-
《R语言与农业数据统计分析及建模》学习——描述性统计分析
一、描述性统计概念和方法
1、概念和作用
描述性统计是对数据进行概括和描述,便于理解数据的特征、趋势和分布,帮助我们了解数据基本情况和总体特征,为后续更深入的数据分析和建模提供基础。
2、基础方法
(1)中心趋势度量
数据的中心趋势度量是描述性统计中的一类指标,用于衡量数据的集中程度。
常见的中心趋势度量包括:平均值(mean)、中位数(median)和众数(mode)
- # 利用内置数据集iris进行平均数的计算
- # 计算平均值
- mean(iris$Sepal.Length)
- # 计算中位数
- median(iris$Sepal.Length)
- # 计算众数
- # 基础包中没有提供众数的计算函数,需用自编函数进行计算
- get_mode<-function(v){
- uniqv<-unique(v)
- uniqv[which.max(tabulate(match(v,uniqv)))]
- }
- get_mode(iris$Sepal.Length)

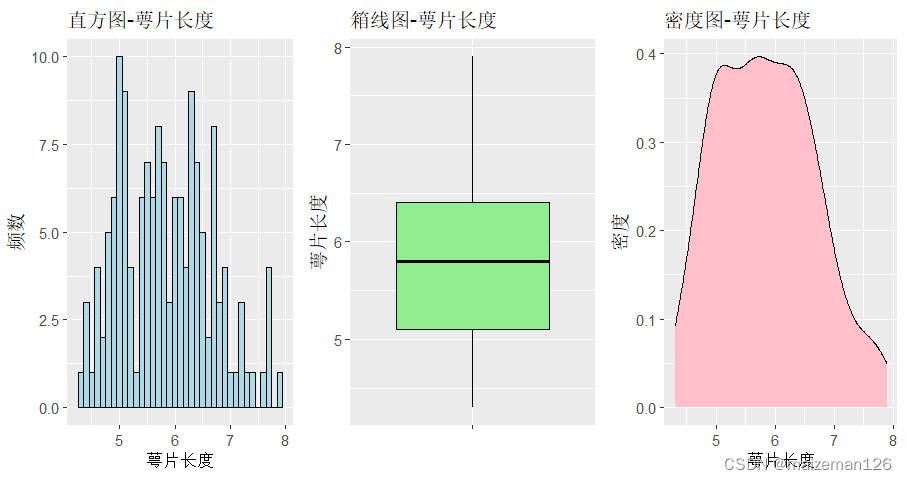
(2)中心趋势可视化
数据的中心趋势度量是描述性统计中的一类指标,用于衡量数据的集中程度。常用的可视化方法包括直方图、箱线图和密度图。
- # 导入ggplot2包
- library(ggplot2)
- # 导入gridExtra包
- library(gridExtra)
- # 绘制直方图
- p1<-ggplot(data=iris,aes(x=Sepal.Length))+geom_histogram(
- binwidth = 0.1,color="black",fill="lightblue"
- )+labs(
- title = "直方图-萼片长度",x="萼片长度",y="频数"
- )
- # 绘制箱线图
- p2<-ggplot(iris,aes(x="",y=Sepal.Length))+geom_boxplot(
- fill="lightgreen",color="black"
- )+labs(
- title='箱线图-萼片长度',x="",y="萼片长度"
- )
- # 绘制密度图
- p3<-ggplot(iris,aes(x=Sepal.Length))+geom_density(
- fill='pink',color='black'
- )+labs(
- title = "密度图-萼片长度",x="萼片长度",y="密度"
- )
- # 图表拼接
- grid.arrange(p1,p2,p3,ncol=3)
(3)离散程度度量
数据的离散程度度量用于衡量数据的分散程度或变异程度。常见的离散程度度量包括方差、标准差、极差和四分位差。
- # 计算方差和标准差
- var(iris$Sepal.Length)
- sd(iris$Sepal.Length)
- # 计算极差
- max(iris$Sepal.Length)-min(iris$Sepal.Length)
- # 计算四分位差
- q1<-quantile(iris$Sepal.Length,0.25)
- q3<-quantile(iris$Sepal.Length,0.75)
- q3-q1

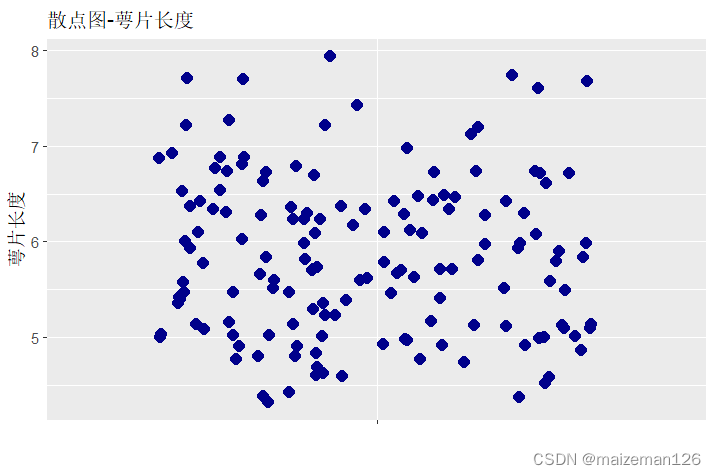
(4)离散程度可视化
数据离散程度的可视化常用方法有:散点图、箱线图。
- # 绘制散点图
- ggplot(iris,aes(x="",y=Sepal.Length))+geom_jitter(
- shape=16,size=3,color="darkblue"
- )+labs(
- title="散点图-萼片长度",x="",y="萼片长度"
- )
(5)数据的分布形状度量
是指通过统计量或图形来描述数据分布的形状特征。常用的分布形状度量包括偏度(skewness)和偏度(kurtosis)。
- # 安装moments包
- install.packages("moments")
- # 加载moments包
- library(moments)
- skewness(iris$Sepal.Length)
- kurtosis(iris$Sepal.Length)

二、一站式描述统计函数
1、summary()函数
基础包中的summary()函数提供最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑性向量的频数统计
- # 每加仑汽油形式英里数(mpg)、马力(hp)、车重(wt)
- vars<-c('mpg','hp','wt')
- # 展示部分数据
- head(mtcars[vars])
- # 应用summary()函数
- summary(mtcars[vars])

2、sapply()函数
sapply()函数计算自定义的任意描述性统计量。
- # 使用sapply()函数自定义描述性统计分析
- mystats<-function(x,na.omit=FALSE){
- if(na.omit)
- x<-x[!is.na(x)]
- m<-mean(x)
- n<-length(x)
- s<-sd(x)
- skew<-sum((x-m)^3/s^3)/n
- kurt<-sum((x-m)^4/s^4)/n-3
- return(c(n=n,mean=m,stdev=s,skew=skew,kurtosis=kurt))
- }
- sapply(mtcars[vars],mystats)

3、Hmisc包中的describe()函数
Hmisc包中的describe()函数可返回变量可观测的数量、缺失值和唯一值的数目、平均值、分位数、以及前五个最大值和最小值。
- # 下载Hmisc包
- install.packages("Hmisc")
- # 加载Hmisc包
- library(Hmisc)
- # 应用describe()函数
- describe(mtcars[vars])

4、pastecs包的stat.desc()函数
此函数可以计算种类繁多的描述性统计量。
- install.packages("pastecs")
- # 加载pastecs包
- library(pastecs)
- # 应用stat.desc()函数
- stat.desc(mtcars[vars])

5、psych包的describe()函数
它可以计算非缺失值的数量、平均数、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、值域、偏度、峰度和平均值的标准误。
- install.packages("psych")
- # 加载psych包
- library(psych)
- # 应用describe函数
- describe(mtcars[vars])

6、explore包中的explore()函数
此函数能够实现交互式数据探索。
- install.packages("dplyr")
- install.packages("explore")
- library(dplyr)
- library(explore)
- explore(mtcars[vars])

-
相关阅读:
什么是腾讯云云硬盘?有哪些优势?应用于哪些场景?
Spring面试题23:Spring支持哪些事务管理类型?Spring框架的事务管理有哪些优点?你更倾向用哪种事务管理类型?
Java枚举类的使用
0号进程,1号进程,2号进程
VVC码率控制改进
15、spring+mybatis+servlet框架搭建
Shire.run:Prompt 即代码到 Prompt 即程序,思考 Prompt 的无限可能性
使用Docker安装MySQL
likeshop外卖点餐系统【100%开源无加密】
【Express】服务端渲染(模板引擎 EJS)
- 原文地址:https://blog.csdn.net/maizeman126/article/details/137424673
