-
负载均衡的原理及算法
一、定义
负载均衡(Load Balancing)是一种计算机网络和服务器管理技术,旨在分配网络流量、请求或工作负载到多个服务器或资源,以确保这些服务器能够高效、均匀地处理负载,并且能够提供更高的性能、可用性和可扩展性。
二、负载均衡算法
1.Round Robin-轮询
轮询,顾名思义,把请求按顺序分配给每个服务器,然后重复执行这个顺序,进行请求分配。如下图:
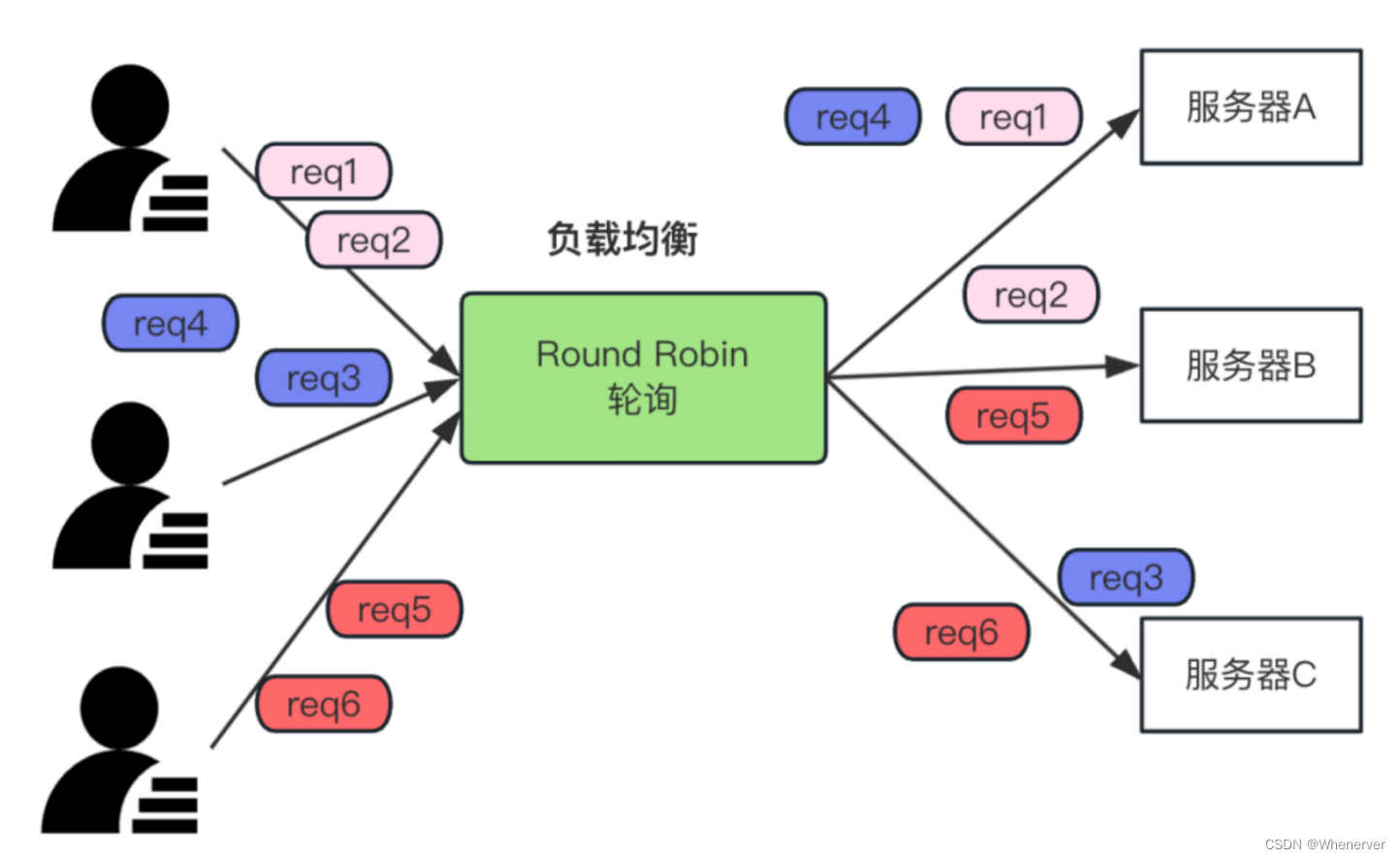
如上图,有3台服务器,分别为服务器A、服务器B和服务器C,当客户端有请求过来时,请求会按照 A->B->C->A->B->C->… 这种轮询的顺序分配给各个服务器。
(1) 原理:
- 服务器列表:维护一个服务器列表,有服务器加入/剔除时,相应的更新服务器列表;
- 服务器游标:记录需要处理下一个请求的服务器;
- 请求分发:新请求到达,选择当前服务器来处理该请求,然后服务器游标+1;
- 循环:不断重复步骤3,以确保每个服务器都有机会处理请求;
(2) 算法实现
方法1:
轮询算法的实现非常简单,可以定义一个服务器的列表和当前服务器指针,如下伪代码:
# 服务器列表 servers = ["ServerA", "ServerB", "ServerC"] # 当前服务器 current_server = 0 # 轮询算法 if(req): # 选择当前服务器来处理请求 process_request(servers[current_server]) # 将当前服务器移到服务器列表的末尾 if current_server == length(servers): current_server = 0 else: # 指针+1 current_server += 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
当客户端有新的请求到达时,负载均衡器会选择服务器指针(current_server)指向的服务器来处理请求,然后将当前服务器指针移到下一个服务器(current_server += 1), 如果 current_server=服务器总数,则把current_server设置为0,进行下一场轮询。
方法2: 循环列表
循环列表是一个环形数据结构,用于按照顺序循环遍历服务器列表。当指针指向列表的末尾时,指针会回到列表的开头,从而实现循环。如下伪代码:
servers = ["Server1", "Server2", "Server3"] # 服务器列表 current_index = 0 # 当前服务器的索引 def get_next_server(self): if not self.servers: return None # 获取当前服务器 current_server = self.servers[self.current_index] # 更新索引,移到下一个服务器 self.current_index = (self.current_index + 1) % len(self.servers) return current_server # 创建一个包含服务器的列表 servers_list = ["ServerA", "ServerB", "ServerC"] # 模拟请求的处理过程 if(req): # 假设有5个请 next_server = get_next_server() if next_server is not None: process_request(next_server) else: print("No available servers.")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
(3) 优缺点
优点:简单,实现成本低;
缺点:
- 无法根据服务器的负载情况来分配请求,当服务器的负载不均衡时,轮询算法无法自动调整。
- 当服务器down机了,轮询算法无法自动剔除该服务器,导致请求会被转发到down机的服务器上。
servers = ["Server1", "Server2", "Server3"] # 服务器列表 current_index = 0 # 当前服务器的索引 def get_next_server(self): if not self.servers: return None # 获取当前服务器 current_server = self.servers[self.current_index] # 更新索引,移到下一个服务器 self.current_index = (self.current_index + 1) % len(self.servers) return current_server # 创建一个包含服务器的列表 servers_list = ["ServerA", "ServerB", "ServerC"] # 模拟请求的处理过程 if(req): # 假设有5个请 next_server = get_next_server() if next_server is not None: process_request(next_server) else: print("No available servers.")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
(4) 适用场景
对服务器没有什么特别的要求,就可以采用轮询算法,比如:Nginx 默认适用的就是轮询算法。
2.Weighted Round Robin - 加权轮询
加权轮询算法是轮询算法的一种改进,只不过在负载时会根据服务器的权重来分配请求,权重越大,分配的请求就会越多。如下图:
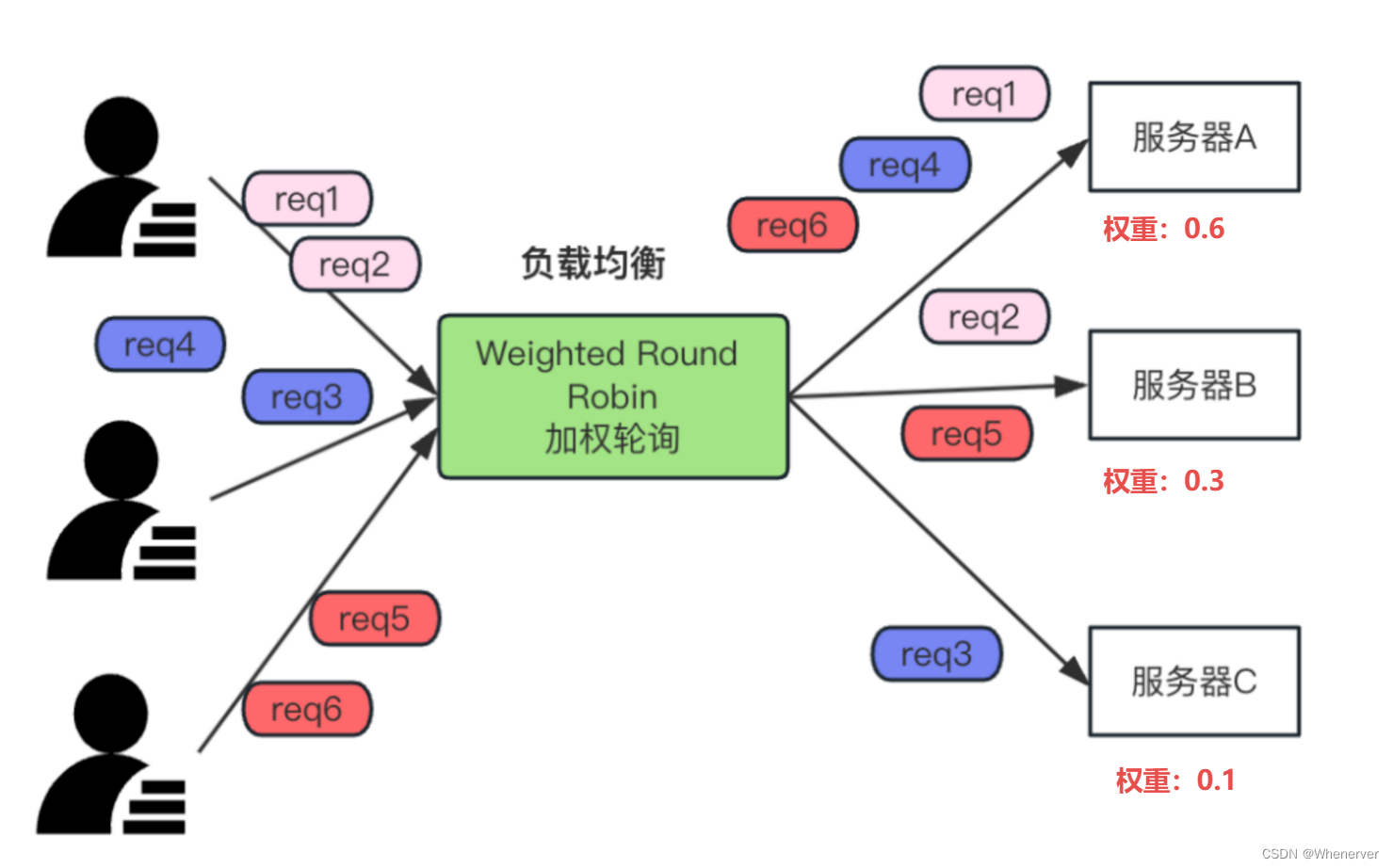
(1) 算法实现
实现算法和轮询很类似,只不过会根据权重在列表中放置不同比例的服务器,同时定义一个服务器的列表和当前服务器指针,如下伪代码:
# 服务器列表 servers = ["ServerA", "ServerA", "ServerA", "ServerB","ServerB", "ServerC"] # 当前服务器 current_server = 0 # 轮询算法 if(req): # 选择当前服务器来处理请求 process_request(servers[current_server]) # 将当前服务器移到服务器列表的末尾 if current_server == length(servers): current_server = 0 else: # 指针+1 current_server += 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
当客户端有新的请求到达时,负载均衡器会选择服务器指针(current_server)指向的服务器来处理请求,然后将当前服务器指针移到下一个服务器(current_server += 1), 如果 current_server=服务器总数,则把current_server设置为0,进行下一场轮询。
(2) 优缺点
优点:可以人为配置权重,为处理能力强的服务器配置高的权重,处理能力弱的配置低的权重,从而实现负载均衡。
缺点:无法应对服务器动态变化的情况,比如:服务器down机了,无法自动剔除该服务器,导致请求会被转发到down机的服务器上。
(3) 适用场景
服务器的处理能力不一致,可以采用加权轮询算法。
比如:有3台服务器,服务器A(4C8G,4个CPU,8G内存),服务器B(2C4G,2个CPU,4G内存),服务器C(1C2G,1个CPU,2G内存),那么可以配置服务器A的权重为4,服务器B的权重为2,服务器C的权重为1。
3.Least Connections - 最小连接数
最小连接数,是指把请求分配给当前连接数最少的服务器,以确保负载更均匀。如下图:
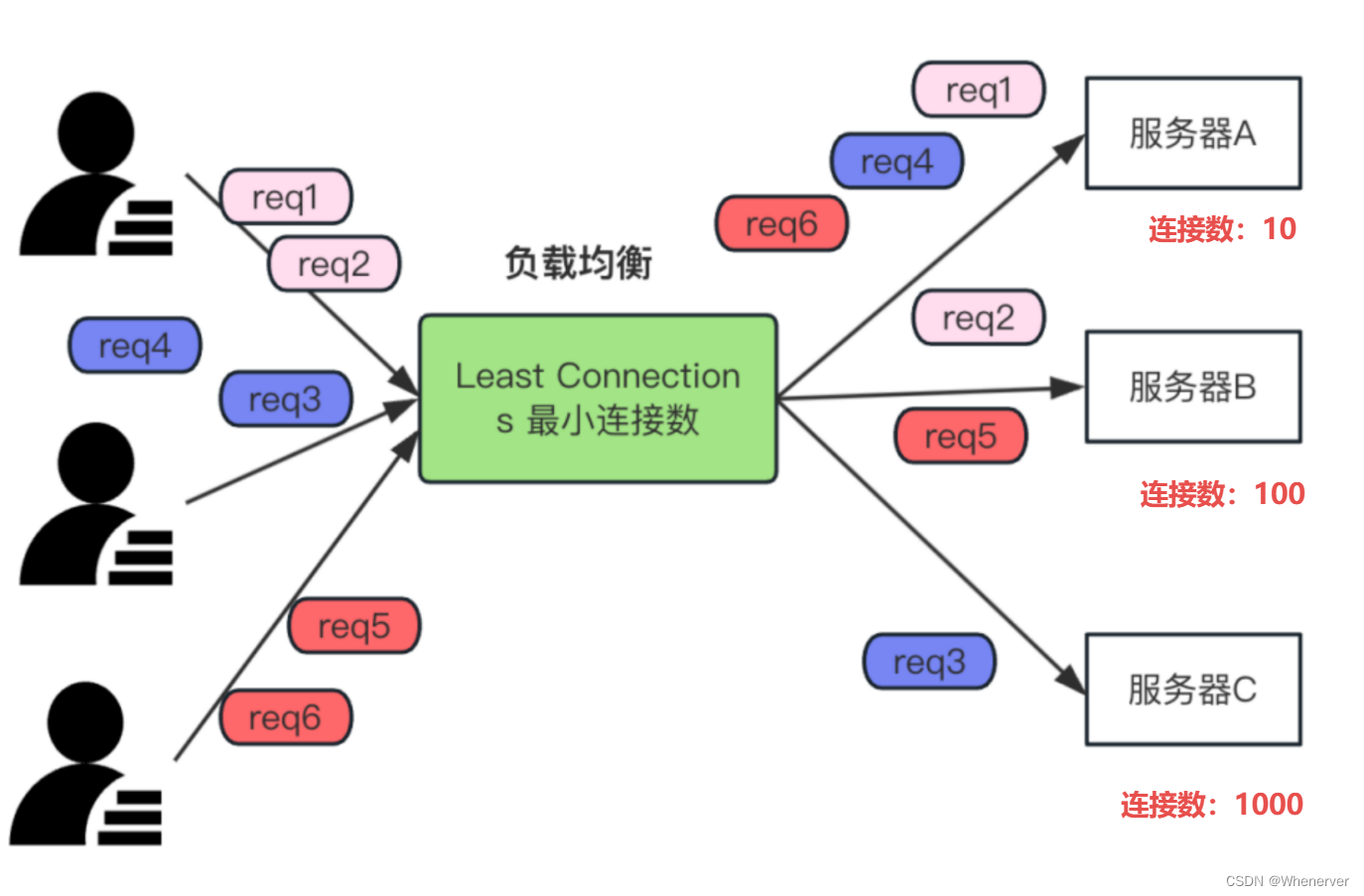
上图中有 3台服务器,服务器A(连接数10)、服务器B(连接数100)和服务器C(连接数1000),连接数最少的服务器A分配的Req比其他服务器多。
(1) 原理
- 维护一个所有服务器和连接数的字典(Map);
- 当新的请求到达时,负载均衡器会检查服务器列表中当前连接数最少的服务器;
- 请求将被分配给具有最少连接数的服务器,处理请求后该服务器的连接数+1;
- 如果有多台服务器具有相同的最小连接数,算法可以使用其他标准来选择其中一台,如加权等。
(2) 算法实现
如下伪代码:
# 创建一个包含服务器及其连接数的字典 servers = {"Server A": 5, "Server B": 3, "Server C": 4} def get_server_with_least_connections(): # 找到当前连接数最少的服务器 min_connections = min(servers.values()) # 找到具有最小连接数的服务器 for server, connections in servers.items(): if connections == min_connections: return server # 选择连接数最少的服务器 def assign_request(self): # 获取具有最小连接数的服务器 server = get_server_with_least_connections() if server is not None: # 模拟分配请求给服务器,增加连接数 self.servers[server] += 1 return server else: return "No available servers." # 模拟请求的处理过程 if req: # 假设有请求 assigned_server = load_balancer.assign_request()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
(3) 优缺点
优点:
- 动态负载均衡:它根据服务器的当前负载情况来做出决策,这使得它能够有效地分配请求给当前连接数最少的服务器,从而确保了服务器资源的最佳利用。
- 适应性强:这个算法适用于服务器性能不均匀的情况,因为它关注的是连接数,而不是服务器的硬件配置或性能评估。
- 避免过载:通过将新请求分配给连接数最少的服务器,”最小连接数”算法有助于防止某些服务器被过度加载,从而提高了系统的稳定性和性能。
- 自动恢复:如果某台服务器由于故障或重启而导致连接数清零,该算法会自动开始将新请求分配给该服务器,以实现自动恢复。
缺点:
- 连接数不一定代表负载:”最小连接数”算法假设连接数与服务器的负载成正比,但这并不总是准确。有时候,某台服务器的连接数可能很高,但仍然能够处理更多的请求,而另一台连接数较低的服务器可能已经达到了其性能极限。
- 不适用于长连接:如果服务器上有大量长期活跃的连接,例如WebSocket连接,该算法可能不太适用,因为长连接不同于短暂的HTTP请求,连接数的统计可能会产生误导。
- 无法解决服务器性能差异:虽然”最小连接数”算法可以平衡连接数,但它无法解决服务器硬件性能差异的问题。在这种情况下,可能需要其他负载均衡算法,如加权轮询,来更好地适应性能差异。
(4) 适用场景
通过服务器连接数来做负载均衡的场景。到目前为止,还没有遇到生产上使用这种算法的场景。
4.IP/URL Hash - IP/URL 散列
IP/URL 散列算法是一种根据客户端 IP 地址或 URL 来分配请求的负载均衡算法,这样相同的IP或者URL就会负载到相同的服务器上。
(1) 原理
- 将客户端 IP 地址或 URL 散列到服务器列表中,
- 然后将请求分配给散列值对应的服务器。
如下图:有3台服务器,分别为服务器A、服务器B和服务器C,当相同IP的客户端请求会被负载到形同的服务器列中。
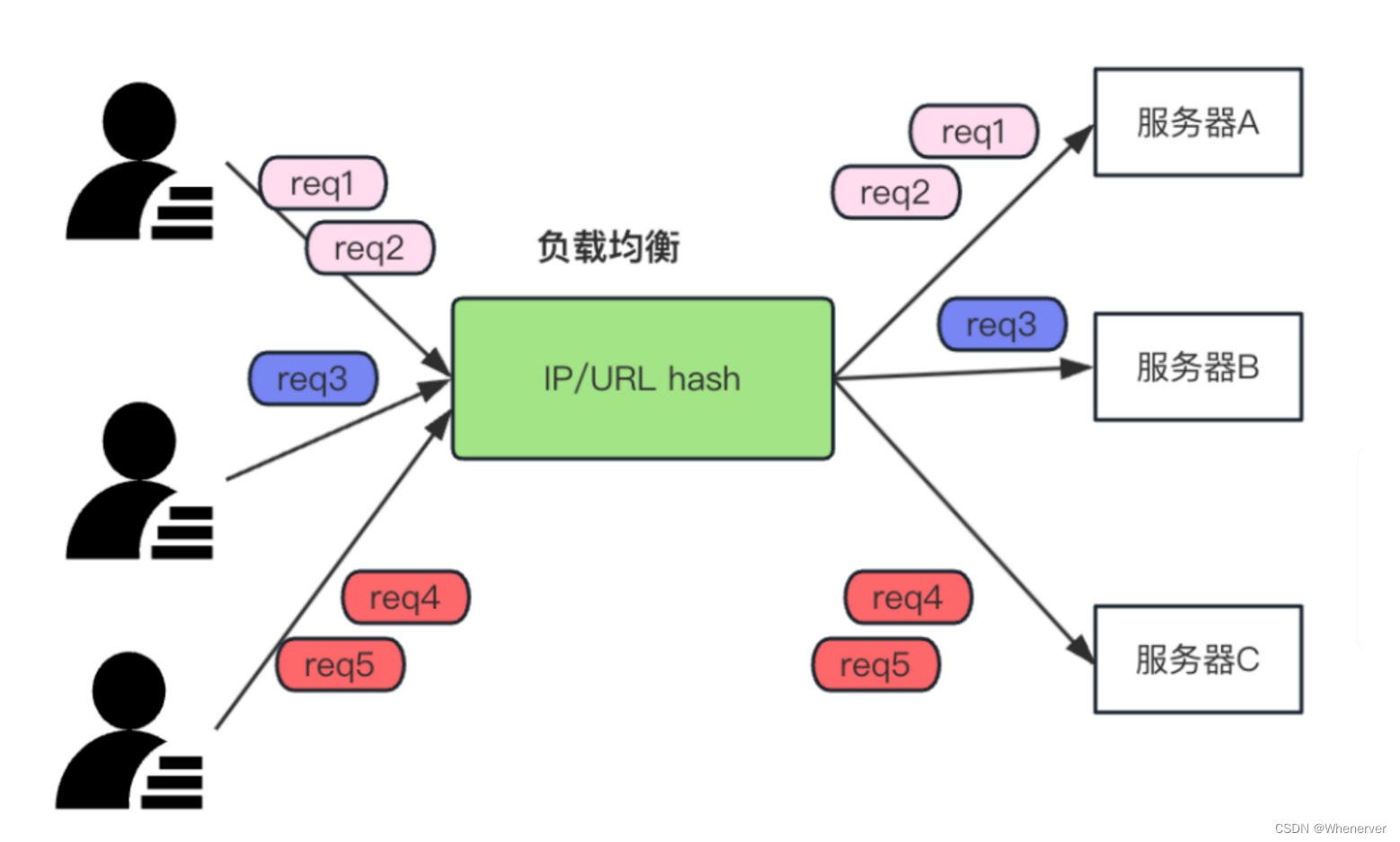
(2) 优缺点
优点:
- 稳定性:IP/URL Hash
算法可以确保相同的客户端请求总是被分发到相同的服务器上。这可以提高应用程序的稳定性,因为客户端的会话数据在同一服务器上保持一致。 - 适用于会话保持:当应用程序需要在多次请求之间保持会话状态时,IP/URL Hash
算法非常有用。客户端在一次请求中选择的服务器会在后续请求中保持一致,确保会话数据不会丢失。 - 负载均衡:IP/URL Hash 算法可以将特定的客户端请求均匀地分配到多个服务器上,从而实现基本的负载均衡,避免了某些服务器被过度请求。
缺点:
- 不适用于动态环境:IP/URL Hash 算法基于客户端的 IP 地址或 URL,一旦客户端 IP 或请求的 URL
发生变化,请求可能会被分配到不同的服务器上,导致会话数据丢失或不一致。 - 不考虑服务器负载:IP/URL Hash 算法不考虑服务器的当前负载情况。如果某个服务器的负载过高,IP/URL Hash
无法动态地将请求分发到负载较低的服务器上。
(3) 适用场景
- 静态环境:在静态环境中,即客户端的 IP 地址或请求的 URL 不经常变化的情况下,IP/URL Hash 算法可以提供稳定的负载均衡。
- 少数服务器的负载均衡:当服务器数量相对较少且不太容易动态扩展时,IP/URL Hash 算法可以用于基本的负载均衡。
5.Least Response Time - 最短响应时间
最短响应时间就是指:处理请求的响应时间最少的服务器,获取的请求就越多。直白讲就是随速度快,随就干的多。如下图:
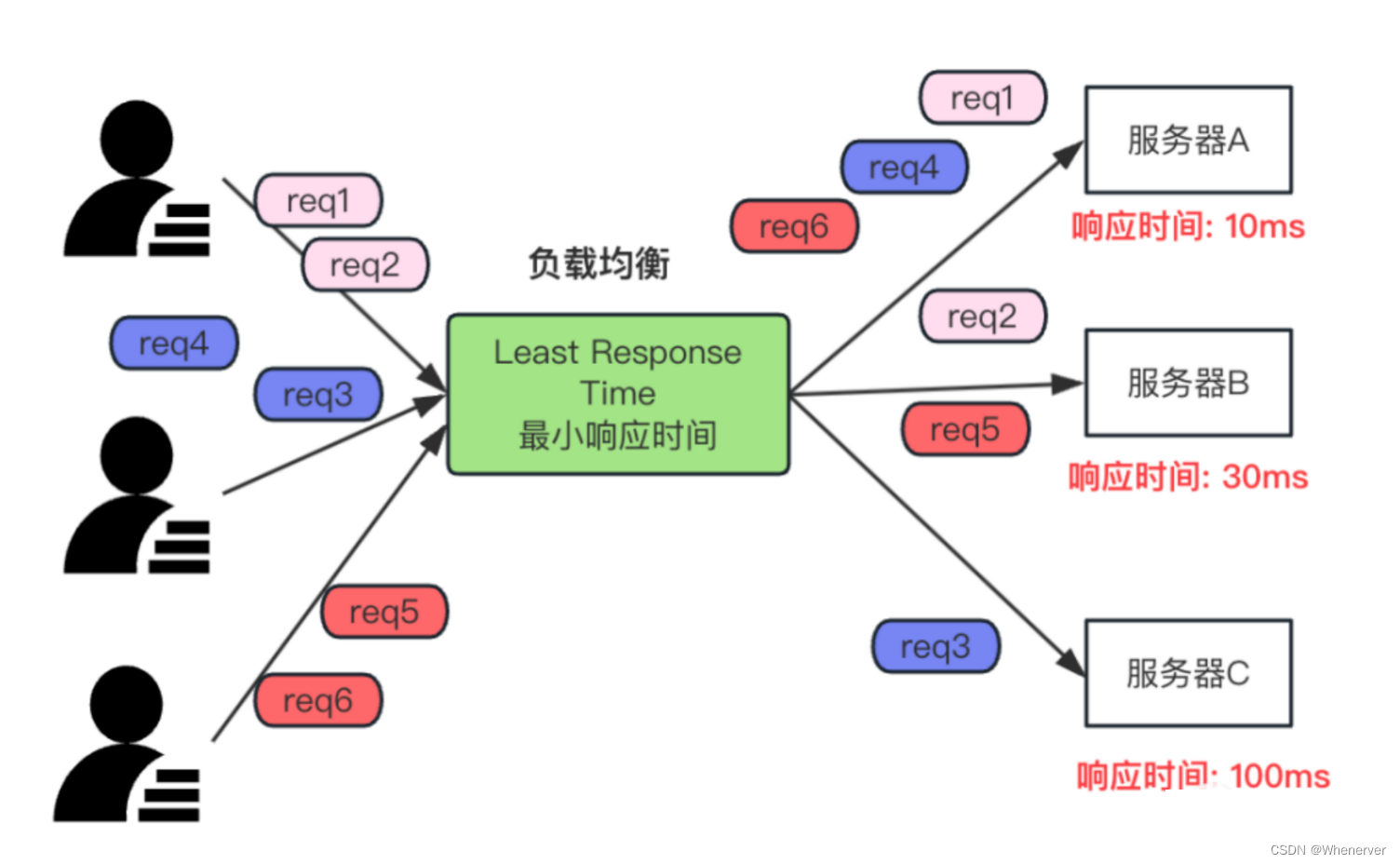
(1) 适用场景
负载均衡的所有服务器,处理能力相差比较大。比如:有3台服务器,服务器A(4C8G,4个CPU,8G内存),服务器B(2C4G,2个CPU,4G内存),服务器C(1C2G,1个CPU,2G内存), 那么就可以采用这种算法,这样可以根据服务器的处理来实现动态负载。
(2) 优缺点
优点:可以充分发挥各个服务器的性能,提高服务器的利用率。
缺点:饥饿问题。比如,服务器A的性能最好,处理速度最快,那么所有的请求都会被分配到服务器A,这样服务器B和服务器C就会一直处于饥饿状态,无法处理请求。这样也就会产生不公平。
(3) 算法实现
如下伪代码:记录每台服务器以及响应时间,然后找到响应时间最短的服务器,将请求分配到该服务器上。
# 服务器列表,每个服务器表示为一个字典,包含服务器的唯一标识符和响应时间 servers = [ {"id": "serverA", "response_time": 10}, {"id": "serverB", "response_time": 30}, {"id": "serverC", "response_time": 100}, # 添加更多服务器 ] # 找到响应时间最短的服务器 def find_least_response_time_server(servers): # 初始选择第一个服务器为最短响应时间服务器 least_response_time_server = servers[0] # 遍历服务器列表,找到最短响应时间的服务器 for server in servers: if server["response_time"] < least_response_time_server["response_time"]: least_response_time_server = server return least_response_time_server # 客户端请求到来时,选择最短响应时间的服务器 def handle_client_request(): least_response_time_server = find_least_response_time_server(servers) if req: least_response_time_server.handle_client_request()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
需要说明的是:这只是一个简单的示例,实际的负载均衡系统可能需要更复杂的逻辑,包括定期更新服务器的响应时间、处理服务器故障等。此外,要将这种算法应用于实际生产环境,可能需要使用专门的负载均衡软件或硬件,这些工具可以自动管理服务器并提供更多功能。
(4) 适用场景
交通控制系统:在城市交通控制系统中,需要及时响应交通信号、路况和车辆检测等信息。最短响应时间算法可以帮助确保交通信号及时适应交通流量的变化。
三、总结
本文分析了五种常见的负载均衡算法,算法的实现都比较简单,在实际的生产环境中,我们可以根据自己的业务场景来选择合适的负载均衡算法。
另外,除了上面 5种算法外,还有一种其他的负载均衡算法,比如:
- 一致性哈希:Consistent Hashing,可以参考文章:hash & 一致性hash,如何选择?
- 加权最少连接:Weighted Least Connections,在Weighted Least Connections基础上再加权重。
在实际生产中,我们可能并不需要自己去实现这些算法,而会选择使用一些现有的框架,比如:nginx、lvs、haproxy等, 但是万变不离其宗,了解这些负载均衡算法可以帮组我们更好的去理解框架。
-
相关阅读:
A-B 数对
【微机接口】8086中断指令
Axure8.0:移入菜单(带子菜单)
Redis的持久化详解
NoSQL数据库之MongoDB
“云炬众创”小程序的操作演示
自动从Android上拉取指定文件
Elasticsearch如何保证数据不丢失?
Docker更新Springboot的部署
devops-2:Jenkins的使用及Pipeline语法讲解
- 原文地址:https://blog.csdn.net/qq_38566465/article/details/138075915
