-
Flink CDC详解
文章目录
Flink CDC
一 CDC简介
1.1 CDC定义
CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。
1.2 CDC应用场景
-
**数据同步:**用于备份,容灾;
-
**数据分发:**一个数据源分发给多个下游系统;
-
**数据采集:**面向数据仓库 / 数据湖的 ETL 数据集成,是非常重要的数据源。
1.3 CDC实现机制
-
基于查询的 CDC机制:
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 不保障实时性,基于离线调度存在天然的延迟。
-
基于日志的 CDC机制:
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
1.4 开源CDC工具对比
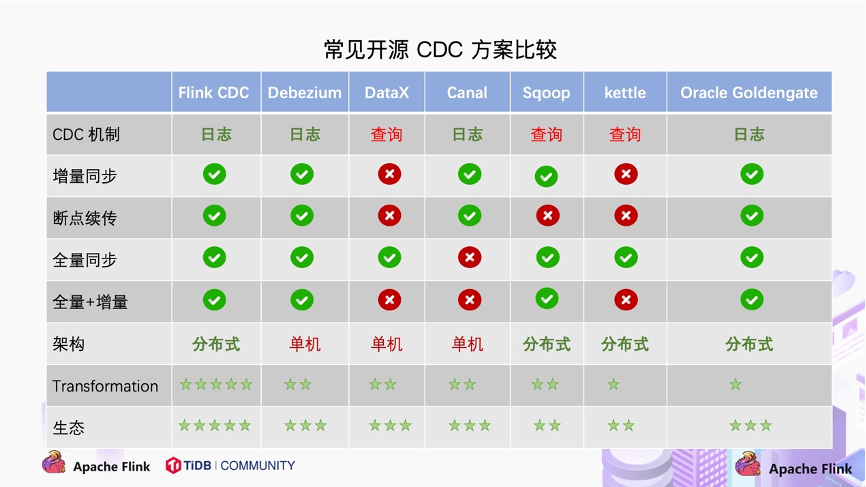
从上图可知:
-
基于日志的CDC机制,除Canal都可以很好的做到增量同步。
-
基于查询的CDC机制,增量和断点几乎都不支持,除Sqoop支持增量方式。
-
从全量同步维度看,除Canal不支持全量同步,其它的CDC都支持。
-
从全量+增量角度看,基于日志方式的CDC都是支持的。
-
从架构角度去看,该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。
-
在数据转换 / 数据清洗能力上,当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合?
- 在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
- 像 DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。
-
在生态方面,这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
二 Flink CDC简介
2.1 Flink CDC介绍
Flink CDC本质是一组数据源连接器,使用
更改数据捕获(CDC)从不同的数据库中摄取更改。Apache Flink®的CDC连接器集成了Debezium作为捕获数据更改的引擎,所以它可以充分利用Debezium的能力。
2.2 Flink CDC Connector(连接器)
Connector Database Driver mongodb-cdc MongoDB: 3.6, 4.x, 5.0 MongoDB Driver: 4.3.1 mysql-cdc MySQL: 5.6, 5.7, 8.0.xRDS MySQL: 5.6, 5.7, 8.0.xPolarDB MySQL: 5.6, 5.7, 8.0.xAurora MySQL: 5.6, 5.7, 8.0.xMariaDB: 10.xPolarDB X: 2.0.1 JDBC Driver: 8.0.27 oceanbase-cdc OceanBase CE: 3.1.xOceanBase EE (MySQL mode): 2.x, 3.x JDBC Driver: 5.1.4x oracle-cdc Oracle: 11, 12, 19 Oracle Driver: 19.3.0.0 postgres-cdc PostgreSQL: 9.6, 10, 11, 12 JDBC Driver: 42.2.12 sqlserver-cdc Sqlserver: 2012, 2014, 2016, 2017, 2019 JDBC Driver: 7.2.2.jre8 tidb-cdc TiDB: 5.1.x, 5.2.x, 5.3.x, 5.4.x, 6.0.0 JDBC Driver: 8.0.27 db2-cdc Db2: 11.5 DB2 Driver: 11.5.0.0 2.3 Flink CDC && Flink版本
Flink®CDC Connectors与Flink®的版本配套关系如下表所示:
Flink® CDC Version Flink® Version 1.0.0 1.11.* 1.1.0 1.11.* 1.2.0 1.12.* 1.3.0 1.12.* 1.4.0 1.13.* 2.0.* 1.13.* 2.1.* 1.13.* 2.2.* 1.13., 1.14. 2.3.* 1.13., 1.14., 1.15.*, 1.16.0 2.4 Flink CDC特点
-
支持读取数据库快照,即使发生故障,也可以只读取一次binlog。
-
CDC连接器用于DataStream API,用户可以在一个作业中对多个数据库和表进行更改,而无需部署Debezium和Kafka。
-
用于表/SQL API的CDC连接器,用户可以使用SQL DDL创建CDC源来监视单个表上的更改。
三 Flink CDC发展
3.1 发展历程
-
2020 年 7 月由云邪提交了第一个 commit,这是基于个人兴趣孵化的项目;
-
2020 年 7 中旬支持了 MySQL-CDC;
-
2020 年 7 月末支持了 Postgres-CDC;
-
2021年2月27,release-1.2.0发布,支持Flink version to 1.12.1,同时支持Debezium version to 1.4.1.Final版本。
-
2021年5月12,release-1.4.0发布,支持Flink version to 1.13.0。
-
2021年8月11,release-2.0.0发布,支持Flink version to 1.13.1,支持MySQL-CDC 2.0,提供并行读取,无锁和检查点功能。
-
2021年11月15,release-2.1.0发布,新增MongoDB-CDC和Oracle-CDC,同时吸引一大堆贡献者。
-
2022年3月27,release-2.2.0发布,兼容Flink version to 1.14,同时新增TiDB-CDC,SQL-Server CDC,oceanbase CDC等。
-
2022年11月10,release-2.3.0发布,当前最新稳定版本。
3.2 背景
Dynamic Table & ChangeLog Stream
大家都知道 Flink 有两个基础概念:Dynamic Table 和 Changelog Stream。
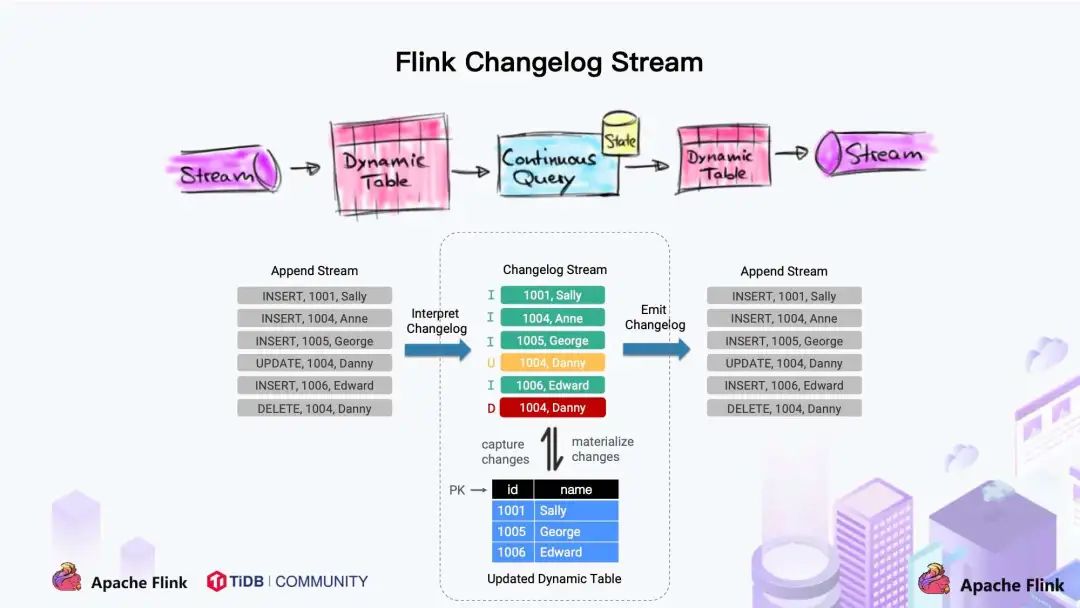
- Dynamic Table 就是 Flink SQL 定义的动态表,动态表和流的概念是对等的。参照上图,流可以转换成动态表,动态表也可以转换成流。
- 在 Flink SQL中,数据在从一个算子流向另外一个算子时都是以 Changelog Stream 的形式,任意时刻的 Changelog Stream 可以翻译为一个表,也可以翻译为一个流。
联想下 MySQL 中的表和 binlog 日志,就会发现:MySQL 数据库的一张表所有的变更都记录在 binlog 日志中,如果一直对表进行更新,binlog 日志流也一直会追加,数据库中的表就相当于 binlog 日志流在某个时刻点物化的结果;日志流就是将表的变更数据持续捕获的结果。这说明 Flink SQL 的 Dynamic Table 是可以非常自然地表示一张不断变化的 MySQL 数据库表。

在此基础上,我们调研了一些 CDC 技术,最终选择了 Debezium 作为 Flink CDC 的底层采集工具。Debezium 支持全量同步,也支持增量同步,也支持全量 + 增量的同步,非常灵活,同时基于日志的 CDC 技术使得提供 Exactly-Once 成为可能。
将 Flink SQL 的内部数据结构 RowData 和 Debezium 的数据结构进行对比,可以发现两者是非常相似的。
- 每条 RowData 都有一个元数据 RowKind,包括 4 种类型, 分别是插入 (INSERT)、更新前镜像 (UPDATE_BEFORE)、更新后镜像 (UPDATE_AFTER)、删除 (DELETE),这四种类型和数据库里面的 binlog 概念保持一致。
- 而 Debezium 的数据结构,也有一个类似的元数据 op 字段, op 字段的取值也有四种,分别是 c、u、d、r,各自对应 create、update、delete、read。对于代表更新操作的 u,其数据部分同时包含了前镜像 (before) 和后镜像 (after)。
通过分析两种数据结构,Flink 和 Debezium 两者的底层数据是可以非常方便地对接起来的,大家可以发现 Flink 做 CDC 从技术上是非常合适的。
3.3 传统 CDC ETL 分析
我们来看下传统 CDC 的 ETL 分析链路,如下图所示:
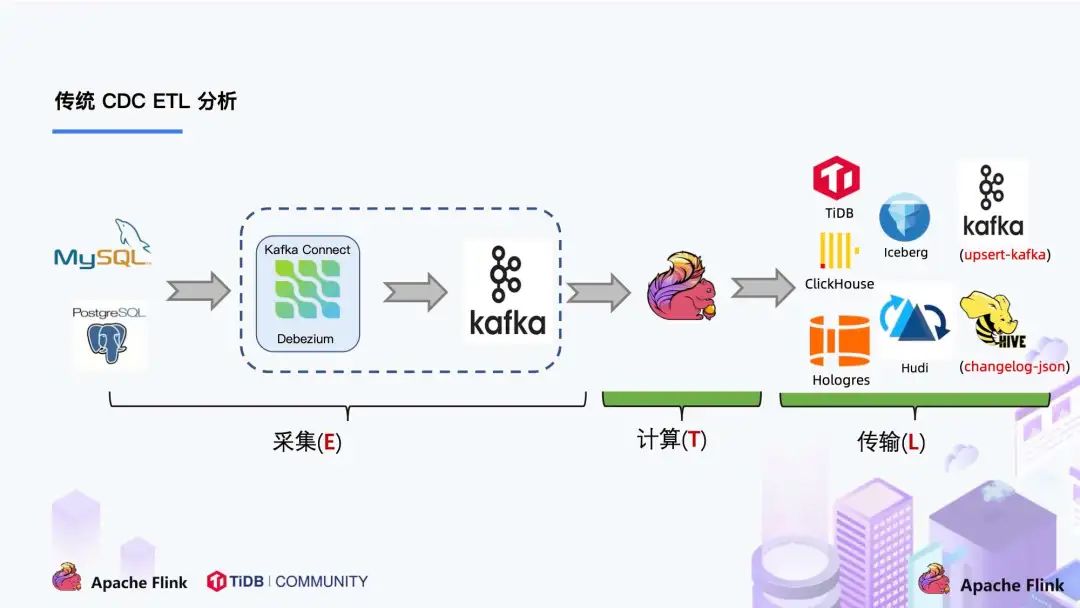
传统的基于 CDC 的 ETL 分析中,数据采集工具是必须的,国外用户常用 Debezium,国内用户常用阿里开源的 Canal,采集工具负责采集数据库的增量数据,一些采集工具也支持同步全量数据。采集到的数据一般输出到消息中间件如 Kafka,然后 Flink 计算引擎再去消费这一部分数据写入到目的端,目的端可以是各种 DB,数据湖,实时数仓和离线数仓。
注意
- Flink 提供了 changelog-json format,可以将 changelog 数据写入离线数仓如 Hive / HDFS;对于实时数仓,Flink 支持将 changelog 通过 upsert-kafka connector 直接写入 Kafka。
- 实时通常讲究效率,缩短链路通常是效率提升的一种方式,于是将上图中虚线框中的内容合二为一,则变成了Flink CDC的最佳实现。
3.4 基于 Flink CDC 的 ETL 分析
在使用了 Flink CDC 之后,除了组件更少,维护更方便外,另一个优势是通过 Flink SQL 极大地降低了用户使用门槛,可以看下面的例子:
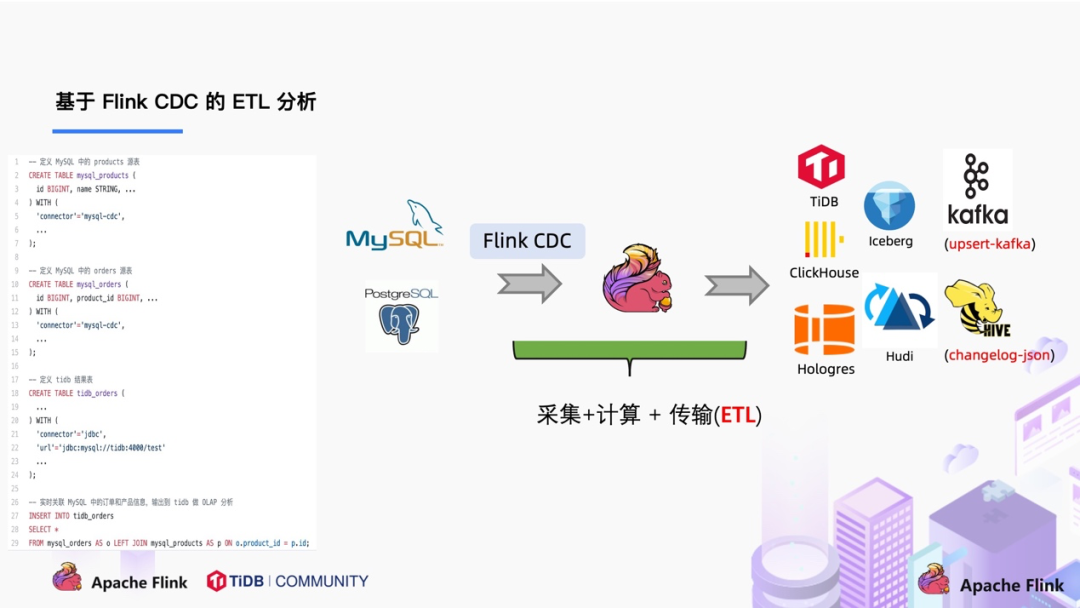
该例子是通过 Flink CDC 去同步数据库数据并写入到 TiDB,用户直接使用 Flink SQL 创建了产品和订单的 MySQL-CDC 表,然后对数据流进行 JOIN 加工,加工后直接写入到下游数据库。通过一个 Flink SQL 作业就完成了 CDC 的数据分析,加工和同步。
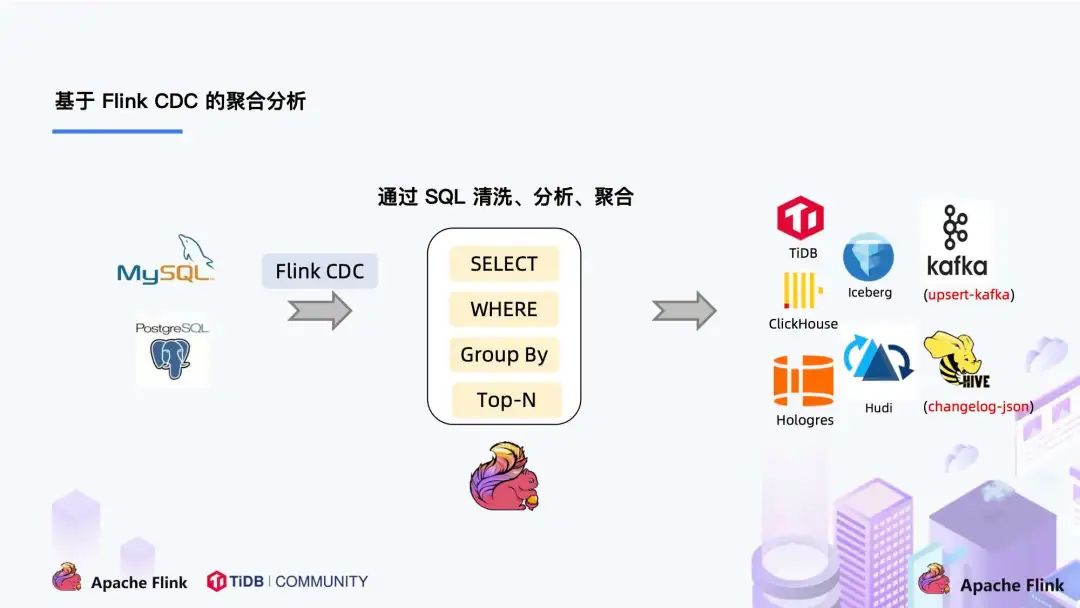
大家会发现这是一个纯 SQL 作业,这意味着只要会 SQL 的 BI,业务线同学都可以完成此类工作。与此同时,用户也可以利用 Flink SQL 提供的丰富语法进行数据清洗、分析、聚合。
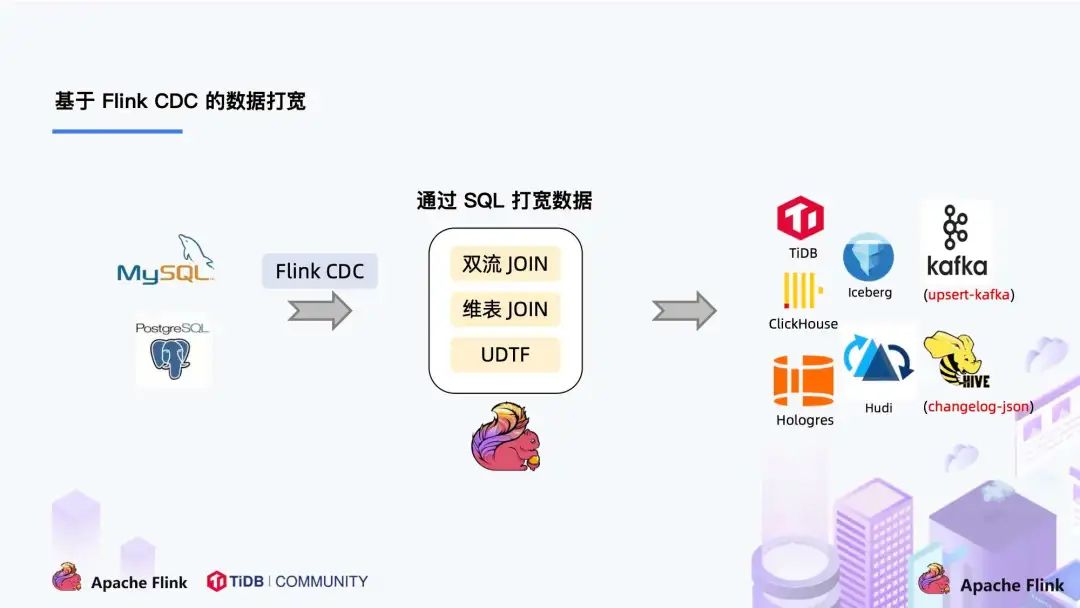
此外,利用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法可以非常容易地完成数据打宽,以及各种业务逻辑加工。
Flink CDC 1.x痛点
-
全量 + 增量读取的过程需要保证所有数据的一致性:因此需要通过加锁保证,但是加锁在数据库层面上是一个十分高危的操作。底层 Debezium 在保证数据一致性时,需要对读取的库或表加锁,全局锁可能导致数据库锁住,表级锁会锁住表的读,DBA 一般不给锁权限。Flink CDC 1.x 可以不加锁,能够满足大部分场景,但牺牲了一定的数据准确性。
Flink CDC 1.x 默认加全局锁,虽然能保证数据一致性,加锁的时间不确定,但存在上述 hang 住数据的风险。 -
不支持水平扩展:因为 Flink CDC 底层是基于 Debezium,起架构是单节点,所以Flink CDC 只支持单并发。在全量阶段读取阶段,如果表非常大 (亿级别),读取时间在小时甚至天级别,用户不能通过增加资源去提升作业速度。 -
全量读取阶段不支持 checkpoint:CDC 读取分为两个阶段,全量读取和增量读取,目前全量读取阶段是不支持 checkpoint 的,因此会存在一个问题:当我们同步全量数据时,假设需要 5 个小时,当我们同步了 4 小时的时候作业失败,这时候就需要重新开始,再读取 5 个小时。
Flink CDC 2.0设计
2.0 的设计方案,核心要解决上述的三个问题,即支持无锁、水平扩展和Checkpoint。
这篇论文里描述的无锁算法如下图所示:
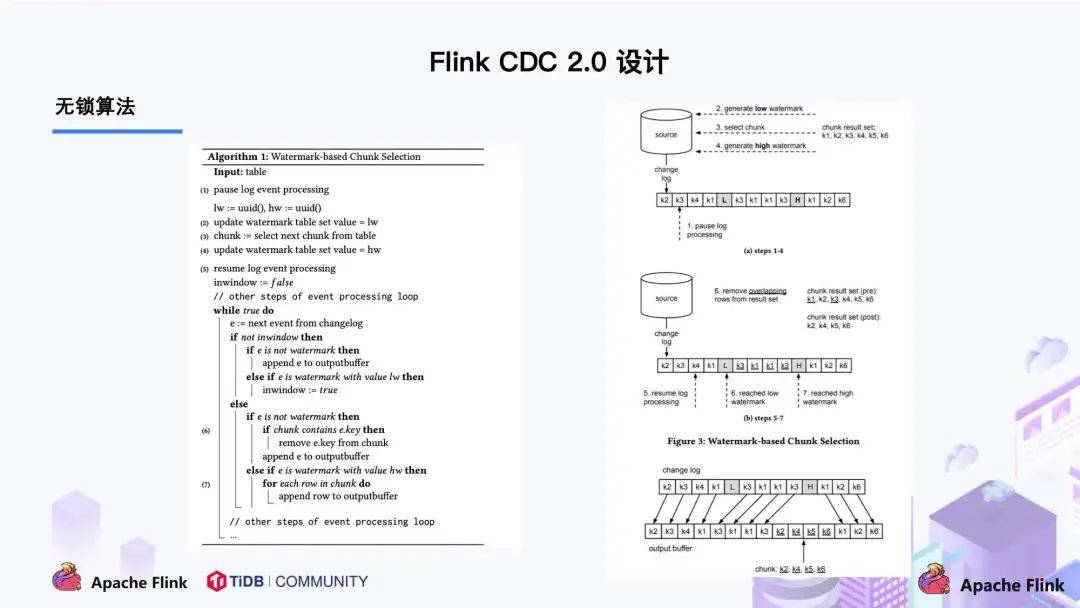
左边是 Chunk 的切分算法描述,Chunk 的切分算法其实和很多数据库的分库分表原理类似,通过表的主键对表中的数据进行分片。假设每个 Chunk 的步长为 10,按照这个规则进行切分,只需要把这些 Chunk 的区间做成左开右闭或者左闭右开的区间,保证衔接后的区间能够等于表的主键区间即可。
右边是每个 Chunk 的无锁读算法描述,该算法的核心思想是在划分了 Chunk 后,对于每个 Chunk 的全量读取和增量读取,在不用锁的条件下完成一致性的合并。Chunk 的切分如下图所示:
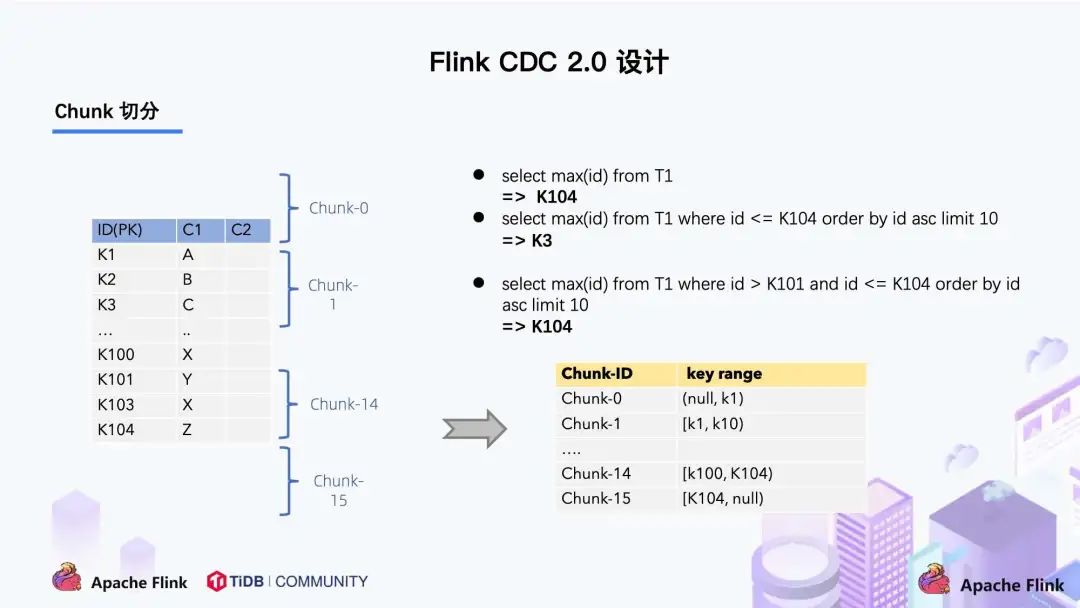
因为每个 chunk 只负责自己主键范围内的数据,不难推导,只要能够保证每个 Chunk 读取的一致性,就能保证整张表读取的一致性,这便是无锁算法的基本原理。
Flink CDC未来规划
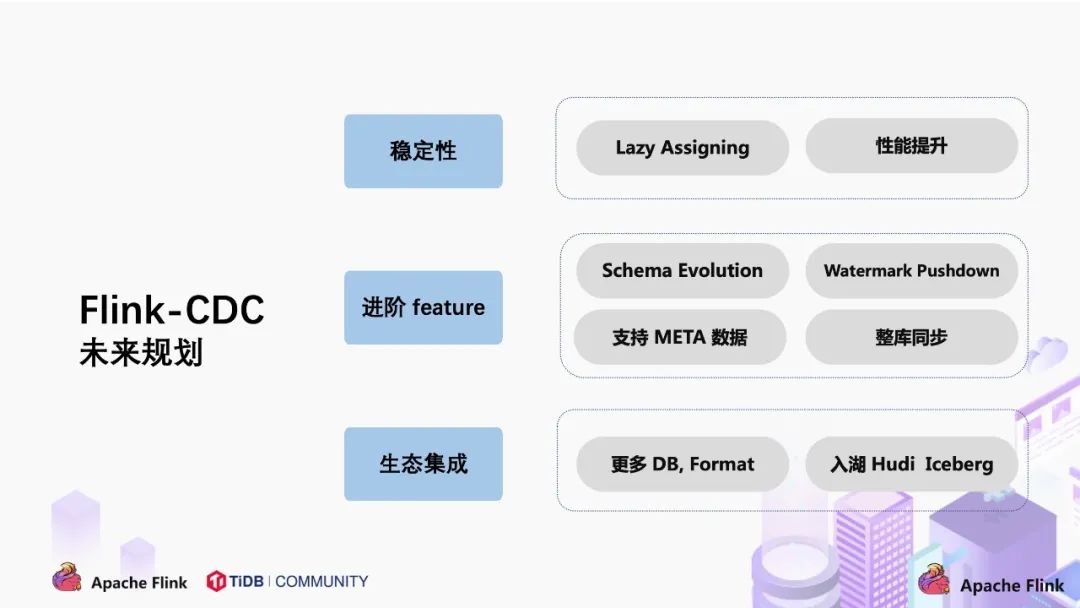
关于 CDC 项目的未来规划,我们希望围绕稳定性,进阶 feature 和生态集成三个方面展开。
-
稳定性
- 通过社区的方式吸引更多的开发者,公司的开源力量提升 Flink CDC 的成熟度;
- 支持 Lazy Assigning。Lazy Assigning 的思路是将 chunk 先划分一批,而不是一次性进行全部划分。当前 Source Reader 对数据读取进行分片是一次性全部划分好所有 chunk,例如有 1 万个 chunk,可以先划分 1 千个 chunk,而不是一次性全部划分,在 SourceReader 读取完 1 千 chunk 后再继续划分,节约划分 chunk 的时间。
-
进阶 Feature
- 支持 Schema Evolution。这个场景是:当同步数据库的过程中,突然在表中添加了一个字段,并且希望后续同步下游系统的时候能够自动加入这个字段;
- 支持 Watermark Pushdown 通过 CDC 的 binlog 获取到一些心跳信息,这些心跳的信息可以作为一个 Watermark,通过这个心跳信息可以知道到这个流当前消费的一些进度;
- 支持 META 数据,分库分表的场景下,有可能需要元数据知道这条数据来源哪个库哪个表,在下游系统入湖入仓可以有更多的灵活操作;
- 整库同步:用户要同步整个数据库只需一行 SQL 语法即可完成,而不用每张表定义一个 DDL 和 query。
-
生态集成
- 集成更多上游数据库,如 Oracle,MS SqlServer。Cloudera 目前正在积极贡献 oracle-cdc connector;
- 在入湖层面,Hudi 和 Iceberg 写入上有一定的优化空间,例如在高 QPS 入湖的时候,数据分布有比较大的性能影响,这一点可以通过与生态打通和集成继续优化。
四 Table & SQL API应用
使用提供的连接器设置Flink集群需要几个步骤。
- 使用1.12+版本和Java 8+安装Flink集群。
- 从下载页面下载连接器SQL jar(或者自己构建)。
- 将下载的jar放在FLINK_HOME/lib/目录下。
- 重新启动Flink集群。
这个例子展示了如何在Flink SQL Client中创建MySQL CDC源并对其执行查询。
-- creates a mysql cdc table source CREATE TABLE mysql_binlog ( id INT NOT NULL, name STRING, description STRING, weight DECIMAL(10,3), PRIMARY KEY(id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'flinkuser', 'password' = 'flinkpw', 'database-name' = 'inventory', 'table-name' = 'products' ); -- read snapshot and binlog data from mysql, and do some transformation, and show on the client SELECT id, UPPER(name), description, weight FROM mysql_binlog;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
五 DataStream API应用
包括以下Maven依赖项(可通过Maven Central获得):
<dependency> <groupId>com.ververicagroupId> <artifactId>flink-connector-mysql-cdcartifactId> <version>2.4-SNAPSHOTversion> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema; import com.ververica.cdc.connectors.mysql.source.MySqlSource; public class MySqlBinlogSourceExample { public static void main(String[] args) throws Exception { MySqlSource<String> mySqlSource = MySqlSource.<String>builder() .hostname("yourHostname") .port(yourPort) .databaseList("yourDatabaseName") // set captured database .tableList("yourDatabaseName.yourTableName") // set captured table .username("yourUsername") .password("yourPassword") .deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String .build(); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // enable checkpoint env.enableCheckpointing(3000); env .fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source") // set 4 parallel source tasks .setParallelism(4) .print().setParallelism(1); // use parallelism 1 for sink to keep message ordering env.execute("Print MySQL Snapshot + Binlog"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
六 Flink CDC Connector
6.1 MySQL CDC 连接器
MySQL CDC 连接器允许从 MySQL 数据库读取快照数据和增量数据。如下描述了如何设置 MySQL CDC 连接器来对 MySQL 数据库运行 SQL 查询。
支持的数据库
Connector Database Driver mysql-cdc MySQL: 5.6, 5.7, 8.0.xRDS MySQL: 5.6, 5.7, 8.0.xPolarDB MySQL: 5.6, 5.7, 8.0.xAurora MySQL: 5.6, 5.7, 8.0.xMariaDB: 10.xPolarDB X: 2.0.1 JDBC Driver: 8.0.21 为了设置 MySQL CDC 连接器,下表提供了使用构建自动化工具(如 Maven 或 SBT )和带有 SQL JAR 包的 SQL 客户端的两个项目的依赖关系信息。
Maven dependency
com.ververica flink-connector-mysql-cdc 2.2.1 - 1
- 2
- 3
- 4
- 5
- 6
SQL Client JAR
下载链接仅在已发布版本可用,请在文档网站左下角选择浏览已发布的版本。- 1
下载 flink-sql-connector-mysql-cdc-2.2.1.jar 到
/lib/ 注意:
flink-sql-connector-mysql-cdc-XXX-SNAPSHOT 版本是开发分支
release-XXX对应的快照版本,快照版本用户需要下载源代码并编译相应的 jar。用户应使用已经发布的版本,例如 flink-sql-connector-mysql-cdc-2.2.1.jar 当前已发布的所有版本都可以在 Maven 中央仓库获取。为每个 Reader 设置不同的 Server id
每个用于读取 binlog 的 MySQL 数据库客户端都应该有一个唯一的 id,称为 Server id。 MySQL 服务器将使用此 id 来维护网络连接和 binlog 位置。 因此,如果不同的作业共享相同的 Server id, 则可能导致从错误的 binlog 位置读取数据。 因此,建议通过为每个 Reader 设置不同的 Server id SQL Hints, 假设 Source 并行度为 4, 我们可以使用
SELECT * FROM source_table /*+ OPTIONS('server-id'='5401-5404') */ ;来为 4 个 Source readers 中的每一个分配唯一的 Server id。设置 MySQL 会话超时时间
当为大型数据库创建初始一致快照时,你建立的连接可能会在读取表时碰到超时问题。你可以通过在 MySQL 侧配置 interactive_timeout 和 wait_timeout 来缓解此类问题。
interactive_timeout: 服务器在关闭交互连接之前等待活动的秒数。 更多信息请参考 MySQL documentations.wait_timeout: 服务器在关闭非交互连接之前等待活动的秒数。 更多信息请参考 MySQL documentations.
6.2 如何创建 MySQL CDC 表
# 启动flink集群 start-cluster.sh # 启动flink sql客户端 sql-client.sh- 1
- 2
- 3
- 4
MySQL中表结构定义:
CREATE TABLE `orders` ( `order_id` int NOT NULL, `order_date` datetime DEFAULT NULL, `customer_name` varchar(255) DEFAULT NULL, `price` decimal(10,5) DEFAULT NULL, `product_id` int DEFAULT NULL, `order_status` tinyint(1) DEFAULT NULL, PRIMARY KEY (`order_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
MySQL CDC 表可以定义如下:
-- 每 3 秒做一次 checkpoint,用于测试,生产配置建议5到10分钟 Flink SQL> SET 'execution.checkpointing.interval' = '3s'; -- 在 Flink SQL中注册 MySQL 表 'orders' Flink SQL> CREATE TABLE orders ( order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'qianfeng01', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'mydb', 'table-name' = 'orders'); -- 从订单表读取全量数据(快照)和增量数据(binlog) Flink SQL> SELECT * FROM orders;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
6.3 支持的元数据
下表中的元数据可以在 DDL 中作为只读(虚拟)meta 列声明。
Key DataType Description table_name STRING NOT NULL 当前记录所属的表名称。 database_name STRING NOT NULL 当前记录所属的库名称。 op_ts TIMESTAMP_LTZ(3) NOT NULL 当前记录表在数据库中更新的时间。 如果从表的快照而不是 binlog 读取记录,该值将始终为0。 下述创建表示例展示元数据列的用法:
-- 在 Flink SQL中注册 MySQL 表 'products' Flink SQL> CREATE TABLE products ( db_name STRING METADATA FROM 'database_name' VIRTUAL, table_name STRING METADATA FROM 'table_name' VIRTUAL, operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL, order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'mydb', 'table-name' = 'orders' ); -- 订单状态实时分布 Flink SQL> select order_status,count(order_id) from products group by order_status;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
6.4 动态加表
扫描新添加的表功能使你可以添加新表到正在运行的作业中,新添加的表将首先读取其快照数据,然后自动读取其变更日志。
想象一下这个场景:一开始, Flink 作业监控表
[product, user, address], 但几天后,我们希望这个作业还可以监控表[order, custom],这些表包含历史数据,我们需要作业仍然可以复用作业的已有状态,动态加表功能可以优雅地解决此问题。以下操作显示了如何启用此功能来解决上述场景。 使用现有的 Flink CDC Source 作业,如下:
MySqlSource<String> mySqlSource = MySqlSource.<String>builder() .hostname("yourHostname") .port(yourPort) .scanNewlyAddedTableEnabled(true) // 启用扫描新添加的表功能 .databaseList("db") // 设置捕获的数据库 .tableList("db.product, db.user, db.address") // 设置捕获的表 [product, user, address] .username("yourUsername") .password("yourPassword") .deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串 .build(); // 你的业务代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果我们想添加新表
[order, custom]对于现有的 Flink 作业,只需更新tableList()将新增表[order, custom]加入并从已有的 savepoint 恢复作业。Step 1: 使用 savepoint 停止现有的 Flink 作业。
$ ./bin/flink stop $Existing_Flink_JOB_ID Suspending job "cca7bc1061d61cf15238e92312c2fc20" with a savepoint. Savepoint completed. Path: file:/tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab- 1
- 2
- 3
Step 2: 更新现有 Flink 作业的表列表选项。
- 更新
tableList()参数. - 编译更新后的作业,示例如下:
MySqlSource<String> mySqlSource = MySqlSource.<String>builder() .hostname("yourHostname") .port(yourPort) .scanNewlyAddedTableEnabled(true) .databaseList("db") .tableList("db.product, db.user, db.address, db.order, db.custom") // 设置捕获的表 [product, user, address ,order, custom] .username("yourUsername") .password("yourPassword") .deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串 .build(); // 你的业务代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Step 3: 从 savepoint 还原更新后的 Flink 作业。
$ ./bin/flink run \ --detached \ --fromSavepoint /tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab \ ./FlinkCDCExample.jar- 1
- 2
- 3
- 4
七 Flink CDC案例一
7.1 基于 Flink CDC 构建 MySQL 和 Postgres 的 Streaming ETL
这篇教程将展示如何基于 Flink CDC 快速构建 MySQL 和 Postgres 的流式 ETL。本教程的演示都将在 Flink SQL CLI 中进行,只涉及 SQL,无需一行 Java/Scala 代码,也无需安装 IDE。
假设我们正在经营电子商务业务,商品和订单的数据存储在 MySQL 中,订单对应的物流信息存储在 Postgres 中。 对于订单表,为了方便进行分析,我们希望让它关联上其对应的商品和物流信息,构成一张宽表,并且实时把它写到 ElasticSearch 中。
接下来的内容将介绍如何使用 Flink Mysql/Postgres CDC 来实现这个需求,系统的整体架构如下图所示:
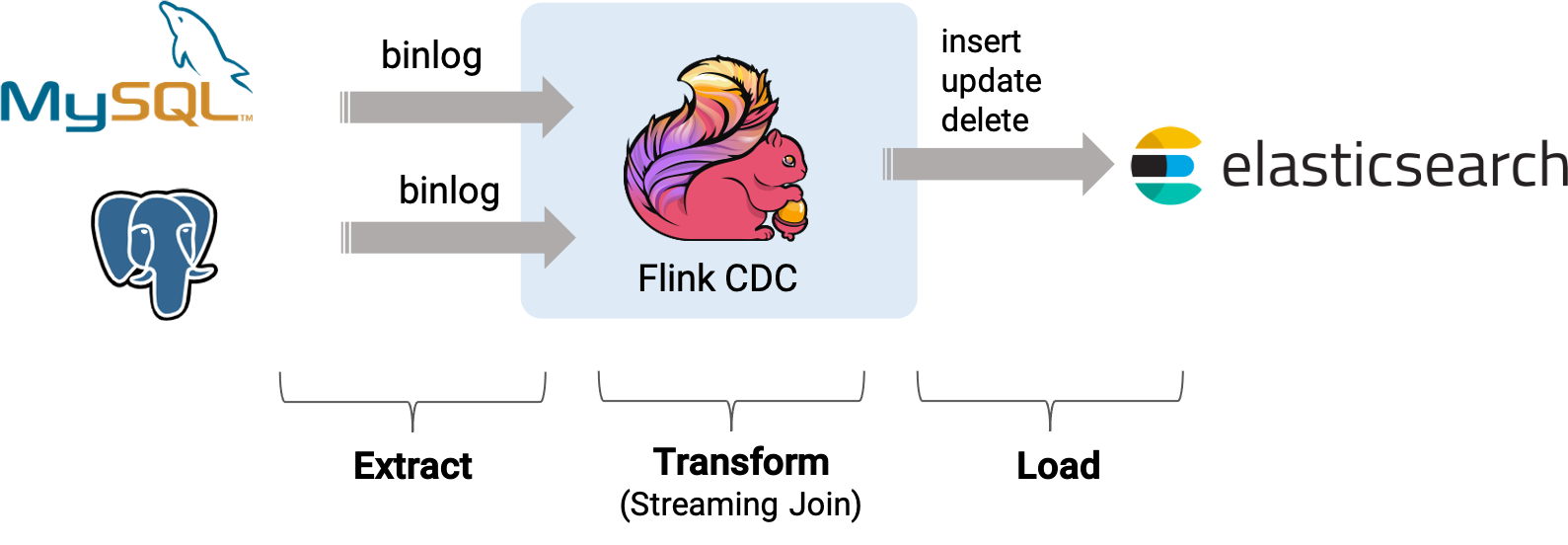
7.2 在 Flink SQL CLI 中使用 Flink DDL 创建表
首先,开启 checkpoint,每隔3秒做一次 checkpoint
-- Flink SQL Flink SQL> SET execution.checkpointing.interval = 3s;- 1
- 2
然后, 对于数据库中的表
products,orders,shipments, 使用 Flink SQL CLI 创建对应的表,用于同步这些底层数据库表的数据-- Flink SQL Flink SQL> CREATE TABLE products ( id INT, name STRING, description STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'mydb', 'table-name' = 'products' ); Flink SQL> CREATE TABLE orders ( order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'mydb', 'table-name' = 'orders' ); Flink SQL> CREATE TABLE shipments ( shipment_id INT, order_id INT, origin STRING, destination STRING, is_arrived BOOLEAN, PRIMARY KEY (shipment_id) NOT ENFORCED ) WITH ( 'connector' = 'postgres-cdc', 'hostname' = 'localhost', 'port' = '5432', 'username' = 'postgres', 'password' = 'postgres', 'database-name' = 'postgres', 'schema-name' = 'public', 'table-name' = 'shipments' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
最后,创建
enriched_orders表, 用来将关联后的订单数据写入 Elasticsearch 中-- Flink SQL Flink SQL> CREATE TABLE enriched_orders ( order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, product_name STRING, product_description STRING, shipment_id INT, origin STRING, destination STRING, is_arrived BOOLEAN, PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'connector' = 'elasticsearch-7', 'hosts' = 'http://localhost:9200', 'index' = 'enriched_orders' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
7.3 关联订单数据并且将其写入 Elasticsearch 中
使用 Flink SQL 将订单表
order与 商品表products,物流信息表shipments关联,并将关联后的订单信息写入 Elasticsearch 中-- Flink SQL Flink SQL> INSERT INTO enriched_orders SELECT o.*, p.name, p.description, s.shipment_id, s.origin, s.destination, s.is_arrived FROM orders AS o LEFT JOIN products AS p ON o.product_id = p.id LEFT JOIN shipments AS s ON o.order_id = s.order_id;- 1
- 2
- 3
- 4
- 5
- 6
八 Flink CDC案例二
8.1 基于 Flink CDC 同步 MySQL 分库分表构建实时数据湖
在 OLTP 系统中,为了解决单表数据量大的问题,通常采用分库分表的方式将单个大表进行拆分以提高系统的吞吐量。 但是为了方便数据分析,通常需要将分库分表拆分出的表在同步到数据仓库、数据湖时,再合并成一个大表。
这篇教程将展示如何使用 Flink CDC 构建实时数据湖来应对这种场景,本教程的演示基于 Docker,只涉及 SQL,无需一行 Java/Scala 代码,也无需安装 IDE,你可以很方便地在自己的电脑上完成本教程的全部内容。
接下来将以数据从 MySQL 同步到 Iceberg 为例展示整个流程,架构图如下所示:

你也可以使用不同的 source 比如 Oracle/Postgres 和 sink 比如 Hudi 来构建自己的 ETL 流程。
8.2 准备教程所需要的组件
接下来的教程将以
docker-compose的方式准备所需要的组件。使用下面的内容创建一个
docker-compose.yml文件:version: '2.1' services: sql-client: user: flink:flink image: yuxialuo/flink-sql-client:1.13.2.v1 depends_on: - jobmanager - mysql environment: FLINK_JOBMANAGER_HOST: jobmanager MYSQL_HOST: mysql volumes: - shared-tmpfs:/tmp/iceberg jobmanager: user: flink:flink image: flink:1.13.2-scala_2.11 ports: - "8081:8081" command: jobmanager environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager volumes: - shared-tmpfs:/tmp/iceberg taskmanager: user: flink:flink image: flink:1.13.2-scala_2.11 depends_on: - jobmanager command: taskmanager environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager taskmanager.numberOfTaskSlots: 2 volumes: - shared-tmpfs:/tmp/iceberg mysql: image: debezium/example-mysql:1.1 ports: - "3306:3306" environment: - MYSQL_ROOT_PASSWORD=123456 - MYSQL_USER=mysqluser - MYSQL_PASSWORD=mysqlpw volumes: shared-tmpfs: driver: local driver_opts: type: "tmpfs" device: "tmpfs"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
该 Docker Compose 中包含的容器有:
- SQL-Client: Flink SQL Client, 用来提交 SQL 查询和查看 SQL 的执行结果
- Flink Cluster:包含 Flink JobManager 和 Flink TaskManager,用来执行 Flink SQL
- MySQL:作为分库分表的数据源,存储本教程的
user表
注意:
-
为了简化整个教程,本教程需要的 jar 包都已经被打包进 SQL-Client 容器中了,镜像的构建脚本可以在 GitHub 上找到。 如果你想要在自己的 Flink 环境运行本教程,需要下载下面列出的包并且把它们放在 Flink 所在目录的 lib 目录下,即
FLINK_HOME/lib/。下载链接只对已发布的版本有效, SNAPSHOT 版本需要本地编译
- flink-sql-connector-mysql-cdc-2.2.0.jar
- flink-shaded-hadoop-2-uber-2.7.5-10.0.jar
- iceberg-flink-1.13-runtime-0.13.0-SNAPSHOT.jar
目前支持 Flink 1.13 的
iceberg-flink-runtimejar 包还没有发布,所以我们在这里提供了一个支持 Flink 1.13 的iceberg-flink-runtimejar 包,这个 jar 包是基于 Iceberg 的 master 分支打包的。 当 Iceberg 0.13.0 版本发布后,你也可以在 apache official repository 下载到支持 Flink 1.13 的iceberg-flink-runtimejar 包。 -
本教程接下来用到的容器相关的命令都需要在
docker-compose.yml所在目录下执行
在
docker-compose.yml所在目录下执行下面的命令来启动本教程需要的组件:docker-compose up -d- 1
该命令将以 detached 模式自动启动 Docker Compose 配置中定义的所有容器。你可以通过
docker ps来观察上述的容器是否正常启动了,也可以通过访问 http://localhost:8081/ 来查看 Flink 是否运行正常。
8.3 准备数据
-
进入 MySQL 容器中
docker-compose exec mysql mysql -uroot -p123456- 1
-
创建数据和表,并填充数据
创建两个不同的数据库,并在每个数据库中创建两个表,作为
user表分库分表下拆分出的表。CREATE DATABASE db_1; USE db_1; CREATE TABLE user_1 ( id INTEGER NOT NULL PRIMARY KEY, name VARCHAR(255) NOT NULL DEFAULT 'flink', address VARCHAR(1024), phone_number VARCHAR(512), email VARCHAR(255) ); INSERT INTO user_1 VALUES (110,"user_110","Shanghai","123567891234","user_110@foo.com"); CREATE TABLE user_2 ( id INTEGER NOT NULL PRIMARY KEY, name VARCHAR(255) NOT NULL DEFAULT 'flink', address VARCHAR(1024), phone_number VARCHAR(512), email VARCHAR(255) ); INSERT INTO user_2 VALUES (120,"user_120","Shanghai","123567891234","user_120@foo.com");- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
CREATE DATABASE db_2; USE db_2; CREATE TABLE user_1 ( id INTEGER NOT NULL PRIMARY KEY, name VARCHAR(255) NOT NULL DEFAULT 'flink', address VARCHAR(1024), phone_number VARCHAR(512), email VARCHAR(255) ); INSERT INTO user_1 VALUES (110,"user_110","Shanghai","123567891234", NULL); CREATE TABLE user_2 ( id INTEGER NOT NULL PRIMARY KEY, name VARCHAR(255) NOT NULL DEFAULT 'flink', address VARCHAR(1024), phone_number VARCHAR(512), email VARCHAR(255) ); INSERT INTO user_2 VALUES (220,"user_220","Shanghai","123567891234","user_220@foo.com");- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
8.4 在 Flink SQL CLI 中使用 Flink DDL 创建表
首先,使用如下的命令进入 Flink SQL CLI 容器中:
docker-compose exec sql-client ./sql-client- 1
我们可以看到如下界面:

然后,进行如下步骤:
-
开启 checkpoint,每隔3秒做一次 checkpoint
Checkpoint 默认是不开启的,我们需要开启 Checkpoint 来让 Iceberg 可以提交事务。 并且,mysql-cdc 在 binlog 读取阶段开始前,需要等待一个完整的 checkpoint 来避免 binlog 记录乱序的情况。
-- Flink SQL Flink SQL> SET execution.checkpointing.interval = 3s;- 1
- 2
-
创建 MySQL 分库分表 source 表
创建 source 表
user_source来捕获MySQL中所有user表的数据,在表的配置项database-name,table-name使用正则表达式来匹配这些表。 并且,user_source表也定义了 metadata 列来区分数据是来自哪个数据库和表。-- Flink SQL Flink SQL> CREATE TABLE user_source ( database_name STRING METADATA VIRTUAL, table_name STRING METADATA VIRTUAL, `id` DECIMAL(20, 0) NOT NULL, name STRING, address STRING, phone_number STRING, email STRING, PRIMARY KEY (`id`) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'mysql', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'db_[0-9]+', 'table-name' = 'user_[0-9]+' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
-
创建 Iceberg sink 表
创建 sink 表
all_users_sink,用来将数据加载至 Iceberg 中。 在这个 sink 表,考虑到不同的 MySQL 数据库表的id字段的值可能相同,我们定义了复合主键 (database_name,table_name,id)。-- Flink SQL Flink SQL> CREATE TABLE all_users_sink ( database_name STRING, table_name STRING, `id` DECIMAL(20, 0) NOT NULL, name STRING, address STRING, phone_number STRING, email STRING, PRIMARY KEY (database_name, table_name, `id`) NOT ENFORCED ) WITH ( 'connector'='iceberg', 'catalog-name'='iceberg_catalog', 'catalog-type'='hadoop', 'warehouse'='file:///tmp/iceberg/warehouse', 'format-version'='2' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
8.5 流式写入 Iceberg
-
使用下面的 Flink SQL 语句将数据从 MySQL 写入 Iceberg 中
-- Flink SQL Flink SQL> INSERT INTO all_users_sink select * from user_source;- 1
- 2
上述命令将会启动一个流式作业,源源不断将 MySQL 数据库中的全量和增量数据同步到 Iceberg 中。 在 Flink UI 上可以看到这个运行的作业:
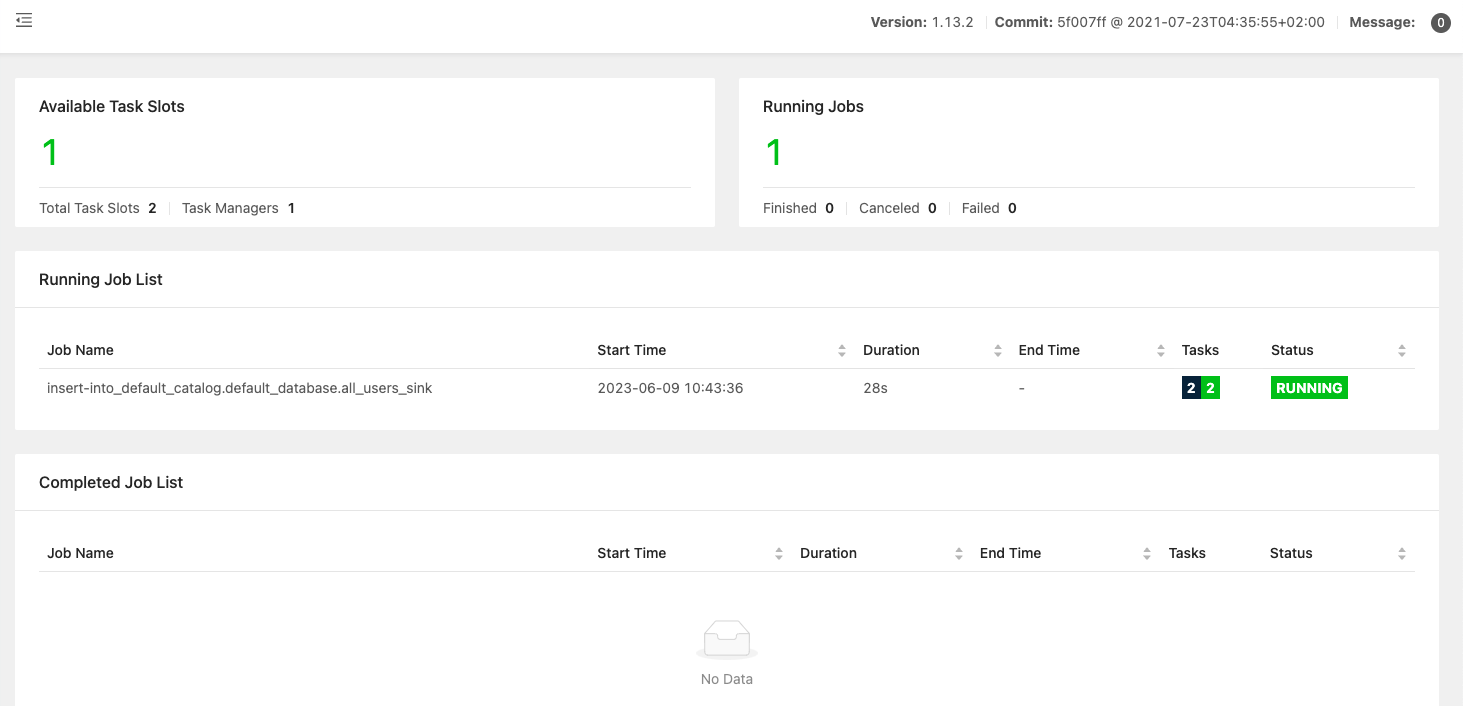
然后我们就可以使用如下的命令看到 Iceberg 中的写入的文件:
docker-compose exec sql-client tree /tmp/iceberg/warehouse/default_database/- 1
如下所示:
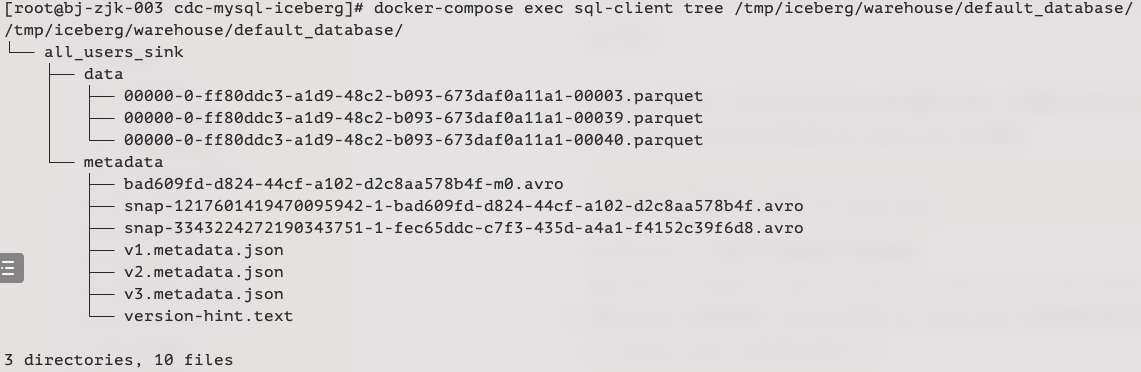
在你的运行环境中,实际的文件可能与上面的截图不相同,但是整体的目录结构应该相似。
-
使用下面的 Flink SQL 语句查询表
all_users_sink中的数据-- Flink SQL Flink SQL> SELECT * FROM all_users_sink;- 1
- 2
在 Flink SQL CLI 中我们可以看到如下查询结果:

-
修改 MySQL 中表的数据,Iceberg 中的表
all_users_sink中的数据也将实时更新:(3.1) 在
db_1.user_1表中插入新的一行--- db_1 INSERT INTO db_1.user_1 VALUES (111,"user_111","Shanghai","123567891234","user_111@foo.com");- 1
- 2
(3.2) 更新
db_1.user_2表的数据--- db_1 UPDATE db_1.user_2 SET address='Beijing' WHERE id=120;- 1
- 2
(3.3) 在
db_2.user_2表中删除一行--- db_2 DELETE FROM db_2.user_2 WHERE id=220;- 1
- 2
每执行一步,我们就可以在 Flink Client CLI 中使用
SELECT * FROM all_users_sink查询表all_users_sink来看到数据的变化。最后的查询结果如下所示:

从 Iceberg 的最新结果中可以看到新增了
(db_1, user_1, 111)的记录,(db_1, user_2, 120)的地址更新成了Beijing,且(db_2, user_2, 220)的记录被删除了,与我们在 MySQL 做的数据更新完全一致。
8.6 环境清理
本教程结束后,在
docker-compose.yml文件所在的目录下执行如下命令停止所有容器:docker-compose down- 1
参考
阿里云云栖号:https://baijiahao.baidu.com/s?id=1708018647118048692&wfr=spider&for=pc
Flink CDC官网:https://ververica.github.io/flink-cdc-connectors/release-2.2/content/about.html
-
-
相关阅读:
公众号留言功能怎么恢复?评论功能如何开启?
Cookie、Session、Token、JWT详解
jira提交bug规范
Windows调试技巧&工具
Webpack Sourcemap文件泄露漏洞
深入URP之Shader篇6: SimpleLit Shader分析(2) Vertex Shader
【mmsegmentation】
实用Pycharm插件
nodejs微信小程序-客户管理管理系统的设计与实现-安卓-python-PHP-计算机毕业设计推荐
ospf综合实验
- 原文地址:https://blog.csdn.net/u010839779/article/details/138160016
