-
《动手学深度学习(Pytorch版)》Task01:初识深度学习——4.22打卡
深度学习介绍
AI地图
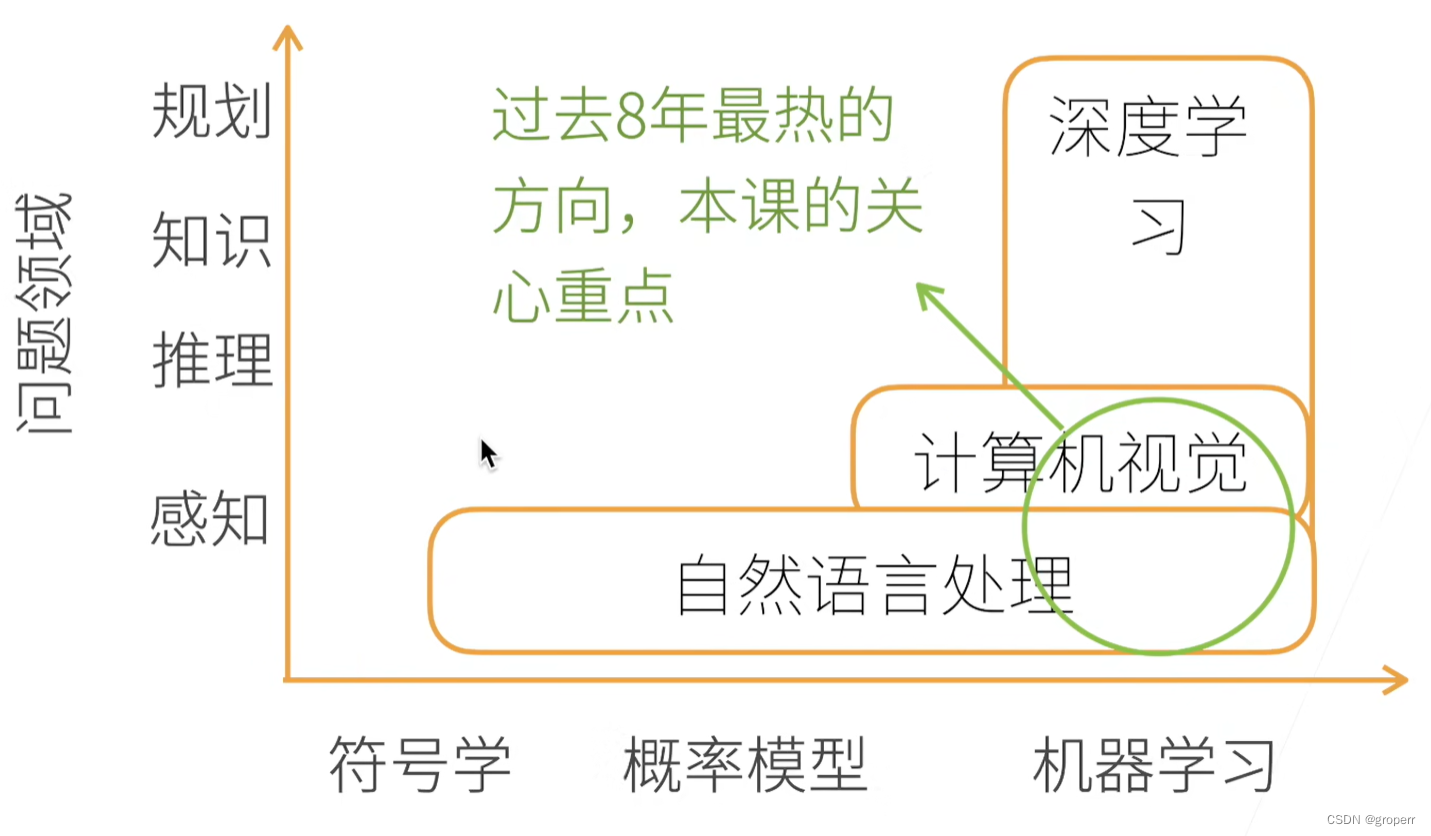
- 自然语言处理:起源于符号学,如机器翻译,人在几秒钟能反应过来,属于感知问题
- 计算机视觉:图片由像素组成,难以用符号学解释,在图片中进行推理,大部分用概率模型或者机器学习
- 深度学习:机器学习的一种
深度学习任务
图片分类
输入图像识别类别
著名数据集Image-net
物体检测和分割
- 目标检测:输入图像识别图像中每个物体的类别和框
- 语义分割:识别每个像素的类别

样式迁移
将一个图像中的样式应用在另一图像之上

人脸合成

文字生成图片
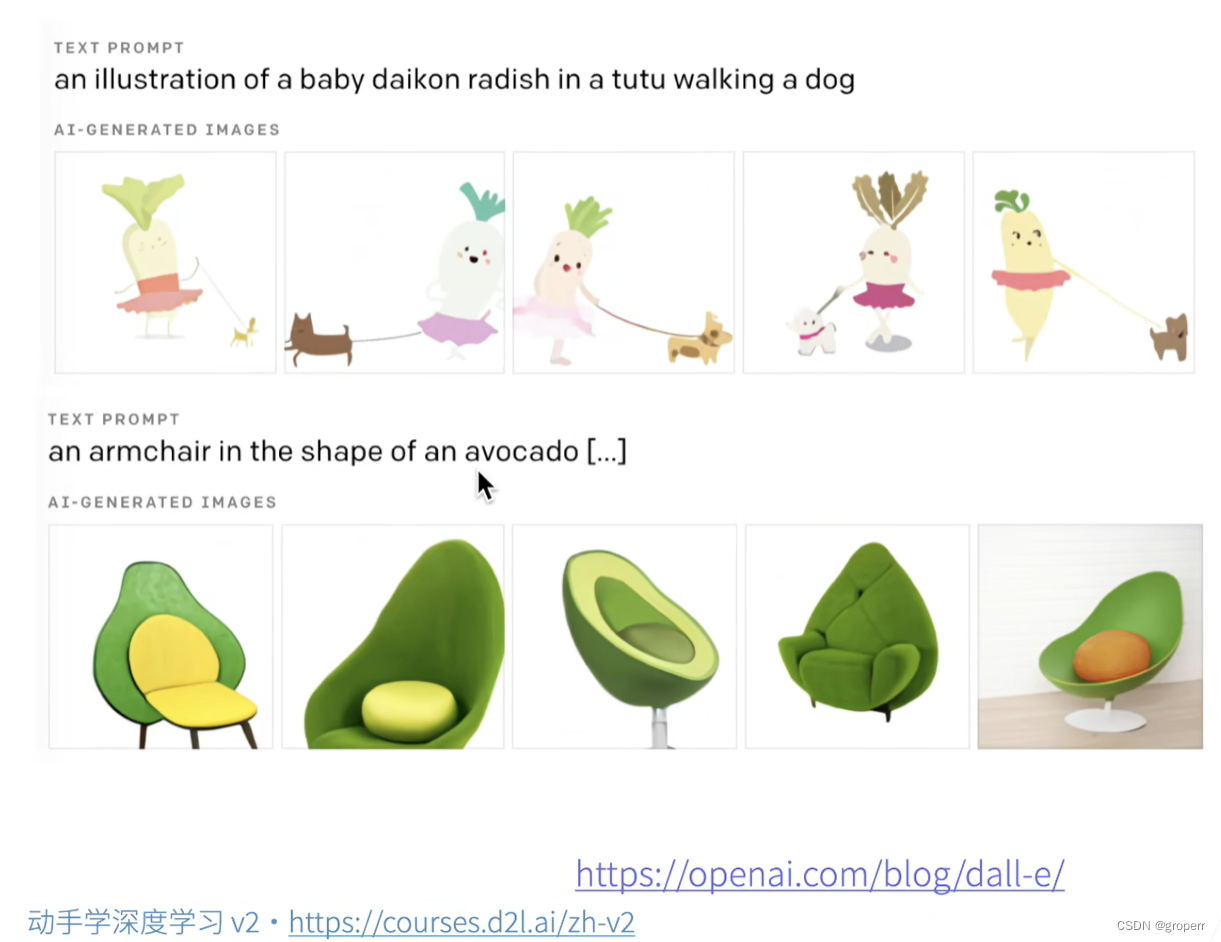
文字生成
以QA形式进行文字生成,如GPT-3

无人驾驶

案例:广告点击
场景:给定用户输入如何返回相应的广告
三个阶段:
- 触发
- 点击率预估 —> 机器学习模型
- 排序
**预测:**特征提取 —> 模型 —> 点击率预测
**训练:**训练数据(过去广告展现和用户点击) —> 特征和用户点击 —> 模型
完整过程
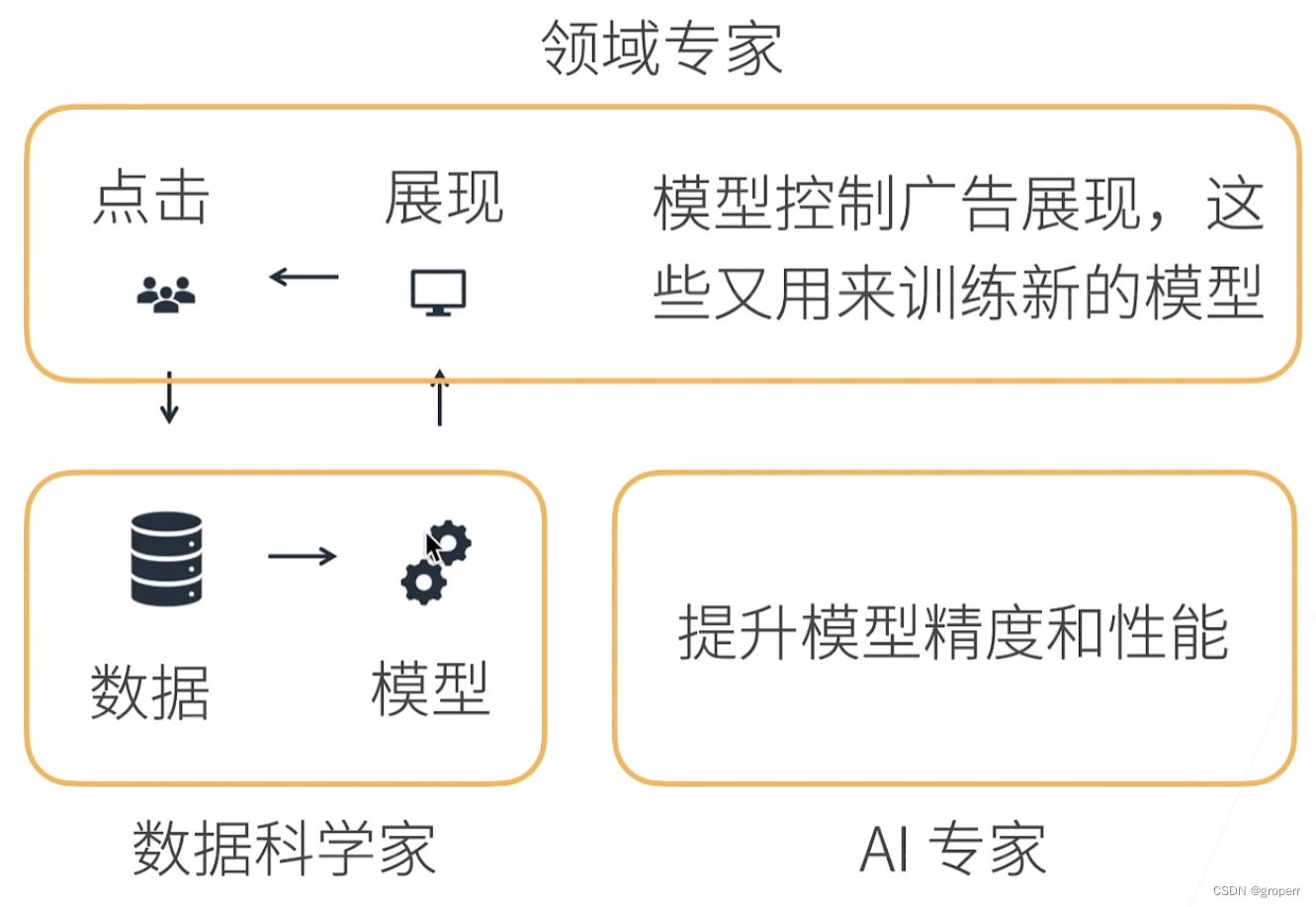
领域专家:关心模型应用产生的影响,提需求的人,甲方
数据科学家:将原始数据转换成机器可以理解的数据,乙方
AI专家:训练模型并且关注模型的进一步提升
QA
Q:机器学习的可解释性:机器学习在图片分割领域为什么有效?
A:深度学习的可解释性(人类理解层面)现在很难定论,但是可以从一些角度解释模型为什么有效
Q:深度学习无法用数学规范表述,只能从直觉上理解对吗?
A:不一定,模型可以用数学表述,但是目前难以用数学来解释模型为什么工作/不工作
引言-相关名词整理
关键组件
数据(data)
数据集(dataset)
模型(model):任一调整参数后的程序
参数(parameter):可以调整程序行为的旋钮
学习算法(learning algorithm):使用数据集来选择参数的元程序
样本(example, sample)数据点(data point)数据实例(data instance):组成数据集的数据
独立同分布(independently and identically distributed, i.i.d.)
特征(features,或协变量(covariates)):一组特征属性组成一个样本
维数(dimensionality):特征向量的长度
深度学习(deep learning):关注功能强大的模型,这些模型由神经网络错综复杂的交织在一起,包含层层数据转换
目标函数(objective function):量化模型的有效性的函数
损失函数(loss function,或cost function):习惯上取目标函数越低越好,所以叫损失
训练数据集(training dataset,或称为训练集(training set)):用于模型训练而收集的样本,拟合模型参数
测试数据集(test dataset,或称为测试集(test set)):用于测试模型性能,模型没有见过的“新数据集”,评估拟合的模型
过拟合(overfitting):模型在训练集上表现良好,但测试集效果很差
梯度下降(gradient descent):常用的优化算法,在每个步骤中,梯度下降法都会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数。
监督学习
监督学习(supervised learning):在“给定输入特征”的情况下预测标签。每个“特征-标签”对都称为一个样本(example)。
回归
回归(regression):训练一个回归函数来输出一个数值
平方误差(squared error):预测值与实际值之差的平方,预测数值最常用
分类
分类(classification):练一个分类器来输出预测的类别
类别(category,正式称为类(class))
二项分类(binomial classification):只有两个类别的分类
多项分类(multiclass classification):有两个以上的类别
交叉熵(cross-entropy):所有标签分布的预期损失值
层次分类(hierarchical classification):一些分类任务的变体可以用于寻找层次结构,层次结构假定在许多类之间存在某种关系
标记问题
多标签分类(multi-label classification):学习预测不相互排斥的类别的问题
推荐系统
推荐系统(recommender system):向特定用户进行“个性化”推荐
序列学习
序列学习(sequence Learning):摄取可变长度的输入序列 和/或 预测可变长度的输出序列
无监督学习
无监督学习(unsupervised learning):数据中不含有“目标”的机器学习问题
聚类(clustering):没有标签的情况下给数据分类
主成分分析(principal component analysis):用少量的参数来准确地捕捉数据的线性相关属性
因果关系(causality)和概率图模型(probabilistic graphical models):根据经验数据发现属性之间的关系
生成对抗性网络(generative adversarial networks):通过两个神经网络相互博弈的方式进行学习,生成数据
与环境互动
离线学习(offline learning):根据预先收集的数据进行模型训练,训练开始后不与环境交互
分布偏移(distribution shift):训练集和测试集之间的数据分布不同,导致模型的泛化性能很差。
强化学习
强化学习(reinforcement learning):让智能体(agent)在与环境交互的过程中,通过学习最优的行为策略,来实现最大的回报或目标。
智能体(agent)
观察(observation)
动作(action)
奖励(reward)
策略(policy):强化学习的目标是产生一个好的策略
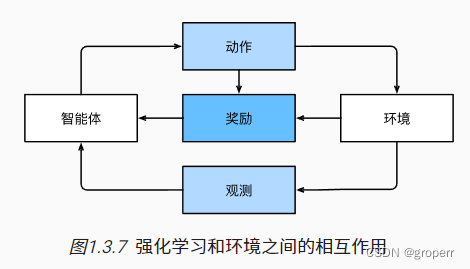
学分分配(credit assignment):决定哪些行为是值得奖励的,哪些行为是需要惩罚的。
马尔可夫决策过程(markov decision process):环境可被完全观察到的强化学习问题
上下文赌博机(contextual bandit problem):状态不依赖于之前的操作的强化学习问题
多臂赌博机(multi-armed bandit problem):没有状态,只有一组最初未知回报的可用动作的强化学习问题
神经网络(neural networks):一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。
层(layers):线性和非线性处理单元的交替
链式规则(也称为反向传播(backpropagation)):一次性调整网络中的全部参数的规则
dropout :有助于减轻过拟合
表示学习(representation learning):模型自动从数据中抽取特征或表达,以方便后续任务
Datawhale环境配置讲解
视频分为Linux和windows环境配置,本人使用笔记本自带的RTX4060显卡进行配置,所以是windows环境,视频在20:30左右开始
视频内容:
下载 Miniconda
更换镜像源
下载GIT
下载课程 Repo
之前已经配置过conda和pytorch,所以跳过
安装
因为已经安装conda,所以跳过安装Miniconda
安装深度学习框架和
d2l软件包创建conda虚拟环境
conda create -n learning_pytorch python=3.9- 1
激活虚拟环境
conda activate learning_pytorch- 1
确定CUDA driver的版本
运行
nvidia-smi, CUDA版本为12.4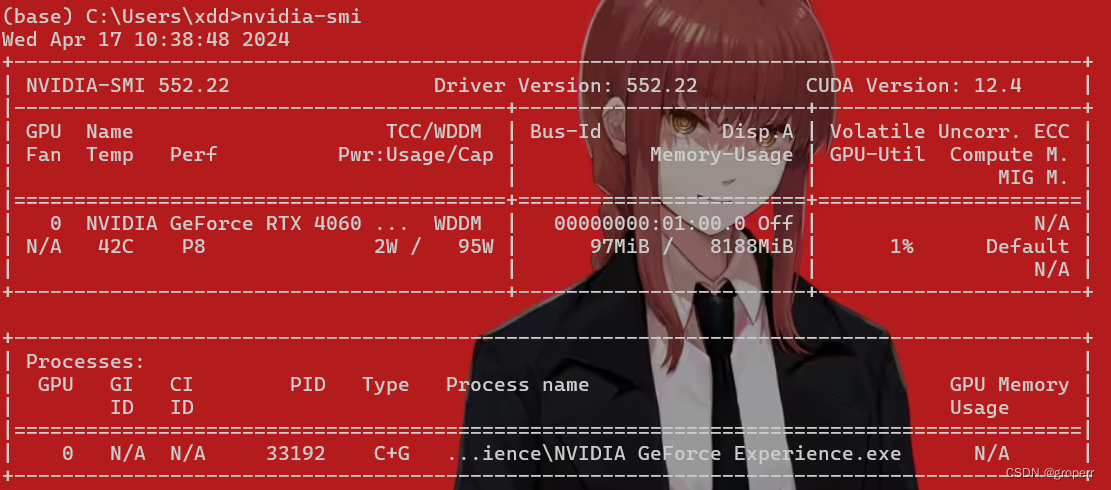
pytorch官网选择比CUDA driver小的最新版本
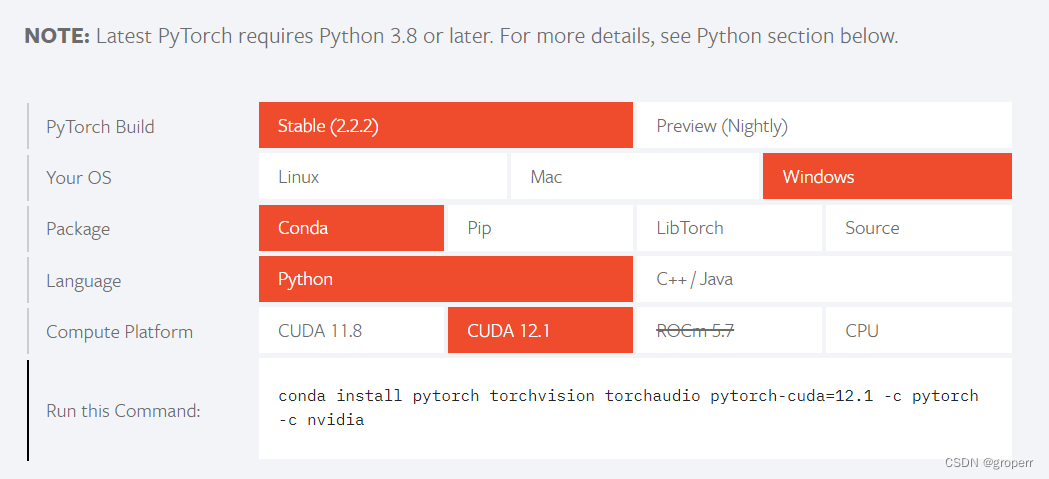
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia- 1
安装
d2l包pip install d2l==0.17.6- 1
下载 D2L Notebook
创建文件夹d2l-zh并下载压缩包
mkdir d2l-zh && cd d2l-zh curl https://zh-v2.d2l.ai/d2l-zh-2.0.0.zip -o d2l-zh.zip- 1
- 2
问题:‘unzip’ 不是内部或外部命令,也不是可运行的程序
或批处理文件。原因:unzip是linux系统下,windows不自带。
解决方法:下载unzip,官网地址:https://gnuwin32.sourceforge.net/packages/unzip.htm
- 选择Binaries;
- 下载ZIP;
- 最后将下载下来的unzip-5.51-1-bin\bin\unzip.exe文件复制到 C:\Windows\System32 即可。
解压,可以正常运行
unzip d2l-zh.zip && del d2l-zh.zip- 1
PS:windows命令提示符(CMD)使用
del命令来删除文件。cd pytorch- 1
打开Jupyter笔记本(在Window系统的命令行窗口中运行以下命令前,需先将当前路径定位到刚下载的本书代码解压后的目录)
jupyter notebook- 1
成功打开
李沐:GPT时代AI怎么学?
原来的深度学习:人在5s可以决策出来的问题
现在的深度学习:一个专业人士1h的工作量
机器学习这么多年在训练上其实没有本质的变化
不同:每几年会把一类模型的做到智能顶点
transformer的智能上限仍在探索中
就算遇到上限,也会去探索新的模型架构
现状:transformer的了解不够深入,下一个架构仍未出现
-
相关阅读:
.360勒索病毒和.halo勒索病毒数据恢复|金蝶、用友、ERP等数据恢复
【Spring Cloud】 Gateway配置说明示例
吴恩达deeplearning.ai:使用多个决策树&随机森林
POST 请求,Ajax 与 cookie
vue知识点——路由
应用平台桌面菜单由常规拖放,换成ht.Grid布局操作步骤
阿里最新分享的《多线程核心技术第三版》神书就此霸榜GitHub,3天点击量已破百万
SpringBoot-27-springSecurity(安全:认证授权)
Python机器学习实战-特征重要性分析方法(9):卡方检验(附源码和实现效果)
数据库学习之索引
- 原文地址:https://blog.csdn.net/qq_46118704/article/details/138096495