-
07.JAVAEE之线程5
与面试相关
1.常见的锁策略
不是一把具体的锁,而是一类锁
1.1 乐观锁 vs 悲观锁
悲观乐观,是对后续锁冲突是否激烈(频繁)给出的预测
如果预测接下来锁冲突的概率不大,就可以少做一些工作. 就称为 乐观锁
如果预测接下来锁冲突的概率很大,就应该多做一些工作. 就称为 悲观锁
1.2 重量级锁 vs 轻量级锁
- 轻量级锁,锁的开销比较小
- 重量级锁,锁的开销比较大.
- 和刚才的乐观悲观是有关联的,
- 一个是预测锁冲突的概率,,一个是实际消耗的开销
1.3 自旋锁和挂起等待锁

此处的忙等带来了更高的效率。
1.4 读写锁
把加锁,分成两种了:
读加锁:读的时候, 能读, 但是不能写
写加锁:读的时候,不能读, 也不能写
两个线程加锁过程中:
1.读锁和读锁之间, 不会产生竞争(多线程读同一个东西,有线程安全)
2.读锁和写锁之间,有竞争
3.写锁和写锁之间, 也有竞争
实际开发中,遇到的场景,往往是"读多,写少"
1.5 可重入锁 vs 不可重入锁
一个线程针对同一把锁,连续加锁两次,不会死锁, 就是可重入锁,会死锁, 就是不可重入锁
1.6 公平锁 vs 非公平锁
当很多线程去尝试加一把锁的时候,一个线程能够拿到锁,其他线程阻塞等待一旦第一个线程释放锁之后,接下来是哪个线程能够拿到锁呢?
公平锁: 就是按照"先来后到”顺序.
非公平锁: 则是剩下的线程以"均等"的概率,来重新竞争锁,操作系统提供的加锁 apì 默认情况, 就属于"非公平锁"如果要想实现公平锁,你还需要引入额外的队列,维护这些线程的加锁顺序
1.7 Synchronized属于那种锁呢???
- 对于"悲观乐观”自适应的,
- 对于"重量轻量"自适应的.
- 对于"自旋挂起等待”自适应的,
- 不是读写锁
- 是可重入锁
- 是非公平锁
- 什么是自适应呢???
- 初始情况下,synchronized 会预测当前的锁冲突的概率不大,此时以乐观锁的模式来运行.(此时也就是轻量级锁,基于自旋锁的方式实现)
在实际使用过程中,如果发现锁冲突的情况比较多。synchronized 就会升级成 悲观锁 (也就是重量级锁, 基于挂起等待的方式实现)
2.CAS
2.1 什么是CAS
Compare and Swap比较和交换寄存器
 2.2 CAS 伪代码
2.2 CAS 伪代码下面写的代码不是原子的, 真实的 CAS 是一个原子的硬件指令完成的. 这个伪代码只是辅助理解
CAS 的工作流程.- boolean CAS(address, expectValue, swapValue) {
- if (&address == expectedValue) {
- &address = swapValue;
- return true;
- }
- return false;
- }
CAS 其实是一个 cpu 指令
(一个 cpu 指令,就能完成上述比较交换的逻辑)
单个的 cpu 指令,是原子的!! 就可以使用 CAS 完成一些操作(给编写线程安全的代码,引入了新的思路~~),进一步的替代"加锁”基于 CAS 实现线程安全的方式,也称为"无锁编程
优点: 保证线程安全, 同时避免阻塞.(效率)缺点:
1.代码会更复杂,不好理解
2.只能够适合一些特定场景, 不如加锁方式更普适,CAS 本质上是 cpu 提供的指令 =>又被操作系统封装,提供成 api =>又被 JVM 封装,也提供成 api =>程序员使用了
2.3 CAS 是怎么实现的
针对不同的操作系统,JVM 用到了不同的 CAS 实现原理,简单来讲:
- java 的 CAS 利用的的是 unsafe 这个类提供的 CAS 操作;
- unsafe 的 CAS 依赖了的是 jvm 针对不同的操作系统实现的 Atomic::cmpxchg;
- Atomic::cmpxchg 的实现使用了汇编的 CAS 操作,并使用 cpu 硬件提供的 lock 机制保证其原子性。
简而言之,是因为硬件予以了支持,软件层面才能做到。
2.4 CAS 有哪些应用
1) 实现原子类
标准库中提供了 java.util.concurrent.atomic 包, 里面的类都是基于这种方式来实现的.
典型的就是 AtomicInteger 类. 其中的 getAndIncrement 相当于 i++ 操作.- import java.util.concurrent.atomic.AtomicInteger;
- public class Demo29 {
- public static AtomicInteger count = new AtomicInteger(0);
- public static void main(String[] args) throws InterruptedException {
- Thread t1 = new Thread(() -> {
- for (int i = 0; i < 50000; i++) {
- // count++;
- count.getAndIncrement();
- // ++ count;
- // count.incrementAndGet();
- // count--
- // count.getAndDecrement();
- // --count
- // count.decrementAndGet();
- }
- });
- Thread t2 = new Thread(() -> {
- for (int i = 0; i < 50000; i++) {
- count.getAndIncrement();
- }
- });
- t1.start();
- t2.start();
- t1.join();
- t2.join();
- System.out.println(count.get());
- }
- }
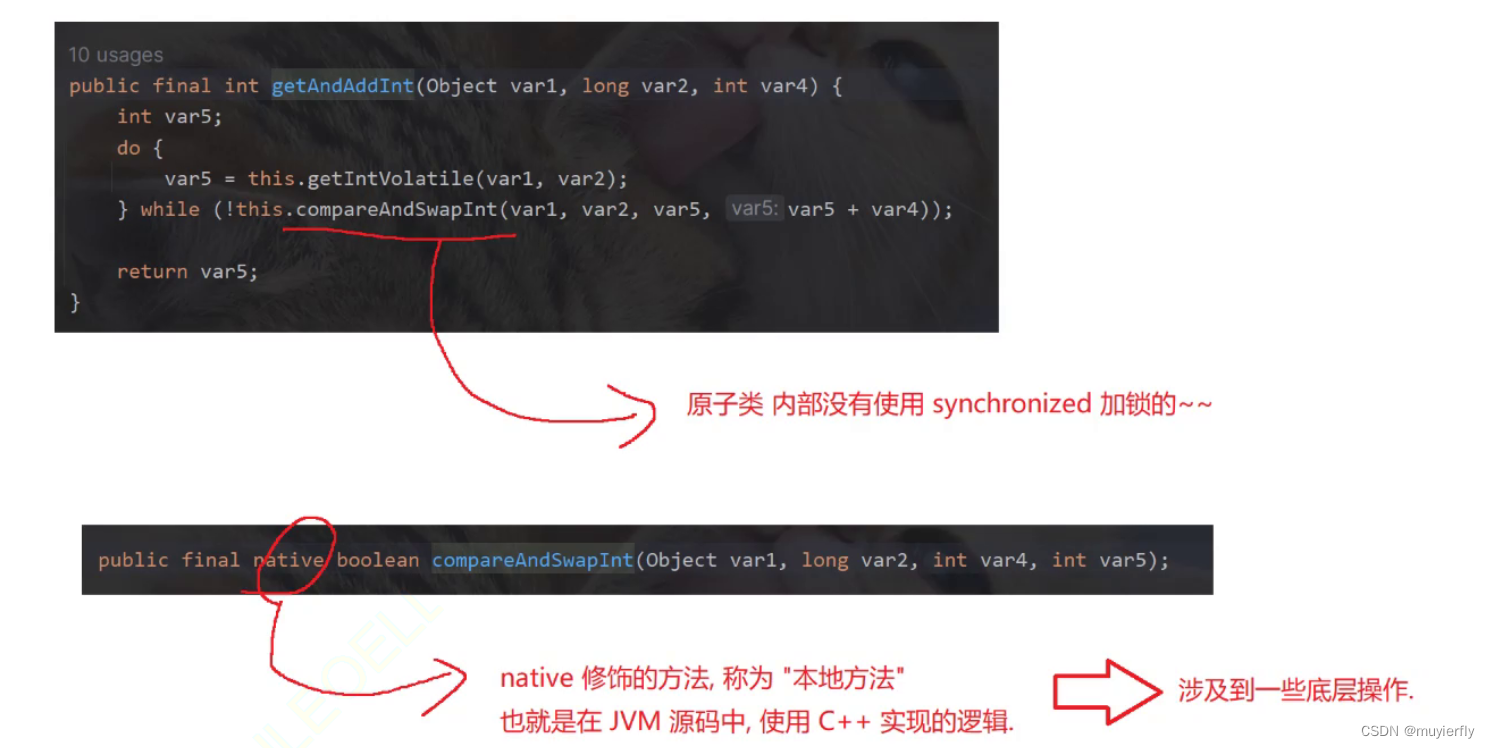
结论: 原子类里面是基于 CAS 来实现的
伪代码的实现:


前面说"线程不安全"本质上是进行自增的过程中,穿插执行了
CAS 也是让这里的自增,不要家插执行,核心思路和加锁是类似的.- 加锁是通过阻塞的方式,避免穿插.
- CAS 则是会通过重试的方式,避免穿插.
2) 实现自旋锁
基于 CAS 实现更灵活的锁, 获取到更多的控制权
伪代码
- public class SpinLock {
- private Thread owner = null;
- public void lock(){
- // 通过 CAS 看当前锁是否被某个线程持有.
- // 如果这个锁已经被别的线程持有, 那么就自旋等待.
- // 如果这个锁没有被别的线程持有, 那么就把 owner 设为当前尝试加锁的线程.
- while(!CAS(this.owner, null, Thread.currentThread())){
- }
- }
- public void unlock (){
- this.owner = null;
- }
- }
缺点:会消耗CPU。
CAS 也是多线程编程中的一种重要技巧,虽然开发中直接使用 CAS 的概率不大,但是经常会用到一些 内部封装了 CAS 的操作.
2.5 CAS 的 ABA 问题
CAS 进行操作的关键,是通过 值"没有发生变化"来作为"没有其他线程穿插执行" 判定依据
但是,这种判定方式,不够严谨.
更极端的情况下,可能有另一个线程穿插进来,把值从 A ->B ->A
针对第一个线程来说,看起来好像是这个值,没变,但是实际上已经被穿插执行了
一般来说ABA这样没有什么问题
但是存在极端问题
假设这个场景,我去 ATM 取钱. 我本身的 账户 1000我想要取 500
我在取钱的过程中, 出现 bug 了.
我按下取钱按钮, 没反应,我又按了一下.此时就产生了两个线程进行扣款操作!!未涉及ABA时

加入t3线程(别人同时进行转钱操作,即就会出现bug)
2.5.1 ABA问题的解决方案
只要让判定的数值,按照一个方向增长即可,(不要反复横跳)有增有减,就可能出现 ABA只是增加,或者只是减少;
针对像账户余额这样的概念,本身就应该要能增能减
可以引入一个额外的变量,版本号.
约定每次修改余额,都要让版本号自增.
此时在使用 CAS 判定的时候,就不是直接判定余额了,而是判定版本号,看版本号是否是变化了如果版本号不变,注定没有线程穿插执行了3.Synchronized原理
1.基本特点
结合上面的锁策略, 我们就可以总结出, Synchronized 具有以下特性(只考虑 JDK 1.8):
1. 开始时是乐观锁, 如果锁冲突频繁, 就转换为悲观锁.
2. 开始是轻量级锁实现, 如果锁被持有的时间较长, 就转换成重量级锁.
3. 实现轻量级锁的时候大概率用到的自旋锁策略
4. 是一种不公平锁
5. 是一种可重入锁
6. 不是读写锁2.synchronized 几个重要的机制
- 锁升级
- 锁消除
- 锁粗化
2.1 锁升级
JVM 将 synchronized 锁分为 无锁、偏向锁、轻量级锁、重量级锁状态。会根据情况,进行依次升级。(是单向的不能降级)

偏向锁不是真正的加锁,只是进行了一个标记。
偏向锁的核心思想, 我们以前讲过, 就是"懒汉模式"另一种体现(没有线程竞争,就不加锁,有别的线程竞争,就抢先一步进行加锁)
能不加锁, 就尽量不加锁.加锁意味着有开销
2.2 锁消除
锁消除.也是一种编译器优化的手段
编译器会自动针对你当前写的 加锁的代码,做出判定,
如果编译器觉得这个场景,不需要加锁,此时就会把你写的synchronized 给优化掉.
- StringBuilder不带 synchronized
- StringBuffer带有 synchronized
- 如果是在单个线程中使用 StringBuffer,此时编译器就会自动的把 synchronized 给优化掉编译器只会在自己非常有把握的时候,才会进行锁消除~~(触发的概率不算很高)

2.3 锁粗化
锁的粒度.
synchronized 里头,代码越多,就认为锁的粒度越粗代码越少,锁的粒度越细
粒度细的时候,能够并发执行的逻辑更多,更有利于充分利用多核 CPU 资源
但是,如果粒度细的锁,被反复进行加锁解锁,可能实际效果还不如粒度粗的锁.(涉及到反复的锁竞争)
3.JUC常见类
3.1.Callable
Callable 是一个 interface . 相当于把线程封装了一个 "返回值". 方便程序猿借助多线程的方式计算结果.
也是一种创建线程的方式,
适合于,想让某个线程执行一个逻辑,并且返回结果的时候。相比之下, Runnable 不关注结果- import java.util.concurrent.Callable;
- import java.util.concurrent.ExecutionException;
- import java.util.concurrent.FutureTask;
- public class Demo30 {
- public static void main(String[] args) throws ExecutionException, InterruptedException {
- // 定义了任务.
- Callable
callable = new Callable () { - @Override
- public Integer call() throws Exception {
- int sum = 0;
- for (int i = 0; i <= 1000; i++) {
- sum += i;
- }
- return sum;
- }
- };
- // 把任务放到线程中进行执行.
- FutureTask
futureTask = new FutureTask<>(callable); - Thread t = new Thread(futureTask);
- t.start();
- // 此处的 get 就能获取到 callable 里面的返回结果.
- // 由于线程是并发执行的. 执行到主线程的 get 的时候, t 线程可能还没执行完.
- // 没执行完的话, get 就会阻塞.
- System.out.println(futureTask.get());
- }
- }
//call()这个是 Callable 中的核心方法返回值就是 Integer, 期望这个线程能够返回一个整数,
小结: 线程的创建方式
1.继承 Thread, 重写 run(创建单独的类,也可以匿名内部类)
2.实现 Runnable, 重写 run(创建单独的类, 也可以匿名内部类3. 实现 Callable, 重写 cal (创建单独的类, 也可以匿名内部类)
4. 使用 lambda 表达式
5.ThreadFactory 线程工厂
6.线程池3.2 ReentrantLock (Reentrant可重入)
可重入互斥锁 . 和 synchronized 定位类似 , 都是用来实现互斥效果 , 保证线程安全 .ReentrantLock lock = new ReentrantLock ();-----------------------------------------lock . lock ();try {// working} finally {lock.unlock() //不能忘记此操作}优势:
1..ReentrantLock,在加锁的时候,有两种方式.lock, tryLock.
给了咱们更多的可操作空间
2.ReentrantLock,提供了 公平锁 的实现.(默认情况下是非公平锁)3.ReentrantLock 提供了更强大的等待通知机制. 搭配了 Condition 类,实现等待通知的
虽然 ReentrantLock 有上述优势,但是咱们在加锁的时候,还是首选:synchronized但是很明显, ReentrantLock 使用更加复杂,尤其是容易忘记解锁
另外 synchronized 背后还有一系列的优化手段~~
3.3 信号量 semaphore
也是操作系统课程中,比较重要的概念,
信号量, 就是一个计数器,描述了"可用资源"的个数
每次申请一个可用资源,就需要让计数器-1->P操作 acquire操作每次释放一个可用资源,就需要让计数器 +1->V 操作 release
(这里的 +1和-1 都是原子的)
信号量,假设初始情况下 数值是 10
每次进行 P操作,数值就 -1
当我已经进行了 10 次 P操作之后,数值就是 0了
如果我继续进行 P操作,会咋样呢?=>阻塞等待!!
- import java.util.concurrent.Semaphore;
- public class Demo31 {
- public static void main(String[] args) throws InterruptedException {
- Semaphore semaphore = new Semaphore(4);
- semaphore.acquire();
- System.out.println("P 操作");
- semaphore.acquire();
- System.out.println("P 操作");
- semaphore.acquire();
- System.out.println("P 操作");
- semaphore.acquire();
- System.out.println("P 操作");
- semaphore.acquire();
- System.out.println("P 操作");
- // semaphore.release();
- }
- }
Semaphore semaphore=new semaphore(4);
开发中如果遇到了需要申请资源的场景,就可以使用信号量来实现了,3.4 CountDownLatch
这个东西,主要是适用于,多个线程来完成一系列任务的时候,用来衡量任务的进度是否完成比如需要把一个大的任务,拆分成多个小的任务,让这些任务并发的去执行,就可以使用 countDownLatch 来判定说当前这些任务是否全都完成了
CountDownLatch 主要有两个方法.
1.await,调用的时候就会阻塞,就会等待其他的线程完成任务,所有的线程都完成了任务之后,此时这个 await 才会返回, 才会继续往下走.
2.countDown,告诉countDownLatch,我当前这一个子任务已经完成了- public class Demo32 {
- public static void main(String[] args) throws InterruptedException {
- // 10 个选手参赛. await 就会在 10 次调用完 countDown 之后才能继续执行.
- CountDownLatch countDownLatch = new CountDownLatch(10);
- for (int i = 0; i < 9; i++) {
- int id = i;
- Thread t = new Thread(() -> {
- System.out.println("thread " + id);
- try {
- Thread.sleep(500);
- } catch (InterruptedException e) {
- throw new RuntimeException(e);
- }
- // 通知说当前的任务执行完毕了.
- countDownLatch.countDown();
- });
- t.start();
- }
- // a => all
- countDownLatch.await();
- System.out.println("所有的任务都完成了. ");
- }
- }
4.线程安全的集合类
数据结构中大部分的集合类,都是线程不安全的.
Vector,Hashtable ,(前面两个是上古时期遗留的产物,现在已经不建议使用了)Stack, 线程安全 =>(加了synchronized)针对这些线程不安全的集合类,要想在多线程环境下使用, 就需要考虑好 线程安全问题了(核心问题是加锁)
同时,标准库,也给我们提供了一些搭配的组件,保证线程安全
Collections.synchronizedList(new ArrayList);
这个东西会返回一个新的对象,这个新的对象,就相当于给 ArrayList 套了一层壳这层壳就是在方法上直接使用 synchronized 的
CopyOnWriteArrayList写时拷贝
比如,两个线程使用同一个 ArrayList可能会读,也可能会修改.
如果要是两个线程读,就直接读就好了如果要是两个线程读,就直接读就好了.
如果某个线程需要进行修改,就把 ArrayList, 复制出一份副本.修改线程,就修改这个副本.与此同时,另一个线程仍然可以读取数据(从原来的数据上进行读取)
一旦这边修改完毕,就会使用修改好的这份数据,替代掉原来的数据,(往往就是一个引用赋值)
1.当前操作的 ArrayList 不能太大.(拷贝成本, 不能太高)
2.更适合于一个线程去修改,而不能是多个线程同时修改,(多个线程读,一个线程修改)这种场景特别适合于 服务器的配置更新~~可以通过配置文件,来描述配置的详细内容.(本身就不会很大)
配置的内容会被读到内存中,再由其他的线程,读取这里的内容但是修改这个配置内容,往往只有一个线程来修改,
使用某个命令让服务器重新加载配置,就可以使用写时拷贝的方式了ConcurrentHashMap
Hashtable 保证线程安全,主要就是给关键方法,加上 synchronized.直接加到方法上的.(相当于给 this加锁)
只要两个线程,在操作同一个 Hashtable 就会出现锁冲突~~
但是,实际上,对于哈希表来说,锁不一定非得这么加,有些情况,其实是不涉及到线程安全问题的~~//两个不同的 key 映射到同一个数组下标上,就会出现hash 冲突.
(数组+链表避免hash冲突,此时是否会发生线程安全)
按照上述这样的方式来操作,并且在不考虑 触发扩容 的前提下操作不同的链表的时候就是线程安全的.
如果两个线程,操作的是不同的链表,就根本不用加锁.只有说操作的同一个链表才需要加锁.
1.ConcurrentHashMap 最核心的改进,就是把一个全局的大锁,改进成了 每个链表独立的一把小锁.
这样做,大幅度降低了锁冲突的概率.
1个 hash 表,有很多这样的链表.两个线程恰好同时访问一个 链表 情况,本身就比较少2.充分利用到了 CAS 特性,把一些不必要加锁的环节给省略加锁了
比如,需要使用变量记录 hash 表中的元素个数此时,就可以使用原子操作(CAS) 修改元素个数
3.ConcurrentHashMap, 还有一个激进的操作,针对读操作没有加锁,读和读之间.读和写之间, 都不会有锁竞争.(读和写之间有加锁)
- 是否会存在这种“读到一个 修改了一半 的数值呢?ConcurrentHashMap 在底层编码过程中,比较谨慎的处理了一些细节修改的时候会避免使用 ++-- 这种非原子的操作!使用 =进行修改,本身就是原子的.
- 读的时候,要么读到的是写之前的旧值,要么是读到写之后的新值,不会出现读到一个 一半的值
4.ConcurrentHashMap 针对扩容操作, 做出了单独的优化.
本身 Hashtable 或者 HashMap 在扩容的时候,都是需要把所有的元素都拷贝一遍的(如果元素很多,拷贝就比较耗时)
用户访问 1000 次,999 次都很流畅,其中有一次就 卡了.(正好这一次触发扩容,导致出现卡顿)【解决方案】化整为零
一旦需要扩容,确实需要搬运,不是在一次操作中搬运完成,而是分成多次,来搬运,每次只搬运一部分数据避免这单次操作过于卡顿ConcurrentHashMap 基本的使用方法和普通的 HashMap 完全一样
-
相关阅读:
六、循环表达式
【Vue 实战】 生成二维码
【DevOps】Git 图文详解(二):Git 安装及配置
springboot整合mybatisPlus全技巧(2-常用开发技巧:通用字段插入)
try catch finally注意事项
开源相机管理库Aravis例程学习(四)——multiple-acquisition-signal
基于python-socket构建任务服务器(基于socket发送指令创建、停止任务)
Mac 安装依赖后依旧报错 ModuleNotFoundError: No module named ‘Crypto‘
【毕业季】从高考失利到成功保研——我的大学四年
黑炫酷的监控界面,实际上是用了什么开源工具?
- 原文地址:https://blog.csdn.net/m0_47017197/article/details/138180696
