-
Opencv Python图像处理笔记一:图像、窗口基本操作
前言
随着人工智能和计算机视觉技术的迅猛发展,OpenCV(Open source Computer Vision library)成为了广大开发者和研究者们不可或缺的利器之一。OpenCV 是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法,涵盖了从简单的图像处理操作到复杂的目标检测和跟踪等领域。
本文旨在帮助读者系统地学习 Opencv Python,从基础的图像输入输出开始,逐步深入到图像处理的各个领域,涵盖 GUI 编程、图像操作、二值化等多个重要主题。无论您是初学者还是有经验的开发者,本文都将提供清晰的指导和实用的示例,帮助您快速掌握 Opencv Python 的应用技巧。
-
github
-
安装
pip install opencv-python- 1
一、输入输出
1.1 图片读取显示保存
import sys import cv2 as cv def main(): img = cv.imread("alice_color.png") if img is None: sys.exit("Could not read the image.") cv.imshow("Display window", img) k = cv.waitKey(0) if k == ord("q"): roi = img[100: 200, 100:200] roi[:] = 0 cv.imwrite("alice_color_change.png", img) if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

1.2 视频读取保存
import cv2 as cv def main(): # 定义解码器 MJPG (.mp4), DIVX (.avi), X264 (.mkv) fourcc = cv.VideoWriter_fourcc(*'MJPG') # 设置 帧率 分辨率 # 注意, 这里设置分辨率需要与你摄像头或者读取的文件的分辨率保持一致, 否则不会写入数据 out = cv.VideoWriter('output.avi', fourcc, 20.0, (960, 506)) # cap = cv.VideoCapture(0) cap = cv.VideoCapture('test.mp4') if not cap.isOpened(): print("Cannot open camera") exit() while True: # Capture frame-by-frame ret, frame = cap.read() # if frame is read correctly ret is True if not ret: print("Can't receive frame (stream end?). Exiting ...") break # Our operations on the frame come here cv.waitKey(1) cv.imshow('frame', frame) # 翻转图像 frame = cv.flip(frame, 0) out.write(frame) # When everything done, release the capture cap.release() out.release() cv.destroyAllWindows() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38

1.3 文件读取保存
opencv 还支持持久化,将数据以xml,yml,json文件保存,并读取
import cv2 as cv import numpy as np def main(): write() read() def write(): # 创建FileStorage对象并打开一个文件用于写入 fs = cv.FileStorage('test.xml', cv.FILE_STORAGE_WRITE) # 写入一些数据 fs.write('First_Integer', 123) fs.write('First_String', 'Hello') # 写入一个矩阵 mat = np.eye(2, 3, dtype=np.uint8) fs.write('Matrix', mat) # 写入一个复杂的数据结构 fs.write('List', (1, 2, 3)) # 关闭FileStorage对象 fs.release() def read(): fs = cv.FileStorage('test.xml', cv.FILE_STORAGE_READ) # 读取数据 if not fs.isOpened(): print("Error: Unable to open file.") exit() First_Integer = fs.getNode('First_Integer').real() First_String = fs.getNode('First_String').string() Matrix = fs.getNode('Matrix').mat() List = fs.getNode('List').mat() print(First_Integer) print(First_String) print(Matrix) print(List) fs.release() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
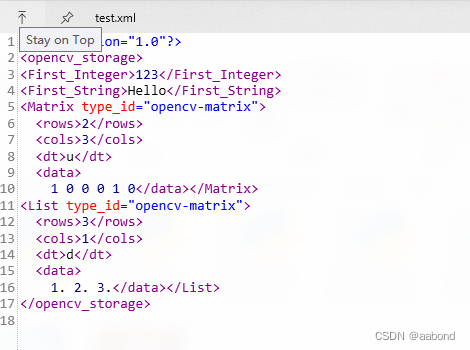
二、GUI
2.1 窗口
import cv2 as cv import numpy as np def main(): # 名字为first 和second 两个窗口 # cv.namedWindow(窗口名称, 窗口属性) """ WindowFlags: WINDOW_NORMAL : user can resize the window WINDOW_AUTOSIZE : user cannot resize the window, the size is constrainted by the image displayed WINDOW_OPENGL : window with opengl support WINDOW_FULLSCREEN : change the window to fullscreen WINDOW_FREERATIO : the image expends as much as it can 自由比例 WINDOW_KEEPRATIO : 保持比例 WINDOW_GUI_EXPANDED : status bar and tool bar WINDOW_GUI_NORMAL : old fashious way """ cv.namedWindow('first', cv.WINDOW_AUTOSIZE) cv.namedWindow('second', cv.WINDOW_NORMAL) img = cv.imread('alice_color.png') img_changed = cv.imread('alice_color_change.png') cv.imshow('first', img) # 更改窗口尺寸 cv.resizeWindow('second', 640, 640) cv.imshow('second', img_changed) # 等待键盘输入,参数为等待时长,单位: ms。0为无限等待 k = cv.waitKey(0) if k == ord("q"): cv.destroyAllWindows() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
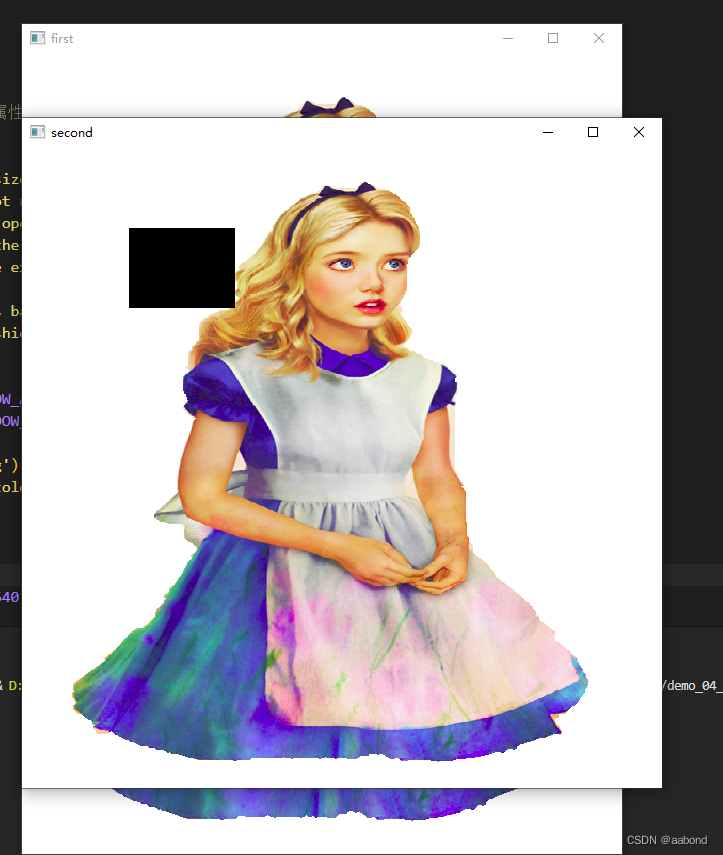
2.2 轨迹条
import cv2 as cv import numpy as np def callback(index): pass def main(): winname = "trackbar" cv.namedWindow(winname, cv.WINDOW_NORMAL) cv.resizeWindow(winname, 640, 480) # 创建trackbar控件 # argument: # trackbarname, winname, value, count, callback, userdata cv.createTrackbar('R', winname, 0, 255, callback) cv.createTrackbar('G', winname, 0, 255, callback) cv.createTrackbar('B', winname, 0, 255, callback) # 创建初始图像 img = np.zeros(shape=(640, 480, 3), dtype=np.uint8) # 显示图像: while True: # 读取控件值: r = cv.getTrackbarPos('R', winname) g = cv.getTrackbarPos('G', winname) b = cv.getTrackbarPos('B', winname) # b,g,r这个通道数, 在opencv中, rgb通道数是反过来的 img[:] = [b, g, r] # 显示图像 cv.imshow(winname, img) # 等待键盘 if cv.waitKey(1) & 0xFF == ord('q'): break cv.destroyAllWindows() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43

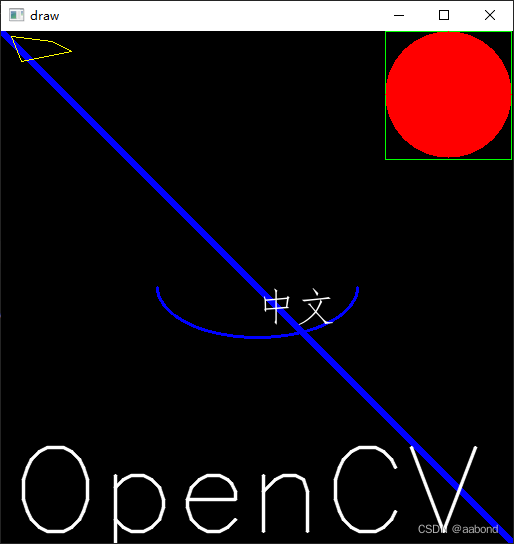
2.3 画图
import cv2 as cv import numpy as np from PIL import Image, ImageDraw, ImageFont def paint_chinese_opencv(im, textstr, position, fontsize, color): # opencv输出中文 img_PIL = Image.fromarray(cv.cvtColor( im, cv.COLOR_BGR2RGB)) # 图像从OpenCV格式转换成PIL格式 font = ImageFont.truetype( r'C:\Windows\Fonts\simfang.ttf', fontsize, encoding="utf-8") # color = (255,0,0) # 字体颜色 # position = (100,100)# 文字输出位置 draw = ImageDraw.Draw(img_PIL) draw.text( position, textstr, font=font, fill=color) img = cv.cvtColor(np.asarray(img_PIL), cv.COLOR_RGB2BGR) # PIL图片转OpenCV 图片 return img def main(): img = np.zeros((512, 512, 3), np.uint8) # 划线 cv.line(img, (0, 0), (511, 511), # 两点 color=(255, 0, 0), # 颜色 thickness=5, # 线宽,默认为1 lineType=4) # 线类型 有 cv.FILLED, cv.LINE_4, cv.LINE_8, cv.LINE_AA 这4种, 默认为LINE_8, # 画矩形,左上角和右下角,其余同上 cv.rectangle(img, pt1=(384, 0), pt2=(510, 128), color=(0, 255, 0)) # 画圆,圆心,半径 cv.circle(img, center=(447, 63), radius=63, color=(0, 0, 255), thickness=cv.FILLED) # 画椭圆 cv.ellipse(img, center=(256, 256), # 中心坐标 axes=(100, 50), # 长轴,短轴 一半 angle=0, # 椭圆沿逆时针方向的旋转角度 startAngle=0, endAngle=180, # 开始角和结束角表示从主轴向顺时针方向测量的椭圆弧的开始和结束 color=255, # 颜色 thickness=2, lineType=cv.FILLED) pts = np.array([[10, 5], [20, 30], [70, 20], [50, 10]], np.int32) pts = pts.reshape((-1, 1, 2)) cv.polylines(img, [pts], isClosed=True, # 是否闭合 color=(0, 255, 255)) cv.putText(img, text='OpenCV', org=(10, 500), # 左下角 fontFace=cv.FONT_HERSHEY_SIMPLEX, # 字体 fontScale=4, # 字体缩放 color=(255, 255, 255), thickness=2, lineType=cv.LINE_AA) img = paint_chinese_opencv(img, '中文', (255, 255), 40, (255, 255, 255)) cv.imshow('draw', img) k = cv.waitKey(0) if k == ord("q"): cv.destroyAllWindows() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
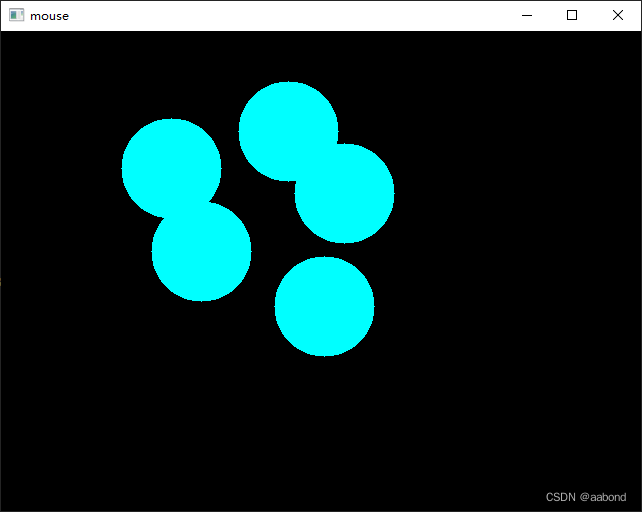
2.4 鼠标回调
import cv2 as cv import numpy as np # 生成全黑图像 img = np.zeros((480, 640, 3), np.uint8) # 定义鼠标回调函数画圆 def draw_circle(event,x,y,flags,param): # 左键双击 if event == cv.EVENT_LBUTTONDBLCLK: cv.circle(img,(x,y),50,(255,255,0),-1) def main(): WINDOW_NAME = "mouse" # 创建桌面 cv.namedWindow(WINDOW_NAME, cv.WINDOW_NORMAL) cv.resizeWindow(WINDOW_NAME, 640, 480) # 设置鼠标回调, 绑定窗口 cv.setMouseCallback(WINDOW_NAME, draw_circle, "123") # 显示图像 while True: cv.imshow(WINDOW_NAME, img) if cv.waitKey(20) & 0xFF == ord('q'): break cv.destroyAllWindows() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
三、图像入门操作
3.1 颜色空间转化
import cv2 as cv import numpy as np def callback(index): pass def main(): winname = "color" trackbarname = "colorspace" cv.namedWindow(winname, flags=cv.WINDOW_NORMAL) cv.resizeWindow(winname, 600, 800) color_space_list = [cv.COLOR_BGR2RGB, cv.COLOR_BGR2BGRA, cv.COLOR_BGR2GRAY, cv.COLOR_BGR2HSV, cv.COLOR_BGR2YUV] # 格式转换队列 # 创建Trackbar cv.createTrackbar(trackbarname, winname, 0, len( color_space_list)-1, callback) # 读取图片 img = cv.imread("alice_color.png") # 显示图像 while True: color_space_index = cv.getTrackbarPos(trackbarname, winname) # 颜色空间转换 -> cvtColor(src, colorSpace)颜色转换 cvt_img = cv.cvtColor(img, color_space_list[color_space_index]) cv.imshow(winname, cvt_img) if cv.waitKey(1) & 0xFF == ord('q'): break cv.destroyAllWindows() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40

3.2 通道分离合并
import cv2 as cv import numpy as np from matplotlib import pyplot as plt def main(): img = cv.imread("lena.png") # 分割出来的b,g,r每一个都是一个单个矩阵. # b, g, r = cv.split(img) # 直接操作可以用索引 b, g, r = img[:, :, 0], img[:, :, 1], img[:, :, 2] zeros = np.zeros(img.shape[:2], dtype='uint8') title = ['ORIGINAL', 'B', 'G', 'R'] # 对应的图像 imgs = [img, cv.merge([b, zeros, zeros]), cv.merge( [zeros, g, zeros]), cv.merge([zeros, zeros, r])] for i in range(len(imgs)): plt.subplot(2, 2, i + 1) plt.imshow(cv.cvtColor(imgs[i], cv.COLOR_BGR2RGB)) plt.title(title[i]) plt.axis('off') plt.show() cv.waitKey(0) cv.destroyAllWindows() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35

3.3 添加边框
import cv2 as cv import numpy as np from matplotlib import pyplot as plt def main(): BLUE = [255, 0, 0] img1 = cv.imread('lena.png') assert img1 is not None, "file could not be read, check with os.path.exists()" width = 20 # cv.BORDER_REPLICATE 边界颜色被复制 eg: aaaaaa|abcdefgh|hhhhhhh # cv.BORDER_REFLECT 边界颜色被镜像 eg: fedcba|abcdefgh|hgfedcb # cv.BORDER_REFLECT_101 和上面类似,有点不同,这是默认值 eg: gfedcb|abcdefgh|gfedcba # cv.BORDER_WRAP eg: cdefgh|abcdefgh|abcdefg # cv.BORDER_CONSTANT 给定边界颜色 replicate = cv.copyMakeBorder( img1, width, width, width, width, cv.BORDER_REPLICATE) reflect = cv.copyMakeBorder( img1, width, width, width, width, cv.BORDER_REFLECT) reflect101 = cv.copyMakeBorder( img1, width, width, width, width, cv.BORDER_REFLECT_101) wrap = cv.copyMakeBorder(img1, width, width, width, width, cv.BORDER_WRAP) constant = cv.copyMakeBorder( img1, width, width, width, width, cv.BORDER_CONSTANT, value=BLUE) title = ['ORIGINAL', 'REPLICATE', 'REFLECT', 'REFLECT_101', 'WAP', 'CONSTANT'] # 对应的图像 imgs = [img1, replicate, reflect, reflect101, wrap, constant] for i in range(len(imgs)): plt.subplot(2, 3, i + 1) plt.imshow(cv.cvtColor(imgs[i], cv.COLOR_BGR2RGB)) plt.title(title[i]) plt.axis('off') plt.show() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44

3.4 算数操作
import cv2 as cv import numpy as np from matplotlib import pyplot as plt def main(): img = cv.imread('lena.png') img_girl = cv.imread('girl.png') assert img & img_girl is not None, "file could not be read, check with os.path.exists()" pixel = img[255, 255] print(pixel) # [ 78 70 181] print(pixel.dtype) # uint8 print(img.item(255, 255, 2)) # 181 x = np.uint8([250]) y = np.uint8([10]) print(cv.add(x, y, dtype=cv.CV_8UC3)) # [[255],[0],[0],[0]] print(x + y) # [6] # 两张图片按照权重叠加,需要宽高一样大 img_new = cv.addWeighted(img_girl, 0.7, img, 0.3, 0) # 对图片进行位运算 取反、与、或、异或 img_bit_not = cv.bitwise_not(img) img_bit_and = cv.bitwise_and(img, img_girl) img_bit_or = cv.bitwise_or(img, img_girl) img_bit_xor = cv.bitwise_xor(img, img_girl) title = ['Lena', 'Girl', 'addWeight', 'Not', 'And', 'Or', 'Xor'] # 对应的图像 imgs = [img, img_girl, img_new, img_bit_not, img_bit_and, img_bit_or, img_bit_xor] for i in range(len(imgs)): plt.subplot(3, 3, i + 1) plt.imshow(cv.cvtColor(imgs[i], cv.COLOR_BGR2RGB)) plt.title(title[i]) plt.axis('off') roi = img_girl[280:340, 330:390] roi[:] = 255 plt.subplot(338), plt.imshow(cv.cvtColor(img_girl, cv.COLOR_BGR2RGB)), plt.title( 'Roi'), plt.axis('off') plt.show() cv.waitKey(0) cv.destroyAllWindows() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57

四、二值化
4.1 普通
import cv2 as cv import numpy as np from matplotlib import pyplot as plt max_value = 255 max_type = 4 max_binary_value = 255 trackbar_type = 'Type' trackbar_value = 'Value' window_name = 'Threshold Demo' def callback(val): # 0: Binary 给定threshold_value,大于它为255,小于为0 # 1: Binary Inverted 给定threshold_value,大于它为0,小于为255 # 2: Threshold Truncated 给定threshold_value,大于它为threshold_value,小于则不变 # 3: Threshold to Zero 给定threshold_value,大于它不变,小于则为0 # 4: Threshold to Zero Inverted 给定threshold_value,大于它为0,小于则不变 threshold_type = cv.getTrackbarPos(trackbar_type, window_name) threshold_value = cv.getTrackbarPos(trackbar_value, window_name) _, dst = cv.threshold(img_gray, threshold_value, max_binary_value, threshold_type) cv.imshow(window_name, dst) def main(): global img_gray img_gray = cv.imread('lena.png', cv.IMREAD_GRAYSCALE) cv.namedWindow(window_name) cv.resizeWindow(window_name, 512, 512) cv.createTrackbar(trackbar_type, window_name, 0, max_type, callback) cv.createTrackbar(trackbar_value, window_name, 0, max_value, callback) cv.waitKey(0) cv.destroyAllWindows() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
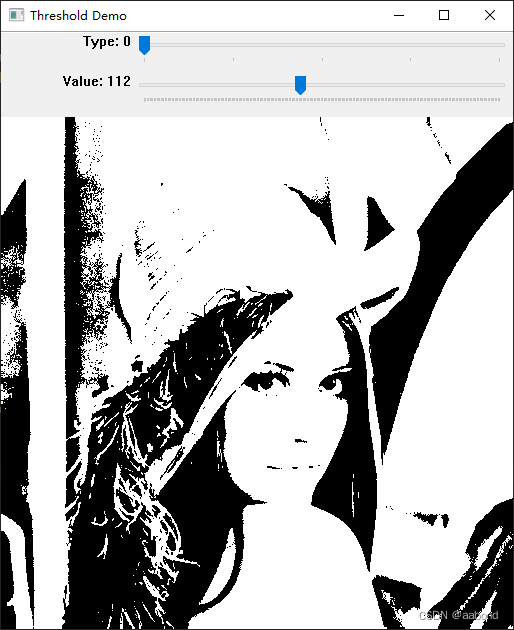
4.2 自适应
import cv2 as cv import numpy as np from matplotlib import pyplot as plt def main(): img = cv.imread('sudoku.png', cv.IMREAD_GRAYSCALE) assert img is not None, "file could not be read, check with os.path.exists()" img = cv.medianBlur(img, 5) ret, th1 = cv.threshold(img, 127, 255, cv.THRESH_BINARY) # 每个像素位置处的二值化阈值不是固定不变的,而是由其周围邻域像素的分布来决定的 # THRESH_BINARY ===> dst(x, y) = maxValue if src(x, y) > T(x, y) else 0 # THRESH_BINARY_INV ===> dst(x, y) = 0 if src(x, y) > T(x, y) else maxValue # maxValue 非零值 # adaptiveMethod 自适应算法T # 1. cv.ADAPTIVE_THRESH_MEAN_C 计算邻域的均值 再减C # 2. cv.ADAPTIVE_THRESH_GAUSSIAN_C 计算邻域的高斯加权和,再减C # thresholdType 必须是 cv.THRESH_BINARY 或 cv.THRESH_BINARY_INV # blockSize 邻域大小 blockSize * blockSize, 一般用3,5,7等等 # C 要减去的值 th2 = cv.adaptiveThreshold(img, maxValue=255, adaptiveMethod=cv.ADAPTIVE_THRESH_MEAN_C, thresholdType=cv.THRESH_BINARY, blockSize=11, C=2) th3 = cv.adaptiveThreshold(img, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 11, 2) titles = ['Original Image', 'Global Thresholding (v = 127)', 'Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding'] images = [img, th1, th2, th3] for i in range(4): plt.subplot(2, 2, i+1), plt.imshow(images[i], 'gray') plt.title(titles[i]) plt.xticks([]), plt.yticks([]) plt.show() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41

4.3 Otsu
在使用 threshold 方法阈值设置中,我们可以使用任意选择的值作为阈值。相比之下,Otsu 二值化不需要手动选择一个值,可以直接设为0
考虑一个只有两个不同图像值的图像(双峰图像),其中直方图将只由两个峰组成。一个很好的阈值应该是在这两个值的中间值。
Otsu 从图像直方图中确定一个最优的全局阈值。该算法找到最优阈值,并作为第一个输出返回。
import cv2 as cv import numpy as np from matplotlib import pyplot as plt def main(): img = cv.imread('southeast.jpg', cv.IMREAD_GRAYSCALE) assert img is not None, "file could not be read, check with os.path.exists()" # global thresholding ret1, th1 = cv.threshold(img, 127, 255, cv.THRESH_BINARY) # Otsu's thresholding ret2, th2 = cv.threshold(img, 0, 255, cv.THRESH_BINARY+cv.THRESH_OTSU) # Otsu's thresholding after Gaussian filtering blur = cv.GaussianBlur(img, (7, 7), 0) ret3, th3 = cv.threshold(blur, 0, 255, cv.THRESH_BINARY+cv.THRESH_OTSU) # plot all the images and their histograms images = [img, 0, th1, img, 0, th2, blur, 0, th3] titles = ['Original Noisy Image', 'Histogram', 'Global Thresholding (v=127)', 'Original Noisy Image', 'Histogram', "Otsu's Thresholding", 'Gaussian filtered Image', 'Histogram', "Otsu's Thresholding"] for i in range(3): plt.subplot(3, 3, i*3+1), plt.imshow(images[i*3], 'gray') plt.title(titles[i*3]), plt.xticks([]), plt.yticks([]) plt.subplot(3, 3, i*3+2), plt.hist(images[i*3].ravel(), 256) plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([]) plt.subplot(3, 3, i*3+3), plt.imshow(images[i*3+2], 'gray') plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([]) plt.show() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40

参考
-
-
相关阅读:
Flink CDC-2.3版本概述
【灵魂拷问:读取 excel 测试数据真的慢吗?】
[排序]leetcode1636:按照频率将数组升序排序(easy)
小A对我说,他现在快想钱想疯了…
mysql 索引选取规则
蚂蚁发布金融大模型:两大应用产品支小宝2.0、支小助将在完成备案后上线
SystemVerilog-逻辑运算符
项目知识点总结-过滤器-MD5注册-邮箱登录
C#演示单例模式
Windows Server 2012 R2系统服务器远程桌面服务多用户登录配置分享
- 原文地址:https://blog.csdn.net/qq_23091073/article/details/138067487
