-
ES中文检索须知:分词器与中文分词器
ElasticSearch (es)的核心功能即为数据检索,常被用来构建内部搜索引擎或者实现大规模数据在推荐召回流程中的粗排过程。
ES分词
分词即为将
doc通过Analyzer切分成一个一个Term(关键字),es分词在索引构建和数据检索时均有体现:- 构建倒排索引时每一个term都指向包含这个term的多个doc。
- 搜索时需要通过分词将查询语句切分成一个一个term进行检索。
简单来说,ES的数据检索原理包含分词、基于分词结果计算相似度得分、按得分从高到低排序返回指定长度下的排序结果三个主要步骤,本文主要关注中文场景下的分词过程。
ES内置分词器
ES官方内置了一些常用的分词器(
Analyzer,分词器在NLP中称为tokenzier,es使用analyzer的原因是除了分词之外后续还会进行一些文本分析的动作):the quick brown-foxes jumped over the lazy dog’s bone. 该英语句子是一个经典的自然语言处理例句,它是全字母句,包含了全部26个字母。
分词器 作用 分词对象 结果示例 Standard Analyzer 标准分词器,也是默认的分词器,基于Unicode文本分割算法。默认分词器适用于英语,并且对大多数语言都有效 The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog’s, bone ] Simple Analyzer 简单分词器,基于非字母字符进行分词,单词会转为小写字母,非字母字符如数字、空格、连字符和撇号将被丢弃 The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. [ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] Whitespace Analyzer 空格分词器,按空格进行切分 The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. [ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog’s, bone. ] Stop Analyzer 在简单分词器的基础上增加了停用词的功能 The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. [ quick, brown, foxes, jumped, over, lazy, dog, s, bone ] Keyword Analyzer 关键词分词器,将整个输入句子认为是关键字直接返回,不分词 The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. [The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.] Pattern Analyzer patter分词器,patter指的是正则的pattern,利用正则表达式对文本进行切分,支持停用词 The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] Language Analyer 针对特定语言的分析器 - - Fingerprint Analyzer 指纹分词器,是一种专业分词器,可通过创建指纹来进行重复检测的 - - Custom Analyzer 如果以上没有符合需求的分词器,es也允许通过添加插件的方式添加自定义分词器 - - 注:停用词,英文称为Stop Words,是在信息检索和自然语言处理过程中,为了节省存储空间和提高搜索效率,系统会自动过滤掉某些出现频率高但又不具有实际意义的字或词。这些被过滤的词语通常包括语气词、连词、介词等,例如汉语中的“的”、“以及”、“甚至”、“吧”,以及英语中的“the”、“a”、“also”等。
在中文场景下,有一个踩坑点是,默认的
Standard Analyzer会按照一个汉字一个汉字切分的方式来分词,这样构建的索引缺乏语义信息,导致检索效果不佳,因而中文场景下需要使用专门的分词器。
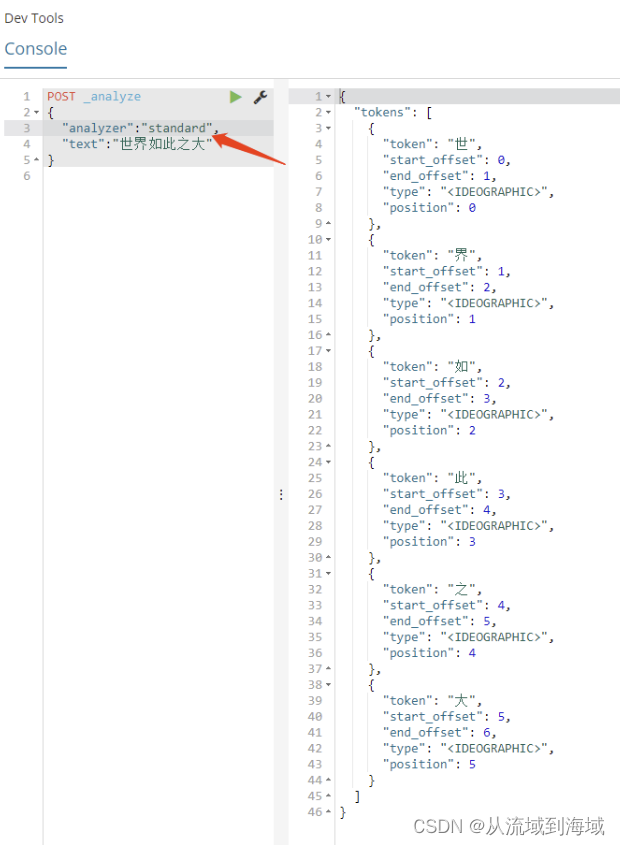
中文分词器
常用的中文分词器有两个比较主流的:
ik analyzer和smartcn(Smart Chinese Analyzer)ik analyzer
ik analyzer是一个基于开源项目IK Analysis进行开发的第三方的中文分词器。IK Analyzer提供了细粒度的中文分词能力,支持词库扩展、自定义词典、停用词过滤、同义词扩展等功能,可以根据具体需求进行匹配和定制。适用于更精确的分词和分析需求。ik analyzer支持两种分词方法,可以在构建索引时指定:
- ik_max_word:将需要分词的文本做最小粒度的拆分,尽可能分出更多的词
- ik_smart_word:将需要分词的文本做最大粒度的拆分,尽可能分出更少的词
git上下载插件,存到es插件目录,重启es服务即可使用:
wget https://github.com/medcl/elasticsearch-analysis-ik/releases- 1
smartcn
smartcn是es内置的中文分词器,使用机器学习算法进行分词,同时适用于简体中文和繁体中文,具有较高的分词准确率和召回率,适用于大多数中文文本检索场景。因为是内置的,所以优点是无需额外配置即可使用。参考文献
-
相关阅读:
osg 操作 NodePathList 节点操作
Nginx 单个端口代理Minio
高级深入--day39
Docker 在 M1 Mac arm64架构上构建 amd64镜像。
React中Toast 库推荐
Docker从入门到上天系列第一篇:Docker简介以及Docker存在的定位和意义
Luckysheet:一个纯前端的excel在线表格
Linux系统MySQL配置主从分离
webpack和vite的区别
Bootstrap Blazor 模板使用(一)Layout 组件
- 原文地址:https://blog.csdn.net/Solo95/article/details/138015001