastText简介
FastText与之前介绍过的CBOW架构相似,我们先来会议一下CBOW架构,如下图:
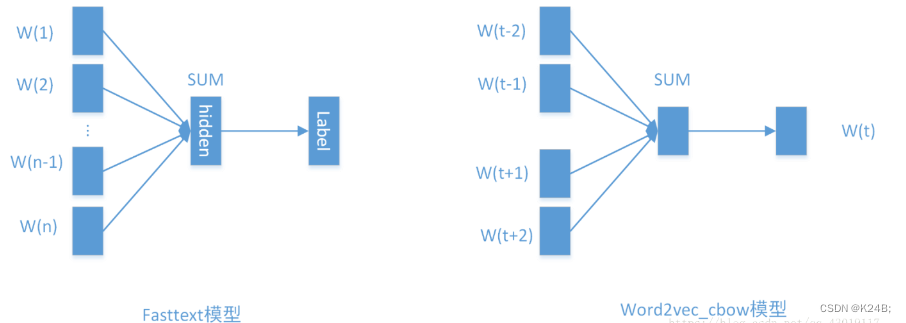
CBOW的任务是通过上下文去预测中间的词,具体做法是使用滑动窗口内部的词的embedding的均值作为中间词的embedding。
FastText的任务是通过文章中的词去预测文章的类别(文档分类),具体做法是使用文章中的所有词的embedding的均值作为文章的embedding。最后从隐层再经过一次的非线性变换得到输出层的label。
CBOW和FastText的相似之处:
- 每个特征都是词向量的平均值。
总结一下CBOW和FastText的不同之处:
- FastText是有监督学习,而CBOW是无监督学习
- FastText是预测文章的label,而CBOW是预测中心词
- FastText使用的是文章中所有词的embedding,而CBOW使用的是中心词所在滑动窗口内其他所有词的embedding
从模型架构上来说,沿用了CBOW的单层神经网络的模式,不过fastText的处理速度才是这个算法的创新之处。
fastText模型的输入是一个词的序列(一段文本或者一句话),输出是这个词序列属于不同类别的概率。在序列中的词和词组构成特征向量,特征向量通过线性变换映射到中间层,再由中间层映射到标签。fastText在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
fastText是一个快速文本分类算法,与基于神经网络的分类算法相比有两大优点:
- fastText在保持高精度的情况下加快了训练速度和测试速度
- fastText不需要预训练好的词向量,fastText会自己训练词向量
- fastText两个重要的优化:Hierarchical Softmax、N-gram
fastText方法包含三部分,模型架构,层次Softmax和N-gram特征。层次softmax
分层 softmax(Hierarchical Softmax)是一种用于加速词嵌入模型训练的技术,特别是在训练大型词汇表时。它通过将词汇表组织成一棵二叉树(通常是霍夫曼树),从而将原来的线性 softmax 运算转换为对树结构进行的多次二元分类,从而减少了计算量。
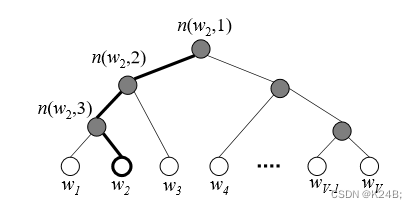
构建哈夫曼树
- 首先,根据词汇表中每个词的词频构建一棵霍夫曼树。
- 霍夫曼树是一种最优的二叉树,它通过最小化编码长度来实现对频繁出现的词进行更短的编码,以及对不太频繁出现的词进行较长的编码。
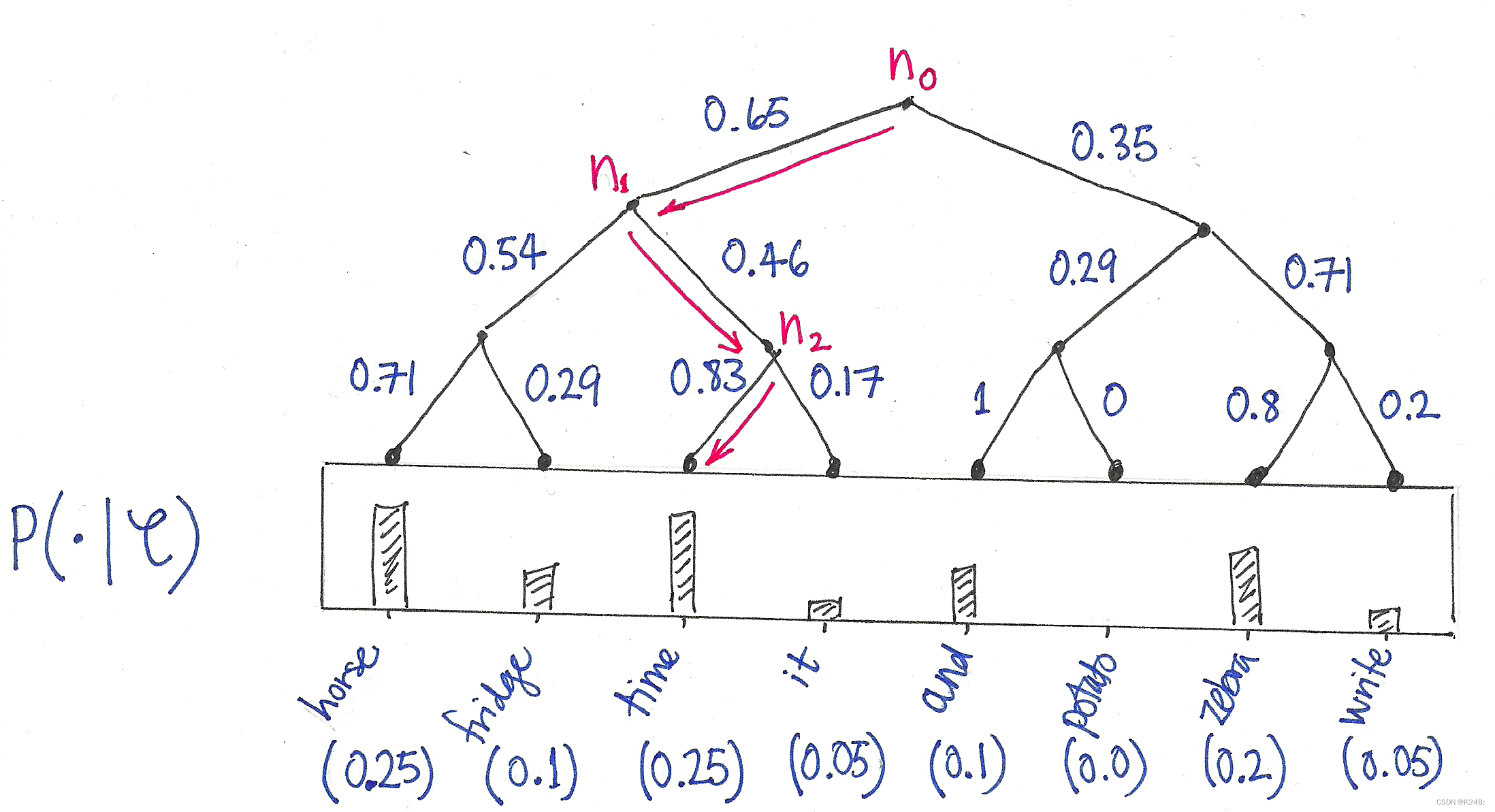
对数学模型进行改造:
- 对于一个普通的 softmax 模型,它的输出层是一个与词汇表大小相同的全连接层,需要对所有词汇进行一次计算。
- 而在分层 softmax 中,将词汇表组织成二叉树,每个内部节点代表一个二元分类任务。模型的输出层不再是一个全连接层,而是根据霍夫曼树的结构构建的一系列内部节点。
预测过程:
- 在预测过程中,对于给定的目标词,从树的根节点开始,根据二元分类的规则逐级向下遍历,直到达到叶子节点,从而确定目标词的概率分布。
- 通过遍历的路径,可以确定目标词在霍夫曼树中的编码,从而得到目标词的概率分布。
我们发现对于每一个节点,都是一个二分类[0,1],也就是我们可以使用sigmod来处理节点信息;
θ ( x ) = 1 1 + e − x \theta \left(x \right)=\frac{1}{1+e{-x}} θ(x)=1+e−x1
此时,当我们知道了目标单词x,之后,我们只需要计算root节点,到该词的路径累乘,即可. 不需要去遍历所有的节点信息,时间复杂度变为O(log2(V))。N-gram特征
n-gram是基于语言模型的算法,基本思想是将文本内容按照字节顺序进行大小为N的窗口滑动操作,最终形成窗口为N的字节片段序列。而且需要额外注意一点是n-gram可以根据粒度不同有不同的含义,有字粒度的n-gram和词粒度的n-gram,下面分别给出了字粒度和词粒度的例子:
#我爱中国 2-gram特征为:我爱 爱中 中国 3-gram特征为:我爱中 爱中国 #我 爱 中国 2-gram特征为:我/爱 爱/中国 3-gram特征为:我/爱/中国- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
从上面来看,使用n-gram有如下优点
- 为罕见的单词生成更好的单词向量:根据上面的字符级别的n-gram来说,即是这个单词出现的次数很少,但是组成单词的字符和其他单词有共享的部分,因此这一点可以优化生成的单词向量。
- 在词汇单词中,即使单词没有出现在训练语料库中,仍然可以从字符级n-gram中构造单词的词向量。
- n-gram可以让模型学习到局部单词顺序的部分信息, 如果不考虑n-gram则便是取每个单词,这样无法考虑到词序所包含的信息,即也可理解为上下文信息,因此通过n-gram的方式关联相邻的几个词,这样会让模型在训练的时候保持词序信息。
但正如上面提到过,随着语料库的增加,内存需求也会不断增加,严重影响模型构建速度,针对这个有以下几种解决方案:
1、过滤掉出现次数少的单词
2、使用hash存储
3、由采用字粒度变化为采用词粒度FastText代码(文档分类)
import torch import torch.nn as nn import torch.nn.functional as F import numpy as np class Config(object): """配置参数""" def __init__(self): self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备 self.dropout = 0.5 # 随机失活 self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练 self.num_classes = 10 # 类别数 self.n_vocab = 10000 # 词表大小,在运行时赋值 self.num_epochs = 20 # epoch数 self.batch_size = 128 # mini-batch大小 self.pad_size = 32 # 每句话处理成的长度(短填长切) self.learning_rate = 1e-3 # 学习率 self.embed = 300 # 字向量维度 self.hidden_size = 256 # 隐藏层大小 self.n_gram_vocab = 250499 # ngram 词表大小 '''Bag of Tricks for Efficient Text Classification''' class Model(nn.Module): def __init__(self, config): super(Model, self).__init__() self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1) self.embedding_ngram2 = nn.Embedding(config.n_gram_vocab, config.embed) self.embedding_ngram3 = nn.Embedding(config.n_gram_vocab, config.embed) self.dropout = nn.Dropout(config.dropout) self.fc1 = nn.Linear(config.embed * 3, config.hidden_size) self.fc2 = nn.Linear(config.hidden_size, config.num_classes) def forward(self, x): out_word = self.embedding(x[0]) # x[0] [batch_size,sentence_len] 经过embedding变为 [batch_size,sentence_len,wmbed_size] torch.Size([128, 32, 300]) out_bigram = self.embedding_ngram2(x[2]) # torch.Size([128, 32, 300]) out_trigram = self.embedding_ngram3(x[3]) # torch.Size([128, 32, 300]) out = torch.cat((out_word, out_bigram, out_trigram), -1) # torch.Size([128, 32, 900]) out = out.mean(dim=1) # torch.Size([128, 900]),沿着第二个维度(即特征维度)对每个样本的特征值进行平均池化 out = self.dropout(out) # torch.Size([128, 900]) out = self.fc1(out) # torch.Size([128, 900])经过fc1 torch.Size([128, 256]) out = F.relu(out) # torch.Size([128, 256]) out = self.fc2(out) # torch.Size([128, 256])经过fc1 torch.Size([128, 10]) return out config=Config() model=Model(config) print(model)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
输出:
Model( (embedding): Embedding(10000, 300, padding_idx=9999) (embedding_ngram2): Embedding(250499, 300) (embedding_ngram3): Embedding(250499, 300) (dropout): Dropout(p=0.5, inplace=False) (fc1): Linear(in_features=900, out_features=256, bias=True) (fc2): Linear(in_features=256, out_features=10, bias=True) )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
相关阅读:
lwip无法连接指定个数TCP连接问题
牛客小白月赛81
Rust(1) 简介和安装
三维模型3DTile格式轻量化压缩的遇到常见问题与处理方法分析
防御XSS攻击的方法
OCS认证有机含量标准
【c#】2022创建WEB API接口教程demo
audit交叉编译
Postgresql运维常用命令_登录_权限设置_创建用户_创建数据库_创建postgis数据库_远程连接---Postgresql工作笔记009
【Redis学习笔记】第十三章 Redis集群
- 原文地址:https://blog.csdn.net/weixin_64017116/article/details/138865751
