-
【MySQL基本查询(下)】
一、update
该关键字的功能就是更新指定表中指定的数据。
语法:
UPDATE table_name SET column = expr [, column = expr …]
[WHERE …] [ORDER BY …] [LIMIT …]接着上一篇文章的表:

现在想更新孙悟空的数学成绩到100分。
mysql> update exam_result set math=100 where name = ‘孙悟空’;
案例
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
mysql> update exam_result set math=60,chinese=70 where name = ‘曹孟德’;

将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
第一步:先找出这三名同学
mysql> select name,math,chinese + math + english as total from exam_result order by total limit 3 ;
第二步:将这三名同学的数学成绩加上30
mysql> update exam_result set math=math+30 order by chinese+math+english limit 3 ;成绩修改前:

成绩修改后:

注意:不支持 math += 30 这种语法
将所有同学的语文成绩更新为原来的 2 倍
mysql> update exam_result set chinese = chinese*2;
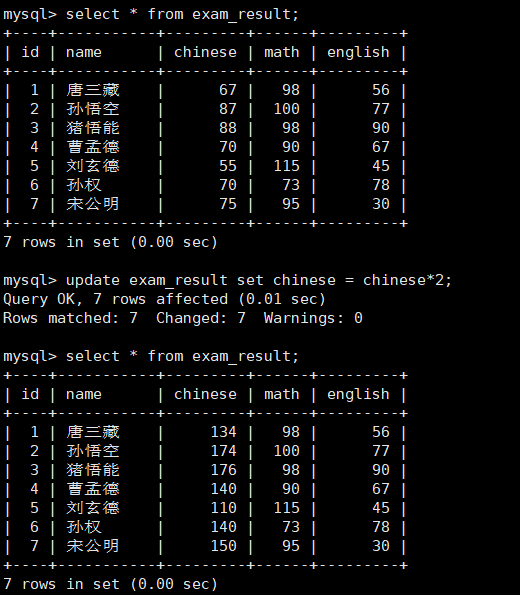
注意:update更新全表的这条语句慎用。其危害不亚于delete表。
二、Delete
语法:
DELETE FROM table_name [WHERE …] [ORDER BY …] [LIMIT …]
注意区别于drop,drop是删除表结构的,不是删除表数据。
案例
删除孙悟空同学的考试成绩
mysql> delete exam_result where name = ‘孙悟空’;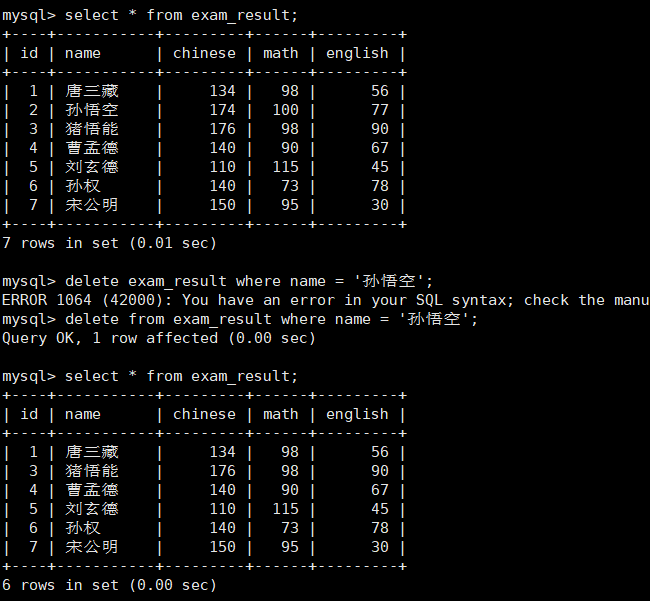
注意:delete 全表数据的行为慎用!
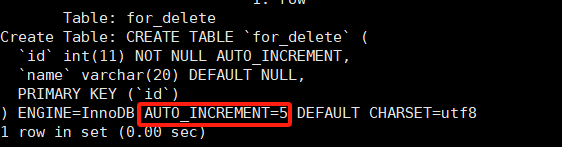
准备一张测试表:
CREATE TABLE for_delete (
id int primary key auto_increment,
name varchar(20)
);
插入一些数据后:如下图
执行delete命令后,结果为空了。但是这种删除表的方式,不会对表的自增式数据清空,比如上面表插入了三条信息,删除完后,再次插入信息,auto_increment约束记录的是从id=4开始的。
truncate
注意:这个操作慎用
- 只能对整表操作,不能像 DELETE 一样针对部分数据操作;
- 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事
物,所以无法回滚 - 会重置 AUTO_INCREMENT 项
该关键字也能将表的内容删除。
truncate + 表名
删除表的所有数据。
不同于delete的是,这个truncate关键字,删除表的内容后,也会将自增键auto_increment的值清空,也就意味着下次插入的时候会从1开始自增。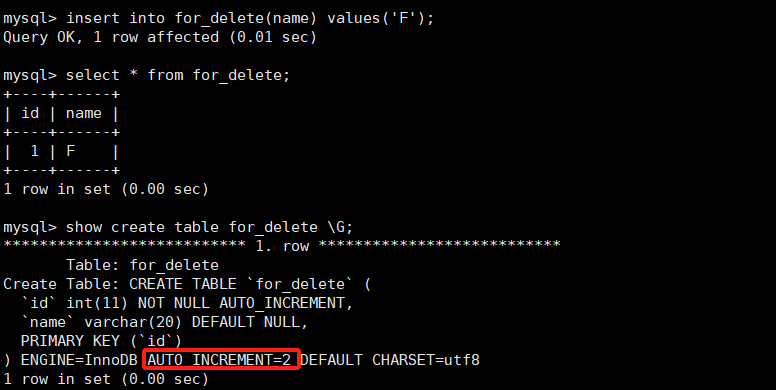
三、插入查询结果
语法:
- INSERT INTO table_name [(column [, column …])] SELECT …
也就是把 select 查询出来的结果进行插入。
案例
案例:删除表中的的重复复记录,重复的数据只能有一份。
首先创建原数据表 CREATE TABLE duplicate_table (id int, name varchar(20)); Query OK, 0 rows affected (0.01 sec)
再插入测试数据 INSERT INTO duplicate_table VALUES (100, ‘aaa’), (100, ‘aaa’), (200, ‘bbb’), (200, ‘bbb’), (200, ‘bbb’), (300, ‘ccc’); Query
OK, 6 rows affected (0.00 sec)Records: 6 Duplicates: 0 Warnings: 0思路:
1)创建一个跟duplicate_table 相同类型的表格。
CREATE TABLE no_duplicate_table LIKE duplicate_table;
2)将duplicate_table的去重数据插入到no_duplicate_table
INSERT INTO no_duplicate_table SELECT DISTINCT * FROM duplicate_table;
3)通过重命名表,实现原子的去重操作
RENAME TABLE duplicate_table TO old_duplicate_table,
no_duplicate_table TO duplicate_table;最后结果如下:
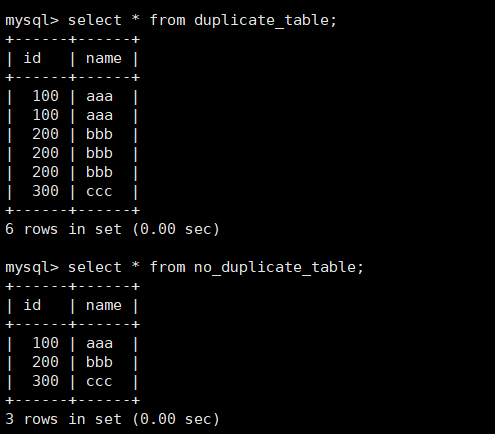
其中上篇文章讲到,去重的关键字是distinct。
四、了解一些函数

1.count函数
案例:统计班级共有多少同学。
select count(*) as 总数 from exam_result;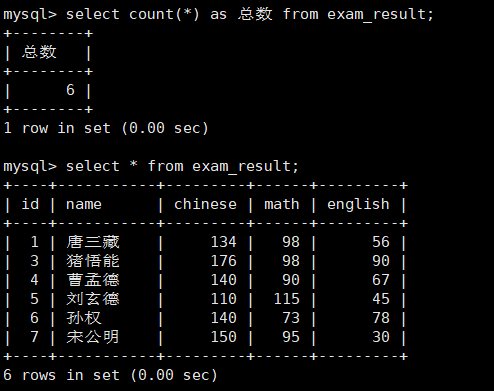
统计班级收集的 qq 号有多少
mysql> select count(qq) from students;

统计本次考试的数学成绩分数个数
mysql> select count(math) from exam_result; —统计的是统计的是全部成绩
mysql> select count(distinct math) from exam_result; —统计的是统计的是去重成绩2.sum函数
一般用来统计总分。
案例:
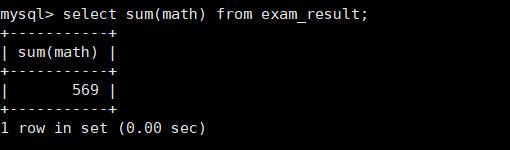
统计班级数学总成绩
mysql> select sum(math) from exam_result;
3. avg函数
一般用来统计平均分。
案例:统计平均总分
mysql> select avg(chinese+math+english) as 平均总分 from exam_result;

4.max函数
可以用来统计最高分。
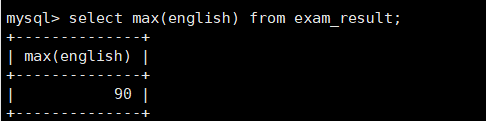
案例:统计全班英语最高分
mysql> select max(english) from exam_result;
5. min函数
一般统计最低(小)的分数。
案例:返回 > 70 分以上的数学最低分
mysql> select min(math) from exam_result where math > 70;
五、group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询
group by 的核心作用:为了分组之后,方便进行聚合统计。
语法:
- select column1, column2, … from table group by column;
获取一张员工表,员工表的信息如下:
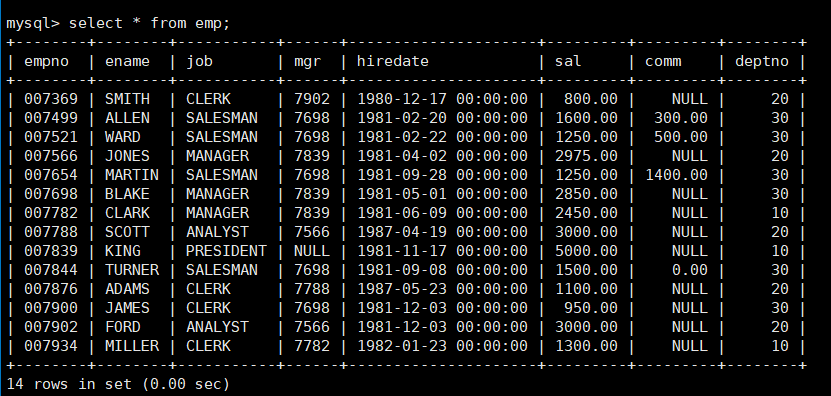
上面的员工信息表,可以看成一个大组。
给员工表按照deptno(department No. 部门)进行分组,结果如下:
mysql> select deptno,max(sal) as 最高工资 , avg(sal) as 平均工资 from emp group by deptno;

按照部门进行分组后,三个部门的的最高工资,平均工资就一目了然,这样就是按照要求进行分组了。
分组,就是把一组按照条件,拆分成多个组,进行各自组内的统计。
分组,也就是把一张表按照一定条件,拆分成多组,然后在每个组内进行聚合统计。案例
显示每个部门的每种岗位的平均工资和最低工资
mysql> select deptno,job,min(sal), avg(sal) from emp group by deptno,job;

先分组统计每个部门的最低和平均工资,再对结果进行聚合。
having和where
having:对最后聚合出来的结果进行判断。
案例:列出表的信息,SMITH这名员工不参与统计。
mysql> select deptno,job,avg(sal) as myavg from emp where ename!=‘SMITH’ group by deptno,job having myavg < 2000;

对该SQL语句进行解读:

不能单纯地认为,只有从磁盘上导入到MySQL中的真实存在的才叫做表。
每个过程中产生的,和最终筛选出来的,都是表!!!总结:
“MySQL下一切皆表。”
-
相关阅读:
耗时半天,我使用 Python 构建电影推荐系统
MySQL JDBC编程
程序人生:从小公司到一线大厂,薪资翻倍,我做到了...
【yolo系列:YOLOV7改进-添加EIOU,SIOU,AlphaIOU,FocalEIOU.】
Kubernetes-进阶(Pod生命周期/调度/控制器,Ingress代理,数据存储PV/PVC)
查询&会议签字
Spark和Hadoop作业之间的区别
我用了多年的前端框架,强烈推荐!
Babylon.js和Three.js的应用场合
react函数式组件ref形式子向父传参
- 原文地址:https://blog.csdn.net/w2915w/article/details/138658002