-
<网络> HTTP
目录
前言:
在序列化与反序列化文章中,我们了解了 协议 的制定与使用流程,不过太过于简陋了,真正的 协议 会复杂得多,也强大得多,比如在网络中使用最为广泛的
HTTP/HTTPS超文本传输协议。HTTP(Hypertext Transfer Protocol,超文本传输协议)是一种应用层的协议,用于在网络中传输超文本(如网页)。HTTP是互联网上应用最为广泛的一种网络协议,所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。一、再谈协议
但凡是使用浏览器进行互联网冲浪,那必然离不开这个 协议,HTTP/HTTPS 不仅支持传输文本,还支持传输图片、音频、视频等 资源

客户端/浏览器上传资源的大小称为 上行流量,获取资源的大小称为 下行流量,网速则是单位时间内所能传输的流量大小,所以网速越快,上传/下载的体验就会越好。
可以在浏览器中根据
CSDN服务器的IP和Port,以及资源路径,基于HTTPS协议,获取我们所需要的资源,例如:https://blog.csdn.net/weixin_61522065?type=blog 表示我的个人主页。
(一)认识URL
诸如上面的网址称为
URL->Uniform Resource Locator统一资源定位符,也就我们熟知的 超链接/链接,URL中包含了 协议、IP地址、端口号、资源路径、参数 等信息:
注:登录信息现在已经不使用了,因为不够安全

IP地址在哪呢?
blog.csdn.net叫做 域名,可以通过 域名 解析为对应的IP地址。- 使用 域名 解析工具解析后,下面就是 服务器的IP地址:

那端口号呢?
- 为了给用户提供良好的体验,一个成熟的服务是不会随意改变端口号的
- 只要是使用了
HTTP协议,默认使用的都是80端口号,而HTTPS则是443 - 如果我们没指明端口号,浏览器就会使用 协议 的默认端口号
现在大多数网站使用的都是
HTTPS协议,更加安全,默认端口为443至于资源路径,这是
Linux中的文件路径,比如下面这个URLhttps://blog.csdn.net/csdnnews/article/details/137972430?spm=1000.2115.3001.5926
其资源路径为
/article/details/137972430,与Linux中的路径规则一致,这里的路径起源于web根目录(不一定是Linux中的根目录):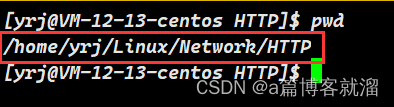
在
Linux机器中存放资源(服务器),客户端访问时只需要知晓目标资源的存储路径,就能访问了,除了上面这些信息外,URL中还存在特殊的 分隔符:://用于分隔 协议 和 IP地址:用于分隔 IP地址 和 端口号/表示路径,同时第一个/可以分隔 端口号 和 资源路径?则是用来分隔 资源路径 和 参数
这些特殊 分隔符 很重要,这是属于 协议 的一部分,就像我们之前定义的 两正整数运算协议 中的 一样,如果没有 分隔符,那就无法获取
URL中的信息。如果 资源路径 或者后面的 参数 中不小心携带了 某些分隔符 会怎么样?
- 最好不要出现,即使出现,服务器在传输之前也会将其进行特殊化处理,比如将 (空格)解释为
%20。
至于 参数 是一组 KV 结构,浏览器可以从 参数 中获取到重要数据。
(二)Encode 和 Decode
Encode就是将诸如 分隔符、中文、其他非英语语言 等转换成计算机能认识的符号,比如在浏览器搜索框中输入
//?::请求相关资源,实际URL中的 参数 为%2F%2F%3F%3A%3A- 转码规则:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
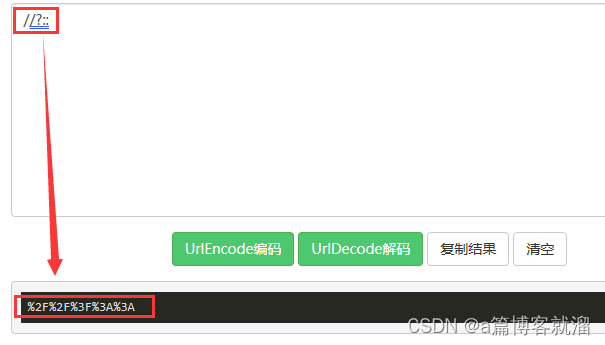
即便输入的是 中文,也能进行转码

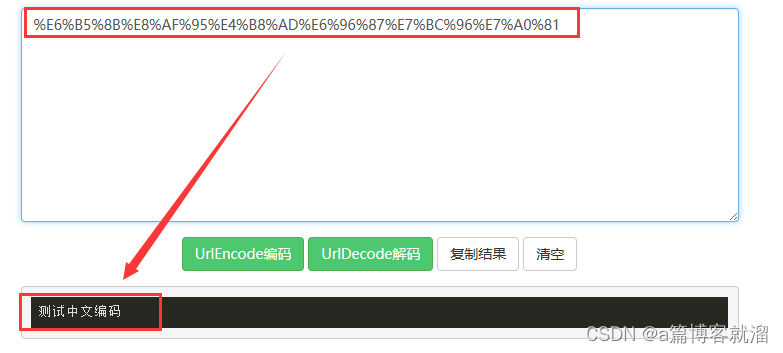
decode 通常指的是将某种编码格式的数据转换(解码)为另一种格式,尤其是将编码后的二进制数据或特定格式的文本转换为人类可读的形式:
所以为什么有的
URL很长?就是因为在转换后字符数会增多。转码这个工作也需要 服务器 完成,基于之前的
ServiceIO()函数,相对完整的请求处理流程如下- void ServiceIO(const int& sock, const std::string ip, const uint16_t& port)
- {
- while(true)
- {
- // 1.读取数据
- // 2.移除报头
- // 3.反序列化
- // 4.Decode 解码
- // 5.业务处理
- // 6.Encode 编码
- // 7.序列化
- // 8.添加报头
- // 9.发送数据
- }
- }
二、HTTP 协议
(一)协议格式
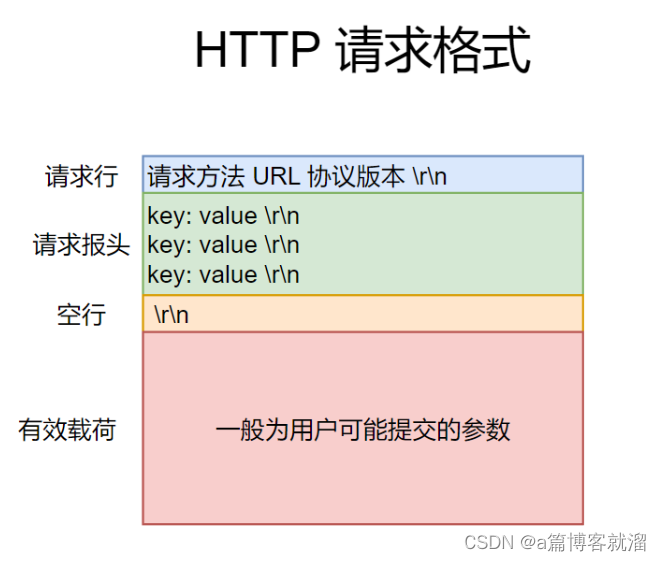
HTTP协议由Request请求 和Response响应 两部分组成从宏观角度来看,
HTTP请求 分为这几部分:- 请求行:包括请求方法(
GET / POST)、URL、协议版本(http/1.0http/1.1http/2.0) - 请求报头:表示请求的详细细节,由多组
k: v结构所组成 - 空行:区分报头和有效载荷
- 有效载荷(可以没有)
在
HTTP协议中是使用\r\n作为 分隔符 的如何分离 协议报头 与 有效载荷 ?
- 以空行
\r\n进行分隔,空行之前为协议报头,空行之后为有效载荷。
如何进行 序列化与反序列?
- 序列化:使用
\r\n进行拼接 - 反序列化:根据
\r\n进行读取
至于
HTTP响应 分为这几部分:- 状态行:协议版本、状态码、状态码描述
- 响应报头:表示响应的详细细节,由多组
k: v结构所组成 - 空行:区分报头和有效载荷
- 有效载荷,即客户端请求的资源
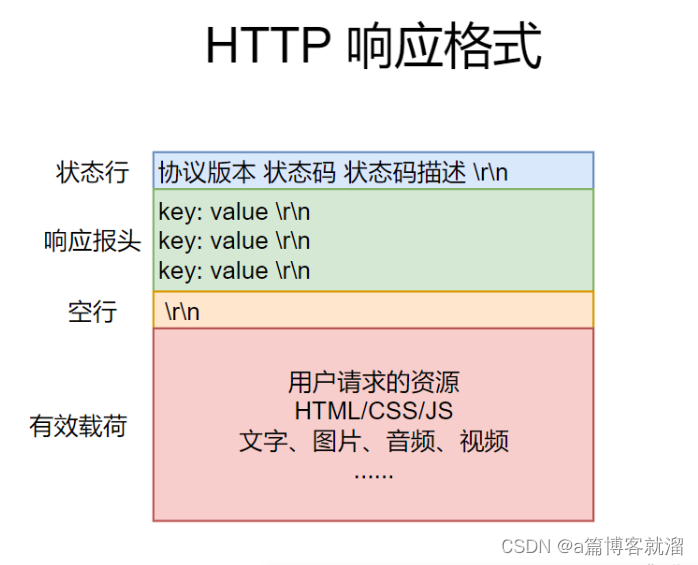
HTTP响应 中关于 协议报头与有效载荷的分离、序列化与反序列化 等问题和HTTP请求 中的处理方式一致。如何理解协议版本?
- 客户端和服务器可能使用了不同的
HTTP版本 - 服务器可以根据协议版本的匹配情况进行功能响应
什么是状态码?
- 状态码类似于
C/C++中的错误码,可以反应请求的情况 - 常见的状态码:
404,状态码的描述为No Found
(二)见一见请求
将浏览器视为客户端,编写服务器,浏览器通过
IP+Port访问服务器时,就会发出HTTP请求,服务器在接收后可以进行打印,也就可以看到HTTP请求了首先完成
HTTP服务器的编写所需文件:
Err.hpp错误码文件Log.hpp日志输出Sock.hpp套接字接口封装HttpServer.hpp服务器头文件HttpServer.cc服务器源文件Makefile自动化编译脚本
Err.hpp错误码文件- #pragma once
- enum
- {
- USAGE_ERR = 1,
- SOCKET_ERR,
- BIND_ERR,
- LISTEN_ERR,
- CONNECT_ERR,
- FORK_ERR,
- SETSID_ERR,
- CHDIR_ERR,
- OPEN_ERR,
- READ_ERR
- };
Log.hpp日志输出- #pragma once
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- using namespace std;
- // 日志等级
- enum
- {
- Debug = 0,
- Info,
- Warning,
- Error,
- Fatal
- };
- static const string file_name = "Log/TCPLogMessage.log"; // 指定存放日志文件目录
- string getLevel(int level)
- {
- vector
vs = {" " , "" , "" , - "
" , "" , "" }; - // 避免非法情况
- if(level < 0 || level >= vs.size()-1)
- return vs[vs.size()-1];
- return vs[level];
- }
- // 获取当前时间
- string getTime()
- {
- time_t t = time(nullptr); // 获取时间戳
- struct tm *st = localtime(&t); // 获取时间相关的结构体
- char buff[128];
- snprintf(buff, sizeof(buff), "%d-%d-%d %d:%d:%d",
- st->tm_year+1900, st->tm_mon+1, st->tm_mday,
- st->tm_hour, st->tm_min, st->tm_sec);
- return buff;
- }
- void logMessage(int level, const char *format, ...)
- {
- // 日志格式:<日志等级> [时间] [PID] {消息体}
- string logmsg = getLevel(level); // 获取日志等级
- logmsg += " " + getTime(); // 获取时间
- logmsg += " [" + to_string(getpid()) + "]"; // 获取进程PID
- // 截获主体消息
- char msgbuff[1024];
- va_list p;
- va_start(p, format); // 将p定位至format的起始位置
- vsnprintf(msgbuff, sizeof(msgbuff), format, p); // 自动根据格式进行读取
- va_end(p);
- logmsg += " {" + string(msgbuff) + "}"; // 获取主体消息
- printf("%s\n", logmsg.c_str());
- // 写入文件中
- // FILE *fp = fopen(file_name.c_str(), "a"); // 以追加的方式写入
- // if(fp == nullptr) return;
- // fprintf(fp, "%s\n", logmsg.c_str());
- // fflush(fp); //手动刷新一下
- // fclose(fp);
- // fp = nullptr;
- }
Sock.hpp套接字接口封装- #pragma once
- #include "Log.hpp"
- #include "Err.hpp"
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- const static int default_sock = -1;
- const static int default_backlog = 32;
- class Sock
- {
- public:
- Sock()
- : sock_(default_sock)
- {}
- // 创建套接字
- void Socket()
- {
- sock_ = socket(AF_INET, SOCK_STREAM, 0);
- if(sock_ < 0)
- {
- logMessage(Fatal, "socket error, code: %d, errstring: %s", errno, strerror(errno));
- exit(SOCKET_ERR);
- }
- logMessage(Debug, "Creater Socket Success");
- }
- // 绑定IP地址和端口号
- void Bind(const uint16_t &port)
- {
- struct sockaddr_in local;
- memset(&local, 0, sizeof(local));
- local.sin_family = AF_INET;
- local.sin_port = htons(port);
- local.sin_addr.s_addr = INADDR_ANY;
- if(bind(sock_, (struct sockaddr*)&local, sizeof(local)) < 0)
- {
- logMessage(Fatal, "bind error, code: %d, errstring: %s", errno, strerror(errno));
- exit(BIND_ERR);
- }
- }
- // 监听
- void Listen()
- {
- if(listen(sock_, default_backlog) < 0)
- {
- logMessage(Fatal, "listen error, code: %d, errstring: %s", errno, strerror(errno));
- exit(LISTEN_ERR);
- }
- }
- // 处理连接请求
- int Accept(std::string *clientip, uint16_t *clientport)
- {
- struct sockaddr_in client;
- socklen_t len = sizeof(client);
- int sock = accept(sock_, (struct sockaddr*)&client, &len);
- if(sock < 0)
- {
- logMessage(Warning, "accept error, code: %d, errstring: %s", errno, strerror(errno));
- }
- else
- {
- *clientip = inet_ntoa(client.sin_addr);
- *clientport = ntohs(client.sin_port);
- logMessage(Debug, "accept success, [acceptSock: %d, clientip: %s , clientport: %d]", sock, clientip->c_str(), *clientport);
- }
- return sock;
- }
- // 连接
- int Connect(const std::string &serverip, const uint16_t &serverport)
- {
- struct sockaddr_in server;
- memset(&server, 0, sizeof(server));
- server.sin_family = AF_INET;
- server.sin_port = htons(serverport);
- server.sin_addr.s_addr = inet_addr(serverip.c_str());
- return connect(sock_, (struct sockaddr*)&server, sizeof(server));
- }
- // 获取sock
- int GetSock()
- {
- return sock_;
- }
- // 关闭sock
- void Close()
- {
- if(sock_ != default_sock) close(sock_);
- logMessage(Debug, "close sock success");
- }
- ~Sock()
- {}
- private:
- int sock_; // 既可以是监听套接字,也可以是连接成功后返回的套接字
- };
在实现
HTTP服务器时,我们可以假设服务器一次就将 请求 全部读完了HttpServer.hpp服务器头文件- #pragma once
- #include "Sock.hpp"
- #include
- #include
- #include
- #include
- class HttpServer;
- class ThreadData
- {
- public:
- ThreadData(int sock, const uint16_t port, const string &ip, HttpServer *httpsvr)
- :sock_(sock), port_(port), ip_(ip), httpsvr_(httpsvr)
- {}
- ~ThreadData()
- {
- close(sock_);
- }
- public:
- int sock_;
- uint16_t port_;
- string ip_;
- HttpServer *httpsvr_;
- };
- class HttpServer
- {
- const static uint16_t default_port = 8080;
- using func_t = function<string(const string &)>;
- public:
- HttpServer(func_t func, uint16_t port = default_port)
- : func_(func), port_(port)
- {}
- void Init()
- {
- listensock_.Socket();
- listensock_.Bind(port_);
- listensock_.Listen();
- logMessage(Debug, "Init server success");
- }
- void Start()
- {
- while(true)
- {
- uint16_t clientport;
- string clientip;
- int clientsock = listensock_.Accept(&clientip, &clientport);
- // 接受客户端请求失败,重新连接
- if(clientport < 0) continue;
- ThreadData *td = new ThreadData(clientsock, clientport, clientip, this);
- pthread_t tid;
- pthread_create(&tid, nullptr, threadRoutine, td);
- }
- }
- static void *threadRoutine(void *args)
- {
- pthread_detach(pthread_self());
- ThreadData *td = static_cast
- // 假设一次都读完了
- char buff[4096];
- ssize_t test = -1;
- ssize_t s = recv(td->sock_, buff, sizeof(buff)-1, 0);
- if(s > 0)
- {
- buff[s] = 0;
- string response = td->httpsvr_->func_(buff);
- send(td->sock_, response.c_str(), response.size(), 0);
- }
- else
- {
- logMessage(Debug, "Cilent [%d -> %s:%d] Quit", td->sock_, td->ip_.c_str(), td->port_);
- }
- delete td;
- return nullptr;
- }
- ~HttpServer()
- {
- listensock_.Close();
- }
- private:
- uint16_t port_;
- Sock listensock_;
- func_t func_;
- };
HttpServer.cc服务器源文件- #include
- #include "HttpServer.hpp"
- string HttpHandler(const string &request)
- {
- // 打印请求
- cout << request << endl;
- return "";
- }
- int main()
- {
- unique_ptr
psvr(new HttpServer(HttpHandler)) ; - psvr->Init();
- psvr->Start();
- }
Makefile自动化编译脚本- HttpServer:HttpServer.cc
- g++ -o $@ $^ -std=c++11 -lpthread
- .PHONY:clean
- clean:
- rm -rf HttpServer
编译并启动服务器

现在服务器已经准备好了,浏览器输入
IP:Port发出HTTP请求,因为当前服务器并未进行任何响应,所以浏览器无法显示页面: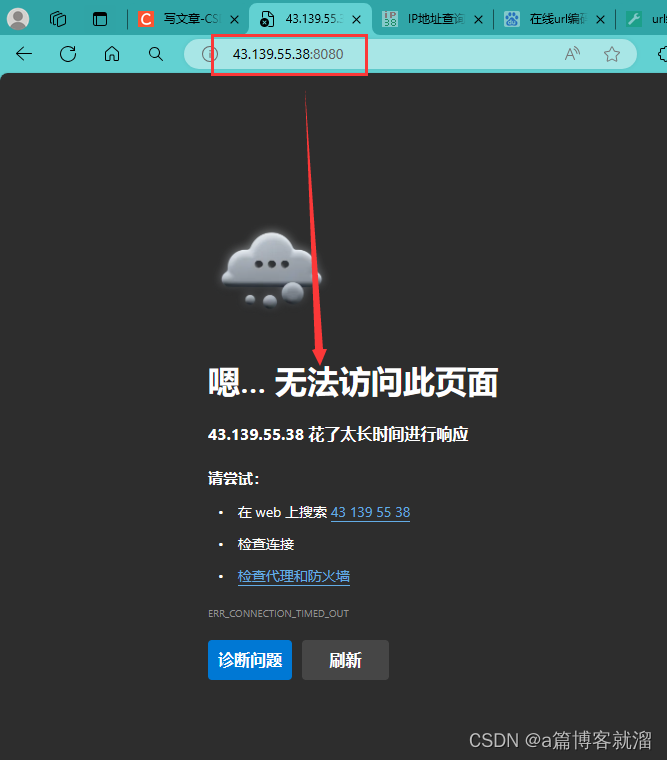
这就是
HTTP请求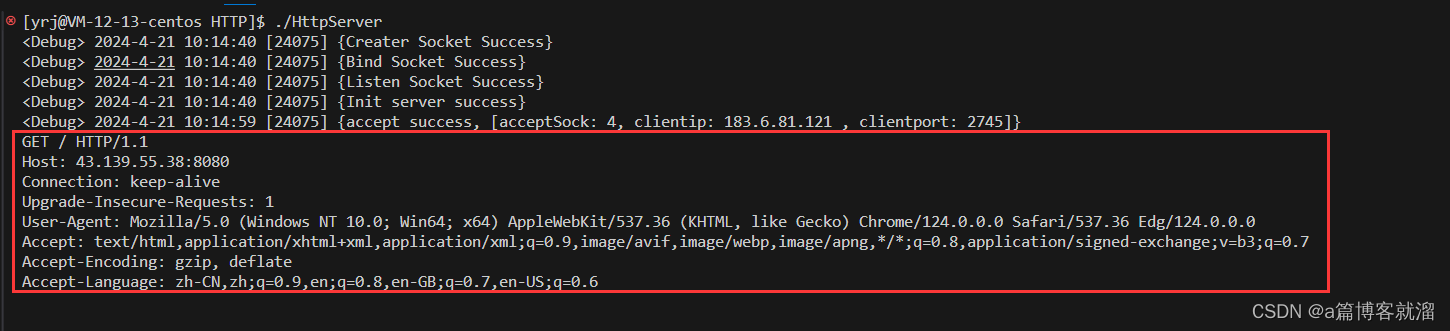
其中包含了 请求行、请求报头、空行

从请求行中可以看到当前使用的是
GET请求,基于HTTP/1.1版本,且请求的资源路径为/,如果我们在浏览器中指定资源路径,那么服务器则会得到该路径
在请求报头中包含多组属性:
- Host 表示当前请求的服务器 IP+Port
- Connection 表示当前连接模式为长连接还是短连接
- Cache-Control 表示双方在通信时缓存的最大生存时间
- Upgrade-Insecure-Requests 表示是否将 HTTP 连接方式升级为 HTTPS 连接
- User-Agent 表示用户端(也就是浏览器)的信息
- Accept 表示客户端(浏览器)能接受的响应类型
- Accept-Encoding 表示客户端(浏览器)能接受的 Encoding 类型
- Accept-Language 表示客户端(浏览器)能接受的编码符号
User-Agent 很有意思,它能让服务器根据不同的设备,提供不同的 标签,比如下载微信客户端,使用
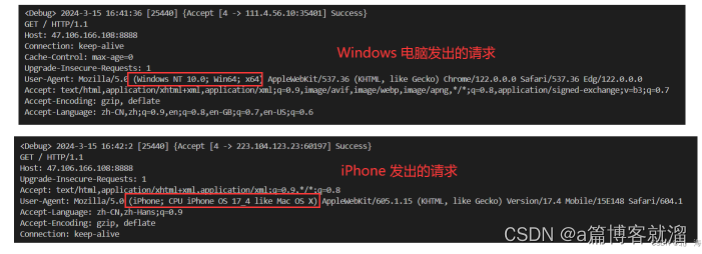
Windows电脑访问,默认显示的下载方式为 电脑下载,但如果使用iPhone访问,下载方式则会变为App Store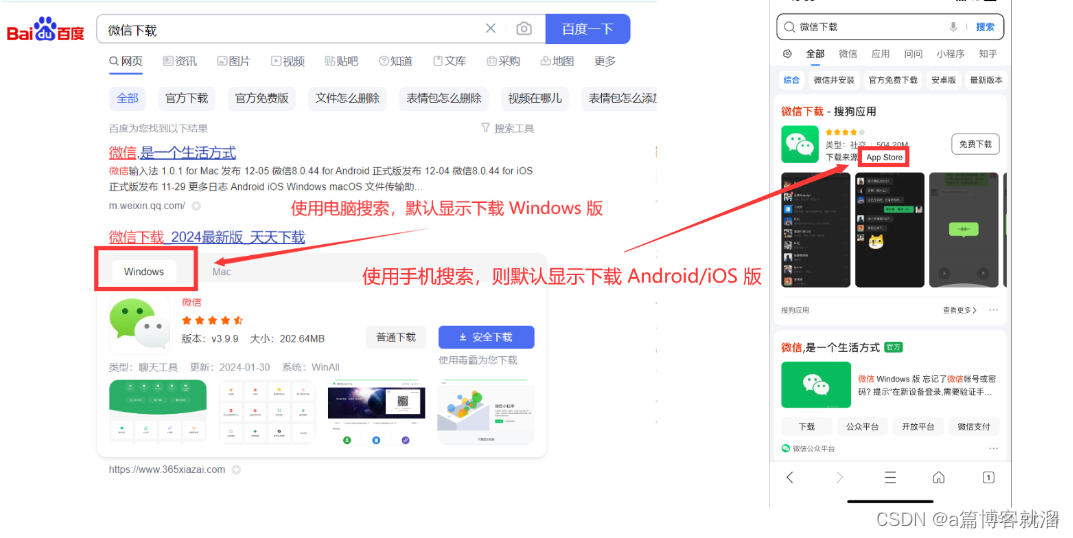
(三)见一见响应
可以通过
telnet这个工具(没有的话自行下载)获取服务器的响应,比如获取 百度 服务器的响应:telnet www.baidu.com 80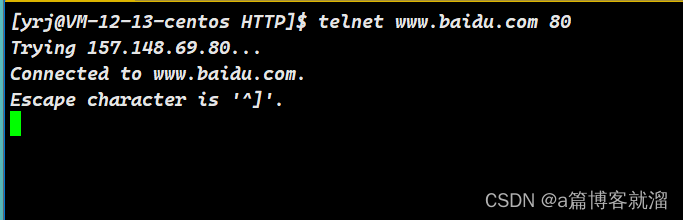
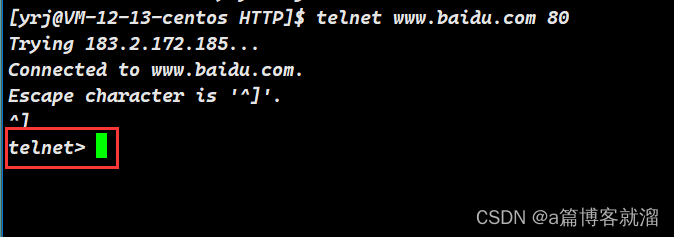
输入
^]连接服务器(ctrl + ])^]此时就表示已经和 百度 的服务器建立了连接
接着发出一个最简单的请求,看看 百度 服务器的响应结果
注意: 需要先按回车后,再发出请求,请求发出后需要再次回车表示空行,同时回车发送。
GET / HTTP/1.0下面这个就是 百度 服务器对于请求资源路径为
/时的响应结果,也就是前端页面信息,它的响应结果也得遵循HTTP协议的响应格式: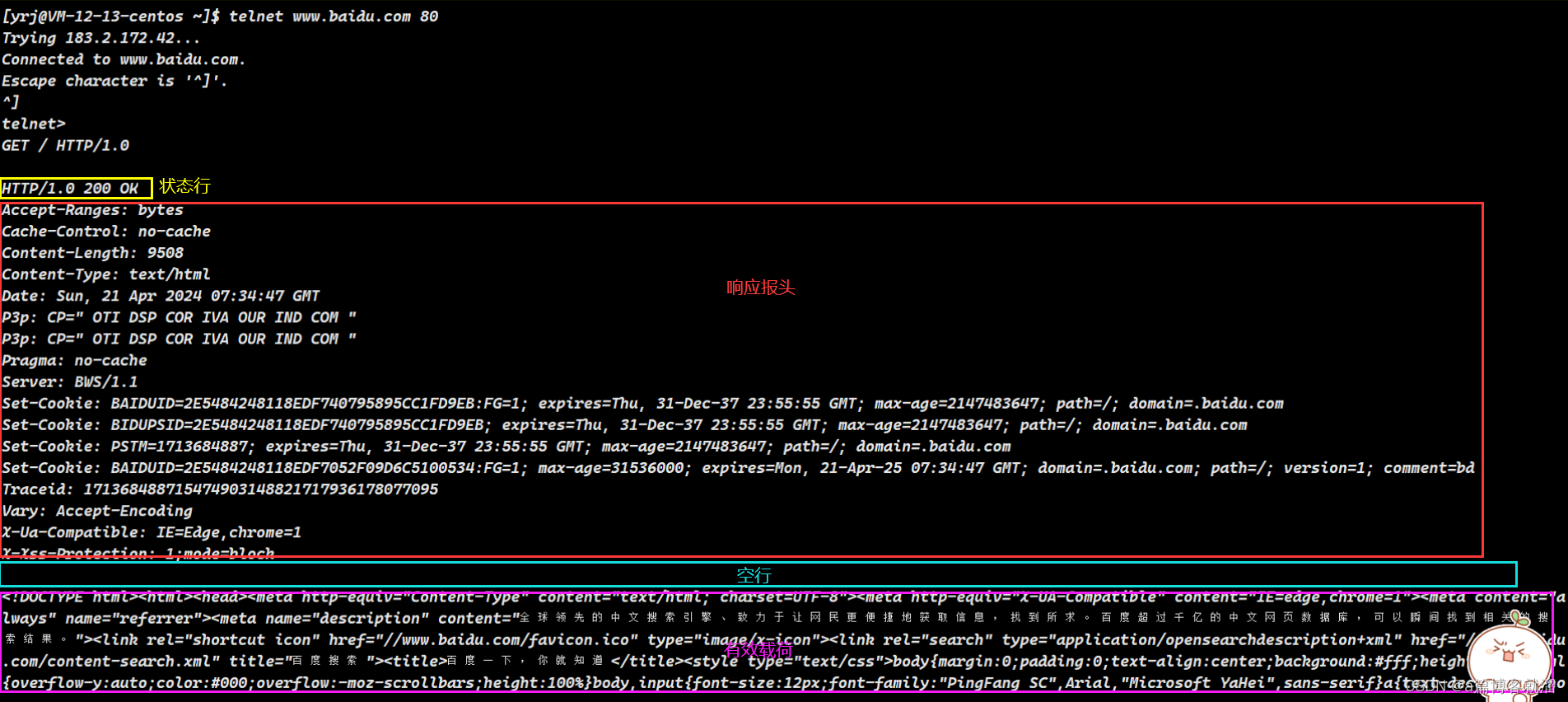
状态行中包括了
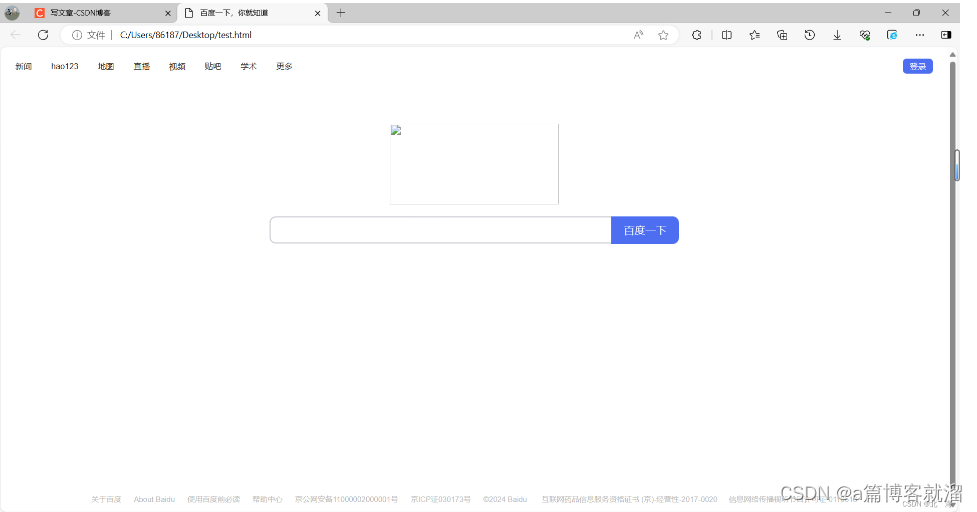
HTTP版本、状态码、状态描述,响应报头中是各种 属性,重要字段后面再谈,有效载荷中则是请求的 资源。将响应结果中的有效载荷部分作为前端页面代码,就可以得到百度 的默认页面:
三、模拟实现响应
了解了
HTTP响应的格式后,可以根据该格式实现一个简单的响应,发送给客户端(浏览器)(一)简单实现
在之前实现的
HTTP服务器中,只需要对HttpHandler()方法中的返回值进行修改即可- 添加状态行
- 添加响应报头(可省略)
- 添加空行
- 添加有效载荷
- const static string SEP = "\r\n";
- string HttpHandler(const string& request)
- {
- // 打印请求
- cout << request << endl;
- string response = "HTTP/1.0 200 OK" + SEP; // 状态行
- response += SEP; // 空行
- response += "Hello HTTP!"; // 有效载荷
- return response;
- }
编译并启动服务器,浏览器发出请求,就能得到服务器的简单响应:

如果将 有效载荷 部分替换成前端代码,就可以得到一个更为美观的响应页面(浏览器识别 有效载荷 为
HTTP代码,自动解释为网页)关于前端页面的学习:HTML
- string HttpHandler(const string& request)
- {
- // 打印请求
- cout << request << endl;
- string response = "HTTP/1.0 200 OK" + SEP; // 状态行
- response += SEP; // 空行
- response += "
TEST
Hello HTTP!
"; // 有效载荷 - return response;
- }
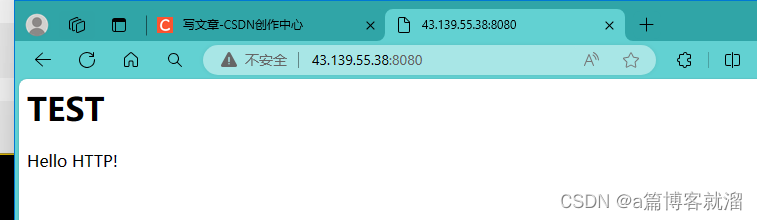
使用
telnet获取我们的服务器响应
除了
telnet外,还可以使用Postman(可以在网上寻找安装包)等工具在Windows中获取服务器响应: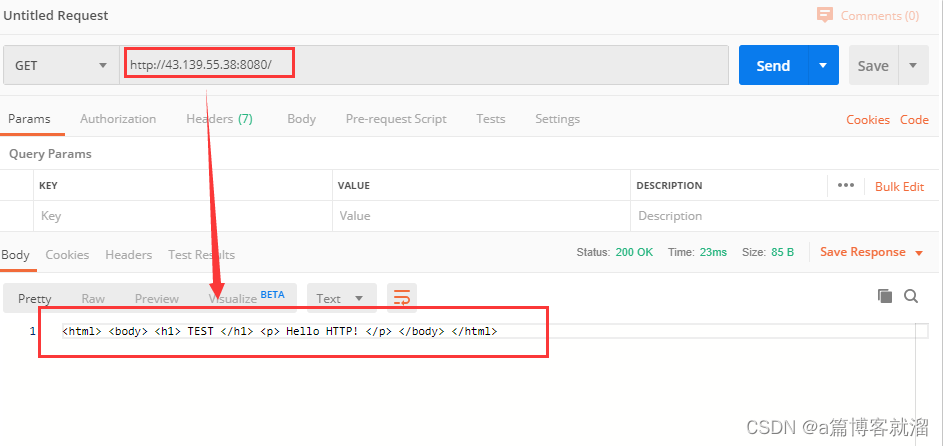
(二)重要属性
客户端/服务器在解析响应/请求时,必须要知道 有效载荷 的长度,避免多个响应/请求粘在一起而导致无法解析。
1.Content-Length
在
HTTP中通过Content-Length: xxx来表示 有效载荷 的长度为xxx,但是在我们上面模拟实现的响应中,并没有添加Content-Length属性,浏览器又是如何知道 有效载荷 的长度呢?这是因为 现代浏览器的功能都十分强大,即使你不指明
Content-Length它也能通过 边读取边解释 等策略读取 有效载荷,但从 协议 角度来看,无论浏览器是否使用,我们都应该注明Content-Length属性。浏览器的编写难度稍稍逊于比操作系统,是一款十分智能、强大的工业级软件。
比如我们给百度服务器发送请求时,它所响应的内容中就包含了
Content-Length属性: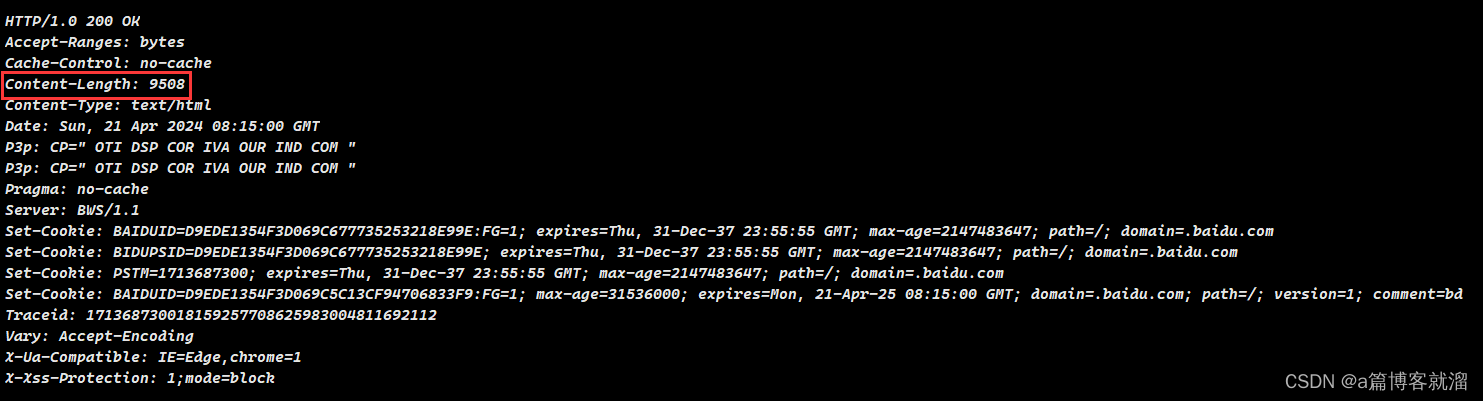
给
HTTP服务器的响应中加上该属性- string HttpHandler(const string& request)
- {
- // 打印请求
- cout << request << endl;
- string body = "
TEST
Hello HTTP!
"; - // 状态行
- string response = "HTTP/1.0 200 OK" + SEP;
- // 响应报头
- response += "Content-Length: " + to_string(body.size()) + SEP; // 有效载荷的长度
- // 空行
- response += SEP;
- // 有效载荷
- response += "
TEST
Hello HTTP!
"; // 有效载荷 - return response;
- }
使用
Postman发起请求,在Header标签可以看到Content-Length属性值为66,表示 有效载荷 长度为66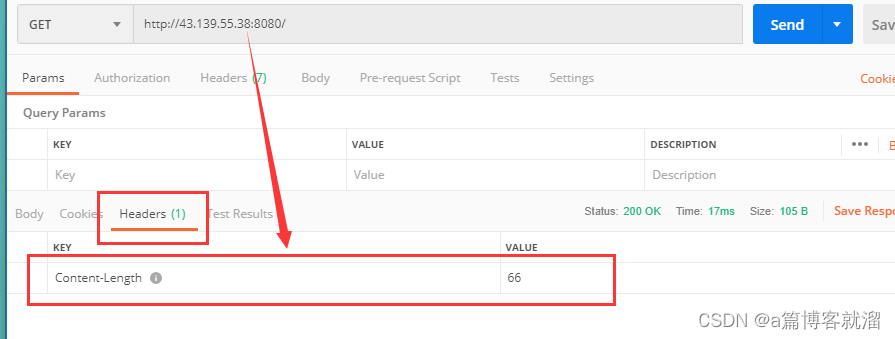
注意: 当主动添加
Content-Length属性后,部分浏览器可能不会主动解析有效载荷,转而直接输出有效载荷的内容。所以为了让浏览器更好的解析 有效载荷,还需要注明 有效载荷 的类型。
2.Content-Type
Content-Type: xxx表示当前响应的资源类型为xxx(网页、文本、图片、音频、视频等),可以通过不同的后缀来表征不同的资源,比如.avi格式的视频,可以使用Content-Type: video/avi来注明,Content-Type 对照表
如果我们将类型指定为
.txt,浏览器再访问HTTP服务器时,就会直接显示 有效载荷,而非解释为网页- string HttpHandler(const string& request)
- {
- // 打印请求
- cout << request << endl;
- string body = "
TEST
Hello HTTP!
"; - // 状态行
- string response = "HTTP/1.0 200 OK" + SEP;
- // 响应报头
- response += "Content-Length: " + to_string(body.size()) + SEP; // 有效载荷的长度
- response += "Content-Type: text/plain" + SEP; // 有效载荷类型为 文本
- // 空行
- response += SEP;
- // 有效载荷
- response += body;
- return response;
- }
浏览器访问
HTTP服务器就会得到一个文本,也就是 有效载荷 中的内容: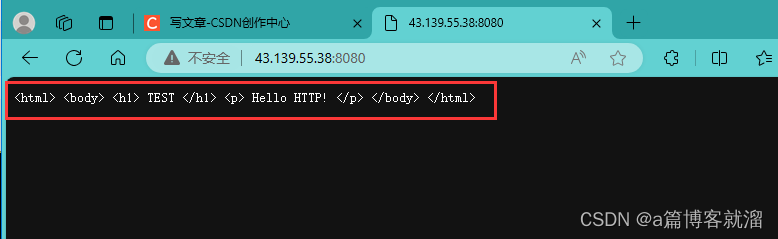
通过
Postman也可以看到Content-Type: text/plain这个属性: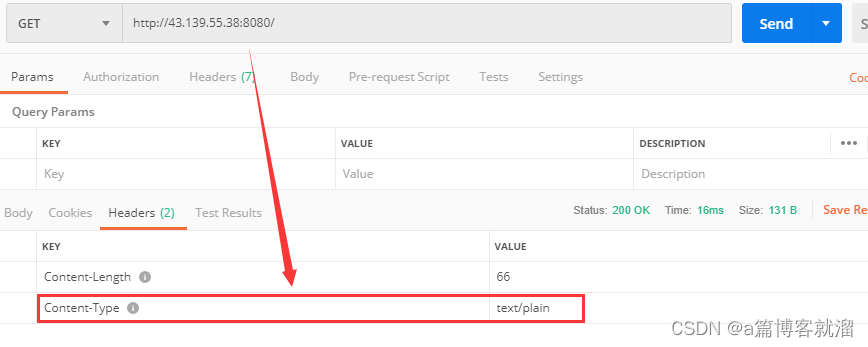
正常情况下,响应的资源是说明类型,
Conten-Type就得注明其类型,确保浏览器能正确解析。(三)请求分析
1. 路径处理
正常情况下,在访问网页时,用户知道自己要访问的是哪个资源,浏览器会通过该资源在服务器中对应的 资源路径 发出请求,所以说
HTTP服务器需要具备根据不同的 资源路径,给出不同的响应的能力,这也就意味着我们需要在服务器中创建一个资源目录webRoot,其中存放各种资源:
此时我们就不能直接在
HttpServer.cc中硬编码了(直接写出有效载荷),而是需要根据 资源路径,去webRoot目录中查找资源文件并读取,读取文件内容需要用到下面这个工具类 Util.hpp注意: 需要按照文件中的大小进行读取,避免因读取到
0而提前停止(二进制文件中存在0)- #pragma once
- #include "Log.hpp"
- #include
- #include
- #include
- #include
- #include
- #include
- class Util
- {
- public:
- static bool ReadFile(const std::string &path, std::string *outStr)
- {
- // 获取文件信息
- struct stat st;
- if(stat(path.c_str(), &st) < 0) return false;
- // 分配空间
- int n = st.st_size;
- outStr->resize(n+1);
- // 打开文件
- int fd = open(path.c_str(), O_RDONLY);
- if(fd < 0) return false;
- // 读取文件
- int size = read(fd, (char*)outStr->c_str(), n);
- close(fd);
- logMessage(Info, "read file %s success", outStr->c_str());
- // 实际读取到的大小应该与文件的大小一致
- return size == n;
- }
- };
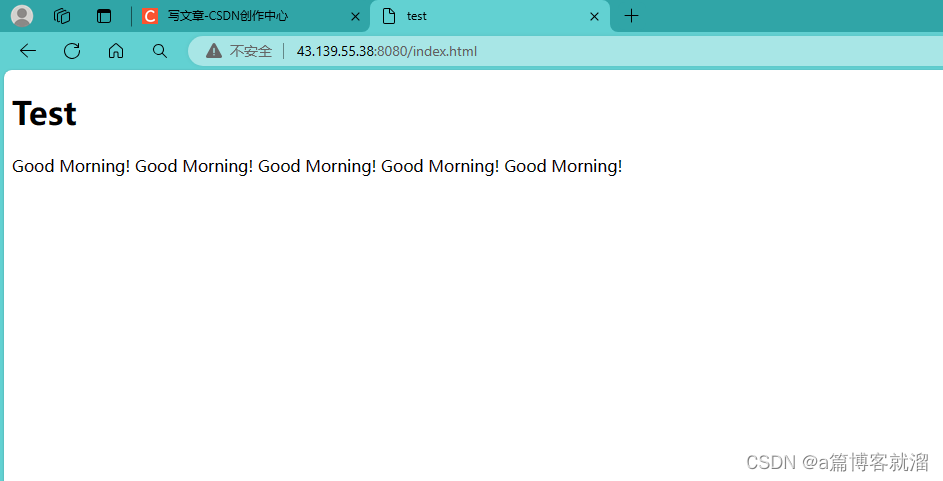
在
index.html文件中设置一个默认页面- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1.0">
- <title>testtitle>
- head>
- <body>
- <h1>
- Test
- h1>
- <p>
- Good Morning!
- Good Morning!
- Good Morning!
- Good Morning!
- Good Morning!
- p>
- body>
- html>
HttpHandler()函数在处理请求时,就可以通过 资源路径 读取资源了- string HttpHandler(const string& request)
- {
- // 打印请求
- cout << request << endl;
- string body;
- // 读取资源文件
- Util::ReadFile(DefaultSourcePath, &body);
- // 状态行
- string response = "HTTP/1.0 200 OK" + SEP;
- // 响应报头
- response += "Content-Length: " + to_string(body.size()) + SEP; // 有效载荷的长度
- response += "Content-Type: text/html" + SEP; // 有效载荷类型为 网页
- // 空行
- response += SEP;
- // 有效载荷
- response += body;
- return response;
- }
现在我们需要一个 结构体 来存储请求中的各种信息,比如 资源路径,同时需要借助 反序列化 进行解析。
注意:
- 如果用户直接请求
"/"根目录,不能将目录中的所有资源都响应,而是需要响应一个默认显示页面。 URL中的资源路径,需要加上web根目录,才是一个完整的路径。
Protocol.hpp请求处理相关头文件:- #pragma once
- #include "Util.hpp"
- #include
- #include
- const static string SEP = "\r\n";
- const static string webRoot = "./webRoot";
- const static string DefaultSourcePath = "/index.html"; // 默认为网页类型
- class Request
- {
- public:
- Request()
- {}
- // 反序列化
- bool Deserialize(const string &url)
- {
- // 根据 url 进行解析
- int n = 0;
- vector
vstr; - while(true)
- {
- string line;
- n = Util::ReadLine(url, n, SEP, &line) + SEP.size();
- if(line.empty()) break;
- vstr.push_back(line);
- }
- // 解析请求行
- ParseFirstLine(vstr[0]);
- // 解析报头行
- ParseHeaderLine(vstr);
- // 读取并解析有效载荷(可能没有)
- Util::ReadLine(url, n, SEP, &_body);
- return true;
- }
- // 解析请求行
- bool ParseFirstLine(const string &str)
- {
- // 读取方法、资源路径、协议版本
- stringstream ss(str);
- ss >> _method >> _path >> _version;
- // 解析出后缀
- if(_path == "/") _path = DefaultSourcePath;
- // 实际路径 = web根目录 + 请求资源路径
- int pos = _path.find_last_not_of(".");
- if(pos == string::npos) _suffix = ".html";
- else _suffix = _path.substr(pos);
- _path = webRoot + _path;
- return true;
- }
- // 解析报头行
- bool ParseHeaderLine(const vector
& vstr) - {
- for(int i = 1; i < vstr.size(); i++)
- {
- const string &str = vstr[i];
- int pos = str.find(':');
- string key = str.substr(0, pos);
- string value = str.substr(pos+2);
- _headers[key] = value;
- }
- return true;
- }
- ~Request()
- {}
- public:
- string _method; // 请求方法
- string _path; // 资源路径
- string _suffix; // 资源后缀
- string _version; // 协议版本
- unordered_map
- string _body; // 有效载荷
- };
ReadLine()读取行函数 — 位于Util.hpp工具类头文件的Request请求类中- static int ReadLine(const std::string &url, int i,
- const std::string &SEP, std::string *line)
- {
- int pos = url.find(SEP, i);
- *line = url.substr(i, pos-i);
- return pos;
- }
此时
HttpHandler()函数中的处理方式就要发生改变了- string HttpHandler(const string &url)
- {
- // 解析请求
- Request req;
- req.Deserialize(url);
- // 读取资源文件
- string body;
- Util::ReadFile(req._path, &body);
- cout << "path: " << req._path << endl;
- // 状态行
- string response = "HTTP/1.0 200 OK" + SEP;
- // 响应报头
- response += "Content-Length: " + to_string(body.size()) + SEP; // 有效载荷的长度
- response += "Content-Type: text/html" + SEP; // 有效载荷类型为 网页
- // 空行
- response += SEP;
- // 有效载荷
- response += body;
- return response;
- }
经过以上修改后,我们的
HTTP服务器就支持根据不同的 资源路径,响应不同的资源了,现在在webRoot这个网页根目录中再添加两个测试文件:file1.html、file2.html- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1.0">
- <title>test file1title>
- head>
- <body>
- <h1>
- FILE1
- h1>
- <p>
- This is file1
- This is file1
- This is file1
- This is file1
- This is file1
- p>
- body>
- html>
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1.0">
- <title>test file2title>
- head>
- <body>
- <h1>
- FILE2
- h1>
- <p>
- This is file2
- This is file2
- This is file2
- This is file2
- This is file2
- p>
- body>
- html>
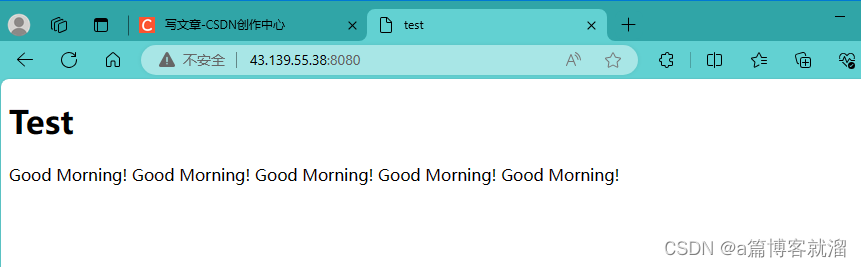
编译并启动服务器,通过浏览器发出不同的请求:
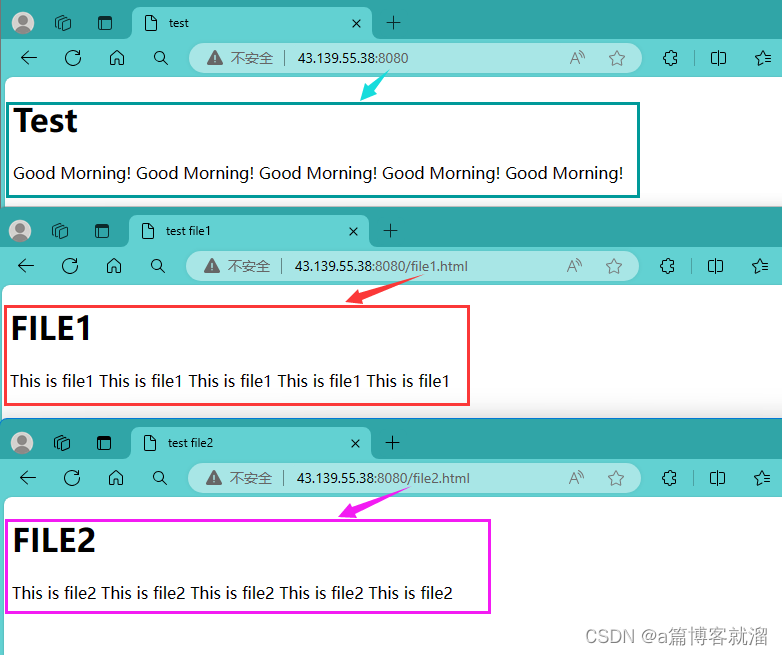
现在已经具备一个服务器的雏形了,接下来就是处理请求不同资源的问题。
2. 类型处理
在进行响应时,需要知晓请求的资源类型,并在响应报头中通过 Content-Type 注明,关于资源路径中的文件后缀提取,已经在
Request类中完成了,现在只需要根据 Content-Type 对照表进行转换,并赋值至Response类中即可:Content-Type 对照表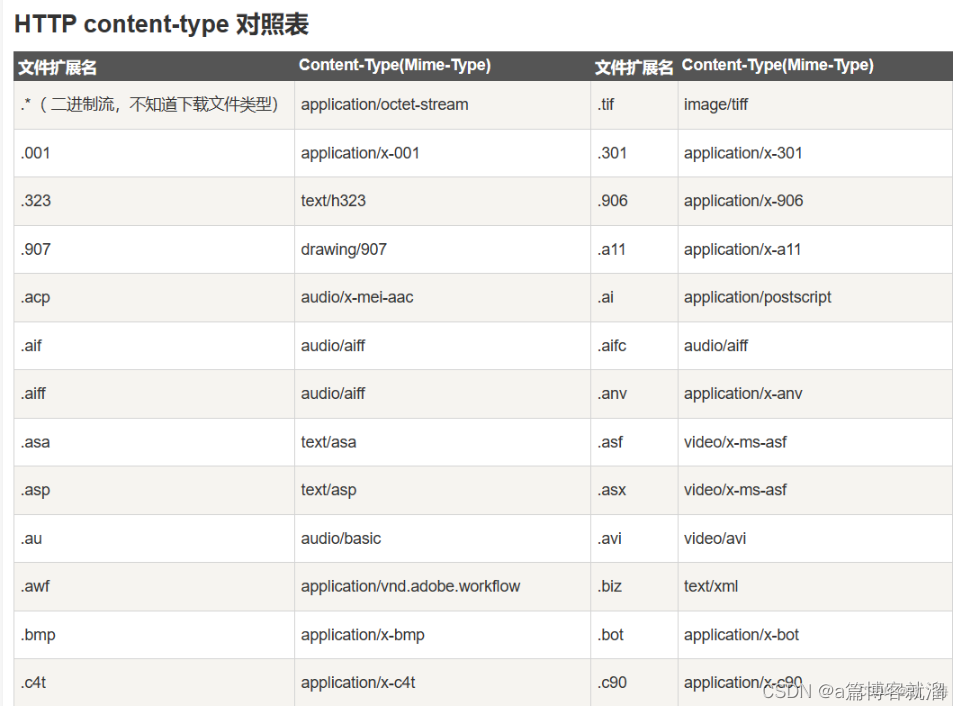
构建
Response响应类,位于Protocol.hpp,成员有:状态行(协议版本、状态码、状态码信息)、响应报头、有效载荷,函数有:根据请求加载响应对象、反序列化- const static string errPage_404 = "/err404.html";
- class Response
- {
- public:
- Response()
- {}
- // 序列化
- bool Serialize(string *outStr)
- {
- outStr->clear();
- *outStr = _version + " " + _st_code + " " + _st_msg + SEP;
- for (auto &kv : _headers)
- *outStr += kv.first + kv.second + SEP;
- *outStr += SEP;
- *outStr += _body;
- return true;
- }
- // 根据请求对象,构建出响应对象
- bool LoadInfo(const Request &req)
- {
- _version = req._version;
- // 读出资源
- string path = req._path;
- if (Util::ReadFile(path, &_body) == false)
- {
- _st_code = "404";
- _st_msg = "No Found";
- path = webRoot + errPage_404;
- Util::ReadFile(path, &_body);
- }
- else
- {
- _st_code = "200";
- _st_msg = "OK";
- }
- cout << "path: " << path << endl;
- // 设置报头
- _headers["Content-Length: "] = to_string(_body.size());
- _headers["Content-Type: "] = Util::GetSuffix(req._suffix);
- return true;
- }
- ~Response()
- {}
- public:
- string _version; // 协议版本
- string _st_code; // 状态码
- string _st_msg; // 状态码信息
- unordered_map
- string _body; // 有效载荷
- };
新增根据后缀获取资源类型的工具函数GetSuffix(),位于
Util.hpp- static string GetSuffix(const string &suffix)
- {
- // 构建类型映射表
- unordered_map
- {
- {".txt", "text/plain"},
- {".htm", "text/html"},
- {".html", "text/html"},
- {".jpg", "image/jpeg"},
- {".jpeg", "image/jpeg"},
- {".png", "image/png"},
- {".mp3", "audio/mp3"},
- {".avi", "video/avi"},
- {".mp4", "video/mpeg4"},
- };
- if(table.count(suffix) == 0) return "text/html";
- return table[suffix];
- }
HttpHandler()函数中不再需要主动处理请求,而是交给Response对象完成- string HttpHandler(const string &url)
- {
- // 解析请求
- Request req;
- req.Deserialize(url);
- // 构建响应
- Response res;
- res.LoadInfo(req);
- // 响应
- string ret;
- res.Serialize(&ret);
- return ret;
- }
因为用户可能请求不存在的资源,所以需要准备一个
404网页404网页代码来源:HTML 和 JavaScript 编写简单的 404 界面err404.html请求资源错误时返回的页面- html>
- <html>
- <head>
- <meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
- <title>404title>
- <style>
- html, body {
- height: 100%;
- min-height: 450px;
- font-size: 32px;
- font-weight: 500;
- color: #5d7399;
- margin: 0;
- padding: 0;
- border: 0;
- }
- .content {
- height: 100%;
- position: relative;
- z-index: 1;
- background-color: #d2e1ec;
- background-image: -webkit-linear-gradient(top, #bbcfe1 0%, #e8f2f6 80%);
- background-image: linear-gradient(to bottom, #bbcfe1 0%, #e8f2f6 80%);
- overflow: hidden;
- }
- .snow {
- position: absolute;
- top: 0;
- left: 0;
- pointer-events: none;
- z-index: 20;
- }
- .main-text {
- padding: 20vh 20px 0 20px;
- text-align: center;
- line-height: 2em;
- font-size: 5vh;
- }
- .main-text h1 {
- font-size: 45px;
- line-height: 48px;
- margin: 0;
- padding: 0;
- }
- .main-text-a {
- height: 32px;
- margin-left: auto;
- margin-right: auto;
- text-align: center;
- }
- .main-text-a a {
- font-size: 16px;
- text-decoration: none;
- color: #0066CC;
- }
- .main-text-a a:hover {
- color: #000;
- }
- .home-link {
- font-size: 0.6em;
- font-weight: 400;
- color: inherit;
- text-decoration: none;
- opacity: 0.6;
- border-bottom: 1px dashed rgba(93, 115, 153, 0.5);
- }
- .home-link:hover {
- opacity: 1;
- }
- .ground {
- height: 160px;
- width: 100%;
- position: absolute;
- bottom: 0;
- left: 0;
- background: #f6f9fa;
- box-shadow: 0 0 10px 10px #f6f9fa;
- }
- .ground:before, .ground:after {
- content: '';
- display: block;
- width: 250px;
- height: 250px;
- position: absolute;
- top: -62.5px;
- z-index: -1;
- background: transparent;
- -webkit-transform: scaleX(0.2) rotate(45deg);
- transform: scaleX(0.2) rotate(45deg);
- }
- .ground:after {
- left: 50%;
- margin-left: -166.66667px;
- box-shadow: -340px 260px 15px #8193b2, -620px 580px 15px #8193b2, -900px 900px 15px #b0bccf, -1155px 1245px 15px #b4bed1, -1515px 1485px 15px #8193b2, -1755px 1845px 15px #8a9bb8, -2050px 2150px 15px #91a1bc, -2425px 2375px 15px #bac4d5, -2695px 2705px 15px #a1aec6, -3020px 2980px 15px #8193b2, -3315px 3285px 15px #94a3be, -3555px 3645px 15px #9aa9c2, -3910px 3890px 15px #b0bccf, -4180px 4220px 15px #bac4d5, -4535px 4465px 15px #a7b4c9, -4840px 4760px 15px #94a3be;
- }
- .ground:before {
- right: 50%;
- margin-right: -166.66667px;
- box-shadow: 325px -275px 15px #b4bed1, 620px -580px 15px #adb9cd, 925px -875px 15px #a1aec6, 1220px -1180px 15px #b7c1d3, 1545px -1455px 15px #7e90b0, 1795px -1805px 15px #b0bccf, 2080px -2120px 15px #b7c1d3, 2395px -2405px 15px #8e9eba, 2730px -2670px 15px #b7c1d3, 2995px -3005px 15px #9dabc4, 3285px -3315px 15px #a1aec6, 3620px -3580px 15px #8193b2, 3880px -3920px 15px #aab6cb, 4225px -4175px 15px #9dabc4, 4510px -4490px 15px #8e9eba, 4785px -4815px 15px #a7b4c9;
- }
- .mound {
- margin-top: -80px;
- font-weight: 800;
- font-size: 180px;
- text-align: center;
- color: #dd4040;
- pointer-events: none;
- }
- .mound:before {
- content: '';
- display: block;
- width: 600px;
- height: 200px;
- position: absolute;
- left: 50%;
- margin-left: -300px;
- top: 50px;
- z-index: 1;
- border-radius: 100%;
- background-color: #e8f2f6;
- background-image: -webkit-linear-gradient(top, #dee8f1, #f6f9fa 60px);
- background-image: linear-gradient(to bottom, #dee8f1, #f6f9fa 60px);
- }
- .mound:after {
- content: '';
- display: block;
- width: 28px;
- height: 6px;
- position: absolute;
- left: 50%;
- margin-left: -150px;
- top: 68px;
- z-index: 2;
- background: #dd4040;
- border-radius: 100%;
- -webkit-transform: rotate(-15deg);
- transform: rotate(-15deg);
- box-shadow: -56px 12px 0 1px #dd4040, -126px 6px 0 2px #dd4040, -196px 24px 0 3px #dd4040;
- }
- .mound_text {
- -webkit-transform: rotate(6deg);
- transform: rotate(6deg);
- }
- .mound_spade {
- display: block;
- width: 35px;
- height: 30px;
- position: absolute;
- right: 50%;
- top: 42%;
- margin-right: -250px;
- z-index: 0;
- -webkit-transform: rotate(35deg);
- transform: rotate(35deg);
- background: #dd4040;
- }
- .mound_spade:before, .mound_spade:after {
- content: '';
- display: block;
- position: absolute;
- }
- .mound_spade:before {
- width: 40%;
- height: 30px;
- bottom: 98%;
- left: 50%;
- margin-left: -20%;
- background: #dd4040;
- }
- .mound_spade:after {
- width: 100%;
- height: 30px;
- top: -55px;
- left: 0%;
- box-sizing: border-box;
- border: 10px solid #dd4040;
- border-radius: 4px 4px 20px 20px;
- }
- style>
- head>
- <body translate="no">
- <div class="content">
- <canvas class="snow" id="snow" width="1349" height="400">canvas>
- <div class="main-text">
- <h1>404 天呐!出错了 ~<br><br>您好像去了一个不存在的地方! (灬ꈍ ꈍ灬)h1>
- <div class="main-text-a"><a href="#">< 返回 首页a>div>
- div>
- <div class="ground">
- <div class="mound">
- <div class="mound_text">404div>
- <div class="mound_spade">div>
- div>
- div>
- div>
- <script>
- (function () {
- function ready(fn) {
- if (document.readyState != 'loading') {
- fn();
- } else {
- document.addEventListener('DOMContentLoaded', fn);
- }
- }
- function makeSnow(el) {
- var ctx = el.getContext('2d');
- var width = 0;
- var height = 0;
- var particles = [];
- var Particle = function () {
- this.x = this.y = this.dx = this.dy = 0;
- this.reset();
- }
- Particle.prototype.reset = function () {
- this.y = Math.random() * height;
- this.x = Math.random() * width;
- this.dx = (Math.random() * 1) - 0.5;
- this.dy = (Math.random() * 0.5) + 0.5;
- }
- function createParticles(count) {
- if (count != particles.length) {
- particles = [];
- for (var i = 0; i < count; i++) {
- particles.push(new Particle());
- }
- }
- }
- function onResize() {
- width = window.innerWidth;
- height = window.innerHeight;
- el.width = width;
- el.height = height;
- createParticles((width * height) / 10000);
- }
- function updateParticles() {
- ctx.clearRect(0, 0, width, height);
- ctx.fillStyle = '#f6f9fa';
- particles.forEach(function (particle) {
- particle.y += particle.dy;
- particle.x += particle.dx;
- if (particle.y > height) {
- particle.y = 0;
- }
- if (particle.x > width) {
- particle.reset();
- particle.y = 0;
- }
- ctx.beginPath();
- ctx.arc(particle.x, particle.y, 5, 0, Math.PI * 2, false);
- ctx.fill();
- });
- window.requestAnimationFrame(updateParticles);
- }
- onResize();
- updateParticles();
- }
- ready(function () {
- var canvas = document.getElementById('snow');
- makeSnow(canvas);
- });
- })();
- script>
- body>
- html>
当前服务器支持请求不同的资源,所以我们可以在
webRoot网页根目录下添加图片,并内嵌到其他资源文件中,可以使用 wget 命令,用于远程获取资源:
将图片资源重命名:
注意: 如果一个网页中包含多份资源,每一份资源都需要发起一次
HTTP请求 。file1.html
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1.0">
- <title>test file1title>
- head>
- <body>
- <h1>
- ?????????????
- h1>
- <p>
- <img src="/image/???.png" alt="鲤鱼大大的文豪">
- p>
- body>
- html>
现在可以请求不同的资源了
请求不存在的网页

请求
file1.html文件
可以在网页中内嵌其他网页的
URL,配合HTML语法,实现网页跳转- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1.0">
- <title>test file1title>
- head>
- <body>
- <h1>
- ?????????????
- h1>
- <p>
- <img src="/image/???.png" alt="鲤鱼大大的文豪">
- <a href="http://www.baidu.com">百度一下a>
- <a href="/index.html">回到首页a>
- p>
- body>
- html>
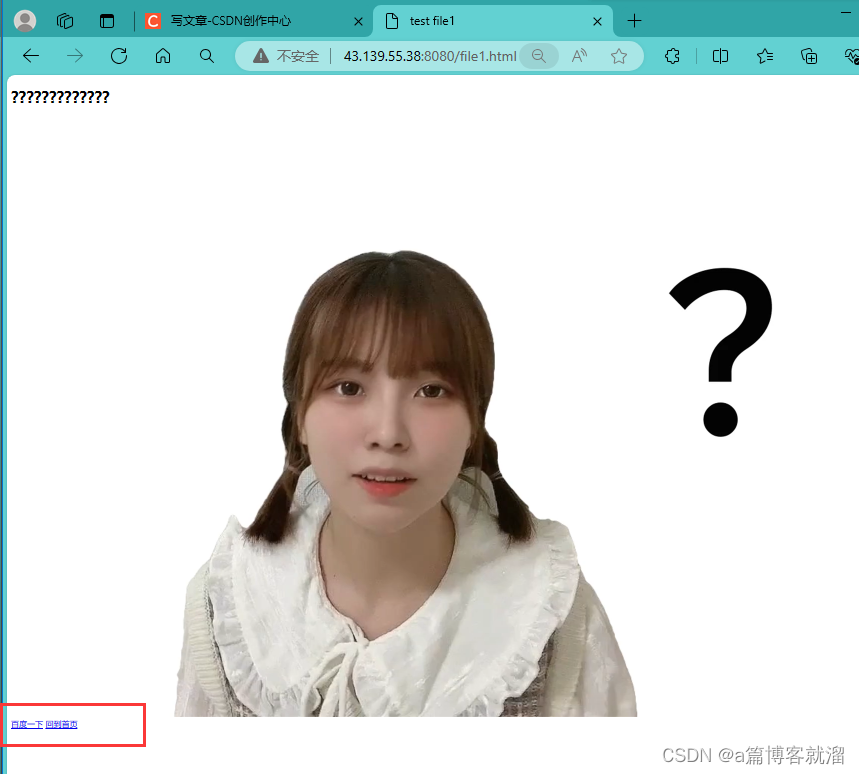
分别点击
百度一下和回到首页实现跳转
3. 请求方法
浏览器(客户端)与服务器间的交互行为可以分为这两类:
- 从服务器中获取资源
- 将资源上传至服务器
这两类行为分别对应着最常用的两个请求方法:
GET、POST(GET也能上传资源),除此之外,还存在其他请求方法,但最常用的就是GET和POST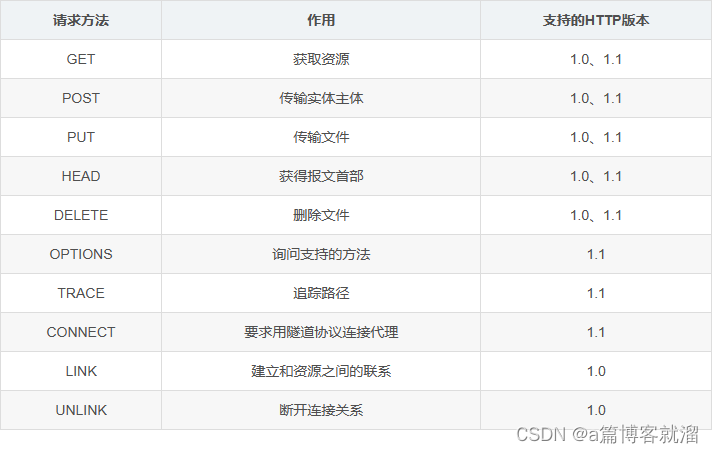
我们之前发出的请求使用的都是
GET请求,如何让浏览器发出POST请求呢?需要使用
HTML中的 表单,语法如下:- <form action="action_page.php" method="GET" target="_blank" accept-charset="UTF-8"
- ectype="application/x-www-form-urlencoded" autocomplete="off" novalidate>
- .
- form elements
- .
- form>
表单 中比较重要的两个属性
action向何处发送表单method表单请求的方法
表单 中可以指定
method(使用GET或者POST),在网页中看到的绝大多数输入框,都是通过 表单 实现的:
在我们的
index.html默认页面文件中实现一个 表单,并指定请求方法为GET注意: 此时的请求可能会导致服务器崩溃,因为我们没有做请求读取的处理工作,可能出现只读取了一半,从而导致读取错误。
访问网页,可以看到在提交 表单 后,
URL会发生变化,跳转到404页面: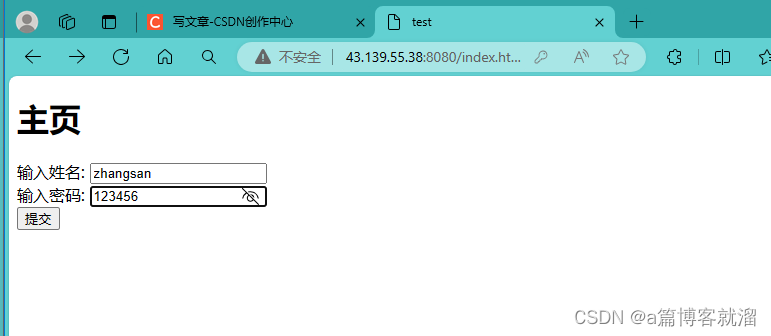
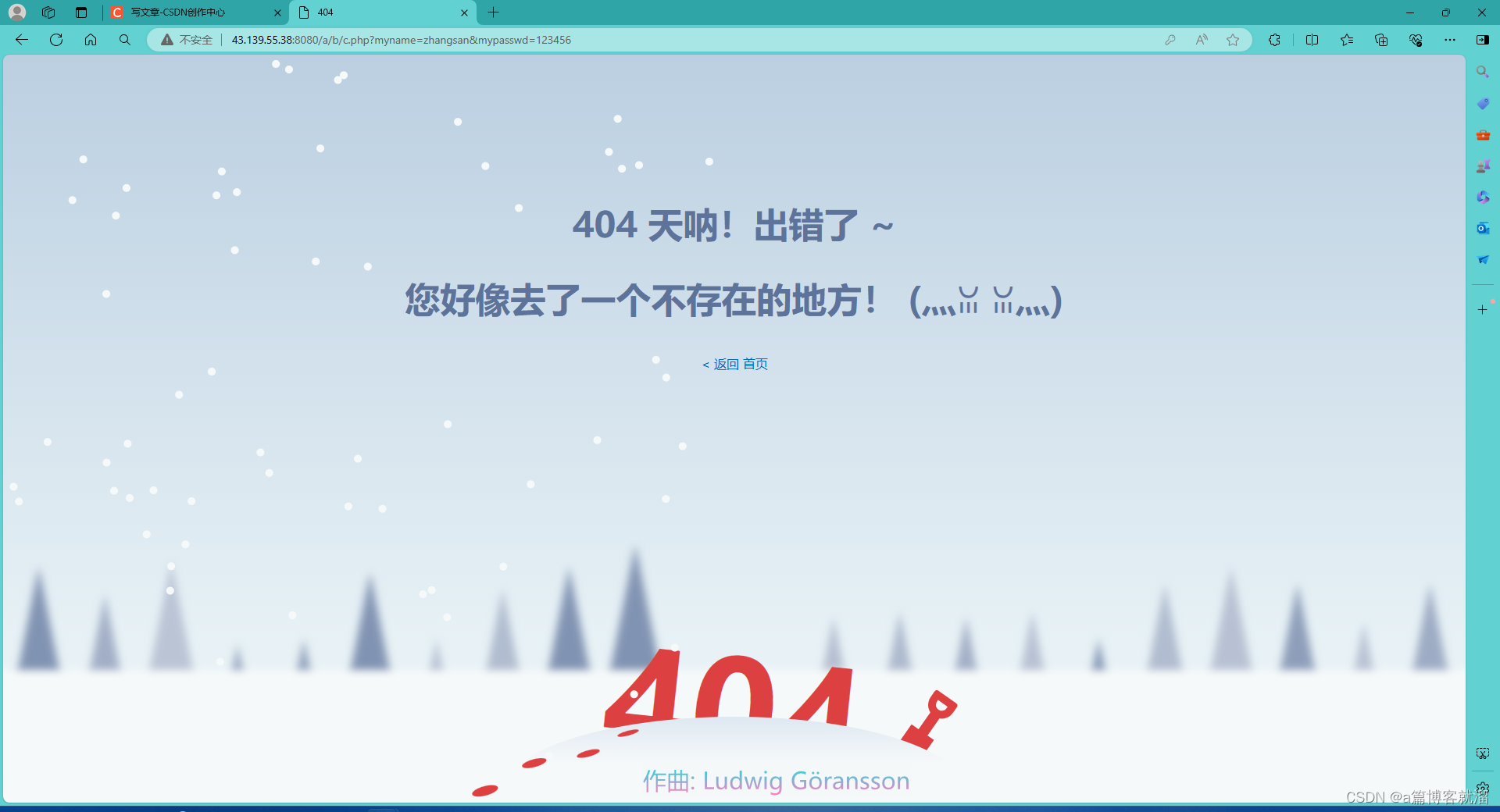
可以看出,如果使用
GET方法提交 表单 的话,请求的资源以及文本框中的内容将会以 明文 的形式添加到URL中。为什么提交后会出现
404页面?
因为请求的/a/b/c.php资源不存在,自动跳转到了404页面。服务器中获取的请求详情如下:

如果将 index.html 表单 中的请求方法改为
POST<form action="/a/b/c.php" method="post">表单提交前后
URL的变化如下
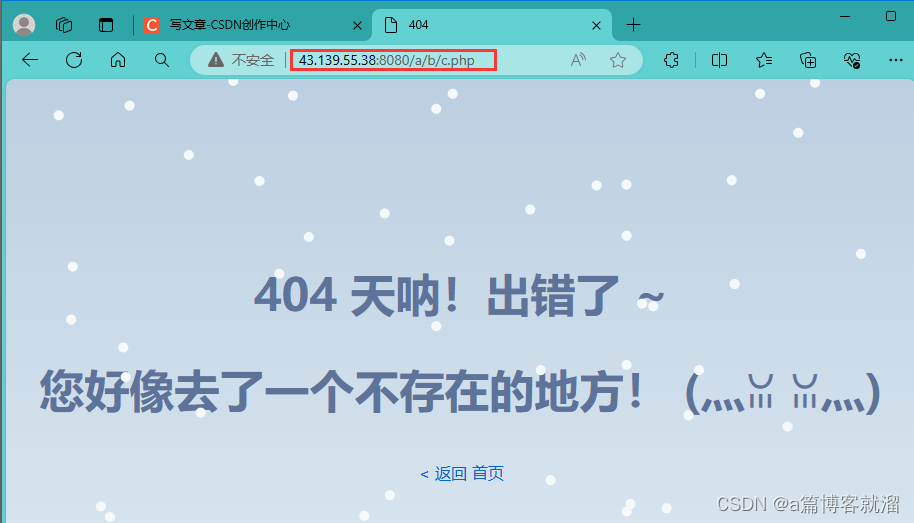
可以看到只有请求的资源路径被添加到了
URL中,那么文本框中的内容哪去了呢?答案是 在有效载荷中
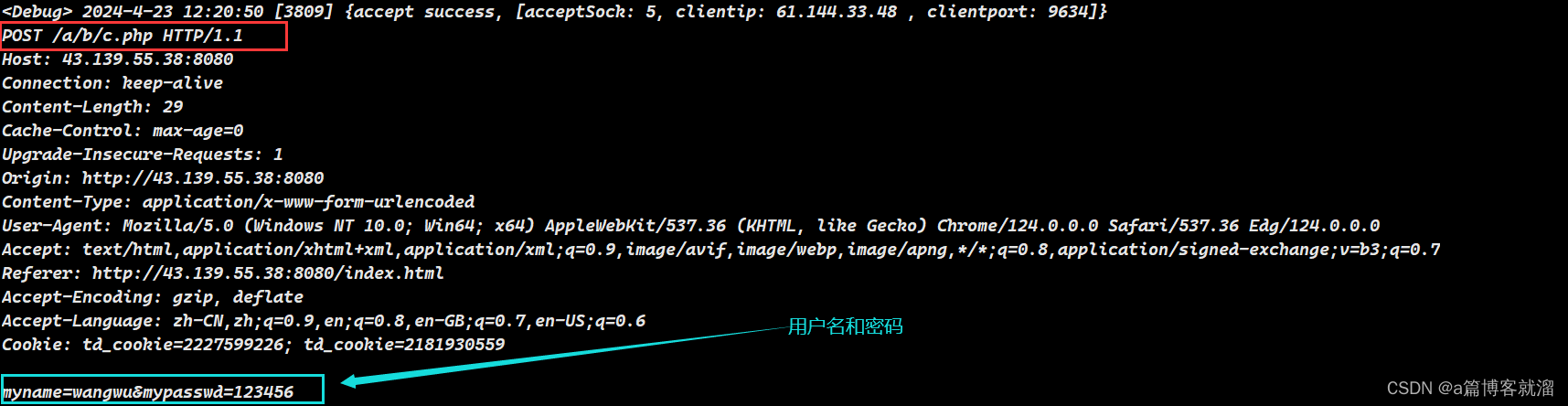
由此可以看出 GET 和 POST 这两种请求方法最大的区别:提参方式,GET 会将表单中的内容直接添加到 URL 中;POST 则会将表单中的内容添加到有效载荷中。
这两种方法在传输表单内容时,都是明文传输,但 POST 相对 GET 而言更 私密,并且容量也会更大。
注意: GET 和 POST 方法都不安全,只是 POST 更私密(存储在有效载荷中,用户不容易获取)。
GET 和 POST 的应用场景:
- GET:搜索框,比如百度的搜索框使用的就是 GET 方法,可以在 URL 中找到搜索的关键字。
- POST:敏感字段,比如账号、密码等个人信息,可以提供一定的私密性。
- 针对敏感字段,除了 POST 外,还可以使用其他更安全的方法。
- 如果需要传输的内容过长,也可以使用 POST 方法,因为有效载荷的容量理论上非常大(URL 有长度限制)。
接下来演示使用
Fiddler等抓包工具,截获POST请求,并从中获取账号和密码- 大致原理:挟持浏览器,让浏览器先把请求发给它,然后它帮浏览器请求

可以看到,即使是POST方法,也能被抓取到私密内容 。所以就目前而言(使用
HTTP协议),只要是没有经过加密的数据,发送到网络中都是不安全的!需要进行加密,随着信息安全的意识增强,会选择使用更加安全的HTTPS协议。4. 状态码
状态码是服务器向浏览器(客户端)反映请求成功与否的一种方式,状态码可以分为这几类:
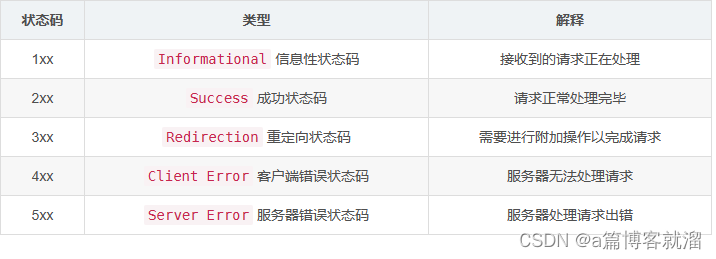 其中最常见的就是
其中最常见的就是 404错误码,表示 请求的资源不存在,属于客户端错误。关于HTTP服务器的404页面编写已经在 「类型处理」 部分完成了,当我们访问不存在的网页时,会得到这样一个页面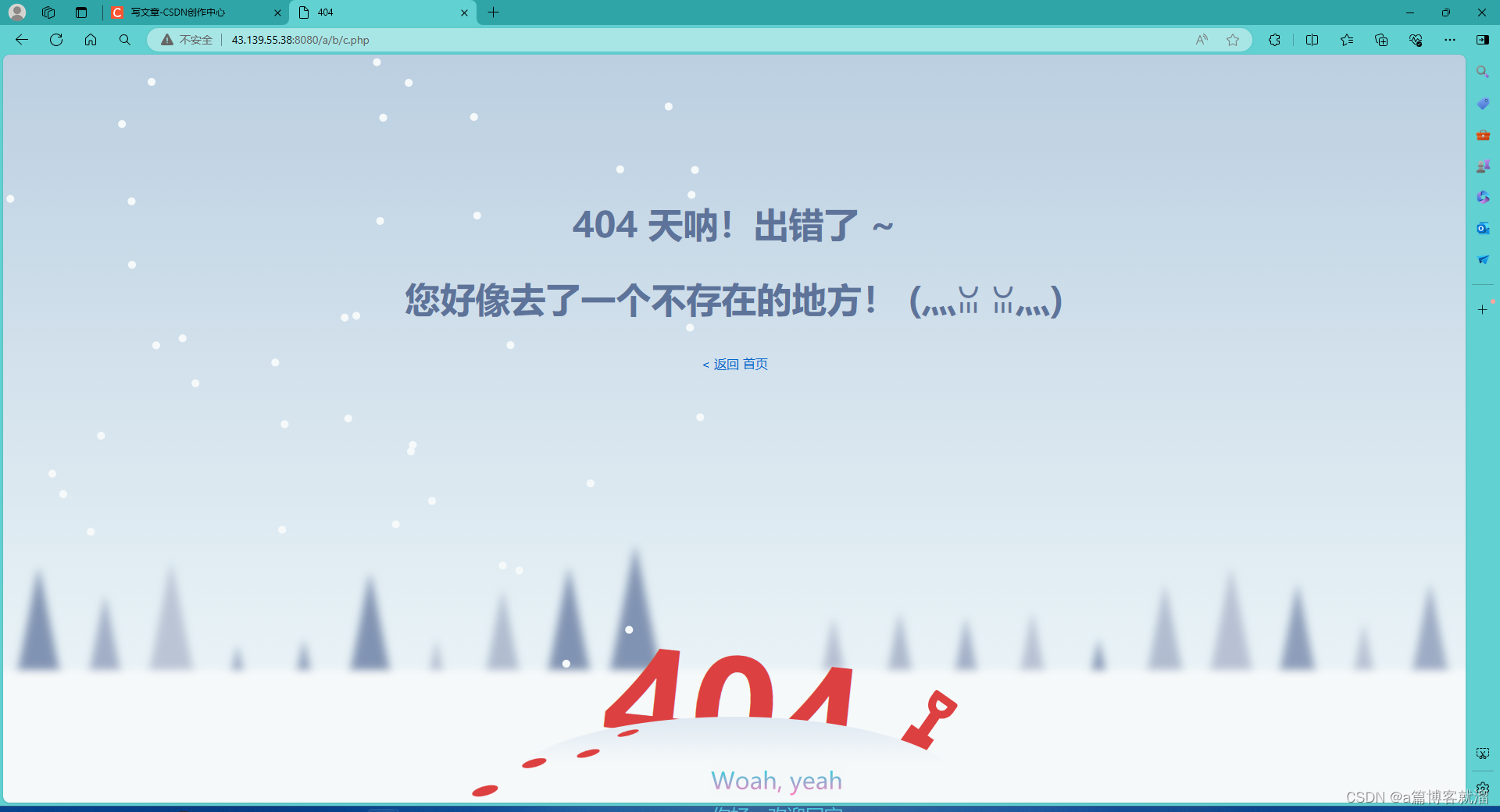
服务器发出的响应正文如下
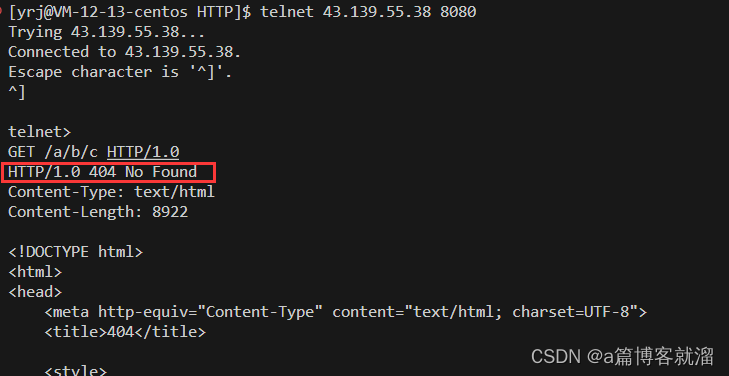
HTTP中浏览器(客户端)的状态码 形态各异,可能出现状态码与实际状态不相符的情况,主要是原因 不同浏览器(客户端)对协议的支持程度不同。
(1)重定向状态码
当浏览器(客户端)访问的目标网站地址发生改变时,服务器返回的HTTP数据流中头信息中的状态码会返回
3xx重定向错误码,浏览器接收到这些状态码后,会自动向新的URL发起请求,以获取所需的资源。常见的重定向状态码如下:- 永久重定向:
301、308 - 临时重定向:
302、303、307 - 其他重定向:
304
最具有代表性的重定向状态码为
301和302如何理解永久重定向和临时重定向?
永久重定向表示表示一个网页已经永久性地转移到了另一个地址,用户访问的已不存在的网址会自动转到另一个网址,只有第一次访问需要跳转;而临时重定向表示目标网址暂时性地被转移到了另一个地址,每次访问都需要跳转。注意: 无论是永久还是临时,站在服务器角度,都需要进行重定向,因为总会有新客户端连接,需要为其进行重定向引导。
关于重定向状态的更多信息可以看看这篇文章 《彻底搞懂 HTTP 3XX 重定向状态码和浏览器重定向》
如何在代码中实现重定向?
设置错误码为3xx,并在响应报头中加上Location: URL对
HTTP服务器进行修改(临时重定向)LoadInfo()根据请求创建响应对象 — 位于Protocol.hpp中的Response响应类中- // 根据请求对象,构建出响应对象
- bool LoadInfo(const Request &req)
- {
- _version = req._version;
- // 读出资源
- string path = req._path;
- if (Util::ReadFile(path, &_body) == false)
- {
- _st_code = "404";
- _st_msg = "No Found";
- path = webRoot + errPage_404;
- Util::ReadFile(path, &_body);
- }
- else
- {
- _st_code = "200";
- _st_msg = "OK";
- }
- // 重新设置状态行(临时重定向)
- _st_code = "301";
- _st_msg = "Moved Permanently";
- // 设置报头
- _headers["Content-Length: "] = to_string(_body.size());
- _headers["Content-Type: "] = Util::GetSuffix(req._suffix);
- _headers["Location: "] = "http://www.baidu.com";
- return true;
- }
编译并启动服务器,通过浏览器发出请求,请求发出后,直接跳转到了百度首页,再发出请求:
通过
telnet获取服务器响应如下
关于重定向的使用场景:
- 永久重定向:网站更新,比如搜索引擎会定期访问网站,可以根据永久重定向进行更新。
- 临时重定向:跳转至指定页面,后续可能改变(登录页面、广告等)。
5. Cookie 缓存
Cookie,有时也用其复数形式 Cookies。Cookies,指某些网站为了辨别用户身份而储存在用户本地终端上的数据(通常经过加密)。Cookies最典型的应用是判定注册用户是否已经登录网站,用户可能会得到提示,是否在下一次进入此网站时保留用户信息以便简化登录手续,这些都是Cookies的功用。
HTTP协议本身是无状态的(不保存数据),主要的工作是完成 超文本传输,实际上用户在登录网站时,除了第一次需要手动登录外,后续一段时间内都不需要登录:

这个现象称为 会话保持,可以大大提高提升用户使用体验,那么无状态的
HTTP是如何实现 会话保持 的呢?答案是使用 Cookie,用户在第一次登录时,服务器的响应中会包含 Set-Cookie
: 账号&密码这个报头,浏览器会保存Cookie相关的信息,后续再访问该网站时,在请求中自动添加Cookie报头,服务器完成验证后即可实现自动登录: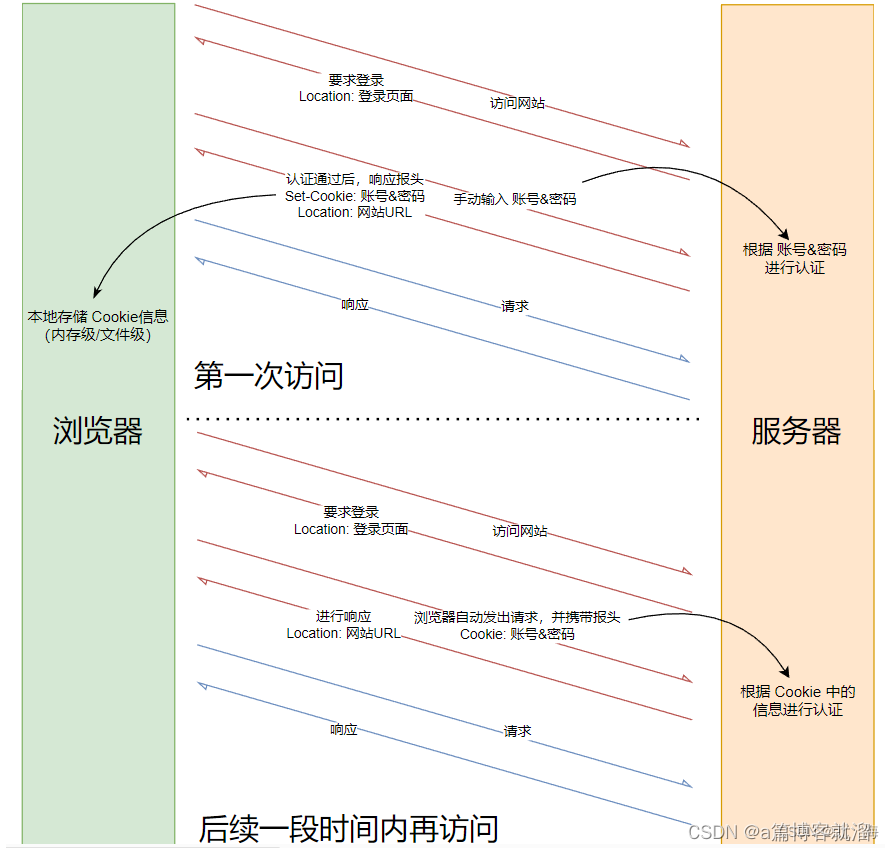
用户后续一段时间内再访问该网站时,看似不需要登录,实际每次都在使用 Cookie 登录,不过这个工作是由浏览器自动完成的,用户几乎感知不到,可以查看浏览器中保存的 Cookie 信息。
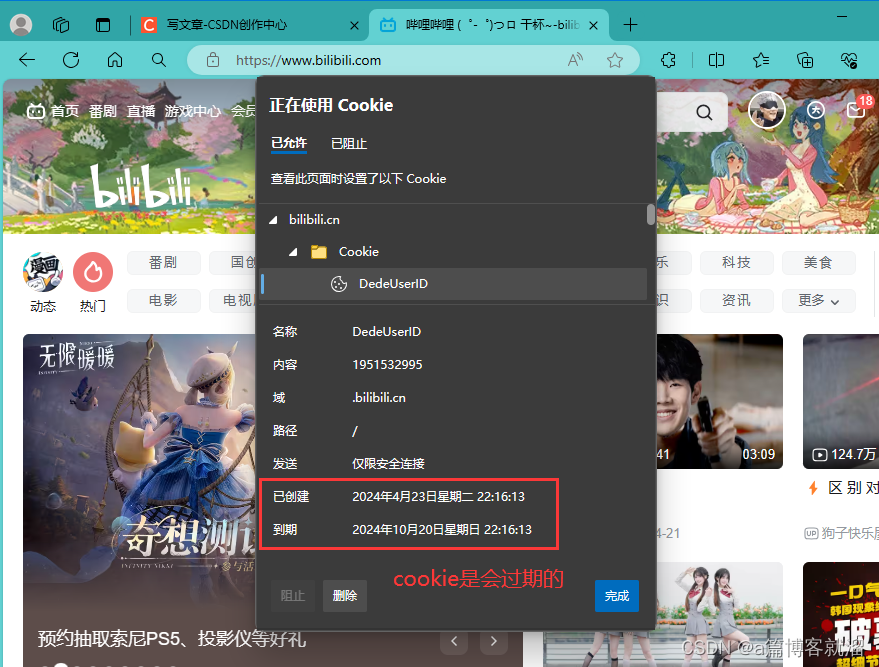
注意: Cookie 可以保存为内存级(只有本次使用浏览器期间有效,安全),也可以保存为文件级(关闭浏览器后仍然有效,方便)。
我们点击网址左边的锁图标可以查看cookie:
前面说过,无论是 GET 还是 POST 方法,都是不安全的,如果 HTTP 中关于 Cookie 的设计真这么简单(直接在报头中携带 账号&密码),那么账号早被盗用了。
木马病毒:
这是一种植入性病毒,如果我们下载了携带病毒的软件,或者是访问了不安全的网站,就有可能导致 Cookie 泄漏,当其他人掌握 Cookie 时,就可以利用该 Cookie 直接登录网站,窃取关键信息。真正的 Cookie 使用了这样一个解决方案:
- 根据 账号&密码 生成
session对象,将session对象id作为Set-Cookie的值传给浏览器。 - 登录时,只需要判断
id是否存在 session id具有唯一性

使用了
seesion id就能避免Cookie泄漏吗?- 不能,照样会发生泄漏,但至少此时泄漏的不是敏感信息。
服务器可以制定安全策略,识别是否为异常登录:
- IP比对:识别登录用户的IP在短时间内是否发生了改变。
- 行为检测:识别用户是否存在异常信息,比如QQ突然大面积发生消息、添加好友。
当服务器判定异常登录后,就会释放服务器中存储的
session id,这就意味着原本的session id失效了,需要重新输入密码登录- 如果是用户,重新使用 账号&密码 登录后,获取服务器重新生成的
session id即可 - 其他人则无法登录,因为没有 账号&密码
session id对比直接存储 账号&密码 最大的优势在于session id更新成本低,且更加安全如何生成唯一的
session id
可以通过哈希加密算法进行计算,比如MD5、SHA256通过
HTTP服务器验证 浏览器在请求时会自动加上Cookie报头启动服务器,并使用浏览器进行访问,首先可以看到 浏览器已经存储了
Cookie信息,也就是服务器响应的session id
此时的请求是这样的
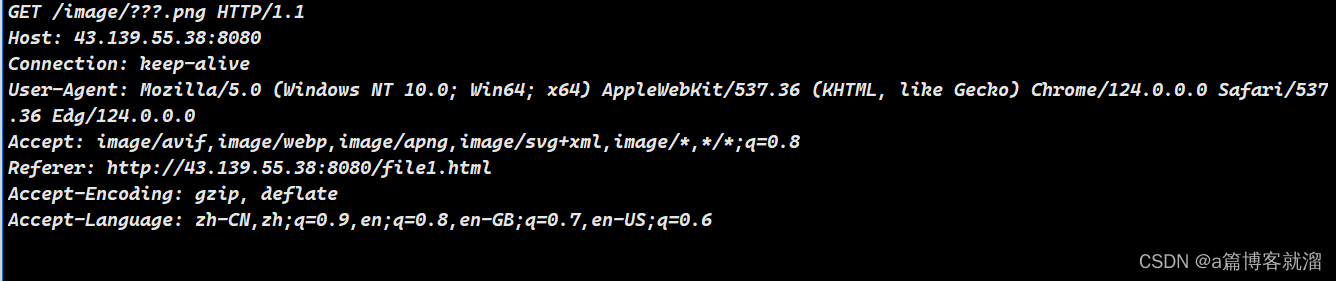
再次进行请求,请求就会变成这样,浏览器自动携带了
Cookie报头,服务器就可以通过session id进行验证了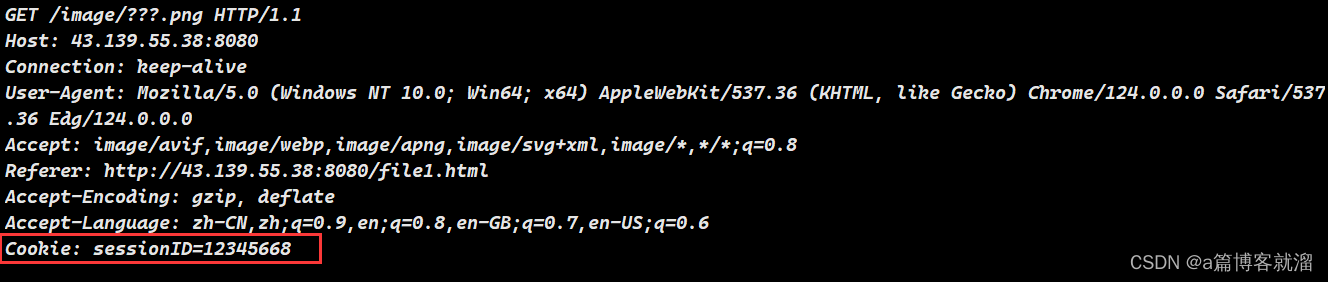
如何在服务器中实现
session?伪代码实现如下:
- class Response
- {
- // ...
- class Session
- {
- public:
- Session(const std::string& id, const std::string& passwd)
- :_id(id), _passwd(passwd)
- {}
- ~Session()
- {}
- public:
- std::string _id;
- std::string _passwd;
- std::string _login_time; // 登录时间
- std::string _status; // 用户状态
- };
- // 首次登录
- int Login(const Request& req)
- {
- // 获取 账号&密码 等关键字段
- std::string id, passwd;
- GetValue(req, &id, &passwd);
- // 判断用户是否存在、密码是否正确
- if(Check(id, passwd) == true)
- {
- // 根据关键字段构建 session 对象
- Session* ss = new Session(id, passwd);
- // 根据 session 对象生成 session id
- int ssID = SessionMD5(ss);
- // 存储映射关系
- _sessions[ssID] = ss;
- // 返回 ssID
- return ssID;
- }
- return 0;
- }
- std::unordered_map<int, Session*> _sessions;
- // ...
- };
当浏览器获取到
session id后,会使用session id进行判断,可以将_sessions中的数据写入文件中,将session id与session对象的映射关系持久化存储。也可以使用
Redis这种关系型数据库存储映射关系,更加高效。6. 补充
常见的
Header如下表所示
关于
Connection属性,一个网页中包含多份资源,每一份资源的都需要发起一个单独的HTTP请求,为了避免请求时与服务器的连接断开(也为了提高效率),可以设置keep-alive表示 长连接 默认,确保所有的资源都能请求完成。关于
/favicon.ico资源,这是一个小图标,显示在网页标题的左侧,添加之后可以提高网页的辨识度,这个资源由浏览器自动发起请求
-
相关阅读:
生成式 AI 落地制造业的关键是什么?亚马逊云科技给出答案
每天五分钟计算机视觉:使用神经网络完成人脸的特征点检测
GitLab首席执行官的日常
HTML常用标签
调用API来获取拼多多的商品数据的详细步骤和注意事项
72. 编辑距离
【开源】基于Vue.js的智能停车场管理系统的设计和实现
『亚马逊云科技产品测评』活动征文|AWS 存储产品类别及其适用场景详细说明
kafka生产者如何提高吞吐量
Vue.js入门教程(六)
- 原文地址:https://blog.csdn.net/weixin_61522065/article/details/137995774
