
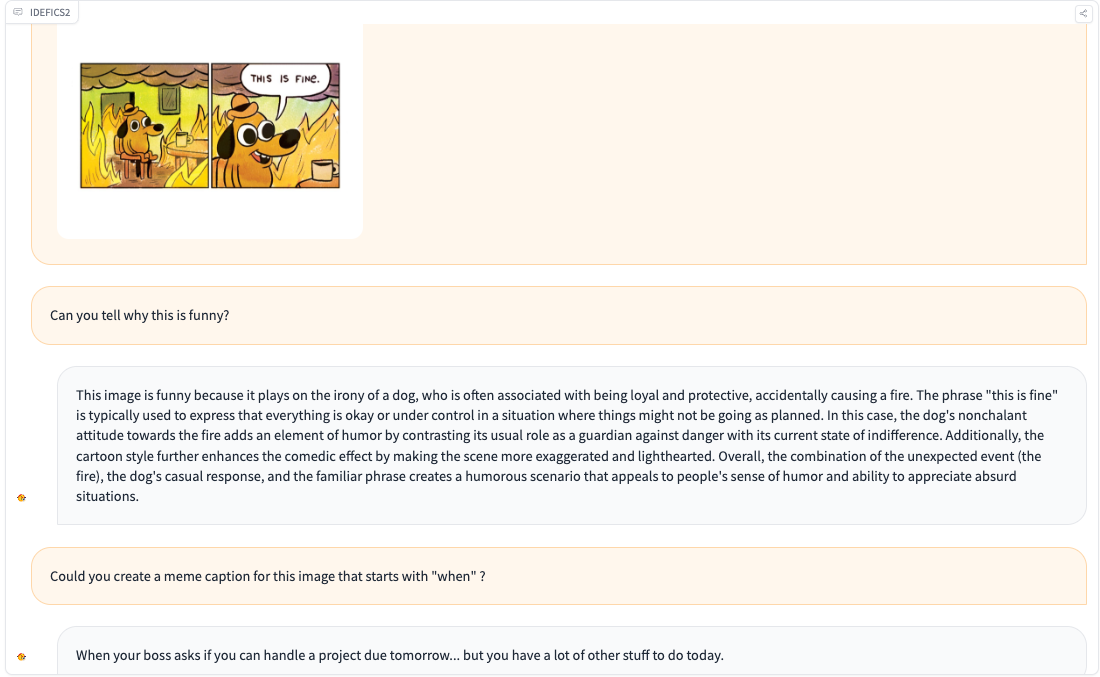
我们很高兴在此发布 Idefics2,这是一个通用的多模态模型,接受任意文本序列和图像序列作为输入,并据此生成文本。它可用于回答图像相关的问题、描述视觉内容、基于多幅图像创作故事、从文档中提取信息以及执行基本的算术运算。
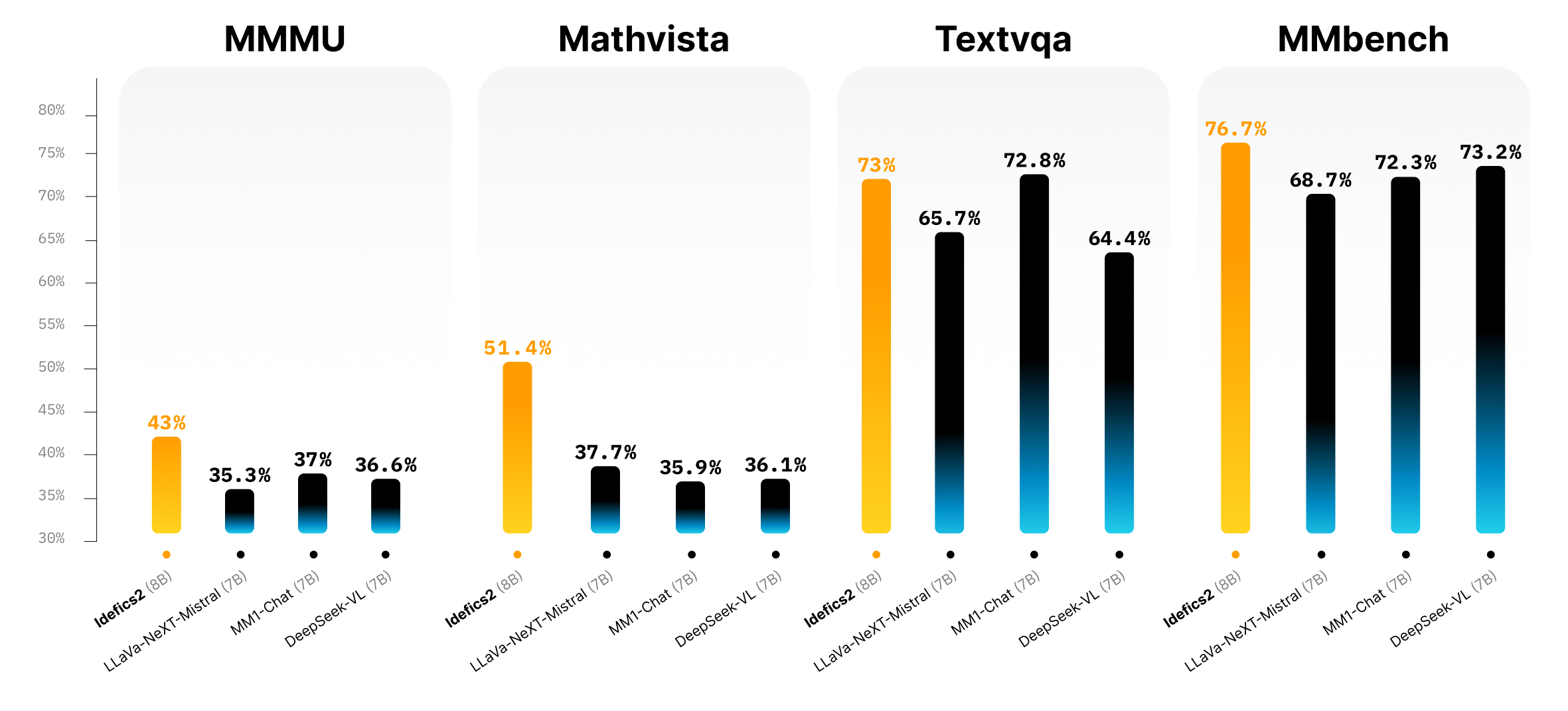
Idefics2 由 Idefics1 改进而得,其参数量为 8B,具有开放许可 (Apache 2.0) 并大大增强了 OCR (光学字符识别) 功能,因此有望成为多模态社区坚实的基础模型。其在视觉问答基准测试中的表现在同规模模型中名列前茅,并可与更大的模型 (如 LLava-Next-34B 以及 MM1-30B-chat) 一较高下。
Idefics2 甫一开始就集成在 🤗 Transformers 中,因此社区可以直接基于它面向很多多模态应用进行微调。你当下就可在 Hub 上试用 该模型!
(val/test) |
(testmini) |
(val) |
(test) |
(test-dev) |
(test) |
||||
|---|---|---|---|---|---|---|---|---|---|
| DeepSeek-VL | ✅ | 7B | 576 | 36.6/- | 36.1 | 64.4 | 73.2 | - | 49.6 |
| LLaVa-NeXT-Mistral-7B | ✅ | 7B | 2880 | 35.3/- | 37.7 | 65.7 | 68.7 | 82.2 | - |
| LLaVa-NeXT-13B | ✅ | 13B | 2880 | 36.2/- | 35.3 | 67.1 | 70.0 | 82.8 | - |
| LLaVa-NeXT-34B | ✅ | 34B | 2880 | 51.1/44.7 | 46.5 | 69.5 | 79.3 | 83.7 | - |
| MM1-Chat-7B | ❌ | 7B | 720 | 37.0/35.6 | 35.9 | 72.8 | 72.3 | 82.8 | - |
| MM1-Chat-30B | ❌ | 30B | 720 | 44.7/40.3 | 39.4 | 73.5 | 75.1 | 83.7 | |
| Gemini 1.0 Pro | ❌ | 🤷♂️ | 🤷♂️ | 47.9/- | 45.2 | 74.6 | - | 71.2 | 88.1 |
| Gemini 1.5 Pro | ❌ | 🤷♂️ | 🤷♂️ | 58.5/- | 52.1 | 73.5 | - | 73.2 | 86.5 |
| Claude 3 Haiku | ❌ | 🤷♂️ | 🤷♂️ | 50.2/- | 46.4 | - | - | - | 88.8 |
| Idefics1 指令版 (32-shots) | ✅ | 80B | - | - | - | 39.3 | - | 68.8 | - |
| Idefics2(不切图)* | ✅ | 8B | 64 | 43.5/37.9 | 51.6 | 70.4 | 76.8 | 80.8 | 67.3 |
| Idefics2 (切图)* | ✅ | 8B | 320 | 43.0/37.7 | 51.4 | 73.0 | 76.7 | 81.2 | 74.0 |
- 切图: 遵循 SPHINX 和 LLaVa-NeXT 的策略,允许算法选择将图切成 4 幅子图。
训练数据
Idefics2 在预训练时综合使用了多种公开数据集,包括: 图文网页 (维基百科,OBELICS) 、图文对 (Public Multimodal Dataset、LAION-COCO) 、OCR 数据 (PDFA (en)、IDL、Rendered-text,以及代码 - 渲染图数据 (WebSight) )。
我们使用了 这个交互式可视化 工具对 OBELICS 数据集进行探索。
遵循基础模型社区的惯例,我们也在各种任务数据集上对基础模型进行了指令微调。此时,由于各任务数据集的格式各不相同,且分散在不同的地方,如何将它们汇聚起来是社区面临的一大难题。为了解决这个问题,我们发布了筹措良久的多模态指令微调数据集: The Cauldron (丹鼎) ,它是我们手动整理的、包含 50 个开放数据集的、多轮对话格式的合辑式数据集。我们的指令微调 Idefics2 模型的训练数据将 The Cauldron 和各种纯文本指令微调数据集的串接而得。

对 Idefics1 的改进
- 我们按照 NaViT 策略以原始分辨率 (最大为 980 x 980) 和原始宽高比操作图像。这免去了传统的将图像大小调整为固定尺寸正方形的做法。此外,我们遵循 SPHINX 的策略,并允许切图以及传入非常大分辨率的图像 (可选项)。
- 我们增加了图像或文档中文本识别的训练数据,这显著增强了 OCR 能力。我们还通过增加相应的训练数据提高了模型回答图表、数字和文档问题的能力。
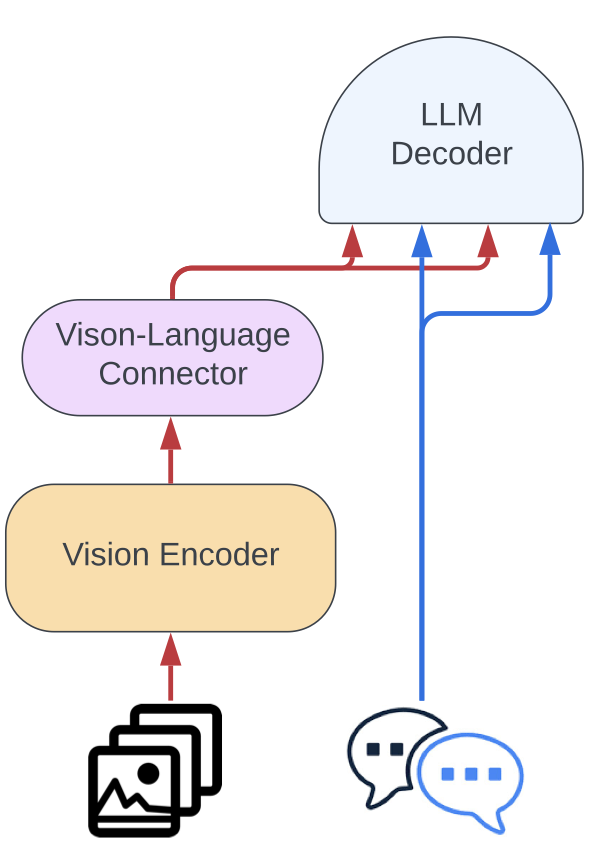
- 我们放弃了 Idefics1 的架构 (门控交叉注意力) 并简化了视觉特征到语言主干的投影子模型。图像先被通过到视觉编码器,再通过已训的感知器池化和 MLP 从而完成模态投影。然后,将所得的池化序列与文本嵌入连接起来,以获得一个图像和文本的交织序列。
所有这些改进叠加上更好的预训练主干网络,使得模型的性能与 Idefics1 相比有显著提升,且尺寸缩小了 10 倍。
Idefics2 入门
Idefics2 可在 Hugging Face Hub 上使用,并已被最新的 transformers 版本支持。以下给出了一段示例代码:
import requests import torch from PIL import Image from transformers import AutoProcessor, AutoModelForVision2Seq from transformers.image_utils import load_image DEVICE = "cuda:0" # Note that passing the image urls (instead of the actual pil images) to the processor is also possible image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg") image2 = load_image("https://cdn.britannica.com/59/94459-050-DBA42467/Skyline-Chicago.jpg") image3 = load_image("https://cdn.britannica.com/68/170868-050-8DDE8263/Golden-Gate-Bridge-San-Francisco.jpg") processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics2-8b") model = AutoModelForVision2Seq.from_pretrained( "HuggingFaceM4/idefics2-8b", ).to(DEVICE) # Create inputs messages = [ { "role": "user", "content": [ {"type": "image"}, {"type": "text", "text": "What do we see in this image?"}, ] }, { "role": "assistant", "content": [ {"type": "text", "text": "In this image, we can see the city of New York, and more specifically the Statue of Liberty."}, ] }, { "role": "user", "content": [ {"type": "image"}, {"type": "text", "text": "And how about this image?"}, ] }, ] prompt = processor.apply_chat_template(messages, add_generation_prompt=True) inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt") inputs = {k: v.to(DEVICE) for k, v in inputs.items()} # Generate generated_ids = model.generate(**inputs, max_new_tokens=500) generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True) print(generated_texts)
我们还提供了一个微调 colab notebook,希望能帮到想在自有用例上微调 Idefics2 的用户。
资源
如欲进一步深入,下面列出了 Idefics2 所有资源:
- Idefics2 合集
- Idefics2 模型及模型卡
- Idefics2-base 模型及模型卡
- Idefics2-chat 模型及模型卡 (即将推出)
- The Cauldron 及数据集卡
- OBELICS 及数据集卡
- WebSight 及数据集卡
- Idefics2 微调 colab
- Idefics2-8B 模型演示 (非聊天模型)
- Idefics2 演示: (即将推出)
- Idefics2 paper: (即将推出)
许可
本模型是两个预训练模型构建的: Mistral-7B-v0.1 以及 siglip-so400m-patch14-384,这两者都是基于 Apache-2.0 许可证发布的。
因此,我们基于 Apache-2.0 许可证发布了 Idefics2 权重。
致谢
感谢 Google 团队和 Mistral AI 向开源 AI 社区发布并提供他们的模型!
特别感谢 Chun Te Lee 的柱状图,以及 Merve Noyan 对博文的评论和建议 🤗。
英文原文: https://hf.co/blog/idefics2
原文作者: Leo Tronchon,Hugo Laurençon,Victor Sanh
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。