-
照片相似性搜索引擎Embed-Photos;赋予大型语言模型(LLMs)视频和音频理解能力;OOTDiffusion的基础上可控制的服装驱动图像合成
✨ 1: Magic Clothing
Magic Clothing是一个以可控制的服装驱动图像合成为核心的技术项目,建立在OOTDiffusion的基础上

Magic Clothing是一个以可控制的服装驱动图像合成为核心的技术项目,建立在OOTDiffusion的基础上。通过使用Magic Clothing,可以在不同的场景下达到根据服装设计或者需求快速生成图像的目的。
地址:https://github.com/ShineChen1024/MagicClothing
✨ 2: Video-LLaMA
赋予大型语言模型(LLMs)视频和音频理解能力

Video-LLaMA是一个先进的项目,旨在赋予大型语言模型(LLMs)视频和音频理解能力。这意味着Video-LLaMA不仅可以处理和理解文本信息,还能理解和分析视频和音频内容。这一功能的实现,使得Video-LLaMA在多种情况下都非常有用,特别是在需要理解和生成对视频内容的描述、执行基于视频的指令或与视频内容互动的场景中。
地址:https://github.com/DAMO-NLP-SG/Video-LLaMA
✨ 3: Embed-Photos
照片相似性搜索引擎

Embed-Photos 是一个照片相似性搜索引擎。这个项目使用CLIP(对比语言-图像预训练)模型来寻找基于文本描述的视觉相似图片。这意味着你可以使用文字描述来查找看起来相似的图片,利用最新的AI技术快速和高效地搜索图片。
地址:https://github.com/harperreed/photo-similarity-search
✨ 4: Tiger
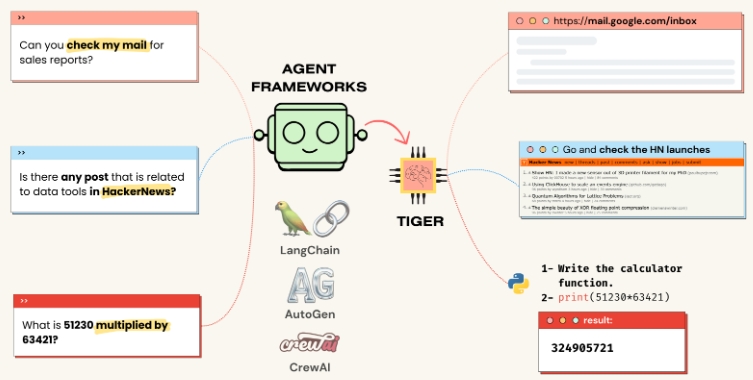
Tiger是一个以社区为驱动的项目,它旨在为LLM (大型语言模型) Agent Revolution开发一个可重复使用且集成的工具生态系统。Tiger可以看作是为你的AI代理提供的“神经连接”,使其能够直接通过“思考”来控制计算机做出各种操作。这包括写代码、使用搜索引擎、管理日历、控制鼠标和键盘、以音频输出与你对话等等。换句话说,你的AI代理想做什么,Tiger就帮它实现什么。
地址:https://github.com/Upsonic/Tiger
✨ 5: MotionGPT
MotionGPT是一个统一、多功能的人体运动与语言模型,能够处理多种与运动相关的任务。
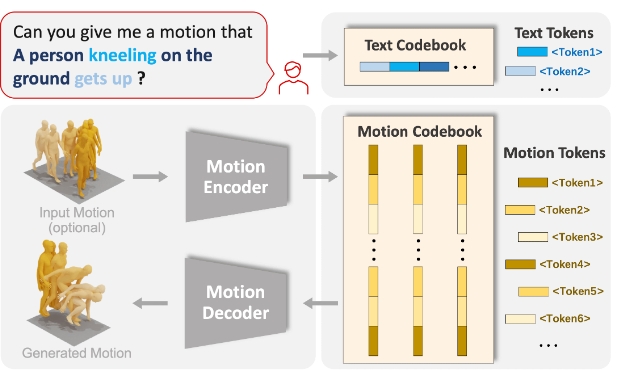
MotionGPT 是一个创新的人工智能框架,旨在理解和生成与人类运动相关的数据,正如其名所示,这一框架汲取了自然语言处理领域的技术,并将其应用于处理和生成人类运动信息。下面我们用通俗的语言详细解释一下MotionGPT的功能和使用场景。
MotionGPT通过将复杂的人体运动数据转换为易于理解的语言模型,使得开发者和研究人员可以更加方便地利用这些数据进行多种运动相关的任务,从为虚拟角色生成自然动作到理解和预测人类运动行为等,它为我们打开了一个使用人工智能理解和生成人体运动新的大门。
地址:https://motion-gpt.github.io/
更多AI工具,参考国内AiBard123,Github-AiBard123
-
相关阅读:
生物素偶联二硒化钨WSe2 (Biotin-WSe2)|羟基修饰PEG化二硒化钨WSe2纳米颗粒 (OH-WSe2)齐岳
leetcode top100(20) 搜索二维矩阵 II
【无标题】
JVM支持的可配置参数查看和分类
Qtday3
视频批量添加背景图片教程,详细步骤一看就会
【C++ Primer Plus】第9章 内存模型和名称空间
Tesla P40千元级大显卡主机装机实践
Doceker-compose——容器群集编排管理工具
python urllib open 头部信息错误
- 原文地址:https://blog.csdn.net/weixin_40425640/article/details/138084735