-
大模型都在用的:旋转位置编码
写在前面
这篇文章提到了绝对位置编码和相对位置编码,但是他们都有局限性,比如绝对位置编码不能直接表征token的相对位置关系;相对位置编码过于复杂,影响效率。于是诞生了一种用绝对位置编码的方式实现相对位置编码的编码方式——旋转位置编码(Rotary Position Embedding, RoPE),兼顾效率和相对位置关系。
RoPE的核心思想是通过旋转的方式将位置信息编码到每个维度,从而使得模型能够捕捉到序列中元素的相对位置信息。现在已经在很多大模型证明了其有效性,比如ChatGLM、LLaMA等。
一、RoPE的优点
1.真正的旋转位置编码
Transformer的原版位置编码也使用了三角函数,但它生成的是每个位置的绝对编码,三角函数的主要用途是生成具有可区分性的周期性模式,也没有应用旋转变换的概念,因此属于绝对位置编码。同时原版的编码使用加法,在多层传递后导致位置信息的稀释,如下图 (没想到这张图也有被当做反面典型的时候吧
 ):
):
RoPE不是简单的加法,而是通过复数乘法实现旋转变换,这种旋转是将位置信息融入到token表示中的关键机制。RoPE在实现过程中通过乘法操作融入位置信息,与模型中的Q和K深度融合,将旋转操作真正植入Attention机制内部,强化了位置编码信息的作用。
2.更好的相对位置信息编码
注意力机制通过计算Embedding的内积来确定它们之间的关系强度。
使用RoPE时,两个位置的编码通过旋转变换后的内积,自然地包含了它们之间的相对位置信息。这是因为旋转操作保持了内积的性质,使得内积计算不仅反映了token的内容相似性,还反映了它们的位置关系。
3.更适用于多维输入
这点很有意思,传统的Transformer位置编码主要针对一维序列,如文本序列。然而,在某些任务中,输入可能是二维或更高维的数据,如图像或视频数据。旋转位置编码可以更灵活地应用于多维输入数据,通过对不同维度的位置信息进行编码,使得模型能够更好地理解多维数据中的位置关系。
4. 更善于处理长序列
RoPE可以减少位置信息的损失。在深层网络中,RoPE通过乘法操作融入位置信息,乘法操作有助于在深层网络中保持位置信息的完整性。在处理一个长文本时,RoPE通过在每一层的自注意力计算中使用旋转变换,确保了位置信息能够被有效保留和利用,即使是在模型的较深层次。
二、公式
既然旋转的位置编码有这么多优点,那怎么实现位置编码的旋转呢,其实网上有很多介绍的文章。大概意思就是复数可以通过乘以e的幂来旋转角度,其中幂就是角度,再结合欧拉公式推出三角函数的表达,大致流程如下。
欧拉公式:
 (1)
(1)复数旋转角度θ:
 (2)
(2)将(1)带入(2):
 (3)
(3)这块东西苏剑林老师已经从数学的角度进行过很深入的推导,这里的融合式部分,我就不班门弄斧了。我今天提供一种朴素的思考过程,从代码实现的角度思考如何进行旋转。
众所周知,一维向量是不能旋转的,那我们就旋转一个[2,d]的二维向量q,并且设
![x=q[0],y=q[1]](https://1000bd.com/contentImg/2024/04/26/b38b24d25a26177e.png) 即:
即:![x=[q_0,q_1...,q_{d/2-1}],y=[q_{d/2},q_{d/2+1}...,q_{d-1}]](https://1000bd.com/contentImg/2024/04/26/f28d7f4d324b6db0.png) (4)
(4)要旋转q很容易,乘以旋转矩阵就可以了,如果我们要旋转角度θ:
![R(\theta )=[x , y]\cdot \begin{bmatrix} cos(\theta ) & -sin(\theta )\\ sin(\theta ) & cos(\theta ) \end{bmatrix}](https://1000bd.com/contentImg/2024/04/26/378156f093200f86.png) (5)
(5)展开之后,结果如下:
(6)
上面的
 ,很眼熟吧,就是沿用了transformer的机制,这里有详细的介绍。
,很眼熟吧,就是沿用了transformer的机制,这里有详细的介绍。而且大家看到字母q也大概能猜到,这就是Attention中的Q,同样的操作也可以对K使用。经过上述操作,其实已经以旋转的方式将位置编码融合到Attention机制内部。
下面就是根据式子(6)的代码实现了。这里提前说一句,ChatGLM的Q和K的形状都是[b,1,32,64],其中b是token_ids的长度;32是multi-head的个数;64将被拆成两部分,每部分32,也就是上面的x,y,下面开始代码实现部分。
三、代码实现
我们以ChatGLM的代码为例,展示一下RoPE的使用,以下代码都在modeling_chatglm.py文件中,一条训练数据:
{"context": "你好", "target": "你好,我是大白话"}1.字符串转换成token_ids
[ 5, 74874, 130001, 130004, 5, 74874, 6, 65806, 63850, 95351, 130005]2.计算position_ids
根据上面的token_ids计算出position_ids:
- [[0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2],
- [0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8]]
解释一下position_ids:第一行表示序列中每个元素的全局位置,第一个“2”表明context结束了,target要开始了,后面所有的2都是target部分;第二行则细化到更具体的局部位置,从1开始表征整个target的内容,这样用两个维度的编码很优雅的体现了context和target,这种层次化处理对于理解上下文非常重要。
代码如下:
- def get_position_ids(self, input_ids, mask_positions, device, use_gmasks=None):
- """
- 根据token_ids生成position_ids
- :param input_ids: 这里是[[ 5, 74874, 130001, 130004, 5, 74874, 6, 65806, 63850, 95351, 130005]]
- :param mask_positions: 2 输出的第1维mask掉几位,即这一位及其前面都是0,后面是1,2...
- :param device:
- :param use_gmasks:
- :return: [[0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2],
- [0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8]]
- """
- batch_size, seq_length = input_ids.shape
- if use_gmasks is None:
- use_gmasks = [False] * batch_size
- context_lengths = [seq.tolist().index(self.config.bos_token_id) for seq in input_ids]
- if self.position_encoding_2d:
- # 会走这一分支
- position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
- for i, context_length in enumerate(context_lengths):
- position_ids[i, context_length:] = mask_positions[i]
- block_position_ids = [torch.cat((
- torch.zeros(context_length, dtype=torch.long, device=device),
- torch.arange(seq_length - context_length, dtype=torch.long, device=device) + 1
- )) for context_length in context_lengths]
- block_position_ids = torch.stack(block_position_ids, dim=0)
- position_ids = torch.stack((position_ids, block_position_ids), dim=1)
- else:
- position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
- for i, context_length in enumerate(context_lengths):
- if not use_gmasks[i]:
- position_ids[i, context_length:] = mask_positions[i]
- return position_ids
3.角度序列Embedding
接下来,将position_ids转换成角度序列Embedding,下表中每个格的公式为

其中m是position_ids中元素的数值;i是编码的索引,ChatGLM使用两个0-31拼接;d是维度,hidden_size // (num_attention_heads * 2)=46:
第一部分:position_ids=[0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2],每个值编码成长度64的角度序列:
m | i 0 1 31 0 1 31 0 m=0, i=0 m=0, i=1 ... m=0, i=31 m=0, i=0 m=0, i=1 ... m=0, i=31 1 m=1, i=0 m=1, i=1 m=1, i=31 m=1, i=0 m=1, i=1 m=1, i=31 2 m=2, i=0 m=2, i=1 m=2, i=31 m=2, i=0 m=2, i=1 m=2, i=31 ... 2 m=2, i=0 m=2, i=1 m=2, i=31 m=2, i=0 m=2, i=1 m=2, i=31 第二部分:block_position_ids=[0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8]
m | i 0 1 31 0 1 31 0 m=0, i=0 m=0, i=1 ... m=0, i=31 m=0, i=0 m=0, i=1 ... m=0, i=31 0 m=0, i=0 m=0, i=1 ... m=0, i=31 m=0, i=0 m=0, i=1 ... m=0, i=31 0 m=0, i=0 m=0, i=1 ... m=0, i=31 m=0, i=0 m=0, i=1 ... m=0, i=31 1 m=1, i=0 m=1, i=1 m=1, i=31 m=1, i=0 m=1, i=1 m=1, i=31 ... 8 m=8, i=0 m=8, i=1 m=8, i=31 m=8, i=0 m=8, i=1 m=8, i=31 代码如下:
- class RotaryEmbedding(torch.nn.Module):
- def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys,
- error_msgs):
- pass
- def __init__(self, dim, base=10000, precision=torch.half, learnable=False):
- """
- 根据position_ids计算旋转角度的Embedding
- :param dim: 这里hidden_size // (num_attention_heads * 2)=46,其中hidden_size=4096 num_attention_heads=32
- :param base:
- :param precision:
- :param learnable:
- """
- super().__init__()
- # 初始化“频率”,可以理解为position_id每增加1,增加的角度,是Embedding形式的。
- inv_freq = 1. / (base ** (torch.arange(0, dim, 2).float() / dim))
- inv_freq = inv_freq.half()
- self.learnable = learnable
- if learnable:
- self.inv_freq = torch.nn.Parameter(inv_freq)
- self.max_seq_len_cached = None
- else:
- self.register_buffer('inv_freq', inv_freq)
- self.max_seq_len_cached = None
- self.cos_cached = None
- self.sin_cached = None
- self.precision = precision
- def forward(self, x, seq_dim=1, seq_len=None):
- if seq_len is None:
- seq_len = x.shape[seq_dim]
- if self.max_seq_len_cached is None or (seq_len > self.max_seq_len_cached):
- self.max_seq_len_cached = None if self.learnable else seq_len
- # 1.对position_ids去重并正序排列得到t,如:[[0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2]] --> t=[[0, 1, 2]]
- t = torch.arange(seq_len, device=x.device, dtype=self.inv_freq.dtype)
- # 2.t与初始化好的“频率”做外积,得到每个position_id的角度,是Embedding
- freqs = torch.einsum('i,j->ij', t, self.inv_freq)
- # 3.每个Embedding重复叠加一次
- emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
- if self.precision == torch.bfloat16:
- emb = emb.float()
- # 4.算cos和sin,并增加维度
- cos_cached = emb.cos()[:, None, :]
- sin_cached = emb.sin()[:, None, :]
- if self.precision == torch.bfloat16:
- cos_cached = cos_cached.bfloat16()
- sin_cached = sin_cached.bfloat16()
- if self.learnable:
- return cos_cached, sin_cached
- self.cos_cached, self.sin_cached = cos_cached, sin_cached
- return self.cos_cached[:seq_len, ...], self.sin_cached[:seq_len, ...]
- def apply_rotary_pos_emb_index(q, k, cos, sin, position_id):
- # position_id: [sq, b], q, k: [sq, b, np, hn], cos: [sq, 1, hn] -> [sq, b, 1, hn]
- # 类似于查表,根据每个position_id获取相应的Embedding
- cos, sin = F.embedding(position_id, cos.squeeze(1)).unsqueeze(2), \
- F.embedding(position_id, sin.squeeze(1)).unsqueeze(2)
- ......
4.截取拼接Q和K
这一步对Q或者K做截断,并将第二段取反拼在第一段的前面,拼接成公式第二项的q部分。
上述3、4流程示意图:

代码如下:
- def rotate_half(x):
- x1, x2 = x[..., :x.shape[-1] // 2], x[..., x.shape[-1] // 2:]
- return torch.cat((-x2, x1), dim=x1.ndim - 1)
5.旋转位置编码融合
将旋转位置编码融合到Q和K中,计算第一部分的cos(
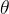 1)和sin(1),并与输入的Q1、K1做乘法融合;计算第二部分的cos(1)和sin(1),并与输入的Q1、K1做乘法融合,最后将Q和K分别拼接,组成融合了旋转位置编码的新Q和K。整体流程图如下,其中rotary_pos_emb是上图,也就是步骤3、4:
1)和sin(1),并与输入的Q1、K1做乘法融合;计算第二部分的cos(1)和sin(1),并与输入的Q1、K1做乘法融合,最后将Q和K分别拼接,组成融合了旋转位置编码的新Q和K。整体流程图如下,其中rotary_pos_emb是上图,也就是步骤3、4:
代码如下:
- def apply_rotary_pos_emb_index(q, k, cos, sin, position_id):
- # position_id: [sq, b], q, k: [sq, b, np, hn], cos: [sq, 1, hn] -> [sq, b, 1, hn]
- # 类似于查表,根据每个position_id获取相应的Embedding
- cos, sin = F.embedding(position_id, cos.squeeze(1)).unsqueeze(2), \
- F.embedding(position_id, sin.squeeze(1)).unsqueeze(2)
- # 执行旋转位置编码与QK的融合
- q, k = (q * cos) + (rotate_half(q) * sin), (k * cos) + (rotate_half(k) * sin)
- return q, k
- # 整体流程如下
- # 1.拆分出Q1、Q2、K1、K2
- q1, q2 = query_layer.chunk(2, dim=(query_layer.ndim - 1))
- k1, k2 = key_layer.chunk(2, dim=(key_layer.ndim - 1))
- # 2.计算旋转Embedding
- cos, sin = self.rotary_emb(q1, seq_len=position_ids.max() + 1)
- position_ids, block_position_ids = position_ids[:, 0, :].transpose(0, 1).contiguous(), \
- position_ids[:, 1, :].transpose(0, 1).contiguous()
- # 3.旋转位置编码融合
- q1, k1 = apply_rotary_pos_emb_index(q1, k1, cos, sin, position_ids)
- q2, k2 = apply_rotary_pos_emb_index(q2, k2, cos, sin, block_position_ids)
- # 4.将拆分出的Q1、Q2、K1、K2合并成新的Q、K
- query_layer = torch.concat([q1, q2], dim=(q1.ndim - 1))
- key_layer = torch.concat([k1, k2], dim=(k1.ndim - 1))
位置编码对于Transformer的重要性毋庸置疑,旋转位置编码也确实解决了一些问题。最有意思的就是它是一个二维编码,将旋转信息通过乘法操作融入Attention机制内部,强化了位置编码信息,现在已经有很多开源大模型都使用了旋转位置编码,可见其效果不俗。
旋转位置编码就介绍到这里,关注不迷路(#^.^#)
关注订阅号了解更多精品文章

交流探讨、商务合作请加微信

-
相关阅读:
Python大数据之PySpark(二)PySpark安装
Hexagon_V65_Programmers_Reference_Manual(29)
数据库存储引擎和数据类型详细介绍
蔚小理处境越发尴尬了?
Nginx的安装
用Python实现链式调用
【服务器数据恢复】Raid阵列更换故障硬盘后数据同步失败的数据恢复案例
Mapbox 与 Babylon.js 可视化 创建喷泉底部
使用Termux在安卓手机上搭建本地Git服务器
【网络安全】——sql注入之云锁bypass
- 原文地址:https://blog.csdn.net/xian0710830114/article/details/138121661
